i. programming domains and paradigms in software developme… · represents meaning of language...
TRANSCRIPT

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
I. Programming Domains and Paradigms
Programming Domains ▸ Languages are designed for a specific purpose▸ There isn’t a one-size-fits-all approach to every problem (i.e., no universal language)
- Scientific Applications (Fortran, Argol): Floating Point Arithmetic- Business Applications (COBOL): Report Generation, Decimal Arithmetic- Artificial Intelligence (Lisp, Prolog): Symbolic Computation- System Programming (C, Pascal): Operating Systems- Scripting Languages (sh, awk, Perl, Tcl): System Configuration
Programming Domains Imperative Style: program = algorithms + data
▸ Oldest style of programming▸ Instructions such as assignments, branches, control flow etc.▸ Data is held in variables so instructions within algorithm can vary▸ Fortran, Assembly, Algol, Pascal, C, Ada
Functional Style: program = function · function ▸ Mathematical approach to programming based on Lambda Calculus ▸ No such thing as variables:
- There is no such thing as state, memory or side affects- Everything is conceptually a function
▪ We push arguments to functions to alter the output▪ The number of arguments we can push is not fixed
▪ We can push as many as we desire
▪ The result of the pure functional program only depends on the arguments supplied ▸ Haskel, Scheme
Logic Style: program = facts + rules ▸ Similar to functional programming in that it takes a mathematical approach via Formal
Logic- Deduce falsehoods and truths from predicates of the facts supplied- Program is devised of predicates, which are the rules that govern a problem - Uses Logical Inference to deduce conclusions from the rules started from the axioms
and theorems already provided▸ Satisfaction of formulae by finding solutions▸ Describe WHAT the problem is, NOT HOW it should be solved (declarative language)▸ Prolog
� / �1 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Object Oriented Style: program = objects + messages ▸ Programs build on types and inheritance
- Inheritance: realising new functionality from existing classes▸ Invoke messages on instances of objects
- The object responds by calling a method- The object could respond by throwing a runtime error should it not understand the
message it received
Prolog▸ Atoms: think string constant
- lowercase
fred, true, emacs
▸ Variable: substitutions Prolog can make with this variable to satisfy a rule- Uppercase- Think of as placeholders that can be wired-up with each other within the problem
editor(zen, SomeEditor)
▸ Facts/Compound Terms: functors or rules that has one or more arguments provided- Characterised by their name and arity (think number of arguments)
editor(zen, emacs). editor/2append(List1, List2, List3). append/3
▸ Goals/Predicates: When prolog is asked a query, it will try and solve each of its goals such that all predicates result in true- Prolog will try to find a set of substitutions for any variables to make all goals true- Think comma as an AND (rule1 AND rule2 AND rule3)
editor(Person1, vim),editor(Person2, vim),Person1 \== Person2
- In the above example, Prolog will try and find Person 1 and Person 2 such that they are not the same person and that two people exist in its rule base where both people use vim as their editor:
editor(ben, vim). editor(fred, vim). editor(fred, emacs).
� / �2 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Rules: Condenses a set of queries to one line statements:- Note how we can make Editor variable on the fly in the example below- This just wires up the two predicates such that their editor must be the same editor
pair(Person1, Person2) :- editor(Person1, Editor), editor(Person2, Editor), Person1 \== Person2.
▸ Lists: A list contains a number of atoms, numeric values or Variables- The bar or pipe symbol cuts the head of the list from its tail- We can use recursion of the same rule to iterate through the list
H { T } // Read as H bar T[alex, declan, rueben]Member ExampleSomething is a member of a list if it’s the first element (head) in listmember(H, [H|_]) :- true.Something is a member of a list if it’s somewhere in the tail of the listmember(X,[_|T]) :- member(X,T).
Syntax and Semantics
Syntax ▸ Concerned with the form of the programming language
- How do we put together expressions, commands and declarations to form a program?- Is it syntactically correct to say x++?
▸ Syntax guides semantics - Syntax alone isn’t enough, it just defines what makes valid sentences- Syntax is used to guide programmers into proper semantics
Semantics ▸ Concerned with the meaning of the programming language
- How does it behave when a program is executed? Why is it so?- Semantics assign meaning to every sentence that is of valid syntax
▸ We can use Axiomatic Semantics to prove the correctness of a programming language- That is, we know that our programming language has executed correctly since we have
mathematically proved that the logic is right based on the outcomes we see
� / �3 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Hilbert-Style Proofs ▸ Axioms of proof systems are the formulae that are provable by definition
- Basic building blocks of proof- E.g., true
▸ Inference rules are assertions that infer the correctness of the conclusion of one formula from another formula
▸ Proofs are a structured object build from formulae according to constraints of axioms and inference rules - Axioms + Inference = Proof- A Proof Tree exists with a premise at the top of the bar and the conclusion at the bottom
▸ For example, if we think in prolog standards:
Anakin is the parent of Lukeparent(anakin,luke).Anakin is a malemale(anakin).All males that are parents are fathersfather(X,Y) :- parent(X,Y), male(X).As Anakin is a male and he is Luke’s parent, he is therefore Luke’s father
Axiomatic Semantics ▸ Assess the correctness of programs based on its output▸ Use Axiomatic Semantics to decompose a conclusion back into its premises
- It is a backwards analysis of conclusions- Work backwards to discover the preconditions that made the program tick to its
conclusion
� / �4 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Hoare Triples ▸ An axiomatic method of defining meaning of a language using logical assertions
{ E1 } C { E2 }The precondition E1 is true, then the C command happens, now the postcondition E2 is true▸ The boolean expression E1 holds before the computation C, then E2 is true must hold too
� Proving the behaviour of the increment statement
� SEQUENCE RULE: Proving the behaviour of a C1;C2 statement
� ASSIGNMENT STATEMENT: — C = C.Target := C.Source
� / �5 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
� IF-THEN-ELSE STATEMENT — C = if C.Test then C.Then else C.Else
Note that ALL possible cases (Then or Else) lead to Q
� RULES OF CONSEQUENCE
We can discover that P -> C -> Q even though we are doing this via subtypes primes
� / �6 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Worked Example
[ P ] { true }if ( a >= b ) then m := a [ Cthen ] else m := b [ Celse ]end[ Q ] {m = MAX(a,b)}
▸ Full Proof Tree needs - DECOMPOSE: Cthen and Celse Proof Tree using Rules of Consequence- As we have decomposed both branches, we have explored all possible outcomes for Q
� / �7 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Operational Semantics ▸ Uses reduction to see how state evolves in the program
- Keep reducing the program to get to its normal form - Sometimes, we can never get to normal form (e.g., recursion)… which means program
won't be able to evaluate its output▸ Provides the means to display the computational steps undertaken when a program is
evaluated to its output.
