high performance computing - moreno.marzolla.name · attività didattica presente e passata ... –...
TRANSCRIPT

High Performance High Performance ComputingComputing
Moreno MarzollaDip. di Informatica—Scienza e Ingegneria (DISI)Università di Bologna
http://www.moreno.marzolla.name/

High Performance Computing 2
Copyright © 2013—2018Moreno Marzolla, Università di Bologna, Italyhttp://www.moreno.marzolla.name/teaching/HPC/
This work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0). To view a copy of this license, visit https://creativecommons.org/licenses/by-sa/4.0/ or send a letter to Creative Commons, 543 Howard Street, 5th Floor, San Francisco, California, 94105, USA.

High Performance Computing 3
Credits
● prof. Salvatore Orlando, Univ. Ca' Foscari di Veneziahttp://www.dsi.unive.it/~orlando/
● prof. Mary Hall, University of Utahhttps://www.cs.utah.edu/~mhall/
● Tim Mattson, Intel

High Performance Computing 4
Presentiamoci
● Chi sono– Moreno Marzolla– prof. associato di Informatica @ DISI– http://www.moreno.marzolla.name/
● Attività didattica presente e passata– High Performance Computing @ ISI– Fondamenti di Informatica A @ Ing. Biomedica/Elettronica– In passato: Algoritmi e Strutture Dati; Sistemi Complessi;
Ingegneria del Software● Di cosa mi occupo
– Programmazione parallela– Modellazione e simulazione di sistemi

High Performance Computing 5
High Performance Computing
● Pagina del corso– http://www.moreno.marzolla.name/teaching/HPC/
● Orario– Martedì 9:00—11:00 Lab 3.3– Giovedì 9:00—12:00 Aula 2.4– Fare riferimento alla pagina del corso e al calendario sul sito
del CdS per variazioni dell'orario● Giovedì 27 settembre no lezione; verrà recuperata venerdì 5
ottobre dalle 11 alle 13 in aula 2.6● Ricevimento
– In qualunque momento, da concordare via mail

High Performance Computing 6
Scopo del corso
● Aspetti teorici e pratici della programmazione parallela– Teoria: dato un problema, progettare un algoritmo parallelo
che lo risolva; valutare l'efficienza di un programma parallelo– Pratica: dato un algoritmo parallelo, implementarlo
utilizzando gli strumenti più appropriati● 6 CFU (~ 60 ore di lezione) così divisi
– Lezioni in aula ~40 ore– Esercitazioni in laboratorio ~20 ore

High Performance Computing 7
Alla fine di questo corso...
● ...saprete come è organizzato un calcolatore parallelo● ...sarete in grado di progettare e realizzare programmi
efficienti su diversi tipi di architetture parallele● ...sarete in grado di valutare le prestazioni dei
programmi paralleli● ...e vi sarete divertiti (spero)!

High Performance Computing 8

High Performance Computing 9
Bibliografia● Peter S. Pacheco, An Introduction to
Parallel Programming, Morgan Kaufmann 2011, ISBN 9780123742605– Teoria + programmazione OpenMP e
MPI● CUDA C programming guide
http://docs.nvidia.com/cuda/cuda-c-programming-guide/
– Programmazione CUDA/C ● Lucidi e altro materiale sulla pagina
del corso

Sui lucidi delle lezioni
https://biblioklept.org/2010/06/11/the-british-library-acquires-j-g-ballard-archive/
I lucidi delle lezioni visti da voi I lucidi delle lezioni visti da me
High Performance Computing 11
Prerequisiti
ProgrammazioneAlgoritmi e
Strutture Dati
Architettura dei Calcolatori
Sistemi Operativi
High PerformanceComputing

High Performance Computing 12
Programma del corso
● Teoria (prime 3/4 settimane)– Architetture parallele– Pattern per la programmazione parallela– Valutazione delle prestazioni di programmi paralleli
● Programmazione (resto del corso)– Programmazione di architetture a memoria condivisa in
C/OpenMP– Programmazione di architetture a memoria distribuita in
C/MPI– Programmazione di GPU con CUDA/C– Programmazione SIMD con estensioni SSEx (se avanza
tempo)

High Performance Computing 13
Laboratorio
● Esercizi di programmazione parallela in ambiente Linux, per applicare i concetti visti a lezione
● Perché Linux?
Fonte: http://www.top500.org

