integrating corpus-linguistic and conversation … of social action in interaction’’ ... in...
TRANSCRIPT

ORIGINAL PAPER
Integrating Corpus-Linguistic and Conversation-Analytic Transcription in XML: The Caseof Backchannels and Overlap in StorytellingInteraction
Christoph Ruhlemann1
Received: 15 November 2016 / Accepted: 31 May 2017 / Published online: 15 June 2017
� Springer International Publishing AG 2017
Abstract This paper sketches out and illustrates the research opportunities that
come with the recent addition to BNCweb of very large numbers of audio files for
the spoken component in the BNC. It aims to demonstrate that the availability of the
audio files enables researchers not only to correct the orthographic transcripts, but
also to re-transcribe the conversations using conversation-analytic transcription. It
also shows that the CA transcripts can be integrated into the BNC’s XML anno-
tation network and illustrates how XML query tools such as XPath and XQuery can
be used to efficiently exploit the XML network. The main thrust of the paper is to
argue that the integration of corpus-linguistic and conversation-analytic transcrip-
tion in XML can make major contributions both to CL and CA. CL research into
conversation can for the first time be performed on the basis of transcription that is
‘‘detailed enough to facilitate the analyst’s quest to discover and describe orderly
practices of social action in interaction’’ (Hepburn and Bolden, in: Sidnell, Stivers
(eds) The handbook of conversation analysis, Wiley Malden, 2013: 58) while CA
research can gain a large-scale quantitative basis to substantiate claims about the
generalizability of observed regularities and patterns in talk-in-interaction. To
illustrate the benefits of doing research on re-transcriptions of the BNC’s audio files,
a case study is presented on backchannels occurring in overlap in storytelling
interaction. The case study reveals, inter alia, that backchannels produced by story
recipients simultaneously with parts of the storyteller’s ongoing turn tend to
increase in frequency as the storytelling reaches its climax. Backchannel overlap is
thus in synchrony with story organization. This finding adds weight to Goodwin’s
observation that recipients attend to the task ‘‘not simply of listening to the events
being recounted but rather of distinguishing different subcomponents of the talk in
terms of the alternative possibilities for action they invoke’’ (Goodwin, in:
& Christoph Ruhlemann
1 University of Marburg, Marburg, Germany
123
Corpus Pragmatics (2017) 1:201–232
DOI 10.1007/s41701-017-0018-7

Atkinson, Heritage (eds) Structures of social action: studies in conversation anal-
ysis, Cambridge University Press, Cambridge, 1984: 243). The case study also
presents exploratory evidence to suggest that, arguably due to the extended length of
storytelling turns (Ochs and Capps in Living narrative, Harvard University Press,
Cambridge, 2001), the proportion of overlap in running speech may be considerably
lower in storytelling than in general conversation and telephone conversation.
Keywords BNC � BNCweb � Conversation-analytic transcription � XML � XPath �XQuery � Corpus pragmatics � Backchannels � Overlap � Storytelling
Introduction
The British National Corpus (BNC) is no doubt a remarkable success story as it
probably represents the most widely-used corpus in corpus-linguistic research. A
large contribution to its success has been the creation of BNCweb, a web interface
for the corpus (Hoffmann et al. 2008). BNCweb recently added yet another
achievement to its list of achievements: a substantial number of the audio recordings
on which the transcripts are based were made available (Coleman et al. 2012).
Making available the audio files underyling a spoken corpus does have some
tradition as far as languageas other than English are concerned; see, for example, the
Spoken Dutch Corpus project (1998–2004) (cf. http://lands.let.ru.nl/cgn/doc_
English/topics/project/pro_info.htm) for Dutch as well as the C-ORAL-ROM cor-
pus (2001–2004) for the four main Romance languages (Cresti and Moneglia 2005)
with the language data presented in multimedia format, allowing simultaneous
access to aligned acoustic and textual information.1 For spoken English corpora, the
BNC audio files are a rare exception. The availability of the audio files presents an
extraordinary new research opportunity with important implications for both Corpus
Linguistics (CL) and Conversation Analysis (CA). In this paper the aim is to sketch
out this opportunity.
To start with, transcription errors in the text can be corrected thus improving the
textual accuracy. Also, speakers, up until recently hidden behind speaker ID tags,
come to life, their voices can be heard and speech delivery can now be examined
first-hand: voice quality and its modulation in mimicry, changes in volume, shifts in
pitch, slowing down or speeding up—everything is out in the open. Finally,
characteristics of timing and sequencing can be determined: pauses can be measured
down to split seconds, latching can be detected, overlap can be ascertained beyond
doubt. In other words: there exists now a resource that invites and facilitates the
kind of fine-grained transcription that Conversation Analysis has made its hallmark.
Considering that the audio files record hundreds of hours of conversations involving
very large numbers of very diverse speakers, the potential for conversation-analytic
research is immense and probably, since it is all publicly available, without parallel.
What is more, the audio files come with already-complete orthographic transcripts,
1 The C-ORAL-ROM project started a tradition continued by Brazilian Portuguese, C-ORAL-BRASIL;
Japanese, C-ORAL-JAPAN; and Chinese C-ORAL-CHINA.
202 C. Ruhlemann
123

so the conversations need not be transcribed from scratch. What remains to be done
is re-transcribing the conversations to weed out erroneous transcription and align
the transcripts with CA conventions (see ‘‘Appendix’’). This requires still a lot of
work but far less work than a new transcription. Finally, for both the audio data and
their transcripts, BNC’s XML architecture is in place providing meta-data related to
speakers (age, sex, class, etc.), speaking turns (delimited by\u[ elements), and
Part-of-Speech (PoS) (morpho-syntactic analysis of word-class) for each and every
word form. That is, altogether three resources are available: the audio files, the
transcripts (initially orthographic and, after re-transcription, in CA format), plus the
BNC’s XML scaffolding. If XML is used for the orthographic-transcripts-turned-
CA-transcripts it will be possible to integrate CA-style transcription in the format of
the eXtensible Mark-up Language XML [for an introduction to XML for corpus
linguists see Hardie (2014); for a general introduction, see, for example, Watt
(2002)]. XML ‘‘provides a standard syntax for the mark-up of data and documents’’
(Watt 2002: 1). Its defining feature is the network structure where every node is
connected in some way to any other node in the document and where thus any node
or set of nodes can be addressed and extracted using appropriate XML query
languages such as XPath and XQuery (cf. Watt 2002; Walmsley 2007; Ruhlemann
and Gries 2015).
The integration of corpus-linguistic and conversation-analytic transcription in
XML will make important contributions both to corpus-linguistic and conversation-
analytic research.
CL will benefit from the integration because not only will its data base be
improved in the sense that the re-transcription of the audio files will help purify the
textual record. The corpus data will also become much richer in the sense that the
rudimentary paralinguistic information already available in the BNC, referred to as
‘enhanced orthographic’ (Crowdy 1994: 26), will be augmented significantly by the
rich phonological and interactional minutiae able ‘‘to facilitate the analyst’s quest to
discover and describe orderly practices of social action in interaction’’ (Hepburn and
Bolden 2013: 58). In other words: talk and talk-in-interaction will become
graspable, and researchable, in a resolution rarely achieved in CL research [for a
similarly fine-grained CL annotation project, cf. SPICE-Ireland, a spoken corpus of
Irish English densely annotated for prosody, discourse markers, quotatives,
quotations, and speech acts but not available in XML format (Kallen and Kirk
2012)].
The benefits of integrating corpus-linguistic and conversation-analytic annotation
in XML will be no less tangible for CA research. This is because the XML format
provides a structure that is searchable and extractable with great efficiency using
XML query tools such as XPath and XQuery (for an introduction for corpus
linguists see Ruhlemann et al. 2015; for an application in learner corpora, see
Campillos 2014). The XML format also has been a mandatory feature since 2004 in
the above-mentioned C-ORAL-ROM corpora. The precise searchability and
extractability of CA transcripts encoded in XML will add to CA, typically defined
as a qualitative method (e.g., Stivers and Sidnell 2013: 2), a serious quantitative
component. This quantitative component will come timely as the reliance on the
qualitative method alone has recently been questioned within CA. Stivers (2015),
Integrating Corpus-Linguistic and Conversation-Analytic… 203
123

for example, criticizes the reduction of CA to a merely qualitative method as ‘‘a
very restrictive view of CA’’ (Stivers 2015: 16). Intriguingly, the reduction also runs
counter to fundamental assumptions of CA. One such assumption is Sacks’s ‘‘order
at all points’’ (Sacks 1984: 22) with ‘order’ understood as a ‘‘resource of a culture’’
(Sacks 1984: 22). Based on the notion of order, CA attempts to describe social
practices of action. ‘Practices of action’ involve ‘‘communication rules that
generate regular patterns of understanding and interactional organization’’ (Robin-
son 2007: 65; emphasis in original). Regular patterns, by definition, require
recurrence; recurrence requires quantification. In fact, quantification has long been a
standard ingredient of CA research. While CA ‘‘does not generally report precise
numbers, most papers in this tradition do rely on [scalar] descriptors’’ (Stivers 2015:
6), such as ‘massively’, ‘quite common’, ‘a lot more frequent’, etc. However, scalar
terms are not only inherently vague leaving open the exact amount of a distribution:
How massively? How common? How much more frequent? More importantly, they
are also unable to help the researcher address the crucial question, raised by Sacks
(1984: 23) in the context of speaking of ‘order at all points’, of ‘generalizability’,
the key question of inferential statistics: Is the distribution I observe in my small
sample the same as the distribution in the population of the phenomenon under
investigation? Can I justifiably generalize from sample to population? Answering
this question requires ‘‘numbers and statistics’’ (Robinson 2007: 65). The XML
format for CA transcriptions facilitates these numbers and helps lay the foundations
for descriptive and analytic statistics. Thus, the availability of CA transcripts in
XML opens up the possibility of supporting claims about social practices of action
in talk-in-interaction on a statistically sound basis.
In the following I illustrate the procedure of re-transcribing audio-based BNC
data as CA transcription and integrating the conversation-analytic details into the
BNC’s existing annotational architecture. The description traces the path from the
orthographic transcript (Section ‘‘Orthographic Transcript’’) to the CA transcript
(Section ‘‘CA Transcript’’) and, finally to the CA transcript integrated with the
BNC’s PoS tagging structure in XML (Section ‘‘XML Transcript’’). In Sec-
tion ‘‘XML Transcript’’, I also provide some simple XPath queries for the sample;
the aim here is to illustrate the potential of this technology for extracting data from
densely annotated XML documents and providing the raw data for statistical
analysis. In Section ‘‘Case Study: Backchannels and Overlap in Storytelling
Interaction’’, a case study is presented on backchannels and overlap in storytelling.
Orthographic Transcript
The text chosen for illustrative purposes is a short storytelling from the BNC file
KBD. The telling is part of an extended round of stories (cf. Sacks 1992)
thematically related to unlucky fishing experiences. Excerpt (1) is the orthographic
transcript downloaded fom BNCweb; lines are numbered for ease of reference, the
numbers between line numbers and text represent counts of s-units in the file,\-|-[denotes the boundaries of overlapped speech; finally, arrows are used to draw
attention to special features of the transcript:
204 C. Ruhlemann
123

