identifying signs of schizophrenia in twitter using text...
TRANSCRIPT

Identifying signs of schizophrenia inTwitter using text mining techniques
Maksim Belousov
Supervised by Dr Goran Nenadic
School of Computer Science
University of Manchester
Computer Science BSc
April 2015

Acknowledgements
I would like to take this opportunity to thank my supervisor Dr Goran Nenadic for theguidance, wisdom and support in this project. I am also grateful to Dr Rohan Morris andNatalie Berry from School of Psychological Sciences for their advices, ideas and the expertknowledge provided.

Abstract
Schizophrenia is a complex mental disorder which affects around 1 in every 100 people andfeatures various symptoms such as hallucinations and delusions. Auditory hallucinations or"hearing voices" is the most common hallucination in schizophrenia.
In this project we have focused on this symptom and developed a computational frame-work along with a set of probabilistic classifiers which can identify real hallucination experi-ence in Twitter using text mining techniques.
We have extracted different semantic classes along with sentiment polarity from postsand experimented with several probabilistic classifiers to provide a classification model.
It was found that negative emotions are more frequently used to describe hallucinations.Also, the significant amount of people shared their experiences during the night.
An accuracy of 92.7% was achieved using Multinomial Naive Bayes classification model.

Table of contents
List of figures vi
List of tables vii
1 Introduction and motivation 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Aim and objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Report structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Background 32.1 Twitter as an information source . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Twitter API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Text mining and natural language processing . . . . . . . . . . . . . . . . . 4
2.2.1 Tokenisation and sentence splitting . . . . . . . . . . . . . . . . . 52.2.2 Word stemming and lemmatisation . . . . . . . . . . . . . . . . . 52.2.3 Part-of-Speech tagging . . . . . . . . . . . . . . . . . . . . . . . . 62.2.4 Spelling correction . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2.5 Named-entity recognition . . . . . . . . . . . . . . . . . . . . . . 62.2.6 Sentiment analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Machine learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3.1 Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3.2 Measuring classifier performance . . . . . . . . . . . . . . . . . . 10
2.4 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Development 123.1 Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2.1 System architecture . . . . . . . . . . . . . . . . . . . . . . . . . . 13

Table of contents v
3.2.2 Crawling the social media data . . . . . . . . . . . . . . . . . . . . 143.2.3 Processing pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . 153.2.4 Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.2.5 Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2.6 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.2.7 Preprocessing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.2.8 Feature extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2.9 Classification of posts . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.3.1 Technologies used . . . . . . . . . . . . . . . . . . . . . . . . . . 273.3.2 Data collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.3.3 Text mining and natural language processing tools . . . . . . . . . 283.3.4 Machine learning . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.4 Regression testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4 Results and evaluation 314.1 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.2 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.3 Data explorations and observations . . . . . . . . . . . . . . . . . . . . . . 36
5 Conclusion 385.1 Reflection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.2 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.3 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
References 40

List of figures
2.1 Text mining pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Text tokenisation example . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 Word stem and lemma extraction . . . . . . . . . . . . . . . . . . . . . . . 52.4 Ambiguities in POS tagging . . . . . . . . . . . . . . . . . . . . . . . . . 62.5 Word transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.6 Processing pipeline for sentiment polarity classification . . . . . . . . . . . 72.7 Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.8 Random subsampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.9 K-fold cross validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 System architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2 Processing pipeline architecture . . . . . . . . . . . . . . . . . . . . . . . 153.3 UI concept for tweet annotation . . . . . . . . . . . . . . . . . . . . . . . 183.4 Punctuation spacing and letter case correction . . . . . . . . . . . . . . . . 203.5 Flesch Reading Ease Score distribution . . . . . . . . . . . . . . . . . . . 213.6 Sentence parse tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.7 Working with Twitter Timelines using additional parameters . . . . . . . . 283.8 Test case example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.1 Statistics of analysed data . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.2 Annotation panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.3 Classification model testing . . . . . . . . . . . . . . . . . . . . . . . . . . 334.4 Classifier accuracy comparison (training data) . . . . . . . . . . . . . . . . 344.5 Number of posts per hour . . . . . . . . . . . . . . . . . . . . . . . . . . . 36

List of tables
3.1 Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2 Search queries used to gather posts from Twitter . . . . . . . . . . . . . . . 153.3 Distance and similarity between two texts . . . . . . . . . . . . . . . . . . 163.4 Posts with quote from the song called "Lips of an Angel" by Hinder. . . . . 173.5 Statistics of data collected from Twitter . . . . . . . . . . . . . . . . . . . 173.6 Frequent tokens for positive and negative classes. . . . . . . . . . . . . . . 193.7 Frequent acronyms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.8 Part of the day distribution . . . . . . . . . . . . . . . . . . . . . . . . . . 223.9 Semantic classes and theirs popular members . . . . . . . . . . . . . . . . 24
4.1 Classification testing results . . . . . . . . . . . . . . . . . . . . . . . . . 344.2 Confusion matrices for different classifiers . . . . . . . . . . . . . . . . . . 354.3 MNB classification errors . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.4 Part of the day distribution . . . . . . . . . . . . . . . . . . . . . . . . . . 364.5 Sentiment polarity distribution . . . . . . . . . . . . . . . . . . . . . . . . 37

Chapter 1
Introduction and motivation
1.1 Motivation
Schizophrenia is a complex mental disorder identified by various kinds of symptoms involvingmany aspects of cognition and emotion [1]. It affects around 1 in every 100 people at somepoint in their life [2], and costs society £11.8 billion a year, but this could be reduced byinvesting in prevention and effective care [3].
Psychologists distinguish positive and negative features of schizophrenia. Positive symp-toms are abnormal by their presence and respond to treatment. They include hallucinations,delusions and incoherence of speech. Negative are abnormal by their absence and includesocial withdrawal, flattening of affect, poverty of action, and poverty of speech [4].
Hallucinations are prominent among the core symptoms of schizophrenia. Psychologistsdefine them as false perceptions that affect people’s senses and cause them to hear (auditory),see (visual), feel (bodily), taste (gustatory) or smell (olfactory) what others do not [5].
The most common hallucination in schizophrenia is "hearing voices" [6]. Numerous sur-veys have shown that up to 15% of general population will experience auditory hallucinationsover the course of their life [3, 7].
Social media platforms like Twitter are popular places to share personal opinions andthoughts using short posts (up to 140 characters). Social activity on Twitter reaches 500million posts per day and 288 million monthly active users [8]. Many users use Twitter toexpress their emotions, describe behaviour and experience [9], which makes it a suitablesource of data to analyse.

2 Introduction and motivation
1.2 Aim and objectives
The aim of this project is to develop a computational framework which will automaticallycollect data from Twitter and allow psychologists to analyse and investigate mental illnesseslike schizophrenia and their symptoms. The project will focus on detecting whether the givenpost is about real hallucination experience or not.
This aim could be split into multiple objectives:
Objective 1 Automatically collect posts from Twitter for a given search query and storethem into a database.
Objective 2 Filter and preprocess the collected posts for further analysis.
Objective 3 Design and build a web application where users can annotate posts, browsedata and see the associated statistics.
Objective 4 Implement various feature extraction algorithms that would extract descriptiveinformation from the text such as statistical, lexical, syntactic and semantic features.
Objective 5 Implement a probabilistic classifier that identifies posts with a real hallucinationexperience.
Objective 6 Provide an environment for testing and evaluating the classifier.
1.3 Report structure
This report has been broken down into 5 chapters. In Chapter 2 we will discuss the back-ground knowledge required and different techniques used in the project along with the relatedwork.
The Development chapter describes how the system was designed and how this designwas implemented.
Then, in Results and evaluation chapter, we will provide what we have achieved and de-scribe various experimentations conducted. In addition, we will discuss several observationswhich we have explored during the data analysis.
Finally, we will discuss how well the project has been managed and propose suggestionsof future work which could be done.

Chapter 2
Background
2.1 Twitter as an information source
Twitter is a popular social networking and microblogging service where users can share briefmessages restricted to 140 characters in length called tweets.
Apart from sharing tweets to followers, there are two additional ways of user interaction:mentions and retweets. Retweet is a primary way of sharing other users’ opinions and thoughtsand act as endorsement. Mentions are used to address a specific person or organisation in thepost. In the text user-mentions are written as @ followed by username. Although there is abuilt-in functionality provided to make a retweet, many users do implicit retweets manuallyusing special markers (i.e "RT @author") or simply re-post almost the same content [10].
To add additional context and metadata to tweet, hashtags are used and described by #followed by a word or topic. Users also are using hashtags to add sentiment such as #scaryor #love [11]. Twitter also provide geotagging feature to add even more context to tweets.Users could optionally share theirs geographical location when posting a new message orspecify their location in the profile [12].
2.1.1 Twitter API
To access this information Twitter provides different application programming interfaces(API) for developers.
Streaming API Using Streaming API developers could access global stream of data andtrack specific users or topics (keywords). This method requires an implementation ofstreaming client which will receive streamed tweets in real-time [13].

