introduction to deep learning @ startup.ml by andres rodriguez
TRANSCRIPT

Proprietary and confidential. Do not distribute.
Introduction to deeplearning with neon
MAKING MACHINES SMARTER.™

Nervana Systems Proprietary
2
• Intel Nervana overview• Machine learning basics
• What is deep learning?
• Basic deep learning concepts
• Example: recognition of handwritten digits
• Model ingredients in-depth
• Deep learning with neon

Nervana Systems Proprietary
Intel Nervana‘s deep learning solution stack
3
Images
Video
Text
Speech
Tabular
Time series
Solutions
Nervana Systems Proprietary
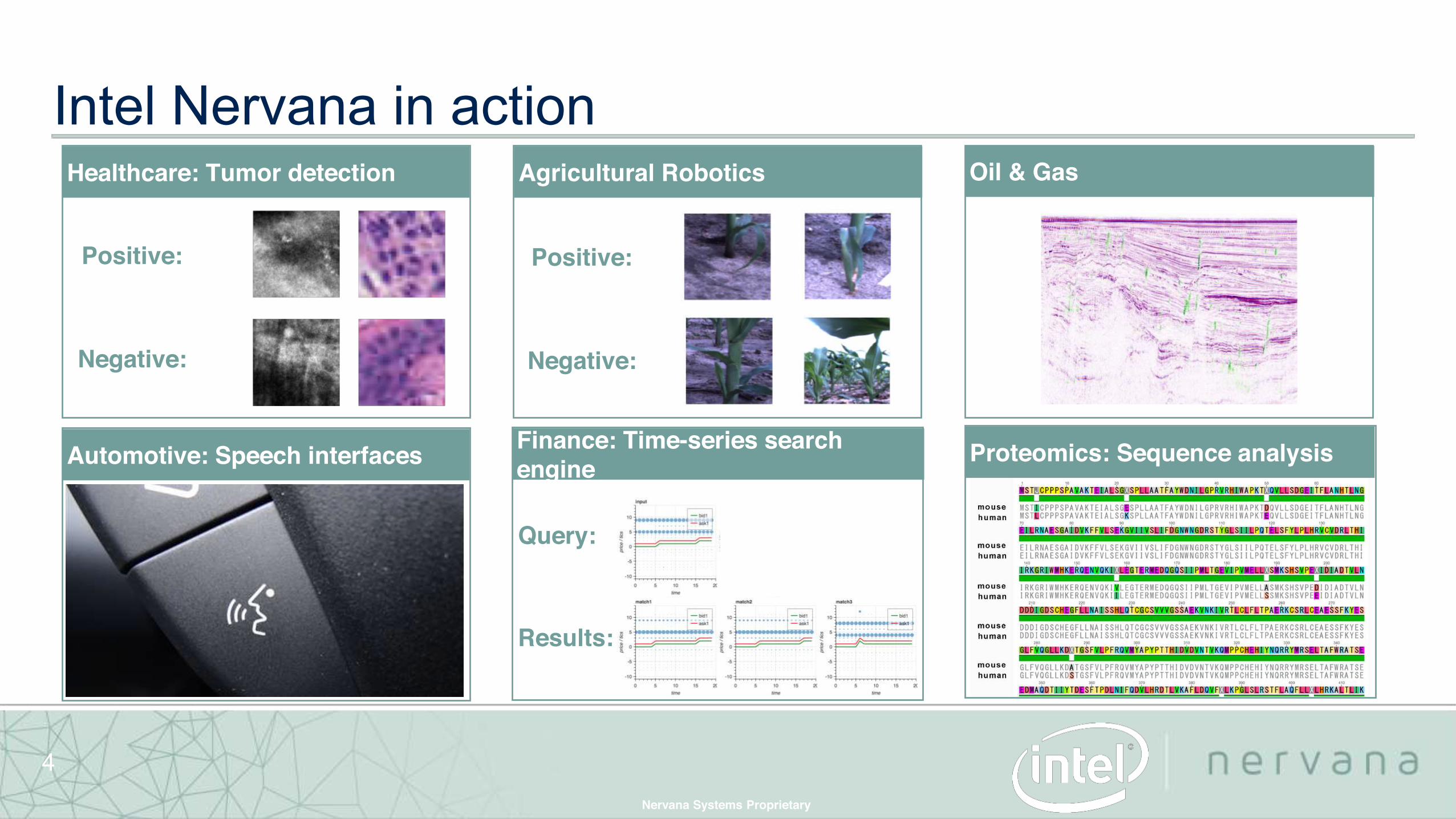
Intel Nervana in action
4
Healthcare: Tumor detection
Automotive: Speech interfaces Finance: Time-series search engine
Positive:
Negative:
Agricultural Robotics Oil & Gas
Positive:
Negative:
Proteomics: Sequence analysis
Query:
Results:

