improving effectiveness and generality of gcc auto...
TRANSCRIPT

Improving Effectiveness And Generality of GCC Auto-vectorization.
Sameera Deshpande - Linaro

Agenda● Introduction● Motivating Example● Limitations● Primitive Reordering Operations● Algorithm● Highlights● Future Work

Autovectorization in GCC● Loop Vectorization
○ Classic single statement vectorization○ Interleaved data vectorization
● Superword Level Parallelism (SLP)● Loop aware SLP

Autovectorization in GCC● Loop Vectorization
○ Classic single statement vectorization○ Interleaved data vectorization
● Superword Level Parallelism (SLP)● Loop aware SLP
for (i = 0; i < N; i++){ D[i] = S1[i] + S2[i];}
for (i = 0; i < N/4; i++){ VS1 = S1[4 * i … 4 * i + 3] VS2 = S2[4 * i … 4 * i + 3] VD[4 * i … 4 * i + 3] = VS1 + VS2;}

Autovectorization in GCC● Loop Vectorization
○ Classic single statement vectorization○ Interleaved data vectorization
● Superword Level Parallelism (SLP)● Loop aware SLP
for (i = 0; i < N; i++){ D[2 * i] = S1[2 * i + 1] + 5; D[2 * i + 1] = S1[2 * i] + 6;}
for (i = 0; i < N/4; i++){ VS1 = S1[4 * i … 4 * i + 3] VS1odd = extract_odd (VS1); VS1even = extract_even (VS1); VT1odd = VS1odd + {5, 5}; VT1even = VS1even + {6, 6}; VD[4 * i … 4 * i + 3] = vec_permute (VT1odd, VT1even, {0, 2, 1, 3});}

Autovectorization in GCC● Loop Vectorization
○ Classic single statement vectorization○ Interleaved data vectorization
● Superword Level Parallelism (SLP)● Loop aware SLP
for (i = 0; i < N; i++){ D[4 * i] = S1[4 * i ] + 2; D[4 * i + 1] = S1[4 * i + 1] + 4; D[4 * i + 2] = S1[4 * i + 2] + 1; D[4 * i + 3] = S1[4 * i + 3] + 3;}
for (i = 0; i < N/4; i++){ VS1 = S1[4 * i … 4 * i + 3]; VD[4 * i … 4 * i + 3] = VS1 + {2, 4, 1, 3};}

Autovectorization in GCC● Loop Vectorization
○ Classic single statement vectorization○ Interleaved data vectorization
● Superword Level Parallelism (SLP)● Loop aware SLP
for (i = 0; i < N; i++){ D[2 * i] = S1[2 * i ] + 5; D[2 * i + 1] = S1[2 * i + 1] + 6;}
for (i = 0; i < N/4; i++){ VS1 = S1[4 * i … 4 * i + 3]; VD[4 * i … 4 * i + 3] = VS1 + {5, 6, 5, 6};}

Motivating Example with Transformationstruct line {
int x1, x2;
int y1, y2;
} arrl[N];
struct point {
int x;
int y;
} Pt1[N], Pt2[N];
for (i=0; i < N; i++)
{
arrl[i].x1 = Pt1[i].x;
arrl[i].x2 = Pt2[i].x;
arrl[i].y1 = Pt1[i].y;
arrl[i].y2 = Pt2[i].y;;
}
for (i = 0; i < N; i++) { D[4 * i] = S1[2 * i]; D[4 * i + 1] = S2[2 * i]; D[4 * i + 2] = S1[2 * i + 1]; D[4 * i + 3] = S2[2 * i + 1]; }

Memory Map for Examplefor (i = 0; i < N; i++) { D[4 * i] = S1[2 * i]; D[4 * i + 1] = S2[2 * i]; D[4 * i + 2] = S1[2 * i + 1]; D[4 * i + 3] = S2[2 * i + 1]; }
3 2 1 0 3 2 1 0
s2 s1
7 6 5 4 3 2 1 0
D

Memory Map for Examplefor (i = 0; i < N; i++) { D[4 * i] = S1[2 * i]; D[4 * i + 1] = S2[2 * i]; D[4 * i + 2] = S1[2 * i + 1]; D[4 * i + 3] = S2[2 * i + 1]; }
3 2 1 0 3 2 1 0
s2 s1
7 6 5 4 3 2 1 0
D
Interleave S1 and S2 to write in D.