4 Background
Search API The Search API is part of Twitter’s REST API. It provides the browsing ofthe recent or popular messages using search queries. Comparing with Streaming API, thisinterface is focused on relevance and not completeness. Its index includes posts from last 6-9days only. Access to this API is restricted to 180 requests/queries per 15 minutes for user. Anapplication can make up to 450 requests/queries per 15 minutes without a user context [14].
2.2 Text mining and natural language processing
Text mining is a computer science field which uses techniques from information retrieval(IR), data mining, machine learning and natural language processing (NLP) to solve theinformation overload problem. It includes preprocessing of documents, entity extraction andrelation modelling, document classification and clustering, sentiment analysis [15].
Natural Language Processing is an area of research concerned with the use of com-puters to understand and manipulate natural language text and speech. There are seveninterdependent levels that people use to extract meaning from the text or spoken language:phonetic level (pronunciation), morphological level, lexical level, syntactic (grammar andstructure), semantic (meaning), discourse level (document structures) and pragmatic level(knowledge from outside of the document). Typical NLP tasks include automatic abstracting(text summarisation), machine translation, named entity recognition, word segmentation andword sense disambiguation [16].
Text mining pipeline In Figure 2.1 we have presented the pipeline that was designedfor "Text Mining the History of Medicine" project in the National Centre for Text Mining(NaCTeM) [17].
raw (unstructured)
text
preprocessing named-entity recognition
part of speechtagging
eventextraction
lexica ontologies
annotated (structured)
text
“I believe the pain was seated in the pillars of the diaphragm as it was chiefly occasioned by hiccough ...”
I believe the pain was seated in the pillars of the diaphragm as it was chiefly occasioned by hiccough Sign of symptom Sign of symptomCausalityAnatomical
Result
Anatomical
Cause
Fig. 2.1 Text mining pipeline

2.2 Text mining and natural language processing 5
2.2.1 Tokenisation and sentence splitting
The process of splitting text into sentences and words or tokens is called tokenisation.Identifying sentence boundaries is the most challenging because this task can not be donesimply by splitting on "." character. Sometimes dot character not only signals the end ofsentence but also could be a part of previous token in different abbreviated forms like Mr.and Dr. [15]. The example of tokenisation process is detailed below (Figure 2.2).
InputHearing voices in my head, seeing & hearing things that aren’t there. It’s scary, Dr.Brown.
Output
1. Hearing voices in my head , seeing & hearing things that are
n’t there .
2. It ’s scary , Dr. Brown .
Fig. 2.2 Text tokenisation example
2.2.2 Word stemming and lemmatisation
Different morphological variants share semantic interpretations and should be treated asequivalent for the most of information retrieval (IR) tasks. To extract root or stem for thegiven word, different stemming algorithms were developed [18].
A stem is the part of the word that never changes, comparing to the lemma which is thebase form of the word (Figure 2.3).
Lemma produced → produce
Stem produced → produc (because there is a words such as production)
Fig. 2.3 Word stem and lemma extraction for "produced".

6 Background
2.2.3 Part-of-Speech tagging
Part-of-speech (POS) tagging is a process of assigning an appropriate part-of-speech tag to agiven word based on the context in which it appears [15]. This is a challenging task becausethe same word could be tagged differently depend on the context as shown in Figure 2.4.
Verb Children like sweets.
Preposition He climbs like a cat.
Noun You won’t see his like again.
Fig. 2.4 Ambiguities in POS tagging. Same word used as different parts of speech.
2.2.4 Spelling correction
In many natural language processing tasks such as spelling correction, it is necessary tomeasure the similarity between two strings to choose candidate corrections for a misspelledword [19].
One of the approaches is to count the minimum number of operations (insertions, dele-tions or substitutions) needed to transform one string into another. It is also called Levenshteindistance after Vladimir Levenshtein, who considered this distance [20]. For example, dis-tance between "notice" and "voices" is 3, since the transformation requires three operationsas described in Figure 2.5.
Deletion notice → noice
Substitution noice → voice
Insertion voice → voices
Fig. 2.5 Word transformation from "notice" to "voices" using three edit operations.
2.2.5 Named-entity recognition
Finding and classifying names in the text is an important sub-task in Information Extraction.Named entities are specific elements in text which belong to corresponding predefinedcategories. The most common examples of categories are persons, locations, organisationsand different numerical entities like date, time and money values.
2.2 Text mining and natural language processing 7
There are several approaches to extract named entities from the text. Grammar-basedsystems require experienced computational linguists and months of work to define specificrules, statistical (i.e. machine-learning) systems typically require a large amount of manuallyannotated training data, and hybrid systems are combination of different approaches [21].
2.2.6 Sentiment analysis
Opinion mining and sentiment analysis systems became popular with high availability ofopinion-rich resources like online review sites. This complex task of identifying "whatpeople think" could be split into two classification problems: subjectivity classification andsentiment polarity classification [22].
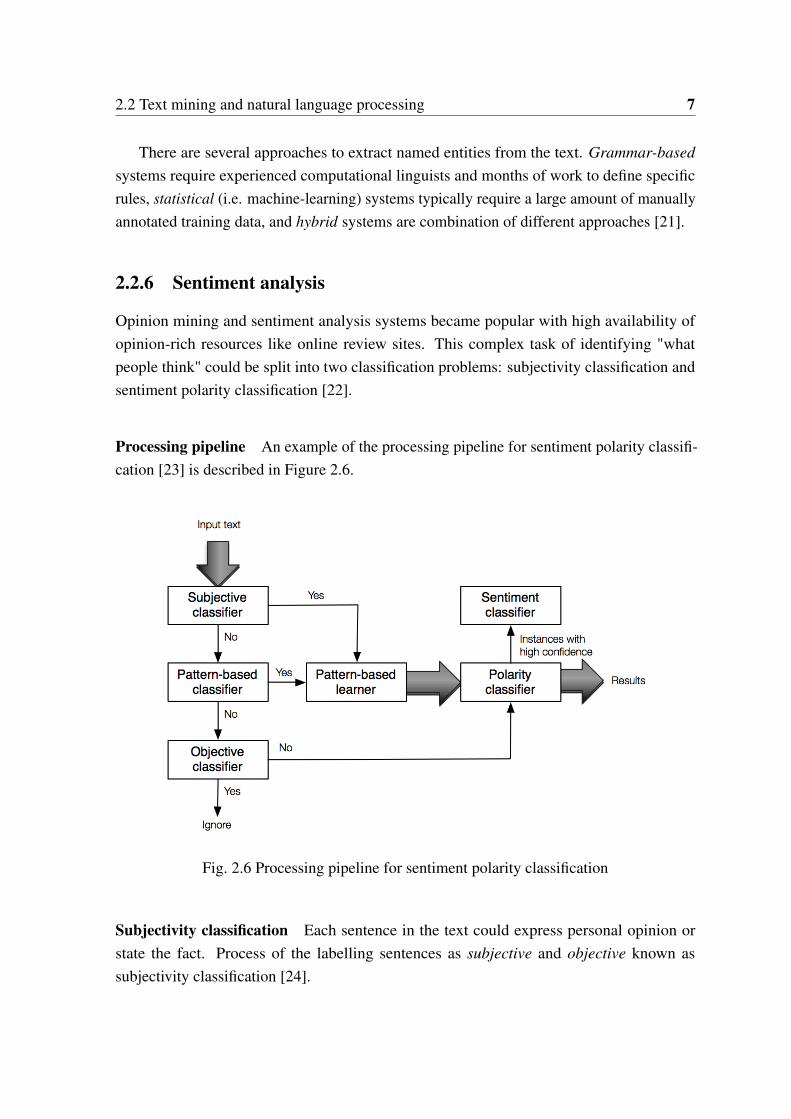
Processing pipeline An example of the processing pipeline for sentiment polarity classifi-cation [23] is described in Figure 2.6.
Fig. 2.6 Processing pipeline for sentiment polarity classification
Subjectivity classification Each sentence in the text could express personal opinion orstate the fact. Process of the labelling sentences as subjective and objective known assubjectivity classification [24].

8 Background
Sentiment polarity classification Having a subjective sentence it is useful to know whichemotion: positive, negative or neutral was expressed. This is a challenging task sincedifferent negation cases must be considered in polarity classification. Negation may be local(e.g., not good), or have distance dependencies (e.g., does not look very good). Moreover,specific phrases could intensify rather than change polarity (e.g., not only good but amazing)[25].
2.3 Machine learning
The field of Machine Learning is a result of intersection of Artificial Intelligence and Statistics,and it focuses on building computer methods that could automatically learn and improvewith experience. Machine learning algorithms are widely used in commercial systems fordata mining, speech recognition and computer vision. [26].
2.3.1 Classification
Classification is a supervised learning task in which machine learning model is trainedon manually annotated or labelled data (training dataset) and then tested again unlabelled(testing) dataset trying to predict a corresponding label based on the experience learned(Figure 2.7). Depending on the number of categories (classes) in which instances should bedistributed, classification could be binary or multi-class.
Prediction
Traininglabel machine
learningalgorithm
input
feature extractor features
input
feature extractor
classifier modelfeatures
label
Fig. 2.7 Classification

2.3 Machine learning 9
Feature extraction
Feature extraction is an important and key part of the classification task. It is a process ofextracting distinctive and informative bits of information (features) from the initial set ofdata to use in the classification.
Advantages of probabilistic classifiers in healthcare
In decision-making tasks related to healthcare, it is important to pass the case on to a humanexpert if classifier is non-confident about the predicted result. Reject option becomes availableonly with probability distribution, comparing with discriminant function, that maps inputs tooutputs directly and where it is impossible to tell anything about the confidence [27].
Naive Bayes classifier
Naive Bayes classification is based on the application of the Bayes’ theorem:
P(A|B) = P(A)×P(B|A)P(B)
with a very naive and unrealistic assumption that all features are stochastically (statistically)independent.
In other words, it assumes that all instances are independent of each other give the contextof a class. Despite the fact that this assumption is definitely false in the most of real lifecases, this approach often produces very good classification results and has been applied inmany research efforts [28]. Naive Bayes classifier (NB) is widely used in text classificationtasks like spam filtering [29].
There are several forms of NB, but multinomial and Bernoulli event models have beensuccessfully used in document classification [30]. In the multivariate Bernoulli event modelthe document is typically considered as a binary feature vector consisting of all words anddoes not capture the information about term frequencies. However the multinomial modelis also considering how many times the term is used in a document. In text categorisationtasks, multivariate Bernoulli performs quite well, especially when set of words used forclassification is small, but it is outperformed by multinomial model on larger vocabularysizes [28, 31].
Maximum entropy classifier
It is a general approach to measure probability distribution from data based on the principlethat when nothing is known, the distribution should be as uniform as possible. Maximum