Assignment Statement
C = C.Target := C.Source
If then else statement
C = if C.Test then C.Then else C.Else
� / �8 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Denotational Semantics ▸ Represents meaning of language concepts as mathematical objects (functions)
- Maps well-typed derivation trees to their mathematical meanings- Th method does not maintain states, but the meaning if the program is given as a
function that interprets all language elements of a corresponding set of values- Small-step semantics; reducing the concepts to partial functions
▪ Function: the mapping of all elements from a source domain to a dst. co-domain▪ Partial Function: function is not defined for all elements (i.e., a restriction of the
domain to the co-domain)
Assignment Statement
C = C.Target := C.Source
If then else statement
C = if C.Test then C.Then else C.Else
We define the If-Then-Else statement concept (S2) using If-Then-Else
Bootstrap Mathematics (S1)… S1 ≠ S2!
� / �9 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Types and Type Systems ▸ Type Systems
- Restricts the number of expressions to prevent runtime errors(i.e., which expressions can be assigned a valid type using the underlying type system)
- Types are collections of values (think sets) that share some common properties(i.e., v ∈ T — all values are subsets of a type)
- Most programming languages have a type system that will:
▪ check the type during compilation (C, C++, C#)—statically typed
▪ check the type during runtime (Objective-C, Ruby)—dynamically typed ▸ Values
- Values: an expression used solely to denote a value- Constants: a named abstraction in the program; refers to an immutable value- Primitive Values: values which cannot be further decomposed (e.g., int, string etc.)- Composite Values: values built up from primitives (e.g., records, arrays, lists, enums)- Pointers: denote the location of values
� / �10 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Inductive Sets of Data
Interpreters and Compilers Interpeter
▸ An interpreter consists of:- a front end
▪ converts the program text to an abstract syntax tree (AST)
▪ the AST is the internal representation of the program text
▪ the AST will check for soundness of the program text; AST parsers will ensure that the AST is sound and valid
- an evaluator
▪ receives at the AST and performs associated actions, dependent on the AST
▪ doesn't actually see or work with the original program input▪ converts the AST + other input => program answer
�
� / �11 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Compiler ▸ A compiler translates program text into another language
- e.g., C to Machine Code, to C# to ByteCode etc.▸ Compilers consist of:
- a front end
▪ converts the program text to an abstract syntax tree (AST) - a set of compiler phases that do particular tasks▪ Analysis Phases: ▹ Semantic Analysis▹ Optimisation
▪ Translator Phases: ▹ Optimisation▹ Code Emission
▸ An evaluator for a compiler may be an interpreter (JVM) or a machine (von Neumann)▸ The process may repeat as many times as it needs in order to resolve dependencies
- That is, it might take one compilation process, and use the output of that compilation process as the input for another compilation process and so on…
� / �12 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
�
� / �13 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Programming Language Artefacts ▸ There are always two sets of values:
- Expressed Values ▪ Specified via literal expressions
▪ string, numbers, characters - Denoted Values ▪ Value is bound to a name
▪ x := 123 ▸ Kinds of languages
- Source
▪ Language used to write programs▪ Evaluated by compiler or interpreter
▪ Java, C, Ruby - Host ▪ Language used to specify the compiler or interpreter
▪ Java, C - Target ▪ Language that is executed
▪ We translate to target languages
▪ C, Machine Code, JVM - E.g.: Scheme (Source) written in Java (Host) written in C (Target)
▸ Lexical Tokens - Building blocks of the language—atoms- A sequence of characters, as one unit, in the programming language definition- When compiling/interpreting, we digest the raw input stream into these tokens- Examples:▪ Identifiers
Give meaning to denoted values
foo, N14, $dbctn, symbol?
▪ Integers▪ Real
▪ KeywordsReserved identifiers with specific meaningif, while, downto, return, final, sealed
▪ Operators
� / �14 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▪ PunctuationAid in the reading if your program, both as a human and as a computer( ) . ; { }
Recognising Tokens ▸ Lexical tokens can be defined using the formal language of regular expressions ▸ Lexical tokens can be recognised using finite deterministic automata (DFA) ▸ DFAs is a quintuple with the following elements:
- Σ — a set of actions or alphabet of the state machine- Q = { q0 , q1 … qn } — a set of states (with each state being q)▪ q0 — designated start state
- F ⊆ Q — F is a subset of Q, where F is the accepting states- σ ⊆ Q × Σ × Q — a subset representing transitions between states (over Σ)
▪ Transitions describe behaviour within the DFA
▪ (q, a, q') ⊆ σ — note the state change from q to q' with automaton a
▸ Automaton A is finite if Q is finite ▸ Can be represented as a
transition graph (right)- The automaton A0 represents
transitions over state q0, q1, q2, q3…
- T h e a u t o m a t o n h a s a n alphabet Σ = { a, b, c }
- In the event we never end up at the final state q1, then we have invalid input
- In the event we approach the black hole state q3, we have invalid input▪ This will lead to recursion or infinite loop affect
▸ Automaton Language - A string is provided as input over an automaton for the alphabet Σ▪ if w is a string over Σ, then length of w is considered to be | w |
▪ a string with | w | = 0 is known as the empty string, or ε▹ an empty string will stop the automaton
- Consider inputs for Σ = { a, b, c } over A0:
▪ a, b, c, a is valid as we end up at q1 (q0 -> q2 -> q3 -> q1)
� / �15 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▪ b, c, a, b, c ad inf. is invalid as we are stuck in the black hole q3
▪ a, b is invalid as we do not end up at the final state q1
Inductive Specification
▸ A mechanism to formally specify possible infinite sets of values▸ Define an infinite set in terms of itself: recursion
- Clauses▪ Base Clause: A candidate (usually the smallest possible set) to represent some truth
about the set
▪ Inductive Clause: A recursive statement which can be decomposed from the base clause
- E.g.
