improving data quality methodology and techniques telcordia technologies proprietary – internal...
Post on 18-Dec-2015
271 views
TRANSCRIPT

Improving Data Quality Methodology and Techniques
Telcordia Technologies Proprietary – Internal Use OnlyThis document contains proprietary information that shall be distributed, routed or made available only within Telcordia Technologies, except with written permission of Telcordia Technologies.
Telcordia Contact:Paolo [email protected], 2001
An SAIC Company

Data Quality –AIPA Feb. 01– 2Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Presentation outline
Rationale for Data Quality– Canonical horror stories plus some good numbers
Process and Root Causes Analysis for quality improvement
Data error types Data Cleaning
– The record matching problem. Searching and matching– Distance functions– Approaches to record matching
Example: The Italian Ministry of Finances case study Analysis toolkits
– The INRIA Extensible framework– The Telcordia Extensible Data Analysis tool

Data Quality –AIPA Feb. 01– 3Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Data Quality in the telecomm
Large US phone companies suffer from various DQ-related problems:– Dispatching errors cost money: e.g. sending the wrong technicians
to fix a problem, or the right technician to the wrong place. It is estimated that a 1% reduction in dispatching errors would result in
$3M savings /year
– For at least one application, one telco company threw away 40% of the data in the DB because it was too expensive to use or attempt to clean it
– Customers may receive service before the they are entered in the billing system they get months worth of service for free
– Bad provisioning leads to wasted resources (lines allocated to no one) and to allocation of the same lines to multiple customers
– The same company cannot tell which wireline customers also subscribe to their own wireless service (the two customer DBs are not integrated)

Data Quality –AIPA Feb. 01– 4Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Data Quality in the Italian Public Administration
– Taxpayers’ residence data can be unreliable (out of date or incorrect): a sizable fraction of taxpayers cannot be reached by regular mail
– Administrative offices may force input values that violate data constraints
– Some taxpayers are assigned more than one SSN, resulting in multiple personae for tax purposes
– Taxpayers can be misidentified in the DB because their personal data is incorrect
– Part of the information provided by taxpayers in their tax returns is lost and unused once it flows into the system

Data Quality –AIPA Feb. 01– 5Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Data Contains Errors
Expected error ratesby industry segment
Source: Innovative Systems, 1999

Data Quality –AIPA Feb. 01– 6Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
The main DQ agenda Top-level agenda:
– Correct current known errors in the data: Data Cleaning Techniques are borrowed from Statistics, Machine Learning, Text
Retrieval, large Databases– Determine the cause for errors and prevent their occurrence:
root cause analysis and process analysis
Specifically:– Assess the current state of the data, for various quality dimensions– Predict the future state of the data (what gets dirty, and how fast)– Define improvement goals (estimate ROI(*) figures)– Identify priorities (which data gives me the highest ROI after
cleaning)? E.g. “wireline DB is dirty but its data are less important that wireless…” “Given a limited budget, cleaning wireless is simpler and more beneficial”
– Define data cleaning plan (methods, tools, extent)Ref.: P.Missier, G.Lalk, V.Verykios , F.Grillo, T.Lorusso, P.Angeletti, Improving Data Quality in Practice: A Case Study in the Italian Public Administration, Distributed and Parallel Databases Journal, Kluwer Academic Publishers, 2001, to appear

Data Quality –AIPA Feb. 01– 7Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Data Quality starts from process analysis
“What processes manipulate which data?” Without data flow analysis, data cleaning is only a temporary
solution:– New data will still be dirty and will contaminate the system
Enforcing Data Quality requires enforcing control over the Data Flows
Suppose data flows F1 and F2 carry logically related data:– When do the flows meet?
– Which entity is responsible for which data?– How is data supplied?– How do duplicates propagate?– Are related entries cross-validated?
Where in the system do they meet?Which procedures are involved?Is it too late to cross-reference the related data?Can they be matched earlier? How much would it cost?

