innovation at aws · pdf fileinnovation at aws eric ferreira ... hadoop 2.7.3, hive 2.1, spark...
TRANSCRIPT


The Amazon Flywheel
Focus on things that stay the same
Price
Selection
Delivery

Applying this at AWS

Amazon Redshift
Focus on things that stay the same
Performance
Value
Simplicity

Adopt a retail mindset

Customers have choice Delight them and they’ll stay
Earn their business one hour at a time

Start with the CustomerWork Backwards

What Do Customers Want?
• What problems are customers facing?
• How will my service alleviate this pain?
• Why will this idea delight customers?
• Why can I do this better than anyone else?

What we heard from customers about DW
• Complicated to install, maintain, operate
• Require large upfront payments
• Too expensive
• Always running out of capacity

Press Release
Describe the product in terms of customer value
Why will customers care?
Is it newsworthy?
How is this differentiated?

FAQAnswer customer questions
How does this help me?
How do I get started?
How will this work with my ETL/BI tools?
When should I use this vs. Hadoop?

2 pizza teams• An individual team should be no larger than can be fed
by two pizzas.
• Beyond this size, you define contracts and interfaces with other teams
• Attention is a scarce resource. Time is a scarce resource
• Apply attention and time to changing reality, not communicating status.
Assemble a Team Build Internal
BetaPrivate Beta Launch Iterate
Build the Product

Iterate
Add Features that matter
Raise ValueIncrease Adoption
Get Feedback

Redshift pushes a new DB version every two weeks. 120+ features since launch
Service Launch (2/14)
PDX (4/2)
Temp Credentials (4/11)
Unload Encrypted Files
DUB (4/25)
NRT (6/5)
JDBC Fetch Size (6/27)
Unload logs (7/5)
4 byte UTF-8 (7/18)
Statement Timeout (7/22)
SHA1 Builtin (7/15)
Timezone, Epoch, Autoformat (7/25)
WLM Timeout/Wildcards (8/1)
CRC32 Builtin, CSV, Restore Progress (8/9)
UTF-8 Substitution (8/29)
JSON, Regex, Cursors (9/10)
Split_part, Audit tables (10/3)
SIN/SYD (10/8)
HSM Support (11/11)
Kinesis EMR/HDFS/SSH copy, Distributed Tables, Audit
Logging/CloudTrail, Concurrency, Resize Perf., Approximate Count Distinct, SNS
Alerts, Cross Region Backup (11/13)
SOC1/2/3 (5/8)
Sharing snapshots (7/18)
Resource Level IAM (8/9)
PCI (8/22) Distributed Tables, Single Node Cursor Support, Maximum Connections to 500
(12/13)
EIP Support for VPC Clusters (12/28)
New query monitoring system tables and diststyle all (1/13)
Redshift on DW2 (SSD) Nodes (1/23)
Compression for COPY from SSH, Fetch size support for single node clusters, new system tables with commit stats,
row_number(), strotol() and query termination (2/13)
Resize progress indicator & Cluster Version (3/21)
Regex_Substr, COPY from JSON (3/25)
50 slots, COPY from EMR, ECDHE ciphers (4/22)
3 new regex features, Unload to single file, FedRAMP(5/6)
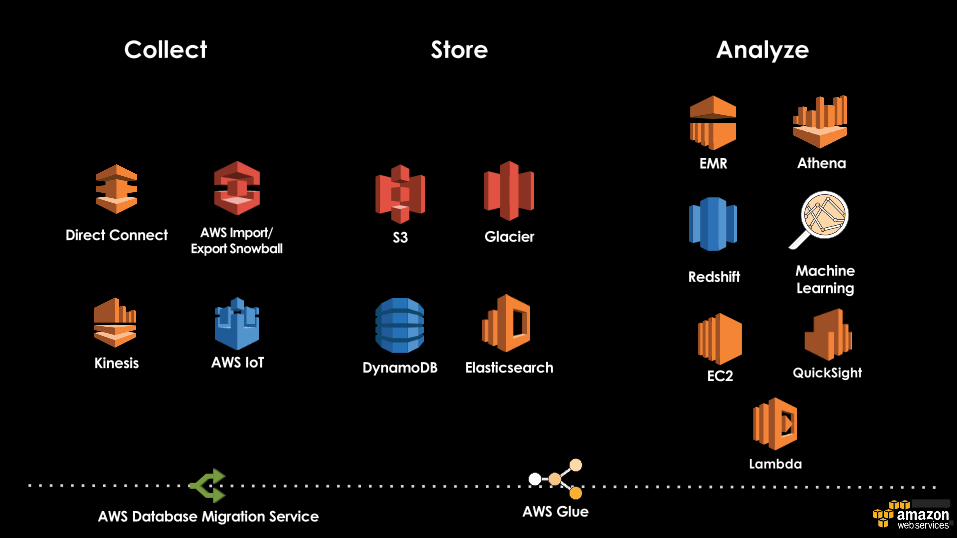
AWS Database Migration Service
EMR
Analyze
GlacierS3
StoreCollect
Kinesis
Direct Connect
Machine Learning
Redshift
DynamoDB AWS IoT
AWS Import/Export Snowball
QuickSight
Athena
EC2Elasticsearch
Lambda
AWS Glue

