index tuning for adaptive multi-route data stream systems karen works, elke a. rundensteiner, and...
TRANSCRIPT

Index Tuning forAdaptive Multi-Route Data Stream Systems
Karen Works, Elke A. Rundensteiner, and Emmanuel [email protected]
Database Systems Research Group (DSRG)Computer Science DepartmentWorcester Polytechnic Institute
This work is supported under NSF Grant 0917017, NSF CNS CRI Grant 0551584 (equipment grant), NSF Grant 0414567, and GAANN Grant. 1

Rudiments of Stream Processing essential to produce rapid results
function over long periods of time
data arrival rates commonly experience frequent fluctuations
2

1) Memory/CPU utilization
2) Query responsiveness
Q1 : Select *From StreamA , StreamB, StreamCWhere StreamA.z = StreamB.zand StreamB.y= StreamC.yand StreamC.x = StreamA.x
[Range 5 Minutes]
*- Avnur and et. al., Eddies: continuously adaptive query processing . (SIGMOD'00).*- Raman and et. al., Using State Modules for Adaptive Query Processing . (ICDE'03).
A B C
A B C
STeMs
States Stored Tuples
Join Operators
Eddy
A B CStreams New Tuples
Output results
Adaptive Multi-Route Systems (AMR)
3

Background
Indexing Research Adaptive Multi-Route
System Research
4

State Possible Indices
A x, z, and (x and z combined)
B y, z, and (y and z combined)
C x, y, and (x and y combined)
Eddy
A B C
A B C
A B C
STeMs
States
Streams
Stored Tuples
New Tuples
Join Operators
Access Modules
Indexx X&Z Y x X&Y Y
Output results
1) Memory/CPU utilization
2) Query responsiveness
Q1 : Select *From StreamA , StreamB, StreamCWhere StreamA.z = StreamB.zand StreamB.y= StreamC.yand StreamC.x = StreamA.x
[Range 5 Minutes]
5
*- Avnur and et. al., Eddies: continuously adaptive query processing . (SIGMOD'00).*- Raman and et. al., Using State Modules for Adaptive Query Processing . (ICDE'03).

Goal
Indexing Research Adaptive Multi-Route
System Research(AMR)
Can we customize an index design for AMR Systems to improve query responsiveness ?
6

B
Index Requirements for AMR
Eddy
A B CStreams
A CSTeMs
A B CStates
New Index Design
results
B
1) support many access patterns
2) require minimal CPU to maintain
3) maintainable in main memory
4) easily adaptable to work loads
7

Index Data Structure Data structure
bit-address index based solution
…
search request
hashA1(1001) = 7 = 00111hashA2(*) = 00 ~ 11hashA3(‘MA’) = 2 = 010bucket_addr1 = 0011100010 = 226bucket_addr2 = 0011101010 = 234bucket_addr3 = 0011110010 = 242bucket_addr4 = 0011111010 = 250
insert tuplePartitionAddress
hashA1(1001) = 7 = 00111hashA2(‘student’) = 3 = 11hashA3(‘MA’) = 2 = 010bucket_addr = 0011111010 = 250
Address Book
…
0
1023
1
Bucket 0 Bucket 1023
…
Bucket 1
A1 A2 A3
Bucket 250
IMportance-based Partitioning Index (IMP Index)
1001 student MA
1001 * MA
A. Aho and et. al.: Optimal Partial-Match Retrieval When Fields Are Independently Specified. (ACM TODS ‘79)
L. Ding and et, al, Index Tuning for Parameterized Streaming Groupby Queries. (SSPS'08).
8

B
Bit-address Index Meets the Requirements
Eddy
A B CStreams
A CSTeMs
A B CStates
Bit-address Index
results
B
1) support many access patterns
2) require minimal CPU to maintain
3) maintainable in main memory
4) easily adaptable to work loads
9

Index Assessment
1) Should all possible statistics be maintained?
Periodically the router sends search requests to suboptimal operators to update system statistics.
The extremely low frequencies of these suboptimal search requests are not likely to influence the final indices selected, yet they add additional overhead.
2) How much resources should be dedicated to Index Assessment?
the overhead of assessment must not affect query responsiveness(i.e., index assessment must be light weight)
Goal - gather statistics about query paths selected by the router
10

Index Assessment: Statistics Collected
11

Assessment Statistics Storage – Option 1 Self Reliant Index Assessment - SRIA
What? – Store count of every access pattern receivedHow? – Hash table. Maps each access pattern to a
unique binary representation
12