Intuitive codeldr q0, [x0, -16] ldr q1, [x2, -16] st2 {v0.4s - v1.4s}, [x1], 32
for (i = 0; i < N; i++) { D[4 * i] = S1[2 * i]; D[4 * i + 1] = S2[2 * i]; D[4 * i + 2] = S1[2 * i + 1]; D[4 * i + 3] = S2[2 * i + 1]; }
N

Intuitive code Vs. AARCH64 code ldr q18, [x0, -32] ldr q19, [x0, -16] ldr q16, [x2, -32] ldr q17, [x2, -16] uzp1 v6.4s, v18.4s, v19.4s uzp2 v7.4s, v18.4s, v19.4s uzp1 v4.4s, v16.4s, v17.4s uzp2 v5.4s, v16.4s, v17.4s orr v0.16b, v6.16b, v6.16b orr v2.16b, v7.16b, v7.16b orr v1.16b, v4.16b, v4.16b orr v3.16b, v5.16b, v5.16b st4 {v0.4s - v3.4s}, [x1], 64
for (i = 0; i < N; i++)
{
D[4 * i] = S1[2 * i];
D[4 * i + 1] = S2[2 * i];
D[4 * i + 2] = S1[2 * i + 1];
D[4 * i + 3] = S2[2 * i + 1];
} N/2

Intuitive code Vs. AARCH64 code ldr q18, [x0, -32] ldr q19, [x0, -16] ldr q16, [x2, -32] ldr q17, [x2, -16] uzp1 v6.4s, v18.4s, v19.4s uzp2 v7.4s, v18.4s, v19.4s uzp1 v4.4s, v16.4s, v17.4s uzp2 v5.4s, v16.4s, v17.4s orr v0.16b, v6.16b, v6.16b orr v2.16b, v7.16b, v7.16b orr v1.16b, v4.16b, v4.16b orr v3.16b, v5.16b, v5.16b st4 {v0.4s - v3.4s}, [x1], 64
for (i = 0; i < N; i++)
{
D[4 * i] = S1[2 * i];
D[4 * i + 1] = S2[2 * i];
D[4 * i + 2] = S1[2 * i + 1];
D[4 * i + 3] = S2[2 * i + 1];
}
ldr q0, [x0, -32] ldr q2, [x2, -32] ldr q1, [x0, -16] ldr q3, [x2, -16]
st2 {v0.4s - v1.4s}, [x1], 32 st2 {v2.4s - v3.4s}, [x1], 32
N/2
N/2

AARCH64 code on GCC ToT ld2 {v6.4s - v7.4s}, [x3], 32 ld2 {v4.4s - v5.4s}, [x2], 32 mov v0.16b, v6.16b mov v2.16b, v7.16b mov v1.16b, v4.16b mov v3.16b, v5.16b st4 {v0.4s - v3.4s}, [x7], 64
`
for (i = 0; i < N; i++) { D[4 * i] = S1[2 * i]; D[4 * i + 1] = S2[2 * i]; D[4 * i + 2] = S1[2 * i + 1]; D[4 * i + 3] = S2[2 * i + 1]; }
N/2

Motivating Example with Transformationstruct quad {
int x1, y1;
int x2, y2;
int x3, y3;
int x4, y4;
} arrl[N];
for (i=0; i < N; i++)
{
arrl[i].x1 = x[2*i + 1];
arrl[i].y1 = y[2*i + 1];
arrl[i].x2 = x[2*i];
arrl[i].y2 = y[2*i];
arrl[i].x3 = x[2*i + 3];
arrl[i].y3 = y[2*i + 3];
arrl[i].x4 = x[2*i + 2];
arrl[i].y4 = y[2*i + 2];
}
for (int i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }

Intuitive code ld2 {v6.4s - v7.4s}, [x3], 32 ld2 {v4.4s - v5.4s}, [x2], 32 mov v0.16b, v7.16b mov v2.16b, v6.16b mov v1.16b, v5.16b mov v3.16b, v4.16b st4 {v0.4s - v3.4s}, [x7], 64
for (int i = 0; i < N/2; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
N/2