Nervana Systems Proprietary
5
• Intel Nervana overview
• Machine learning basics• What is deep learning?
• Basic deep learning concepts
• Example: recognition of handwritten digits
• Model ingredients in-depth
• Deep learning with neon

Nervana Systems Proprietary
7
Training error

Nervana Systems Proprietary
8
Training error
x
x
x
x
x
x
x
x x
xx
x xx
x x
xxx
x
x
xxx
xxx
Testing error

Nervana Systems Proprietary
9
Training Time
Err
or
Training Error
Testing/Validation Error
Underfitting Overfitting
Bias-Variance Trade-off

Nervana Systems Proprietary
10
• Intel Nervana overview
• Machine learning basics
• What is deep learning?
• Basic deep learning concepts• Model ingredients in-depth
• Deep learning with neon
Nervana Systems Proprietary
11
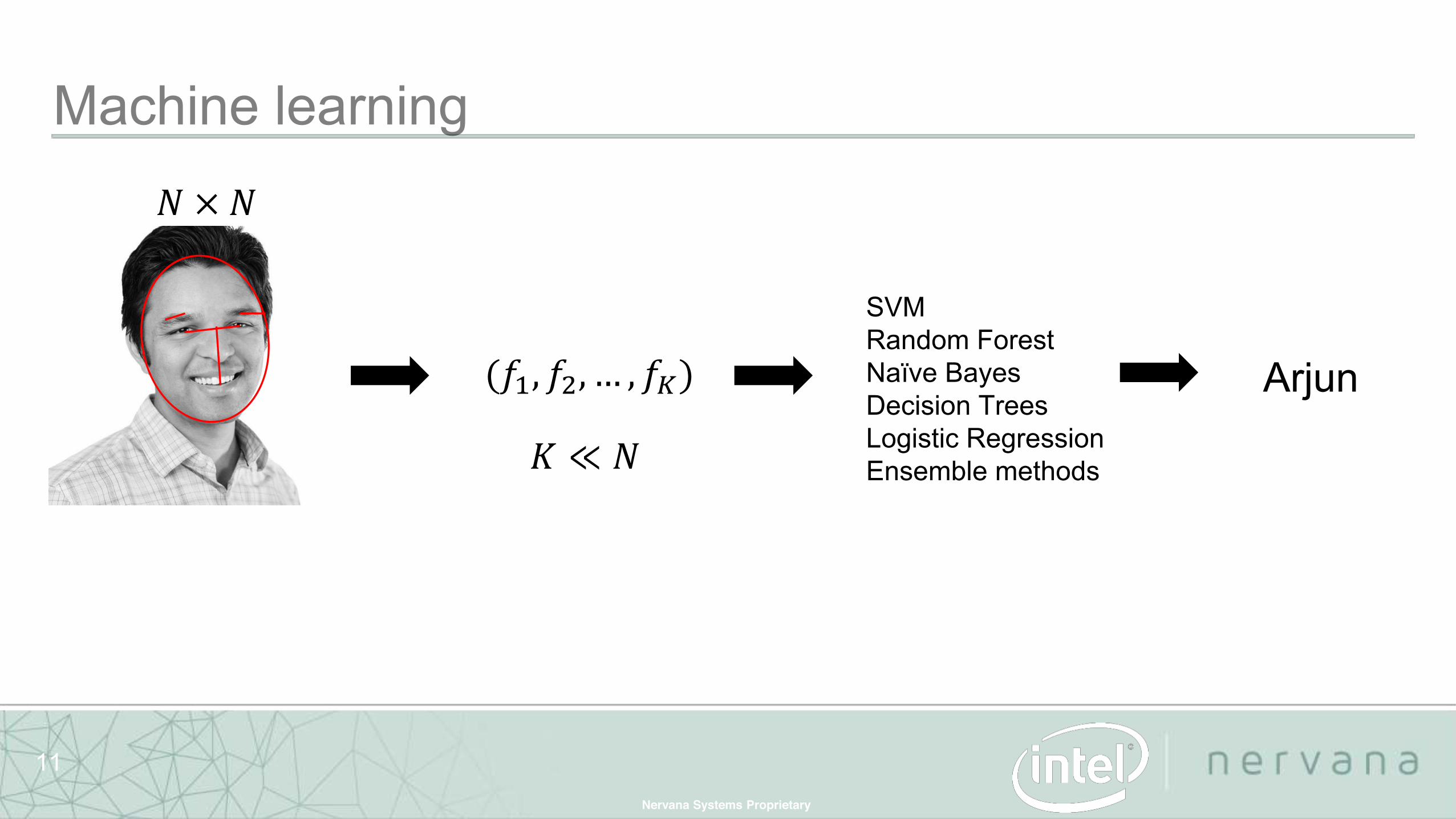
(𝑓1, 𝑓2, … , 𝑓𝐾)
SVMRandom ForestNaïve BayesDecision TreesLogistic RegressionEnsemble methods
𝑁 × 𝑁
𝐾 ≪ 𝑁
Arjun

