handwritten recognition for ethiopic (ge ez) ancient
TRANSCRIPT

IN DEGREE PROJECT INFORMATION AND COMMUNICATION TECHNOLOGY,SECOND CYCLE, 30 CREDITS
, STOCKHOLM SWEDEN 2020
Handwritten Recognition for Ethiopic (Ge’ez) Ancient Manuscript Documents
ADISU WAGAW TEREFE
KTH ROYAL INSTITUTE OF TECHNOLOGYSCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE

Handwritten Recognition forEthiopic (Ge’ez) AncientManuscript Documents
ADISU WAGAW TEREFE
Master in Software Engineering of Distributed SystemsDate: November 20, 2020Supervisor: Anne HExaminer: Mihhail Matskin PROFESSOR, Kungliga Tekniska HogskolanSwedish title: Handskrivet erkännande för etiopiska (Ge’ez) ForntidamanuskriptdokumentSchool of Electrical Engineering and Computer Science


iii
AbstractThe handwritten recognition system is a process of learning a patternfrom a given image of text. The recognition process usually combinesa computer vision task with sequence learning techniques. Transcrib-ing texts from the scanned image remains a challenging problem, es-pecially when the documents are highly degraded, or have excessivedusty noises. Nowadays, there are several handwritten recognitionsystems both commercially and in free versions, especially for Latinbased languages. However, there is no prior study that has been builtfor Ge’ez handwritten ancient manuscript documents. In contrast, thelanguage has many mysteries of the past, in human history of science,architecture, medicine and astronomy.
In this thesis, we present two separate recognition systems. (1) Acharacter-level recognition system which combines computer visionfor character segmentation from ancient books and a vanilla Convo-lutional Neural Network (CNN) to recognize characters. (2) An end-to-end segmentation free handwritten recognition system using CNN,Multi-Dimensional Recurrent Neural Network (MDRNN) with Con-nectionist Temporal Classification (CTC) for the Ethiopic (Ge’ez)manuscriptdocuments.
The proposed character label recognition model outperforms 97.78%accuracy. In contrast, the second model provides an encouraging re-sult which indicates to further study the language properties for betterrecognition of all the ancient books.
Key WordsCNN, CTC, Ge’ez, Handwritten Recognition, LSTM, MDRNN

iv
SammanfattningDet handskrivna igenkännings systemet är en process för att lära sigettmönster från en viss bild av text. Erkännande Processen kombinerarvanligtvis endatorvisionsuppgiftmed sekvens inlärningstekniker. Tran-skribering av texter från den skannade bilden är fortfarande ett ut-manande problem, särskilt när dokumenten är mycket försämrad ellerhar för omåttlig dammiga buller. Nuförtidenfinns det flera handskrivnaigenkänningar systembåde kommersiellt och i gratisversionen, särskiltför latin baserade språk. Det finns dock ingen tidigare studie som harbyggts för Ge’ez handskrivna gamla manuskript dokument. I motsatstill detta språk har många mysterier från det förflutna, i vetenskapensmänskliga historia, arkitektur, medicin och astronomi.
I denna avhandling presenterar vi två separata igenkänningssystem.(1)Ett karaktärs nivå igenkänningssystem somkombinerar bildigenkän-ning för karaktär segmentering från forntida böcker och ett vanilj Con-volutional Neural Network (CNN) för att erkänna karaktärer. (2) Ettänd-till-slut-segmentering fritt handskrivet igenkänningssystem somanvänderCNN,Multi-Dimensional RecurrentNeuralNetwork (MDRNN)medConnectionist TemporalClassification (CTC) för etiopiska (Ge’ez)manuskript dokument.
Den föreslagna karaktär igenkänningsmodellen överträffar 97,78%nog-grannhet. Däremot ger den andra modellen ett uppmuntrande resul-tat som indikerar att ytterligare studera språk egenskaperna för bättreigenkänning av alla antika böcker.
NyckelordCNN, CTC, Ge’ez, Handskrivet erkännande, LSTM, MDRNN


Acronyms
BLSTM Bi-directional Long Short Term Memory. 6
CNN Convolutional Neural Networks. 9
CTC Connectionist Temporal Classification. 6
LSTM Long Short Term Memory. 6
MDLSTM Multi dimensional Long Short Term Memory. 8
MLP Multilayer Perceptron. 9
OCR Optical Character Recognition. 6, 9
RNN Recurrent Neural Networks. 9
SDG Sustainable Development Goals. 5
SVM Support Vector Machine. 14
UN United Nations. 5
v