Even a cursory look through the excerpt raises a few questions: in line 2 the
second overlap delimitor \-|-[ is curiously missing. The same absence can be
observed in lines 12 and 19. The absence is explained by the fact that some tags got
lost in the course of the BNC’s conversion from SGML to XML. These losses
affected mostly instances of overlap and pauses (cf. Hoffmann et al. 2008: 57).
Given the faulty annotation, automatic retrieval of these instances of overlap is
impossible. Further, the transcript records nine pauses; the duration (6 seconds) is
given only for one of them, in line 20.
CA Transcript
The following is an audio-based CA transcript of the same storytelling passage
using Jeffersonian transcription symbols (for CA transcription conventions see, for
example, Liddicott 2007; Schegloff 2000; also, see the list of relevant transcription
symbols in the ‘‘Appendix’’).
(2) [“Drained canal”, BNC: KBD 1790-1801]
Alan 1 Well it's, it's (.) luck innit [( I don' know), ] Barry 2 [ I remember ] once go:n' on, 3 I got- (0.4) we got up 'bou' three three thirty in the morning 4 ( ) went out to er (0.9) canal somewhere up 5 (1.3) 6 Dulga' area past Dulgate 7 (1.3) 8 we set up 9 and we'd we'd been fishing for about two and half hours 10 it's aba- about six thirty in the morning 11 this old farmer comes up 12 says er (1.1) Aye aye lads, 13 he said er (0.7) I wou' n' bother it 14 —> they >>drained this area of the canal a few months aG(h)O<< Hhh::::, 15 [ hh::: GGAeehh::: he ] he he Allan 16 —> [ huh huh huh huh huh .] Barry 17 S(h)at there watching our floats for hours uhheh heh: 18 I mean luckily you- you know, you'd gone on- with a car 19 so it's a ma'er o' throw'n ev'ryth'n in th' back 20 ['n' j's go:n'] s'm'ere else sort of (ay) (1.5) Alan 21 [ ° ye:: ° ] Barry 22 could've sat there all bleed'n' day! 23 (1.00) 24 °°an’ not known anythin' about it.°° 25 (4.4) Alan 26 aye
(1) [BNC: KBD 1790-1801]
Alan 1 1788 Well it's, it's luck innit? 2—> 1789 <-|-> I don't know. Barry 3—> 1790 <-|-> I don't know <-|-> what's going on. 4—> 1791 I don't <pause> we got about three, three thirty in the morning, both of them 5—> went out to er <pause> canal somewhere up <pause> Dulgate, past Dulgate 6 <pause> we set up and we'd <pause> we'd been fishing for about two and 7 half hours it's aba-- <pause> about six thirty in the morning this old farmer 8 comes up says er <pause> aye, aye lads, he said er <pause> I wouldn't 9 bother it, they drained this area of the canal a few <voice quality: 10 laughing>months ago! 11—> 1792 And we said, oh<end of voice quality>! Alan 12—> 1793 Yeah. <laugh> <-|-> Barry 13 1794 <-|-> <laugh> <-|-> <pause> <voice quality: laughing>Sat there watching our 14 floats for hours<end of voice quality>! 15 1795 I mean Alan 16 1796 Yeah. Barry 17 1797 I mean luckily you, you know, you'd gone on a car, with a car so it's a matter 18—> of throwing everything in the back <-|-> and just going <-|-> Alan 19—> 1798 <-|-> That's it. Barry 20—> 1799 somewhere else so <pause dur="6"> could have sat there all bleeding day! 21 1800 And not have known anything about it. Alan 22 1801 Aye.
Integrating Corpus-Linguistic and Conversation-Analytic… 205
123

The changes that have been made to the original transcript are numerous
affecting many layers of discourse and interaction. Not all of them can be mentioned
in detail here. First, overlap annotation in (1) has been corrected in (2), where it is
indicated by square brackets around the overlapped speech; see lines 1–2, 15–16,
and 20–21. Second, laughter, summarily indicated as \laugh[ in (1), is fully
transcribed in (2) with appropriate vowels and laughter pulses in lines 15 and 16
thus indicating what the laughter ‘sounded’ like. Third, the verbal record has seen
many corrections, some large, some small. For example, Barry’s I don’t know
indicated in (1) in line 3 is not supported by the audio data. Only Alan seems to say I
don’ know (without producing a hearable t on the negation) in line 1; however, due
to its occurring in overlap, it cannot be heard with certainty but represents the
transcriber’s ‘best guess’, as indicated by the parentheses. Barry, in the same
overlap, says I remember (with stress on I), certainly an important change over I
don’t know in (1) in that the verb remember is commonly found in story
introductions and thus counts among the turn design features projecting a
storytelling sequence (Rossano 2013). Also, instead of I don’t- in line 4 in (1),
we find I got- in line 3 in (2). Further, backchannels seem to be mis-recorded in (1):
the orthographic transcript features Yeah in line 16 and That’s it in line 19. In the
audio file, the latter does not seem to occur at all, while the former does occur,
however, clearly later in the turn, in low volume and with the diphthong strechted
into a long monophthong e::; see line 21 in (2). Perhaps the most important textual
correction concerns line eleven in (1): there, Alan appears to use constructed dialog
(or direct speech) in And we said, oh in line 11. The audio tape does not evidence
constructed dialog at this point; the BNC’s transcriber may have misheard Alan’s
laughing delivery of S(h)at in line 17 as said oh. Given the centrality of constructed
dialog to storytelling (e.g., Mayes 1990; Ruhlemann 2013), this correction in (2)
must be considered essential.
Fourth, pauses are transcribed rather differently in the two transcripts. While
the number of pauses is not dramatically different—there are ten pauses in (2) as
opposed to nine in (1)—the durational information is dramatically different: not
only are all pauses but the very first one (which is shorter than 0.3 seconds)
measured in seconds up to one decimal but also the 6-second pause recorded in
transcript (1) has disappeared and given way to a mere 1.5 second pause. What
is more, there is a major new pause in line 26 in (2) that was apparently
overlooked in the BNC transcription. This long inter-speaker pause, or gap, is
interactionally significant in that it conveniently signals the storytelling’s
completion.
Fifth, transcript (2) is rich in articulatory detail. To begin with, in (1) Alan is
transcribed as having used Dulgate twice in its full form, whereas in (2) the first
mention of the location in line 3 is shortened to Dulga’. Other such ‘deviant’
pronunciations include don’ in line 2 (instead of don’t) and woul’ in line 13 where
the d is silent. In line 12, the upward arrow : indicates a sharp rise in pitch, whereas
the upper case A in :Aye aye lads marks increased loudness; the colon(s) used in
206 C. Ruhlemann
123

Hhh:::: (line 14) and go:n’ (lines 2 and 15) are used to indicate the stretching of the
sound preceding them. Italics in [I do (line 2) and luckily (line 19) are used to
indicate stress. Punctuation, finally, reflects intonational contours, with the period in
lines 1, 2, and 24 indicating a falling tone and the comma in lines 2, 12, and 14
indicating incomplete intonation.
In sum, there will be little doubt that transcript (2) is of much better quality due to
its greater verbal accuracy and its richer phonological, sequential, temporal and
interactional detail. The key question is whether this level of detail defies XML
transposition. In other words: can CA transcripts be turned into XML transcripts
without compromizing dearly held CA principles?
XML Transcript
In the following I discuss a few key excerpts from the XML version of
transcript (2). The annotation scheme used here is the one underlying
XTranscript, an online tool developed in collaboration with Birmingham City
University for automatic conversion of CA transcripts into the XML syntax
(see Section ‘‘Concluding Remarks’’). The full current scheme can be found in
the ‘‘Appendix’’.
The tagging scheme provides for five broad categories, in XML parlance
‘elements’: the\sequence[ element for sequential features including overlap and
latching; the \voice[ element for phonological characteristics including, for
example, volume, stress, pitch, intonation, etc.; the\timing[ element for temporal
aspects including pausing and variation in tempo of delivery; the\laugh[ element
for laughter including within-speech and between-speech laughter; and, finally, the
\comment[element for transcriber comments relating, for example, to hearability
issues and extra-linguistic events. (For video recordings, more elements are required
to capture gaze and gestures).
In the XML excerpts discussed below, two element types found in the BNC’s
XML file are consistently omitted:\s[ elements for sentence-like units as well as
\c[ elements for grammatical punctuation. In the BNC,\w[ elements have ‘c5’,
‘hw’ and ‘PoS’ attributes. In the interest of legibility of the extracts, the ‘hw’ and
the ‘PoS’ attributes have been removed. Other omissions (for expository reasons)
are indicated by XML comments in the form of\!– –[. Finally, I also show some
rather simple XPath queries for retrieving data from the transcript. The aim here is
to illustrate the potential of this technology for extracting data from densely
annotated XML documents.
Excerpt (3) represents lines 1–2 of the CA transcript in (2). The excerpt illustrates
XML annotation of overlap as a sequential feature, transcriber’s comments, and
some phonological features:
Integrating Corpus-Linguistic and Conversation-Analytic… 207
123

(3) 1 <u who="PS040"> 2 <!-- w-elements omitted --> 3 —> <sequence type="overlap" n="1" part="1"> 4 —> <comment hearing="possible"> 5 <w c5="PNP" >I </w> 6 <w c5="VDB" >do</w> 7 —> <voice realization="n' "> 8 —> <w c5="XX0" >n't </w> 9 </voice> 10 <w c5="VVI" >know</w> 11 —> <voice intonation="continued"/> 12 </comment> 13 </sequence> 14 </u> 15 <u who="PS03W" > 16 —> <sequence type="overlap" n="1" part="2"> 17 —> <voice stress="i" degree="much"> 18 <w c5="PNP" > I</w> 19 </voice> 20 <w c5="VVB" >remember</w> 21 <w c5="ADV">once</w> 22 —> <voice stretch="o" degree="much" realization="go:n' "> 23 —> <w c5="VVG"> going</w> 24 </voice> 25 <w> on</w> 26 —> <voice intonation="continued"/> 27 </sequence> 28 <!-- w-elements omitted --> 29 </u>
In lines 3 and 17, we find \sequence[ elements specified as overlap by
type = ‘‘overlap’’. The\sequence[ elements are wrapped around the simultane-
ously produced verbal material. The elements have two more attributes intended to
provide handles by which to ‘yank out’ different types or components of overlap.
One is ‘n’: its values 1, 2, etc. number the overlaps consecutively in their textual
environment. With this attribute, overlap elements can be extracted by position in
overlap sequences: the first overlap, the second, and so forth. If extracted via ‘n’, the
query will return both the overlapped speech and the overlapping speech. For
example,
//sequence[@type="overlap" and @n="1"]
selects all text-initial overlaps (in the present case, just one).
If, by contrast, the aim is to tease apart overlapping and overlapped speech, the
third attribute ‘part’ comes handy: by specifiying part = ‘‘1’’, only overlapped
speech will be addressed (in most cases, address forms, laughter, tags, or, as in the
present case, turn increments; cf. Jefferson 1979), while specifiying part = ‘‘2’’
addresses overlapping speech. For example:
//sequence[@type="overlap" and @part = "2"]
Within the overlapped sequence, we find in line 4 a\comment[ element. This
element type accomodates the transcriber’s comments related, for example, to extra-
linguistic events or audibility issues; in line 4, the attribute hearing = ‘‘possible’’
indicates that I don’ know is just a candidate hearing. In line 5, we encounter the first
\voice[ element. These elements capture phonological characteristics. The
208 C. Ruhlemann
123

