hmm hidden markov model hidden markov model. cpg islands cpg islands in human genome, cg...
TRANSCRIPT

HMM
Hidden Markov Model

CpG islands
In human genome, CG dinucleotides are relatively rare CpG pairs undergo a process called
methylation that modifies the C nucleotide
A methylated C mutates (with relatively high chance) to a T
Promotor regions are CG rich These regions are not methylated, and
thus mutate less often These are called CG (aka CpG) islands


Initiation of Transcription from a Promoter

Properties of CpG Islands


Finding CpG islands
Simple approach: Pick a window of size N
(N = 100, for example) Compute log-ratio for the sequence in the
window, and classify based on that
Problems: How do we select N ? What do we do when the window
intersects the boundary of a CpG island?

Slot machine

Fair Bet Casino The game is to flip coins, which results in
only two possible outcomes: Head or Tail. The Fair coin will give Heads and Tails
with same probability ½. The Biased coin will give Heads with
prob. ¾.
Fair coin: ½ ½
Biased coin: ¾ ¼

The “Fair Bet Casino” (cont’d)
Thus, we define the probabilities: P(H|F) = P(T|F) = ½ P(H|B) = ¾, P(T|B) = ¼ The crooked dealer changes
between Fair and Biased coins with probability 10%
Game start:
T H H H H T T T T H T
F FF F F F FBBB B

The Fair Bet Casino Problem
Input: A sequence x = x1x2x3…xn of coin tosses made by two possible coins (F or B).
Output: A sequence π = π1 π2 π3…
πn, with each πi being either F or B indicating that xi is the result of tossing the Fair or Biased coin respectively.

Log-odds Ratio
We define log-odds ratio as follows:
log2(P(x|fair coin) / P(x|biased coin)) = Σk
i=1 log2(p+(xi) / p-
(xi))
= n – k log23

Log-odds Ratio in Sliding Windows
x1x2x3x4x5x6x7x8…xn
Consider a sliding window of the outcome sequence. Find the log-odds for this short window.
Log-odds value
0
Fair coin most likely used
Biased coin most likely used
Disadvantages:- the length of Fair coin seq is not known in advance- different windows may classify the same position differently

HMM

Markov Process & Transition Matrix
A stochastic process for which the probability of entering a certain state depends only on the last state occupied is called a Markov process. The process is governed by a transition matrix.
Ex. Suppose that the 1995 state of land use in a city of 50 square miles of area is
Assuming that the transition matrix for 5-year intervals are given by
The 2000 state: I (Residential) = ?
I (residential used) 30%II (commercially used) 20%III (industrially used) 50%
To I To II To III
From I 0.8 0.1 0.1
From II
0.1 0.7 0.2
From III
0 0.1 0.9
.8*30+.1*20+0*50 = 26%

Markov ModelA stochastic process for which the
probability of entering a certain state depends only on the last state occupied is called a Markov process.
Residentiallyused
Commerciallyused
Industriallyused
0.8
0.1 0.9
0.0
0.1
0.2
0.7
0.1 0.1
RIICCRRRCCII
Markov Chain

Basic Mathematics Markov chains: probability of a
sequence: S=a1a2...an
P(S)=P(a1)P(a2|a1)P(a3|a1 a2)...P(an|a1... an-1) P(S)=P(a1)P(a2|a1)P(a3|a2)...P(an|an-1) P(S)=P(a1) P P(ai|ai-1)
ExerciseProbability of sequence CATG
Bayes’ theorem
A T G C
A 0.2 0.35 0.15 0.3
T 0.25 0.15 0.4 0.2
G 0.25 0.25 0.25 0.25
C 0.3 0.25 0.2 0.25

Hidden Markov Model1 2 4 3 1 4 5 2 3 4 6 1 2 2 1 …Which dice was used is hidden.

HMM The state sequence is hidden The process is governed by a transition
matrix
akl = P (i=l | i-1=k) and emission probabilities
ek(b)= P (xi=b | i=k) HMMs: prob. depends on states passed
thru if known: (states = s1 s2 ... sn)
P(Seq)=P(a1|s1)P(s2|s1)P(a2|s2)P(s3|s2)...P(sn|sn-
1)P(an|sn) if unknown, sum over all possible paths find the
sequence that maximize P(S)?

Hidden Markov Model (HMM)
Can be viewed as an abstract machine with k hidden states that emits symbols from an alphabet Σ.
Each state has its own probability distribution, and the machine switches between states according to this probability distribution.
While in a certain state, the machine makes 2 decisions: What state should I move to next? What symbol - from the alphabet Σ -
should I emit?
Why “Hidden”?
Observers can see the emitted symbols of an HMM but have no ability to know which state the HMM is currently in.
Thus, the goal is to infer the most likely hidden states of an HMM based on the given sequence of emitted symbols.