10 Background
entropy has already been widely used in many natural language processing tasks [32] such aspart-of-speech tagging [33] and text segmentation [34]. In text classification tasks, maximumentropy could estimate the conditional distribution of the class label given a document thatrepresented by a set of word count features. It was shown that maximum entropy is promisingtechnique for text classification [35].
2.3.2 Measuring classifier performance
The overall accuracy of a classifier is measured as a percentage of correctly classified samplesin the testing dataset. There are several methods introduced:
Random sub-sampling
Monte Carlo cross validation is also known as random sub-sampling and performs randomselection of the subset to form the training dataset, then it is using the rest of instances as avalidation data. The random partitioning procedure is repeated multiple times as illustratedon Figure 2.8.
Fig. 2.8 Random subsampling
K-fold cross validation
The dataset is divided into k different samples. Then k−1 subsamples are used to train themodel and the last one is used as the validation data for the testing as shown in Figure 2.9.

2.4 Related work 11
Fig. 2.9 K-fold cross validation
2.4 Related work
Researchers from Microsoft have found that social media platforms like Twitter containuseful information to identify signs of major depression in individuals. They measuredbehavioural attributes related to emotion, social engagement, language and linguistic stylesto build a statistical classifier that could predict the risk of a depression in the future. Theyhave implemented Supporting Vector Machine (SVM) classifier and achieved promisingresults with 70% classification accuracy [9].
Another research was focused on analysing Twitter messages to predict rates of influenza-like illnesses. They have compared multiple regression models to correlate with the statisticsreported by the Centers for Disease Control and Prevention (CDC) and achieved the bestcorrelation of .78 using simple bag-of-words classifier to filter erroneous document matches[36].
The most recent research paper related to schizophrenia and Twitter was focused onanalysing attitudes towards depression and schizophrenia on Twitter. They have collectedmessages with hashtags such as #depression or #schizophrenia and found that the majority ofposts about schizophrenia were aimed to increase awareness of this mental illness (51%, 232tweets). More than one hundred messages were describing personal opinions or experiences(22%, 101 tweets) [37].
2.5 Summary
In this chapter we have discussed required background knowledge and techniques used in thecurrent project. Also the related researches were presented to take into consideration otherapproaches and results while doing this project.

Chapter 3
Development
3.1 Requirements
It is helpful to break the objectives defined in Section 1.2 into the set of requirements. Severalinterviews with our experts were conducted to define the list of requirements. We havealso assigned priority (low, medium and high) and complexity (easy, medium, hard andchallenging) for each requirement (Table 3.1).
Table 3.1 Requirements
Objective Requirement Priority Complexity1 Produce and schedule data collection script which
collect posts from Twitter.High Medium
1 Store results in the project database to have an abilityto process them later.
High Easy
2 Design and implement algorithms to filter the dupli-cates.
High Medium
2 Implement different preprocessing routines such asTwitter-specific object removal, error correction andtransformation of acronyms.
Medium Challenging
3 Develop a user authentication functionality Medium Medium3 Build an annotation tool with labelling and highlight-
ing.High Challenging
3 Develop a functionality to browse and search amongcollected data.
Low Medium
Continued on next page

3.2 Design 13
Table 3.1 – continued from previous pageObjective Requirement Priority Complexity3 Develop a functionality to display an aggregated data
statistics and insights.Medium Hard
4 Statistical feature extraction such as number of words,sentences, characters.
Medium Easy
4 Lexical feature extraction such as number of differentpart-of-speech tags.
Medium Medium
4 Analyse parse tree to extract informative features. Medium Challenging4 Detection of various semantic classes and named
entity recognition, sentiment polarity identification.High Challenging
5 Implement Naive Bayes classification. High Easy5 Implement MaxEnt classification. Medium Easy6 Design a classifier testing environment High Medium6 Display classification errors (misclassified instances). Medium Medium6 Implement a classifier evaluation environment to run
multiple experiments and display results and overallaccuracy.
Low Medium
3.2 Design
In this section the architecture of the system and how its components were designed will bediscussed.
3.2.1 System architecture
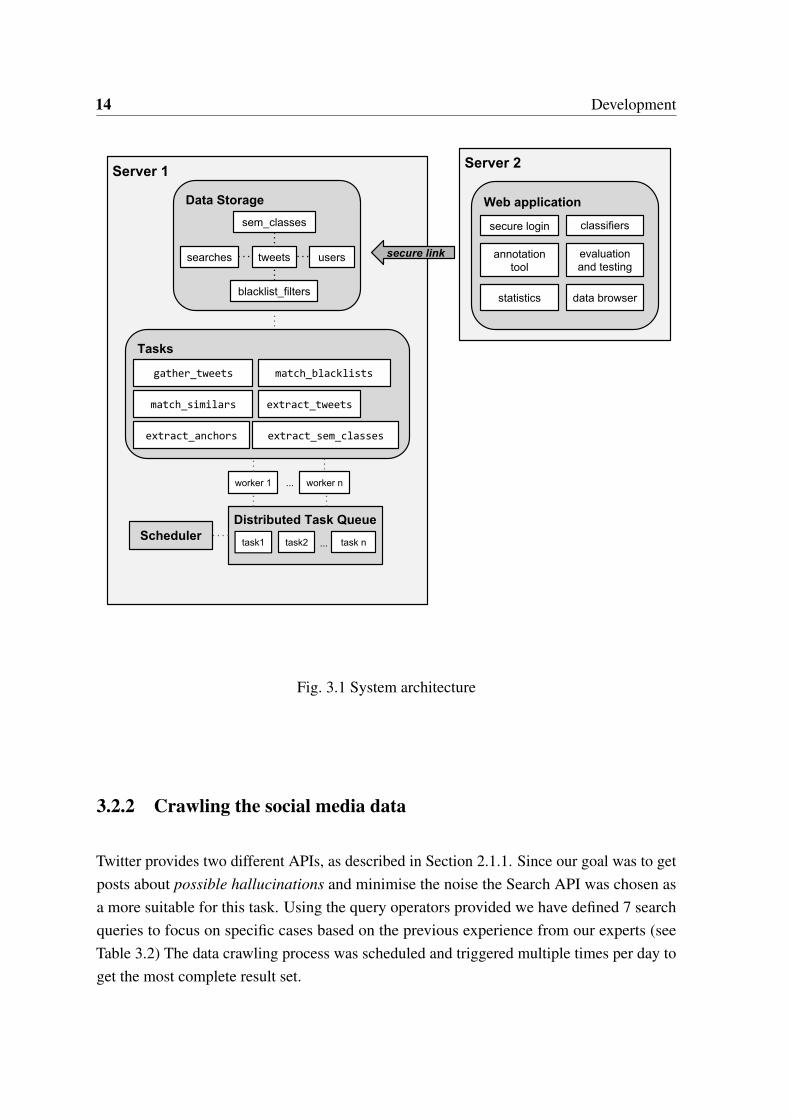
We have decided to divide our system into two different servers (Figure 3.1). Server 1 isresponsible for data crawling, storage and analysing. The second server is for a front-endweb application only, where the experts can annotate data, see statistics and test classifiers.Web application communicates through a secure link to write and read data only.
14 Development
Server 1
Data Storage
tweets
sem_classes
searches
blacklist_filters
users
Tasks
SchedulerDistributed Task Queue
task1 task2 task n...
Server 2
Web application
secure login
annotation tool
statistics
evaluation and testing
data browser
classifiers
secure link
worker nworker 1 ...
Fig. 3.1 System architecture
3.2.2 Crawling the social media data
Twitter provides two different APIs, as described in Section 2.1.1. Since our goal was to getposts about possible hallucinations and minimise the noise the Search API was chosen asa more suitable for this task. Using the query operators provided we have defined 7 searchqueries to focus on specific cases based on the previous experience from our experts (seeTable 3.2) The data crawling process was scheduled and triggered multiple times per day toget the most complete result set.

3.2 Design 15
Search query
(hear OR hearing) (voice OR voices) (god OR angel OR allah OR spirit OR soul OR "holyspirit")hallucinating hearing(hear OR hearing) ("other people" OR "other ppls" OR "other ppl") thoughts(voice OR voices) (commenting OR criticising) (scary OR frightening OR "everything Ido")hearing scary things "in my head"(hear OR hearing) (voice OR voices) (scary OR devil OR demon OR daemon OR djinnOR jinn OR evil OR "evil spirit")("hear things" OR "hearing things") "in my head"
Table 3.2 Search queries used to gather posts from Twitter
3.2.3 Processing pipeline
We have designed a processing pipeline that takes tweet as input and output the result. Noticethat output is not just the classification result. During the passage through the pipeline,different additional context were added to the tweet such as extracted information andpredicted class.
Pipeline consists of four essential steps: filtering, preprocessing, feature extraction andclassification. Each step or module contains different components, and the anchor detectionshould be treated as sub-module of feature extraction, since it does feature extraction fromdetected anchor rather than from the whole text.
FilteringSimilarity matching
Blacklist filtering
PreprocessingTwitter-specific
objects removal
Acronyms and interjections
transformation
Acronym and interjection
transformation
Spelling, letter-case and
punctuation correction
Feature ExtractionSemantic classes POS tags
Part of the day Sentiment polarity
Named entities
Readability score
Anchor detection
Sentiment polarity
Named entities POS tags Semantic
classes
Classification
input tweet
output
Fig. 3.2 Processing pipeline architecture
3.2.4 Filtering
Even though we have defined specific search queries, the gathered dataset still included alot of noise such as famous quotes, song lyrics and re-postings of someone else’s opinions(Tables 3.3, 3.4). To filter them out two different approaches were introduced.