Collection & Storage• Store anything
• Object storage
• Designed for 99.999999999% durability
• Scalable & Cost effective; $0.023/GB-Mo
• Integrated with Amazon Glacier
• Support for multiple encryption methods; integrated with AWS KMS, with support for external HSMs
Amazon S3

Data Management & ETL
• Hive Metastore-compatible data catalog with integrated crawlers for schema, data type, and partition inference
• Generates Python code to move data from source to destination
• Edit jobs using your favorite IDE and share snippets via Git
• Runs jobs in Spark containers that auto-scale based on SLA
• Serverless with no infrastructure to manage; pay only for the resources you consume
AWS Glue

Amazon RDS for Aurora• MySQL compatible with up to 5x better performance on the
same hardware: 100,000 writes/sec & 500,000 reads/sec
• Scalable with up to 64 TB in single database, up to 15 read replicas
• Highly available, durable, and fault-tolerant custom SSD storage layer: 6-way replicated across 3 Availability Zones
• Transparent encryption for data at rest using AWS KMS
• Stored procedures in Aurora can invoke AWS Lambda functions
• MySQL & PostgreSQL compatible engines

Structured Data Processing• Petabyte-scale relational, MPP, data warehousing clusters with the
ability to join across Exabytes of data in S3 using Redshift Spectrum, a serverless scale out query layer that charges $5/TB scanned
• Fully managed with SSD and HDD platforms
• Built-in end to end security, including customer-managed keys
• Fault tolerant. Automatically recovers from disk and node failures
• Data automatically backed up to Amazon S3 with cross region backup capability for global disaster recovery
• $1,000/TB/Year; start at $0.25/hour. Provision in minutes; scale from 160GB to 2PB of compressed data with just a few clicks
Amazon Redshift

Semi-structured / Unstructured Data Processing• Hadoop, Hive, Presto, Spark, Tez, Impala etc.
– Release 5.3: Hadoop 2.7.3, Hive 2.1, Spark 2.1, Zeppelin, Presto, HBase 1.2.3 and HBase on S3, Phoenix, Tez, Flink.
– New applications added within 30 days of their open source release
• Fully managed, autoscaling clusters with support for on-demand and spot pricing
• Support for HDFS and S3 filesystems enabling separated compute and storage; multiple clusters can run against the same data in S3
• HIPAA-eligible. Support for end-to-end encryption, IAM/VPC, S3 client-side encryption with customer managed keys and AWS KMS
Amazon EMR

Serverless Query Processing• Serverless query service for querying data in S3 using standard SQL,
with no infrastructure to manage
• No data loading required; query directly from Amazon S3
• Use standard ANSI SQL queries with support for joins, JSON, and window functions
• Support for multiple data formats include text, CSV, TSV, JSON, Avro, ORC, Parquet
• Pay per query only when you’re running queries based on data scanned. If you compress your data, you pay less and your queries run faster
AmazonAthena

Serverless Event Processing• Server-less compute service that runs your code in
response to events
• Extend AWS services with user defined custom logic
• Write custom code in Node.js, Python, and Java
• Pay only for the requests served and compute time required - billing in increments of 100 milliseconds
AWS Lambda

Stream Processing• Real-time stream processing
• High throughput; elastic
• Highly available; data replicated across multiple Availability Zones with configurable retention
• S3, Redshift, DynamoDB Integrations
• Kinesis Streams for custom streaming applications; Kinesis Firehose for easy integration with Amazon S3 and Redshift; Kinesis Analytics for streaming SQL
AmazonKinesis

Search and Operational Analytics• Distributed search and analytics engine
• Managed service using Elasticsearch and Kibana
• Fully managed; Zero admin
• Highly Available and Reliable
• Tightly integrated with other AWS services
AmazonElasticsearch
Service

Predictive Applications• Easy to use, managed service built for developers -
Deploy models to in seconds
• Robust, powerful technology based on Amazon’s internal systems
• Create models using your data already stored in the AWS cloud; deploy models in batch and real time modes
• Spark on Amazon EMR also available for custom machine learning applications
Amazon ML

Business Intelligence• Fast and cloud-powered
• Easy to use, no infrastructure to manage
• Scales to 100s of thousands of users
• Quick calculations with SPICE
• 1/10th the cost of legacy BI software
AmazonQuickSight

Amazon Redshift

Columnar
MPP
OLAP
AWS IAMAmazonVPCAmazonSWF
AmazonS3 AWSKMS AmazonRoute53
AmazonCloudWatch
AmazonEC2
PostgreSQL AmazonRedshift

Redshift Cluster Architecture
• Massively parallel, shared nothing• Leader node
– SQL endpoint– Stores metadata– Coordinates parallel SQL processing
• Compute nodes– Local, columnar storage– Executes queries in parallel– Load, backup, restore
10 GigE(HPC)
IngestionBackupRestore
SQL Clients/BI Tools
128GB RAM
16TB disk
16 cores
S3 / EMR / DynamoDB / SSH
JDBC/ODBC
128GB RAM
16TB disk
16 coresCompute Node
128GB RAM
16TB disk
16 coresCompute Node
128GB RAM
16TB disk
16 coresCompute Node
LeaderNode

Brute force only takes you so far…

Designed for I/O Reduction
• Columnar storage
• Data compression
• Zone mapsaid loc dt1 SFO 2016-09-012 JFK 2016-09-143 SFO 2017-04-014 JFK 2017-05-14
• Accessing dt with row storage:
– Need to read everything– Unnecessary I/O
aid loc dt
CREATE TABLE audience (aid INT --audience_id,loc CHAR(3) --location,dt DATE --date
);

