hdfs: hadoop distributed file system -...
TRANSCRIPT

HDFS:
Hadoop Distributed
File SystemCIS 612
Sunnie Chung

Introduction
• What is Big Data??
– Bulk Amount
– Unstructured
• Lots of Applications which need to handle
huge amount of data (in terms of 500+ TB per
day)
• If a regular machine need to transmit 1TB of
data through 4 channels : 43 Minutes.
• What if 500 TB ??
SS Chung CIS 612 Lecture Notes 2

What is Hadoop?
• Framework for large-scale data processing
• Inspired by Google’s Architecture: – Google File System (GFS) and MapReduce
• Open-source Apache project
– Nutch search engine project
– Apache Incubator
• Written in Java and shell scripts
SS Chung CIS 612 Lecture Notes 3

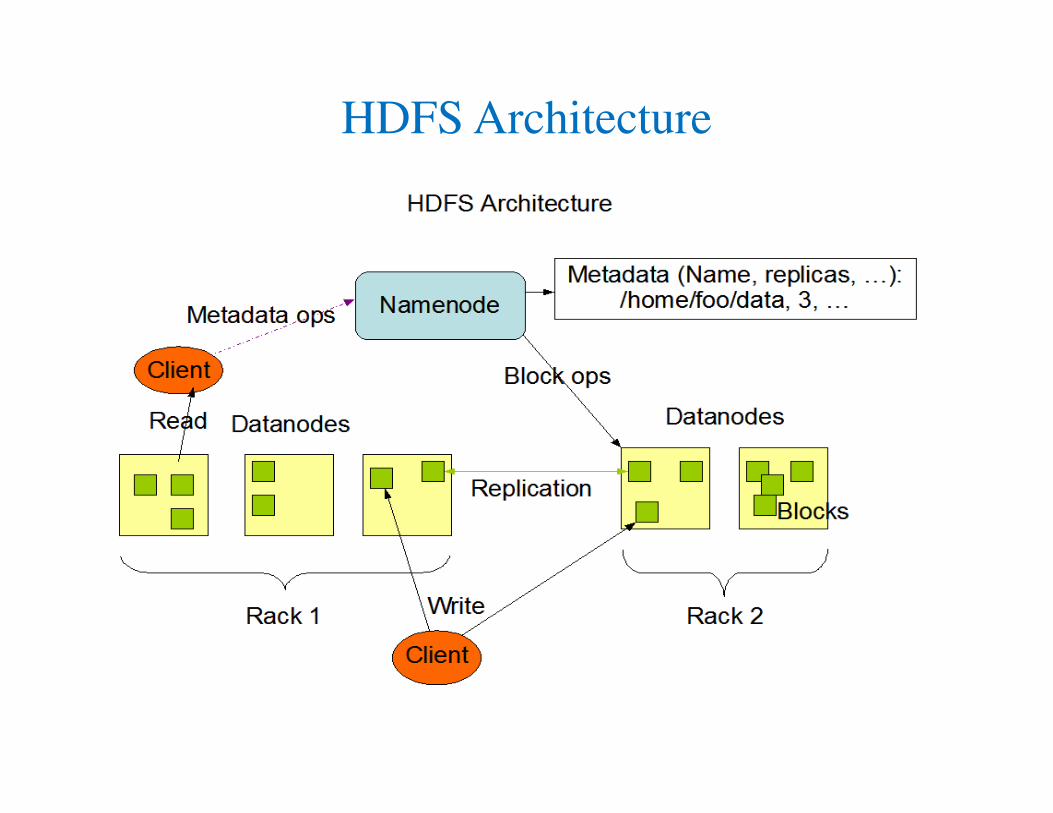
Hadoop Distributed File System (HDFS)
• Storage unit of Hadoop
• Relies on principles of Distributed File System.
• HDFS have a Master-Slave architecture
• Main Components:
– Name Node : Master
– Data Node : Slave
• 3+ replicas for each block
• Default Block Size : 128MB
SS Chung CIS 612 Lecture Notes 4

H
Hadoop Distributed File System (HDFS)
• Hadoop Distributed File System (HDFS)
– Runs entirely in userspace
– The file system is dynamically distributed across multiple computers
– Allows for nodes to be added or removed easily
– Highly scalable in a horizontal fashion
• Hadoop Development Platform
– Uses a MapReduce model for working with data
– Users can program in Java, C++, and other languages
SS Chung CIS 612 Lecture Notes 5

Why should I use Hadoop?
• Fault-tolerant hardware is expensive
• Hadoop designed to run on commodity hardware
• Automatically handles data replication and deals with node failure
• Does all the hard work so you can focus on processing data
SS Chung CIS 612 Lecture Notes 6

HDFS: Key Features
• Highly Fault Tolerant:
Automatic Failure Recovery System
• High aggregate throughput for streaming large files
• Supports replication and locality features
• Designed to work with systems with vary large file
(files with size in TB) and few in number.
• Provides streaming access to file system data. It is
specifically good for write once read many kind of
files (for example Log files).
SS Chung CIS 612 Lecture Notes 7