Compact Self Reliant Index Assessment - CSRIA
*- modeled after a heavy hitter algorithm proposed by Manku, and Motwan. Approximate frequency counts overdata streams. (VLDB’02).
What? – Remove access patterns that fall below a preset thresholdHow? – Hash table.
Map each access pattern to a unique binary representation
During assessment – removes the statistics that fall below a preset error rate
End of assessment – returns all statistics above a preset threshold
Assessment Statistics Storage – Option 2
13

CSRIA Example
14

Relationships between access patterns
15

Assessment Storage – Option 3 Dependent Index Assessment - DIA
What? – Store count of every access pattern received Keep search benefit relationships
How? – Logically - LatticePhysically - Hash table.
16

Compressed Dependent Index Assessment CDIA
Random combination randomly picks a single parent node
Highest count combination picks the single parent node with the highest frequency count thus far
<A, B, *, *> <*, B,*, D><A, *, *, D>
<A, B, *, D>
$<A,B,*,*>$
*- modeled after a hierarchical heavy hitter algorithm proposed by Cormode and et. al., Finding hierarchical heavy hitters indata streams. (VLDB’03).
What? – Combine access patterns that fall below a preset thresholdHow? – Hash table-keep search benefit relationships
During assessment – removes the statistics that fall below a preset error rateEnd of assessment – returns all statistics above a preset threshold
Assessment Storage – Option 4
17
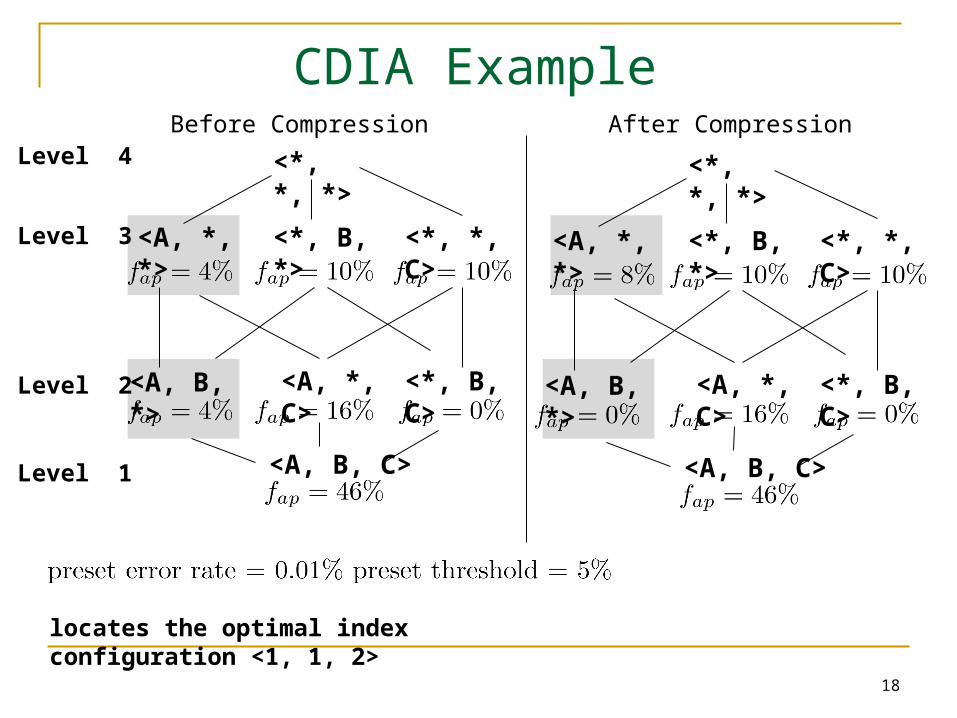
CDIA Example
Level 4
Level 3
Level 2
Level 1
<*, *, *>
<*, B, *><A, *, *> <*, *, C>
<*, B, C><A, B, *> <A, *, C>
<A, B, C>
After Compression
<*, *, *>
<*, B, *><A, *, *> <*, *, C>
<*, B, C><A, B, *> <A, *, C>
<A, B, C>
Before Compression
locates the optimal index configuration <1, 1, 2>
18
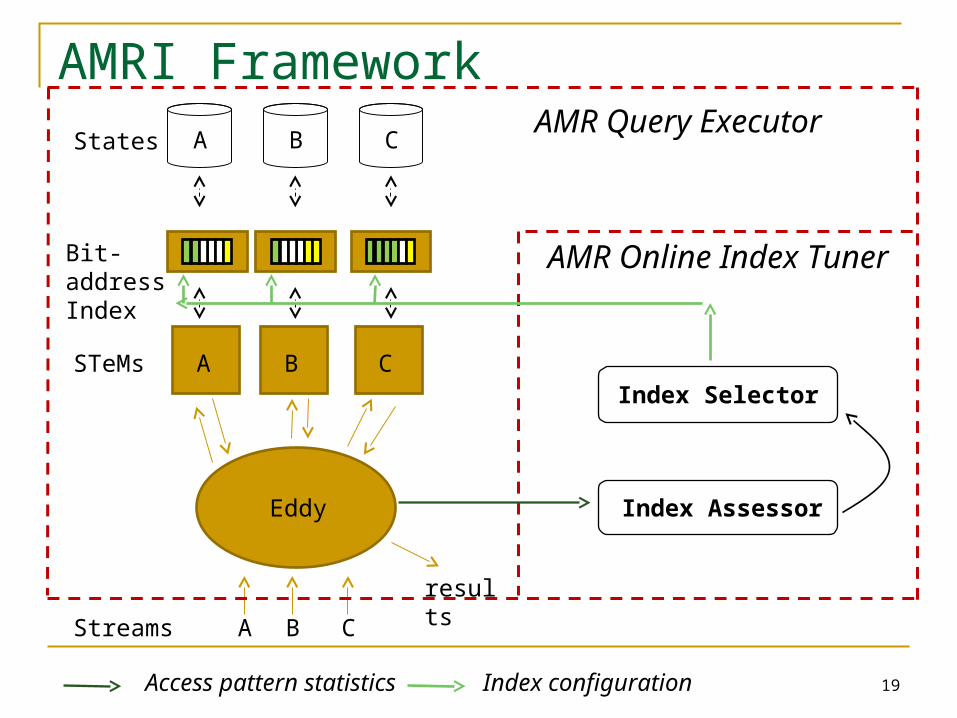
AMRI Framework
Eddy
A B CStreams
A CSTeMs
A B CStates
Bit-address Index
results
B
19Access pattern statistics Index configuration
AMR Online Index Tuner
Index Assessor
Index Selector
AMR Query Executor