List of Figures
1.1 An Ancient Handwritten Ge’ez manuscript documentpage, the snippet is taken from the book of the Miracleof Jesus. The books are written from left to write in mul-tiple columns, and they usually contain old paints of thesaints or other to clarify the content. The pigment in thetext shows the birth of Jesus Christ. . . . . . . . . . . . . 2
2.1 A Recurrent neural network architecture which showsa rolled network (left) and unrolled one (right), imagetaken from Colah’s blog post in 2015-08, UnderstandingLSTMs see [here for the original image], Accessed date:November 20, 2020 . . . . . . . . . . . . . . . . . . . . . . 11
2.2 LSTM gates and its interacting layers, image taken fromColah’s blog post in 2015-08, Understanding LSTMs see[here for the original image], Accessed date: November20, 2020 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1 Unlabelled 32x32 cropped image characters (syllables)generated from the segmenter algorithm . . . . . . . . . . 17
3.2 The count of individual characters in the dataset, that isgenerated from 134 books. As we can see in the plot themost dominant letter in the collection is the sixth charac-ter of the vowel row inGe’ez scripts which is symbolisedas (”እ” ). The second most dominant character in thelist is the script (”ል” ), which is also the sixth characterof the consonants that are found in the second row. . . . 18
4.1 Model 1, character label recognitionwithCNN.Themodelrequires an explicit segmentation of the characters withsome specific size (32x32). . . . . . . . . . . . . . . . . . . 23
vi

LIST OF FIGURES vii
4.2 The character recognition model . . . . . . . . . . . . . . 274.3 A single line of text, formed by using Listing 2 script,
while the individual characters, including the spaces,are taken randomly from different handwritten docu-ments. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4 A single line of text taken from the original book, pre-sented to show the differences of the synthetic data andthe original document. . . . . . . . . . . . . . . . . . . . . 28
4.5 Model 2, an end to end recognition model architecturewhich utilizes CNN, RNN specifically MDLSTM and CTC 31
4.6 An end-to-end model which is capable of predicting aline of text without using an explicit segmentation ofcharacters from the line. . . . . . . . . . . . . . . . . . . . 32
4.7 The first few CNN layers of the network, which are ca-pable of extracting essential features of the input images.TheReshape andDense layers are used to reduce dimen-sions. TheGaussian noise, on the other hand, adds noiseto the data to protect overfitting. . . . . . . . . . . . . . . 33
4.8 Here, the middle layers of the model, which are BLSTNlayers built to learn the more in-depth features of the se-quences. The sequences of texts are encoded here willbe decoded later in the CTC layer. . . . . . . . . . . . . . . 34
4.9 The final layer of themodel, which is aCTC layer respon-sible for transcribing the texts. TheCTC layermainly cal-culates the loss of the model by taking the input labelslength, output labels length, input labels, output labelsand the softmax layer. . . . . . . . . . . . . . . . . . . . . 35
5.1 Shows the training andvalidation accuracies for the char-acter level recognition, as we can see here, the modelperforms 0.9875 (98.75 %), 0.9777 (97.77 %) and 0.9778(97.78%) training, validation and test accuracies respec-tively. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 The losses of the training and the validation sets duringthe training of the model. . . . . . . . . . . . . . . . . . . 38
5.3 Illustration of the training validation loss for the modelcontaining bidirectional LSTM layers. Althoughwehavea minimal training resource and dataset size, the modelkeeps improving through time. . . . . . . . . . . . . . . . 39

viii LIST OF FIGURES
5.4 Illustration of the training validation loss for the modelcontaining unidirectional LSTM layers. In this model,there was no any improvement when we introduce anew data during the training. The possible reason isthat, only the forward pass was not enough to learn thesequences and be able to predict accurately. . . . . . . . 40
5.5 Predictions during the training, lines of texts are differ-ent in the dataset. As we can see the encoded texts arepredicted with 99% accuracy . . . . . . . . . . . . . . . . 40
A.1 The accuracy of the the-end-to-end model on new data,as shown on the snippet output, the model makes mis-takes on very similar characters. For example, on theninth row, one can see how hard it is to identify the dif-ferences of the first character of the word both in the la-bel and the prediction. . . . . . . . . . . . . . . . . . . . . 48
A.2 The overall network of the end-to-end model . . . . . . . 49