Fair Bet Casino Problem
Fair Bet Casino ProblemAny observed outcome of coin tosses could have been generated by any sequence of states!
Need to incorporate a way to grade different sequences differently.
Decoding Problem

HMM Parameters
Σ: set of emission characters.Ex.: Σ = {H, T} for coin tossing
Σ = {1, 2, 3, 4, 5, 6} for dice tossing Σ = {A, C, G, T} for a DNA seq
Q: set of hidden states, each emitting symbols from Σ.
Q={F,B} for coin tossing Q={intron, exon} for a gene

HMM Parameters (cont’d)
A = (akl): a |Q| |Q| matrix of probability of changing from state k to state l.
aFF = 0.9 aFB = 0.1
aBF = 0.1 aBB = 0.9
E = (ek(b)): a |Q| |Σ| matrix of probability of emitting symbol b while being in state k.
eF(0) = ½ eF(1) = ½
eB(0) = ¼ eB(1) = ¾

HMM for Fair Bet Casino The Fair Bet Casino in HMM terms:
Σ = {0, 1} (0 for Tails and 1 Heads)Q = {F,B} – F for Fair & B for Biased coin.
Transition Probabilities A *** Emission Probabilities EFair Biased
Fair aFF = 0.9
aFB = 0.1
Biased
aBF = 0.1
aBB = 0.9
Tails(0) Heads(1)
Fair eF(0) = ½
eF(1) = ½
Biased
eB(0) = ¼
eB(1) = ¾

HMM for Fair Bet Casino (cont’d)
HMM model for the Fair Bet Casino Problem

Hidden Paths A path π = π1… πn in the HMM is defined
as a sequence of states. Consider path π = FFFBBBBBFFF and
sequence x = 01011101001 (0=T, 1=H)
x 0 1 0 1 1 1 0 1 0 0 1
π = F F F B B B B B F F FP(xi|πi) ½ ½ ½ ¾ ¾ ¾ ¼ ¾ ½ ½ ½
P(πi-1 πi) ½ 9/10 9/10 1/10
9/10 9/10
9/10 9/10
1/10 9/10
9/10 Transition probability from state πi-1 to state πi
Probability that xi was emitted from state πi

Decoding Problem
Goal: Find an optimal (most probable) hidden path of states given observations.
Input: Sequence of observations x = x1…xn generated by an HMM M(Σ, Q, A, E)
Output: A path that maximizes P(x, π) over all possible paths π.

Decoding Problem
T H H H H T T T TF
B

P(x, π) Calculation
P(x, π): Probability that sequence x was generated by the path π: n
P(x, π) = P(π0→ π1) · Π P(xi|πi) · P(πi → πi+1)
i=1
= a π0, π1 · Π e πi (xi) · a πi,
πi+1
= Π e πi+1 (xi+1) · a
πi, πi+1
if we count from i=0 instead of i=1 to
i=n
Number of possible paths?

Building Manhattan for Decoding Problem
Andrew Viterbi used the Manhattan grid model to solve the Decoding Problem.
Every choice of π = π1… πn
corresponds to a path in the graph. The only valid direction in the graph
is eastward. This graph has |Q|2(n-1) edges.
?


Graph for Decoding Problem

Decoding Problem vs. Alignment Problem
Valid directions in the alignment problem.
Valid directions in the decoding problem.

Decoding Problem as Finding a Longest Path
in a DAG The Decoding Problem is reduced to
finding a longest path in the directed acyclic graph (DAG) above.
Notes: the length of the path is defined as the product of its edges’ weights, not the sum.

Decoding Problem: weights of edges
The weight w = el(xi+1) . akl
w?
(k, i) (l, i+1)
T H H H H T T T TF
B

Decoding Problem n
Maximize: P(x, π) = Π e πi+1 (xi+1) . a πi, πi+1
i=0

Decoding Problem (cont’d)
Every path in the graph has the probability P(x,π) (= length of the path).
The Viterbi algorithm finds the path that maximizes P(x, π) among all possible paths.
The Viterbi algorithm runs in O(n|Q|2) time.
?

Decoding Problem and Dynamic Programming
sl,i+1=maxk Q {sk,i · weight of (k,i) (l,i+1)}
=maxk Q {sk,i · akl · el (xi+1)}
=el (xi+1) · maxk Q {sk,i · akl}
lk
i i+1

Decoding Problem (cont’d)
Initialization: sbegin,0 = 1
sk,0 = 0 for k ≠ begin.
Let π* be the optimal path. Then,
P(x, π*) = maxk Є Q {sk,n . ak,end}

Most probable path: Viterbi alg
Dynamic programming define pi,j as the prob of the most probable path
ending in state j after emitting element i Define solution recursively:
suppose we know pi-1,j states up to previous char
update: pi,k=P(ai, sk) * maxj(pi-1,j*P(sk, sj)) traceback
keep table of state probs, start with 1st char, assign prob to each state, iterate updates...
a1 a2 a3 a4s1 0.6 0.9 0.9 0.2s2 0.1 0.1 0.05 0.8s3 0.3 0 0.05 0

