improving code readability models with textual features
TRANSCRIPT

Improving Code Readability Models with Textual FeaturesSimone Scalabrino, Mario Linares-Vásquez, Denys Poshyvanyk, Rocco Oliveto

Software maintenance accounts for
70%of the costs of a project


for (int i=1;i<=100;i++) { int a=((528>>i%15-1)&1)*4; int b=((-2128340926>>(i%15)*2)&3)*4; System.out.println("FizzBuzz".substring(a,b)+(a==b?i:""));}
What does it do?

Not really clear...

for (int i=1;i<=100;i++) { String fizzBuzz = “”; if (i % 3 == 0) fizzBuzz += “Fizz”;
if (i % 5 == 0) fizzBuzz += “Buzz”;
if (fizzBuzz.isEmpty()) fizzBuzz += i;
System.out.println(fizzBuzz);}
What about this one?

Why is it easier to understand?

Code readability

Code readability prediction

Source code

Source code
Source codeSource codeFeatures

Source code
Source codeSource codeFeatures
Training set Machine learner

Source code
Source codeSource codeFeatures
Readable Unreadable
Training set Machine learner

Code readability prediction

Code readability prediction

Code readability prediction

Code readability prediction
Structural features

Code readability prediction
Structural features
Visual features

Code readability prediction
Structural features
Visual features
Two datasets

Something is missing...

Code is text!

New features

Comments readability

Comments readability
Flesch-Kincaid index

Comments and identifiers consistency

Comments and identifiers consistency
Overlap between terms in commentsand terms in identifiers

Identifier terms in dictionary

Identifier terms in dictionary
Percentage of correct terms in identifiers

Narrow meaning identifiers

Narrow meaning identifiers
“Sum” more specific than “computation”

Number of meanings

Number of meanings
“Present” more ambiguous than “Attendee”

Textual coherence

Textual coherence
Consistency between pairs of syntactic blocks

Textual features

Source code
Source codeSource codeFeatures
Readable Unreadable
Training set Logistic regression

Case study

New datasetNew dataset
200 Java snippets
9annotators

Do textual features complement the others proposed
in the literature?

Overlap metrics

Textual Features vs Buse’s
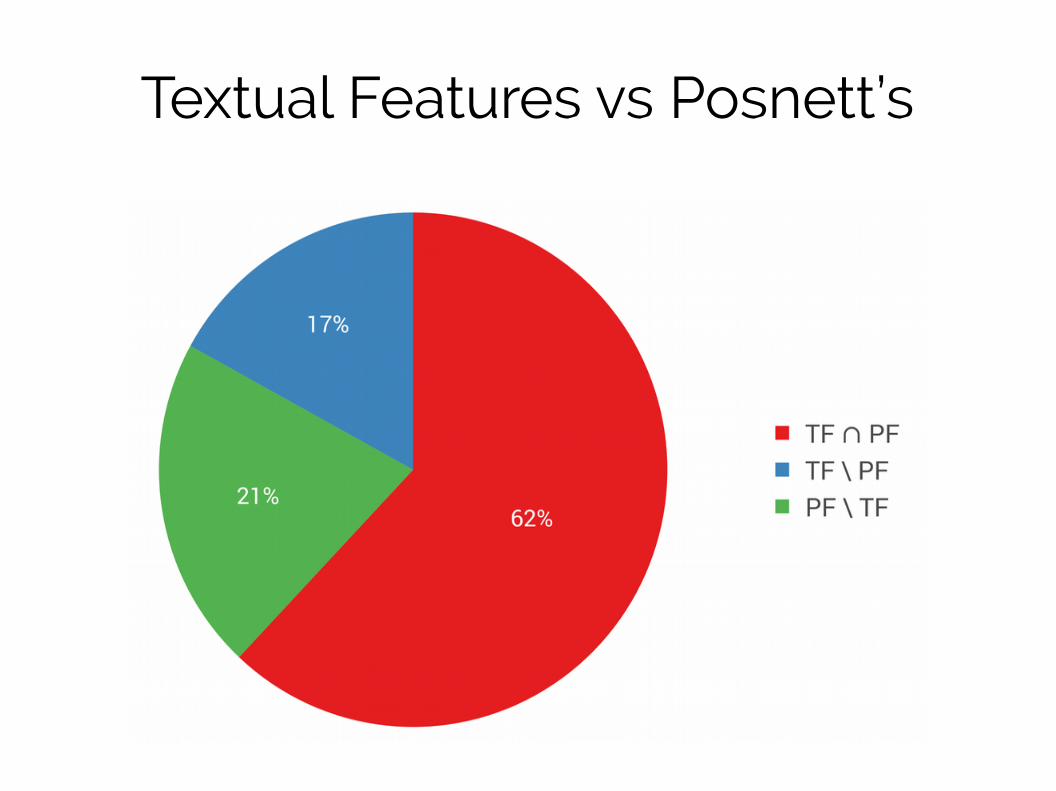
Textual Features vs Posnett’s

Textual Features vs Dorn’s

Textual Features vs Dorn’s
Readability of 12%-21% of snippets can
be explained only using textual features

What is the accuracy of a readability model based
on structural and textual features?

79%
81%
78%
80%
74%
Dataset by Buse and Weimer
ALL-F: All featuresT-F: Textual features
D-F: Dorn’s featuresP-F: Posnett’s features
BW-F: Buse’s features

84%
79%
73%
80%
77%
Dataset by Dorn
ALL-F: All featuresT-F: Textual features
D-F: Dorn’s featuresP-F: Posnett’s features
BW-F: Buse’s features

80%
71%
66%
76%
68%
New dataset
ALL-F: All featuresT-F: Textual features
D-F: Dorn’s featuresP-F: Posnett’s features
BW-F: Buse’s features

80%
71%
66%
76%
68%
New dataset
ALL-F: All featuresT-F: Textual features
D-F: Dorn’s featuresP-F: Posnett’s features
BW-F: Buse’s features
A model which includes all features
achieves an higher accuracy on 2 datasets

In summary...

Code readability for defect prediction

Thanks.