16 Development
Duplicates matching The first approach is to find duplicates for the specific post. Twoposts are marked as duplicates if the similarity ratio between them is greater than specifiedthreshold.
To measure the difference between two posts, a string metric called Levenshtein distanceis used. Similarity ratio calculated by formula: sim = lensum−lsdist
lensum , where lensum - sum ofthe lengths of both strings and ldist - calculated Levenshtein distance. The example of twosimilar textsy is described in Table 3.3.
TextLevenshtein
distanceSimilarity
ratio
Don’t get so comfortable in life that you can’t hear the voiceof God when it is time to move to a new opportunity. Have ablessed day 39 0.8244Do not get so comfortable in your life where you can’t hear thevoice of God when it is time to move on to new opportunities
Table 3.3 Distance and similarity between two texts
Similarity threshold with the value of 0.85 has been identified empirically as the mostsuitable and everything above this value was marked as duplicates and excluded.
Blacklists We have spotted several groups of similar posts in the collected data. Therefore,to improve filtering performance, it was useful to define a specific rule or matching criteriafor this seed set of tweets.
Several examples of posts with quote from the same song are listed in Table 3.4. Subse-quence "coming from lips of angel" appears to be an optimal to filter this quote from thecollected data.
To determine whether the subsequence is found in the text, the longest common subse-quence (LCS) of them is extracted. If it is similar to the subsequence or to the text with 0.95ratio or over, the post is marked as a duplicate and excluded (blacklisted).
This approach aimed at improving overall filtering speed, since it outperforms pairwiseduplicate matching when dataset contain large groups of duplicates.

3.2 Design 17
Text
It’s really good to hear your voice saying my name, It sounds so sweet. Coming from thelips of an angel, Hearing those words it makes me weakComing from the lips of an angel hearing your voice it makes me weakI just wanna hear your voice Saying my name it sounds so sweet Coming from the lipsof an angel Hearing those words it makes me weakIts really good to hear your voice say my name, it sounds so sweet, comin from the lipsof an angel hearing those words it makes me weakIt’s really good to hear your voice saying my name it sounds so sweet. Coming from thelips of angel, hearing those words it makes me weakit’s really good to hear your voice saying my name, it sounds so sweet. coming from lipsof an angel, hearing those words it makes me weak
Table 3.4 Posts with quote from the song called "Lips of an Angel" by Hinder.
In Table 3.5 we have listed the statistics of the collected social data. All further analysishas been done on unique posts only.
Total number of Twitter posts 30,648Total number of users 25,069Average number of posts per user 1.223Total number of unique posts 4,994Total number of users 4,767Average number of unique posts per user 1.048
Table 3.5 Statistics of data collected from Twitter and unique data left after the filtering.
3.2.5 Annotation
To build training dataset for the classifier, our experts have to manually annotate tweets. Inorder to make this process easier the special annotation tool has been designed.
During annotation the experts choose an appropriate class: positive, negative or unsure(to skip the instance). To explain their decision, specific words (or tokens) the expert need toclick on words to highlight it as shown on Figure 3.3.

18 Development
I haven't slept for like 4 days and I started hallucinating yesterday. I am hearing things and I can’t sleep negative
positive
unsure
Fig. 3.3 UI concept for tweet annotation
Highlighted annotation tokens will be used for further analysis (Section 3.2.6).
Annotation guidelines
Guidelines were provided in order to make the annotated data consistent and increaseeffectiveness of the analysis. We have listed several examples below.
Positive examples In Example 1 the person is probably experiencing auditory and tactilehallucinations (saying that "people were touching me" and "kept hearing voices"). The causeof a hallucinations could be the last night tiredness.
(1) Was so tired last night that I started hallucinating and it felt like people weretouching me and I kept hearing voices lol wtf
Another person in Example 2 classified voices as "scary" and in addition to auditory hallu-cination there is an example of another symptom of schizophrenia called delusion (whensomebody thinks that other people can read or control somebody’s mind).
(2) I didn’t know the address of the place and I kept hearing scary voices in my headand it was reading my mind and holy sh*t it was scary
Negative examples On the other hand if people are saying that they are hearing scaryvoices does not always mean that it is something wrong. It could be a sound coming fromTV speakers while somebody is watching a movie (example 3) or a noise from another roomwhich could be misclassified as auditory hallucinations (example 4).
(3) My mom is watching Deliver us From Evil and I’m hearing this weird highpitched voice and I want Eric Bana to hold me.
(4) So I was convinced I was hearing stuff. Like it’s so funny because the noise wascoming from another room but I legit thought I was hallucinating.

3.2 Design 19
3.2.6 Analysis
To investigate what characterise positive and negative categories we have analysed the tokenshighlighted during the annotation. The most frequent examples are shown in Table 3.6.
Category Frequent tokens
Positive hallucinating, scary(-ed), sleep, myhead, TV, things, home, night, crazy,f*cking, echoes, alone, kids, my mind,evil, office, nephew, apartment, an-tipsychotic, parents, husband, weird,noise(-es), dog bark, paralysis, in-sane, demon, whispering, footsteps,exhaustion, meds
Negative your voice, my [own] voice, phone,called, Ed Sheeran, mother (mom,mum), song, sound, sing, home,god, night, Sam, girlfriend, evil,Zayn, baby, opinions (thoughts),daughter, grandmother, movies, Sally,grandmother (grandma), Beyonce,psalm, TV, voicemail(-s), Kanye, ra-dio, record(-er), speaker, FaceTime,father (dad, daddy), people
Table 3.6 Frequent tokens for positive and negative classes.
3.2.7 Preprocessing
As mentioned before, posts in Twitter are brief and short therefore every single bit ofinformation is important. Since most of messages has spelling and punctuation mistakes,abbreviations and different Internet slang. This step is required to prepare text for furtherprocessing.
Twitter/online-specific objects removal During this step, all Twitter/online-specific ob-jects like retweet shorthands, URLs, hashtags (#), user mentions (@) and unicode emoticons

20 Development
must be removed. All named and numeric character references should be converted to thecorresponding unicode characters ("→ ”).
Acronyms and interjections transformation To transform acronyms, we have collectedour own dictionary based on data from two public dictionaries [38, 39]. We have used andextended Dictionary of interjections [40] to replace interjections like "yay" and "phew".
The most frequent acronyms among collected data are listed in Table 3.7.
Acronym Value Acronym Value
u you rn right nowur your idk i don’t known in, and bc becauseomg, omfg Oh my God aka also known aslol laughing out loud y whyppl people lmao laughing my ass offya you stfu shut the f*ck upwtf what the f*ck lil littlethx thanks em thempls, plz please
Table 3.7 Frequent acronyms among collected data
Punctuation spacing and letter case correction The rule-based approach is used to splittext into tokens and then join them back correcting letter case and adding required spacesbased on basic punctuation rules (Figure 3.4).
Original my grammy and papa are life,hearing their voices was exactly what i needed.things are looking up ... thank you God .
Corrected My grammy and papa are life, hearing their voices was exactly what I needed.Things are looking up... Thank you God.
Fig. 3.4 Example of punctuation spacing and letter case correction.
Spelling correction For all non-standard words, the list of similar words (suggestions) isextracted. Then the best replacement candidate based on the calculated edit distance betweenthe mistaken word and the replacement. We have observed and identified that minimumdistance value of 3 works well with this kind of data which allows to substitute, insert ordelete up to three characters to transform one word into another.