\voice[ element is specified as realization = ‘‘n’ ‘‘ and it encloses the \w[element for n’t in line 9; the meaning of realization = ‘‘n’ ‘‘ is, then, that the
contraction n’t is deviantly realized as n’. Why make this distinction? If n’ were
used instead of n’t in the\w[ element, it would appear as a separate entry in a
frequency list. This would be counterintuitive because n’ is hardly a different word
but rather a different realization of n’t. It should therefore be counted among the
occurrences of n’t. This is made possible by its two-fold record both in the\voice[and the \w[ element (frequency lists are commonly made from the latter). We
notice the same double entry for go:n’ as a value on the ‘realization’ attribute in line
22 and going in line 23. The\voice[element in line 22 also contains the attribute
values stretch = ‘‘o’’ indicating the lengthened sound, and degree = ‘‘much’’
indicating the degree of lengthening.
The element in line 11 grasps the intonation contour of Alan’s I don’ know,
which is incomplete or ‘continued’, as indicated by intonation = ‘‘continued’’. This
\voice[element is ‘empty’, meaning that it does not play host to another element
(empty elements have no closing tag, but instead are closed by the forward slash
after the attribute values.) The same phenomenon, continued intonation, is marked-
up in line 26 for Barry’s once go:n’ on. In line 17, two more\voice[attributes are
found: stress = ‘‘i’’, indicating that Barry stresses the personal pronoun, as well as
degree = ‘‘much’’, indicating the degree to which it is stressed.
We instantly see that the XML annotation has already gained considerably in
‘depth’: the\u[ element in line 1 is parent to the\sequence[ element in line 3,
grandparent to the\comment[ element in line 4, grandgrandparent to the first two
\w[ elements in lines 5 and 6 as well as the \voice[ element in line 7, and
grandgrandgrandparent to the \w[ element which is the child of the \phn[element in line 7. Widely-used corpus tools such as WordSmith fail this depth of
annotation; the XPath and XQuery technologies, by contrast, can handle it with
ease. For example, if the interest is in deviant pronunciations occurring in the
overlaps by a distinct speaker, this rather simple XPath returns, in overlaps by
Barry, all\voice[elements that have a ‘realization’ attribute wherever they may be
tucked in the XML hierarchy:
//u[@who="PS03W"]//sequence[@type="overlap"]//voice[@realization]
That CA transcription in XML format need not always cause deep (and
challenging) dependencies is shown in extract (4), which represents lines 12 to 13 in
the CA transcript in (2). The extract illustrates XML annotation for pausing and
variation in delivery:
Integrating Corpus-Linguistic and Conversation-Analytic… 209
123

(4) 1 <u who="PS03W"> 2 <!-- w-elements omitted --> 3 <w c5="VVZ" >says </w> 2 <w c5="UNC" >er </w> 3 —> <timing type="pause" duration="1.1"/> 4 —> <voice pitch="up" > 5 <w c5="ITJ" >Aye</w> 6 </voice> 7 <w c5="ITJ" >aye </w> 8 <w c5="NN2" >lads</w> 9 —> <voice intonation="continued"/> 10 <w c5="PNP" >he </w> 11 <w c5="VVD" >said </w> 12 <w c5="UNC" >er </w> 13 —> <timing type="pause" duration="1.1"/> 14 <w c5="PNP" >I </w> 15 <voice realization="wou' "> 16 <w c5="VM0" >would</w> 17 </voice> 18 <w c5="XX0" >n't </w> 19 <w c5="VVI" >bother </w> 20 <w c5="PNP" >it</w> 21 <!-- w-elements omitted --> 22 </u>
In (4), lines 3 and 13 show \timing[ elements for the type = ‘‘pause’’; the
attribute values duration = ‘‘1.1’’ and duration = ‘‘0.7’’ record their length. Note that
the pause in line 3 nicely demarcates the beginning of constructed dialog in lines 5–8
thus assuming a function as auditory quotation marker (cf. Bolden 2004; Ruhlemann
2013). Moreover, the attribute pitch = ‘‘up’’ in line 4 accounts for the sharp pitch rise
occurring in Aye. Sharp pitch rises are presumably always interactionally and
discoursally significant. This is demonstrably so in the present case. In (4), the
significance lies in the initiation of constructed dialog, where the pitch rise, much like
the pause, helps the listener identify, to use Goffman’s (1981) terminology, the
speaker’s switch from ‘author’ (of his own words) to ‘animator’ (of the old farmer’s
words). XPath can easily target these pitch rises, simply by addressing the\voice[elements that satisfy the condition of having the attribute value pitch = ‘‘up’’:
//voice[@pitch = "up"]
To investigate whether sharp pitch rises collocate with quotative verbs and,
hence, with constructed dialog (to my knowledge, an as-yet neglected research
question), this query retrieves all words preceding the rise in a 3-word window:
//voice[@pitch = "up"]/preceding::w[position() = 1 to 3]
Excerpt (5) illustrates how the tagging scheme handles laughter. As is well
known, laughter is a central concern in CA research (for example, Jefferson 1985).
CA transcription of laughter aims to approximate what the laughter sounds like by
paying attention to laughter pulses and the appropriate vowel (Liddicott 2007: 26).
Laughter in conversation can occur in two forms: either as within-speech laughter or
as between-speech laughter. The current tagging scheme targets laughter using the
\laugh[ element. The two types of laughter are distinguished by the attributes
‘within-speech’ and ‘between-speech’ respectively. The laughter in lines 13–14 is
210 C. Ruhlemann
123

within-speech. Two attribute values are used to grasp it in more detail: the attribute
value form = ‘‘aG(h)O’’ describes the way in which it intrudes the word within
which it occurred while volume = ‘‘high’’ denotes its high intensity on the second
syllable. The two remaining laughter occurrences in lines 17–18, 20, and 23–25
represent between-speech laughter most of it produced by Barry and Alan
simultaneously. The ‘form’ attribute records laughter pulses as well as vowels.
The two laughs’ almost complete occurrence in overlap represents a neat illustration
of Schegloff’s analysis of laughter as a ‘choral’ activity ‘‘NOT to be done serially
(…) but simultaneously’’ (Schegloff 2000, p. 6).
(5) 1 <u who="PS03W"> 2 <!-- w-elements omitted --> 3 <w c5="PNP" >they </w> 4 <w c5="VVD" >drained </w> 5 <w c5="DT0" >this </w> 6 <w c5="NN1" >area </w> 7 <w c5="PRF" >of </w> 8 <w c5="AT0" >the </w> 9 <w c5="NN1" >canal </w> 10 <w c5="AT0" >a </w> 11 <w c5="DT0" >few </w> 12 <w c5="NN2" >months </w>
13 —> <laugh type="within-speech" form="aG(h)O" volume="high" > 14 —> <w c5="AV0" >ago</w> 15 </laugh> 16 <sequence type="overlap" n="2" part="1">
17 —> <laugh type="between-speech" form="hh::: GGAeehh::: he" 18 —> volume="high"/> 19 </sequence> 20 —> <laugh type="between-speech" form="he he" > 21 </u> 22 <u who="PS040"> 23 <voice intonation="fall"> 23 —> <sequence type="overlap" n="2" part="2"> 24 —> <laugh type="between-speech" 25 —> form="huh huh huh huh huh" /> 26 </sequence> 27 </voice> 28 </u>
Finally, the larger storytelling context suggests that the choral laughter does not
occur randomly in the storytelling sequence but in response to the point of the
storytelling, its climax, and its association with the climax is clearly evidenced by
the laughter’s loudness and extended duration (as indicated by the high number of
laughter pulses). I’ll return to this point in the case study in Section ‘‘Case Study:
Backchannels and Overlap in Storytelling Interaction’’.
Needless to say that the XML format makes these instances of laughter, just as
any other nodes in the XML network, readily available for extraction and
examination. A simple XPath query to retrieve laughter occurring in overlap is this:
//sequence[@type = "overlap"]//laugh
This query returns all instances of simultaneous laughter with all the meta-data
included in the elements. If the laughter sound, captured by the ‘form’ attribute, is of
primary interest, call the string() function:
//sequence[@type = "overlap"]//laugh[@description]/string(@description)
Integrating Corpus-Linguistic and Conversation-Analytic… 211
123

