introduction to regular expressions - amazon s3 · datacamp natural language processing...
TRANSCRIPT

DataCamp NaturalLanguageProcessingFundamentalsinPython
Introductiontoregularexpressions
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON
KatharineJarmulFounder,kjamistan

DataCamp NaturalLanguageProcessingFundamentalsinPython
WhatisNaturalLanguageProcessing?Fieldofstudyfocusedonmakingsenseoflanguage
UsingstatisticsandcomputersYouwilllearnthebasicsofNLP
TopicidentificationTextclassification
NLPapplicationsinclude:ChatbotsTranslationSentimentanalysis...andmanymore!

DataCamp NaturalLanguageProcessingFundamentalsinPython
Whatexactlyareregularexpressions?StringswithaspecialsyntaxAllowustomatchpatternsinotherstringsApplicationsofregularexpressions:
FindallweblinksinadocumentParseemailaddresses,remove/replaceunwantedcharacters
In[1]:importre
In[2]:re.match('abc','abcdef')Out[2]:<_sre.SRE_Matchobject;span=(0,3),match='abc'>
In[3]:word_regex='\w+'
In[4]:re.match(word_regex,'hithere!')Out[4]:<_sre.SRE_Matchobject;span=(0,2),match='hi'>

DataCamp NaturalLanguageProcessingFundamentalsinPython
CommonRegexPatternspattern matches example
\w+ word 'Magic'

DataCamp NaturalLanguageProcessingFundamentalsinPython
CommonRegexpatterns(2)pattern matches example
\w+ word 'Magic'
\d digit 9

DataCamp NaturalLanguageProcessingFundamentalsinPython
Commonregexpatterns(3)pattern matches example
\w+ word 'Magic'
\d digit 9
\s space ''

DataCamp NaturalLanguageProcessingFundamentalsinPython
Commonregexpatterns(4)pattern matches example
\w+ word 'Magic'
\d digit 9
\s space ''
.* wildcard 'username74'

DataCamp NaturalLanguageProcessingFundamentalsinPython
Commonregexpatterns(5)pattern matches example
\w+ word 'Magic'
\d digit 9
\s space ''
.* wildcard 'username74'
+or* greedymatch 'aaaaaa'

DataCamp NaturalLanguageProcessingFundamentalsinPython
Commonregexpatterns(6)pattern matches example
\w+ word 'Magic'
\d digit 9
\s space ''
.* wildcard 'username74'
+or* greedymatch 'aaaaaa'
\S notspace 'no_spaces'

DataCamp NaturalLanguageProcessingFundamentalsinPython
Commonregexpatterns(7)pattern matches example
\w+ word 'Magic'
\d digit 9
\s space ''
.* wildcard 'username74'
+or* greedymatch 'aaaaaa'
\S notspace 'no_spaces'
[a-z] lowercasegroup 'abcdefg'

DataCamp NaturalLanguageProcessingFundamentalsinPython
Python'sreModuleremodule
split:splitastringonregex
findall:findallpatternsinastring
search:searchforapattern
match:matchanentirestringorsubstringbasedonapattern
Patternfirst,andthestringsecondMayreturnaniterator,string,ormatchobject
In[5]:re.split('\s+','Splitonspaces.')Out[5]:['Split','on','spaces.']

DataCamp NaturalLanguageProcessingFundamentalsinPython
Let'spractice!
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON

DataCamp NaturalLanguageProcessingFundamentalsinPython
Introductiontotokenization
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON
KatharineJarmulFounder,kjamistan

DataCamp NaturalLanguageProcessingFundamentalsinPython
Whatistokenization?Turningastringordocumentintotokens(smallerchunks)OnestepinpreparingatextforNLPManydifferenttheoriesandrulesYoucancreateyourownrulesusingregularexpressionsSomeexamples:
BreakingoutwordsorsentencesSeparatingpunctuationSeparatingallhashtagsinatweet

DataCamp NaturalLanguageProcessingFundamentalsinPython
nltklibrarynltk:naturallanguagetoolkit
In[1]:fromnltk.tokenizeimportword_tokenize
In[2]:word_tokenize("Hithere!")Out[2]:['Hi','there','!']

DataCamp NaturalLanguageProcessingFundamentalsinPython
Whytokenize?EasiertomappartofspeechMatchingcommonwordsRemovingunwantedtokens"Idon'tlikeSam'sshoes.""I","do","n't","like","Sam","'s","shoes","."