List of source codes
1 A segmenter function used to crop characters from thegiven input image. . . . . . . . . . . . . . . . . . . . . . . 25
2 A text to image generator script, which makes imagesof texts by selecting characters from the corpus and ran-domly taking respected images from the list of labelledimages using the previous model. . . . . . . . . . . . . . . 30
ix


Contents
1 Introduction 11.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Problem Statement . . . . . . . . . . . . . . . . . . . . . . 31.3 Research Question . . . . . . . . . . . . . . . . . . . . . . 31.4 Purpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.5 Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.6 Research Methodology . . . . . . . . . . . . . . . . . . . . 41.7 Research Benefits, Sustainability and Ethical Aspects . . 4
1.7.1 Research Benefits . . . . . . . . . . . . . . . . . . . 51.7.2 Research Sustainability . . . . . . . . . . . . . . . . 51.7.3 Research Ethical Aspects . . . . . . . . . . . . . . . 5
1.8 Delimitation . . . . . . . . . . . . . . . . . . . . . . . . . . 61.9 Structure of the Thesis . . . . . . . . . . . . . . . . . . . . 6
2 Theoretical Study 82.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Convolutional Neural Networks . . . . . . . . . . . . . . . 92.3 Recurrent Neural Networks . . . . . . . . . . . . . . . . . 9
2.3.1 Long Short Term Memory . . . . . . . . . . . . . . 112.4 Connectionist Temporal Classification . . . . . . . . . . . 132.5 Related Works . . . . . . . . . . . . . . . . . . . . . . . . . 14
3 Methodology 153.1 Research Process . . . . . . . . . . . . . . . . . . . . . . . 153.2 Data Collection Techniques . . . . . . . . . . . . . . . . . 15
3.2.1 Dataset Labeling . . . . . . . . . . . . . . . . . . . 183.3 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . 19
3.3.1 Software and Hardware . . . . . . . . . . . . . . . 193.3.2 Cloud Configuration . . . . . . . . . . . . . . . . . 21
x

CONTENTS xi
3.4 Data Analysis Tool . . . . . . . . . . . . . . . . . . . . . . 21
4 Implementation 224.1 Character Recognition Model . . . . . . . . . . . . . . . . 22
4.1.1 Character Segmentation . . . . . . . . . . . . . . . 224.1.2 Building CNN for Character Recognition . . . . . 26
4.2 Dataset Generation . . . . . . . . . . . . . . . . . . . . . . 284.3 The End-to-End Recognition Model . . . . . . . . . . . . 31
5 Result and Analysis 365.1 Analysis of the Character Level Model . . . . . . . . . . . 365.2 Analysis of the End-to-end Model . . . . . . . . . . . . . 38
6 Conclusion and Future Work 426.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 426.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.3 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . 43
Bibliography 44
A Unnecessary Appended Material 47


Chapter 1
Introduction
Handwriting recognition may be categorized into two systems, onlineand offline recognition. In the online recognition system a sequence ofcoordinates, representing the movement of the pen-tip, is captured. Incontrast, within the offline case, solely a scanned image of the text isavailable. Due to the ease of extracting relevant options, online recog-nition usually yields higher results [12].
Offline handwritten recognition uses both computer vision anddeep-learning methods to transcribe a fully scanned page. The computer vi-sion task has been used to extract valuable pieces of information fromthe given image of text either into character level or word level. How-ever, trimming the handwriting text is much harder than extractingtexts from printed or typewritten books. Traditional methods [2] seg-mented characters from words and compute segmentation hypothesesfor righteousness, for example, byperforming a heuristic over-segmentation,followed by the scoring of groups of segments [3].
1.1 BackgroundGeez is an ancient South Semitic language of the Ethiopic branchwhichhas survived in the form of a legendary language in Ethiopia [1] aswellas some other international institutions that teach Semitic studies as asubject (including Uppsala University).
Today, Ge’ez is used only as of the primary language of the liturgyof the Ethiopian andEritreanOrthodoxTewahedo churches, the Ethiopian
1

2 CHAPTER 1. INTRODUCTION
and Eritrean Catholic churches, and the Beta Israel Jewish community.The closest living languages to Ge’ez are Tigre and Tigrinya with lexi-cal similarity at 71% and 68%, respectively [1].
Figure 1.1: AnAncientHandwrittenGe’ezmanuscript document page,the snippet is taken from the book of theMiracle of Jesus. The books arewritten from left towrite inmultiple columns, and they usually containold paints of the saints or other to clarify the content. The pigment inthe text shows the birth of Jesus Christ.