High Performance Computing 14
I (potenti) mezzi a nostra disposizione
● disi-hpc– VM 16 core, 16 GB RAM, Debian/jessie– Esercitazioni OpenMP e MPI
● isi-raptor03– Dual core Xeon, 12 core, 64 GB RAM, Ubuntu 16.04– 3x NVidia GeForce GTX 1070 – Esercitazioni CUDA
● H/W vario– A disposizione per tesi

High Performance Computing 15
Modalità d'esame
● Prova scritta (peso 40%)– Domande su tutto il contenuto del corso (esempio sulla pagina del corso)– 6 appelli d'esame: 2 nella sessione invernale (gen/feb); 3 nella sessione estiva
(giu/lug); 1 nella sessione autunnale (set)– Si può rifiutare il voto quante volte si vuole
● Progetto individuale + relazione scritta (peso 60%)– Specifiche assegnate dal docente al termine del corso– Non è previsto un orale, ma mi riservo la facoltà di chiedere chiarimenti sui
progetti consegnati– In caso di rifiuto del voto, si consegna un NUOVO progetto su NUOVE specifiche
● Voto finale arrotondato all'intero più vicino● Le prove possono essere sostenute in modo indipendente● Il voto di ciascuna prova resta valido fino al 30 settembre 2019
– Ogni anno accademico si ricomincia da capo– Potrebbero cambiare le modalità d'esame, quindi occhio...

High Performance Computing 16
Valutazione del progetto
● Comprensibilità● Correttezza● Efficienza● Qualità della relazione
– Correttezza tecnica– Completezza dell'analisi– Qualità del testo scritto (grammatica, sintassi...)

High Performance Computing 17
Non copiate

High Performance Computing 18
Domande?

High Performance Computing 19
Introduzione al calcolo parallelo

High Performance Computing 20
High Performance Computing
● Molte applicazioni hanno bisogno di elevata potenza di calcolo – Meteorologia, fisica, ingegneria, animazione 3D, finanza...
● Perché?– Per risolvere problemi più complessi– Per risolvere lo stesso problema in modo più accurato– Per risolvere lo stesso problema in minor tempo– Per sfruttare al meglio le risorse disponibili

High Performance Computing 21
La legge di Moore
"Il numero di transistor in un circuito integrato raddoppia ogni 2 anni"
● Fino a poco tempo fa ciò significava un maggior numero di transistor più piccoli in ogni nuova generazione di processori
Moore, G.E., Cramming more components onto integrated circuits. Electronics, 38(8), April 1965 Gordon E.
Moore(1929– )

High Performance Computing 22By Wgsimon - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=15193542

High Performance Computing 23
La legge di Moore
Source: Hennessy, Patterson, Computer Architecture: A Quantitative Approach

High Performance Computing 24
Lezione di fisica
● Transistor più piccoli → processore più veloce● Processore più veloce → maggiore energia consumata● Maggiore energia consumata → maggiore calore prodotto● Maggiore calore prodotto → processore non affidabile

High Performance Computing 25
Potenza
● La potenza assorbita da un processore può essere espressa come
Power = C ´ V 2 ´ f
dove:– C è la capacitanza (abilità di un circuito di immagazzinare
energia)– V è il voltaggio– f è la frequenza a cui opera il processore

High Performance Computing 26
Potenza
ProcessorInput Output
f
Processor
Processor
Input Output
f / 2
f / 2
f
Slide credits: Tim Mattson, Intel
Capacitance CVoltage VFrequency fPower = C V 2 f
Capacitance 2.2 CVoltage 0.6 VFrequency 0.5 f Power = 0.396 C V 2 f