▪ 0 ∈ S, where S is the smallest set of all natural numbers
▪ Hence: x ∈ S ⇒ x + 3 ∈ S
▪ Hence, as we truly said 0 is a subset of S, have defined x is a subset of S, we
therefore know x + 3 is part of
Mathematical Induction ▸ Once the sets have been defined inductively:
- we can use the inductive definition to deduce the properties about members in the set- we write down an infinite proof in a finite way
▸ Take the mathematical concept of reason on numbering applied to reason the structure of languages
▸ Well-formed formulae:- Base form:▪ true and false
▪ p where p is a propositional value- Induced (Inductive specification) from base form:▪ ( ¬ p ) "not p"
is well-formed, given p is well-formed
▪ ( p ∧ q ) "p and q" is well formed, given p and q are well-formed
▪ ( p ∨ v ) "p or q" is well formed, given p and q are well-formed
� / �16 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▪ ( p ⇒ q ) "if p then q" ( p implies q )
is well formed, given p and q are well-formed
▪ ( p ⇔ q ) "p if and only if q; q if and only if p" ( p is equivalent to q )
is well formed, given p and q are well-formed
Example I ▸ Proof by mathematical induction that P is true for every positive integer, n (i.e. P(n))▸ Form a base clause that is wholly true
P(1) ⇒ true
"The integer 1 is a positive one"▸ Form the inductive step which can induct all other values for n
P(n) ⇒ P(n+1)
"Given P of n is true (that is, n is positive as implied from the base clause), this will imply that one added to whatever value n is is also true"
Example II ▸ Proof by mathematical induction that sum(n) = n(n+1) / 2 ▸ Form a base clause that is wholly true
sum(0) = 0 ( 0 + 1 ) / 2 = 0 ⇒ true
▸ Form the inductive step which can induct all other values for nAssume base clause holdsWe must show that n ∖ n + 1 will hold (i.e., swap n with n + 1) sum ( n ) = n ( n + 1 ) / 2∴ sum ( n + 1 ) = ( n + 1 ) ( ( n + 1 ) + 1 ) / 2
∴ sum ( n + 1 ) = ( n + 1 ) ( n + 2 ) / 2Now use inference to apply sum ( n ) on RHSWe must show that the sum of the first n numbers is ( n + 1 ) sum ( n + 1 ) = sum ( n ) + ( n + 1 )We must show that sum (n)∖n ( n + 1) / 2 will hold∴ sum ( n + 1 ) = ( n ( n + 1 ) / 2 ) + ( n + 1 )
∴ sum ( n + 1 ) = ( n ( n + 1 ) + 2( n + 1 ) ) / 2∴ sum ( n + 1 ) = ( n2 + n + 2n + 2 ) / 2
∴ sum ( n + 1 ) = ( n2 + 3n + 2 ) / 2∴ sum ( n + 1 ) = ( n + 1 ) ( n + 2 ) / 2
Q.E.D� / �17 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Structural Induction ▸ Uses the fact that it is possible to break up a larger substructure into smaller substructures
- Think onions: we infer the inner shells, but look at the outer shell to peel back▸ Similar to mathematical induction
- Base step: Simple structures (without the substructures) are wholly true- Induction step: If the induction hypothesis on the substructures of a given object, then
it is true on the overall structure itself
Example I ▸ Prove the following BNF specification
- <exp> is a set of expressions- <idf> is a set of identifiers
<exp> ::= <idf> | ( lambda ( <idf> ) <exp> ) | ( <exp> <exp> )
▸ Use induction prove that the structure of expression <e> if e ∈ <e>, that e has the same
number of left and right parentheses - e ≡ id
"e is identical to id"#( = 0#) = 0
∴ #( = #) Q.E.D
- e ≡ ( lambda (id) e1 )
Assume induction hypothesis (base clause)Since e1 ∈ <e>, #( e1 = #) e1
let m#( = #( e1
let k#( = #) e1 m = kHence e1 has been proved. Time for e… (why 2? look at # braces!!!!!) #( e = 2 + m #) e = 2 + k∴ #( e = 2 + m = 2 + k = #) e Q.E.D
� / �18 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Arden's Rule ▸ The following base operations exist for sets of strings S
- AlternationS1 | S2 = { s | s ∈ S1 ⋁ s ∈ S2 }
The string s is S1 or S2 - Concatenation
S1 · S2 = { s1s2 | s ∈ S1, s ∈ S2 }
The string is a combination of both strings - Iteration
S* = { ε | S | S · S | S · S · S | S · S · S · S … }We iterate from an empty string, then keep iterating…
▸ The following equations hold for strings S- (S1 · S2) · S3 = S1 · (S2 · S3) - (S1 | S2) · T = S1 · T | S2 · T- T · (S1 | S2) = T · S1 | T · S2- S · ε = S- S · ∅ = ∅
- S · (T · S)* = (S · T)* · S
▪ Note, ∅ means “no path” (think infinite loop state with DFA)
▹ When we have no path, we cancel out that path from out automata calculations
▪ ε means “empty path" (think no more paths to continue from with DFA—dead end)▸ Therefore, Arden's Rule is defined as:
X = S · X | T ⇒ X = S* · T
▸ That is, if X is recursively defined with a concatenation for S or T, then the automaton accepts S and continues to accept S until we find T
Regular Expression Notation
�
Regular Expression Notation
79
a An ordinary character stands for itself.Empty string (we write ε)
M | N Alternation, choosing one M or one N.M N Concatenation, one M followed by one N. M* Repetition, zero or more times M.M+ Repetition, one or more times M.M? Optional, zero or one occurrence of M.[a-zA-Z] Character set alternation. A period stands for any single character (except newline).“while” Quotation, a string in quotes stands for itself.
� / �19 48
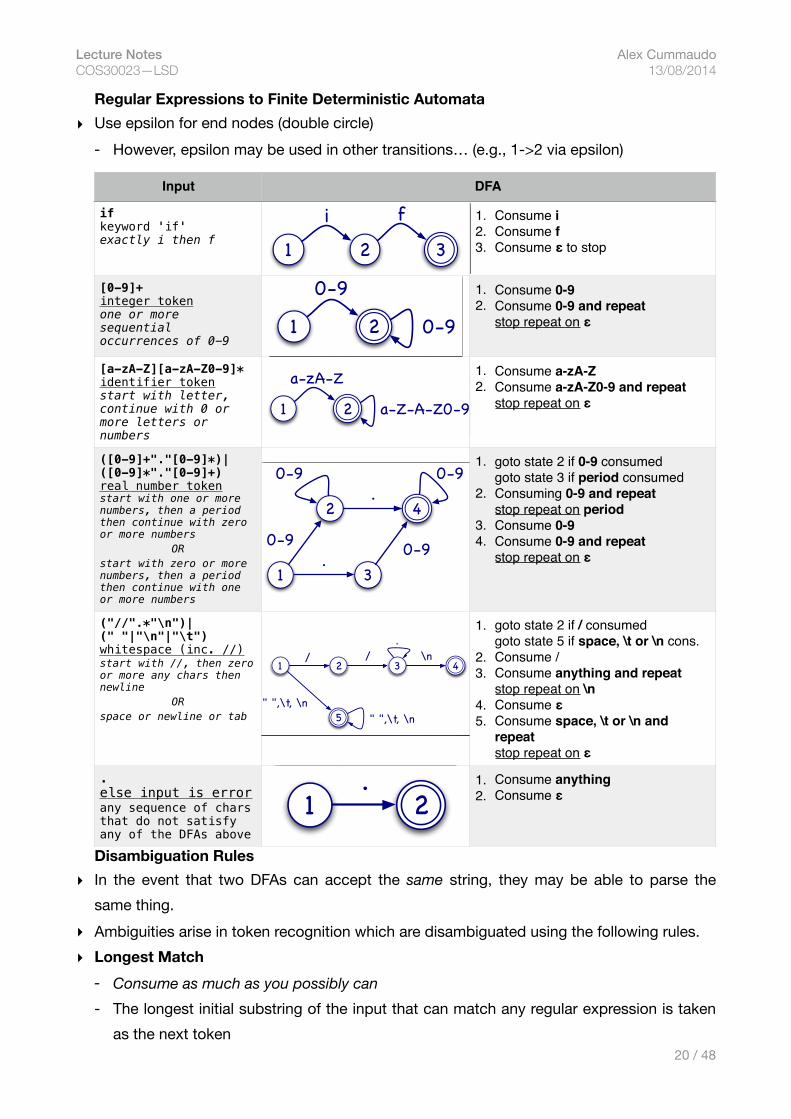
Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Regular Expressions to Finite Deterministic Automata ▸ Use epsilon for end nodes (double circle)
- However, epsilon may be used in other transitions… (e.g., 1->2 via epsilon)
Disambiguation Rules ▸ In the event that two DFAs can accept the same string, they may be able to parse the
same thing. ▸ Ambiguities arise in token recognition which are disambiguated using the following rules.▸ Longest Match
- Consume as much as you possibly can - The longest initial substring of the input that can match any regular expression is taken
as the next token
Finite Automata for Tokens
81
i f1 2 3
1 2.