Hadoop Distributed File System (HDFS)
• Can be built out of commodity hardware. HDFS
doesn't need highly expensive storage devices
– Uses off the shelf hardware
• Rapid Elasticity
– Need more capacity, just assign some more nodes
– Scalable
– Can add or remove nodes with little effort or
reconfiguration
• Resistant to Failure
• Individual node failure does not disrupt the
systemSS Chung CIS 612 Lecture Notes 8

Who uses Hadoop?
SS Chung CIS 612 Lecture Notes 9

What features does Hadoop offer?
• API and implementation for working with
MapReduce
• Infrastructure
– Job configuration and efficient scheduling
– Web-based monitoring of cluster stats
– Handles failures in computation and data nodes
– Distributed File System optimized for huge amounts of
data
SS Chung CIS 612 Lecture Notes 10

When should you choose Hadoop?
• Need to process a lot of unstructured data
• Processing needs are easily run in parallel
• Batch jobs are acceptable
• Access to lots of cheap commodity machines
SS Chung CIS 612 Lecture Notes 11

When should you avoid Hadoop?
• Intense calculations with little or no data
• Processing cannot easily run in parallel
• Data is not self-contained
• Need interactive results
SS Chung CIS 612 Lecture Notes 12

Hadoop Examples
• Hadoop would be a good choice for:
– Indexing log files
– Sorting vast amounts of data
– Image analysis
– Search engine optimization
– Analytics
• Hadoop would be a poor choice for:
– Calculating Pi to 1,000,000 digits
– Calculating Fibonacci sequences
– A general RDBMS replacement
SS Chung CIS 612 Lecture Notes 13

Hadoop Distributed File System (HDFS)
• How does Hadoop work?
– Runs on top of multiple commodity systems
– A Hadoop cluster is composed of nodes
• One Master Node
• Many Slave Nodes
– Multiple nodes are used for storing data & processing
data
– System abstracts the underlying hardware to
users/software
SS Chung CIS 612 Lecture Notes 14

How HDFS works: Split Data
• Data copied into HDFS is split into blocks
• Typical HDFS block size is 128 MB
– (VS 4 KB on UNIX File Systems)
SS Chung CIS 612 Lecture Notes 15

How HDFS works: Replication
• Each block is replicated to multiple machines
• This allows for node failure without data loss
SS Chung CIS 612 Lecture Notes 16
Data
Node 2
Data
Node 3
Data
Node 1
Block
#1
Block
#2
Block
#2
Block
#3
Block
#1
Block
#3

HDFS Architecture

Hadoop Distributed File System (HDFS)p:
HDFS • HDFS Consists of data blocks
– Files are divided into data
blocks
– Default size if 64MB
– Default replication of blocks is 3
– Blocks are spread out over Data
Nodes
SS Chung CIS 612 Lecture Notes 18
� HDFS is a multi-node system
� Name Node (Master)
� Single point of failure
� Data Node (Slave)
� Failure tolerant (Data
replication)

Hadoop Architecture Overview
SS Chung CIS 612 Lecture Notes 19
Client
Job Tracker
Task Tracker Task Tracker
Name
Node
Name
NodeData
Node
Data
Node Data
Node
Data
NodeData
Node
Data
Node
Data
Node
Data
Node

Hadoop Components: Job Tracker
SS Chung CIS 612 Lecture Notes 20
Client
Job Tracker
Task Tracker Task Tracker
Name NodeName NodeData
Node
Data
NodeData
Node
Data
NodeData
Node
Data
Node
Data
Node
Data
Node
�Only one Job Tracker per cluster
� Receives job requests submitted by client
� Schedules and monitors jobs on task trackers

Hadoop Components: Name Node
SS Chung CIS 612 Lecture Notes 21
Client
Job
TrackerTask
Tracker
Task
TrackerName NodeName Node
Data
Node
Data
NodeData
Node
Data
NodeData
Node
Data
Node
Data
Node
Data
Node
� One active Name Node per cluster
�Manages the file system namespace and metadata
� Single point of failure: Good place to spend money on hardware