CHAPTER 1. INTRODUCTION 3
Ge’ez language has 26 different consonants that aremarked for sevenvowels which are known as a fidel (26 * 7 = 182), 4 * 5 additional let-ters, 20 numbers, and eight punctuation marks. In full scripts are rep-resented in 230 syllables. The Ge’ez syllable is one of the rare writingsystems among the Semitic languages in which vowels are indicated[1]. As shown in figure 1.1, the writing system of Ge’ez language isfrom left to write, and a colon separates every word in ancient hand-written documents.
1.2 Problem StatementAncient Ethiopian history, beliefs, traditions, science and arts have beendocumented byGe’ez language. Most of these documents are availablein the national museum of Ethiopia, in Ethiopian Orthodox churchesand in some European countries such as France [8], the United King-dom, Germany, Italy and Sweden. Although these documents havevaluable contents, they are disappearing due to different factors. Themanuscripts are exposed to termite, fire, theft, moth and fading. More-over, these documents should be studied and well documented sincethere are no prior systems available.
1.3 Research QuestionThe key questions that we are going to address in the research are:
1. How do we generate a dataset from available books that are suit-able for deep learning tasks?
2. What amount of data is sufficient to effectively train and test thehandwriting recognition model?
3. Which approach works best to build and end-to-end recognitionmodel while preserving data that has a sequence to sequence in-put and output features?
4. What kind of deep learning algorithm combination can performbetter to recognize texts on images?

4 CHAPTER 1. INTRODUCTION
1.4 PurposeThis thesis work has the following purposes,
• preserving these heritages fromdamage by converting intomachine-readable formats,
• improve retrieval of information via the Internet and other appli-cations and
• allowing future researchers by digitizing the documents.
1.5 GoalThe main goal of this thesis work is to develop a handwritten recogni-tion system which can convert Ge’ez manuscript documents into ed-itable text formats (machine-readable, such as Unicode) by using thecurrent state-of-the-artmachine learning anddeep learning techniques.
1.6 Research MethodologyThe researchmethod describes the data preparations, the software andhardware used, and how the data is collected and analysed, includ-ing specifications of the procedures and measurements used for thedata analysis. However, a quantitative method, which is based on nu-merical data is appropriate for this research. In the quantitative re-search method, numerical information is collected, and the analysis isdone using mathematically-based methods [21]. We used qualitativeresearch method because we wanted to find and analyse the resultsthat we get from several experiments such as the loss and accuracy oftraining and tests (ex. in character label, and line label recognitions).
1.7 Research Benefits, Sustainability and Eth-ical Aspects
We expect that our research will have the following implications to-wards the research benefits, sustainability and ethical aspects.

CHAPTER 1. INTRODUCTION 5
1.7.1 Research BenefitsAs the thesis is about studying and converting the ancient handwrittentexts, the first and foremost beneficiary would be the owner of the doc-uments that is the Ethiopian Orthodox Church and its researchers. Asmentioned in section 1.2, ancient books are found in several interna-tional libraries and museums. Many international universities such as[10, 22] are still studying the language as it is one of the oldest Semiticlanguages. So these international universities and researchers wouldbe the next targets as they are interested in finding out the contents ofthe books and in studying the language properties. Moreover, by con-verting ancient documents into machine-readable formats, the projectsaves the language from disappearance, which then benefits the com-munity as a whole.
1.7.2 Research SustainabilityHeritages, especially ancient books, have been extraordinary originsof the current modern human development. Hence, studies on suchresource will have an impact on sustainable development. For the bet-ter achievements of sustainable developments set by United Nations(UN)’s Sustainable Development Goals (SDG), such as quality educa-tion[15], this kind of research has to be done more straightforwardly.Since researchers can have easy access to the ancient books in a digitalformat, we anticipate thatwewill have a contribution towards fulfillingthe UN’s SDG achievements.
1.7.3 Research Ethical AspectsWe performed extensive measurements and detailed analysis of thetwomodels concerning the accuracy and loss calculation. We attemptedto be very explicit in stating the setup and tools used in each datasetpreparation, the used hardware when training and the platform thatweused intending to facilitate reproducibility of our resultswhile keep-ing the privacy aspects of the available historical books.