Intuitive code Vs. AARCH64 code ld4 {v20.4s - v23.4s}, [x7], 64 ld4 {v16.4s - v19.4s}, [x6], 64 mov x1, x5 mov v2.16b, v21.16b mov x2, x4 mov v4.16b, v22.16b mov v26.16b, v17.16b mov v24.16b, v18.16b mov v7.16b, v20.16b mov v28.16b, v23.16b mov v3.16b, v16.16b ld4 {v20.4s - v23.4s}, [x7] mov v27.16b, v19.16b ld4 {v16.4s - v19.4s}, [x6] mov v1.16b, v20.16b mov v20.16b, v23.16b mov v0.16b, v17.16b mov v23.16b, v16.16b mov v16.16b, v19.16b zip1 v6.4s, v1.4s, v22.4s zip2 v19.4s, v1.4s, v22.4s zip1 v17.4s, v23.4s, v18.4s zip1 v1.4s, v21.4s, v20.4s zip2 v23.4s, v23.4s, v18.4s zip1 v5.4s, v0.4s, v16.4s zip1 v25.4s, v2.4s, v28.4s zip2 v18.4s, v2.4s, v28.4s zip2 v20.4s, v21.4s, v20.4s zip1 v2.4s, v7.4s, v4.4s zip2 v21.4s, v26.4s, v27.4s zip2 v0.4s, v0.4s, v16.4s zip2 v7.4s, v7.4s, v4.4s zip1 v16.4s, v3.4s, v24.4s
N/8
zip1 v16.4s, v3.4s, v24.4s zip1 v4.4s, v26.4s, v27.4s zip2 v3.4s, v3.4s, v24.4s zip1 v22.4s, v20.4s, v19.4s zip1 v24.4s, v1.4s, v6.4s zip2 v20.4s, v20.4s, v19.4s zip2 v1.4s, v1.4s, v6.4s zip1 v19.4s, v0.4s, v23.4s zip1 v6.4s, v5.4s, v17.4s zip2 v0.4s, v0.4s, v23.4s zip2 v5.4s, v5.4s, v17.4s zip1 v23.4s, v25.4s, v2.4s zip1 v17.4s, v4.4s, v16.4s zip2 v2.4s, v25.4s, v2.4s zip2 v4.4s, v4.4s, v16.4s zip1 v16.4s, v18.4s, v7.4s zip2 v7.4s, v18.4s, v7.4s zip1 v18.4s, v21.4s, v3.4s zip2 v3.4s, v21.4s, v3.4s zip1 v25.4s, v24.4s, v6.4s zip1 v21.4s, v22.4s, v19.4s zip2 v6.4s, v24.4s, v6.4s zip1 v26.4s, v23.4s, v17.4s zip1 v24.4s, v1.4s, v5.4s str q25, [x0, 128] zip2 v1.4s, v1.4s, v5.4s str q6, [x0, 144] zip2 v5.4s, v22.4s, v19.4s str q26, [x0] zip1 v19.4s, v20.4s, v0.4s str q24, [x0, 160] zip1 v22.4s, v2.4s, v4.4s str q1, [x0, 176]
zip2 v0.4s, v20.4s, v0.4s str q21, [x0, 192] zip2 v2.4s, v2.4s, v4.4s str q22, [x0, 32] zip1 v20.4s, v16.4s, v18.4s str q5, [x0, 208] zip1 v4.4s, v7.4s, v3.4s str q2, [x0, 48] zip2 v17.4s, v23.4s, v17.4s str q20, [x0, 64] zip2 v16.4s, v16.4s, v18.4s str q4, [x0, 96] zip2 v3.4s, v7.4s, v3.4s str q17, [x0, 16] str q16, [x0, 80] str q3, [x0, 112] str q19, [x0, 224] str q0, [x0, 240]
ld2 {v6.4s - v7.4s}, [x3], 32 ld2 {v4.4s - v5.4s}, [x2], 32 mov v0.16b, v7.16b mov v2.16b, v6.16b mov v1.16b, v5.16b mov v3.16b, v4.16b
st4 {v0.4s - v3.4s}, [x7], 64
N/2

