how deepmind mastered the game of go
TRANSCRIPT

HOW DEEPMIND MASTERED THE GAME OF GO
TIM RISER - PWL BOSTON/CAMBRIDGEPhoto: Nature7/28/2016


HELLO~
My name is Tim Riser▸ Researcher @ Berkman Klein Center for Internet & Society▸ Applied Computational Mathematics & Economics @ BYU ▸ @riserup

1. CONTEXTNO PAPER WE LOVE IS AN ISLAND
Shannon’s “Programming a Computer
for Playing Chess”
Game tree complexity
First attempts at a Go AI
Enter AlphaGo

“The computer should make more use of brutal calculation than humans, but a little selection goes a long way forward improving blind trial and error…
It appears that to improve the speed and strength of play the machine must … select the variations to be explored by some process so that the machine does not waste its time in totally pointless variations.
Claude Shannon
Programming a Computer to Play Chess

“SHANNON & COMPUTER CHESS
Photo: Computer History Museum

“SHANNON & COMPUTER CHESS
Claude Shannon - the father of information theory -thought that creating a computer chess program would lead to practical results.
He envisioned that the methods devised in solving chess would be applied to areas such as circuitry design, call routing, proving math theorem, language translation, military planning, and even creative works like music composition.

HOW DO YOU SOLVE A GAME LIKE CHESS OR GO?
▸ Chess has ~35 legal moves per position and a game length of ~80 moves
▸ Go has ~250 legal moves per position and a game length of ~150 moves
▸ Maybe brute force is out, then
250150 > 3580 ≅ 3.3x10123 > # of atoms in the (known) universe
1082

GAME TREE COMPLEXITY
▸ Let b is the approximate breadth (# of legal moves/position)
and d is the approximate depth (game length)
▸ Then bd is a reasonable lower bound on the complexity of the search space
▸ What can we do to make this problem computationally tractable?

GAME TREE COMPLEXITY
1. Remove unneeded branches from the search tree to reduce search breadth (b)
2. Truncate branches to reduce search depth (d) and then use a function to approximate the value of the branches underneath the cut-off point

BREADTH REDUCTION
Photo: UCLA Stat232B
Remove highlighted branches from
search candidates in advance

BREADTH REDUCTION METHODS
1. Train with experts to learn which branches are uncommon or improbable
2. Randomly sample sequences from the search tree to avoid exhaustive search

DEPTH REDUCTION
If we have an function v(s) that can evaluate a state s, we can truncate a branch and replace its subtree with a value. This
lets us avoid searching it to the maximum depth
Photo: UCLA Stat232B

DEPTH REDUCTION METHOD
1. Find a function to approximate the value of a state, and truncate the search branches beneath that state.
To choose an action, the program can then compare that assigned value with the values of other actions.

SURVEY OF AI GAMING MILESTONES
1914 Torres y Quevedo built a device that played a limited chess endgame1950 Claude Shannon writes “Programming a Computer to Play Chess”1952 Alan Turing writes a chess program (with no computer to run it!)1968 Alfred Zobrist’s Go program beats total beginners [minimax tree search]1979 Bruce Wilson’s Go program beats low-level amateurs [knowledge systems] 1980 Moor plays the world Othello champion (1-5)1994 Chinook plays the world checkers champion (2-4-33)1997 Deep Blue plays Gary Kasparov at chess (2-1-3)2006 “The year of the Monte Carlo revolution in Go” - Coulum discovers MCTS2011 IBM Watson plays Ken Jennings at Jeopardy ($77,147 - $24,000)2013 Crazy Stone beats a handicapped Go pro player [Monte Carlo tree search]2015 AlphaGo beats the European Go champion Fan Hui (5-0) [neural networks]2016 AlphaGo beats the Go world champion Lee Sedol (4-1)

A FEW EXPERT PREDICTIONS
2007Deep Blue’s chief engineer
Feng-Hsiung Hsu
Monte Carlo techniques “won’t play a
significant role in creating a machine that can top the best
human players” in Go.
It will take “10 years” for a machine to win against a pro
Go player without a handicap... “I don’t like making
predictions.”
2014MCTS Researcher
Rémi Coulom

ENTER ALPHAGO
The hunt
Google DeepMind, enjoying the success of their Atari-playing deep Q network (DQN), was looking for the next milestone to tackle.
The opening
In 2006, computer Go was reenergized by the discovery of a new search method: Monte Carlo search trees. However, move evaluation and selection policies were still shallow and/or linear functions.
The gamble
DeepMind saw the chance to build a hybrid system to beat Go, combining MCST with their state-of-the-art neural networks, which have excelled at complex pattern recognition.
Photo: Google DeepMind