6 CHAPTER 1. INTRODUCTION
1.8 DelimitationWe train our model to recognize only 200 syllables (198 characters andtwo punctuation marks) out of 230 syllables due to several reasons.Especially numbers in gees have several shapes that are not linkedwitheach other. For instance, the number four (፬ ) has a 0 like shape in themiddle and two curved dashed lines on the top and bottom of it, whichmakes it challenging to extract numbers from the given image usingcharacter segmentation algorithms.
1.9 Structure of the ThesisThis thesis project is about handwritten recognition system for Ge’ezlanguage, which aims to convert an input image of the ancient hand-written vellum Ge’ez documents to editable text files. It mainly de-scribes the approaches to the design and implementation of the hand-written recognition system using the latest deep learning and machinelearning libraries.
Chapter 1 introduces about Ge’ez language followed by the objec-tives and goals of the system. Chapter 2 describes the relevant back-ground of handwriting recognition and Optical Character Recognition(OCR) systems. In contrast, the third chapter discusses the methodsand data collection techniques that are used in this thesis. Chapter 4represents the implementation of the system, which describes how theproblem is solved using Long Short Term Memory (LSTM) and Con-nectionist Temporal Classification (CTC). The fifth chapter discussesthe results and findings of the thesis in detail. The last but least chap-ter presents the conclusions and future of works of the paper.
This thesis includes two separate models. The first model is aboutcharacter label recognition which combines image processing for thepre-processing tasks and a CNN model for the training and predic-tion. The second model, on the other hand, is an end-to-end recogni-tion model which does not require an explicit segmentation techniquefor both the pre-processing and transcription phase. This model usesthe CNN layer as a feature extractor, Bi-directional Long Short TermMemory (BLSTM) to find out the patterns and encode sequenced char-

CHAPTER 1. INTRODUCTION 7
acters, and CTS to calculate the loss of the prediction.


Chapter 2
Theoretical Study
This chapter provides necessary background information about hand-writing recognition, CNN, recurrent neural networks, more specifi-cally Multi dimensional Long Short Term Memory (MDLSTM) andCTC. Additionally, the chapter describes the related studies that areperformed to recognize the Ge’ez (Ethiopic) language.
2.1 BackgroundHandwritten recognition is the process of converting a text on imagesto machine-readable and editable formats. Unlike [12] traditional ap-proaches used both the image processing techniques, to segment therequired features from the given image and artificial neural networksto recognize the characters [2]. As indicated in the introduction sec-tion, one can classify handwritten recognition systems as offline andonline recognition systems. Offline handwritten recognition is inher-ently more challenging than online recognition systems, in which theinformation is available only from the given input image. Whereas, inthe online case, we can extract features from both the pen movementand the resulting image [12].
Moreover, the dimensions of the input images is still another chal-lenge in offline handwritten recognition, where we found the image intwo or three dimensions. In contrast, the input image needs to be trans-formed into a 1-dimensional image to be able to use multi-dimensionalrecurrent neural networks.
8

CHAPTER 2. THEORETICAL STUDY 9
2.2 Convolutional Neural NetworksA Convolutional Neural Networks (CNN) is one part of deep neuralnetworks, usually used for image analysis. CNNs include many moreconnections thanweights; in which the architecture itself shows a formof regularization. The regularization of the network realizes that CNNsare specific versions of Multilayer Perceptron (MLP). These networksautomatically provide some degree of translation invariance (a prop-erty of CNNs that allow them to be more robust to variations in theirpositions)[4].
Layers (input, hidden, and output) inCNNare diversified sub-sampling(pooling) layers to reduce the computational load, the memory usage,and the number of parameters, which further produces down-sampledversions of the input layers[4].Moreover, CNNs can be expressed by the following properties;
• Kernels: are hyperparameters of the network defined by thewidth and height of the receptive field.
• Input/Output channels: are also hyperparameters of the net-work that can show the number of input and output channels.
• Depth of the convolution: typically, the number of filters (in-put channels) must be equal to the number channels of the inputfeature map.
However, CNNs have been used in many pattern recognition areassuch as handwritten recognition [23, 19]. Moreover, CNN with Recur-rent Neural Networks (RNN) more specifically with Long Short TermMemory(LSTM) is highly used in handwritten and Optical CharacterRecognition (OCR) studies [20, 14].
2.3 Recurrent Neural NetworksRecurrent Neural Network (RNN) is one class of deep learning whichworks best on sequential data. Sequential data is a type of data wherethe order affects the meaning of the result. For example, when we hu-mans read a text, we do not throw the previous words and start un-derstanding each story from scratch. Instead, we save words, and they

