high throughput dna sequencing. 30,000 shotgun sequencing isolate chromosome sheardna into fragments...
Post on 22-Dec-2015
229 views
TRANSCRIPT

High Throughput DNA Sequencing
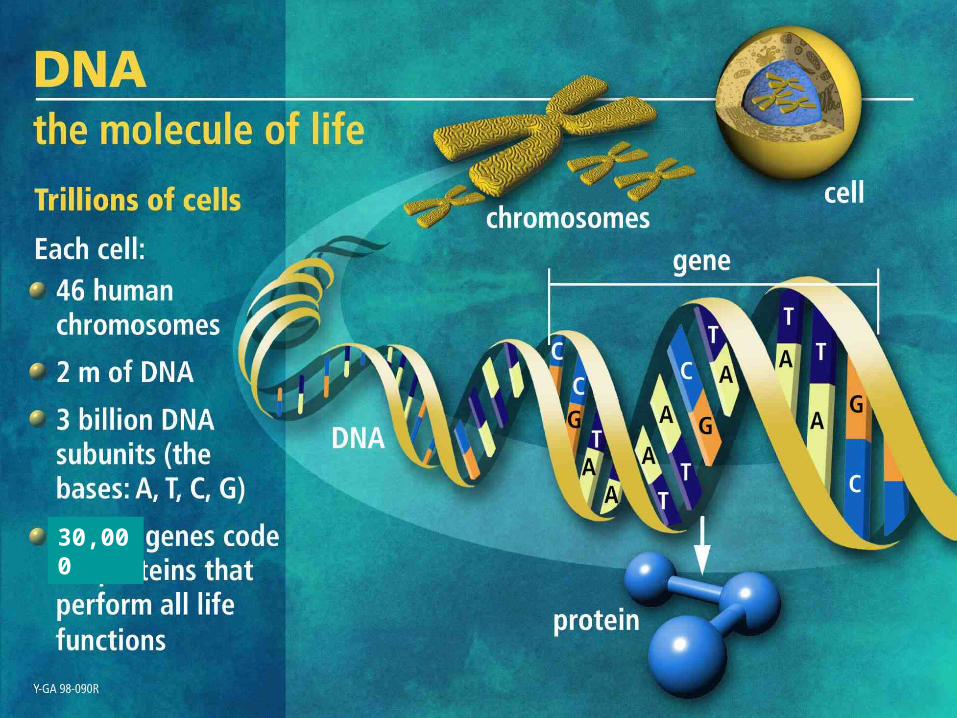
30,000

Shotgun Sequencing
IsolateChromosome
ShearDNAinto Fragments
Clone intoSeq. Vectors Sequence

Principles of DNA Sequencing
Primer
PBR322
Amp
Tet
Ori
DNA fragment
Denature withheat to produce
ssDNA
Klenow + ddN + dN+ primers

The Secret to Sanger Sequencing
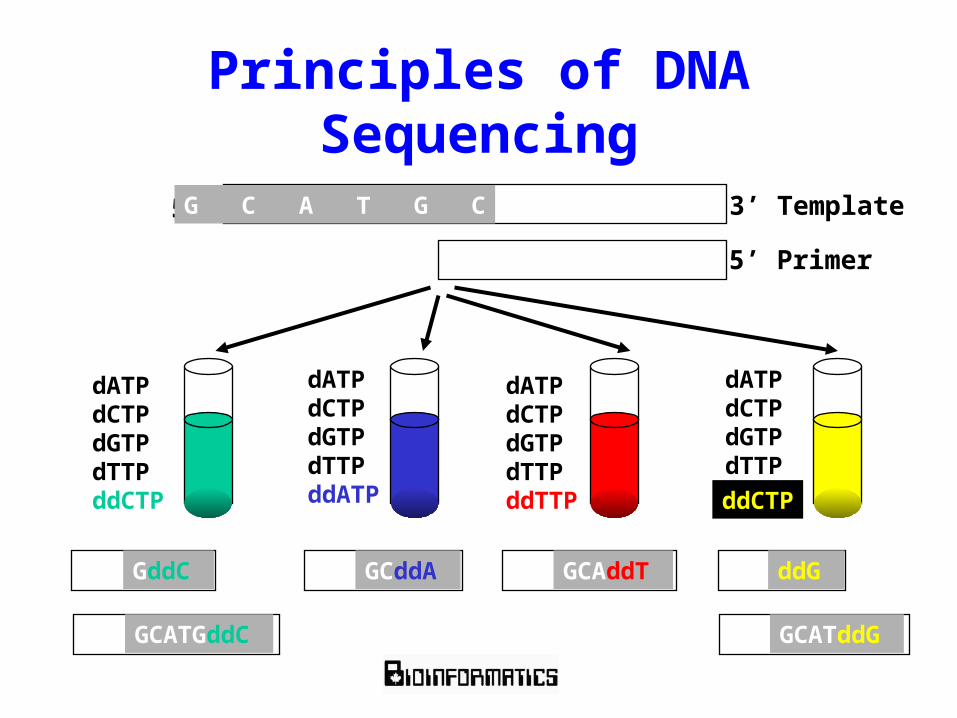
Principles of DNA Sequencing
5’
5’ Primer
3’ TemplateG C A T G C
dATPdCTPdGTPdTTPddATP
dATPdCTPdGTPdTTPddCTP
dATPdCTPdGTPdTTPddTTP
dATPdCTPdGTPdTTP
ddCTP
GddC
GCATGddC
GCddA GCAddT ddG
GCATddG