In the following section the aim is to demonstrate the benefits of doing research
on re-transcriptions of the BNC’s audio files. To this end I present a case study on
backchannels occurring in overlap in storytelling interaction.
Case Study: Backchannels and Overlap in Storytelling Interaction
Introduction
Backchannels are unobtrusive vocalisations that are phonologically and semanti-
cally minimal and by which listeners put on record their listening and understand-
ing, and their willingness to continue listening. They are ‘‘not construed as full
turns, but rather pass up the opportunity to take a turn’’ (Levinson and Torreira
2015: 8). There is no shortage of research on backchannels occurring in general
conversation. They have been studied in a wide range of linguistic and linguistics-
related subdisciplines, including conversation analysis (e.g., Jefferson 1986),
sociolinguistics (e.g., Holmes and Stubbe 1997), variational pragmatics (e.g.,
O’Keeffe and Adolphs 2008), and corpus linguistics (e.g., Kjellmer 2009).
Backchannels in storytelling have seen much less scrutiny (e.g., Stivers 2008;
Tolins and Fox Tree 2014; Ruhlemann 2013) and their functions in that particular
(and central) context have not yet been fully understood. The overarching goal in
this brief case study is to contribute to a fuller understanding.
The literature on forms and functions of backchannels is large and diverse.
Kjellmer (2009: 83) notes that it is ‘‘hardly possible to give a finite list of English
backchannels.’’ There is some agreement though as to how backchannels function in
turntaking, namely as non-turn-claiming talk, that is, as talk ‘‘in the back channel,
over which the person who has the turn receives short messages such as yes and uh-
huh without relinquishing the turn’’ (Yngve 1970: 568; see also Wong and Peters
2007: 485; Levinson and Torreira 2015; for a critical discussion of their supposed
‘non-turnhood’, see Ruhlemann 2013, Ruhlemann and Gries 2015). Another
defining feature of backchannels is their ability to occur in overlap, that is,
simultaneously with the main speaker’s talk without being perceived as interrupting
talk (e.g., McCarthy 2003; Wong and Peters 2007). A distinction is sometimes made
between minimal and non-minimal response tokens (e.g., McCarthy 2003) with the
former referring to ‘‘nonword vocalizations such as ‘hnh’ and ‘hmm’’’ (McCarthy
2003: 38) and the latter referring to (strings of) items more readily identifiable as
proper words. Generally, backchannels have been viewed as serving a number of
functions (cf. Stenstrom 1987; Holmes and Stubbe 1997; McCarthy 2003; O’Keeffe
and Adolphs 2008). There is some consensus suggesting that the most basic function
underlying all types of backchannels is vocalizing understanding, that is, ‘‘providing
speakers with feedback that tells them something about how they are being
understood, and thus how they might proceed with the talk’’ (Gardner 1998: 220).
Over and above this basic function additional functions have been distinguished
acting alongside the basic vocalizing understanding function. These additional
functions include the following: the function as ‘continuer’, exhibiting ‘‘an
understanding that an extended unit of talk is underway by another [speaker] and
212 C. Ruhlemann
123

that it is not yet, or may not yet be (…) complete’’ (Schegloff 1982: 81). Stivers
(2013) refers to this type of backchannel function as ‘acknowledgement token’
noting that it occurs in the early stages of storytelling interaction. Further, O’Keefe
and Adolphs (2008) identify a distinct function as ‘convergence token’. This
function is ‘‘found at points of convergence in conversations, that is, where
participants agree, or simply converge on opinions or mundane topics’’ (O’Keeffe
and Adolphs 2008: 85). Holmes and Stubbe (1997) describe the function as
‘supportive minimal response’ (Holmes and Stubbe 1997: 11) signaling ‘‘an
increasing degree of interactional involvement on the part of the listener’’; cf.
O’Keefe and Adolphs’s (2008) related notion of ‘engagement tokens’. In Stiver’s
terminology, both convergence tokens and supportive response tokens would
probably be covered by the term ‘affiliative token’. Backchannels serving to register
the recipient’s affiliation with the main speaker, Stivers (2013) adds, are found at
later stages in storytelling interaction, specifically around the climax where the
recipient’s aggreeing and affiliating with the narrator’s ‘stance’ towards the
recounted events becomes relevant. Finally, investigating the temporal properties of
minimal backchannels, Peters and Wong (2015) observe a significant correlation of
the lengths of the listener-controled interval preceding the backchannel yeah and the
lengths of the speaker-controled interval following yeah. They interpret this finding
as accommodation on the part of the speaker, whose ‘‘response time is intended to
match up with that of the listener-produced interval’’ (Peters and Wong 2015: 424)
before yeah. In this case, then, yeah assumes the function of a ‘discontinuer’,
signaling the half-time of the current speaker’s turn and the listener’s wish to take
over the speaking turn after the remaining interval.
Research on overlap, on the other hand, has been one of the mainstays of
conversation-analytic research whereas there has been ‘‘a lack of detailed statistical
analysis of overlaps in corpora’’ (Levinson and Torreira 2015: 6). The long research
tradition in CA arguably originates in Sacks et al. (1974) seminal treatment on turn-
taking, where it was observed that ‘‘[t]ransitions (from one turn to a next) with no
gap and no overlap between them are common’’ (Sacks et al. 1974: 700). ‘No
overlap’, however, is not to be taken as an exact acoustic quantification. As Heldner
and Edlund (2010) have shown, turn transitions from one speaker to another are
most commonly 200 ms long, that is, they occur after a slight gap, while the second
most common type of transition is in overlap, with overlap accounting for 40% of
all transitions (Heldner and Edlund 2010: 564). Cases of zero gap and zero overlap,
by contrast, represented only a ‘‘marginal part’’ in Heldner and Edlund’s (2010:
564) data. Sacks et al.’s (1974) model of turn-taking suggested ‘‘systematic bases
for the occurrence of overlap’’ (Sacks et al. 1974: 706), including competition
between self-selecting speakers (two speakers happen to start up a turn at the same
time) as well as projection (prediction) of turn completion. This latter type has been
found to be ‘‘massively present’’ (Jefferson 1986: 158; cf. also Jefferson
1973, 1986), particularly in cases of ‘terminal overlap’ occurring when a recipient
‘‘reasonably, warrentedly treats some current utterance as complete, ‘transition
ready’’’ (Jefferson 1986: 154) and starts up speaking at the same time as the speaker
adds an increment to an otherwise complete turn (another optional adverbial,
vocative, tag question, etc.).
Integrating Corpus-Linguistic and Conversation-Analytic… 213
123

Also, overlap is intimately associated with backchannelling. Indeed, backchan-
nels provide the core ecological niche for the occurrence of overlap in that, for
example in Levinson and Torreira’s (2015) large-scale corpus analysis, ‘‘the
majority of overlap cases (73%) involved a backchannel’’ (Levinson and Torreira
2015: 8).
This brief case study focuses on backchannels in overlap. Its target is thus a
restricted type of speaker transition. While backchannels in conversation generally
may be one context among a number of contexts for overlap (but even there,
backchannels are the prime context of occurrence for overlap; see above), in
storytelling, however, backchannels may be considered crucial. It can be argued that
in storytelling the backchannel response represents the default type of reponse.
Stories, Sacks noted, ‘‘take more than an utterance to produce’’ (Sacks 1992: 222)
and story recipients ‘‘are specifically invited’’ (Sacks 1992: 227) to provide tokens
of listenership to convey ‘‘the recognition that a story is being told’’ (Sacks 1992:
227), a recognition typically accomplished by means of Schegloff’s ‘continuers’.
Similarly, backchannels are used by recipients to affiliate with the teller’s stance
around the climax, an affiliation typically realized by Stivers’s affiliation tokens.
The relationship between backchannels and overlap in storytelling is, then, anything
but peripheral but central to the social practices of action driving the ‘machinery’
(Sacks 1984) of storytelling as an interactional achievement by the teller and the
recipient(s).
The analysis will address five research questions:
(1) How often do backchannels occur in overlap in storytelling?
(2) Which backchannels occur in, which outside of overlap?
(3) How long are backchannel overlaps?
(4) How long are backchannel overlaps compared to the overlapped turn?
(5) How much running speech is occupied by backchannel overlap in
storytelling?
In the following section, I briefly describe the data and methods used for this case
study.
Data and Methods
The data underlying this case study come from the the Narrative Corpus (NC;
Ruhlemann and O’Donnell 2012), extracted from the demographically-sampled
sub-corpus of the British National Corpus (BNC). The NC is a densely annotated
XML corpus. Not only does the NC feature all the corpus-linguistic annotation of its
mother corpus, the BNC, including meta-data on speakers, textual divisions, turn
beginnings, and, characteristically, Parts-of-Speech (PoS) markup. The NC also
integrates an extensive discourse-analytic layer of annotation to capture storytelling-
specific characteristics, including narrative sub-genre (1st person experience, 3rd
person experience, etc.), textual component (pre-narrative component, story-initial
utterance, etc.), textual embedding (free-standing story, or 1st, 2nd, 3rd in story
round), quotatives (SAY, GO, THINK, BE like, etc.), and discourse presentation
214 C. Ruhlemann
123

(direct speech, free direct speech, indirect speech, etc.). Yet another discourse-
analytic annotation type, which is critical in the present connection, is
participant role. This annotation category distinguishes narrator and recipient
sub-roles on an utterance-by-utterance basis. One of the two recipient sub-roles
recognized in the NC is ‘responsive recipiency’, tagged as PRR. Tagging a
response as PRR is based, not on a formal, but a functional definition of
backchannel response: utterances by story recipients are tagged PRR if, and only
if, line-by-line analysis of the sequential context suggests that the recipient’s
utterance is ‘informationally redundant’ [cf. Walker’s (1993) concept of
informationally-redundant utterances] in that the recipient does not add, or
elicit via questions, any topic-related content to the story, but merely signals
distinct levels of reception (acknowledging or affiliating) and structural analysis
of the on-going telling performance. Thus, responses labeled PRR represent
backchannel responses.
The NC is not based on the BNC’s audio data. For the purpose of the case study,
a targeted re-analysis of the NC data was undertaken where audio files were
available. The steps involved in this process were the following.
First, using complex XQuery scripts, all backchannel responses and the
storytelling turns to which they were a response were extracted from the NC;
also extracted were the number of words in each storytelling turn as well as the
positions of the backchannels in the sequential context of their storytelling.
Following established procedure (e.g., Hoey and O’Donnell 2008; Ruhlemann
2013), positions were calculated as proportions obtained from dividing the number
of words preceding the backchannel by the total number of words in the story.
Positional values range on a continuum from 0 (very first position) to 1 (very last
position). Thus, for example, an mm by a recipient occurring after a story-initial turn
of, say, 20 words’ length and occurring in a story that turns out to be a 100 words
long would be positioned at 9/100 = 0.09. The total number of backchannel
responses thus extracted was 1,265.
Second, all turn-backchannel pairs were tested for whether they were available in
the BNC audio files. The pairs available in audio were re-transcribed and re-
analyzed using Audacity (http://www.audacityteam.org/), an acoustic analysis
software. Re-transcription involved correcting errors in the BNC’s orthographic
transcript, while re-analysis involved re-measuring intra- and inter-speaker pauses,
measuring durations of overlaps, defining the exact extent of overlap in the text (for
example, if a word was only partially overlapped). The number of turn-backchannel
pairs thus processed was 820 occurring in 231 storytellings; the backchannels were
produced by 189 distinct speakers covering a wide range of socio-demographics.
Third, the data were examined using descriptive and analytic statistics in R, a
programming language and environment for data analysis and graphical represen-
tation (cf., for example, Gries 2009a, b).
Integrating Corpus-Linguistic and Conversation-Analytic… 215
123