DataCamp NaturalLanguageProcessingFundamentalsinPython
Othernltktokenizers
sent_tokenize:tokenizeadocumentintosentences
regexp_tokenize:tokenizeastringordocumentbasedonaregularexpressionpattern
TweetTokenizer:specialclassjustfortweettokenization,allowingyoutoseparatehashtags,mentionsandlotsofexclamationpoints!!!

DataCamp NaturalLanguageProcessingFundamentalsinPython
MoreregexpracticeDifferencebetweenre.search()andre.match()
In[1]:importre
In[2]:re.match('abc','abcde')Out[2]:<_sre.SRE_Matchobject;span=(0,3),match='abc'>
In[3]:re.search('abc','abcde')Out[3]:<_sre.SRE_Matchobject;span=(0,3),match='abc'>
In[4]:re.match('cd','abcde')
In[5]:re.search('cd','abcde')Out[5]:<_sre.SRE_Matchobject;span=(2,4),match='cd'>

DataCamp NaturalLanguageProcessingFundamentalsinPython
Let'spractice!
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON

DataCamp NaturalLanguageProcessingFundamentalsinPython
Advancedtokenizationwithregex
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON
KatharineJarmulFounder,kjamistan

DataCamp NaturalLanguageProcessingFundamentalsinPython
Regexgroupsusingor"|"ORisrepresentedusing|
Youcandefineagroupusing()
Youcandefineexplicitcharacterrangesusing[]In[1]:importre
In[2]:match_digits_and_words=('(\d+|\w+)')
In[3]:re.findall(match_digits_and_words,'Hehas11cats.')Out[3]:['He','has','11','cats']

DataCamp NaturalLanguageProcessingFundamentalsinPython
Regexrangesandgroupspattern matches example
[A-Za-z]+ upperandlowercaseEnglishalphabet 'ABCDEFghijk'
[0-9] numbersfrom0to9 9
[A-Za-z\-\.]+
upperandlowercaseEnglishalphabet,-and.
'My-Website.com'
(a-z) a,-andz 'a-z'
(\s+l,) spacesoracomma ','

DataCamp NaturalLanguageProcessingFundamentalsinPython
Characterrangewithre.match()In[1]:importre
In[2]:my_str='matchlowercasespacesnumslike12,butnocommas'
In[3]:re.match('[a-z0-9]+',my_str)Out[3]:<_sre.SRE_Matchobject;span=(0,42),match='matchlowercasespacesnumslike12'>

DataCamp NaturalLanguageProcessingFundamentalsinPython
Let'spractice!
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON

DataCamp NaturalLanguageProcessingFundamentalsinPython
Chartingwordlengthwithnltk
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON
KatharineJarmulFounder,kjamistan

DataCamp NaturalLanguageProcessingFundamentalsinPython
Gettingstartedwithmatplotlib
ChartinglibraryusedbymanyopensourcePythonprojectsStraightforwardfunctionalitywithlotsofoptions
HistogramsBarchartsLinechartsScatterplots
...andalsoadvancedfunctionalitylike3Dgraphsandanimations!