Principles of DNA SequencingG
C
T
A
+
_
+
_
G
C
A
T
G
C

Capillary Electrophoresis
Separation by Electro-osmotic Flow

Multiplexed CE with Fluorescent detection
ABI 3700 96x700 bases

Shotgun Sequencing
SequenceChromatogram
Send to Computer AssembledSequence

Shotgun Sequencing
• Very efficient process for small-scale (~10 kb) sequencing (preferred method)
• First applied to whole genome sequencing in 1995 (H. influenzae)
• Now standard for all prokaryotic genome sequencing projects
• Successfully applied to D. melanogaster• Moderately successful for H. sapiens

The Finished Product
GATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTAGAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGATTACAGAT

Sequencing Successes
T7 bacteriophagecompleted in 198339,937 bp, 59 coded proteins
Escherichia colicompleted in 19984,639,221 bp, 4293 ORFs
Sacchoromyces cerevisaecompleted in 199612,069,252 bp, 5800 genes

Sequencing Successes
Caenorhabditis eleganscompleted in 199895,078,296 bp, 19,099 genes
Drosophila melanogastercompleted in 2000116,117,226 bp, 13,601 genes
Homo sapiens1st draft completed in 20013,160,079,000 bp, 31,780 genes

Scoring Matrices• An empirical model of evolution, biology and
chemistry all wrapped up in a 20 X 20 table of integers
• Structurally or chemically similar residues should ideally have high diagonal or off-diagonal numbers
• Structurally or chemically dissimilar residues should ideally have low diagonal or off-diagonal numbers
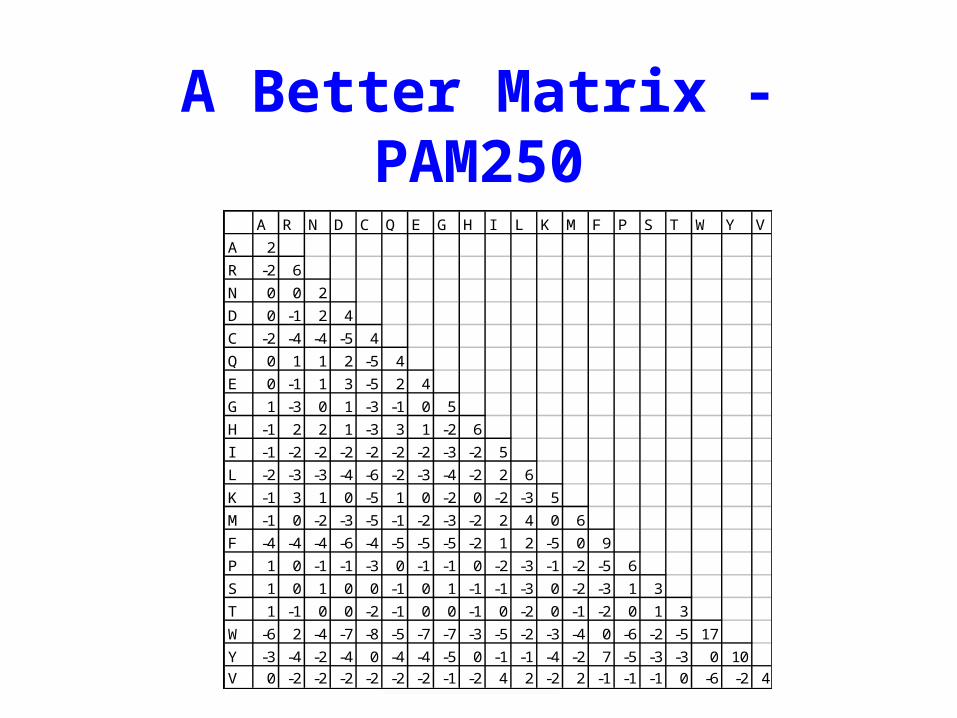
A Better Matrix - PAM250A R N D C Q E G H I L K M F P S T W Y V
A 2
R -2 6
N 0 0 2
D 0 -1 2 4
C -2 -4 -4 -5 4
Q 0 1 1 2 -5 4
E 0 -1 1 3 -5 2 4
G 1 -3 0 1 -3 -1 0 5
H -1 2 2 1 -3 3 1 -2 6
I -1 -2 -2 -2 -2 -2 -2 -3 -2 5
L -2 -3 -3 -4 -6 -2 -3 -4 -2 2 6
K -1 3 1 0 -5 1 0 -2 0 -2 -3 5
M -1 0 -2 -3 -5 -1 -2 -3 -2 2 4 0 6
F -4 -4 -4 -6 -4 -5 -5 -5 -2 1 2 -5 0 9
P 1 0 -1 -1 -3 0 -1 -1 0 -2 -3 -1 -2 -5 6
S 1 0 1 0 0 -1 0 1 -1 -1 -3 0 -2 -3 1 3
T 1 -1 0 0 -2 -1 0 0 -1 0 -2 0 -1 -2 0 1 3
W -6 2 -4 -7 -8 -5 -7 -7 -3 -5 -2 -3 -4 0 -6 -2 -5 17
Y -3 -4 -2 -4 0 -4 -4 -5 0 -1 -1 -4 -2 7 -5 -3 -3 0 10
V 0 -2 -2 -2 -2 -2 -2 -1 -2 4 2 -2 2 -1 -1 -1 0 -6 -2 4
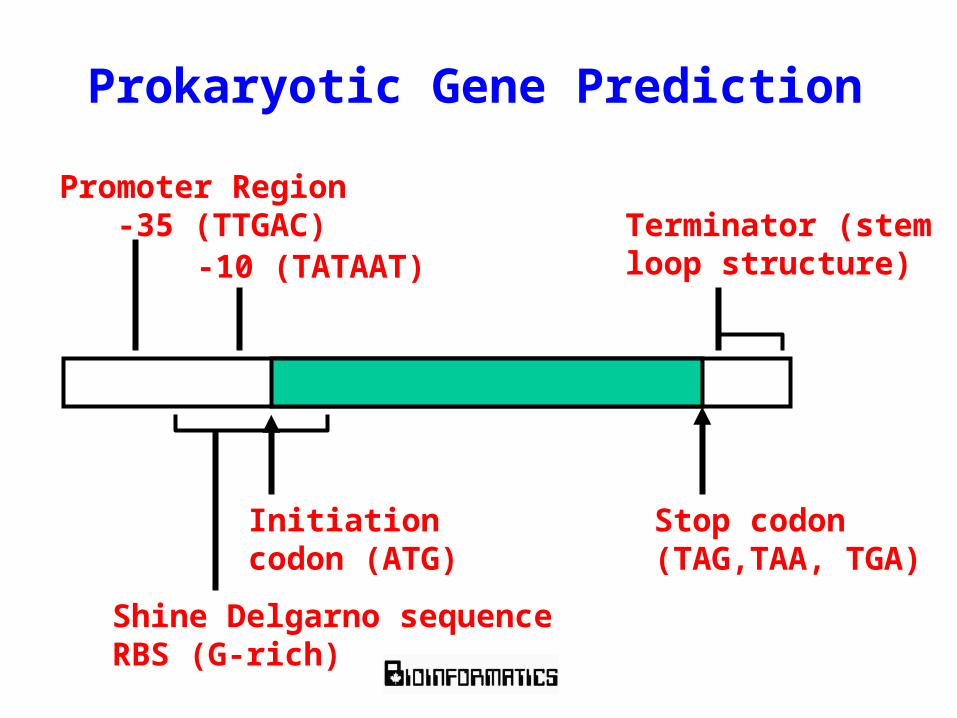
Prokaryotic Gene Prediction
Initiationcodon (ATG)
Stop codon(TAG,TAA, TGA)
Shine Delgarno sequenceRBS (G-rich)
Terminator (stemloop structure)
Promoter Region -35 (TTGAC)
-10 (TATAAT)