Name Node
• Master of HDFS
• Maintains and Manages data on Data Nodes
• High reliability Machine (can be even RAID)
• Expensive Hardware
• Stores NO data; Just holds Metadata!
• Secondary Name Node:
– Reads from RAM of Name Node and stores it to hard
disks periodically.
• Active & Passive Name Nodes from Gen2 Hadoop
SS Chung CIS 612 Lecture Notes 22
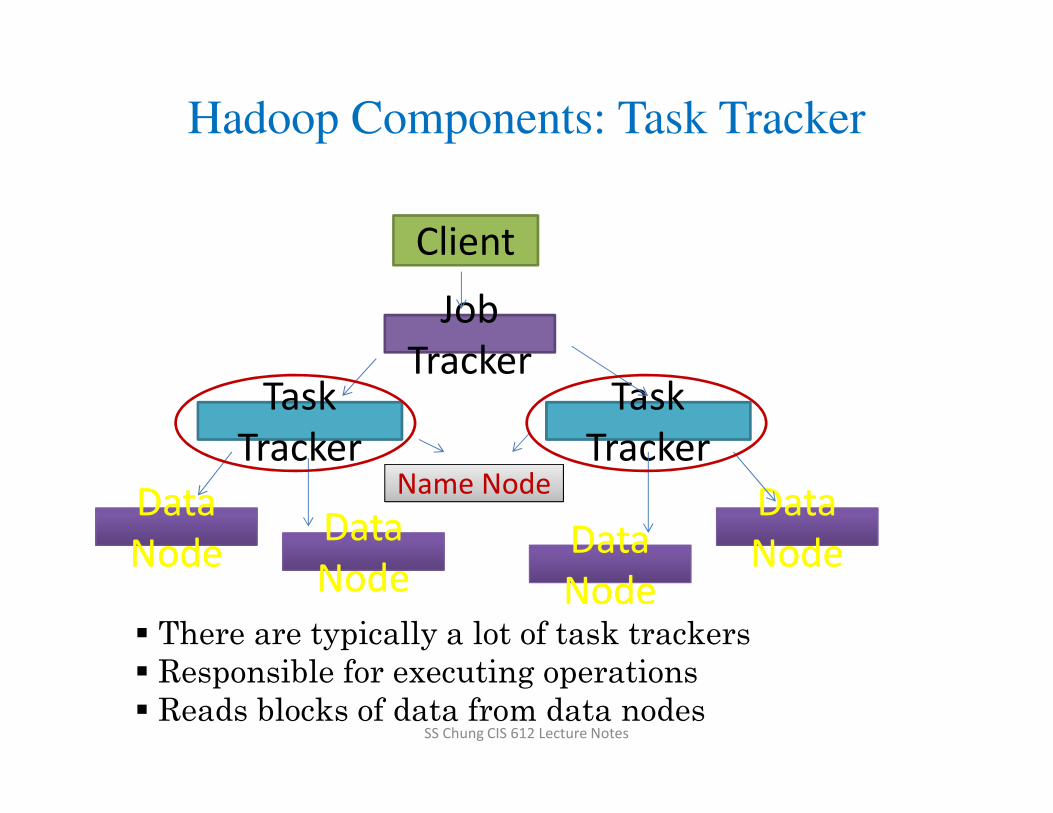
Hadoop Components: Task Tracker
SS Chung CIS 612 Lecture Notes 23
Client
Job
TrackerTask
Tracker
Task
TrackerName NodeName Node
Data
Node
Data
NodeData
Node
Data
NodeData
Node
Data
Node
Data
Node
Data
Node
� There are typically a lot of task trackers
� Responsible for executing operations
� Reads blocks of data from data nodes
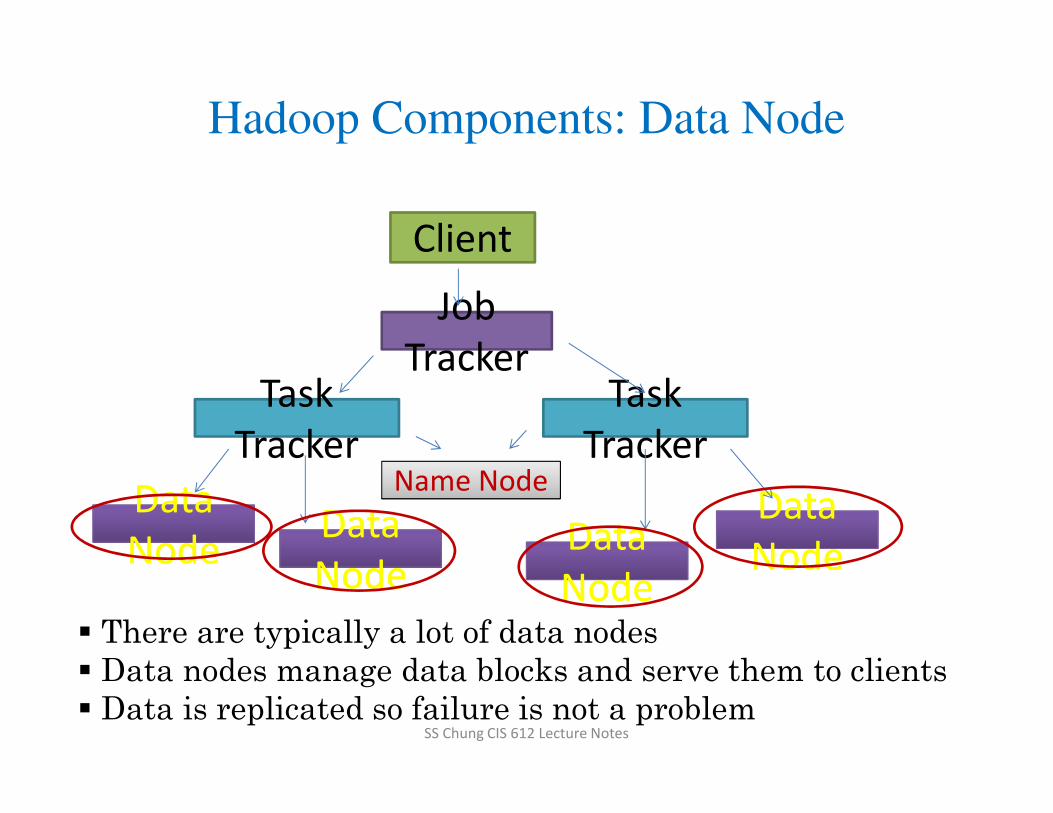
Hadoop Components: Data Node
SS Chung CIS 612 Lecture Notes 24
Client
Job
TrackerTask
Tracker
Task
TrackerName NodeName Node
Data
Node
Data
NodeData
Node
Data
NodeData
Node
Data
Node
Data
Node
Data
Node
� There are typically a lot of data nodes
� Data nodes manage data blocks and serve them to clients
� Data is replicated so failure is not a problem