3.2 Design 21
Capitalisation of proper nouns Since the letter case is not considered in the majority ofposts, the writing of potential proper nouns must be transformed to title case.
All words marked as spelling mistakes but tagged as proper noun, proper noun + pos-sessive or determiner [41] are classified as potential proper nouns in addition to all otherproper nouns. This transformation aimed at improving named entity recognition described inSection 3.2.8.
3.2.8 Feature extraction
To perform the classification task, we need to extract informative data (features) from theposts.
Spelling mistakes and use of specific language
Number of corrections and transformations which we have done during the preprocessingstep is counted.
We have also calculated multiple readability scores based on formulas most commonlyused in health care [42]. Distribution of Flesch Reading Ease Score among all unique postsand plain-text posts (without hashtags, URLs and mentions) is illustrated in Figure 3.5 (0 -very confusing, 100 - very easy).
0-29 30-49 50-59 60-69 70-79 80-89 90-1000
200
400
600
800
1,000
1,2001,068
1,174
857
542
237
143
25
520509
374
200
77462
Flesch Reading Ease Score
Num
bero
fpos
ts
all posts plain text posts
Fig. 3.5 Flesch Reading Ease Score distribution.
22 Development
This metrics aimed at finding some patterns in the use of specific language and grammar.
Part of the day
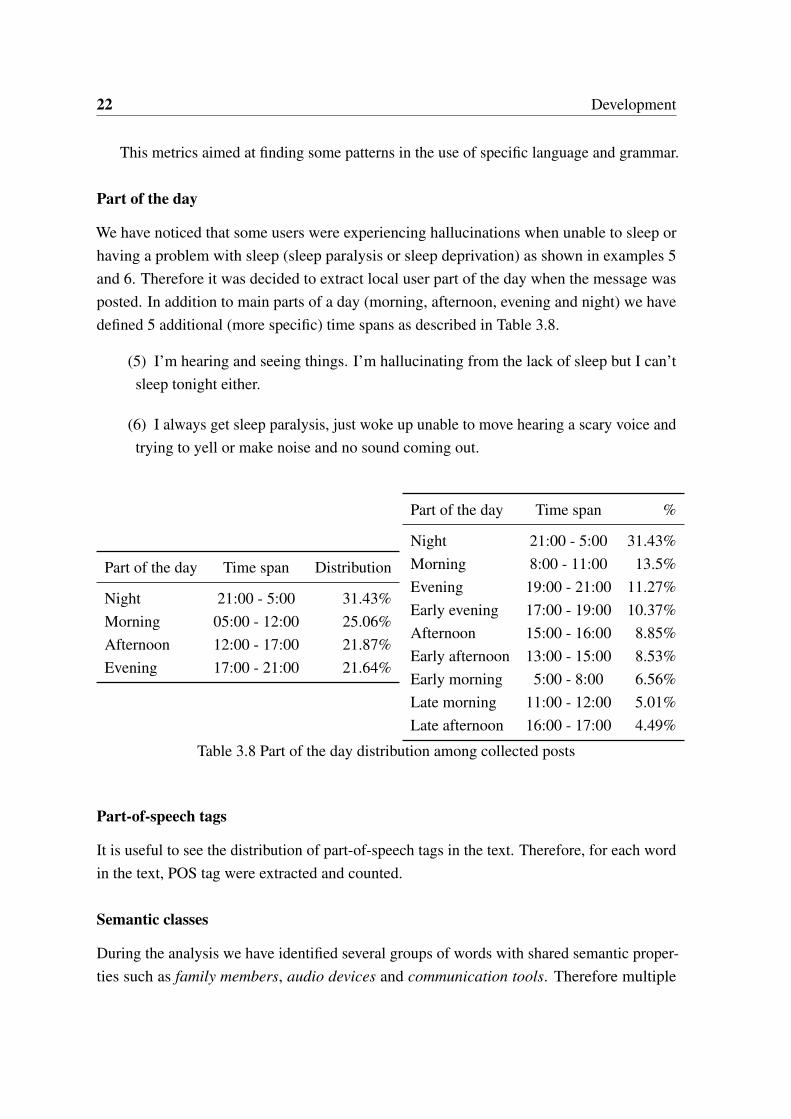
We have noticed that some users were experiencing hallucinations when unable to sleep orhaving a problem with sleep (sleep paralysis or sleep deprivation) as shown in examples 5and 6. Therefore it was decided to extract local user part of the day when the message wasposted. In addition to main parts of a day (morning, afternoon, evening and night) we havedefined 5 additional (more specific) time spans as described in Table 3.8.
(5) I’m hearing and seeing things. I’m hallucinating from the lack of sleep but I can’tsleep tonight either.
(6) I always get sleep paralysis, just woke up unable to move hearing a scary voice andtrying to yell or make noise and no sound coming out.
Part of the day Time span Distribution
Night 21:00 - 5:00 31.43%Morning 05:00 - 12:00 25.06%Afternoon 12:00 - 17:00 21.87%Evening 17:00 - 21:00 21.64%
Part of the day Time span %
Night 21:00 - 5:00 31.43%Morning 8:00 - 11:00 13.5%Evening 19:00 - 21:00 11.27%Early evening 17:00 - 19:00 10.37%Afternoon 15:00 - 16:00 8.85%Early afternoon 13:00 - 15:00 8.53%Early morning 5:00 - 8:00 6.56%Late morning 11:00 - 12:00 5.01%Late afternoon 16:00 - 17:00 4.49%
Table 3.8 Part of the day distribution among collected posts
Part-of-speech tags
It is useful to see the distribution of part-of-speech tags in the text. Therefore, for each wordin the text, POS tag were extracted and counted.
Semantic classes
During the analysis we have identified several groups of words with shared semantic proper-ties such as family members, audio devices and communication tools. Therefore multiple

3.2 Design 23
semantic classes were defined as listed in Table 3.9. We have counted the number of mentionsof different semantic classes in the text, to have a rough understanding about its relevance tothe topic.

24 Development
Semantic class Popular members
Negative supernatural evil, devil, demon, satan, evil spirit, djinn,daemon
Relative baby, mom, son, father, friends, child,children, brother, friend, sister, husband,dad, wife, mother, parents, grandma, fam-ily, daddy, uncle, mum, mate, grand-mother, roommate, ex, nephew, neigh-bours, god daughter
Bad/swear word f*cking, shit, f*ck, hell, god damn, ass,damn, bitch, sex, nigga, dick
Fear expression scary, scared, creepy, afraid, terrifying,nervous, shocked, anxious
Religious term Jesus, prayer, Allah, Bible, pastor, church,Christ, psalm, Christian, prophet, Quran,sabbath
Media & applications song, music, video, YouTube, album,movie, audio, Vine, chorus, Siri
Supernatural spirit, Holy SpiritPossible hallucination in my head, in my mind, echoes, seeing
thingsProperty home, room, house, living room, kitchen,
apartment, office, library, hall, attic, toi-let
Audio device radio, TV (television), speaker, head-phones, laptop
Communication tool phoneRecording recording, record, voicemail (voice mail),
voice message, voice memoMentally strange crazy, insane, mad, paranoid, irrational
Table 3.9 Semantic classes and theirs popular members

3.2 Design 25
Named entities
Annotation tokens analysis shown that many posts have mentions of different celebrities andlocations (Example 7). We have counted occurrences of different types of named entities inthe text such as locations, persons and organisations.
(7) I can’t wait to hear Louis’ angel voice live in Cardiff!!!
Sentiment polarity
Using the processing pipeline design which was described in Figure 2.6 (Section 2.2.6), thesentiment polarity classification was implemented and used as classification feature.
Anchors
Since the most interesting information is what is exactly heard in the post, the anchorswere introduced. Anchors are specific elements in the text which provide clues that relevantinformation should be found nearby. We have listed several examples of anchors below.
(8) Thank god I’m not hearing their voices in my head.
(9) Hearing Moroccans with a deep voice speak Arabic oh my god.
(10) It’s really good to hear my little angel’s voice again.
(11) I swear I hear footsteps and voices from upstairs in the attic all the time... ei-ther there are strangers in our attic, or some spirit friends.
Anchor extraction pipeline consist of three steps: Firstly parsing tree matching is appliedand if it fails then inline matching is used. When anchor is extracted it also looks for negationbefore the anchor as described in Example 8.
Parsing tree matching For each sentence in the text, we generated the parse tree (Figure3.6), which then is being searched for a clue (target node). In our case, we described thisnode as a verb phrase (VP) with the stemmed verb "hear". Having found the subtree with atarget token in the root, each node is being analysed ignoring subordinate clauses, verb andadverb phrases inside. Each leaf in the subtree is saved until a finish node is found whichcan be described as any noun or pronoun in our case. The finish node is also saved into ananchor value.

26 Development
S
VP
S
VP
VP
ADVP
RB
again
NP
NN
voice
NP
POS
’s
NN
angel
JJ
little
PRP$
my
VB
hear
TO
to
ADJP
JJ
good
RB
really
VBZ
’s
NP
PRP
It
Fig. 3.6 Sentence parse tree for "It’s really good to hear my little angel’s voice again."
Inline matching When it is impossible to get valid parse tree, then inline matching isapplied. Firstly, the given sentence is tokenised. Then starting from the target token, eachsucceeding word is extracted until finish token is found or the end of sentence is matched.We describe a target token as a stemmed verb "hear" and a finish token as any noun (properand common), determiner, pre- or postposition and adjective.
Negation detection To detect whether extracted anchor was negated, a naive negationdetection was implemented. All the tokens preceding the anchor are checked for negation("not", "no", "but", "cannot" and "’t") and added to the beginning of the anchor (Example 8).
Analysis In addition to the whole tweet, each anchor is analysed and distinctive informationis extracted such as semantic classes, named entities and sentiment polarity. Also for eachword in the anchor, part-of-speech tag is determined.
Dictionary-based detection of the own voice was introduced to detect those cases whenpersons are hearing their own voice on videos or other recordings as described in Example12.
(12) I hear my voice in videos and hope to god I don’t actually sound like that

3.3 Implementation 27
3.2.9 Classification of posts
To classify collected posts into two different categories (positive and negative), it was decidedto implement Naive Bayes classifier, and compare its performance with the MaximumEntropy classifier.
We have also provided the testing and evaluation environment which automatically runsmultiple experiments for the specified dataset to evaluate different classification algorithmsand review the misclassified examples.
3.3 Implementation
3.3.1 Technologies used
Python was used as the primary programming language for this project because it is ahigh-level and well suited for prototyping.
As a main data storage, we have chosen MongoDB because it is non-relational, document-based which makes it ideal for storing JSON (JavaScript Object Notation) responses fromTwitter API since document-based databases are designed to store this kind of data efficiently[43].
To schedule our crawling and text mining tasks and gain the maximum performancewe have used asynchronous distributed task queue which is called Celery. Using multipleworkers that process the task queue in parallel, we have decreased the time required toanalyse the large amount of data.
We have used Django, a high-level web framework which is also written in Python, thatallows us to rapidly deliver the web application for our experts [44].
3.3.2 Data collection
To communicate with the Twitter API Python library Tweepy was used. Using since_id andmax_id parameters provided [45] we have managed to minimise the amount of redundantdata we fetch and process only new Tweets which have been added since the last time theresults were processed (Figure 3.7).