Prokaryotic Gene Prediction
• ORF finder – http://www.ncbi.nlm.nih.gov/gorf/gorf.html
• GLIMMER– http://www.tigr.org/softlab/glimmer/glimmer.html
• GeneMark– exon.biology.gatech.edu/GeneMark/– www.ebi.ac.uk/genemark


Hidden Markov Model


Eukaryotic Gene Prediction
5’site 3’site
branchpoint site
exon 1 intron 1 exon 2 intron 2
AG/GT CAG/NT

Gene Predictors
• GRAIL2 (http://compbio.ornl.gov/Grail-1.3/)
• Neural Network Model CC=0.47
• HMMgene (http://www.cbs.dtu.dk/services/HMMgene/)
• Hidden Markov Model CC=0.91
• GENSCAN (http://genes.mit.edu/GENSCAN.html)
• Probabilistic Model CC=0.91
• GRPL (GeneTool)• Reference Point Logistics CC=0.94




Evaluation Statistics
TP FP TN FN TP FN TN
Actual
Predicted
Sensitivity Fraction of actual coding regions that are correctly predicted as codingSn=TP/(TP + FN)
Specificity Fraction of the prediction that is actually correctSp=TP/(TP + FP)
Correlation Combined measure of sensitivity and specificityCC=(TP*TN-FP*FN)/[(TP+FP)(TN+FN)(TP+FN)(TN+FP)]0.5

Gene PredictionA
ccu
racy
(%
)A
ccu
racy
(%
)
MethodMethod
61 63
7276
8694 97
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
80.0
90.0
100.0
Xpound GeneID GRAIL 2 Genie GeneP3 RPL RPL+