Inherent Limitations● Machine independent permute order generation
● Loop-aware SLP for continuous memory accesses
● Interleaved data vectorization has rigid structure
● No optimal instruction selection
● No unified representation
● Loop information in source is lost in enumeration
● Loop broken across iterations or across body

Loop Representation in GCC IR
for (i = 0; i < N; i++){ Stmt1: D[k * i + d1] = op1 (S1[k * i + c11], … Sm[k * i + c1m]); Stmt2: D[k * i + d2] = op2 (S1[k * i + c21], … Sm[k * i + c2m]); … Stmtk: D[k * i + dk] = opk (S1[k * i + ck1], … Sm[k * i + ckm]);}

Loop Representation in GCC IR
for (i = 0; i < N; i++){ Stmt1: D[k * i + d1] = op1 (S1[k * i + c11], … Sm[k * i + c1m]); Stmt2: D[k * i + d2] = op2 (S1[k * i + c21], … Sm[k * i + c2m]); … Stmtk: D[k * i + dk] = opk (S1[k * i + ck1], … Sm[k * i + ckm]);}

Loop Representation in GCC IR
for (i = 0; i < N; i++){ Stmt1: D[k * i + d1] = op1 (S1[k * i + c11], … Sm[k * i + c1m]); Stmt2: D[k * i + d2] = op2 (S1[k * i + c21], … Sm[k * i + c2m]); … Stmtk: D[k * i + dk] = opk (S1[k * i + ck1], … Sm[k * i + ckm]);}

Loop Representation in GCC IR
for (i = 0; i < N; i++){ Stmt1: D[k * i + d1] = op1 (S1[k * i + c11], … Sm[k * i + c1m]); Stmt2: D[k * i + d2] = op2 (S1[k * i + c21], … Sm[k * i + c2m]); … Stmtk: D[k * i + dk] = opk (S1[k * i + ck1], … Sm[k * i + ckm]);}

Loop Representation in GCC IR
for (i = 0; i < N; i++){ Stmt1: D[k * i + d1] = op1 (S1[k * i + c11], … Sm[k * i + c1m]); Stmt2: D[k * i + d2] = op2 (S1[k * i + c21], … Sm[k * i + c2m]); … Stmtk: D[k * i + dk] = opk (S1[k * i + ck1], … Sm[k * i + ckm]);}
create_data_ref

Primitive Reordering Operation - EXTRACT
for (i = 0; i < N; i++){ Stmt1: … = op1 (S1[k * i + c11], … );}
i = 0
0 1 … c11 … k k+1 … k+c11 … 2k ….. Nk-k Nk-k+1 … Nk-k+c11 … Nk-1S

Primitive Reordering Operation - EXTRACT
for (i = 0; i < N; i++){ Stmt1: … = op1 (S1[k * i + c11], … );}
i = 1
0 1 … c11 … k k+1 … k+c11 … 2k ….. Nk-k Nk-k+1 … Nk-k+c11 … Nk-1S

Primitive Reordering Operation - EXTRACT
for (i = 0; i < N; i++){ Stmt1: … = op1 (S1[k * i + c11], … );}
i = N-1
0 1 … c11 … k k+1 … k+c11 … 2k ….. Nk-k Nk-k+1 … Nk-k+c11 … Nk-1S

Primitive Reordering Operation - EXTRACT
for (i = 0; i < N; i++){ Stmt1: … = op1 (S1[k * i + c11], … );}
0 1 … c11 … k k+1 … k+c11 … 2k ….. Nk-k Nk-k+1 … Nk-k+c11 … Nk-1
0 1 … N-1
S
D

PRO - EXTRACT● EXTRACTNk
k,i : k-ary operation which divides source of size Nk into N parts, and accumulates ith element from each part to form a vector of size N
0 1 … c11 … k k+1 … k+c11 … 2k ….. Nk-k Nk-k+1 … Nk-k+c11 … Nk-1
0 1 … N-1
Nk
k,c11
S
D