Data Quality –AIPA Feb. 01– 8Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Data Flow and Process Analysis
Rationale:– Unpredictability in Data Quality is a consequence of poor control
and documentation over the processes that manipulate the data
Questions:– Who can update which data value? On which version? When do
synchronization and validation occur?
Goals:– Identify the processes and systems that manipulate the data
that is subject to quality control– Determine how that data flows through those processes and
systems

Data Quality –AIPA Feb. 01– 9Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Root Cause Analysis: Identify causes of poor data quality
Data-oriented process analysis. Ex.: When data flows F1 and F2 meet at time t, mismatches about related
data records are found. Can data be matched earlier? How much would it cost?
How many times is this address entered, and into how many systems? Are related entries cross-checked?
Mine data on current state of quality. Infer conclusions such as:
“most errors are due to manual data entry, and mostly come from processing centers with specific characteristics”
“systematic data currency errors in system B occur for data that is derived from system A”
“There is a strong correlation between this data being entered late, and the number of spelling errors it contains”
“Quality levels for subscribers’ address data have improved by x% on average after processes A,B,C were re-engineered”
Data Quality –AIPA Feb. 01– 10
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
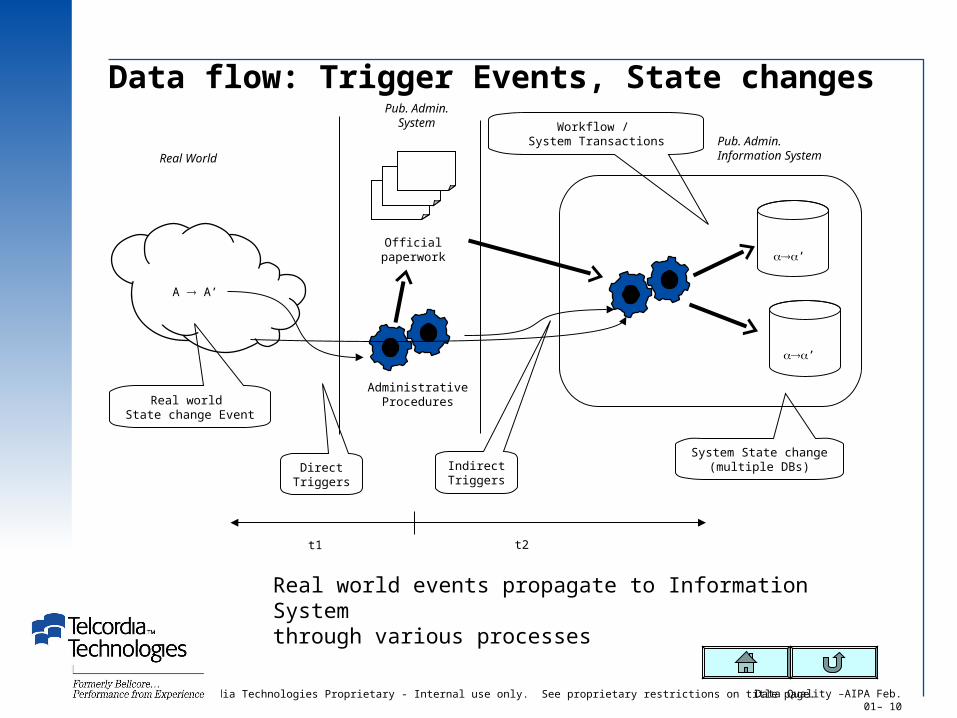
Data flow: Trigger Events, State changes
Real world events propagate to Information Systemthrough various processes
Pub. Admin.Information System
Pub. Admin.System
Officialpaperwork
Real World
’
’
A A’
AdministrativeProcedures
Workflow / System Transactions
Real world State change Event
System State change(multiple DBs)Direct
TriggersIndirectTriggers
t1 t2

Data Quality –AIPA Feb. 01– 11
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Process Analysis - Example (Italian P.A.)Trigger Input System
ProcedureExpected Data Quality
Correctness Currency Coerenzaformato
Birth.Notification tolocal town
Newborn’svital data
Integrated ormanualprocedure forgeneration ofnew SSN
High is procedure is integrated.Medium is manual data entry required
Max three months lag (bylaw)
Birth.Notification tofinances office
Parents’request(self-certified)
Finances’ officeonline (TP)
Low is cross-reference with DS notavailable.One dat entry step always required.High if DS immediately certifies datapresented by parents
Determined by parents’timeliness. Negligiblesystem processing time
Taxpayer’sdirect request
Taxpayer’srequest
Finances’ officeonline (TP)
Determined by ID used.One dat entry step always required.
Determined by taxpayer.Negligible systemprocessing time
Occasionalrealignmentwith DataSteward
Data Batchfrom DataSteward
Ad hocvalidation proc.for the specificbatch
High for validated data.No data entry required.
Arbitrarily low.Subsequent furthermisalignments areinevitable..
High forvalidateddata.