DataCamp NaturalLanguageProcessingFundamentalsinPython
PlottingahistogramwithmatplotlibIn[1]:frommatplotlibimportpyplotasplt
In[2]:plt.hist([1,5,5,7,7,7,9])Out[2]:(array([1.,0.,0.,0.,0.,2.,0.,3.,0.,1.]),array([1.,1.8,2.6,3.4,4.2,5.,5.8,6.6,7.4,8.2,9.]),<alistof10Patchobjects>)
In[3]:plt.show()
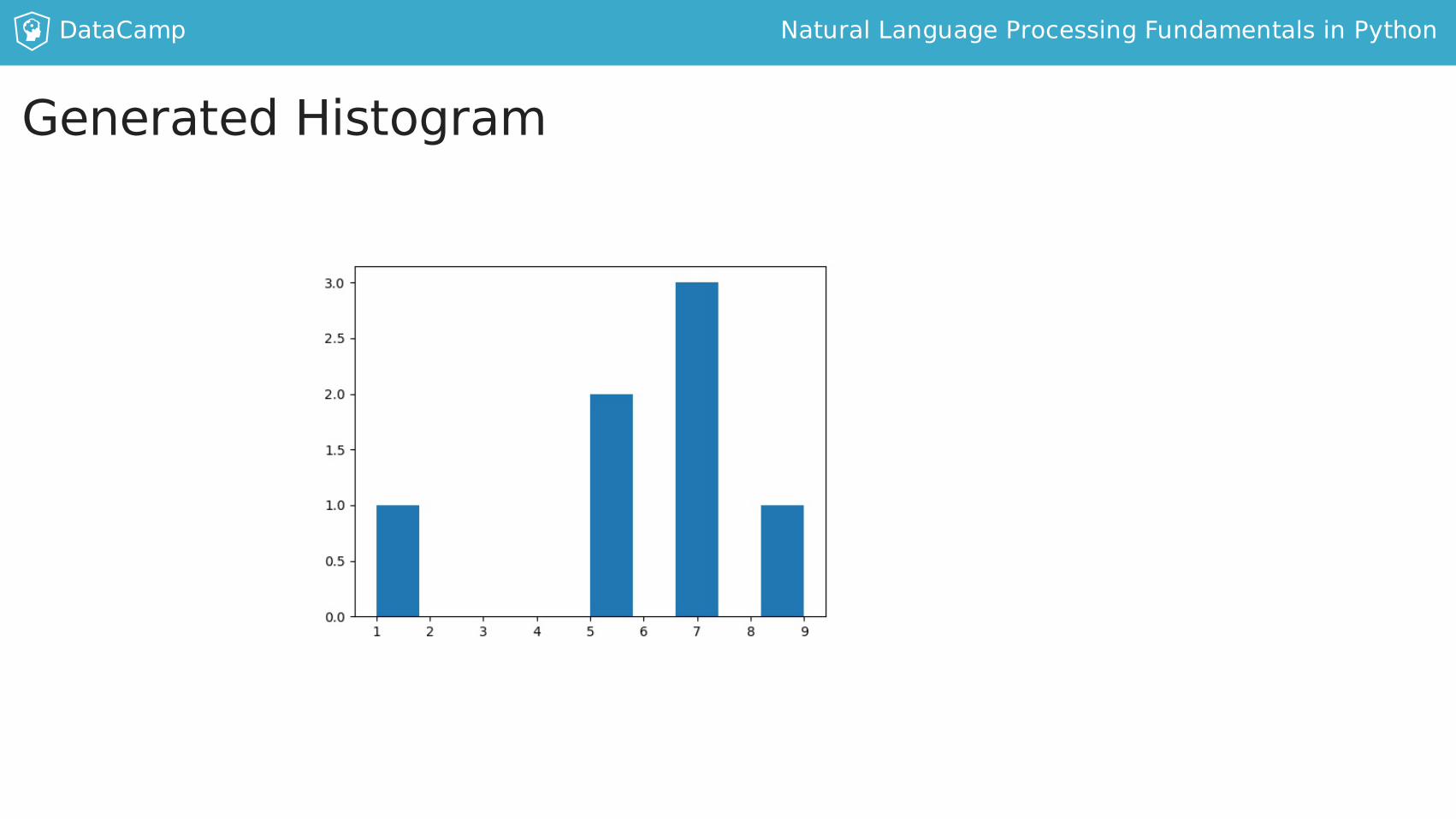
DataCamp NaturalLanguageProcessingFundamentalsinPython
GeneratedHistogram

DataCamp NaturalLanguageProcessingFundamentalsinPython
CombiningNLPdataextractionwithplottingIn[1]:frommatplotlibimportpyplotasplt
In[2]:fromnltk.tokenizeimportword_tokenize
In[3]:words=word_tokenize("Thisisaprettycooltool!")
In[4]:word_lengths=[len(w)forwinwords]
In[5]:plt.hist(word_lengths)Out[5]:(array([2.,0.,1.,0.,0.,0.,3.,0.,0.,1.]),array([1.,1.5,2.,2.5,3.,3.5,4.,4.5,5.,5.5,6.]),<alistof10Patchobjects>)
In[6]:plt.show()

DataCamp NaturalLanguageProcessingFundamentalsinPython
Wordlengthhistogram

DataCamp NaturalLanguageProcessingFundamentalsinPython
Let'spractice!
NATURALLANGUAGEPROCESSINGFUNDAMENTALSINPYTHON