High Performance Computing 27
I trend dei microprocessori
Herb Sutter, The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software, Dr. Dobb's Journal, 30(3), March 2005, http://www.gotw.ca/publications/concurrency-ddj.htm
# Transistor
Clock speed
Power (W)
Perf/clock
High Performance Computing 28
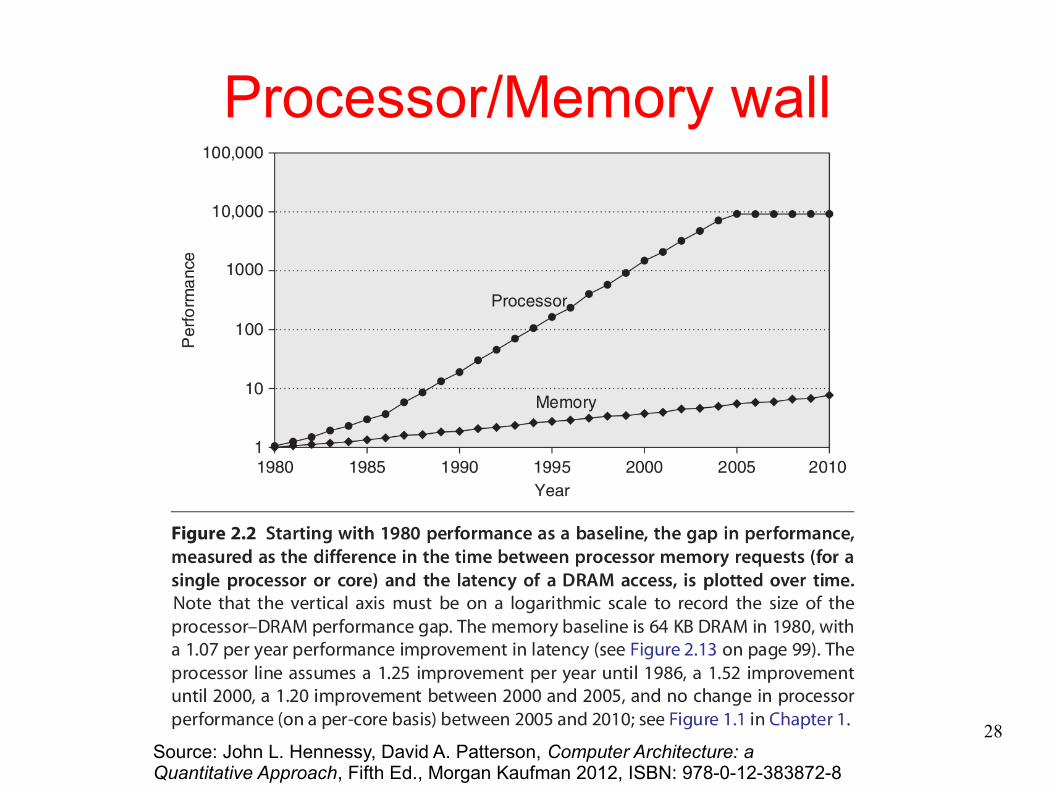
Processor/Memory wall
Source: John L. Hennessy, David A. Patterson, Computer Architecture: a Quantitative Approach, Fifth Ed., Morgan Kaufman 2012, ISBN: 978-0-12-383872-8

High Performance Computing 29
Limiti
● There are limits to “automatic” improvement of scalar performance:– The Power Wall: Clock frequency cannot be increased
without exceeding air cooling– The Memory Wall: Access to data is a limiting factor– The ILP Wall: All the existing instruction-level parallelism
(ILP) is already being used● Conclusion:
– Explicit parallel mechanisms and explicit parallel programming are required for performance scaling
Slide credits: Hebenstreit, Reinders, Robison, McCool, SC13 tutorial

High Performance Computing 30
Che succede oggi?
● I progettisti HW creano processori con un numero elevato di core
● Risultato:– l'hardware parallelo è
ovunque– il software parallelo è
raro● La sfida
– Il software parallelo deve diventare diffuso come l'hardware parallelo
NVidia Tegra 4 SoC

High Performance Computing 31
La programmazione parallela in breve
● Decomporre il problema in sotto-problemi● Distribuire i sottoproblemi ai processori disponibili● Ciascun processore risolve il sottoproblema
assegnatogli● I processori possono cooperare per risolvere problemi
comuni● Obbiettivi
– Ridurre il tempo totale necessario per risolvere il problema– Bilanciare il carico tra i processori– Ridurre al minimo l'overhead dovuto alla comunicazione e
alla sincronizzazione tra processi
Slide credits: S. Orlando

High Performance Computing 32
Concorrenza vs Parallelismo
Slide credits: Tim Mattson, Intel
Task 1
Task 2
Task 3
Concorrenza senza parallelismo Parallelismo

High Performance Computing 33
La programmazione parallela in breve
● Fino a pochi anni fa, la programmazione parallela era un argomento di nicchia, dato che i calcolatori paralleli erano rari e costosi(ssimi)
● Oggi la programmazione parallela è essenziale dato che i processori paralleli sono ovunque
Apple iPhone 7 Quad-core 2.3 GHz ARMv8-A
Huawei P9Quad-core 2.5 GHz Cortex-A72