Primitive Reordering Operation - INTERLEAVEFOR(i = 0; i < N; i + +) { Stmt1 : D[k∗i+0]= … ; Stmt2 : D[k∗i+1]= … … Stmtk : D[k∗i+k−1]= … ; }
i = 0
0 1 … k-1 k k+1 … 2k-1 2k 2k+1 … 3k-1 … Nk-k Nk-k+1 … Nk-1D

Primitive Reordering Operation - INTERLEAVEFOR(i = 0; i < N; i + +) { Stmt1 : D[k∗i+0]= … ; Stmt2 : D[k∗i+1]= … … Stmtk : D[k∗i+k−1]= … ; }
i = 1
0 1 … k-1 k k+1 … 2k-1 2k 2k+1 … 3k-1 … Nk-k Nk-k+1 … Nk-1D
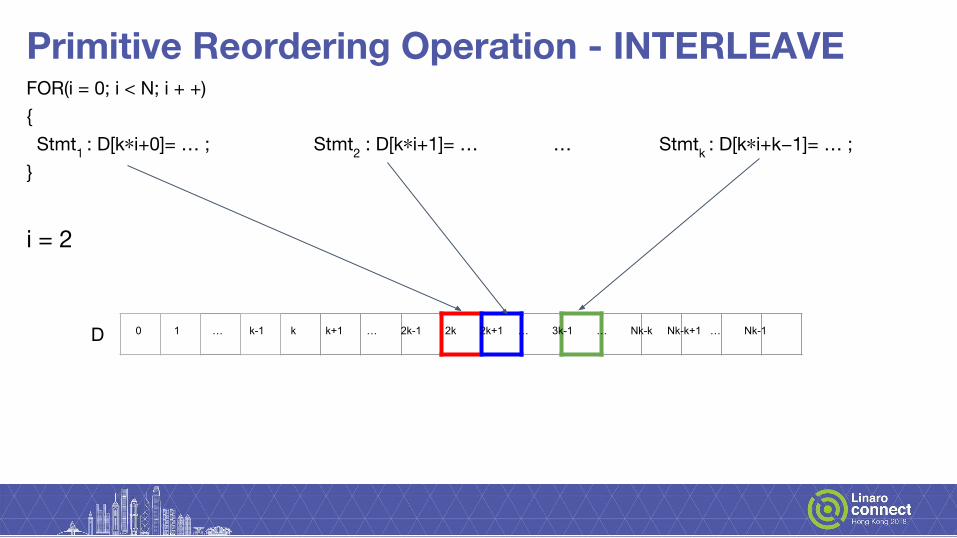
Primitive Reordering Operation - INTERLEAVEFOR(i = 0; i < N; i + +) { Stmt1 : D[k∗i+0]= … ; Stmt2 : D[k∗i+1]= … … Stmtk : D[k∗i+k−1]= … ; }
i = 2
0 1 … k-1 k k+1 … 2k-1 2k 2k+1 … 3k-1 … Nk-k Nk-k+1 … Nk-1D

Primitive Reordering Operation - INTERLEAVEFOR(i = 0; i < N; i + +) { Stmt1 : D[k∗i+0]= … ; Stmt2 : D[k∗i+1]= … … Stmtk : D[k∗i+k−1]= … ; }
i = N-1
0 1 … k-1 k k+1 … 2k-1 2k 2k+1 … 3k-1 … Nk-k Nk-k+1 … Nk-1D