Results
The first research question (how often do backchannels occur in overlap in
storytelling?) can be addressed by comparing frequencies of backchannels in
overlap and outside of overlap.
As shown in Table 1, backchannel overlap was found for 336 backchannels,
accounting for 41% of all backchannels, whereas 478 backchannels occurred
without overlap, representing 58%. This distribution is largely consistent with
reported distributions. Kjellmer (2009: 86), not specifying proportions, notes that
backchannels occur ‘‘predominantly turn-externally’’ (i.e., outside of overlap). ten
Bosch et al. (2005) found overlap to account for 44% of speaker changes in face-to-
face conversation. Heldner and Edlund (2010) report 40% of speaker-transitions
involving overlaps. Only in Levinson and Torreira (2015) the proportion of overlap
was clearly lower, with 30% of transitions occurring in overlap. The present
findings relate only to a subset of overlap transitions, namely backchannel overlap,
not to overlap tout court. Nonetheless, considering most reported proportions, the
proportion of overlap incurred by backchannels in storytelling is a fair reflection of
the proportion of overlap incurred by any linguistic means.
The second question (Which backchannels occur in, which outside of overlap?)
has, to the best of my knowledge, not yet been addressed in published research.
Given that the data are drawn from a representative corpus (the NC; cf.
Section ‘‘Data and Methods’’), the question can be approached with a view to
statictical analysis. To this end, frequency lists were generated for two subsets:
(i) backchannels occurring in overlap, and (ii) backchannels occurring outside of
overlap. All intersecting backchannels (i.e., backchannels included in both subsets)
were identified; items not intersecting the subsets were highly infrequent and not
further investigated. Permutation tests were performed on the intersecting items.
The permutation test is a computationally expensive, non-parametric test. Under-
lying it is the assumption that, given the null hypothesis that labelings (such as, in
the present case, whether a backchannel occurs in overlap or not) are arbitrary, the
significance of a given distribution (in the present case, the frequency of
backchannels in and out of overlap) can be assessed ‘‘via comparison with the
distribution of values obtained when the labels are permuted’’ (Nichols and Holmes
2001: 2–3). The results are displayed in Table 2.
As can be seen from Table 2, the test returned significant results for 6 items: mm,
mhm, no, and yeah are more frequent outside of overlap, while yeah yeah as well as
laughter are more common in overlap. As regards laughter, it will not be surprising
that it is more frequently overlapped than free-standing: this tendency has already
Table 1 Frequencies and
percentages of BC in and out of
overlap
BC Frequency %
Overlap 336 40.98
No overlap 478 58.29
Unclear 6 0.73
Total 820 100
216 C. Ruhlemann
123

been observed in CA research. Schegloff, for example, views laughter as a ‘choral’
activity ‘‘NOT to be done serially (…) but simultaneously’’ (Schegloff 2000: 6). But
the significant results also invite interesting hypotheses with regard to the sequential
placement of overlap in storytelling. Stivers (2013: 201) views backchannels such as
mm and mhm as acknowledging tokens occurring ‘‘early in the telling’’; by contrast,
affiliative items ‘‘are common (…) near the high point of the telling’’ (Stivers 2013:
201). She cites head nods, great!, and wow! as examples of affiliative backchannels.
Laughter, it seems, in most cases also performs an affiliative rather than an
acknowledging function. Thus, it is tempting to hypothesize that overlapped
laughter is more commonly found around the climax. To test this hypothesis, based
on the procedure described in Section ‘‘Data and Methods’’, the positions of
overlapped laughter in the context of their storytellings (and, for comparison, of mm
and yeah) were calculated. The results are depicted in the three histograms in Fig. 1.
Table 2 Frequencies and permutation test statistics for backchannels in and out of overlap
BC Freq_in Freq_out CI_lower CI_upper p-value Sign
((laughs)) 54 49 0.01042 0.01042 0.01815 *
(unclear) 4 1 -0.00397 -0.00395 0.16576 ns
ah 3 4 -0.01087 -0.01083 1 ns
aha 3 8 -0.025 -0.025 0.37962 ns
aye 1 4 -0.01571 0.00513 0.4111 ns
did she 1 1 -0.00529 0.00532 1 ns
hm 2 6 -0.02062 0.00526 0.48112 ns
i know 1 2 -0.01031 0.00526 1 ns
i see 1 1 -0.00529 0.00532 1 ns
it was 1 1 -0.00529 0.00532 1 ns
mhm 4 24 -0.06404 -0.01471 0.00286 **
mm 56 112 -0.12435 -0.01042 0.02204 *
mm mm 9 6 -0.0051 0.03185 0.18516 ns
no 1 12 -0.0402 -0.00508 0.01918 *
oh 12 20 -0.03415 0.02051 0.71708 ns
oh (unclear) 1 1 -0.00529 0.00532 1 ns
oh no 3 2 -0.00529 0.01531 0.65393 ns
oh right 1 1 -0.00529 0.00532 1 ns
oh yes 1 3 -0.01463 -0.0146 0.64666 ns
ooh 3 1 -0.0049 0.01554 0.31196 ns
that’s right 1 3 -0.01463 -0.0146 0.64666 ns
tt 1 1 -0.00529 0.00532 1 ns
yeah 52 109 -0.12889 -0.12887 0.01218 *
yeah yeah 10 3 0.0051 0.04054 0.01053 *
yes 12 15 -0.02066 -0.02062 0.84289 ns
yes yeah 1 2 -0.01031 0.00526 1 ns
Integrating Corpus-Linguistic and Conversation-Analytic… 217
123
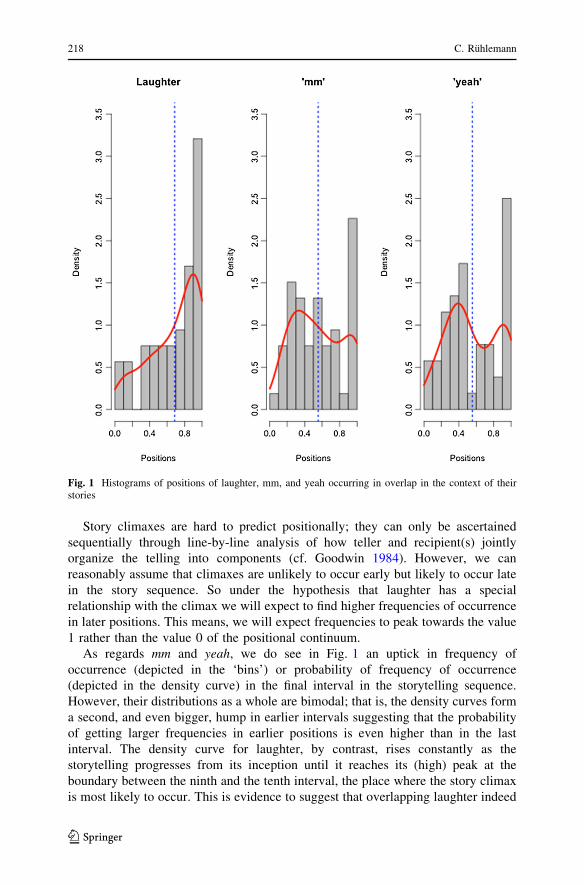
Story climaxes are hard to predict positionally; they can only be ascertained
sequentially through line-by-line analysis of how teller and recipient(s) jointly
organize the telling into components (cf. Goodwin 1984). However, we can
reasonably assume that climaxes are unlikely to occur early but likely to occur late
in the story sequence. So under the hypothesis that laughter has a special
relationship with the climax we will expect to find higher frequencies of occurrence
in later positions. This means, we will expect frequencies to peak towards the value
1 rather than the value 0 of the positional continuum.
As regards mm and yeah, we do see in Fig. 1 an uptick in frequency of
occurrence (depicted in the ‘bins’) or probability of frequency of occurrence
(depicted in the density curve) in the final interval in the storytelling sequence.
However, their distributions as a whole are bimodal; that is, the density curves form
a second, and even bigger, hump in earlier intervals suggesting that the probability
of getting larger frequencies in earlier positions is even higher than in the last
interval. The density curve for laughter, by contrast, rises constantly as the
storytelling progresses from its inception until it reaches its (high) peak at the
boundary between the ninth and the tenth interval, the place where the story climax
is most likely to occur. This is evidence to suggest that overlapping laughter indeed
Fig. 1 Histograms of positions of laughter, mm, and yeah occurring in overlap in the context of theirstories
218 C. Ruhlemann
123

clusters around positions in the storytelling sequence where the storyteller is likely
to reach the high point of the story. Consider, for illustration, the storytelling
‘‘Dropped your johnnies’’ in (6). While there is laughter already early on (see lines
3, 5, and 6–7), the overlapping laughter that is the most extended and the one with
the greatest acoustic intensity, in lines 22–24, represents not only Joanne’s and
Helen’s acceptance of Andy’s invitation to laugh with him (cf. Jefferson 1979) but
also a clearly affiliative reponse by the two recipients to the story climax realized, as
so often (e.g., Mayes 1990, Holt 1996), in constructed dialog (hi Greg (1.57)
dropped your johnnies>) in line 20.
(6) [“Dropped your johnnies”, BNC: KCE 2659-2674] Andy 1 Oh it was so funny at work today, 2 Greg fell off his chair. Helena 3 Hh. Andy 4 Packet of condoms fell out of his pocket Helena 5 eh Hih Heh Huh huh huh huh Andy 6 And they were ripped [ h'::: ] Helena 7 [ heh Heh eh heh ] Andy 8 Ah no he was, 9 he, he wouldn't sit on his chair 10 cos he'd just called me an arsehole? (0.45) 11 and I goes oh sit down on y’ chair Greg mh'm 12 I said sit down Gregory and shut up, 13 so he went to sit down 14 but his chair weren't there? (0.89)
15 All I saw were his pair of legs ( ) over the desk 16 and him goin’ AAAAgh::Joanne 17 °And his [condoms ( )] Andy 18 [ He got up ] 19 and then one of the girls says (.) 20 hi Greg (1.57) dropped your johnnies¿ 22 [ heh heh ] Joanne 23 [ heh hih hih heh hih heh hih huh huh] Helen 24 [ h'm Heh Heh Heh heh heh heh] Andy 25 [ I’ve ] never seen anyone go so red in my life.
This is evidence, then, to suggest that laughter in overlap has its preferred locus
around the climax. It is, then, synchronized with story organization. This is no small
discovery in that it adds weight to Goodwin’s observation that recipients attend to
the task ‘‘not simply of listening to the events being recounted but rather of
distinguishing different subcomponents of the talk in terms of the alternative
possibilities for action they invoke’’ (Goodwin 1984: 243).
The third question concerns the durations of backchannel overlaps. As noted,
using Audacity the temporal extensions of overlaps were measured. In a number of
cases, durations could not be established with certainty, due to poor audio quality or
interfering background noises. The number of overlaps (and their corresponding
turns) for which durations could be reliably observed was 291.
As depicted in the scatterplot in the left panel of Fig. 2, overlaps are brief: the
median duration is half a second, while the mean is 0.63 seconds. Only occasionally
did overlap exceed one second. This finding is almost perfectly consistent with
previous research. Heldner and Edlund (2010), for example, report for overlap a
mean length of 610 ms and a median length of 470 ms. The findings then support the
view that ‘‘the bulk of overlaps are of short duration’’ (Levinson and Torreira 2015:
4; cf. also Wong and Peters 2007; Peters and Wong 2015).
Integrating Corpus-Linguistic and Conversation-Analytic… 219
123