Designed for I/O Reduction
• Columnar storage
• Data compression
• Zone mapsaid loc dt1 SFO 2016-09-012 JFK 2016-09-143 SFO 2017-04-014 JFK 2017-05-14
• Accessing dt with columnar storage:
– Only scan blocks for relevant column
aid loc dt
CREATE TABLE audience (aid INT --audience_id,loc CHAR(3) --location,dt DATE --date
);

Designed for I/O Reduction
• Columnar storage
• Data compression
• Zone mapsaid loc dt1 SFO 2016-09-012 JFK 2016-09-143 SFO 2017-04-014 JFK 2017-05-14
• Columnsgrowandshrinkindependently
• Effectivecompressionratiosduetolikedata
• Reducesstoragerequirements
• ReducesI/O
aid loc dt
CREATE TABLE audience (aid INT ENCODE LZO,loc CHAR(3) ENCODE BYTEDICT,dt DATE ENCODE RUNLENGTH
);

Designed for I/O Reduction
• Columnar storage
• Data compression
• Zone mapsaid loc dt1 SFO 2016-09-012 JFK 2016-09-143 SFO 2017-04-014 JFK 2017-05-14
aid loc dt
CREATE TABLE audience (aid INT --audience_id,loc CHAR(3) --location,dt DATE --date
);
• In-memoryblockmetadata• Containsper-blockMINandMAXvalue• Effectivelyprunesblockswhichcannot
containdataforagivenquery• EliminatesunnecessaryI/O
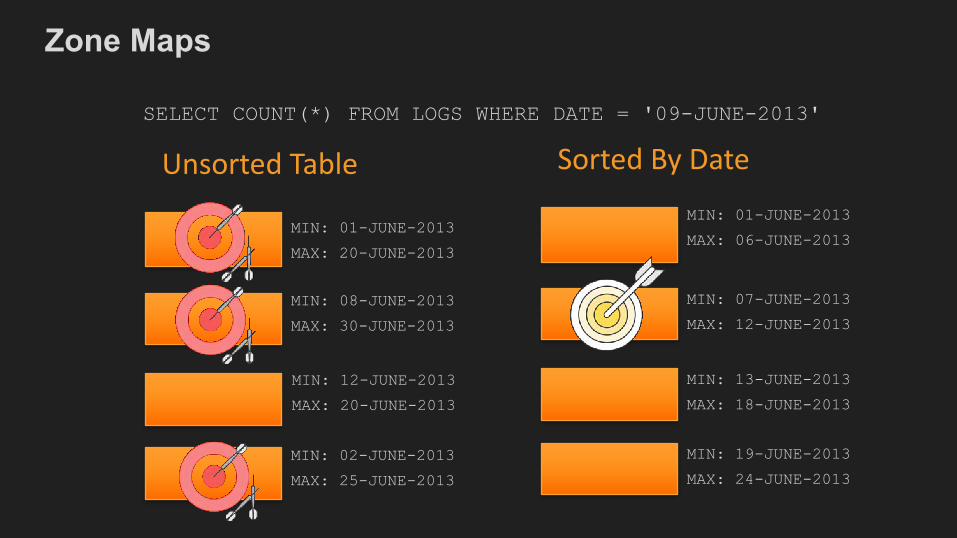
SELECT COUNT(*) FROM LOGS WHERE DATE = '09-JUNE-2013'
MIN: 01-JUNE-2013
MAX: 20-JUNE-2013
MIN: 08-JUNE-2013
MAX: 30-JUNE-2013
MIN: 12-JUNE-2013
MAX: 20-JUNE-2013
MIN: 02-JUNE-2013
MAX: 25-JUNE-2013
UnsortedTableMIN: 01-JUNE-2013
MAX: 06-JUNE-2013
MIN: 07-JUNE-2013
MAX: 12-JUNE-2013
MIN: 13-JUNE-2013
MAX: 18-JUNE-2013
MIN: 19-JUNE-2013
MAX: 24-JUNE-2013
SortedByDate
Zone Maps
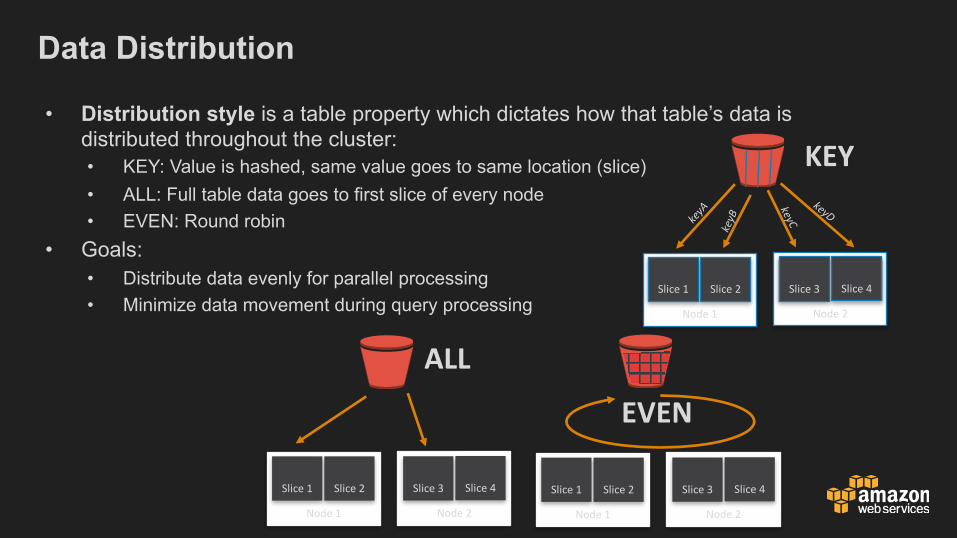
Data Distribution
• Distribution style is a table property which dictates how that table’s data is distributed throughout the cluster:• KEY: Value is hashed, same value goes to same location (slice)• ALL: Full table data goes to first slice of every node• EVEN: Round robin
• Goals:• Distribute data evenly for parallel processing• Minimize data movement during query processing
KEY
ALLNode1
Slice1 Slice2
Node2
Slice3 Slice4
Node1
Slice1 Slice2
Node2
Slice3 Slice4
Node1
Slice1 Slice2
Node2
Slice3 Slice4
EVEN