Data Nodes
• Slaves in HDFS
• Provides Data Storage
• Deployed on independent machines
• Responsible for serving Read/Write requests from
Client.
• The data processing is done on Data Nodes.
SS Chung CIS 612 Lecture Notes 25

HDFS Architecture
SS Chung CIS 612 Lecture Notes 26

Hadoop Modes of Operation
Hadoop supports three modes of operation:
• Standalone
• Pseudo-Distributed
• Fully-Distributed
SS Chung CIS 612 Lecture Notes 27

HDFS Operation
SS Chung CIS 612 Lecture Notes 28

HDFS Operation
• Client makes a Write request to Name Node
• Name Node responds with the information about on available data nodes and where data to be written.
• Client write the data to the addressed Data Node.
• Replicas for all blocks are automatically created by Data Pipeline.
• If Write fails, Data Node will notify the Client and get new location to write.
• If Write Completed Successfully, Acknowledgement is given to Client
• Non-Posted Write by Hadoop
SS Chung CIS 612 Lecture Notes 29

HDFS: File Write
SS Chung CIS 612 Lecture Notes 30

HDFS: File Read
SS Chung CIS 612 Lecture Notes 31

Hadoop: Hadoop Stack• Hadoop Development Platform
– User written code runs on system
– System appears to user as a single entity
– User does not need to worry about
distributed system
– Many system can run on top of Hadoop
• Allows further abstraction from system
SS Chung CIS 612 Lecture Notes 32

Hadoop: Hive & HBase�Hive and HBase are layers on top of Hadoop
�HBase & Hive are applications
�Provide an interface to data on the HDFS
�Other programs or applications may use Hive or
HBase as an intermediate layer
SS Chung CIS 612 Lecture Notes 33
HB
ase
Zo
oK
ee
pe
r

Hadoop: Hive
• Hive
– Data warehousing application
– SQL like commands (HiveQL)
– Not a traditional relational database
– Scales horizontally with ease
– Supports massive amounts of data*
SS Chung CIS 612 Lecture Notes 34
* Facebook has more than 15PB of information stored in it and imports 60TB each day (as of 2010)

Hadoop: HBase
• HBase
– No SQL Like language
• Uses custom Java API for working with data
– Modeled after Google’s BigTable
– Random read/write operations allowed
– Multiple concurrent read/write operations allowed
SS Chung CIS 612 Lecture Notes 35

Hadoop MapReduceHadoop has it’s own implementation of MapReduce
Hadoop 1.0.4
API: http://hadoop.apache.org/docs/r1.0.4/api/
Tutorial: http://hadoop.apache.org/docs/r1.0.4/mapred_tutorial.html
Custom Serialization
Data Types
Writable/Comparable
Text vs String
LongWritable vs long
IntWritable vs int
DoubleWritable vs double
SS Chung CIS 612 Lecture Notes 36

Structure of a Hadoop Mapper (WordCount)
SS Chung CIS 612 Lecture Notes 37

Structure of a Hadoop Reducer (WordCount)
SS Chung CIS 612 Lecture Notes 38

Hadoop MapReduce�Working with the Hadoop� http://hadoop.apache.org/docs/r1.0.4/commands_manual.html
�A quick overview of Hadoop commands
�bin/start-all.sh
�bin/stop-all.sh
�bin/hadoop fs –put localSourcePath hdfsDestinationPath
�bin/hadoop fs –get hdfsSourcePath localDestinationPath
�bin/hadoop fs –rmr folderToDelete
�bin/hadoop job –kill job_id
�Running a Hadoop MR Program
� bin/hadoop jar jarFileName.jar programToRun parm1 parm2…
SS Chung CIS 612 Lecture Notes 39

Useful Application Sites
[1] http://wiki.apache.org/hadoop/EclipsePlugIn
[2] 10gen. Mongodb. http://www.mongodb.org/
[3] Apache. Cassandra. http://cassandra.apache.org/
[4] Apache. Hadoop. http://hadoop.apache.org/
[5] Apache. Hbase. http://hbase.apache.org/
[6] Apache, Hive. http://hive.apache.org/
[7] Apache, Pig. http://pig.apache.org/
[8] Zoo Keeper, http://zookeeper.apache.org/
SS Chung CIS 612 Lecture Notes 40