Primitive Reordering Operation - INTERLEAVEFOR(i = 0; i < N; i + +) { Stmt1 : D[k∗i+0]= … ; Stmt2 : D[k∗i+1]= … … Stmtk : D[k∗i+k−1]= … ; }
0 1 … k-1 k k+1 … 2k-1 2k 2k+1 … 3k-1 … Nk-k Nk-k+1 … Nk-1D
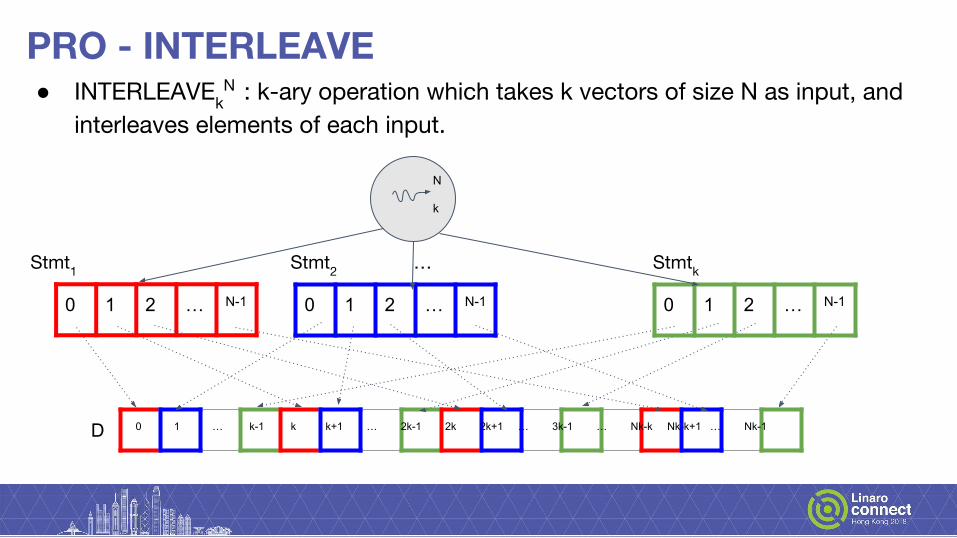
PRO - INTERLEAVE● INTERLEAVEk
N : k-ary operation which takes k vectors of size N as input, and interleaves elements of each input.
0 1 … k-1 k k+1 … 2k-1 2k 2k+1 … 3k-1 … Nk-k Nk-k+1 … Nk-1D
Stmt1 Stmt2 … Stmtk
0 1 2 … N-1 0 1 2 … N-1 0 1 2 … N-1
N
k

Algorithm● Phase 1: Represent loop as AST per destination memory
variable
● Phase 2: Arity promotion/reduction rules
● Phase 3: Unity reduction/redundancy elimination rules
● Phase 4: Tree-tiling algorithm for cost effective instruction
selection.

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
S1
N
4,1
S2
N
2,1
N
4,1

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
S1
N
4,1
S2
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
S1
N
4,1
S2
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
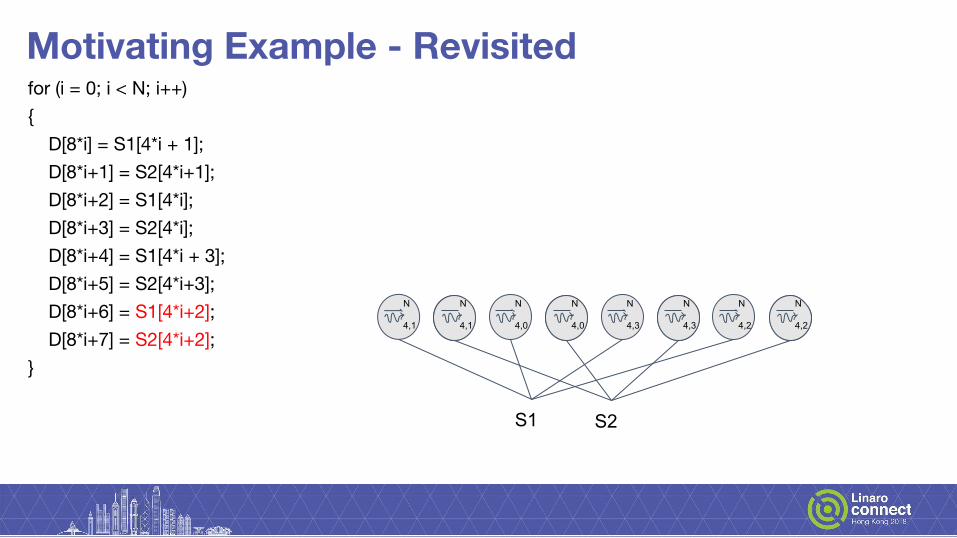
Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
0
N/4
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
0
N/4
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2
1

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
0
N/4
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2
1