2 4.
1 3.
0-90-9
0-9 0-9
2 3/1 4/.
" ",\t, \n
\n
5" ",\t, \n
a-zA-Z1 2 a-Z-A-Z0-9
0-91 2 0-9
Finite Automata for Tokens
81
i f1 2 3
1 2.
2 4.
1 3.
0-90-9
0-9 0-9
2 3/1 4/.
" ",\t, \n
\n
5" ",\t, \n
a-zA-Z1 2 a-Z-A-Z0-9
0-91 2 0-9
Finite Automata for Tokens
81
i f1 2 3
1 2.
2 4.
1 3.
0-90-9
0-9 0-9
2 3/1 4/.
" ",\t, \n
\n
5" ",\t, \n
a-zA-Z1 2 a-Z-A-Z0-9
0-91 2 0-9
Finite Automata for Tokens
81
i f1 2 3
1 2.
2 4.
1 3.
0-90-9
0-9 0-9
2 3/1 4/.
" ",\t, \n
\n
5" ",\t, \n
a-zA-Z1 2 a-Z-A-Z0-9
0-91 2 0-9
Finite Automata for Tokens
81
i f1 2 3
1 2.
2 4.
1 3.
0-90-9
0-9 0-9
2 3/1 4/.
" ",\t, \n
\n
5" ",\t, \n
a-zA-Z1 2 a-Z-A-Z0-9
0-91 2 0-9
Finite Automata for Tokens
81
i f1 2 3
1 2.
2 4.
1 3.
0-90-9
0-9 0-9
2 3/1 4/.
" ",\t, \n
\n
5" ",\t, \n
a-zA-Z1 2 a-Z-A-Z0-9
0-91 2 0-9
Input DFA
if keyword 'if'exactly i then f
1. Consume i2. Consume f3. Consume ε to stop
[0-9]+integer token one or more sequential occurrences of 0-9
1. Consume 0-92. Consume 0-9 and repeat
stop repeat on ε
[a-zA-Z][a-zA-Z0-9]*identifier token start with letter, continue with 0 or more letters or numbers
1. Consume a-zA-Z2. Consume a-zA-Z0-9 and repeat
stop repeat on ε
([0-9]+"."[0-9]*)|([0-9]*"."[0-9]+) real number token start with one or more numbers, then a period then continue with zero or more numbers
OR start with zero or more numbers, then a period then continue with one or more numbers
1. goto state 2 if 0-9 consumed goto state 3 if period consumed
2. Consuming 0-9 and repeatstop repeat on period
3. Consume 0-94. Consume 0-9 and repeat
stop repeat on ε
("//".*"\n")|(" "|"\n"|"\t") whitespace (inc. //) start with //, then zero or more any chars then newline
OR space or newline or tab
1. goto state 2 if / consumed goto state 5 if space, \t or \n cons.
2. Consume /3. Consume anything and repeat
stop repeat on \n4. Consume ε5. Consume space, \t or \n and
repeatstop repeat on ε
. else input is error any sequence of chars that do not satisfy any of the DFAs above
1. Consume anything2. Consume ε
� / �20 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▪ "596.354"⇒ real▪ "85893a" ⇒ integer as 85893
▸ Rule Priority - For a longest initial substring, the first regular expression that can match determines its
token type- E.g.: for the text input if and the following regular expressions:
RegEx1: ifRegEx2: [a-zA-Z][a-zA-Z0-9]*
- The order of definitions of regular expressions determines its priority▪ Because the if keyword RegEx (1) is defined before the identifier RegEx (2) then (1)
gets priority over (2) for input of 'if'
Combining DFAs ▸ To turn all the individual machines into one machine, we create:
- Finite Nondeterministic Automata (NFA) - It is nondeterministic because it can decide which path to go to even if there are
multiple same-transition paths- It is a refinement of the NDA:
▪ It still satisfies the quintuple (Σ, Q, q0, σ, F) butσ ⊆ Q × Σ × 2Q
That is, transitions (σ) are now subsets of:1. a relation starting at state Q2. the FDA looks at a label in subset Σ
3. adds in a state that is a subset of a power set of all the states (2Q)In other words, we can end up at multiple states at once
DFA NFA
Discrete labels from one state to another; all labels labelled differently and branch off discretely.
Can have two transitions out of one state with the same label (q0 and a1 goes to both q1 and q2)
� / �21 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ NFA's can be expressed into equivalent DFA'sWorked Example:
DFA NFA
q0 = (a · (b | a · c))*
is the regular expression to express both automata
� / �22 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ A note on pruning- q3 = ( 0 | 1 ) · q3 where Σ = { 0, 1 }
Above is an empty path since it is recursively infinite…"Consume 0 or 1 and then goto q3 again"Hence since this is a "black hole": q3 = ( 0 | 1 ) · q3∴ q3 = ∅ Now all occurrences of q3 can be pruned and substituted with nothing
- a | ε ≙ [a]
For all expressions where a or ε, replace with optional a = [a]
Syntax Analysis & Grammar ▸ While DFA/NFAs describe valid input, it doesn't mean it helps with the form of the input
- The DFA/NFA will sort the whole stream of input into tokens▸ The parser will ensure that the tokens have appropriate grammar
- grammar describes all possible sequences that have correct formi.e., does it make sense to have if while for then?
▸ Unfortunately, regular expressions can only go so far- Regular expressions are stateless and do not keep track of what has been processed- For example
we can't keep track of the number of { and the number of } to see if they match - We can use Pumping Lemma for regular languages to achieve this
any sufficiently long string in the language contains a section that can be removed, or repeated any number of times, with the resulting string remaining in that language.