Nervana Systems Proprietary
12
~60 million parameters
Arjun
But old practices apply: Data Cleaning, Underfit/Overfit, Data exploration, right cost function, hyperparameters, etc.
𝑁 × 𝑁

Nervana Systems Proprietary
13

Nervana Systems Proprietary
𝑦𝑥2
𝑥3
𝑥1
𝑎
max(𝑎, 0)
𝑡𝑎𝑛ℎ(𝑎)
Output of unit
Activation Function
Linear weights Bias unit
Input from unit j
𝒘𝟏𝒘𝟐
𝒘𝟑
𝑔∑

Nervana Systems Proprietary
InputHidden
Output
Affine layer: Linear + Bias + Activation

Nervana Systems Proprietary
MNIST dataset 70,000 images (28x28 pixels)Goal: classify images into a digit 0-9
N = 28 x 28 pixels = 784 input units
N = 10 output units (one for each digit)
Each unit i encodes the probability of the input image of being of the
digit i
N = 100 hidden units (user-defined parameter)
InputHidden
Output

Nervana Systems Proprietary
N=784N=100
N=10
Total parameters:
𝑊𝑖→𝑗, 𝑏𝑗𝑊𝑗→𝑘, 𝑏𝑘
𝑊𝑖→𝑗𝑏𝑗𝑊𝑗→𝑘𝑏𝑘
784 x 100100100 x 1010
= 84,600
𝐿𝑎𝑦𝑒𝑟 𝑖𝐿𝑎𝑦𝑒𝑟 𝑗
𝐿𝑎𝑦𝑒𝑟 𝑘

Nervana Systems Proprietary
InputHidden
Output 1. Randomly seed weights2. Forward-pass3. Cost4. Backward-pass5. Update weights

Nervana Systems Proprietary
InputHidden
Output
𝑊𝑖→𝑗, 𝑏𝑗 ∼ 𝐺𝑎𝑢𝑠𝑠𝑖𝑎𝑛(0,1)
𝑊𝑗→𝑘, 𝑏𝑘 ∼ 𝐺𝑎𝑢𝑠𝑠𝑖𝑎𝑛(0,1)

Nervana Systems Proprietary
0.00.10.00.30.10.10.00.00.40.0
Output (10x1)
28x28
InputHidden
Output

Nervana Systems Proprietary
0.00.10.00.30.10.10.00.00.40.0
Output (10x1)
28x28
InputHidden
Output
0001000000
Ground Truth
Cost function
𝑐(𝑜𝑢𝑡𝑝𝑢𝑡, 𝑡𝑟𝑢𝑡ℎ)