Data Quality –AIPA Feb. 01– 12
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Indicators
Quantities that describe the degree of correctness and currency of a population of data values, e.g.– % of values that are incorrect– % of values that are obsolete
When Computed:– at fixed intervals (scheduled monitoring)– on demand– when updates are available
Computed based on: sample or entire population How:
– aggregate over the validation state associated with the data

Data Quality –AIPA Feb. 01– 13
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Indicators example
I1: % duplicate SSN I2: % obsolete residence data I3: % truncated values in field xyz I4: % null values in field xyz I5: % gender values inconsistent with SSN
Given attribute A with values in {a1,…,an}, indicators can also be aggregated on A (e.g. A = set of administrative regions), e.g.– I1i: % duplicate SSN for group ai,, 1 i n

Data Quality –AIPA Feb. 01– 14
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Quality Constraints
Constraints are predicates over the indicators, e.g.– I2 < Y at the end of each month– I5 < Z for values generated before Dec. 31, 1997– …
Aggregated on A = {a1,…,an}:
– I1i < Xi with 1 i n, Xi possibly different for each ai
Parameters in the constraints are usually subject to negotiation between Data Provider and Data Customer;
Trade -off: cost of constraints satisfaction, resulting data quality– more stringent constraints => more expensive, better quality

Data Quality –AIPA Feb. 01– 15
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Classification of data error types
Syntactic correctness: the value is legal and it conforms to format constraints. Ex.:– a multi-part address (town, street, zip code, etc.)– Internal consistency of a credit card number– Misspelling errors
Semantic correctness: “how well does the data represent the true state of the world?”– Ex.: the residence data for a citizen is semantically correct if the address in the
record corresponds, to some degree, to the address where the citizen currently resides.
– Format and Value Consistency: How many acceptable formats and spelling exist for the same data item (think of all the known abbreviations in street addresses)
– Accuracy: we can measure by how much a format and spelling for a street deviates from a defined standard
– Value Completeness and Precision: ex.: how many optional elements are present for an address?
– Currency: Is data obsolete? Does it represent the current state of the world?

Data Quality –AIPA Feb. 01– 16
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Correcting data errors: Data Cleaning
Data Cleaning is the process of correcting data errors. Different techniques are used to deal with each error type
Research work on data quality has traditionally focused on the record matching problem
The goal in the record matching problem is to identify records in the same or different data sources/databases that refer to the same real world entity, even if the records do not match completely.
Record matching techniques only address the non-temporal error types
Challenges: Accuracy: need to quantify the errors incurred by a cleaning
technique Efficiency: algorithms must be suitable to handle large databases
(millions of records)

Data Quality –AIPA Feb. 01– 17
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Record Matching Across Data Sources
DB A DB B
Name Lastname DOB POB Address SSN
Name Lastname Phone Address SSN
Key matchNon-key, approximate match

Data Quality –AIPA Feb. 01– 18
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
The Record Matching Problem
Given a pair of records A and B in two data sources (could be the same source!), the matching algorithms attempt to determine if:– A and B represent the same entity: Match– A and B represent two different entities: Non-match
Within a single database, a duplicate is a record that represents the same entity as another record in the same database.
Common record identifiers such as names, addresses, and code numbers (SSN, object identifier), are the matching variables that are used to identify matches.
Ref.: Verykios, V.S., Elmagarmid, A.K., Elfeky, M., Cochinwala, M., and Dalal, S., A Survey on Record Linkage Techniques, unpublished.

Data Quality –AIPA Feb. 01– 19
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Steps in record matching
Data preparation– Normalize values
Bring field values to a standard format, based on the consistency rules
Searching– Build pairs of records that are potential matches within the
databases– Challenges: How to avoid building all n2 potential pairs
Matching– Determine whether or not a pair of records is actually a
match

Data Quality –AIPA Feb. 01– 20
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Values normalization - example

Data Quality –AIPA Feb. 01– 21
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Searching
S OSVALDO 16 FONDO D ORTO 7 FONDO D ORTO 9 NAPOLI 281 COGNULO 20 BRACCO 7 A.DE GASPERI 108 LO MARGI MONTE SANTO 5
DRUSO 1 FONDO DORTO 9 FONDO DORTO 7 TRAV. LATTARO 2 TRAV. LATTARO 2 BENEDETTO BRIN 79 CSA ALCIDE DE GASPERI 105BCDA MARGI-MONTE DON BOSCO 5A
How many record pairs do I need to consider?