What is next?
When your data sets become so large and diverse that you have to start innovating around how to collect, store, process, analyze and share them
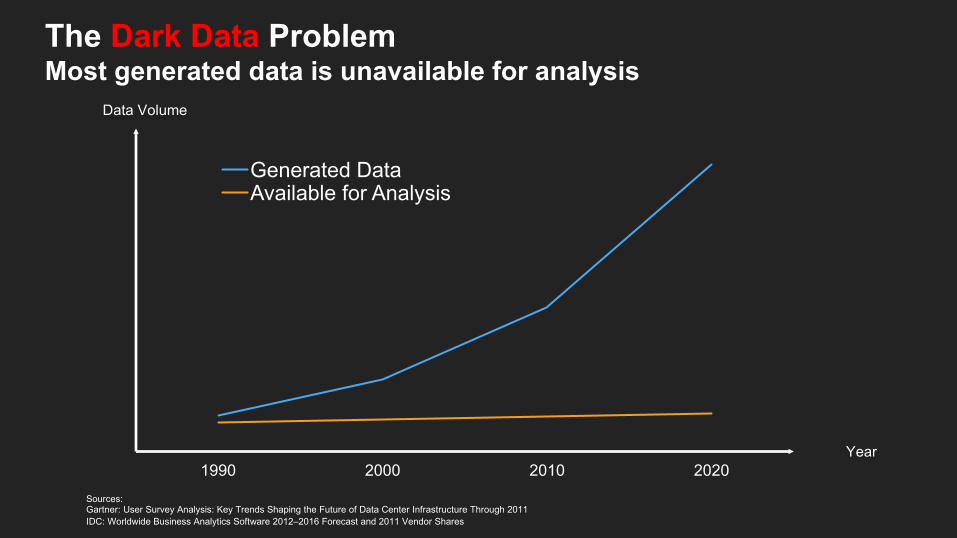
1990 2000 2010 2020
Generated DataAvailable for Analysis
Sources: Gartner: User Survey Analysis: Key Trends Shaping the Future of Data Center Infrastructure Through 2011 IDC: Worldwide Business Analytics Software 2012–2016 Forecast and 2011 Vendor Shares
Data Volume
Year
The Dark Data ProblemMost generated data is unavailable for analysis

The tyranny of “OR”
Amazon EMR
Directly access data in S3
Scale out to thousands of nodes
Open data formats
Popular big data frameworks
Anything you can dream up and code
Amazon Redshift
Super-fast local disk performance
Sophisticated query optimization
Join-optimized data formats
Query using standard SQL
Optimized for data warehousing

Customers wantsophisticated query optimization and scale-out processing
super fast performance and support for open formats
the throughput of local disk and the scale of S3