Nervana Systems Proprietary
0.00.10.00.30.10.10.00.00.40.0
Output (10x1)
InputHidden
Output
0001000000
Ground Truth
Cost function
𝑐(𝑜𝑢𝑡𝑝𝑢𝑡, 𝑡𝑟𝑢𝑡ℎ)
Δ𝑊𝑖→𝑗 Δ𝑊𝑗→𝑘

Nervana Systems Proprietary
InputHidden
Output 𝐶 𝑦, 𝑡𝑟𝑢𝑡ℎ
𝑊∗
𝜕𝐶𝜕𝑊∗
compute

Nervana Systems Proprietary
InputHidden
Output 𝐶 𝑦, 𝑡𝑟𝑢𝑡ℎ = 𝐶 𝑔 ∑(𝑊𝑗→𝑘𝑥𝑘 + 𝑏𝑘)
𝑊∗

Nervana Systems Proprietary
InputHidden
Output 𝐶 𝑦, 𝑡𝑟𝑢𝑡ℎ = 𝐶 𝑔 ∑(𝑊𝑗→𝑘𝑥𝑘 + 𝑏𝑘)
𝑎(𝑊𝑗→𝑘, 𝑥𝑘)=
𝑊𝑗→𝑘∗𝜕𝐶𝜕𝑊∗=𝜕𝐶𝜕𝑔∙𝜕𝑔𝜕𝑎∙𝜕𝑎𝜕𝑊∗
a
𝑔 = max(𝑎, 0)
a
𝑔′(𝑎)
= 𝐶 𝑔(𝑎 𝑊𝑗→𝑘, 𝑥𝑘 )

Nervana Systems Proprietary
InputHidden
Output 𝐶 𝑦, 𝑡𝑟𝑢𝑡ℎ = 𝐶 𝑔𝑘(𝑎𝑘 𝑊𝑗→𝑘, 𝑔𝑗(𝑎𝑗(𝑊𝑖→𝑗, 𝑥𝑗))
𝜕𝐶𝜕𝑊∗=𝜕𝐶𝜕𝑔𝑘∙𝜕𝑔𝑘𝜕𝑎𝑘∙𝜕𝑎𝑘𝜕𝑔𝑗∙𝜕𝑔𝑗𝜕𝑎𝑗∙𝜕𝑎𝑗𝜕𝑊∗
𝐶 𝑦, 𝑡𝑟𝑢𝑡ℎ = 𝐶 𝑔𝑘 𝑎𝑘(𝑊𝑗→𝑘, 𝑥𝑘 = 𝑦𝑗
𝑦𝑗
𝑊𝑖→𝑗∗

Nervana Systems Proprietary
Szegedy et al, 2015 Schmidhuber, 1997
• Activation functions• Weight initialization• Learning rule• Layer architecture (number of layers,
layer types, depth, etc.)

Nervana Systems Proprietary
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊

Nervana Systems Proprietary
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
Update weights via:
Δ𝑊 = 𝛼 ∗1𝑁 𝛿𝑊
Learning rate

Nervana Systems Proprietary
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
fprop cost bprop 𝛿𝑊
minibatch #1 weight update
minibatch #2 weight update

Nervana Systems Proprietary
Epoch 0
Epoch 1
Sample numbers:• Learning rate ~0.001• Batch sizes of 32-128• 50-90 epochs

Nervana Systems Proprietary
SGDGradient Descent

Nervana Systems Proprietary
Krizhevsky, 2012
60 million parameters
120 million parametersTaigman, 2014

Nervana Systems Proprietary
34
• Intel Nervana overview
• Machine learning basics
• What is deep learning?
• Basic deep learning concepts
• Model ingredients in-depth• Deep learning with neon

Nervana Systems Proprietary
Dataset Model/Layers Activation OptimizerCost
𝐶(𝑦, 𝑡)

Nervana Systems Proprietary
Filter + Non-Linearity
Pooling
Filter + Non-Linearity
Fully connected layers
…
“how can I help you?”
cat
Low level features
Mid level features
Object parts, phonemes
Objects, words
*Hinton et al., LeCun, Zeiler, Fergus
Filter + Non-Linearity
Pooling