Data Quality –AIPA Feb. 01– 22
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Complexity reduction in Searching
Brute-force approach is quadratic in the number of records Cluster based on the values of some grouping variables or
some a-priori knowledge. Ex.:– If I know the “place of birth” is clean, then I can build as many
clusters as there are cities. Sorting according to a comparison key will bring “similar”
records close to each other.– Blocking: only compare records that agree on the comparison key– Windowing: only compare records that lie within a window of
given size after sorting
Complexity reduction incurs the risk of missing valid matches. Metrics have been developed to evaluate the accuracy of a
clustering and sorting technique

Data Quality –AIPA Feb. 01– 23
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Matching: field values distance functions
First, we define functions that measure the distance between two values. Different functions are used for different value types.
The distance function definition depends on the specific data domain:– Standard Strings Comparison functions: There are many
ways to define the distance between two strings Which one is more appropriate?
– Other data types require ad hoc comparison functions: Ex.: “Codice Fiscale”: what is the distance between two CFs?

Data Quality –AIPA Feb. 01– 24
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Simple Examples of String Distance
Simple edit distance:– d(A,B) = number of single-char insert/delete required to
map string A to string B– d(“smith”, “mitch”) = 2 (“mitch” +’s’ -‘c’ = “smith”)– d(“mitch’, “mitcheli”) = 3
Weighted edit distances: different chars have different weights:– if blanks only count .5, then
d(“lungotevere Massimo”, “lungo tevere Masimo”) = 1.5
Different fields contribute different weights:d([piazza, Toti], [via, Toti]) < 6
because d(“piazza”, “via”) < 6 in this context. Distance can also be a discrete function, e.g.:
d(piazza, via) = X, d(via, strada) = Y, ...

Data Quality –AIPA Feb. 01– 25
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Basic Field Matching Algorithm
Degree of match in two composite fields:– “number of matching atomic strings” / “avg. number of
atomic strings”
– atomic strings S1, S2 match if: S1 = S2, or S1 = S2 +
Ex.: A = “Comput Sci Eng Dept University of California San Diego”
B= “Department of Computer Science Univ Calif San Diego"
– k = 6 strings in A match some string in B:Comput, Sci, San, Diego, Univ, and Calif.
– The overall matching score is k / (|A| + |B|)/2) = 0.8.
Data Quality –AIPA Feb. 01– 26
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
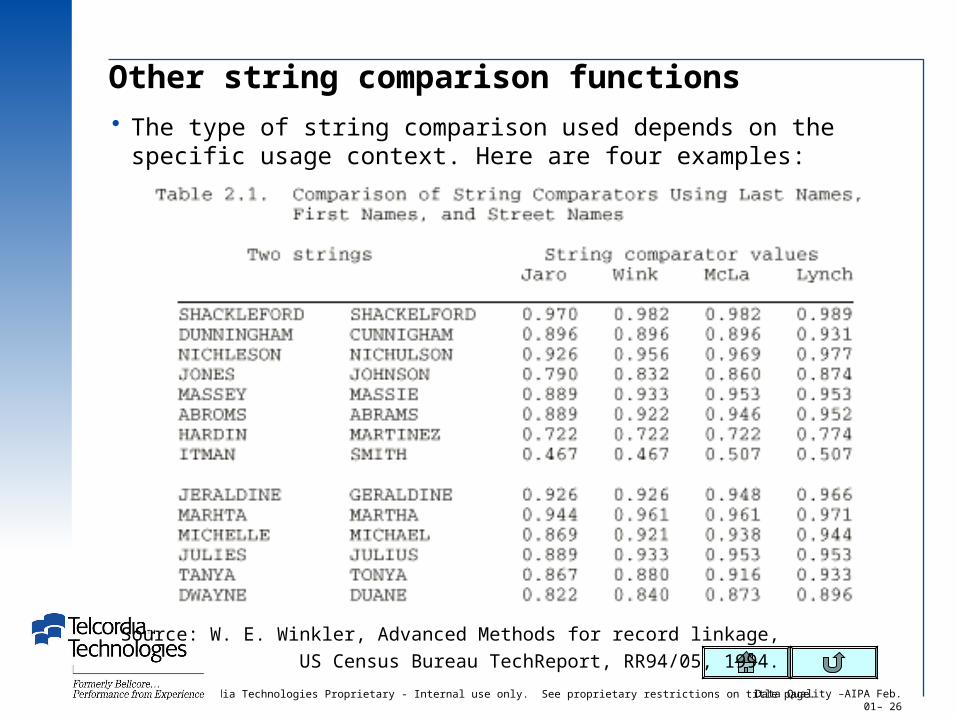
Other string comparison functions The type of string comparison used depends on the specific
usage context. Here are four examples:
Source: W. E. Winkler, Advanced Methods for record linkage, US Census Bureau TechReport, RR94/05, 1994.