10 CHAPTER 2. THEORETICAL STUDY
will stay persistently in our brain to get a full meaning of the context.The order of words in a sentence (especially in a written document)can have a significant effect on the definition.
In traditional neural networks, it is impossible to inference the pre-vious output and be able to predict the next event. For example, imag-ine we want to indicate tomorrow’s weather condition, where the pre-diction is dependent on today’s and yesterday’s weather. There is noway to refer back to yesterday’s and today’s outputs to predict tomor-row’s event when using feed-forward neural networks.
However, we can model such types of problems by using RNNs.Recurrent neural networks address this issue by using their internalstate as a memory to predict the next event. The state allows RNNs tosave the information for a longer time in the sequence.
Figure 2.1 shows the overall architecture of RNNs; the left side ofthe picture represents the foldednetworkwhile the right side of the pic-ture is the unfolded version of the system. In the network, the inputsare represented by Xt => X0, X1, X1...Xt, the outputs, on the otherhand, are represented by ht => h0, h1, h1...ht while the letter A repre-sents the activation function. The network accepts X0as its first inputfrom the sequence of the data with an output from h(t − 1) and thenperforms output h0 based some activation function. The output h0 isthen used as an input with X1 to the next step. The process continuesthe same way by taking a snapshot of the current state and passing itsresult to the next step.
More over we can represent RNNs mathematically as follows:
current state of the network:ht = f(ht−1, Xt)
Activation of the steps:ht = tanh(Whhht−1 +W (xh)Xt)