▸ Use Grammar to validate form- Grammar is a quadruple
G = (V, T, S, P) - V = vocabulary
set of all terms used - T ⊂ V
T is a true subset of VT is the terminal tokens
- S ∈ (V - T)
start symbols - P ⊆ (V* - T*) ⨉ V*
productions over the vocabulary and tokens
� / �23 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Language of a grammar is defined as the set of all strings of terminals that are derivable from the start string for the particular grammar:L(G) = { w ∈ T* | S ⇒+ w }
- w ∈ T* All strings of the terminal sets
- S ⇒+ w
Apply the productions of the grammar at least once from start to end ▸ Types of grammar
- Type 0: Free
▪ No restrictions on productions
▪ Just a simple, arbitrary rule set▪ Prolog
- Type 1: Context-Sensitive
▪ Only ok if we have context; can only apply the rule if its in context- Type 2: Context-Free
▪ A grammar can only have productions
▪ One, and one only, non-terminal symbol- Type 3: Regular
▪ A grammar can only have productions of the form:a is a terminalaB, Ba, a, ε, where B is a non-terminal
Backus-Naur Form (BNF) ▸ Specify the grammar of a language using a context-free grammar, BNF▸ Follows the format:
lhs ::= rhs
- Where lhs is a nonterminal and rhs is a list (separated by |) of terminals and nonterminals
< ListOfNumbers > ::= "()" | "(" < Number > "." < ListOfNumbers > ")"Bolded = nonterminalUnderlined = terminal
A list of numbers is either an empty list ( ) OR in the format (H.T)
� / �24 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Concrete Syntax Tree ▸ Represents the external representation of
statements, expressions and values▸ We can construct a syntax tree from the
tokens that are made available to us▸ Remember:
- 1. Input text stream undergoes a lexical analysis using a DFA/NFA
- 2. Tokens are then consumed using the syntax tree to their terminals
- 3. Once we are at the leafs of the syntax tree, we have made the syntax tree- Goal: For all possible input strings, we get exactly one syntax tree
▸ The problem is we may have ambiguous grammars:- Ambiguous Grammars:
The same input and achieve multiple syntax trees- Non-Ambiguous Grammars:
One input string to get one syntax tree (i.e., this string produces a unique syntax tree)- Consider the following ambiguous grammar:
< Expression > ::= < Identifier >< Expression > ::= < Number >< Expression > ::= < Expression > + < Expression >< Expression > ::= < Expression > - < Expression >< Expression > ::= < Expression > * < Expression >< Expression > ::= < Expression > / < Expression >< Expression > ::= ( < Expression > )
▸ Precedence Problem - The higher up the syntax rules the lower the priority- An operator has tighter binding (higher priority) if it's defined deeper in the hierarchy- In the above example:
▪ Followed BODMAS since the order of the rules are defined with higher priorities last ▸ Associativity Problem
- If an operator uses left-recursive structure, then it is associated to the left of that rule
< Expression > ::= < Expression > + < Expression >
- If an operator uses right-recursive structure, then it is associated to the right of that rule
< Expression > ::= - < Expression >
� / �25 48
Low Priority
Higher Priority

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Consider the following Syntax Rules…
< Expression > ::= < Identifier >< Expression > ::= < Number >< Expression > ::= < Expression > + < Expression >< Expression > ::= < Expression > - < Expression >< Expression > ::= < Expression > * < Expression >< Expression > ::= < Expression > / < Expression >< Expression > ::= ( < Expression > )
Priority In ActionSince the * operator is defined after the + operator, the RHS tree is taken
Associativity In ActionSince the + operator is defined with a left-recursive structure, the left route is taken
� / �26 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Abstract Syntax Tree ▸ Represents the internal representation of the statements, expressions and values▸ In the abstract syntax tree, we have no terminals
- The building blocks are tokens, rather than terminals.▸ Abstract trees generate ambiguous trees, but isn't meant for parsing (so this is okay)
Concrete Tree Define in terms of actual terminal characters (bolded)
< Lines > ::= ( < Expression > "\n" )*< Expression > ::= < Term > ( ( "+" | "-" ) < Term > )*< Term > ::= < PrimaryExpression > ( ( "x" | "/" ) < Primary > )*< PrimaryExpression > ::= "(" < Expression > ")" | "-" < Primary > | < Number >
Abstract Tree Define in abstract terms, without terminals
< Lines > ::= ε | < Expression > < Lines >< Expression > ::= < Expression > - < Expression > | < Expression > + < Expression > | < Expression > * < Expression > | < Expression > / < Expression > | - < Expression > | < Number >
� / �27 48
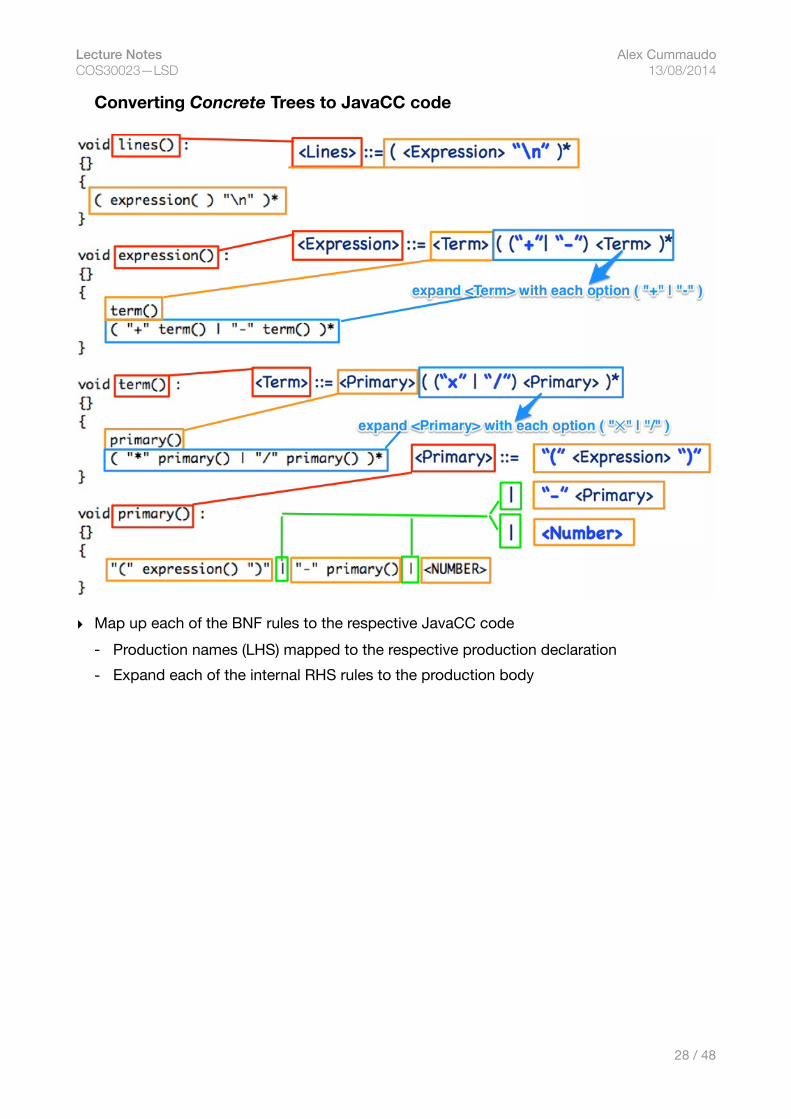
Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Converting Concrete Trees to JavaCC code
▸ Map up each of the BNF rules to the respective JavaCC code- Production names (LHS) mapped to the respective production declaration- Expand each of the internal RHS rules to the production body
� / �28 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Converting Abstract Trees to JavaCC code ▸ Start by creating a class hierarchy for the Category on the RHS of the BNF
- i.e., the make the superclass the AST root node ▸ For each sub-node, map to a subclass of the root node that will implement an evaluation
in the way it needs to…
▸ Implement each subclass with its appropriate implementation- Binary operators should take two objects in the constructor- Unary operators should take one objects in the constructors- Literals will take the token supplied at the creation of the AST and will use that token's
image for the creation of its node
▪ The token's image is just the literal string of the token input…
� / �29 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
� ▸ Map the classes together in JavaCC
Concrete Syntax<Lines> ::= ( <Expression> “\n” )*!!