Data Quality –AIPA Feb. 01– 27
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
“Group distance” – example of correct matches
CCCGPP55B65F258D S.SCRIBANO 1 G NNA SORTINO SCRIBANO 1CCHRSR45E30H163N C SA VITTORIO VENETO 629 VITT VENETO 629 CLDDRC24P57E730R FIUME VECCHIO2 S LORENZO FIUME VECCHIOCRRMRA61H64L219G F ROSSITTO 6 FELICIANO ROSSITTO 6 SCALA DCSCGNN22A22H163Y P.MONTECHIARO 52 PALMA DI MONTECHIARO N.52DLLRSN26R58E730C VILLA S.MARTINO PROV.BAGNARA 113 PROV BAGNARA 79 VILLA S MARTINCSSGNZ60A31H163V G.CADORNA 4 GEN CADORNA LOTTO 95 4
BBNLRA45C58I787D U.DELLA RAGGIOLA 3 UGUCCIONE DELLA FAGGIUOLA 3BBTDNC39M45C129M R VINI 33 RAFFAELE VIVIANI 33 BBRMHL71R04C129F TRAVERSA IOVINE 18 TRAV. IOVINO 18 BBNMSM67E14E730T CARRARA PASETTI I 1 - BELRICET CARR. PASETTI I 1
Anagrafe Tributaria: Comparing Archivio Anagrafico with Dichiarazioni
Anagrafe Tributaria: Comparing Archivio Anagrafico with data from Comuni

Data Quality –AIPA Feb. 01– 28
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
“Group distance” – correctly identified mismatches
BBDSDA57A41Z330Q S OSVALDO 16 DRUSO 1 BBGNNT63T54L245R FONDO D ORTO 7 FONDO DORTO 9 BBGRFL67L49C129D FONDO D ORTO 9 FONDO DORTO 7 BBLGRL56B27C129P NAPOLI 281 TRAV. LATTARO 2 BBLLCU95S09C129V COGNULO 20 TRAV. LATTARO 2 BBLNTN73S07C129P BRACCO 7 BENEDETTO BRIN 79 BBLVCN58P19C129L A.DE GASPERI 108 CSA ALCIDE DE GASPERI 105BBBTGRG46R01F258O LO MARGI MONTE CDA MARGI-MONTE BBTVCN25B18C129F SANTO 5 DON BOSCO 5A
Anagrafe Tributaria: Archivio Anagrafico Comuni: group distance = 7

Data Quality –AIPA Feb. 01– 29
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Other String comparison functions
Many other functions can be used to define the distance between two strings, i.e.:
Smith-Waterman: Given two strings, the Smith-Waterman algorithm uses dynamic programming to find the lowest cost series of changes that converts one string to another.
N-grams: Letter n-grams, including trigrams, bigrams, and/or unigrams, have been used in a variety of ways in text recognition and spelling correction techniques
Jaro algorithm: a string comparison algorithm that accounts for insertions, deletions, and transpositions.
Russell Soundex code is a phonetic coding, based on the assignment of code digits which are the same for any of a phonetically similar group of consonants. It is used most frequently to bring together variant spellings of what are essentially the same names.