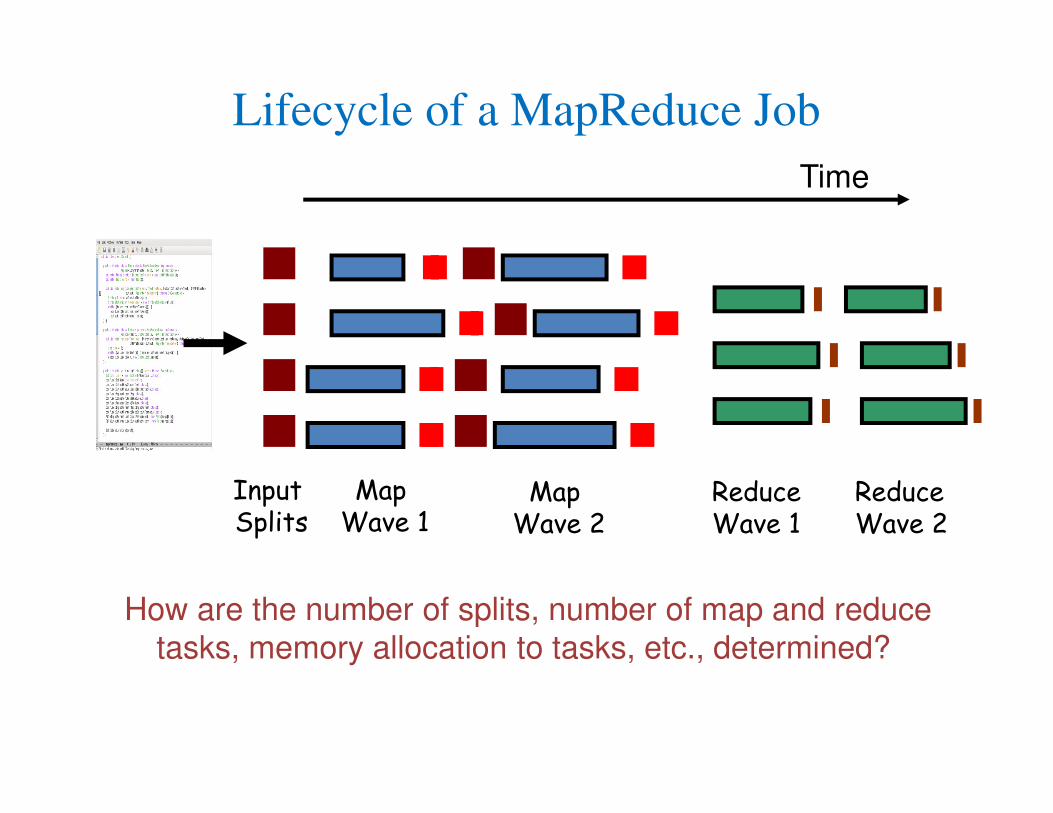
How MapReduce Works in Hadoop

Lifecycle of a MapReduce Job
Map function
Reduce function
Run this program as a
MapReduce job

Lifecycle of a MapReduce Job
Map function
Reduce function
Run this program as a
MapReduce job
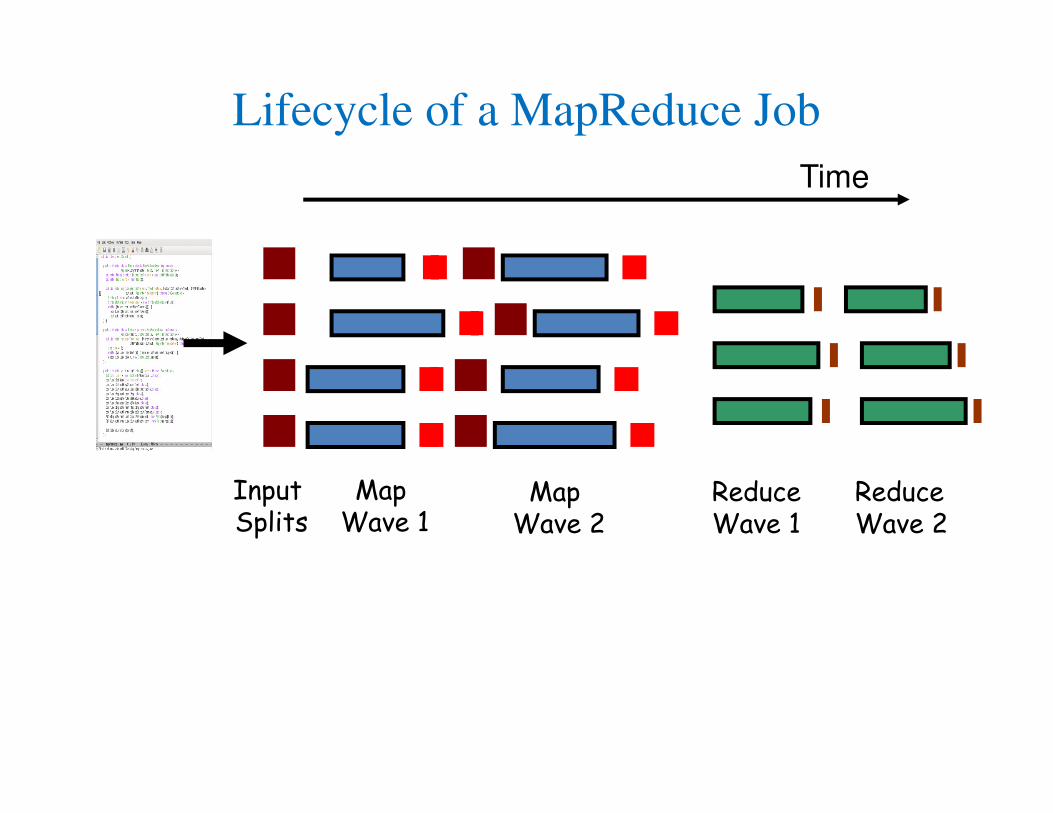
Map Wave 1
ReduceWave 1
Map Wave 2
ReduceWave 2
Input Splits
Lifecycle of a MapReduce Job
Time