<Expression> ::= <Term> ( (“+”| “-”) <Term> )*!!
<Term> ::= <Primary> ( (“x” | “/”) <Primary> )*!!
<Primary> ::= “(” <Expression> “)”! | “-” <Primary>! | <Number>
123
� / �30 48
Concrete Syntax<Lines> ::= ( <Expression> “\n” )*!!
<Expression> ::= <Term> ( (“+”| “-”) <Term> )*!!
<Term> ::= <Primary> ( (“x” | “/”) <Primary> )*!!
<Primary> ::= “(” <Expression> “)”! | “-” <Primary>! | <Number>
123
Concrete Syntax<Lines> ::= ( <Expression> “\n” )*!!
<Expression> ::= <Term> ( (“+”| “-”) <Term> )*!!
<Term> ::= <Primary> ( (“x” | “/”) <Primary> )*!!
<Primary> ::= “(” <Expression> “)”! | “-” <Primary>! | <Number>
123

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Turing Machines and Effective Compatibility ▸ A Turing machine is an abstract computer software that solves problems
- Consists of a readwrite head that runs along a tape as it passes in and out the machine- The tape can run bidirectionally- The tape usually reads binary only, but can have any alphabet as desired- The machine is usually fed a table of instructions - It is NOT a Finite Deterministic Automata!!!
▸ Effective Computability - Church’s Thesis proves that it is not possible to build a machine that is more powerful
than a Turing machine—if an algorithm is expressible in Lambda Calculus then it is effectively computable
▸ If an algorithm can pass the turing machine, then it is “turing computable”▸ Halting Problem is an example of what is not computable
- “The Control-C problem” - How will the program eventually produce a result?- There is no way to write a program that will check if your program will eventually halt!
� / �31 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Lambda Calculus λ▸ “The mother of all computer programming languages!”
- A language that uses operational and denotational semantics to express algorithms- A language that can denote mathematical proofs- A language that can assign and specify type systems- A medium to represent mathematics on computers with the aim to exchange and store
reliable mathematical knowledge- A mathematical formalism for expressing computation by functions- A pure functional programming language
▸ Lambda Expression Syntax:
▸ We say that lambda functions will consume as many arguments as it needs to- Any arguments left over will be left over for he next function
▸ Examples: - Identify Function
The λx introduces x as a new argument in inner scope, which is immediately returned
- Pair FunctionThe λx introduces x, λx introduces y; this is mapped into λz, that introduces z, where z is mapped to a pair expression made of x and y
� / �32 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
References vs. Declarations ▸ Declaration: λx.e
The occurrence of x in the λ abstraction introduces the variable x as a placeholderThink of it like a prolog variable; eventually this variable will be bound to a concrete value
▸ Reference: f x yHere, all 3 variables (f, x, y) appear as references whose meanings are defined in the enclosing declaration (i.e., are concretely defined by the context by which they are in)
▸ Binding & Declarations - The value which the variable names is known as its meaning or denotation- The denotation comes from some declaration▪ We say that the variable is bound by that declaration (or refers to the declaration)
- The declaration have a limited scope (area where the variable is applicable)- As such, we can have multiple, different variables with the same name
▸ Scoping Rules - Static Scoping
▪ Determine variable declaration and its scope by looking at program text alone▪ Think most normal languages—we put our finger on the paper and hand execute it!
- Dynamic Scoping
▪ Determine variable declaration and its scope at runtime▹ Look at the program trace to see what’s going on▹ No such thing as inner functions or “final/sealed” keyword
▸ Binding Rules - In λx.e, x is a declaration that binds all occurrences of that variable in e
Wherever we see an x in e, it was bound in λx.e
Look for the binding at λx.
� / �33 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Free Occurrence and Bound Occurrence - Free Occurrence ▪ We use a variable that has a does NOT have a previous binder
▪ A variable x occurs free in an expression e if and only if there is:▹ a use of x in e▹ x is not bound to any declaration in e
▪ E.g. λx.x yy is used but not bound anywhere in the expression
▪ Think of it like cout in C++; it’s freely used but not defined anywhere (in your scope) - Bound Occurrence
▪ We use a variable that has a previous binder▪ A variable x occurs free in an expression e if and only if there is:▹ a use of x in e▹ x is bound to a declaration in e
▪ E.g. λf.λx.fxboth f and x are being used, and they have been defined
� / �34 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Scope, Blocks and Visibility ▸ Blocks
- We can have as many nested regions as we need- The scope of the variable can include inner regions that hide the variable - Where we use a variable of the same name, the innermost use of the variable hides the
outermost variable
▸ Contour Diagrams - Regions can also be expressed as a contour diagram
Currying ▸ A way in which we can model functions with multiple parameters as curried functions
- Non-curried to curry = curry- Curry on non-curried = uncurry
� / �35 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Lexical Addresses ▸ A way in which we can refer to variables without using the name
- We use an [d, p] expression, where:
▪ d is the relative depth up in the region to use and
▪ p is the position of the variable
▪ Going to d=n means we move n region’s out (down and out)
▪ Going to p=s means we move s places right (after moving down and out)
Free and Bound Variables ▸ In λx.e, x is bound by the enclosing λ▸ A variable that is not bound by λ is free ▸ Expressions with
- no free variables are closed: λx.x- free variables are open: λy.x y
▸ Lambda expressions with no free variables are called combinators - Procedures when applied to all arguments (i.e., a procedure call) is a combinator
Variable fv(x) = {x} The free variables of x is the singleton x
Function fv(λx.e) = fv(e) \ {x}The free variables of λx.e is all of the free vars of e minus x; because x is bound by λ and is therefore NOT free!
Application fv(e1.e2) = fv(e1) ∪ fv(e2) The free variables of an application is just a union of both free variables in both exprs.
Variable bv(x) = ∅ There are no bound variables in x; empty set
Function bv(λx.e) = bv(e) ∪ {x}x is bound by λ; therefore the bound variables of a function λx.e is all of the bound variables of e union with that of x singleton
Application bv(e1.e2) = bv(e1) ∪ bv(e2) The free bound of an application is just a union of both bound variables in both exprs.