Motivating Example - Revisitedfor (i = 0; i < N; i++) { D[8*i] = S1[4*i + 1]; D[8*i+1] = S2[4*i+1]; D[8*i+2] = S1[4*i]; D[8*i+3] = S2[4*i]; D[8*i+4] = S1[4*i + 3]; D[8*i+5] = S2[4*i+3]; D[8*i+6] = S1[4*i+2]; D[8*i+7] = S2[4*i+2]; }
0
N/4
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2
1 2 3 4 5 6 7

Motivating Example - Revisited
Before Arity Promotion/Reduction
0
N/4
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2
1 2 3 4 5 6 7

Motivating Example - Revisited
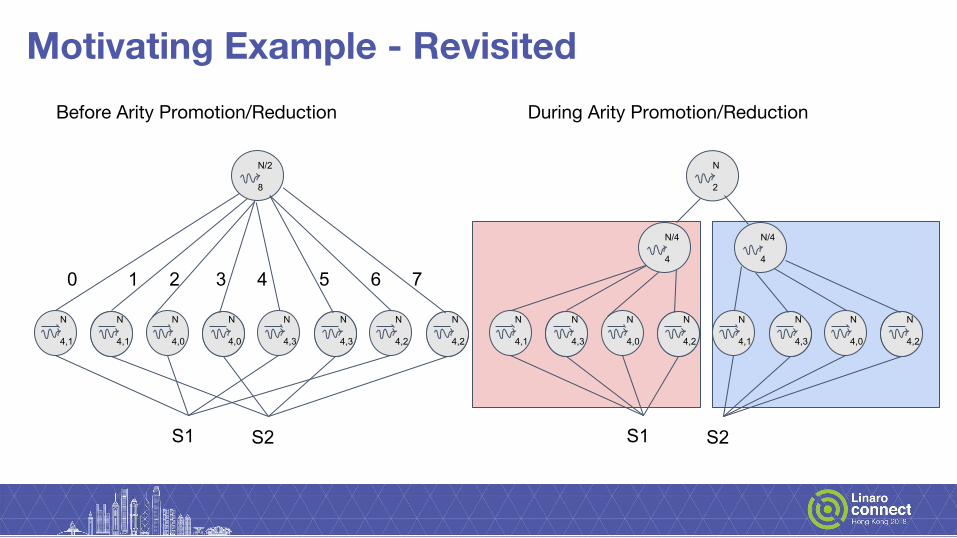
Before Arity Promotion/Reduction After Arity Promotion/Reduction
0
N/4
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2
1 2 3 4 5 6 7
N
2
N
4,1
N
2,1
N
4,3
N
4,0
N
2,1
N
4,2
N
4,1
N
2,1
N
4,3
N
4,0
N
2,1
N
4,2
S1 S2
N/4
4
N/4
4
Motivating Example - Revisited
Before Arity Promotion/Reduction During Arity Promotion/Reduction
0
N/2
8
N
4,1
N
2,1
N
4,1
N
4,0
N
2,1
N
4,0
N
4,3
N
2,1
N
4,3
N
4,2
N
2,1
N
4,2
S1 S2
1 2 3 4 5 6 7
N
2
N
4,1
N
2,1
N
4,3
N
4,0
N
2,1
N
4,2
N
4,1
N
2,1
N
4,3
N
4,0
N
2,1
N
4,2
S1 S2
N/4
4
N/4
4

Motivating Example - Revisited
N
4,1
N
2,1
N
4,3
N
4,0
N
2,1
N
4,2
S1
N/2
4

Motivating Example - Revisited
N
4,1
N
2,1
N
4,3
N
4,0
N
2,1
N
4,2
S1
N/2
4
S1
N
2
N
2,0
N
2,1
N
2,1
N
2,0
N/2
2
N/2
2
N
2,0
N
2,0
N
2,1
N
2,1

Motivating Example - Revisited
Before Unity Reduction
S1
N
2
N
2,0
N
2,1
N
2,1
N
2,0
N/2
2
N/2
2
N
2,0
N
2,0
N
2,1
N
2,1