Amazon Redshift Spectrum

Amazon Redshift SpectrumRun SQL queries directly against data in S3 using thousands of nodes
Fast @ exabyte scale Elastic & highly available On-demand, pay-per-query
High concurrency: Multiple clusters access same data
No ETL: Query data in-place using open file formats
Full Amazon Redshift SQL support
S3 SQL
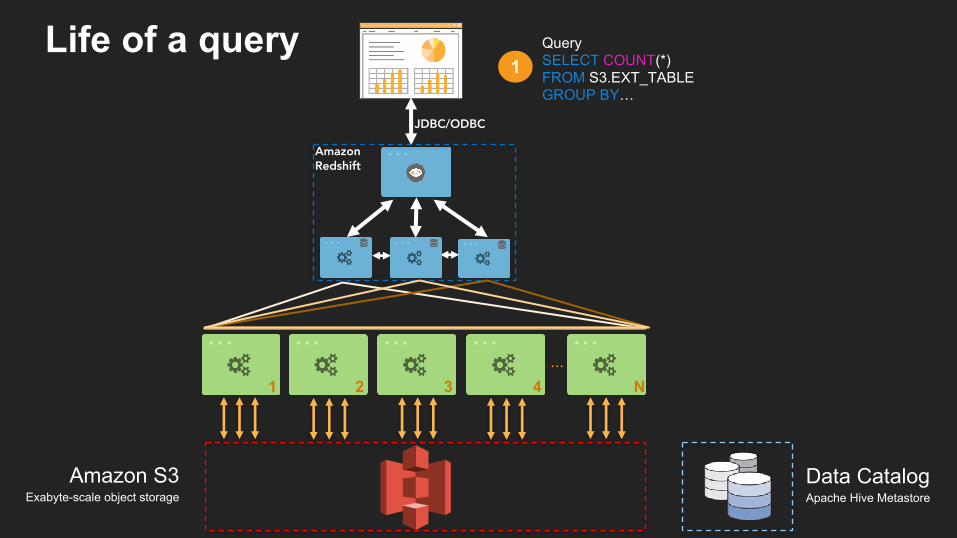
QuerySELECT COUNT(*)FROM S3.EXT_TABLEGROUP BY…
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
1
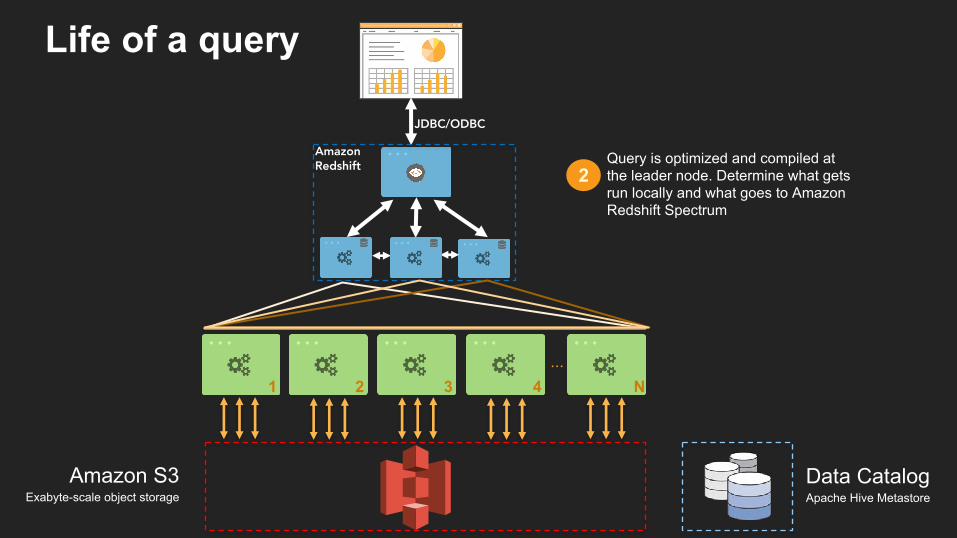
Query is optimized and compiled at the leader node. Determine what gets run locally and what goes to Amazon Redshift Spectrum
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
2
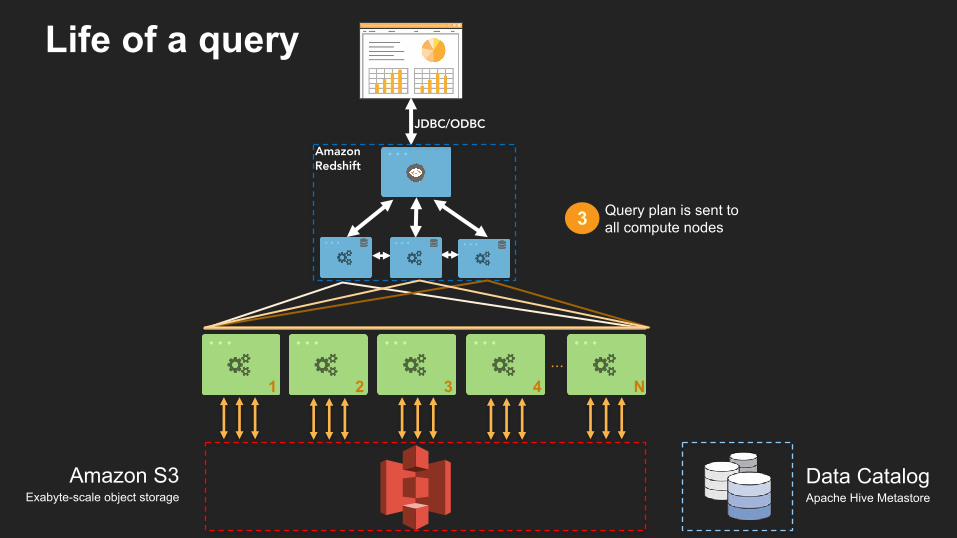
Query plan is sent to all compute nodes
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
3