Experiments
20

Experimental Set Up Experimental Set Up
Testing system CAPE* prototype continuous query engine
Testing machine 3GHz Intel® Pentium-IV, 1GB RAM Windows XP, Java 1.5.0_06 SDK
Design 4 way join query across 4 data streams The IC on each state uses 64 bits The maximum error = 5% and threshold 10%
*-E. A. Rundensteiner and et. al., CAPE: Continuous Query Engine with Heterogeneous-Grained Adaptivity. (VLDB Demo, 2004).
21
Time (min)
Cu
mul
ativ
e T
hro
ugh
pu
t (t
up
les)
Assessment
0 7.5 15 22.5 300
600,000
1,200,000
1,800,000
2,400,000
3,000,000
3,600,000SRIA & DIACSRIACDIA - randomCDIA - highest count
Time (min)
Cu
mul
ativ
e T
hro
ughp
ut (
tup
les)
Current AMR Index
0 2.5 5 7.5 10 12.50
50,000
100,000
150,000
200,000
250,0001 Hash Index2 Hash Indices3 Hash Indices4 Hash Indices5 Hash Indices6 Hash Indices7 Hash Indices
22
Time (min)
Cum
ulat
ive
Thr
ough
put (
tupl
es)
Synthetic Data Set Overall results
0 7.5 15 22.5 300
600,000
1,200,000
1,800,000
2,400,000
3,000,000
3,600,000AMRI7 Hash IndicesBitmap Index
23