28 Development
Fig. 3.7 Working with Twitter Timelines using additional parameters
User’s local time determination
Twitter API returns all timestamps in Coordinated Universal Time (UTC) therefore we havedeveloped an algorithm which determines user local timestamp based on the geographicallocation assigned to the post and user location defined in the profile. To get local time forspecific geographic location Google Timezone API [46] was used.
3.3.3 Text mining and natural language processing tools
To analyse the text and work with natural language processing routines we have used aNatural Language Toolkit (NLTK) [47].
Stanford NLP tools
The Stanford NLP Group have developed several natural language processing tools and madethem available for everyone. Although all of them are written in Java, the NLTK providesmultiple interfaces that allow us to easily integrate them into our project.
We have used Stanford Parser [48] to generate parse trees for the text. Different typesof named entities were extracted using Stanford Named Entity Recognizer [49] with 3-classmodel to identify locations, persons and organisations in the text.

3.3 Implementation 29
Part-of-speech tagging
For each word in the post the part-of-speech tag is extracted using TweetNLP tagger [50]developed in Carnegie Melon University. This tagger aimed to produce better results onsocial media data than Stanford POS tagger [51] and MaxEnt Treebank POS tagger [33]since it was trained on texts from Twitter and introduces additional POS tags, emoticonsdetection, better tokenization and proper noun recognition [52].
Word stemming
To get the word base or root form we have used NLTK port of the Snowball stemmersdeveloped by Martin Porter [53].
Sentiment polarity detection
To identify which emotion: positive or negative was expressed in the post we have improvedthe implementation of an unsupervised sentiment classifier [23] which was originally usedfor an opinion retrieval and mining system [54] and for improving one-class collaborativefiltering [55].
During the testing we have noticed that existent implementation does not consider thepart-of-speech of a word when calculating its prior polarity. For example, when the word"pretty" is an adjective it has positive prior polarity as described in Example 13. On otherhand the same word can have neutral prior polarity when it is an adverb and should not affectpositively on the whole sentence polarity (Example 14).
(13) I have met a pretty girl today.
(14) I hear voices and it is pretty scary.
Therefore we have improved algorithm for polarity calculation taking this into account.Also to make classification process more accurate we have also added Stanford POS tagger[51] support which turned up more reliable than originally implemented sequential taggerwhich use three classifiers in sequential order (Unigram, Bigram and Trigram) and was trainedon Brown Corpus of English text [56]. Although TweetNLP tagger shown better resultson social media data (Section 3.3.3), the Stanford tagger better integrates into the existentsentiment polarity classification pipeline since both of them use Penn Treebank POS tag set.

30 Development
3.3.4 Machine learning
We have used Python module for machine learning scikit-learn which provides an imple-mentation of Naive Bayes classifier for multinomial and multivariate Bernoulli models [57].Maximum entropy model was implemented using classifier provided with NLTK.
3.4 Regression testing
Tasks such as an anchor extraction and punctuation correction were aimed to improve thequality of classification features and, as a result, boost the classifier performance. Boththese algorithms were continuously changing during the training of the classification model.Therefore regression tests were introduced to make sure that aforementioned algorithms workproperly and stable.
We have chosen the most tricky cases and then defined the test set for each task as a"table" with an input text and expected output. The example of the test case used to testan anchor extraction is shown in Figure 3.8. All testing processes were implemented usingPython unit testing framework [58].
Input"How can you leave a church cause you hear the voice of God?" Well I say "How canyou NOT hear the voice of God and stay at a church?"
Expected output
1. hear the voice of God
2. NOT hear the voice of God
Fig. 3.8 Test case example

Chapter 4
Results and evaluation
This chapter represents the final results achieved along with evaluation of outcomes.
4.1 Results
Figure 4.1 illustrates the aggregated statistics of extracted information such as part of theday distribution, different named entities, distribution of semantic classes and their frequentmembers represented with a word cloud.
Fig. 4.1 Statistics of analysed data
32 Results and evaluation
The designed annotation panel is shown in Figure 4.2. According to the feedbackreceived from our experts, they found this annotation tool more convenient and easy to usethan annotating using different spreadsheet applications. Also they have noticed that it takesless time to annotate tweets which allows them to annotate more tweets.
Fig. 4.2 Annotation panel
Figure 4.3 illustrates testing results for a given classifier and data set. We have foundthis testing environment helpful since it provides the most important features along withclassification errors and simplifies the training of a classification model.

4.2 Experiments 33
Fig. 4.3 Classification model testing
4.2 Experiments
We experimented with two standard machine learning algorithms: Naive Bayes classificationand maximum entropy classification (MaxEnt). Also two different event models of NaiveBayes: multinomial (MNB) and multi-variate Bernoulli (BNB) were compared.
During the training we have used random sub-sampling to split our data (50 positiveexamples, 151 negative examples) into training and testing sets and run 10 experiments. Weachieved almost equal accuracy for different NB event-models: MNB (avg. 90.84%), BNB(avg. 90.56%), and slightly less with the maximum entropy model: MaxEnt (avg. 88.22%)as shown in the Figure 4.4.
Weak features Several statistical features such as message length, number of words andsentences did not appear to be good classification features most likely because of the briefmessage format. Any of the readability scores calculated has not improved classification too.