Compute nodes obtain partition info from Data Catalog; dynamically prune partitions
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
4
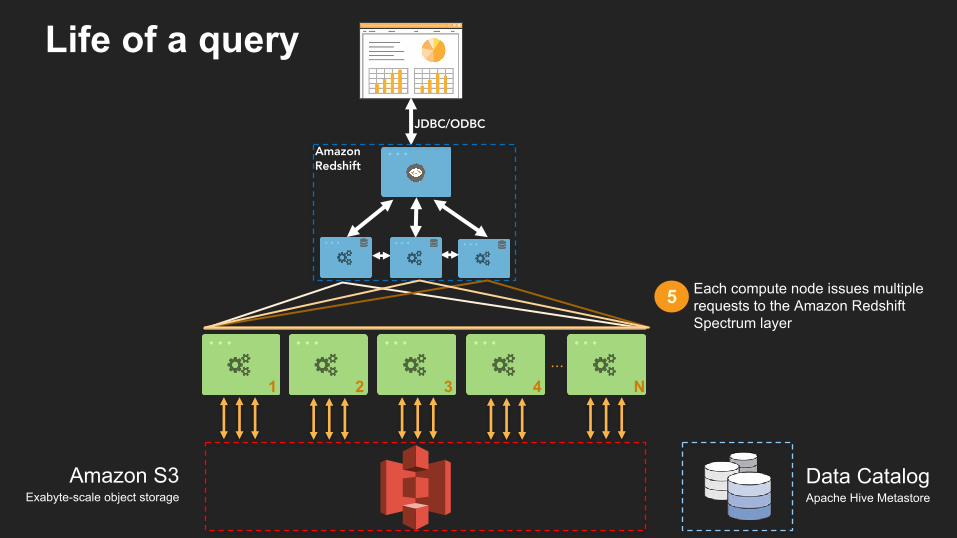
Each compute node issues multiple requests to the Amazon Redshift Spectrum layer
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
5
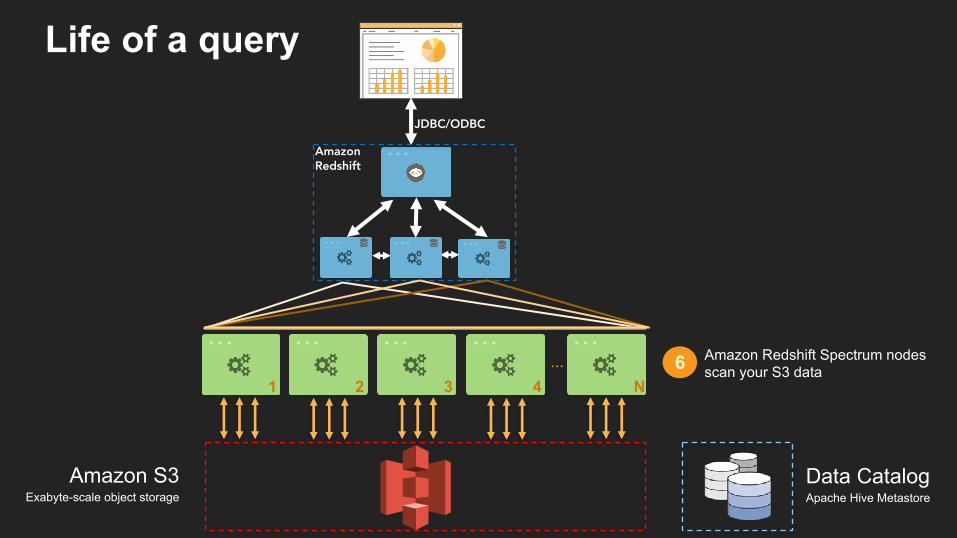
Amazon Redshift Spectrum nodes scan your S3 data
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
6
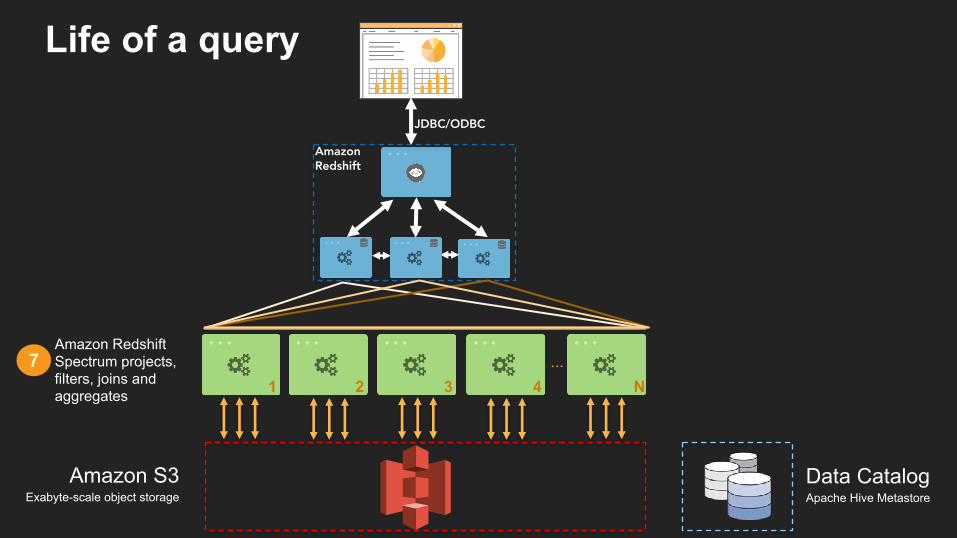
7Amazon Redshift Spectrum projects, filters, joins and aggregates
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
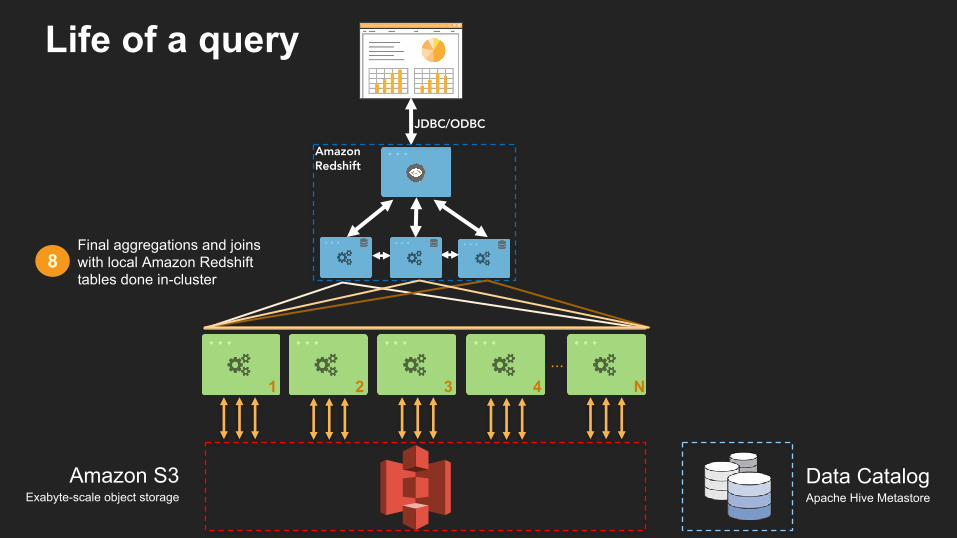
Final aggregations and joins with local Amazon Redshift tables done in-cluster
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
8