Most probable path: Viterbi alg
Dynamic programming
a1 a2 a3 a4
s1 0.6 0.9 0.9 0.2
s2 0.1 0.1 0.05 0.8
s3 0.3 0 0.05 0

Problem with Viterbi Algorithm
The value of the product can become extremely small, which leads to under-flowing.
To avoid overflowing, use log value instead.
sk,i+1= log el(xi+1) + max k Є Q {sk,i + log(akl)}

Exercise
Consider a hidden Markov model with the following transition and emission matrices:
What is the most probable sequence of states for a given DNA sequence ACGG?
exon intron
exon 0.9 0.1
intron 0.05 0.95
purine pyrimidine
exon 0.3 0.7
intron 0.5 0.5

Forward-Backward Problem
Given: a sequence of coin tosses generated by an HMM.
Goal: find the probability that the dealer was using a biased coin at a particular time i.
T H H H H T T T T H T

Forward-Backward Problem
T H H H H T T T TF
Bi

Forward Algorithm Define fk,i (forward probability) as
the probability of emitting the prefix x1…xi and reaching the state πi = k.
The recurrence for the forward algorithm:
fk,i = ek(xi) Σ fl,i-1 alk l Є Q
Similar to Viterbi, except replace ‘max’ with probabilistic ‘sum’!
kl
i1 i

Dishonest Casino Computing posterior probabilities
for “fair” at each point in a long sequence:

Backward Algorithm
However, forward probability is not the only quantity that provides info to P(πi = k|x).
The sequence of transitions and emissions that the HMM undergoes between πi+1 and πn also affect P(πi = k|x).
forward xi backward

Define backward probability bk,i as the probability of being in state πi = k and emitting the suffix xi+1…xn.
The recurrence for the backward algorithm:
bk,i = Σ akl el(xi+1) bl,i+1
l Є Q
Backward Algorithm (cont’d)
k l
i i+1

The probability that the dealer used a biased coin at any moment i:
P(x, πi = k) fk(i) . bk(i)
P(πi = k|x) = _______________ = ____________
P(x) P(x)
Backward-Forward Algorithm
P(x) is the sum of P(x, πi = k) over all k
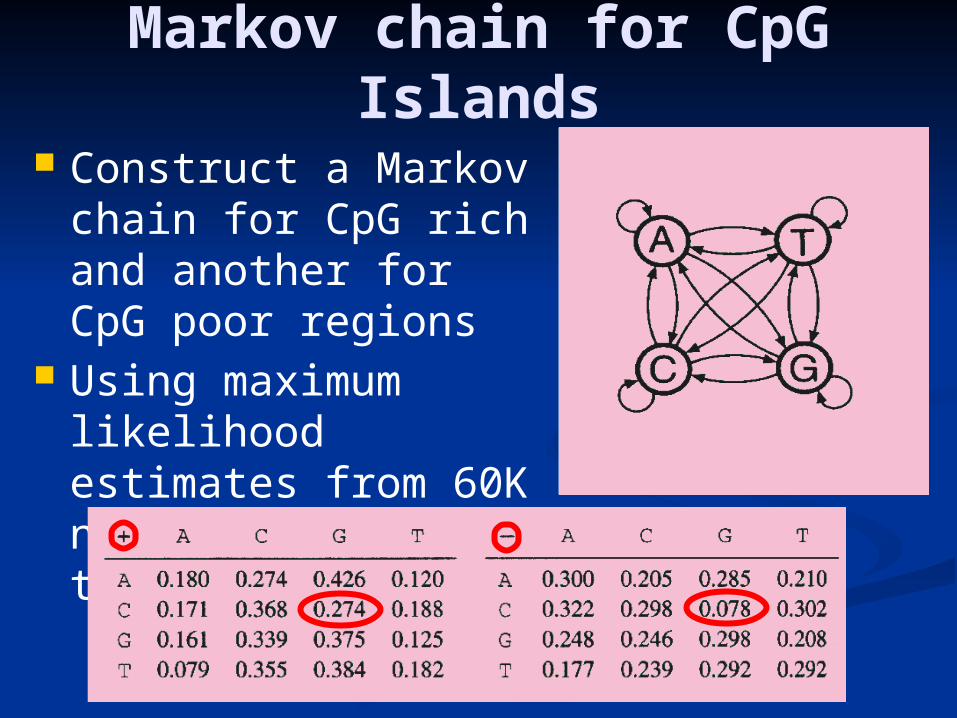
Markov chain for CpG Islands
Construct a Markov chain for CpG rich and another for CpG poor regions
Using maximum likelihood estimates from 60K nucleotide, the two models:

Ratio Test for CpC islands
Given a sequence X1,…,Xn , compute the likelihood ratio
1
1
1
11
1
( , , | )( , , ) log
( , , | )
log i i
i i
i i
nn
n
X X
i X X
X Xi
P X XS X X
P X X
A
A
2
2

HMM Approach Build one model that include “+” states
and “-” states
A state “remembers” last nucleotide and the type of region
A transition from a state to a + corresponds to the start of a CpG island

p? q?