� / �36 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Lambda Calculus Reduction Rules ▸ Describe transitional relations from one state to another
α-conversion ▸ Allows the renaming of bound variables
- A bound name x in λx.e may be renamed to y as long as there are no FREE occurrences of y in the expression e
- We say that y is “fresh” in e
β-reduction (parameter passing!) ▸ The computational engine for lambda calculus
- We reduce a term in order to “run or execute the term”
▸ Applicable in applications only- Evolution of applications
▸ Avoid name capture; parameter passing- It is the mathematical
representation of the stack!!- We swap e2 (the argument expression) with a concrete binding (e.g., x)
� / �37 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
η-reduction ▸ Allows removal of “redundant lambdas”▸ Whenever x does not occur free in f, then we can
rewrite:
Substitution Rules ▸ What parameter passing entails in Lambda Calculus▸ We define substitution carefully to avoid name capture:
- [e/x]x = eReplace x with e in x; results in e (x singleton)
- [e/x]y = yReplace x with e in y; results in y (y does not contain any bound x variables)
- [e/x](e1e2) = ([e/x]e1 [e/x]e2)Replace x with e in both expressions; leave as an application but distribute the x into each of the subexpressions
- [e/x](λx.e1) = (λx.e1)Replace x with e in the expression; introduces a new binder in x and therefore no changes are made
- [e/x](λy.e1) = (λy.[e/x]e1) if x ≠ y and y ∉ fv(e)Replace x with e in the expression; introduces a new binder y and therefore we can therefore replace y GIVEN y is not in the free variables of the expression e and not = x
- [e/x](λy.e1) = (λz.[e/x][z/y]e1) if x ≠ y and z ∉ (fv(e) ∪ fv(e1))
Replace x with e in the expression; introduces a new binder z and therefore we can therefore swap e for x with y GIVEN z is not in the free variables of the expression e and e1 and not = x
� / �38 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Representing ADTs as Lambda Functions ▸ Booleans
▸ Pairs
▸ Church Numbers
SETS: See lecture notes…
� / �39 48
Booleans• We can represent Boolean values and operations that manipulate Boolean values as functions: ! TRUE ≡ λx.λy. x!
FALSE ≡ λx.λy. y!
not ≡ λb.((b FALSE) TRUE)!
if then else ≡ λb.λx.λy.((b x) y)!
• Example: ! if TRUE then 1 else 2 ≡ λb.λx.λy.((b x) y) TRUE 1 2!
= ((TRUE 1) 2)! = 1
181
Pairs• Although tuples are not supported by the lambda calculus, they can easily be modeled as higher-order functions that “wrap” pairs of values. N-tuples can be modeled by composing pairs:! pair ≡ λx.λy.λz.((z x) y)!
first ≡ λp.(p TRUE)!
second ≡ λp.(p FALSE) !
• Example: ! first (pair 1 2)! ➔ 1! second (pair 1 2)! ➔ 2
182
succ 0
1 = succ 0 = λn.λs.λz.(s (n s z)) λs.λz.z !
→ λs.λz.(s ((λs.λz.z) s z))!
→ λs.λz.(s ((λz.z) z))!
→ λs.λz.(s z)
184

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Evaluation Order ▸ A lambda expression is in normal form if it can no longer be reduced by β- or η-reduction▸ We can keep down-reducing our expressions until they are no longer reducible▸ We say that normal form is the output of our program (we evaluate the program to
normal form) - though not all lambda expressions have a normal form, like the Ω expression:
- This shows that there exists non-normal-form expressions
▪ e.g., programs that cannot reduce—endless loop!
Strict Evaluation (Applicative Order Reduction) ▸ Evaluates the expression before control is passed over to the function▸ i.e., call by value; always evaluate/reduce
expressions, regardless of if it’s used later on- This means that a function that is
applied to a nontermintating expression will cause no output: f ⊥ = ⊥ A function f is applied to expression that is non-reductive; this means that the function will not reduce too
▸ This models call by value—i.e., evaluate the arguments, then invoke the function ▸ This means:
- in the application (e1 e2):
▪ reduce e2 (args) first using applicative order reduction, then
▪ reduce e1 (func) second using applicative order reduction, then▪ if e1 is a function, then apply beta reduction and reduce the result to normal form
▪ else return a new application consisting of reduced e1 and e2 � / �40 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Using fully parenthesised notation, always perform the RIGHTMOST and INNERMOST beta reduction
▸ That is, work from top right to bottom left—repeatedly scan for rightmost innermost (left parenthesis) occurrence of ((λx.e1) e2) terms
Lazy Evaluation (Normal Order Reduction) ▸ Evaluates the expression only when they are needed ▸ This means we keep on passing along the unevaluated expression until it gets to a point
where we need to evaluate the expression to move onto the next reduction- This means that a function that is applied to a nontermintating expression will still be
reducible: f ⊥ ≠ ⊥ A function f is applied to expression that is non-reductive; this means that the function will still be able to be reduced as we have never evaluated the non-reductive expression as it is not needed.