Nervana Systems Proprietary
Tanh Rectified Linear UnitLogistic
-1
11
0
𝑔 𝑎 =𝑒𝑎
∑𝑘 𝑒𝑎𝑘
Softmax

Nervana Systems Proprietary
Gaussian Gaussian(mean, sd)
GlorotUniform Uniform(-k, k)
Xavier Uniform(k, k)
Kaiming Gaussian(0, sigma)
𝑘 =6
𝑑𝑖𝑛 + 𝑑𝑜𝑢𝑡
𝑘 =3𝑑𝑖𝑛
𝜎 =2𝑑𝑖𝑛

Nervana Systems Proprietary
• Cross Entropy Loss
• Misclassification Rate
• Mean Squared Error
• L1 loss

Nervana Systems Proprietary
0.00.10.00.30.10.10.00.00.40.0
Output (10x1)
0001000000
Ground Truth
− 𝑘
𝑡𝑘 × log(𝑦𝑘) = −log(0.3)

Nervana Systems Proprietary
0.3 0.3 0.4
0.3 0.4 0.3
0.1 0.2 0.7
0 0 1
0 1 0
1 0 0
Outputs Targets Correct?
Y
Y
N
0.1 0.2 0.7
0.1 0.7 0.2
0.3 0.4 0.3
0 0 1
0 1 0
1 0 0
Y
Y
N
-(log(0.4) + log(0.4) + log(0.1))/3=1.38
-(log(0.7) + log(0.7) + log(0.3))/3=0.64

Nervana Systems Proprietary
• SGD with Momentum
• RMS propagation
• Adagrad
• Adadelta
• Adam

Nervana Systems Proprietary
Δ𝑊1 Δ𝑊2 Δ𝑊3 Δ𝑊4
training time
𝛼𝑡=4′ =𝛼
Δ𝑊2 2 + Δ𝑊3 2 + Δ𝑊4 2

Nervana Systems Proprietary
Δ𝑊1 Δ𝑊2 Δ𝑊3 Δ𝑊4
training time
𝛼𝑡=𝑇′ =𝛼
∑𝑡=0𝑡=𝑇 Δ𝑊𝑡 2

Nervana Systems Proprietary
45
• Intel Nervana overview
• Machine learning basics
• What is deep learning?
• Basic deep learning concepts
• Model ingredients in-depth
• Deep learning with neon

Nervana Systems Proprietary

Nervana Systems Proprietary

Nervana Systems Proprietary
•Popular, well established, developer familiarity
•Fast to prototype
•Rich ecosystem of existing packages.
•Data Science: pandas, pycuda, ipython, matplotlib, h5py, …
•Good “glue” language: scriptable plus functional and OO support,
plays well with other languages

Nervana Systems Proprietary
Backend NervanaGPU, NervanaCPU
Datasets MNIST, CIFAR-10, Imagenet 1K, PASCAL VOC, Mini-Places2, IMDB, Penn Treebank, Shakespeare Text, bAbI, Hutter-prize, UCF101, flickr8k, flickr30k, COCO
Initializers Constant, Uniform, Gaussian, Glorot Uniform, Xavier, Kaiming, IdentityInit, Orthonormal
Optimizers Gradient Descent with Momentum, RMSProp, AdaDelta, Adam, Adagrad,MultiOptimizer
Activations Rectified Linear, Softmax, Tanh, Logistic, Identity, ExpLin
LayersLinear, Convolution, Pooling, Deconvolution, Dropout, Recurrent,Long Short-
Term Memory, Gated Recurrent Unit, BatchNorm, LookupTable,Local Response Normalization, Bidirectional-RNN, Bidirectional-LSTM
Costs Binary Cross Entropy, Multiclass Cross Entropy, Sum of Squares Error
Metrics Misclassification (Top1, TopK), LogLoss, Accuracy, PrecisionRecall, ObjectDetection

Nervana Systems Proprietary
1. Generate backend2. Load data3. Specify model architecture4. Define training parameters5. Train model6. Evaluate

Nervana Systems Proprietary