Hadoop MR Job Interface:
Input Format
• The Hadoop MapReduce framework spawns
one map task for each InputSplit
• InputSplit: Input File is Split to Input Splits (Logical
splits (usually 1 block), not Physically split chunks)
Input Format::getInputSplits()
• The number of maps is usually driven by the total
number of blocks (InputSplits) of the input files.
1 block size = 128 MB,
10 TB file configured with 82000 maps

Hadoop MR Job Interface:
map()
• The framework then calls
map(WritableComparable, Writable, OutputCollector,
Reporter) for each key/value pair (line_num, line_string
) in the InputSplit for that task.
• Output pairs are collected with calls to
OutputCollector.collect(WritableComparable,Writable).

Hadoop MR Job Interface:
combiner()
• Optional combiner, via
JobConf.setCombinerClass(Class)
• to perform local aggregation of the intermediate
outputs of mapper

Hadoop MR Job Interface:
Partitioner()
• Partitioner controls the partitioning of the keys of the
intermediate map-outputs.
• The key (or a subset of the key) is used to derive the
partition, typically by a hash function.
• The total number of partitions is the same as the
number of reducers
• HashPartitioner is the default Partitioner of reduce
tasks for the job

Hadoop MR Job Interface:
reducer()
• Reducer has 3 primary phases:
1. Shuffle:
2. Sort
3. Reduce

Hadoop MR Job Interface:
reducer()
• Shuffle
Input to the Reducer is the sorted output of the mappers.
In this phase the framework fetches the relevant
partition of the output of all the mappers, via HTTP.
• Sort
The framework groups Reducer inputs by keys (since
different mappers may have output the same key) in this
stage.
• The shuffle and sort phases occur simultaneously;
while map-outputs are being fetched they are merged.

Hadoop MR Job Interface:
reducer()
• Reduce
The framework then calls
reduce(WritableComparable, Iterator, OutputCollector, Reporter)
method for each <key, (list of values)> pair in the
grouped inputs.
• The output of the reduce task is typically written to
the FileSystem via OutputCollector.collect(WritableComparable, Writable).

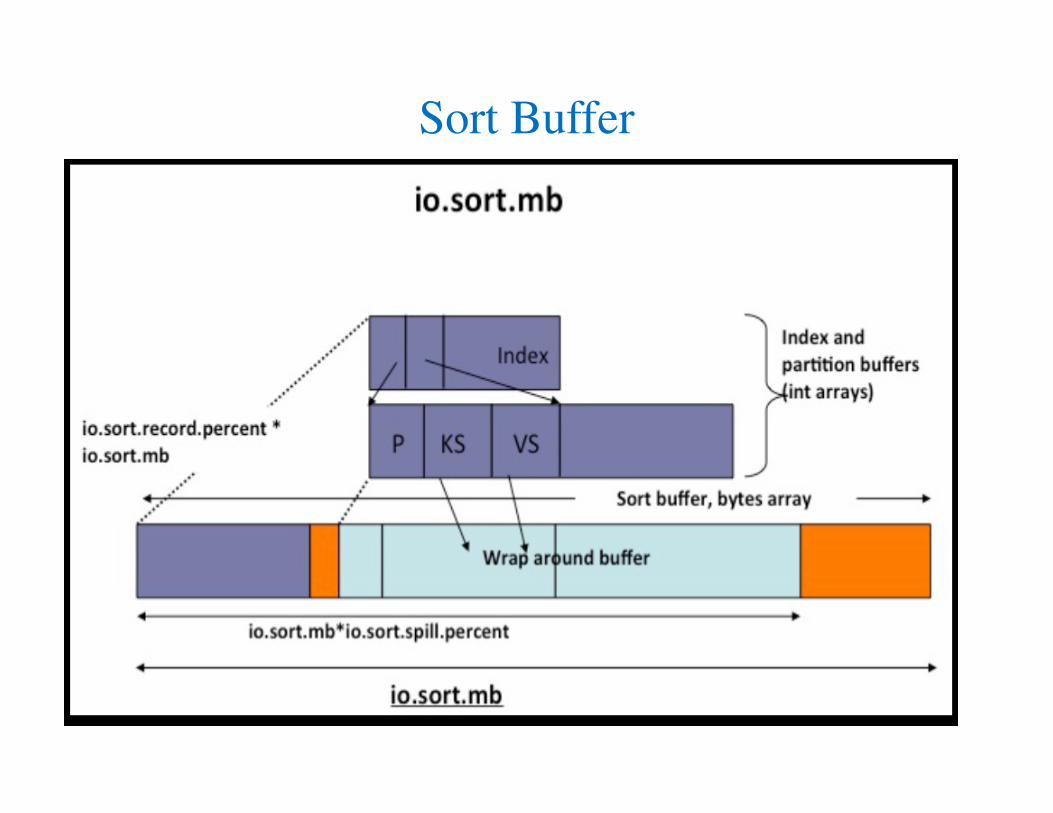
MR Job Parameters
• Map Parameters
io.sort.mb
• Shuffle/Reduce Parameters
io.sort.factor
mapred.inmem.merge.threshold
mapred.job.shuffle.merge.percent