Data Quality –AIPA Feb. 01– 30
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Comparison Vectors
For each pair of records identified in the search phase, we compare their field values using the distance functions.
Example:– A= [CF1, Nome1, Cognome1, DataNascita1, LuogoNascita1, Sesso1],– B= [CF2, Nome2, Cognome2, DataNascita2, LuogoNascita2, Sesso2],– Compare:
CF with CF d = 3.2 Nome1 + Cognome1 with Nome2 + Cognome2 d = 2.4 DataNascita1 with DataNascita2 d = 10 LuogoNascita1 with LuogoNascita2 d = 3.5 Sesso1 with Sesso2 d = 0
The resulting vector of comparison values is called the comparison vector:– Final vector = [ 3.2, 2.4, 10, 3.5, 0]

Data Quality –AIPA Feb. 01– 31
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Using Comparison Vectors: Approaches to record matching
We now have a potentially very large collection of comparison vectors.
For each vector, we need to determine if it represents: a match, a non-match, or an undecided pair– This is a classification problem
Probabilistic approach:– Hypothesis testing: “pick the match status that minimizes
cost or error” Equational theory model / the merge-purge algorithm
(S. Stolfo)– Introduce knowledge that can be used to make inferences
about the match status of two records

Data Quality –AIPA Feb. 01– 32
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Examples of equational rules
/* RULE: compare-addresses */
similar_addrs = compare_addresses(person1stname,person2stname);
/* RULEs: closer-addresses-use-zips and closer-address-use-states*/
very_similar_addrs =
(similar_addrs && similar_city &&(similar_state || similar_zip));
/* RULEs: same-ssn-and-address and same-name-and-address */
if ((similar_ssns || similar_names) && very_similar_addrs) {
merge_tuples(person1, person2);
continue;
}

Data Quality –AIPA Feb. 01– 33
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Examples of correct matches in merge/purge

Data Quality –AIPA Feb. 01– 34
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Accuracy of merge/purge
Accuracy measured in % duplicates detected on synthetic data and % false positives

Data Quality –AIPA Feb. 01– 35
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
The 1999 Ministry of Finance study on the Quality of its data
Specific Goals:
To assess the quality of addresses in DB Archivio Anagrafico with respect to:– currency (how many records do not reflect the real
taxpayer’s address)– correctness (how many addresses are spelled out correctly)
To determine the better reference source for cleaning the Archivio Anagrafico
To detect unknown duplicate Codici Fiscali (CFs) in DB Archivio Anagrafico

Data Quality –AIPA Feb. 01– 36
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Approach
Addresses:– sample AA (about 275,000 records) according to various criteria
(mainly, availability of corresponding Comuni data)– match addresses against recent, official residence data (Comuni) for
the same taxpayers (same CF)– match addresses against recent data from Dichiarazioni for the same
taxpayers (same CF)
Duplicate CFs:– sample about 600,000 records from three Comuni (Bari, Carbonara di
Bari, Chioggia)– from the population, a set of 34,244 records (5.71%) are known
duplicates (“connessi”)
– Detect patterns of anomalies that lead to known duplicate CFs, using “connessi” as the training set. Induce heuristics.
– Process entire population automatically using the induced heuristics

Data Quality –AIPA Feb. 01– 37
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Analysis of known duplicates (“connessi”) - TS
mismatching field count frequencycognome 4104 11.98%nome 6116 17.86%anno nascita 3403 9.94%mese nascita 2435 7.11%giorno nascita 8754 25.56%sesso 2152 6.28%comune nascita 4419 12.90%piu di un campo 2861 8.35%tot connessi 34244 100.00%
cognomenomeanno nascitamese nascitagiorno nascitasessocomune nascitapiu di un campo

Data Quality –AIPA Feb. 01– 38
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
General Classification approach: Supervised Learning
Described in M. Cochinwala, V. Kurien, G. Lalk, and D. Shasha. Efficient Data Reconciliation, Bellcore Research, February 1998.
Use of machine learning and statistical techniques for reducing the matching complexity for large datasets.
Use a machine learning algorithm (CART, a well-known decision tree inducer) to generate matching rules.
The system generates rules with very high accuracy, and low complexity. The automatically reported rules increased the accuracy of the matching process from 63% to 90%.
Follow-up Research work still in progress

Data Quality –AIPA Feb. 01– 39
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Prototype Data Analysis and Cleaning Toolkits