� / �41 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Confluence ▸ If an expression has a normal form, then it doesn't matter
how you get to that normal form- There can be multiple ways of evaluating to a normal
form- 2 programs are the same if they both evaluate to ∃T
(i.e., normalised)
▪ Can go from M ➝ P ➝ ∃T orCan go from M ➝ Q ➝ ∃T
▪ You still end up at a normalised ∃T
▸ Evaluation order does not matter in lambda calculus- That said applicative-order reduction may not terminate even if a normal form exists- Consider the Ω expression = ( λ x.y ) (( λ.x x x ) ( λ x.x x))
▪ Applicative-order reduction does not reduce this to a normal form since it attempts to reduce itself, which leads to a reduction into itself (i.e., self replicating)
▪ Normal-order reduction will not ever evaluate Ω over again since it doesn't need to
Recursion ▸ Recession is fundamental to programming, but it is not a primitive▸ We need to find a way in which we can “program” recursion▸ Consider:
plus = λn m.(if n then (plus (dec n)(inc m)) else m)
- Here we are trying to define plus in terms of itself- We can’t do that because we haven’t defined what plus actually is yet
▸ Instead, we define a closed expression (i.e., one with no free variables—without the recursive plus) by abstracting over plus- Redefine the function plus into rplus, where:
rplus = λplus n m.(if n then (plus (dec n)(inc m)) else m)
- Now, we can redefine the actual addition function we want as fplus - We pass rplus as a parameter before we perform any operations:
(rplus fplus) - Hence:
rplus fplus ⟷ fplus
- This means that plus is the fixed point of rplus - Fixed points are functions to an argument that just return the argument
� / �42 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
Type Systems▸ Type systems ensures that there will be:
- documentation in our code- prevention of runtime errors if enforced- ensure the expected result is met
▸ We have a whole bunch of types at our disposal
< TYPE > ::= int primitive integer | char primitive char | string primitive string | < IDENTIFIER > type variable | ( < TYPE > ) lists | ( { < TYPE > }*(✕)) tuples | ( { < TYPE > }*(✕) -> < TYPE >) functions< TYPED EXPRESSION > ::= ( < EXPRESSION > < TYPE > )
▸ Note that the superscript (✕) refers to a separation of types by ✕ (i.e., cross factor)
Function Types ( { < TYPE > }*(✕) -> < TYPE >) ▸ Deduces the types of expressions without the need to evaluate them
List Types ( { < TYPE > } ) ▸ Lists ::= ( { < EXPRESSION > }* )▸ A list of type a has the type "(a)"
((1 2 3 4 5)(int)) valid int list(("Hello" "World")(string)) valid string list(("Hello" 123 'a')(??)) invalid list (3 different types)
Tuples ( { < TYPE > }*(✕) ) ▸ Tuples ::= ( { < EXPRESSION > }* )▸ A tuple must have matching type
specifications- A tuple (x1, x2, x3… xn) has a type (a1 ✕ a2 ✕ a3 … an)
� / �43 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Static Typing - Possible to determine the static type of an object from the programming text alone- WYSIWYG approach—runtime is the same as definition- Type check at compile time
▸ Dynamic Typing - Types are determined at runtime- Type checking before variable is used- Type changes or determined at runtime
▸ Type Consistency - Strongly typed languages ensure every expression is type-consistent from program text- Type consistency is ensured using
▪ compile-time type-checks
▪ type interference▪ dynamic type-checks
▸ Kinds of types - Primitive: bool, int, char, float- Composite: functions, lists, tuples- User-Defined: enumerations, recursive types, generic types
Lambda Calculus and Types ▸ Three type checking mechanisms:
- Type Assignment
▪ Just like any assignment▪ We bind an expression, M, to a type, τ
M : τ
- Type Contexts/Assumption/Environment
▪ A type environment, Γ, is a partial function
Γ : V → V
▪ It defines a 'hash-map' of possibly empty set of variables that are bound to types
▪ That way, we can lookup the variable name and see the type definition
Γ = { int32: int, string: char* }
▪ Hence, now we can say that:Γ(int32) = int, Γ(string) = char* i.e., in our type environment int32 maps to int etc.
� / �44 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
- Type Judgement
▪ The triple (Γ, M, τ) specify a type judgement▪ It is a formal specification of the type environment in our program
Γ ⊢ M : τunder type gamma, there is an expression M which is assigned type tau
{ int32 : int, string : char* } ⊢ string : char*
▸ Subject Reduction - Reduction of lambda calculus preserves the type- If a program is assigned the type τ and M is reduced to normal form N, N has type τ:
If Γ ⊢ M : τ and M →β N, then Γ ⊢ N : τ
- If this is the case, then there is no need for runtime type checks!▸ Type Safety
- Does the reduction of M lead to stages that are type-safe?- We can ensure this if the term M has the type τ—then it is safe- This helps us reduce mismatch of the:▪ declared type of a variable and
▪ the application type when that variable is used
▪ i.e., int foo = 12; foo + "hi";▸ Typed Lambda Calculus
� / �45 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Type Lambda Calculus Reduction Rules - Simply the same; with preservation of types
▸ Type Lambda Calculus Type Rules
ɑAlpha Conversion
βBeta Reduction
η Eta Reduction
�
e ::= xτVariable
e ::= (λxσ.eτ)(σ→τ)
Function
e ::= e1(σ→τ) e2σ
Application
� / �46 48

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
- Polymorphism and Type Systems
▪ Monomorphic type system ensure a definition of generic abstraction remains hidden
▪ Polymorphic type expressions describe families of types
- We can deduce the types of expressions using polymorphic type functions - Polymorphism types:
▪ Parametric: NSObject in ObjC, object in C#, void* in C
▪ Inclusion: sub-typing ▪ Overloading: Operator + applied to both integers and floating point
▪ Coercion: Integer values being used where floating points are expected
Type Inference
▸ The set of untyped lambda-terms are defined as
� ▸ Whereas the set of typed lambda-terms are defined as
� ▸ This means that et being the set of typed lambda-terms is obtained by modifying the
second clause in the definition of the untyped lambda terms
�
Typed Lambda-Terms• The set e of untyped lambda-terms are defined as follows:! e ::= x! | (λx.e)!
| (e1 e2)! • The set T of types is defined as follows:! t ::= K - basic types! | (t1 → t2) - function types!
• The set eT of typed lambda-terms is obtained by modifying the second clause in the definition of the untyped lambda-terms:! (λx : t.e)
246
Typed Lambda-Terms• The set e of untyped lambda-terms are defined as follows:! e ::= x! | (λx.e)!
| (e1 e2)! • The set T of types is defined as follows:! t ::= K - basic types! | (t1 → t2) - function types!
• The set eT of typed lambda-terms is obtained by modifying the second clause in the definition of the untyped lambda-terms:! (λx : t.e)
246
Typed Lambda-Terms• The set e of untyped lambda-terms are defined as follows:! e ::= x! | (λx.e)!
| (e1 e2)! • The set T of types is defined as follows:! t ::= K - basic types! | (t1 → t2) - function types!
• The set eT of typed lambda-terms is obtained by modifying the second clause in the definition of the untyped lambda-terms:! (λx : t.e)
246
� / �47 48
Polymorphic Types• We can deduce the types of expressions using polymorphic functions by simply binding type variables to concrete types:!Consider:!
(length ((a) -> int))!
(stringlength (string -> int))!
(map ((a -> b) -> (a) -> (b)))!
Then:!((map stringlength) ((string) -> (int)))!((“Hello” “World” “!”) (string))!((map stringlength (“Hello” “World” “!”)) (int))
239

Lecture Notes Alex Cummaudo COS30023—LSD 13/08/2014
▸ Type inference for closed terms can be stated as:
Given a closed lambda-term e, find all types t such that (∅, e, t).
▸ Wand’s algorithm
� Action Table:
�
Wand’s Algorithm - SkeletonInput: !
• A lambda-term e0.!
Initialization:!• Set E = ∅ and G = {(Γ0, e0, t0)}, where t0 is a type variable and Γ0 maps the free variables of e0 to other distinct type variables.!
Loop Step:!• If G = ∅, then halt and return E. Otherwise, choose a subgoal (Γ, e, t) from G, delete it from G, and add to E and G new verification conditions and subgoals, as specified in an action table.!
End of Skeleton
249
The Action Table(Γ, x, t):!
Generate the equation t = Γ(x).!
(Γ, (λx . e ), t):!Let τ1 and τ2 be fresh type variables. Generate the equation t = (τ1 → τ2) and the subgoal (Γ; x : τ1, e, τ2).!
(Γ, (e1 e2), t):!Let τ1 be a fresh type variable. Then generate the subgoals (Γ, e1, τ1 → t) and (Γ, e2, τ1).
250
� / �48 48