Components in a Hadoop MR Workflow
Next few slides are from: http://www.slideshare.net/hadoop/practical-problem-solving-with-apache-hadoop-pig

Job Submission

Initialization

Scheduling
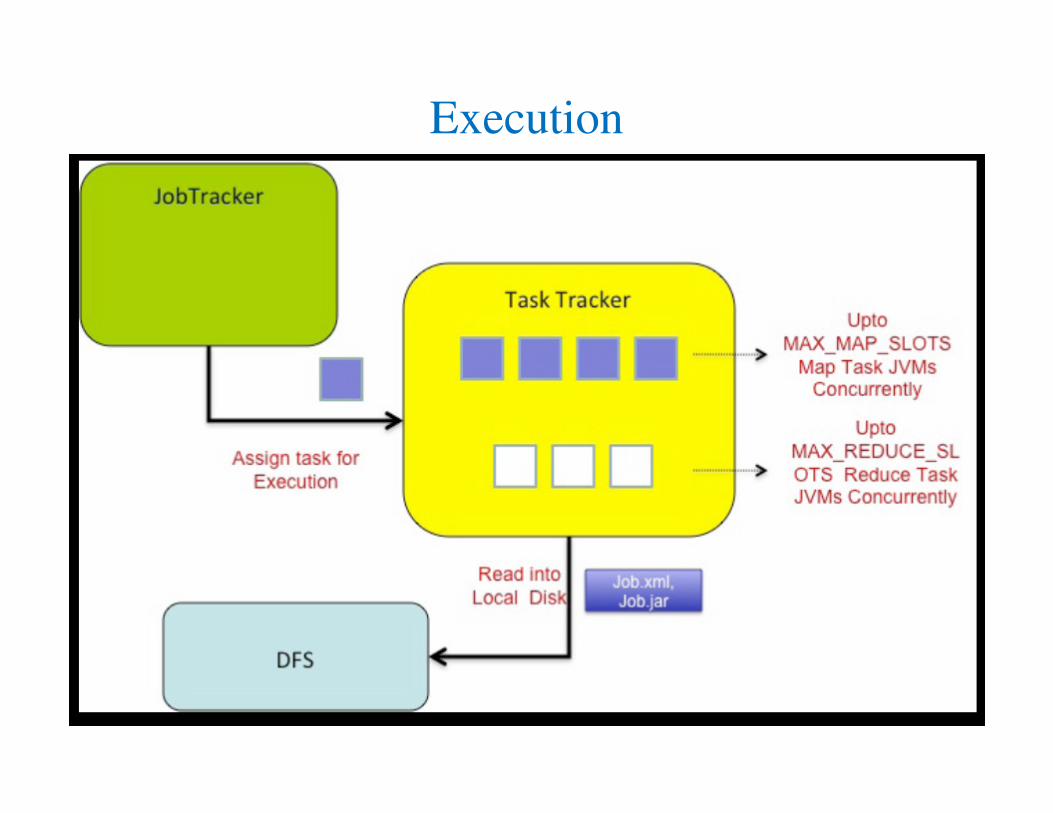
Execution
Map Task

Hadoop MR Job Interface:
Partitioner()
• Partitioner controls the partitioning of the keys of the
intermediate map-outputs.
• The key (or a subset of the key) is used to derive the
partition, typically by a hash function.
• The total number of partitions is the same as the
number of reducers
• HashPartitioner is the default Partitioner of reduce
tasks for the job

Partitioning at the end of Mapper
• The total number of
partitions in each mapper’s
local hard disk is the same
as the number of reducers.
So, B number of reducers
Input bufferfor Si
Hash table for partition
Ri (k < B-1 pages)
Sort/Combine on Key
(io.sort.mb)
Output
buffer
h2h2
B main memory buffers
(io.sort.mb)Disk
OUTPUT
2INPUT
1
hashfunction
h B
Partitions
12
B
. . .