What Works Best?
• Expect only a single exon…– BLASTN vs. dbEST– BLASTX vs. nr(protein)
• Fully sequenced data– Run GENSCAN + HMMgene + GRPL– Combine predictions (CC > 0.95)– BLAST vs. nr(protein)– Combine BLAST result with prediction
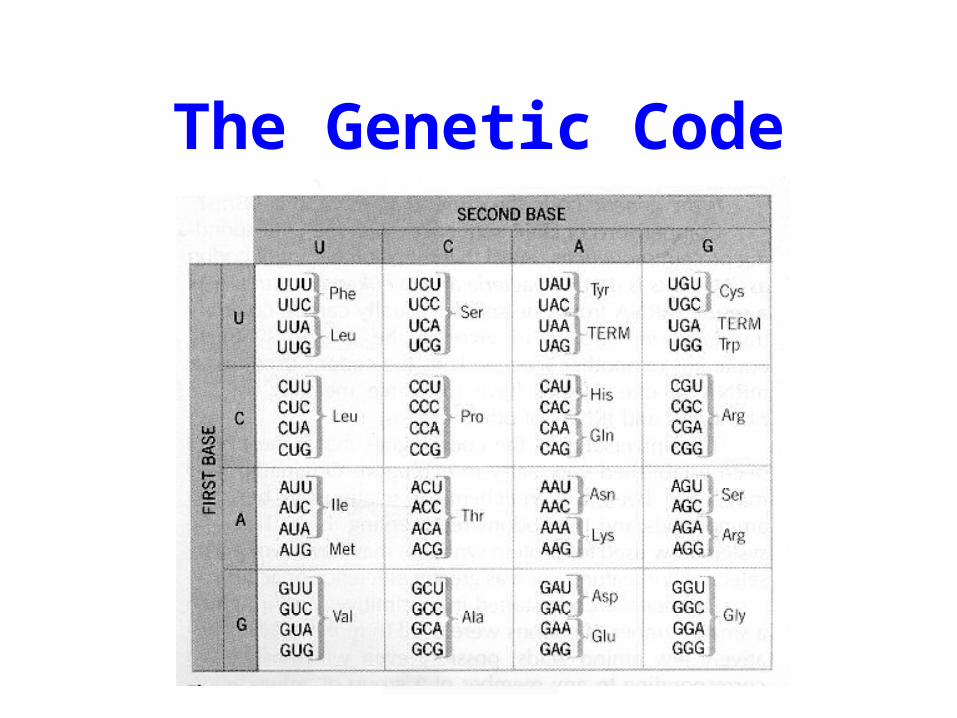
The Genetic Code

Translation
ATGCGTATAGCGATGCGCATTTACGCATATCGCTACGCGTAA
Frame3 A Y S D A HFrame2 C V * R C AFrame1 M R I A M R I
Frame-1 H T Y R H A NFrame-2 R I A I R MFrame-3 A Y L S A C

From Sequence to Function (and Structure)
ACEDFHIKNMFACEDFHIKNMFSDQWWIPANMCSDQWWIPANMCASDFDPQWEREASDFDPQWERELIQNMDKQERTLIQNMDKQERTQATRPQDS...QATRPQDS...

PROSITE Pattern Expressions
C - [ACG] - T - Matches CAT, CCT and CGT only
C - X -T - Matches CAT, CCT, CDT, CET, etc.
C - {A} -T - Matches every CXT except CAT
C - (1,3) - T - Matches CT, CCT, CCCT
C - A(2) - [TP] - Matches CAAT, CAAP
[LIV] - [VIC] - X(2) - G - [DENQ] - X - [LIVFM] (2) -G

PepTool Pattern Expressions
C[ACG]T - Matches CAT, CCT and CGT only
C*T - Matches CAT, CCT, CDT, CET, etc.
C!AT - Matches every C * T except CAT
C{1,3}T - Matches C*T, C * * T, C * * * T
$CAA(TP] - Matches CAAT, CAAP at N terminus
[LIV][VIC] * * G[DENQ] *[LIVFM][LIVFM]* G