High Performance Computing 34
Quando la programmazione parallela è necessaria
● Paradigma scientifico tradizionale– Sviluppa una teoria, e poi effettua esperimenti per confermare la teoria
● Paradigma ingegneristico tradizionale– Prima sviluppa un progetto, poi costruisci un prototipo
● Entrambi questi paradigmi stanno venendo rimpiazzati da esperimenti e prototipazione numerica– Certi fenomeni reali sono troppo complessi per essere modellati (es.,
previsioni del tempo)– Certi tipi di esperimenti sono troppo complessi, costosi, o pericolosi per
essere condotti in laboratorio (es., simulazioni sismiche, gallerie del vento, progettazione di aerei, dinamica di ammassi stellari...)
● Computational science– Le simulazioni numeriche stanno diventando il nuovo modo per "fare
scienza"
Slide credits: S. Orlando

High Performance Computing 35
Numerical Wind Tunnel
Source: http://ecomodder.com/forum/showthread.php/random-wind-tunnel-smoke-pictures-thread-26678-12.html

High Performance Computing 36
Molecular dynamicsSource: http://bionano.physics.illinois.edu/node/109

High Performance Computing 37
Global Climate models
Source: Chapter 1 of Climate Change 2013: The Physical Science Basis https://www.ipcc.ch/report/ar5/wg1/

High Performance Computing 38
The Bolshoi Simulation
Bolshoi simulation https://vimeo.com/29769051
The Bolshoi Simulation recreates the large-scale structure of the universe; it required 6 million CPU hours on NASA's Pleiades Supercomputer
Source : https://www.nas.nasa.gov/hecc/resources/pleiades.html

High Performance Computing 39
Il “Santo Graal”
● Da anni gli informatici tentano di sviluppare linguaggi di programmazione che “parallelizzano da soli”– In casi molto particolari i risultati sono positivi– In generale i risultati sono mediocri (quando va bene), o
inesistenti (quando va male)● Occorre quindi usare strumenti specifici e sviluppare
algoritmi efficienti che traggano vantaggio dalle caratteristiche specifiche dell'architettura parallela sottostante Qui entriamo in gioco noi

High Performance Computing 40
Nessuno però dice che sia facile...
Versione sequenziale(~49 righe di codice C++)
http://www.moreno.marzolla.name/software/svmcell/

High Performance Computing 41
Nessuno però dice che sia facile...
Versione sequenziale(~49 righe di codice C++)
Versione parallela (PPU+SPU)(~1000 righe di codice C/C++15 fogli A4)
http://www.moreno.marzolla.name/software/svmcell/

High Performance Computing 42
Limiti della programmazione parallela
● Sviluppare un programma parallelo è in genere più difficile che svilupparne uno sequenziale
● La portabilità tra architetture diverse è limitata– Esistono alcuni standard de facto (OpenMP e MPI) che
facilitano la portabilità tra certe classi di architetture parallele● La fase di tuning necessaria per ottenere le
prestazioni migliori può risultare molto laboriosa

High Performance Computing 43
EsempioSomma degli elementi di un array
("Hello, world!" del calcolo parallelo)

High Performance Computing 44
Somma degli elementi di un array
● Consideriamo una architettura a memoria condivisa– Tutti i thread possono accedere ad una memoria condivisa
comune● Iniziamo con un algoritmo sequenziale, modificandolo
per l'esecuzione parallela– Questa non è necessariamente la strategia migliore: spesso
algoritmi paralleli efficienti non hanno nulla in comune con la loro controparte sequenziale!
– È comunque un approccio sensato, dato che siamo già abituati alla programmazione sequenziale
Slide credits: Mary Hall

High Performance Computing 45
Algoritmo sequenziale
● Calcola la somma dei valori contenuti in un array A di n elementi
float seq_sum(float* A, int n){
int i;float sum = 0.0;for (i=0; i<n; i++) {
sum += A[i];}return sum;
}
Slide credits: Mary Hall

High Performance Computing 46
Concetti base
● Decomposizione– Distribuire la computazione tra processori/threads– Distribuire i dati tra processori/threads
● Dipendenze– Assicurarsi che i valori delle variabili siano consistenti con
l'esecuzione sequenziale● Race Condition
– Si verifica una race condition quando il risultato di una computazione dipende dall'ordine relativo tra due o più eventi
● Sincronizzazione– Usata per gestire l'esecuzione concorrente di processi/threads
● Overhead
Slide credits: Mary Hall