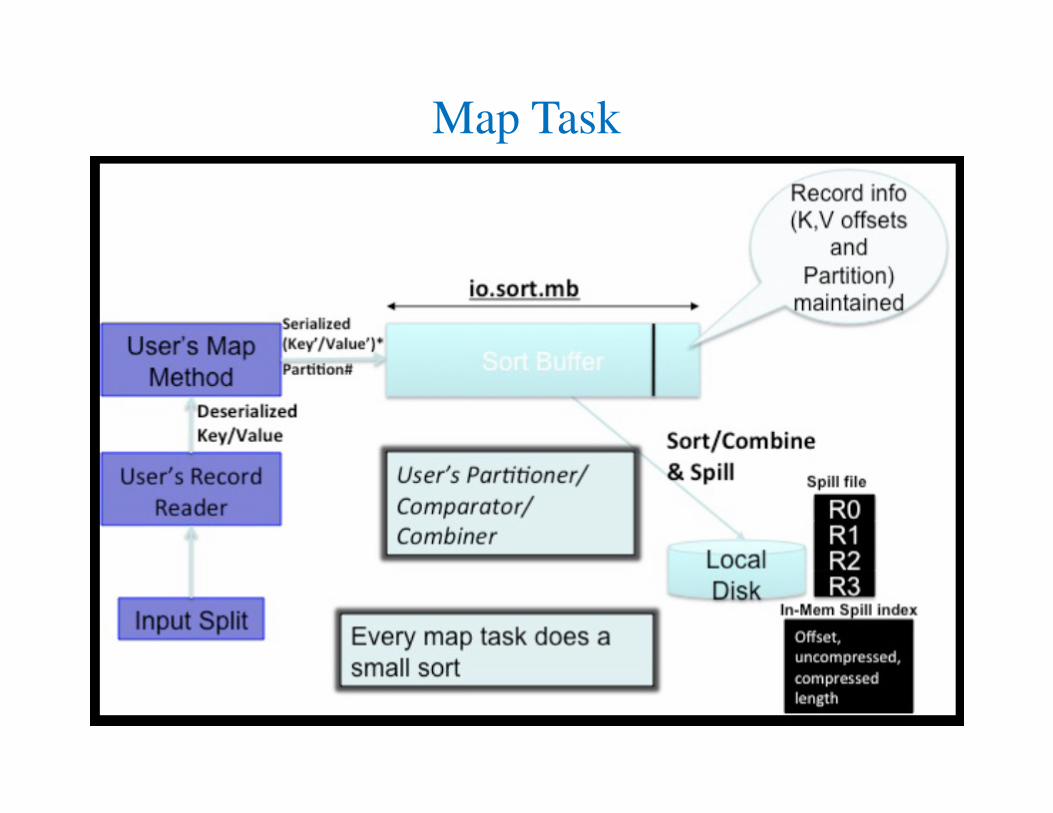
Map: Sort in io.sort.mb (in each Partition)
& Spill to Disk in Partitions
• A record emitted from a map will be serialized into a buffer and
metadata will be stored into accounting buffers.
• When either the serialization buffer or the metadata exceed a
threshold, the contents of the buffers will be sorted and written
to disk in the background while the map continues to output
records.
• If either buffer fills completely while the spill is in progress, the
map thread will block.
• When the map is finished, any remaining records are written to
disk and all on-disk segments are merged into a single file.
• Minimizing the number of spills to disk can decrease map time,
but a larger buffer also decreases the memory available to the
mapper.
Sort Buffer

Reduce Tasks

Quick Overview of Other Topics
• Dealing with failures
• Hadoop Distributed FileSystem (HDFS)
• Optimizing a MapReduce job

Dealing with Failures and Slow Tasks
• What to do when a task fails?
– Try again (retries possible because of idempotence)
– Try again somewhere else
– Report failure
• What about slow tasks: stragglers
– Run another version of the same task in parallel. Take
results from the one that finishes first
– What are the pros and cons of this approach?
Fault tolerance is ofhigh priority in the
MapReduce framework
HDFS Architecture
Map Wave 1
ReduceWave 1
Map Wave 2
ReduceWave 2
Input Splits
Lifecycle of a MapReduce Job
Time
How are the number of splits, number of map and reduce
tasks, memory allocation to tasks, etc., determined?

Job Configuration Parameters
• 190+ parameters in
Hadoop
• Set manually or defaults
are used

Image source: http://www.jaso.co.kr/265
Hadoop Job Configuration Parameters

Tuning Hadoop Job Conf. Parameters
• Do their settings impact performance?
• What are ways to set these parameters?
– Defaults -- are they good enough?
– Best practices -- the best setting can depend on data, job, and
cluster properties
– Automatic setting

Experimental Setting
• Hadoop cluster on 1 master + 16 workers
• Each node:
– 2GHz AMD processor, 1.8GB RAM, 30GB local disk
– Relatively ill-provisioned!
– Xen VM running Debian Linux
– Max 4 concurrent maps & 2 reduces
• Maximum map wave size = 16x4 = 64
• Maximum reduce wave size = 16x2 = 32
• Not all users can run large Hadoop clusters:
– Can Hadoop be made competitive in the 10-25 node, multi GB
to TB data size range?

Parameters Varied in Experiments

• Varying number of reduce tasks, number of concurrent sorted
streams for merging, and fraction of map-side sort buffer
devoted to metadata storage
Hadoop 50GB TeraSort

Hadoop 50GB TeraSort
• Varying number of reduce tasks for different values of the fraction of map-side sort buffer devoted to metadata storage (with io.sort.factor = 500)

Hadoop 50GB TeraSort
• Varying number of reduce tasks for different values of io.sort.factor (io.sort.record.percent = 0.05, default)

• 1D projection for
io.sort.factor=500
Hadoop 75GB TeraSort

Automatic Optimization? (Not yet in Hadoop)
Map Wave 1
Map Wave 3
Map Wave 2
ReduceWave 1
ReduceWave 2
Shuffle
Map Wave 1
Map Wave 3
Map Wave 2
ReduceWave 1
ReduceWave 2
ReduceWave 3
What if#reducesincreased
to 9?