Summary of Experimental Results
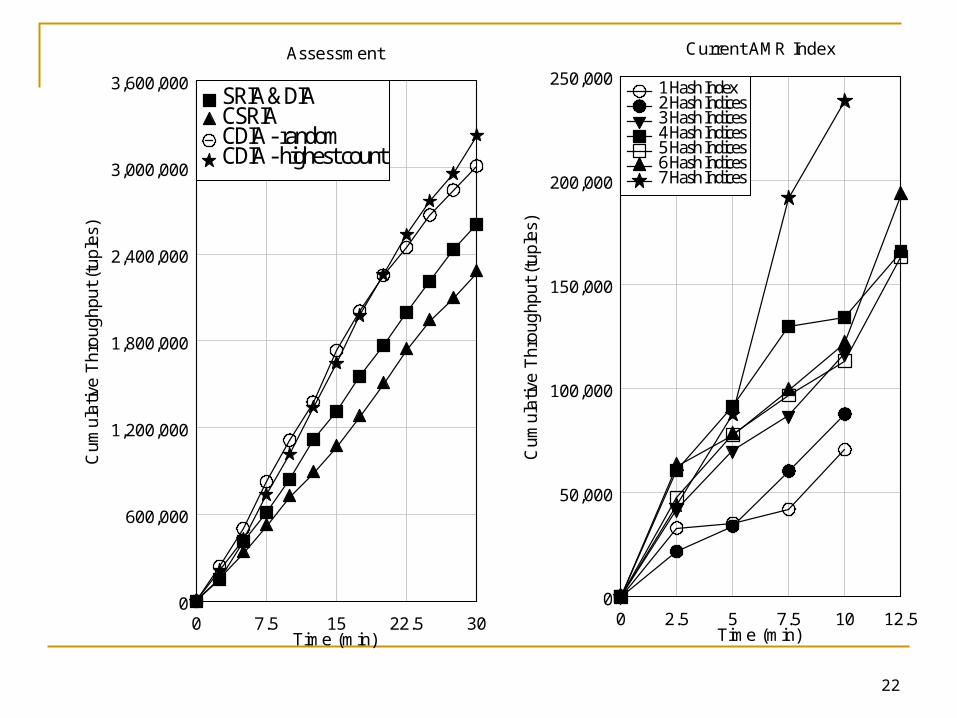
CDIA using highest count compression produced on average 19% more results (cumulative throughput) than both DIA and SRIA, and 30% more results than CSRIA over the same period of time.
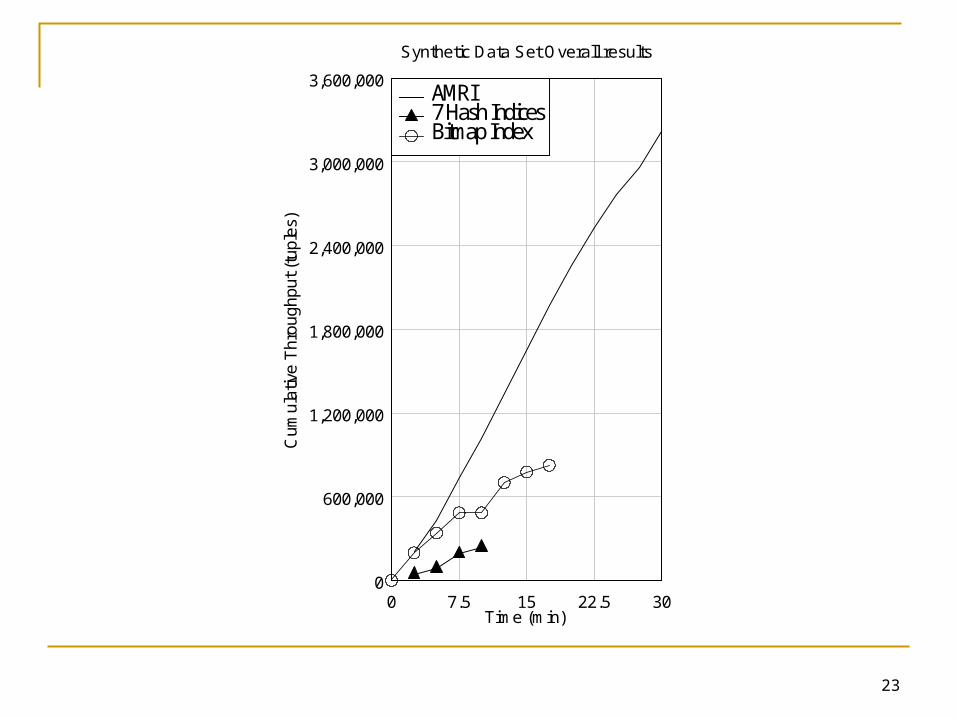
AMRI produced on average 93% more results (cumulative throughput) than the current indexing approach and 75% more results than the bitmap indexing approach over the same period of time.
24

Conclusion We developed the first customized
Adaptive Multi-Route Index for AMR systems.
We proposed 4 customized AMR systems assessment methods (SRIA, CSRIA, DIA, and CDIA).
Our experiments demonstrate overall effectiveness of our AMRI at improving throughput in dynamic stream environments compared to the state-of-art approach.
25

Thank you!
Welcome to DSRG Website
http://davis.wpi.edu/dsrg/
26