LEE SEDOL IN GAME 5 AGAINST ALPHAGO

1.2. METHOD
THE ALPHAGO APPROACH
Overview
Training Pipeline Visualization
Policy & Value Networks
Searching with MCTS

OVERVIEW Program reads in board state s
AlphaGo selects an action using a novel MCST implementation that isintegrated with neural networks, which evaluate and choose actions.
MCST simulates n search tree sequences, selecting an action at each timestep based on action value (initially zero) and prior probability (output of policy network) and an exploration parameter.
The action value of a leaf node is a weighted sum of output of the value network and the output (win/loss) of a direct terminal rollout from that node
At the end of the n simulations, action values and visit counts for each traversed leaf node are updated
AlphaGo then backpropogates - or returns and reports - the mean value of all subtree evaluations up to each adjacent, legal action. Then, it chooses the action with the highest action value (or the leaf node most visited).

OVERVIEW
Photo: Wikimedia

OVERVIEW
Photo: Wikimedia
AlphaGo is essentially a search algorithm - specifically, a modified implementation of Monte Carlo tree search with DeepMind’s proprietary neural networks plugged in. The basic idea of MCTS is to expand the search tree through random sampling of the search space.
Backpropogation (the reporting stage of the algorithm) ensures that good paths are weighted more heavily in each additional simulation. Thus, the tree grows asymmetrically as the method concentrates on the more promising subtrees.
Here comes the main difficulty: 250150 sequences is still a lot of moves to explore, so the effect of MCTS, though considerable, is ultimately limited. That is, unless we have some other method for sorting out which branches are worth exploring… like DeepMind’s neural networks.

AN ASIDE ON NEURAL NETWORKS
Photo: Wikimedia
Chief among ongoing mysteries is why AlphaGo’s neural networks continue to outperform other hybrids of MCTS and neural nets.
The realistic answer is there is much more to their implementation of neural nets than is outlined in their paper.
What follows does not remotely approximate pseudocode, and is merely the skeleton of AlphaGo’s structure and training pipeline.

TRAINING PIPELINE VISUALIZATION
Photo: Nature

POLICY SUPERVISED LEARNING (SL)
Photo: Nature
Training data
30 million positions from the KGS Go server.
Methodology
The SL policy network (13 layers) and rollout policy network (fewer layers) are trained on state-action pairs randomly sampled from the data.
OutcomeThe networks are learning to recognize which possible action a has the greatest likelihood of being selected in state s.

POLICY NETWORK TRANSITION
Photo: Nature
Parallel structures
The weights of the reinforcement learning (RL) policy network is initialized to the current weights as the SL network

POLICY REINFORCEMENT LEARNING
Photo: Nature
Training the RL policy network
The current policy network plays games with a random past iteration of the network - not with its immediate predecessor, which would lead to overfitting.
Methodology
The weights in the network are updated using policy gradient learning to appropriately reward winning and losing policies.
OutcomeThe policy network is now optimized for winning games, not just accurately predicting the next move.

VALUE REINFORCEMENT LEARNING
Photo: Nature
Training the RL value network
Uses 30 million distinct positions sampled from separate games between policy networks.
Methodology
The weights in the network trained using regression on state-outcome pairs, minimizing the error between the predicted and actual result.
OutcomeThe value network outputs a probability of a game’s expected outcome given any state of the board.
VALUE REINFORCEMENT LEARNING
Photo: Nature
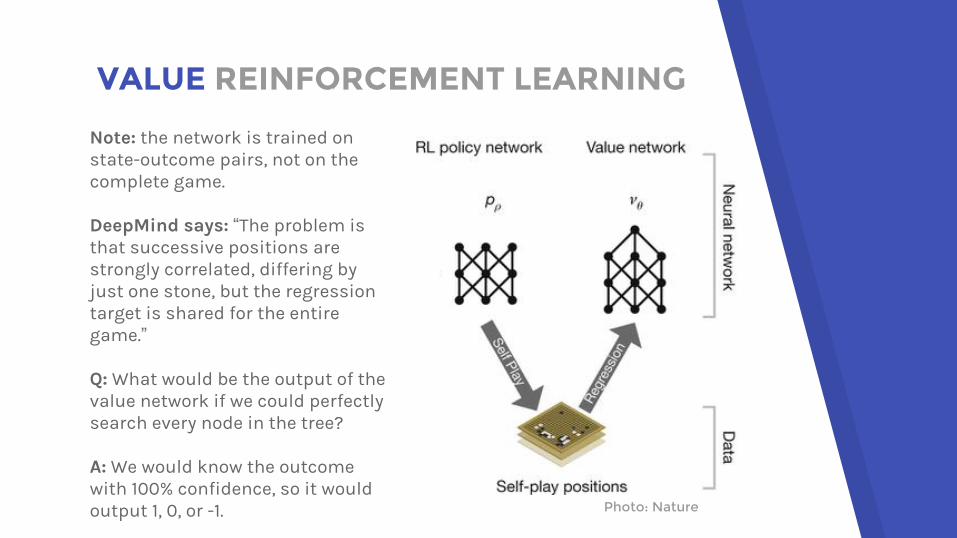
Note: the network is trained on state-outcome pairs, not on the complete game.
DeepMind says: “The problem is that successive positions are strongly correlated, differing by just one stone, but the regression target is shared for the entire game.”
Q: What would be the output of the value network if we could perfectly search every node in the tree?
A: We would know the outcome with 100% confidence, so it would output 1, 0, or -1.