CHAPTER 2. THEORETICAL STUDY 11
Although RNNs can model sequential data with long-term depen-dencies, however, they have vanishing gradient and exploding prob-lems [13]. Vanishing gradient problem happens when training a stan-dard RNN during back-propagation. Since RNNs are capable of han-dling long dependencies, the gradients which are back-propagated canvanish. To overcome this problem, particular kinds of RNN have beendesigned, such as LSTM and GURU.
Figure 2.1: A Recurrent neural network architecture which shows arolled network (left) and unrolled one (right), image taken from Co-lah’s blog post in 2015-08, Understanding LSTMs see [here for the orig-inal image], Accessed date: November 20, 2020
2.3.1 Long Short Term MemoryLong Short Term Memory (LSTM) networks are special versions ofRNNs, which are capable of storing and remembering information fora longer time. Many authors, such as, [12, 11, 9], have contributed tothe development of LSTM networks after it was introduced by [13]. Itsmain advantage is that it can learn from long term dependencies andhave the ability to avoid vanishing gradient and exploding problems.
Moreover, LSTM works well in classifying, processing and predict-ing longer time series data with unknown time duration such as hand-written prediction and OCR systems in general. Standard RNNs havefolded structurewhich is a repeatingmodule of the neural network likethe tanh activation layer. LSTMs also have a similar chain-like designbut with a different repeating module architecture [18].
LSTMs repeating structure has four interacting layers and three gates.
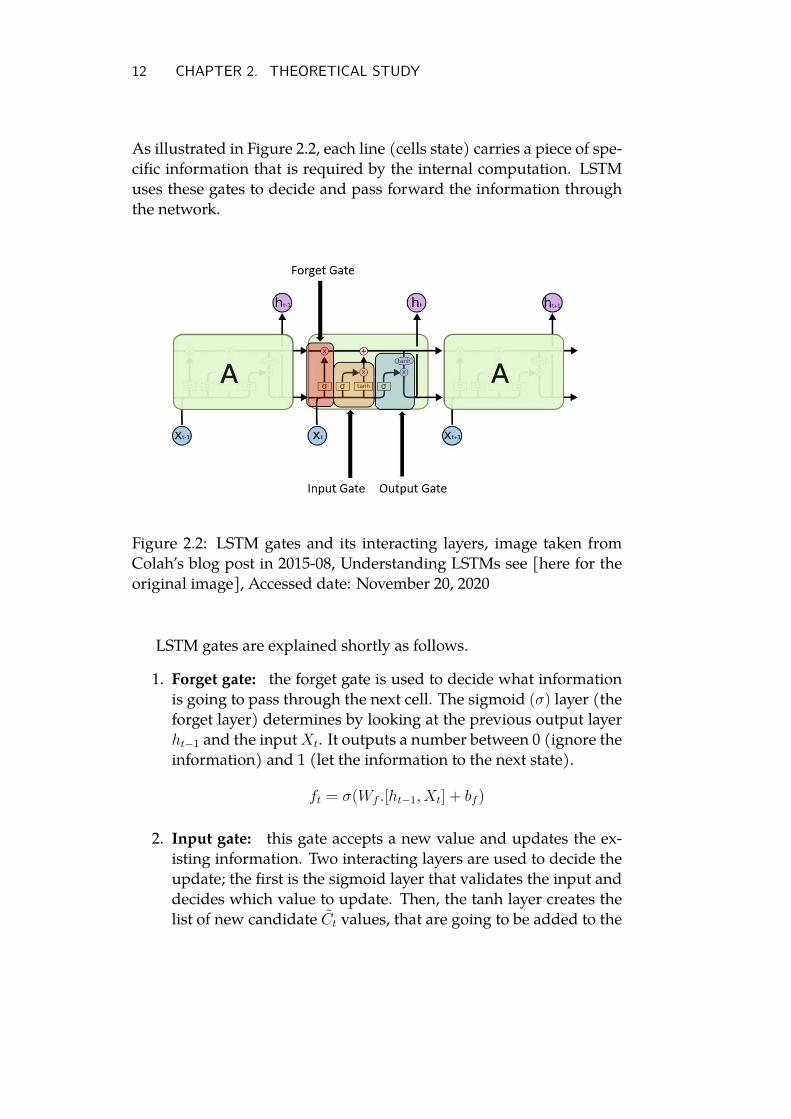
12 CHAPTER 2. THEORETICAL STUDY
As illustrated in Figure 2.2, each line (cells state) carries a piece of spe-cific information that is required by the internal computation. LSTMuses these gates to decide and pass forward the information throughthe network.
Figure 2.2: LSTM gates and its interacting layers, image taken fromColah’s blog post in 2015-08, Understanding LSTMs see [here for theoriginal image], Accessed date: November 20, 2020
LSTM gates are explained shortly as follows.
1. Forget gate: the forget gate is used to decide what informationis going to pass through the next cell. The sigmoid (σ) layer (theforget layer) determines by looking at the previous output layerht−1 and the inputXt. It outputs a number between 0 (ignore theinformation) and 1 (let the information to the next state).
ft = σ(Wf .[ht−1, Xt] + bf )
2. Input gate: this gate accepts a new value and updates the ex-isting information. Two interacting layers are used to decide theupdate; the first is the sigmoid layer that validates the input anddecides which value to update. Then, the tanh layer creates thelist of new candidate Ct values, that are going to be added to the

CHAPTER 2. THEORETICAL STUDY 13
next cell state.it = σ(Wf .[ht−1, Xt] + bi)
Ct = tanh(Wc.[ht−1, Xt] + bc)
3. Output gate: the last layer in the LSTM network is the outputlayer which combines the input and the forget layer. The outputwill be based on the cell information:
(a) The sigmoid layer will decide what parts of the cell state aregoing to be transferred to the output layer.
(b) The information that is passed through the sigmoid layerwill be then pushed to tanh layer and multiply it by the out-put of the sigmoid gate.
(c) The result can be decided by a sigmoid layer, as shown infigure 2.2.
Ot = σ(Wo.[ht−1, Xt] + bo)
ht = Ot ∗ tanh(Ct)
2.4 Connectionist Temporal ClassificationConnectionist Temporal Classification (CTC) is a type of neural net-work layer (usually used in the output) that is used to tackle the prob-lem of the alignment differences between the input and output. Con-sider a handwritten recognition systemwhich has an image pixel valueis an input and the corresponding characters as an output where thealignment of pixel to characters is accurately unknown.
Mathematically, let us consider mapping the input pixel value se-quences as X = [x1, x2, ..., xn] to corresponding output sequences ofcharacters or words Y = [y1, y2, ..., yt]. Hence, we have to find the accu-rate mapping from X’s to Y ’s while considering;
• Both the lengths of X and Y can vary.
• The alignment of X to Y is unknown correctly.
• Ratio of the lengths of X to Y can vary.