Protein Sequence Motifs
• Pattern-Based (PQL) Sequence Motifs• >*TCP&NLGT*• DOOLITTLE, R.F., OF URFS AND ORFS (1986)• GUANIDINE KINASE ACTIVE SITE
• Profiles or Position Scoring Matrix (PSSM)• A C D E F G H I K L M N P Q R
• 1 W G V L V 3 -2 3 4 0 4 -1 3 -1 4 4 1 1 1 -2
• 2 L L S P L 2 -2 -2 -1 3 0 -1 3 -1 6 5 -1 3 0 -1
• 3 V V V V V 2 2 -2 -2 2 2 -3 11 -2 8 6 -2 1 -2 -2
• 4 K E A T A 6 -2 5 6 -5 4 1 0 5 -2 0 3 3 3 1
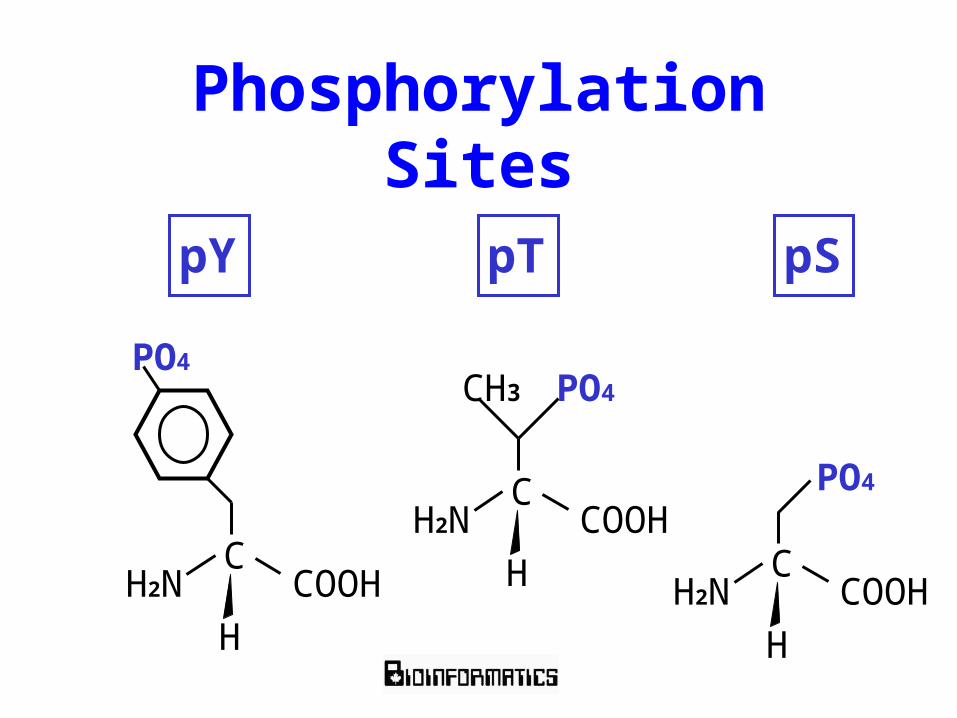
Phosphorylation Sites
CCOOHH2N
H
PO4
CCOOHH2N
H
PO4CH3
CCOOHH2N
H
PO4
pY pT pS

Phosphorylation SitesPhopshorylation Sites>*KRKQI[ST]VR* CHAN K.F. et al., J. BIOL. CHEM. 257:3655-3659 (1982) PHOSPHORYLASE KINASE PHOSPHORYLATION SITE
>*KKR**R**[ST]* KEMP B.E. et al., PNAS 72:3448-3452 (1975) MYOSIN LIGHT CHAIN KINASE PHOSPHORYLATION SITE
>*NYLRRL[ST]DSNF* CZERNIK A.J. et al. PNAS 84:7518-7522 (1987)
CALMODULIN DEPENDENT PROTEIN KINASE I PHOSPHORYLATION SITE

Glycosylation

Glycosylation Sites
Glycosylation Sites>*N!P[ST]!P* MARSHALL, R.D.W. ANN. REV. BIOCHEM. 41:673-702 (1972) GLYCOSYLATION SITE (S AND/OR T ARE GLYCOSYLATED)
>*G*K*R* MARSHALL, R.D.W. ANN. REV. BIOCHEM. 41:673-702 (1972) GLYCOSYLATION SITE (K IS GLYCOSYLATED)
>*G*K**R* MARSHALL, R.D.W. ANN. REV. BIOCHEM. 41:673-702 (1972) GLYCOSYLATION SITE (K IS GLYCOSYLATED)

Signaling

Signaling SitesSignaling Sites>*[KRH][DEN]EL$ SMITH M.J. et al., EMBO J. 8:3581-3586 (1989) ENDOPLASMIC RETICULUM DIRECTING SEQUENCE
>*P***KKRKAV* KALDERON, D. et al., CELL 39:400-509 (1984) NUCLEAR TRANSPORT SIGNAL OF SV40 LARGE T ANTIGEN
>${3,20}[LIVFTA][LIVFTA][LIVFTA]{3,6}[LIV]*[GA]C* VON HEIJNE, G. PROT. ENG. 2:531-534 (1989)
SIGNAL PEPTIDASE II CLEAVAGE SITE

Protease Cut Sites

Protease Cut Sites
Protease Cut Sites>*[KR]* *[KR]/* TRYPSIN CLEAVAGE SITE (CUTS AFTER [KR])
>*[FLY]![VAG] */[FLY]![VAG] PEPSIN CLEAVAGE SITE (CUTS BEFORE [FY])
>*[FWY]* *[FWY]/* CHYMOTRYPSIN CLEAVAGE SITE (CUTS AFTER [FWY])

Binding SitesBinding Sites>*RGD* RUOSLAHTII E. et al., CELL 44:517-518 (1986) FIBRONECTIN ADHESION SITE
>*CDPGYIGSR* GRAF, J. et al., CELL 48:989-996 (1987) MAMMAL LAMNIN DOMAIN III B1 CHAIN CELL ATTACHMENT SITE
>*[VIL]**[TS][DN]Y**[FY][AL]* GODOVAC-ZIMMERMANN, J., TIBS 13:64-66 (1988)
BINDING SITE FOR HYDROPHOBIC MOLECULE TRANSPORT PROTEINS