34 Results and evaluation
1 2 3 4 5 6 7 8 9 1075
80
85
90
95
Experiment number
Acc
urac
y%
BNBMNB
MaxEnt
Fig. 4.4 Classifier accuracy comparison on the training data
Strong (most important) features Number of pronouns, proper nouns, nominal + verbalphrases (i.e. i’m) in the text turned up into a good classification features. We have alsoidentified that mentions of semantic classes such as fear expression, possible hallucination,property, audio device and mentally strange are important features too. Use of named entitiesespecially persons were appeared to be a distinctive feature either in the anchor or anywherein the text. Also sentiment polarity, number of spelling mistakes and abbreviations alsohelped to classify posts correctly.
Validation
To estimate how good our classification model has been trained we have collected a testset, which consist of 137 previously unseen instances (24 positive examples, 113 negativeexamples). The results are shown that Naive Bayes (both models) performed better thanMaximum Entropy model (Tables 4.1, 4.2). We have achieved the best performance with theMultinomial Naive Bayes classifier during the training and testing.
Classifier Precision Recall F1 score Accuracy
BNB 74.07% 83.33% 0.78 91.97%MNB 79.17% 79.17% 0.79 92.7%MaxEnt 72.73% 66.67% 0.70 89.78%
Table 4.1 Classification testing results
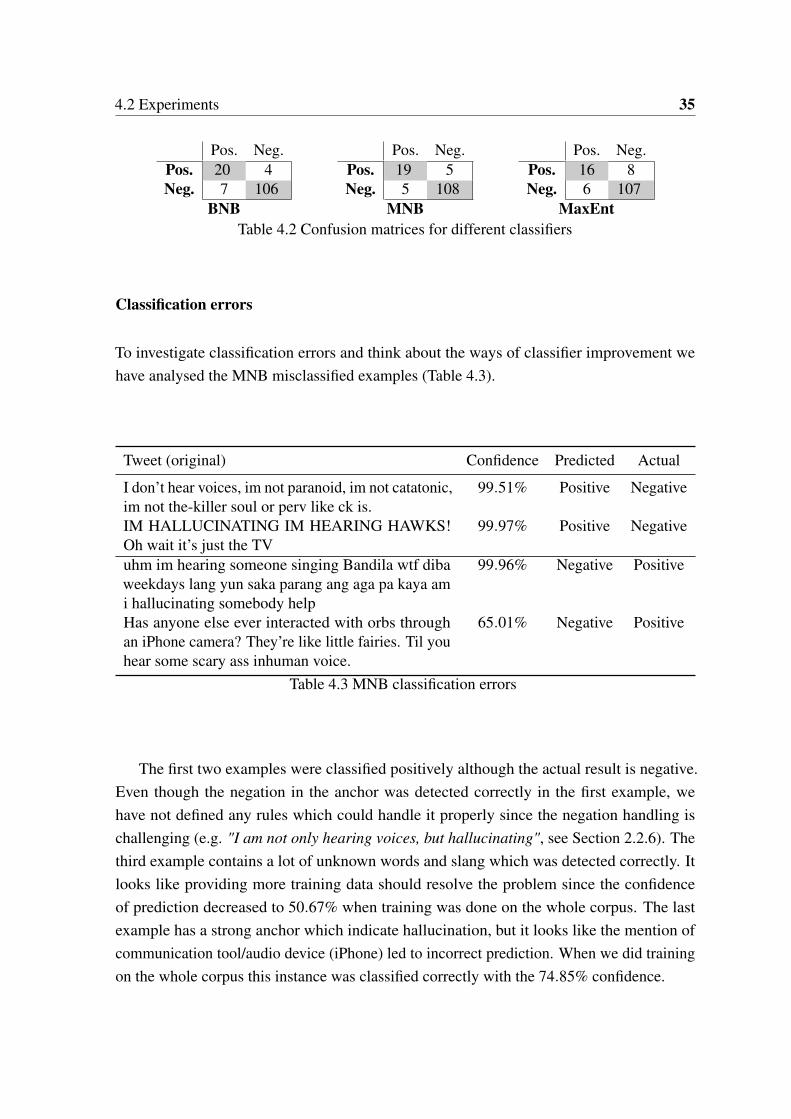
4.2 Experiments 35
Pos. Neg.Pos. 20 4Neg. 7 106
BNB
Pos. Neg.Pos. 19 5Neg. 5 108
MNB
Pos. Neg.Pos. 16 8Neg. 6 107
MaxEntTable 4.2 Confusion matrices for different classifiers
Classification errors
To investigate classification errors and think about the ways of classifier improvement wehave analysed the MNB misclassified examples (Table 4.3).
Tweet (original) Confidence Predicted Actual
I don’t hear voices, im not paranoid, im not catatonic,im not the-killer soul or perv like ck is.
99.51% Positive Negative
IM HALLUCINATING IM HEARING HAWKS!Oh wait it’s just the TV
99.97% Positive Negative
uhm im hearing someone singing Bandila wtf dibaweekdays lang yun saka parang ang aga pa kaya ami hallucinating somebody help
99.96% Negative Positive
Has anyone else ever interacted with orbs throughan iPhone camera? They’re like little fairies. Til youhear some scary ass inhuman voice.
65.01% Negative Positive
Table 4.3 MNB classification errors
The first two examples were classified positively although the actual result is negative.Even though the negation in the anchor was detected correctly in the first example, wehave not defined any rules which could handle it properly since the negation handling ischallenging (e.g. "I am not only hearing voices, but hallucinating", see Section 2.2.6). Thethird example contains a lot of unknown words and slang which was detected correctly. Itlooks like providing more training data should resolve the problem since the confidenceof prediction decreased to 50.67% when training was done on the whole corpus. The lastexample has a strong anchor which indicate hallucination, but it looks like the mention ofcommunication tool/audio device (iPhone) led to incorrect prediction. When we did trainingon the whole corpus this instance was classified correctly with the 74.85% confidence.
36 Results and evaluation
4.3 Data explorations and observations
For experimental purposes, we have used our classifier to predict classes automatically. Itidentified 485 (10%) positive instances which we have analysed to test some hypotheses.
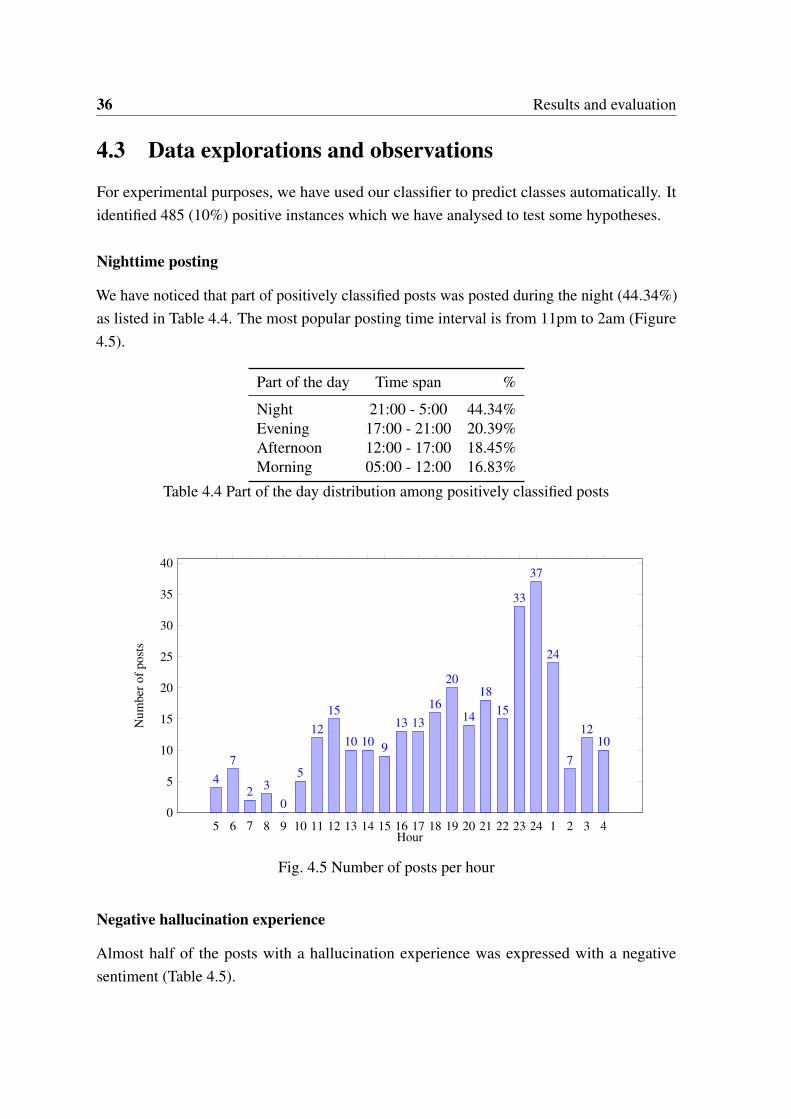
Nighttime posting
We have noticed that part of positively classified posts was posted during the night (44.34%)as listed in Table 4.4. The most popular posting time interval is from 11pm to 2am (Figure4.5).
Part of the day Time span %
Night 21:00 - 5:00 44.34%Evening 17:00 - 21:00 20.39%Afternoon 12:00 - 17:00 18.45%Morning 05:00 - 12:00 16.83%
Table 4.4 Part of the day distribution among positively classified posts
5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1 2 3 40
5
10
15
20
25
30
35
40
47
2 30
5
1215
10 10 9
13 1316
20
14
1815
33
37
24
7
1210
Hour
Num
bero
fpos
ts
Fig. 4.5 Number of posts per hour
Negative hallucination experience
Almost half of the posts with a hallucination experience was expressed with a negativesentiment (Table 4.5).

4.3 Data explorations and observations 37
Sentiment polarity Distribution
Negative 48.04%Neutral 39.59%Positive 12.37%
Table 4.5 Sentiment polarity distribution among positively classified posts
This sentiment polarity distribution made us to analyse negative emotions in more details.The most frequent characteristic of voice which people are hearing: scary, evil, f*cking,weird, strange, demonic, annoying, whiny, unfamiliar, random, nasty, male, inner, inhuman,familiar, evil-gentle, deep, cr*ppy, screwed, chopped, whispering, odd.
We have also extracted negative emotions expressed in the posts: scary, scared, afraid,creepy, terrifying, shocked, frightened, anxious.
Where do people hear voices?
Almost 10% or 44 positively classified examples mention different types of property: home(13), room (10), house (9), office (3), library (3), attic (2), apartment (2), living room (1),kitchen (1).
Experimentation results and hypotheses testing shown that provided classification model canbe used to identify hallucination experiences and investigate other schizophrenia symptoms.

Chapter 5
Conclusion
5.1 Reflection
Since we were unable to find any similar works on hallucination detection available, it wasimpossible to tell in advance which of the features will be the most important and descriptive.Therefore, it was crucial to manage the time properly and not to spend too much time onimplementing a single feature extraction algorithm. It is worth to develop a sort of prototypefirst, and see how it affect the classification performance. There was also relative amount oftime spent on the collection of knowledge bases such as dictionaries and semantic classes.
The most challenging part in the project was to extract as much information as possiblefrom brief messages. In terms of implementation, all preprocessing and correction algorithmsshould be developed very carefully since inappropriately implemented they will only addmore noise.
5.2 Future work
Implementation of the negation detection and handling will improve the classifier perfor-mance. When a positive tweet is classified it could be interesting to collect all surroundingtweets for the same user and analyse them. This could help to investigate additional sharedtopics for persons who potentially affected by this mental disorder.
In addition, the implemented classifier could be used on the whole stream of tweets, i.e.using Streaming API described in Section 2.1.1, to collect all positive examples. Then thisdataset could be analysed to get other patterns and topics.

5.3 Summary 39
5.3 Summary
We have developed a web application which automatically collects, filters and analyses postsfrom Twitter. Psychologists can use it to research and study more about schizophrenia andits symptoms.
We have also provided a set of probabilistic classifiers which can tell that specific tweetis about real hallucination experience with a high accuracy. Therefore, it was shown thattext mining techniques could be used to identify signs of schizophrenia in Twitter. Witha slight modification, this system could be used to investigate any other disease since allconfigurations are customisable.

References
[1] N. C. Andreasen, S. Arndt, V. Swayze, T. Cizadlo, M. Flaum, D. O’Leary, J. C. Ehrhardt,and W. Yuh, “Thalamic abnormalities in schizophrenia visualized through magneticresonance image averaging,” Science, vol. 266, no. 5183, pp. 294–298, 1994.
[2] R. C. of Psychiatrists, “Schizophrenia,” 2014.
[3] T. S. Commission, “The abandoned illness: A report from the schizophrenia commis-sion,” Rethink Mental Illness, 2012.
[4] C. D. Frith, The cognitive neuropsychology of schizophrenia. Psychology Press, 2014.
[5] L. F. Fontenelle, A. P. Lopes, M. C. Borges, P. G. Pacheco, A. L. Nascimento, andM. Versiani, “Auditory, visual, tactile, olfactory and bodily hallucinations in patientswith obsessive-compulsive disorder,” CNS spectrums, vol. 13, no. 2, p. 125, 2008.
[6] N. I. of Mental Health, Schizophrenia. NIH Publication No. 9-3517, 2009.
[7] A. Y. Tien, “Distribution of hallucinations in the population,” Social psychiatry andpsychiatric epidemiology, vol. 26, no. 6, pp. 287–292, 1991.
[8] “Twitter Usage [online].” Available: https://about.twitter.com/company, accessed:2015-04-22.
[9] M. De Choudhury, M. Gamon, S. Counts, and E. Horvitz, “Predicting depression viasocial media.,” in ICWSM, 2013.
[10] D. Boyd, S. Golder, and G. Lotan, “Tweet, tweet, retweet: Conversational aspects ofretweeting on twitter,” in System Sciences (HICSS), 2010 43rd Hawaii InternationalConference on, pp. 1–10, IEEE, 2010.
[11] D. Davidov, O. Tsur, and A. Rappoport, “Enhanced sentiment learning using twitterhashtags and smileys,” in Proceedings of the 23rd International Conference on Compu-tational Linguistics: Posters, pp. 241–249, Association for Computational Linguistics,2010.
[12] A. Mislove, S. Lehmann, Y.-Y. Ahn, J.-P. Onnela, and J. N. Rosenquist, “Understandingthe demographics of twitter users.,” ICWSM, vol. 11, p. 5th, 2011.
[13] “Twitter Streaming APIs Documentation [online].” Available: https://dev.twitter.com/streaming/overview, accessed: 2015-04-20.