High Performance Computing 47
Versione 1: PartitioningPrimo tentativo (sbagliato)
● Se ci sono P thread, ciascuno calcola la somma parziale di n / P elementi consecutivi
● Esempio: n = 15, P = 3
block_len = n/P; my_start = my_id * block_len; my_end = my_start + block_len; sum = 0.0;for (my_i=my_start; my_i<my_end; my_i++) { my_x = get_value(my_i); sum += my_x;}
Thread 0 Thread 1 Thread 2
ATTENZIONE...
Le variabili il cui nome inizia per my_ si considerano locali ad ogni thread; tutte le
altre si considerano globali

High Performance Computing 48
Problema
● Tutti i thread incrementano la variabile condivisa sum● Le operazioni di incremento devono essere effettuate
in modo atomico per preservare la correttezza del programma
● Soluzione: usare un mutex per fare in modo che un solo thread alla volta possa incrementare la variabile condivisa

High Performance Computing 49
Versione 1: PartitioningSecondo tentativo (meglio, ma ancora non corretto)
● Se ci sono P thread, ciascuno calcola la somma parziale di n / P elementi consecutivi
● Esempio: n = 15, P = 3
block_len = n/P; my_start = my_id * block_len; my_end = my_start + block_len; sum = 0.0; mutex m;for (my_i=my_start; my_i<my_end; my_i++) { my_x = get_value(my_i); mutex_lock(&m); sum += my_x; mutex_unlock(&m);}
Thread 0 Thread 1 Thread 2
ATTENZIONE...

High Performance Computing 50
Versione 1: PartitioningSecondo tentativo (meglio, ma ancora non corretto)
● Se ci sono P thread, ciascuno calcola la somma parziale di n / P elementi consecutivi
● Esempio: n = 17, P = 3
block_len = n/P; my_start = my_id * block_len; my_end = my_start + block_len; sum = 0.0; mutex m;for (my_i=my_start; my_i<my_end; my_i++) { my_x = get_value(my_i); mutex_lock(&m); sum += my_x; mutex_unlock(&m);}
Thread 0 Thread 1 Thread 2
ATTENZIONE...
?? ??

High Performance Computing 51
Versione 1: PartitioningTerzo tentativo (corretto, ma inefficiente)
● Se ci sono P thread, ciascuno calcola la somma parziale di n / P elementi consecutivi
● Esempio: n = 17, P = 3
Thread 0 Thread 1 Thread 2
my_start = n * my_id / P; my_end = n * (my_id + 1) / P;sum = 0.0; mutex m;for (my_i=my_start; my_i<my_end; my_i++) { my_x = get_value(my_i); mutex_lock(&m); sum += my_x; mutex_unlock(&m);}

High Performance Computing 52
Versione 2
● La versione 1 non è efficiente perché c'è eccessiva contesa sul mutex m– Ogni thread acquisisce e rilascia il mutex per ogni elementi dell'array!
● Soluzione: aumentare la granularità del mutex– Ogni thread accumula la somma parziale in una variabile privata (locale)– Il mutex viene usato alla fine per aggiornare la somma globale
my_start = n * my_id / P; my_end = n * (my_id + 1) / P;sum = 0.0; my_sum = 0.0; mutex m;for (my_i=my_start; my_i<my_end; my_i++) {
my_x = get_value(my_i);my_sum += my_x;
}mutex_lock(&m);sum += my_sum;mutex_unlock(&m);

High Performance Computing 53
Versione 3: Eliminiamo il mutex(sbagliato, in modo subdolo)
● Usiamo un array globale in cui ogni elemento contiene la somma locale di un thread diverso
● Il processo master calcola la somma globale
my_start = n * my_id / P; my_end = n * (my_id + 1) / P;psum[0..P-1] = 0.0; /* all elements set to 0.0 */for (my_i=my_start; my_i<my_end; my_i++) {
my_x = get_value(my_i);psum[my_id] += my_x;
}if ( 0 == my_id ) { /* only the master executes this */
sum = 0.0;for (my_i=0; my_i<P; my_i++)
sum += psum[my_i];}
ATTENZIONE...