Family Signature Sequences
Protein Family Signature Sequences>*[FY]CRNPD* NAKAMURA T. et al., NATURE 342:441-445 (1989) KRINGLE DOMAIN SIGNATURE
>*[LIVM][LIVM]DEAD*[LIVM][LIVM]* CHANG T.H. et al., PNAS 87:1571-1575 (1990) EIF 4A FAMILY ATP DEPENDENT HELICASE SIGNATURE
>*C*C*****G**C* BLOMQUIST M.C. et al., PNAS 81:7363-7362 (1984)
EGF/TGF SIGNATURE SEQUENCE

Enzyme Active SitesEnzyme Active Sites>*[MAFILV]DTG[STA][STAN]* DOOLITTLE, R.F., OF URFS AND ORFS, 1986 ACID OR ASPARTYL PROTEASE ACTIVE SITE
>*TCP&NLGT* DOOLITTLE, R.F., OF URFS AND ORFS, 1986 GUANIDINE KINASE ACTIVE SITE
>*F*[LIVFMY]*S**K****[AG]*[LIVM]L*JORIS, B. ET AL., BIOCHEM. J. 250:313-324 (1989)BETA LACTAMASE (TYPE A) ACTIVE SITE

Sequence Pattern Databases
• PROSITE - http://www.expasy.ch/
• BLOCKS - http://www.blocks.fhcrc.org/
• DOMO - http://www.infobiogen.fr/~gracy/domo
• PFAM - http://pfam.wustl.edu
• PRINTS - http://www.biochem.ucl.ac.uk/bsm/dbrowser/PRINTS
• SEQSITE - PepTool
Sequence Profiles
PI
HAA K
AGT AA
L
AC
QRVN
A
AY
F
AG
A

Defining Sequence Profiles 1 50
P43871-1 .......... ...IKKLDSN SIHAIISDIP YGIDYDDWDI LHSNTNSALGS18997-1 LMSKIYQMDA VDWLKTLENC SVDLFITDPP YESL.EKYRQ IGTTTRLKESP23192-1 EINKIHQMNC FDFLDQVENK SVQLAVIDPP YNL....... ..........P29538-1 MDQRLICSNA IKALKNLEEN SIDLIITDPP YNLG.KDY.. ..........P14751-1 TRHVYDVCDC LDTLAKLPDD SVQLIICDPP YNI....... ..........P34721-1 KNFNIYQGNC IDFMSHFQDN SIDMIFADPP YFLS.NDG.L TFKNSIIQ..P50178-1 ENAILVHADS FKLLEKIKPE SMDMIFADPP YFLS.NGG.M SNSGGQIV..P20590-1 FLNTILKGDC IEKLKTIPNE SIDLIFADPP YFMQ.TEGKL LRTNGDEF..S43876-1 GPETIIHGDC IEQMNALPEK SVDLIFADPP YNLQ.LGGDL LRPDNSKV..P28638-1 EAKTIIHGDA LAELKKIPAE SVDLIFADPP YNIG.KNF.. ..........P23941-1 DLGKLYNGDC LELFKQVPDE NVDTIFADPP FNLD.KEY.. ..........P14230-1 RSCKIIVGDA REAVQGLDSE IFDCVVTSPP YWGL.RDY.. ..........P14243-1 NGATLFEGDA LSVLRRLPSG SVRCIVTSPP YWGL.RDY.. ..........Q04845-1 LNNMLLQGNC AETLKKLPDE SVNLVFTSPP YY........ ..........S53866-1 WVNDIHEGDA EEVLAELPES SVHMVMTSPP YFGL.RDY.. ..........P29568-1 .......... ...MNELKDK SINLVVTSPP YPMV.EIWDR LFSELNPKIE
Signature Sequence: DPP Y

A Sample Sequence Profile
A C D E F G H I K L M N P Q R S T V W Y
1 W G V L V 3 -2 3 4 0 4 -1 3 -1 4 4 1 1 1 -2 1 2 6 -6 -2
2 L L S P L 2 -2 -2 -1 3 0 -1 3 -1 6 5 -1 3 0 -1 3 1 4 1 -1
3 V V V V V 2 2 -2 -2 2 2 -3 11 -2 8 6 -2 1 -2 -2 0 2 15 -9 -1
4 K E A T A 6 -2 5 6 -5 4 1 0 5 -2 0 3 3 3 1 3 6 0 -6 -4
5 A P L P P 6 -1 0 1 -2 2 0 1 0 2 2 0 8 2 0 2 2 3 -5 -4
6 G G G G G 7 1 7 5 -6 15 -1 -3 0 -4 -3 4 3 6 1 6 2 -1 -6 -5
7 S S Q E D 4 -1 7 7 -6 7 2 -2 2 -3 -2 4 3 6 1 6 2 -1 -6 -5
8 S S T P S 4 4 2 2 -4 4 -1 0 2 -3 -2 2 7 0 1 10 6 0 -2 -4
<>i = log2(qi/pi)