References 41
[14] “Twitter Search API Documentation [online].” Available: https://dev.twitter.com/rest/public/search, accessed: 2015-04-20.
[15] R. Feldman and J. Sanger, The text mining handbook: advanced approaches in analyz-ing unstructured data. Cambridge University Press, 2007.
[16] G. G. Chowdhury, “Natural language processing,” Annual review of information scienceand technology, vol. 37, no. 1, pp. 51–89, 2003.
[17] S. Ananiadou, “Text Mining the History of Medicine,” March 2015. Digital Historyseminar, Institute of Historical Research.
[18] D. A. Hull, “Stemming algorithms: A case study for detailed evaluation,” JASIS, vol. 47,no. 1, pp. 70–84, 1996.
[19] R. A. Wagner and M. J. Fischer, “The string-to-string correction problem,” Journal ofthe ACM (JACM), vol. 21, no. 1, pp. 168–173, 1974.
[20] V. I. Levenshtein, “Binary codes capable of correcting deletions, insertions, and rever-sals,” in Soviet physics doklady, vol. 10, pp. 707–710, 1966.
[21] X. Liu, S. Zhang, F. Wei, and M. Zhou, “Recognizing named entities in tweets,”in Proceedings of the 49th Annual Meeting of the Association for ComputationalLinguistics: Human Language Technologies-Volume 1, pp. 359–367, Association forComputational Linguistics, 2011.
[22] B. Pang and L. Lee, “Opinion mining and sentiment analysis,” Foundations and trendsin information retrieval, vol. 2, no. 1-2, pp. 1–135, 2008.
[23] N. Pappas, “Subjectivity and sentiment classification using polarity lexicons [online].”Available: https://github.com/nik0spapp/unsupervised_sentiment, accessed: 2015-04-20.
[24] C. Lin, Y. He, and R. Everson, “Sentence subjectivity detection with weakly-supervisedlearning.,” in IJCNLP, pp. 1153–1161, 2011.
[25] T. Wilson, J. Wiebe, and P. Hoffmann, “Recognizing contextual polarity in phrase-levelsentiment analysis,” in Proceedings of the conference on human language technologyand empirical methods in natural language processing, pp. 347–354, Association forComputational Linguistics, 2005.
[26] T. M. Mitchell, The discipline of machine learning. Carnegie Mellon University, Schoolof Computer Science, Machine Learning Department, 2006.
[27] K. P. Murphy, “Naive bayes classifiers,” University of British Columbia, 2006.
[28] A. McCallum, K. Nigam, et al., “A comparison of event models for naive bayes textclassification,” in AAAI-98 workshop on learning for text categorization, vol. 752,pp. 41–48, Citeseer, 1998.
[29] I. Androutsopoulos, J. Koutsias, K. V. Chandrinos, G. Paliouras, and C. D. Spyropoulos,“An evaluation of naive bayesian anti-spam filtering,” arXiv preprint cs/0006013, 2000.

42 References
[30] S.-B. Kim, K.-S. Han, H.-C. Rim, and S. H. Myaeng, “Some effective techniques fornaive bayes text classification,” Knowledge and Data Engineering, IEEE Transactionson, vol. 18, no. 11, pp. 1457–1466, 2006.
[31] K.-M. Schneider, “A comparison of event models for naive bayes anti-spam e-mailfiltering,” in Proceedings of the tenth conference on European chapter of the Associationfor Computational Linguistics-Volume 1, pp. 307–314, Association for ComputationalLinguistics, 2003.
[32] A. L. Berger, V. J. D. Pietra, and S. A. D. Pietra, “A maximum entropy approach tonatural language processing,” Computational linguistics, vol. 22, no. 1, pp. 39–71,1996.
[33] A. Ratnaparkhi et al., “A maximum entropy model for part-of-speech tagging,” inProceedings of the conference on empirical methods in natural language processing,vol. 1, pp. 133–142, Philadelphia, PA, 1996.
[34] D. Beeferman, A. Berger, and J. Lafferty, “Statistical models for text segmentation,”Machine learning, vol. 34, no. 1-3, pp. 177–210, 1999.
[35] K. Nigam, J. Lafferty, and A. McCallum, “Using maximum entropy for text classifi-cation,” in IJCAI-99 workshop on machine learning for information filtering, vol. 1,pp. 61–67, 1999.
[36] A. Culotta, “Towards detecting influenza epidemics by analyzing twitter messages,” inProceedings of the first workshop on social media analytics, pp. 115–122, ACM, 2010.
[37] N. J. Reavley and P. D. Pilkington, “Use of twitter to monitor attitudes toward depressionand schizophrenia: an exploratory study,” PeerJ, vol. 2, p. e647, 2014.
[38] “Internet Acronyms Dictionary [online].” Available: http://www.gaarde.org/acronyms/,accessed: 2015-04-20.
[39] “Urban Dictionary [online].” Available: http://www.urbandictionary.com/, accessed:2015-04-20.
[40] “Dictionary of interjections [online].” Available: http://www.vidarholen.net/contents/interjections/, accessed: 2015-04-20.
[41] K. Gimpel, N. Schneider, and O’Connor, “Annotation guidelines for twitter part-of-speech tagging version 0.3,” March 2013.
[42] P. Ley and T. Florio, “The use of readability formulas in health care,” Psychology,Health & Medicine, vol. 1, no. 1, pp. 7–28, 1996.
[43] M. A. Russell, Mining the Social Web: Data Mining Facebook, Twitter, LinkedIn,Google+, GitHub, and More. " O’Reilly Media, Inc.", 2013.
[44] “Django: The Web framework for perfectionists with deadlines [online].” Available:https://www.djangoproject.com/, accessed: 2015-04-20.
[45] “Working with Timelines [online].” Available: https://dev.twitter.com/rest/public/timelines, accessed: 2015-04-20.

References 43
[46] “Google Timezone API [online].” Available: https://developers.google.com/maps/documentation/timezone/, accessed: 2015-04-20.
[47] S. Bird, E. Klein, and E. Loper, Natural language processing with Python. " O’ReillyMedia, Inc.", 2009.
[48] D. Chen and C. D. Manning, “A fast and accurate dependency parser using neuralnetworks,” in Proceedings of the 2014 Conference on Empirical Methods in NaturalLanguage Processing (EMNLP), pp. 740–750, 2014.
[49] J. R. Finkel, T. Grenager, and C. Manning, “Incorporating non-local information intoinformation extraction systems by gibbs sampling,” in Proceedings of the 43rd AnnualMeeting on Association for Computational Linguistics, pp. 363–370, Association forComputational Linguistics, 2005.
[50] O. Owoputi, B. O’Connor, C. Dyer, K. Gimpel, N. Schneider, and N. A. Smith, “Im-proved part-of-speech tagging for online conversational text with word clusters.,” inHLT-NAACL, pp. 380–390, 2013.
[51] K. Toutanova, D. Klein, C. D. Manning, and Y. Singer, “Feature-rich part-of-speechtagging with a cyclic dependency network,” in Proceedings of the 2003 Conferenceof the North American Chapter of the Association for Computational Linguistics onHuman Language Technology-Volume 1, pp. 173–180, Association for ComputationalLinguistics, 2003.
[52] O. Owoputi, B. O’Connor, C. Dyer, K. Gimpel, and N. Schneider, “Part-of-speechtagging for twitter: Word clusters and other advances,” School of Computer Science,Carnegie Mellon University, Tech. Rep, 2012.
[53] M. F. Porter, “Snowball: A language for stemming algorithms,” 2001.
[54] N. Pappas, G. Katsimpras, and E. Stamatatos, “Distinguishing the popularity betweentopics: A system for up-to-date opinion retrieval and mining in the web,” in Computa-tional Linguistics and Intelligent Text Processing, pp. 197–209, Springer, 2013.
[55] N. Pappas and A. Popescu-Belis, “Sentiment analysis of user comments for one-classcollaborative filtering over ted talks,” in Proceedings of the 36th international ACMSIGIR conference on Research and development in information retrieval, pp. 773–776,ACM, 2013.
[56] W. N. Francis and H. Kucera, “Computational analysis of present-day american english,”1967.
[57] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel,P. Prettenhofer, R. Weiss, V. Dubourg, et al., “Scikit-learn: Machine learning in python,”The Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
[58] “Python Unit testing framework [online].” Available: https://docs.python.org/2/library/unittest.html, accessed: 2015-04-20.