The stripchart in the right panel in Fig. 2 also depicts overlap durations but
additionally presents color codings for the five most frequent backchannels occurring
in overlap: mm (51 occurrences), yeah (46 occ.), laughter (40 occ.), oh (11 occ.), and
yes (11 occ.). It can be seen that the median durations (depicted in the dotted vertical
lines) for mm, yeah, oh, and yes are all smaller than the median for all backchannels in
overlap (which is 0.5). Conversely, the median duration for laughter is far more
extended with 0.7 seconds. This stark difference is arguably due not only to the serial
extensibility of the number of laughter pulses (he, hu, etc.) but also to the fact that
laughter, as a non-verbal vocalization, is ‘‘not turn organized’’ (Lerner 1996: 259) and
will therefore not be construed as an attempt to take the floor even if extended.
The fourth question is intimately related to the third: how long are the overlapping
backchannels relative to the length of the turn to which the backchannel is a response?
This is best answered by calculating the proportions of overlap durations. As can be
seen from the histogram in Fig. 3, by far the overwhelming majority of overlaps
occupy less than 20% of the turn to which they respond. The median proportion is
0.122 (12%) and the mean proportion is 0.185 (19%). Considering the brevity of
overlaps discussed above, the low proportions will not be surprising.
The next question addressed also concerns proportions of overlap but casts the net
wider focusing on the amount of running speech occupied by backchannel overlap, not
only in the ovelapped turn, but in storytelling. This is an intriguing question but
answering it is anything but straightforward. A successful attempt to address the
question conclusively would require the availability of not only a representative corpus
of storytellings (a condition arguably satisfied in the case of the NC) but also of
exhaustive measurements of all turns as well as all backchannel responses in and out of
overlap in that corpus. What we do have are exhaustive measurements of backchannel
overlaps and measurements of the turns to which they respond. Measuring the
durations of non-overlapped turns was far beyond the resources available for this case
Fig. 2 Left panel scatterplot of overlap durations; right panel stripchart of overlap durations withhighlighting of the durations of the top six most frequent backchannels in overlap
220 C. Ruhlemann
123

study. However, the measurements available allow us to predict the durations of non-
overlapped turns. As noted in Section ‘‘Data and Methods’’, we also extracted the
number of words in each storyteller turn in the sample. It seems reasonable to assume
that a turn’s verbosity is correlated with the turn’s duration: a one or two-word turn can
be expected to take up less time than a 10- or 20-word turn. This assumption can be
tested based on the turns for which data for both variables (turn verbosity, turn
duration) are available. Indeed, according to a Kendall’s rank correlation test, there
exists a very strong correlation (tau = 0.819023) which is very highly significant
(p\2.2e-16): the more words in a turn, the longer the turn (and the inverse).
The relationship between turn verbosity as the independent (explanatory) variable and
turn duration as the dependent (outcome) variable can be modeled in a linear regression
model, shown in Fig. 4: the data points cluster very closely around the regression line.
Therefore, not surprisingly, the adjusted R-squared value of more than 0.9 is very close
to its maximum value 1, underscoring, again, that the correlation is very powerful.
Based on the actual observations the linear model also computes a ‘slope’
representing the factor by which the duration of a turn increases or decreases depending
on the number of words in it. The slope is key for predicting the durations of turns for
which no durational information is available: the value can be extracted and the number
of words in a turn without observed duration can be multiplied with it. The resulting
product is the turn’s predicted duration. Proceeding in this way, the predicted durations
for all turns without observed duration were calculated. Based on both observed
durations (for turns that were overlapped by backchannels) and predicted durations (for
turns not overlapped by backchannels) the proportion of speech in overlap out of all
running speech in storytelling could be estimated.
Fig. 3 Histogram with density curve for overlap proportions
Integrating Corpus-Linguistic and Conversation-Analytic… 221
123

The estimate obtained was for overlap to occupy 3.2% of all speech in
storytelling interaction. This proportion is in stark contrast with reported propor-
tions. Following Sacks et al. (1974) observation that ‘‘overwhelmingly, one party
speaks at a time’’ (Sacks et al. 1974: 700), an early overall estimate by Levinson
(1983) predicted that ‘‘less (and often considerably less) than 5 per cent of the
speech stream is delivered in overlap’’. While Levinson (1983) did not provide
statistical evidence to back up the estimate, Levinson and Torreira (2015) did
provide this evidence drawn from large corpora of conversation, finding that overlap
occupies ‘‘less than 5% of the speech stream’’ (Levinson and Torreira 2015: 4).2 In
Norwine and Murphy’s (1938) early study on overlap in telephone dialogs, overlap
accounted for 8% of running speech in telephone conversations!3
So, clearly, our model predicts that the total amount of overlap will be smaller in
storytelling than in conversation generally and much smaller than in telephone
conversation. Can we make linguistic sense of this difference?
Fig. 4 Linear regression model for turn duration as a function of turn verbosity
2 In Levinson and Torreira (2015) the percentage of 5% refers to overlap in turns including all silent
parts, i.e., inter- and intra-speaker pauses; when silent parts are excluded, the percentage is 3.8%. This
proportion is clearly closer to the 3.2% obtained from the model. However, the model’s most critical
coefficient, the slope, is calculated on the basis of turn lengths including silent parts. So the percentage of
3.2% is best juxtaposed to the percentage of 5%.3 The proportion of 8% is not stated explicitly but can be read off the cumulative distribution
(summation) of response times shorter than 0 ms (overlaps) on the right hand scale (scale b) of Fig. 5 on
page 289 of Norwine & Murphy’s study; I’m indebted to Mattias Heldner (personal email
communication) for this pointer.
222 C. Ruhlemann
123

It appears that the difference may be plausibly explained with the greater turn
length typical of storytelling. Turns in storytelling have frequently been observed to
outsize turns in general conversation. Indeed, as Ochs and Capps put it, ‘‘[e]xtended
turn length by a principal teller is a distinguishing feature of personal narratives’’
(Ochs and Capps 2001: 37; see also Ruhlemann 2013: Chapter 3).4 However,
extended turn length alone would not help explain the low percentage of overlap in
storytelling if overlap length were correlated with turn length, i.e., if overlaps
became longer as the turn gets longer, and became shorter as the turn gets shorter.
According to a Kendall’s correlation test, there is a highly significant correlation (p
\0.001); however, the coefficient of 0.1735229 obtained from the test suggests that
the correlation is very weak. Overlap durations and turn durations can, thus, be
considered rather unrelated, as illustrated by the dotchart in Fig. 5.
The observed turn lengths in the dotchart in Fig. 5 are sorted in descending order
with the respective overlap duration plotted over them. For example, the longest
turn in the sample, with a duration of 68.32 seconds, is depicted in the uppermost
grey line; the respective backchannel-incurred overlap is just 1.45 seconds long. It
can be seen that, while turns can occasionally be just slightly longer than the
overlapped backchannel (see the lower third of the dotchart), more frequently they
will outsize overlap considerably (see the upper two thirds of the chart). What is
more, as turns grow in length the overlaps do not noticeably grow with them. This
Fig. 5 Dotchart comparing observed durations of turns (grey) and observed durations of overlap (blue).(Color figure online)
4 Another contributing factor to greater turn length in storytelling is the significantly greater number of
storyteller pauses within storytelling turns (cf. Ruhlemann 2013).
Integrating Corpus-Linguistic and Conversation-Analytic… 223
123

relative asynchrony, clearly visible to the naked eye in the dotchart, is also clearly
indicated by a statistical measure, the standard deviation, ‘‘a measure of how closely
the data cluster around the mean’’ (Woods et al. 1986: 41): the sd for turn length
(8.03) is almost 19 times the sd for overlap length (0.43). Thus, the influence of
extended turn length on overlap length can be considered negligible. On the whole,
overlaps remain brief whatever the turn’s size. Because turn length and overlap length
are, then, out of ‘sync’, it is plausible to assume that it is the greater length of story
turns that drives up the proportion of speech ‘in the clear’ and reduces the proportion
of overlapped speech in storytelling compared to general conversation and telephone
conversation. Consider (7) for illustration: Susan, a grown-up woman, is telling how
her mother, visiting her in her house, behaved as if Susan was still a little child:
(7) ["Mothers", BNC: KBG 303-334]
Susan: 13 °°Yeah°° Cos mum made me laugh tonight (.) 14 cos she came in and (.) 15 she said oh you 16 can have a hot cross bun the:re, I said well (.) 17 I think I'll have a piece of chocolate cake 18 and she said (1.0) alright 19 I said, oh I'm gla(h)d you approve
20 being as though it's mi:ne and it's m(h)y21 house, I c(h)an ea(h)t what I wa(hhh)nt 22 A(h)nd she'd just totally forgotten
23 [ .hh uhm uh::: ]=Carl: 24 [Mm, comfortably so]Susan: 25 =it was really quite funny .hh
Susan’s first turn is quite extended, containing 71 words as well as four pauses (of
which three are below 0.25 seconds and one is one second long). The storytelling as
a whole is 20.34 seconds long, the overlap occurring in lines 23 and 24 between
Susan’s part inhalation .hh, part vocalized hesitation uhm uh::: and Carl’s
assessment Mm, comfortably so occupies 0.61 seconds, accounting for only 3.0%
of the total speech stream in the story.
Extended turn size may, then, cause a significantly lower overlap proportion in
storytelling compared to conversation generally and telephone conversation
specifically. However, two caveats need to be borne in mind. First, backchannels
are not the only loci where overlap occurs (cf. Section ‘‘Introduction’’). The present
analysis was based exclusively on overlap incurred by backchannels. Obviously,
alternative types of overlap will have to be ‘counted in’ in more comprehensive
analyses. Also, the present analysis is based not only on observed durations but also
to a large extent on predicted durations derived from a linear model. The proportion
of 3.2% discovered here thus represents an estimate. The estimate’s accuracy, or
lack thereof, needs yet to be ascertained in future research.
Concluding Remarks
The excerpts and analyses discussed above demonstrate the research opportunity
offered by the availability of the audio files of the BNC. The audio files open up
avenues for research that have thus far been blocked.
First, while many corpora with merely orthographic transcription have been
advertized as presenting ‘real speech’ by ‘real speakers’, the BNC’s audio files put
real voices to these speakers. The hearability is a game changer. Rather than relying
224 C. Ruhlemann
123