High Performance Computing 54
Problema con la versione 3
● Il master potrebbe iniziare il calcolo della somma globale prima che tutti gli altri thread abbiano terminato il calcolo delle somme locali!
Calcolo somme locali
Calcolo somma globale
T0 T1 T2

High Performance Computing 55
Versione 4(corretta)
● Utilizziamo una barriera per sincronizzare i thread– Una barriera serve per impedire ad un thread di procedere
oltre fino a quando tutti i thread hanno raggiunto la barriera
my_start = n * my_id / P; my_end = n * (my_id + 1) / P;psum[0..P-1] = 0.0; for (my_i=my_start; my_i<my_end; my_i++) {
my_x = get_value(my_i);psum[my_id] += my_x;
}barrier();if ( 0 == my_id ) {
sum = 0.0;for (my_i=0; my_i<P; my_i++)
sum += psum[my_i];}
Calcolo somme locali
Calcolo somma globale
T0 T1 T2
barrier()

High Performance Computing 56
Versione 5Comunicazione tramite scambio di messaggi
● P << n processi● Ciascun processo
calcola la somma degli elementi di un sottovettore
● Ogni processo (tranne il master) invia la somma parziale al thread 0
...my_sum = 0.0;my_start = …, my_end = …;
for ( i = my_start; i < my_end; i++ ) {my_sum += get_value(i);
}if ( 0 == my_id ) {
for ( i=1; i<P; i++ ) {tmp = receive from proc i;my_sum += tmp;
}printf(“The sum is %f\n”, my_sum);
} else {send my_sum to thread 0;
}

High Performance Computing 57
Versione 5Proc 0
A[ ]
my_sum
Proc 1 Proc 2 Proc 3 Proc 4 Proc 5 Proc 6 Proc 7
1 3 -2 7 -6 5 3 4
15
4
2
9
3
8
11

High Performance Computing 58
Problema
● Il master è il collo di bottiglia, perché riceve P - 1 messaggi e deve eseguire P - 1 somme– Sbilanciamento del carico: nella seconda fase, l'operazione
di somma dei parziali viene svolta solo dal master● È possibile calcolare la somma globale, partendo dai
risultati parziali, in maniera più bilanciata?

High Performance Computing 59
Somma parallelaProc 0
A[ ]
my_sum
Proc 1 Proc 2 Proc 3 Proc 4 Proc 5 Proc 6 Proc 7
1 3 -2 7 -6 5 3 4
5 -1 7
6
15
4
9
● In tutto si eseguono P – 1 somme; il master (processo 0) riceve log
2 P messaggi ed effettua log
2 P somme.

High Performance Computing 60
Coordinazione
● I processi devono coordinare il loro lavoro● Comunicazione
– Uno o più processi inviano la propria somma parziale ad un altro processo
● Bilanciamento del carico– Dividere il lavoro tra i processi in maniera uniforme
● Sincronizzazione– Assicurarsi che il lavoro di ciascun processo sia “allineato” a
quello degli altri

High Performance Computing 61
Come scrivere applicazioni parallele?
● Task Parallelism– Distribuire i compiti da eseguire tra i processi/thread
● Data Parallelism– Distribuire i dati tra i processi/thread– I processi eseguono lo stesso programma

High Performance Computing 62
Esempio
● Supponiamo di raccogliere in un foglio di calcolo (spreadsheet) le temperature giornaliere misurate durante un anno (365 giorni) in una certa località
● La temperatura viene registrata una volta all'ora (24 misurazioni giornaliere)
● Vogliamo calcolare, per ogni giorno, la temperatura massima, minima e media
● Possiamo usare 3 processi (indipendenti)

High Performance Computing 63
Esempio
max min ave0 1 2 3 22 23
Hour (0—23)
0
1
2
364
Day
s (0
—36
4)

High Performance Computing 64
Approccio data parallel
max min ave0 1 2 3 22 23
Hour (0—23)
0
1
2
364
Day
s (0
—36
4)
Proc 0
Proc 1
Proc 2

High Performance Computing 65
Approccio task parallel
max min ave0 1 2 3 22 23
Hour (0—23)
0
1
2
364
Day
s (0
—36
4)
Pro
c 0
Pro
c 1
Pro
c 2

High Performance Computing 66
Concetti chiave
● Le leggi della fisica ci hanno condotto verso le architetture di calcolo parallele
● I programmi sequenziali generalmente non traggono vantaggio dalla presenza di più processori
● La parallelizzazione automatica (quando funziona) non sempre produce la soluzione migliore
● I programmi paralleli sono solitamente molto più complessi dei corrispondenti sequenziali