Calculating a Profile Score
VLVAPGDS = 6+6+15+6+8+15+7+10=66LVLGPGLA = 4+4+8+4+8+15-3+4= 44
A C D E F G H I K L M N P Q R S T V W Y
1 W G V L V 3 -2 3 4 0 4 -1 3 -1 4 4 1 1 1 -2 1 2 6 -6 -2
2 L L S P L 2 -2 -2 -1 3 0 -1 3 -1 6 5 -1 3 0 -1 3 1 4 1 -1
3 V V V V V 2 2 -2 -2 2 2 -3 11 -2 8 6 -2 1 -2 -2 0 2 15 -9 -1
4 K E A T A 6 -2 5 6 -5 4 1 0 5 -2 0 3 3 3 1 3 6 0 -6 -4
5 A P L P P 6 -1 0 1 -2 2 0 1 0 2 2 0 8 2 0 2 2 3 -5 -4
6 G G G G G 7 1 7 5 -6 15 -1 -3 0 -4 -3 4 3 6 1 6 2 -1 -6 -5
7 S S Q E D 4 -1 7 7 -6 7 2 -2 2 -3 -2 4 3 6 1 6 2 -1 -6 -5
8 S S T P S 4 4 2 2 -4 4 -1 0 2 -3 -2 2 7 0 1 10 6 0 -2 -4

Profiles & Motifs are Useful
• Helped identify active site of HIV protease
• Helped identify SH2/SH3 class of STP’s
• Helped identify important GTP oncoproteins
• Helped identify hidden leucine zipper in HGA
• Used to scan for lectin binding domains
• Regularly used to predict T-cell epitopes

Membrane Spanning Regions

Predicting via Hydrophobicity
-3
-2
-1
0
1
2
3
4
1
Bacteriorhodopsin
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2OmpA
Bacteriorhodoposin OmpA

Predicting via Hydrophobicity
Protein Technique Predicted #helices Actual #helicesEngelman et al. 10
Microsomal cytochrome Chou & Fasman 8p 450 Rao & Argos 5
AMP07 1Eisenberg et al. 8Kyte-Doolittle 5Rao & Argos 4AMP07 4Jahnig 6Eisenberg et al. 1
Photosynthetic Reaction Rose 4 Centre (M chain) Kyte-Doolittle 4
Klein et al. 5Jahnig 7Kyte-Doolittle 4Engelman et al. 7Klein et al. 7
Quality of Membrane Helix Prediction of Membrane Proteins.
Fo-F1 ATPase (subunit A)
Bacteriorhodopsin
4
1
5
67

Predicting via Sequence Similarity
Protein Family No. of Membrane Segments
Cytokine/growth factor receptors (EGF, interleukin, Insulin receptors)G-coupled receptors (rhodopsin, bacteriorhodopsin etc.)Extracellular activated gated channels (Glutamate, GABA, ACh sensitive)
5) photosynthetic proteins (H chain) 5 (helices)6) photosynthetic proteins (L chain) 5 (helices)7) porins 17 (-strands)8) microsomal cytochrome p450 1 (helix)9) cytochrome b 1 (helix)10) Fo ATPases 4 (helices)
Intracellular activated gated channels 6 (helices)
1 (helix)
Table 6
7 (helices)
4 (helices)

Predicting via Neural Nets and PSSM’s
• PHDhtm http://dodo.cpmc.columbia.edu/predictprotein/
• TMAP http://www.mbb.ki.se/tmap/index.html
• TMPred http://www.ch.embnet.org/software/TMPRED_form.html
ACDEGF...
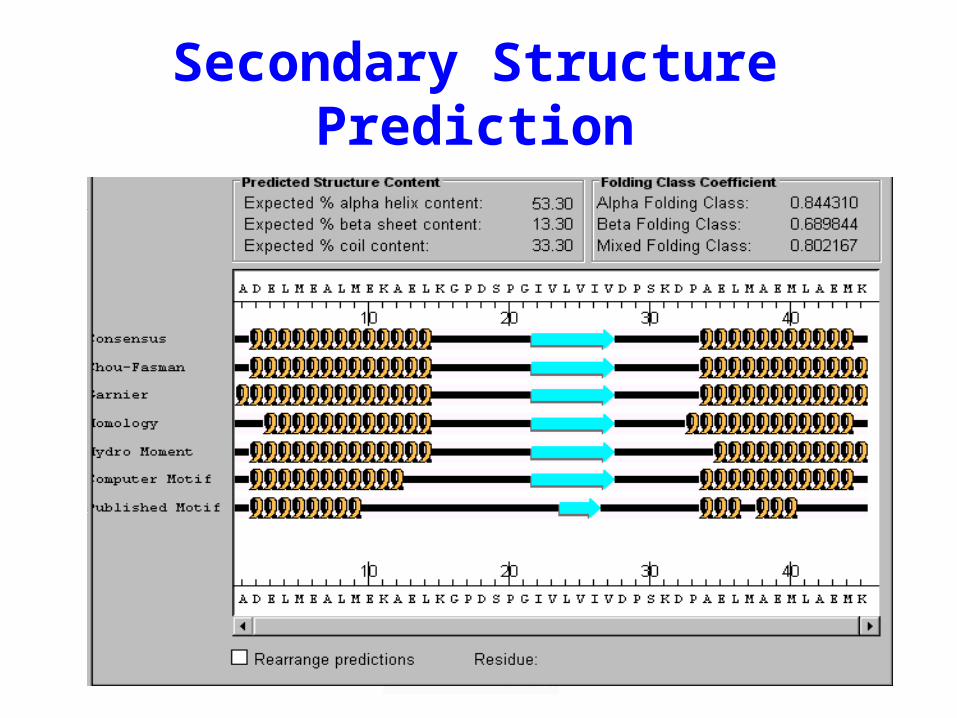
Secondary Structure Prediction