SEARCHING WITH POLICY & VALUE NETWORKS
Photo: NaturePhoto: Nature
Actual Gameplay
Let’s say AlphaGo begins a game of Go. By this time, it has already “asynchronously” trained its neural networks (learned probability weights for each board position, hopefully in a smart way) long before the game begins.
At each step of the game, AlphaGo reads in a board position. Since there are so many board positions, it needs a fast way to look them up.
AlphaGo uses a modified Monte Carlo tree search to run n simulations (however many it can run in the time allotted per turn), evaluates what it learned, and then chooses its next move.

SEARCHING WITH POLICY & VALUE NETWORKS
Photo: NaturePhoto: Nature

SEARCHING WITH POLICY & VALUE NETWORKS
Photo: NaturePhoto: Nature
At each step in a simulation, AlphaGo selects and expands into the next node based on three things:
1) The action value of the node (initialized at zero in each simulation)
2) The prior probability associated with the node (learned from expert games and self-play)
3) An exploration parameter (to favor nodes not yet visited)

SEARCHING WITH POLICY & VALUE NETWORKS
Photo: NaturePhoto: Nature
After expanding into a node, AlphaGo evaluates it using two methods :
1) The value network processes the node and returns a value.
2) The fast policy network runs a rollout to the end of the tree, and returns the outcome: win, loss, or draw.

SEARCHING WITH POLICY & VALUE NETWORKS
Photo: NaturePhoto: Nature
The algorithm then takes a weighted sum of those two values, and propagates the new information back up the tree.
That updating changes the action values to reflect what this simulation learned, allowing the next simulation to incorporate that information into its decision process.

SEARCHING WITH POLICY & VALUE NETWORKS
When n simulations have been completed (i.e. the allotted time per turn is almost expired), AlphaGo updates the action values and visit counts of all traversed edges so that “each edge accumulates the visit count and mean evaluation of all simulations passing through that edge.”
At that point, the algorithm will have visit counts and action values for each legal action, and will choose the “principal variation”, the move from the current position that was most frequently visited in the simulations.

SEARCHING WITH POLICY & VALUE NETWORKS
Photo: Nature
At this point, all of our simulations combine to single out the principal variation,the move that was most frequently visited over the n simulations.

COMPETITION WIN RATES
AlphaGo (single machine) vs. other Go programs 494/495
AlphaGo (distributed version) vs. other Go programs -/-
AlphaGo (distributed version) vs. AlphaGo (single machine) -/-
AlphaGo (distributed version) vs. Fan Hui (European Go champion) 5/5
AlphaGo (distributed version) vs. Lee Sedol (World Go champion) 4/5
98.0%
100.0%
77.0%
100.0%
80.0%

The chief weakness is that the machine will not learn by mistakes. The only way to improve its play is by improving the program.
Some thought has been given to designing a program which is self-improving but, although it appears to be possible, the methods thought of so far do not seem to be very practical.
Claude Shannon
Programming a Computer to Play Chess

THANK YOU
ResourcesProgramming a Computer to Play Chess
Mastering the Game of Go with Deep Neural Networks and Tree Search
The Mystery Of Go, The Ancient Game That Computers Still Can’t Win
UCLA Stats 232B Course Notes
Deep Learning for Artificial General Intelligence