on (faulty) orthographic transcripts ‘deaf’ to meaningful nuances of actual delivery,
we, as analysts, are permitted access to the richness of phonology in interaction.
Second, the amount of speech available for acoustic analysis is impressive. Albert
(private email communication) estimates that the audio files for the conversational (i.e.,
the ‘demographically-sampled’) subcorpus of the BNC record ‘‘about 164 hours of
audio’’ produced by more than 600 distinct speakers that are likely to ‘represent’ the
population of British speakers because the samples were drawn representatively
Ruhlemann from a very wide-ranging socio-demographic spread (Crowdy 1995: 225).
The sample size and its representativeness Ruhlemann are crucial for quantification,
especially for statistical inference. For statistical tests assume samples that are sizable
and random or at least representative Ruhlemann. By contrast, as Robinson notes, ‘‘[a]s
is the case with much social-scientific research utilizing college-student populations,
most CA data are nonrandom, convenience samples. In such cases, statistical results are
crude rules of thumb’’ (Robinson 2007: 72). The audio data available via BNCweb
allows quantification to get beyond crude rules of thumb enabling reliable statistical
testing and hence generalization: regularities, or practices of social action, found for the
sample can confidently be generalized to the larger population (e.g., of storytelling).
Third, corpus-linguistic transcripts and conversation-analytic transcripts can be
merged and integrated into an XML architecture. The integration into XML pays
dividends on three counts. Firstly, XML is by now the encoding standard for
computerized text world-wide. Working on XML-formatted CA transcripts will, then,
greatly enhance their exportability, storability, and sharability. Secondly, XML
documents are networks in which all nodes are connected in one way or another. This
omni-connectedness is key in that any node or set of nodes in the document can be
addressed and extracted using appropriate XML query tools such as XPath and
XQuery. For CA transcription, XML formatting is a game changer: while CA
researchers have been used to searching their data manually, with all the limitations to
size and extractability of data, XML transcripts allow for efficient automatic retrieval,
extraction, and analysis of very complex and very large data sets. Thus, XML will
also facilitate what has so far been beyond the reach of orthodox CA research:
examining data with a view to large-scale quantification and eventual statistical
evaluation. The third reason why the transposition into XML is worth the effort is the
unique integration of two distinct approaches to conversational data—the corpus-
linguistic one embodied in the exhaustive annotation for word class through PoS
tagging and the conversation-analytic one embodied in the careful attention to situated
interactional detail. While a number of CA transcription tools such as ELAN
(Wittenburg et al. 2006), EXMARaLDA (Schmidt and Worner 2014), and FOLKER
(Schmidt and Schutte 2014) do have an XML component, none of them have to date
any PoS tagging functionality. In other words, an integrated corpus-linguistic and
conversation-analytic transcription in XML format allows high-efficiency access to
conversational data both on the (lower) lexical to grammatical levels as well as the
(higher) discourse and pragmatic levels of interaction—a potentially fruitful marriage
in the spirit of the recent rapprochement of CL and CA witnessed in the burgeoning
field of corpus pragmatics (cf., for example, Aijmer and Ruhlemann 2015).
Where to from here? There are intriguing research projects under way that aim to
integrate CL and CA in XML. First, Albert et al. (2015) created CABNC, a corpus
Integrating Corpus-Linguistic and Conversation-Analytic… 225
123

based on the demographically-sampled (conversational) BNC audio files in XML.
While not yet transcribed in CA style, as aimed for, what the corpus does offer already
is additional information in the form of exact durations for both\s[ (sentence-like)
units and\w[ (word) elements. Since durational aspects are critical in interactional
terms and hence central in CA, for example in the study of latching, overlap, or tempo
of delivery, this added data may prove invaluable for future research.
Second, a major step towards integrating CL and CA transcription has been taken
through the recent development at Birmingham City University of XTranscript, an
online tool that converts CA transcripts into XML; it is available at: http://rdues.
bcu.ac.uk/cgi-bin/xtranscript/index.cgi. XTranscript may be immensely useful for
CA researchers, who typically store considerable amounts of CA transcripts in
formats such as MS Word. XTranscript offers an elegant and efficient shortcut from
that (non-machine-readable) format to XML. In its current form, XTranscript works
with the tagging scheme detailed in the ‘‘Appendix’’. The scheme is closely aligned
with Jeffersonian trancription conventions and only little post-editing is necessary to
obtain from a CA transcript rich in interactional detail a fully functional XML
version. Finally, XTranscript offers the additional option to automatically PoS-tag
the transcripts in the XML output (based on the Stanford tagger) thus facilitating
fully integrated CL and CA transcription in XML.
Finally, work is underway to update the Narrative Corpus (NC; Ruhlemann and
O’Donnell 2012) based on the BNC audio files. As noted, the NC is a corpus of
storytellings and their surrounding conversational contexts extracted from the
British National Corpus (BNC). The updated NC, which will be re-named
Storytelling Interaction Corpus (SITCO), will thus integrate three levels of
observation: the corpus-linguistic level with its systematic analysis of morpho-
syntactic function (PoS) of every single lexical item in the corpus, the discourse-
analytic level with detailed attention paid to discourse type, discourse structure,
discourse presentation and discourse roles, and the conversation-analytic level with
its focus on interactionally significant details of delivery of talk and other conduct. It
is hoped that the integration of the three distinct levels of observation will make the
updated NC, or SITCO, unique: such an integration has not been attempted so far
and will potentially help advance the study of storytelling interaction.
To conclude, integrating CL and CA in XML has significant potential. It may
provide CL with the long-sought level of interactionally relevant detail that is
necessary to examine talk, not as an empoverished variant of writing, but as talk in
its full interactional richness and complexity. By facilitating serious quantitative
examination, the integration of CL and CA in XML may not only advance the
methodological scope of CA but also widen CA’s appeal to related areas of
research. As Stivers notes, the combination ‘‘with quantitative methods enables CA
research to play a role in a wider range of research questions and to speak to a
broader audience than would otherwise be possible’’ (Stivers 2015: 2).
Appendix
See Table 3.
226 C. Ruhlemann
123

Table
3XTranscripttaggingschem
e
Category
XML
elem
ent
Sub-
category
XMLattributes&
attribute
values
CA
symbol
Description
Sequential
aspects
\sequence[
overlap:
\sequence
type=
"overlap"[
[]
overlapped/overlappingspeech
\sequence
n=
""[
idnumber
ofoverlap
\sequence
part=
"1/2/…
"[positionoftheoverlapin
asequence
of
overlaps
\sequence
from
=""orto
=""[
overlapin
mid-w
ord
latching:
\sequence
type=
"latching"[
5oneturn
latched
onto
nextturn
with
less-than-usual
ornogap
atall
\sequence
position=
"start"or"end"or"w
ithin"[
thepositionwithin
theturn
ofthelatch
Tem
poral
aspects
\timing[
pauses:
\timingtype=
"pause"duration=
""[
(.)or(1.2)
shortorlonger
pause
speed-up:
\timingspeed=
"faster"
degree=
"much"or"m
ore"
or"m
ost"[
>a<
increase
inspeed
slow-down:
\timingspeed=
"slower"degree=
"much"or"m
ore"
or"m
ost"[
<a>
decreasein
speed
Phonological
aspects
\voice[
intonation:
\voiceintonation=
"rise"[
?question(-like)
rise
\voiceintonation=
"halfrise"[
>or?,
rise
stronger
than
acommabutweaker
than
aquestionmark
\voiceintonation=
"weakrise"[
>weakly
risingintonation
\voiceintonation=
"fall"[
.fallingintonation
\voiceintonation=
"continued"[
,continued
intonation
\voiceintonation=
"level"[
_level
intonation
\voiceintonation=
"anim
ated"[
!anim
ated
tone,
notnecessarily
an
exclam
ation
Integrating Corpus-Linguistic and Conversation-Analytic… 227
123

Table
3continued
Category
XML
elem
ent
Sub-
category
XMLattributes&
attribute
values
CA
symbol
Description
pitch change:
\voicepitch
="up"[
:or^
sharprise
inpitch
\voicepitch
="updown"[
:;
sharprisefallin
pitch
\voicepitch
="down"[
;or|
sharpfallin
pitch
volume:
\voicevolume=
"high"[
Aorbold
form
atting
loudvoice
\voicevolume=
"low"degree=
"much"or
degree=
"more"ordegree=
"most"[
�asoftvoice;
threedegrees
stretching:
\voicestretch=
""degree=
"much"or
degree=
"more"ordegree=
"most"word
=""[
a::
lengthened
sound;threedegrees;
stretched
letter
andword
infull
stress:
\voicestress
=""degree=
"much"or"m
ore"or
"most"[
aoraorA
orbold
form
atting
stressed
orheavilystressed
orvery
heavilystressed
sound
realization:
\voicerealization=
""[
deviantrealizationofword
truncation:
\voicetruncation=
""[
-cut-offin
mid-w
ord
aspiration:
\voiceaspiration=
"inhale"
oraspiration=
"exhale"[
.horh.
inhalationorexhalation
\voiceform
="h"or"hh"or"hhh"[
hh
extentofaspiration
smilevoice:
\voicequality=
"smile"[
£talk
producedwhilesm
iling
creaky
voice:
\voicequality=
"creaky"[
*or#
wordspronouncedwithacreak
trem
ulous
voice:
\voicequality=
"tremulous"[
~trem
ulousspeech
Laughter
\laugh[
within-
speech:
\laughtype=
"within-speech"form
=""[
a(h)a
laughingwithin
words
\laughvolume=
"high"orvolume=
"low"[
(H)or(h)
loudorsoftwithin-speech
laughter
228 C. Ruhlemann
123

Table
3continued
Category
XML
elem
ent
Sub-
category
XMLattributes&
attribute
values
CA
symbol
Description
between-
speech:
\laughtype=
"between-speech"form
=""[
h,ha,hah,heh,
hih,hohorhuh
laughingbetweenwords
\laughvolume=
"high"orvolume=
"low"[
Horh
loudorsoftbetween-speech
laughter
Comments
\comment[
onhearing:
\commenthearing=
"unclear"[
()
unclearhearing
\commenthearing=
"possible"[
(a)
possible
hearing
\commenthearing=
"alternative"
alternative=
""[
(a/b)
alternativehearings;specified
in
‘alternative’
attribute
onevent:
\commentevent=
""[
(())
extra-linguisticevent
onanything
else:
\commentother
=""[
other
types
ofcomment
Gaze
\gaze[
direction:
\gazeto
=""duration=
""[
Xinitial1.3
gazed-atparticipant;andduration
\gazeto
="down"duration=
""[
X;1.3
downwardgaze;
duration
\gazeto
="up"duration=
""[
X:1.3
upwardgaze;
duration
\gazeto
="side"
duration=
""[
X/
1.3
orX?
1.3
sidew
aysgazeaw
ayfrom
participant(s);
duration
\gazeto
="shift"
duration=""[
X1.3
shiftinggaze;
duration
Gesture
\gesture[
hand
gesture:
\gesture
type="hand"description=""duration=""[
descriptionanddurationofhandgesture
facial
expression:
\gesture
type="face"
description=""duration=""[
descriptionanddurationoffacial
expression
Integrating Corpus-Linguistic and Conversation-Analytic… 229
123