Result is sent back to client
Life of a query
Amazon Redshift
JDBC/ODBC
...1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
9

Running an analytic query over an exabyte in S3

Now let’s run a query over an exabyte of data in S3
Roughly 140 TB of customer item order detail records for each day over past 20 years.
190 million files across 15,000 partitions in S3. One partition per day for USA and rest of world.
Need a billion-fold reduction in data processed.
Running this query using a 1000 node Hive cluster would take over 5 years.*
• Compression ……………..….……..5X• Columnar file format……….......…10X
• Scanning with 2500 nodes…....2500X
• Static partition elimination…............2X• Dynamic partition elimination..….350X• Redshift’s query optimizer……......40X
---------------------------------------------------Total reduction……….…………3.5B X
* Estimated using 20 node Hive cluster & 1.4TB, assume linear* Query used a 20 node DC1.8XLarge Amazon Redshift cluster* Not actual sales data - generated for this demo based on data format used by Amazon Retail.

Amazon Redshift Spectrum is fast
Leverages Amazon Redshift’s advanced cost-based optimizer
Pushes down projections, filters, aggregations and join reduction
Dynamic partition pruning to minimize data processed
Automatic parallelization of query execution against S3 data
Efficient join processing within the Amazon Redshift cluster

Amazon Redshift Spectrum is cost-effective
You pay for your Amazon Redshift cluster plus $5 per TB scanned from S3
Each query can leverage 1000s of Amazon Redshift Spectrum nodes
You can reduce the TB scanned and improve query performance by: Partitioning dataUsing a columnar file format Compressing data

Amazon Redshift Spectrum is secure
End-to-end data encryption
Alerts & notifications
Virtual private cloud
Audit logging
Certifications & compliance
Encrypt S3 data using SSE and AWS KMS
Encrypt all Amazon Redshift data using KMS, AWS CloudHSM or your on-premises HSMs
Enforce SSL with perfect forward encryption using ECDHE
Amazon Redshift leader node in your VPC. Compute nodes in private VPC. Spectrum nodes in private VPC, store no state.
Communicate event-specific notifications via email, text message, or call with Amazon SNS
All API calls are logged using AWS CloudTrail
All SQL statements are logged within Amazon Redshift
PCI/DSSFedRAMP
SOC1/2/3 HIPAA/BAA

Amazon Redshift Spectrum uses standard SQL
Redshift Spectrum seamlessly integrates with your existing SQL & BI apps
Support for complex joins, nested queries & window functions
Support for data partitioned in S3 by any key Date, Time and any other custom keyse.g., Year, Month, Day, Hour

Defining External Schema and Creating Tables
DefineanexternalschemainAmazonRedshiftusingtheAmazonAthenadatacatalogoryourownApacheHiveMetastore
CREATEEXTERNALSCHEMA<schema_name>
Queryexternaltablesusing<schema_name>.<table_name>
RegisterexternaltablesusingAthena,yourHiveMetastoreclient,orfromAmazon RedshiftCREATEEXTERNALTABLEsyntax
CREATEEXTERNALTABLE<table_name>[PARTITIONEDBY<column_name,data_type,…>]STOREDASfile_formatLOCATIONs3_location[TABLEPROPERTIESproperty_name=property_value,…];