Motivating Example - Revisited
Before Unity Reduction
S1
N
2
N
2,0
N
2,1
N
2,1
N
2,0
N/2
2
N/2
2
N
2,0
N
2,0
N
2,1
N
2,1
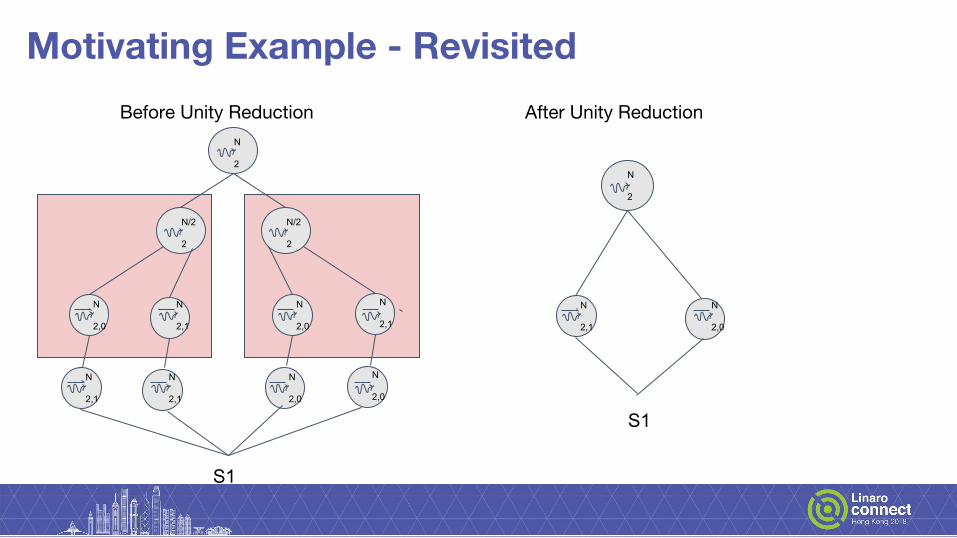
Motivating Example - Revisited
Before Unity Reduction After Unity Reduction
N
2
S1
S1
N
2
N
2,0
N
2,1
N
2,1
N
2,0
N/2
2
N/2
2
N
2,0
N
2,0
N
2,1
N
2,1
N
2,0
N
2,1
S1

Motivating Example - Revisited
N
2
S1N
2,0
N
2,1
S2
N
2
S1N
2,0
N
2,1
S1
2N
2
Reconstructed Tree

Motivating Example - Revisited
N
2
S1N
2,0
N
2,1
S2
N
2
S1N
2,0
N
2,1
S1
2N
2
LD2

Motivating Example - Revisited
N
2
S1N
2,0
N
2,1
S2
N
2
S1N
2,0
N
2,1
S1
2N
2
Reconstructed Tree
ST4

Code Generated with PRO ld2 {v6.4s - v7.4s}, [x3], 32 ld2 {v4.4s - v5.4s}, [x2], 32 mov v0.16b, v7.16b mov v2.16b, v6.16b mov v1.16b, v5.16b mov v3.16b, v4.16b st4 {v0.4s - v3.4s}, [x7], 64
for (i = 0; i < N; i++) { D[4 * i] = S1[2 * i]; D[4 * i + 1] = S2[2 * i]; D[4 * i + 2] = S1[2 * i + 1]; D[4 * i + 3] = S2[2 * i + 1]; }
N/2

Highlights● Whole loop is represented using extract and interleave operators.
● All auto-vectorization transformations can be performed by reduction/promotion rules.
● All PROs can be moved across order-preserving operations for better optimizations.
● Target reordering instructions can be represented using primitive reordering operations.
● Cost aware reorder instruction selection can be performed for efficient code generation.
● Loop transformations can be selectively performed based on target - using
reduction/promotion rules.
● New vectorization algorithm can be added by introducing new rules. All previous
transformations are recorded in representation.

Current status of PoC
● Vectorization of load and store operations within loop.● Instruction tiles creation for target instructions.● Cost effective BURS automata creation at build-time from instruction
tiles.● Arity promotion/reduction algorithm. ● Unity redundancy elimination algorithm.● Bottom-up labeling algorithm label and top-down reduction algorithm
reduce for BURS for compile time pattern matching

Thank You
#HKG18HKG18 keynotes and videos on: connect.linaro.orgFor further information: www.linaro.org