Secondary Structure Prediction
• Statistical (Chou-Fasman, GOR)• Homology or Nearest Neighbor (Levin)• Physico-Chemical (Lim, Eisenberg)• Pattern Matching (Cohen, Rooman)• Neural Nets (Qian & Sejnowski, Karplus)• Evolutionary Methods (Barton, Niemann)• Combined Approaches (Rost, Levin, Argos)

Chou-Fasman Statistics
P P Pc P P Pc
A 1.42 0.83 0.75 M 1.45 1.05 0.5C 0.7 1.19 1.11 N 0.67 0.89 1.44D 1.01 0.54 1.45 P 0.57 0.55 1.88E 1.51 0.37 1.12 Q 1.11 1.1 0.79F 1.13 1.38 0.49 R 0.98 0.93 1.09G 0.57 0.75 1.68 S 0.77 0.75 1.48H 1 0.87 1.13 T 0.83 1.19 0.98I 1.08 1.6 0.32 V 1.06 1.7 0.24K 1.16 0.74 1.1 W 1.08 1.37 0.45L 1.21 1.3 0.49 Y 0.69 1.47 0.84
Chou & Fasman Secondary Structure Propensity of the Amino Acids
Table 8

Chou-Fasman Algorithm
• Assign each residue a P, P, Pc value• Take a window of 7 residues and calculate
a window-averaged value for all P, P, Pc
• Assign the average value for each of the secondary structures to the middle residue
• Move down one residue and repeat steps 2 thru 3 until finished
• Scan and assign SS to the highest P/residue

The PhD Approach
PRFILE...

The PhD Algorithm• Search the SWISS-PROT database and
select high scoring homologues• Create a sequence “profile” from the
resulting multiple alignment• Include global sequence info in the profile• Input the profile into a trained two-layer
neural network to predict the structure and to “clean-up” the prediction
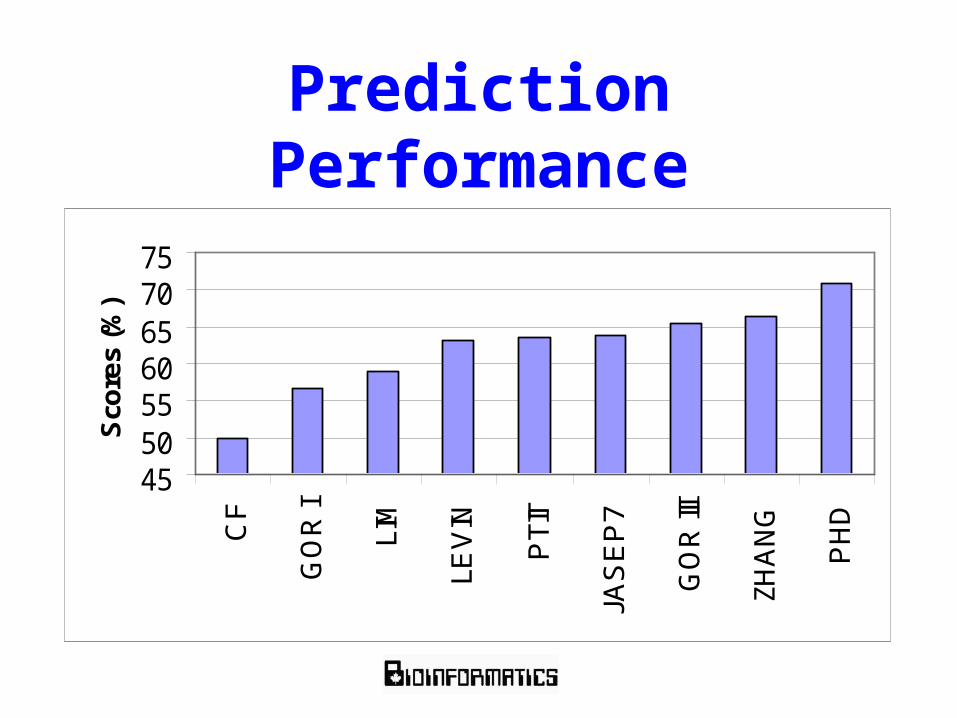
Prediction Performance
45505560657075
CF
GO
R I
LIM
LEV
IN
PTI
T
JAS
EP
7
GO
R II
I
ZHA
NG
PH
D
Sco
res
(%)

Best of the Best
• PredictProtein-PHD (72%)– http://cubic.bioc.columbia.edu/predictprotein
• Jpred (73-75%)– http://jura.ebi.ac.uk:8888/
• PREDATOR (75%)– http://www.embl-heidelberg.de/cgi/predator_serv.pl
• PSIpred (77%)– http://insulin.brunel.ac.uk/psipred