References
Aijmer, K., & Ruhlemann, C. (Eds.). (2015). Corpus pragmatics. A handbook. Cambridge: Cambridge
University Press.
Albert, S., de Ruiter, L. E., & de Ruiter, J. P. (2015). CABNC: the Jeffersonian transcription of the
Spoken British National Corpus. https://saulalbert.github.io/CABNC/.
Bolden, G. (2004). The quote and beyond: Defining boundaries of reported speech in conversational
Russian. Journal of Pragmatics, 36, 1071–1118.
Campillos, L. L. (2014). A Spanish learner oral corpus for computer-aided error analysis. Corpora, 9(2),
207–238.
Coleman, J., Baghai-Ravary, L., Pybus, J., & Grau, S. (2012). Audio BNC: The audio edition of the
Spoken British National Corpus. Phonetics Laboratory, University of Oxford. http://www.phon.ox.
ac.uk/AudioBNC
Cresti, E., & Moneglia, M. (Eds.). (2005). C-ORAL-ROM: Integrated reference corpora for spoken
Romance languages. Amsterdam: Benjamins.
Crowdy, S. (1994). Spoken corpus transcription. Literary and Linguistic Computing, 9(1), 25–28.
Crowdy, S. (1995). The BNC spoken corpus. In G. Leech, G. Myers, & J. Thomas (Eds.), Spoken English
on computer: Transcription, mark-up and application (pp. 225–234). London: Longman.
Gardner, R. (1998). Between speaking and listening: The vocalisation of understandings. Applied
Linguistics, 19(2), 204–224.
Goffman, E. (1981). Forms of talk. Philadelphia: Philadelphia University Press.
Goodwin, C. (1984). Notes on story structure and the organization of participation. In J. M. Atkinson & J.
Heritage (Eds.), Structures of social action: Studies in conversation analysis (pp. 225–246).
Cambridge: Cambridge University Press.
Gries, S Th. (2009a). Quantitative corpus linguistics with R. A practical introduction. New York:
Routledge.
Gries, S Th. (2009b). Statistics for linguistics with R. A practical introduction. Berlin: Mouton de
Gruyter.
Hardie, A. (2014). Modest XML for corpora: Not a standard, but a suggestion. ICAME Journal, 38,
73–103.
Heldner, M., & Edlund, J. (2010). Pauses, gaps and overlaps in conversations. Journal of Phonetics, 38,
555–568. doi:10.1016/j.wocn.2010.08.002.
Hepburn, A., & Bolden, G. (2013). The conversation-analytic approach to transcription. In J. Sidnell & T.
Stivers (Eds.), The handbook of conversation analysis (pp. 57–76). Malden, MA: Wiley.
Hoey, M., & O’Donnell, M. B. (2008). Lexicography, grammar, and textual position. International
Journal of Lexicography, 21(3), 293–309.
Hoffmann, S., Evert, S., Smith, N., Lee, D., & Berglund Prytz, Y. (2008). Corpus linguistics with
BNCweb—A practical guide. Frankfurt am Main: Peter Lang.
Holmes, J., & Stubbe, M. (1997). Good listeners: Gender differences in New Zealand conversation.
Women and Language, 20(2), 7–14.
Holt, E. (1996). Reporting talk: The use of direct reported speech in conversation. Research on Language
and Social Interaction, 29(3), 219–245.
Jefferson, G. (1973). A case of precision timing in ordinary conversation: Overlapped tag-positioned
address terms in closing sequences. Semiotics, 9, 47–96.
Jefferson, G. (1979). A technique for inviting laughter and its subsequent acceptance declination. In G.
Psathas (Ed.), Everyday language—Studies in ethnomethodology (pp. 79–95). New York: Irvington
Publishers.
Jefferson, G. (1985). An exercise in the transcription and analysis of laughter. In T. A. van Dijk (Ed.),
Handbook of discourse analysis (Vol. 3, pp. 25–34). London: Academic.
Jefferson, G. (1986). Notes on ‘latency’ in overlap onset. Human Studies, 9, 153–183.
Kallen, J. L., & Kirk, J. (2012). SPICE-Ireland: A user’s guide. Belfast: Clo Ollscoil na Banrıona.
Kjellmer, G. (2009). Where do we backchannel? International Journal of Corpus Linguistics, 14(1),
81–112.
Lerner, G. (1996). On the ‘‘semi-permeable’’ character of grammatical units in conversation: conditional
entry into the turn space of another speaker. In E. Ochs, E. A. Schegloff, & S. A. Thompson (Eds.),
Interaction and grammar (pp. 238–276). Cambridge: Cambridge University Press.
Levinson, S. C. (1983). Pragmatics. Cambridge: Cambridge University Press.
230 C. Ruhlemann
123

Levinson, S. C., & Torreira, F. (2015). Timing in turn-taking and its implications for processing models
of language. Frontiers in Psychology, 6, 731. doi:10.3389/fpsyg.2015.00731.
Liddicott, A. J. (2007). An introduction to conversation analysis. London: Continuum.
Mayes, P. (1990). Quotation in spoken English. Studies in Language, 14, 325–363.
McCarthy, M. (2003). Talking back: ‘Small’ interactional response tokens in everyday conversation.
Research on Language and Social Interaction, 36(1), 33–63.
Nichols, T. E., & Holmes, A. P. (2001). Nonparametric permutation test for functional neuroimaging: A
primer with examples. Human Brain Mapping, 15, 1–25.
Norwine, A. C., & Murphy, O. J. (1938). Characteristic time intervals in telephonic conversation. The
Bell System Technical Journal, 17, 281–291.
O’Keeffe, A., & Adolphs, S. (2008). Response tokens in British and Irish discourse. Corpus, context and
variational pragmatics. In K. P. Schneider & A. Barron (Eds.), Variational pragmatics (pp. 69–98).
Amsterdam: John Benjamins.
Ochs, E., & Capps, L. (2001). Living narrative. Cambridge, MA: Harvard University Press.
Peters, P., & Wong, D. (2015). Turn management and backchannels. In K. Aijmer & C. Ruhlemann
(Eds.), Corpus pragmatics. A handbook (pp. 408–429). Cambridge: Cambridge University Press.
Robinson, J. D. (2007). The role of numbers and statistics within conversation analysis. Communication
Methods and Measures, 1(1), 65–75.
Rossano, F. (2013). Gaze in conversation. In T. Stivers & J. Sidnell (Eds.), The handbook of conversation
analysis (pp. 308–329). Malden/MA & Oxford: Blackwell.
Ruhlemann, C. (2013). Narrative in English conversation: A corpus analysis. Cambridge: Cambridge
University Press.
Ruhlemann, C., Bagoutdinov, A., & O’Donnell, M. B. (2015). Modest XPath and XQuery for corpora:
Exploiting deep XML annotation. ICAME Journal, 39, 47–84.
Ruhlemann, C., & Gries, S. T. (2015). Turn order and turn distribution in multi-party storytelling. Journal
of Pragmatics, 87, 171–191.
Ruhlemann, C., & O’Donnell, M. B. (2012). Towards a corpus of conversational narrative. Construction
and annotation of the Narrative Corpus. Corpus Linguistics and Linguistic Theory, 8(2), 313–350.
Sacks, H. (1984). Notes on methodology. In J. M. Atkinson & J. Heritage (Eds.), Structures of social
action (pp. 21–27). Cambridge: Cambridge University Press.
Sacks, H. (1992). Lectures on conversation. (Vols. I and II). Oxford: Blackwell.
Sacks, H., Schegloff, E. A., & Jefferson, G. (1974). A simplest systematics for the organisation of turn-
taking for conversation’. Language, 50(4), 696–735.
Schegloff, E. A. (1982). Discourse as an interactional achievement: Some uses of ‘uh huh’ and other
things that come between sentences. In D. Tannen (Ed.), Georgetown University round table on
languages and linguistics analyzing discourse: Text and talk (pp. 71–93). Washington, DC:
Georgetown University Press.
Schegloff, E. A. (2000). Overlapping talk and the organization of turn-taking for conversation. Language
in Society, 29, 1–63.
Schmidt, T., & Schutte, W. (2014). FOLKER: An annotation tool for efficient transcription of natural,
multi-party interaction. http://www.lrec-conf.org/proceedings/lrec2010/pdf/18_Paper.pdf.
Schmidt, Thomas, & Worner, Kai. (2014). EXMARaLDA. In Jacques Durand, Ulrike Gut, & Gjert
Kristoffersen (Eds.), The Oxford handbook of corpus phonology (pp. 402–419). Oxford: Oxford
University Press.
Stivers, T. (2008). Stance, alignment, and affiliation during storytelling: When nodding is a token of
affiliation. Research on Language and Social Interaction, 41(1), 31–57.
Stivers, T. (2013). Sequence organization. In J. Sidnell & T. Stivers (Eds.), The handbook of conversation
analysis (pp. 191–209). Malden, MA: Wiley.
Stivers, T. (2015). Coding social interaction: A heretical approach in conversation analysis? Research on
Language and Social Interaction, 48(1), 1–19.
Stivers, T., & Sidnell, J. (2013). Introduction. In J. Sidnell & T. Stivers (Eds.), The handbook of
conversation analysis (pp. 1–8). Malden, MA: Wiley.
ten Bosch, L., Oostdijk, N., & Boves, L. (2005). On temporal aspects of turn taking in conversational
dialogues. Speech Communication, 47, 80–86.
Tolins, J., & Fox Tree, J. E. (2014). Addressee backchannels steer narrative development. Journal of
Pragmatics, 70, 152–164.
Walker, M. A. (1993). Informational redundancy and resource bounds in dialogue (Ph.D. thesis).
University of Pennsylvania, Philadelphia, PA.
Integrating Corpus-Linguistic and Conversation-Analytic… 231
123

Walmsley, P. (2007). XQuery. Sebastopol, CA: O’Reilly.
Watt, A. (2002). XPath essentials. New York: Wiley.
Wittenburg, P., Brugman, H., Russel, A., Klassmann, A., & Sloetjes, H. (2006). ELAN: A professional
framework for multimodality research. In: Proceedings of LREC 2006, Fifth international
conference on language resources and evaluation.
Wong, D., & Peters, P. (2007). A study of backchannels in regional varieties of English, using corpus
mark-up as the means of identification. International Journal of Corpus Linguistics, 12(4), 479–509.
Woods, A., Fletcher, P., & Hughes, A. (1986). Statistics in language studies. Cambridge: Cambridge
University Press.
Yngve, V. (1970). On getting a word in edgewise. In: Papers from the sixth regional meeting of the
Chicago Linguistic Society. University of Chicago, pp. 567–77.
232 C. Ruhlemann
123