Amazon Redshift Spectrum – Current support
File formats
• Parquet• CSV• Sequence• RCFile • ORC (coming soon)• RegExSerDe (coming soon)
Compression
• Gzip• Snappy• Lzo (coming soon)• Bz2
Encryption
• SSE with AES256• SSE KMS with default
key
Column types
• Numeric: bigint, int, smallint, float, double and decimal
• Char/varchar/string• Timestamp• Boolean• DATE type can be used only as a
partitioning key
Table type
• Non-partitioned table (s3://mybucket/orders/..)
• Partitioned table (s3://mybucket/orders/date=YYYY-MM-DD/..)
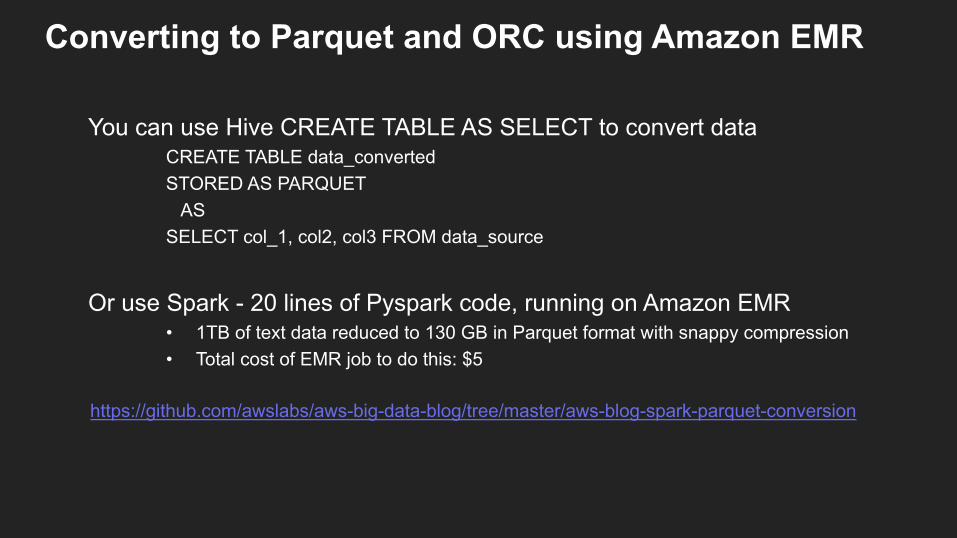
Converting to Parquet and ORC using Amazon EMR
You can use Hive CREATE TABLE AS SELECT to convert dataCREATE TABLE data_convertedSTORED AS PARQUET
ASSELECT col_1, col2, col3 FROM data_source
Or use Spark - 20 lines of Pyspark code, running on Amazon EMR • 1TB of text data reduced to 130 GB in Parquet format with snappy compression• Total cost of EMR job to do this: $5
https://github.com/awslabs/aws-big-data-blog/tree/master/aws-blog-spark-parquet-conversion

Is Amazon Redshift Spectrum useful if I don’t have an exabyte?
Your data will get biggerOn average, data warehousing volumes grow 10x every 5 yearsThe average Amazon Redshift customer doubles data each year
Amazon Redshift Spectrum makes data analysis simplerAccess your data without ETL pipelinesTeams using Amazon EMR, Athena & Redshift can collaborate using the same data lake
Amazon Redshift Spectrum improves availability and concurrencyRun multiple Amazon Redshift clusters against common dataIsolate jobs with tight SLAs from ad hoc analysis

Over 20 customers helped preview Amazon Redshift Spectrum
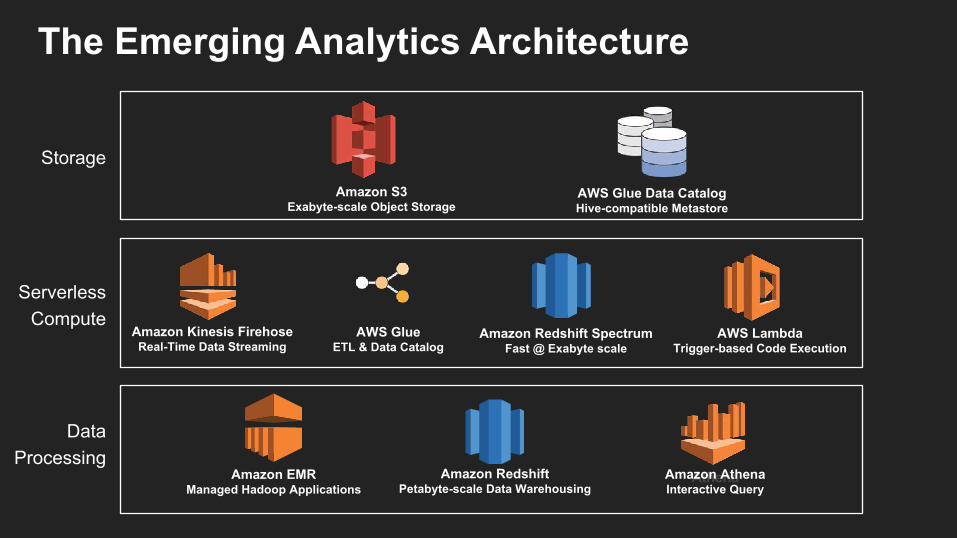
The Emerging Analytics Architecture
AthenaAmazon AthenaInteractive Query
AWS GlueETL & Data Catalog
Storage
Serverless Compute
Data Processing
Amazon S3 Exabyte-scale Object Storage
Amazon Kinesis FirehoseReal-Time Data Streaming
Amazon EMRManaged Hadoop Applications
AWS LambdaTrigger-based Code Execution
AWS Glue Data CatalogHive-compatible Metastore
Amazon Redshift SpectrumFast @ Exabyte scale
Amazon RedshiftPetabyte-scale Data Warehousing

Resources• Amazon Redshift Engineering’s Advanced Table Design Playbook
https://aws.amazon.com/blogs/big-data/amazon-redshift-engineerings-advanced-table-design-playbook-preamble-prerequisites-and-prioritization/
• https://github.com/awslabs/amazon-redshift-utils– Admin scripts
Collection of utilities for running diagnostics on your cluster– Admin views
Collection of utilities for managing your cluster, generating schema DDL, etc.– ColumnEncodingUtility
Gives you the ability to apply optimal column encoding to an established schema with data already loaded
• https://github.com/awslabs/amazon-redshift-monitoring• https://github.com/awslabs/amazon-redshift-udfs

Thank You !