Data Quality –AIPA Feb. 01– 40
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
An Extensible Framework for Data Cleaning-- INRIA, France
Apply a set of transformations to the source data Framework: a platform offering data manipulation
services: Data Transformation for standardization of attribute values Multi-table Matching, Approximate Join, similarity functions,
clustering Duplicate Elimination
– Implementation: SQL-like Macro-operators for:
Data Mapping (CREATE MAPPING) Data Matching (CREATE MATCH) Data Clustering (CREATE CLUSTER) Data Decision (CREATE DECISION)

Data Quality –AIPA Feb. 01– 41
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Key contributions
Open framework with extensible library of user-defined functions for– attribute value similarity matching– clustering strategy
Expressive SQL-like macro commands.– Cartesian product semantics for tuple matching
Optimizations:– mixed execution supported by regular SQL engine +
homegrown extensions– improve upon the baseline Cartesian-product complexity of
the matching for large datasets (>100,000 tuples)
Ref.: H.Galhardas, D. Florescu, D. Shasha, E.Simon, An Extensible Framework for Data Cleaning, Procs. EDBT, 1999

Data Quality –AIPA Feb. 01– 42
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Telcordia’s Data Analysis Toolkit
Toolkit DemoToolkit Demo

Data Quality –AIPA Feb. 01– 43
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Framework
Rules and solutions differ from domain to domain Flexibility in resolution rules is essential Preprocessing and cleaning varies with the nature of data
However, in most cases a common pattern emerges:– Data is handled in stages,– Each stage is responsible for one step of transformation (matching,
merging, cleaning, etc.) and– Stages can be chained together to produce an overall data flow.
We define a framework that allows– Any number of custom-made processing blocks– Combination of those blocks in various ways

Data Quality –AIPA Feb. 01– 44
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Approach
Data-flow architecture– The framework enforces a simple producer-consumer model
between pairs of functional blocks– Workflow-style, graphical design of ad hoc analysis
processes– Flexibility and extensibility:
Functional Blocks are independent components that interoperate through a data-flow infrastructure
Specific user-defined matching, clustering, and other analysis algorithms are incapsulated and can be plugged in
Toolkit Demo

Data Quality –AIPA Feb. 01– 45
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
Summary and conclusions
Data Quality improvement calls for a comprehensive methodology that includes– Process analysis and re-engineering– Data analysis and cleaning
Data cleaning and data analysis automation are still more an art than a craft:– A variety of sophisticated techniques has been used to tackle the
cleaning problem (record matching), borrowing from Statistics, Machine Learning, Text Retrieval
– Current commercial tools are expensive and only solve part of the problem
– Developing cleaning solutions that include re-engineering requires experience and domain espertise
The “open toolkit” approach begins to enter the DQ tools space

Data Quality –AIPA Feb. 01– 46
Telcordia Technologies Proprietary - Internal use only. See proprietary restrictions on title page.
References Verykios, V.S., Elmagarmid, A.K., Elfeky, M., Cochinwala, M., and Dalal, S., On the
Completeness and Accuracy of the Record Matching Process. In Proceedings of the 2000 Conference on Information Quality, pp. 54-69, October 2000, Boston, MA.
M. A. Hernadez and S. J. Stolfo. The merge-purge problem for large databases, In Proc. of the 1995 ACM SIGMOD Conference, pages 127--138, 1995.
H.Galhardas, D. Florescu, D. Shasha, E.Simon, An Extensible Framework for Data Cleaning, Procs. EDBT, 1999.
M. Cochinwala, V. Kurien, G. Lalk, and D. Shasha. Efficient Data Reconciliation, Bellcore Research, February 1998.
Jeremy A. Hylton, Identifying and Merging Related Bibliographic Records, Master's thesis, Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, 1996.
Matthew A. Jaro, Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida, Journal of the American Statistical Association 84 (1989), no. 406, 414-420.
Alvaro E. Monge and Charles P. Elkan, The Field Matching Problem: Algorithms and Applications, Second International Conference on Knowledge Discovery and Data Mining (1996), 267-270, AAAI Press.
W.E. Winkler, Advanced Methods for Record Linking, Proceedings of the Section on Survey Research Methods (American Statistical Association), 1994, pp. 467-472.
W. E. Winkler, The State of Record Linkage and Current Research Problems, Proceedings of the Survey Methods Section (1999), 73-79.