14 CHAPTER 2. THEORETICAL STUDY
CTC solves these challenges ”by allowing the network to make labelpredictions at any point in the input sequence, so long as the overallsequence of labels is correct” [12]. For a given set of inputs X , CTCgenerates an output distribution for all possible Y ’s. Moreover, theCTC algorithm does not require the exact alignment of the input andits corresponding output.
2.5 Related WorksNowadays, there are plenty of available handwritten recognition sys-tems and tools. These algorithms are prepared both commercially andin the free version more specifically for Latin based characters. Forexample, Google’s tesseract library is available for many internationallanguages as a free version. However, there are no prior studies ofGe’ez characters. In this thesis, we tried to set foundations for furtherstudies fo the language.
An extensive literature survey shows that there is no prior study onthe language that has tried to digitise handwritten Ge’ez documents.But there are a few studies that reveal the attempts towards recognisingthe Amharic language machine-printed forms. The Amharic languageis a descendant of Ethiopic Ge’ez which uses all of the Ge’ez syllableswith some own additional characters.
However, the approaches to recognise theAmharicmachine printeddocuments are also different from this thesis work. For example, astudy which was done by Million Meshesha, Optical Character Recog-nition ofAmharicDocuments [17] uses SupportVectorMachine (SVM)to train and recognize texts. While we used a modern and efficient ap-proach to recognize ge’ez handwritten characters.


Chapter 3
Methodology
The purpose of this chapter is to provide an overview of the researchmethod used in this thesis. Section 3.1 describes the research process.Section 3.2 focuses on the data collection techniques used for this re-search. Section 3.3 describes the experimental setups. Finally, section3.4 describes the tools that we used for data analysis.
3.1 Research ProcessWe started this thesis because there is a need to study Ge’ez languagein depth currently in Ethiopia, but without any available resource suchas books both in printed and digital formats. To further investigate thelanguage and save the available ancient handwritten books, we have toconvert them into machine-readable and editable formats. Since thisresearch is the first-ever study in handwritten recognition Ge’ez, westarted collecting available and representative documents in all cor-ners. After collecting about 134 ancient books, we pre-processed thebookpages to use line detection and character segmentation algorithms.
3.2 Data Collection TechniquesWorking with machine learning and deep learning heavily requires avery massive amount of training and test data-set to solve the givenproblem accurately. Data preparation is a critical step inmachine learn-ing and deep learning processes. It is a process that determines the ac-curacy of the model. Data preparation is a crucial start to get an accu-
15

16 CHAPTER 3. METHODOLOGY
rate model that makes the data-set more suitable for machine learningand deep-learning algorithms. Data formation process also requiresfinding and using the right data collection mechanism.
As described in section 1.6, we used a quantitative researchmethod,as it complies with the aim of this research. For this research, we clas-sified the data acquisition process into two sections. First, we collected,sampled ancient books and trained a semi-automated labeller model.Then, we used the trained model to generate the dataset to computethe primary training and to introduce the solution for the problem thatwe have stated.
Furthermore, in research like this thesiswork, for recognizing hand-written documents, the main task is to collect clean data and prepareit for additional processing. Since there is no publicly available datasetfor Ge’ez handwritten documents, the process takes more than threemonths before we run the first algorithm.
Considering that, we first built a character cropper algorithm thattakes an input image and splits each character from images of doc-uments. As shown in Figure 3.1, the algorithm generates a croppedcharacter from a book with some numbered name prefixed by syllable.
After running character segmenter algorithm, we want to performmapping operations, which is grouping characters into their classes.We have about 200 classes in this research that needs to be labelled.The quality of the character segmentation is the other challenge tomapcharacters to their classes. Since the segmenter algorithm only detectsan available pixel value and makes a contour around it, it is possible toconsider an arbitrary stroke of a syllable as a standalone character.
In Ge’ez script, there are characters which have similar shapes, asshown in Figure 3.1 row number 4, columns two and column 4. Theydiffer with each other with a little curve. As we can see from the pic-ture, the fourth column character is very similar to the second-rowfourth column character as well. Hence, the lines and strokes becomeeven more challenging.The algorithm we used here is also expected to identify the correct let-ter andmapwith their right group, which then leads us to use the clas-

CHAPTER 3. METHODOLOGY 17
sification algorithms. To train and classify the characters, the datasethas to be labelled correctly. Labelling the data is a very tedious andtime-consuming task.
Figure 3.1: Unlabelled 32x32 cropped image characters (syllables) gen-erated from the segmenter algorithm
Another challenge that we faced during data collection was the dis-tribution of the scripts that are available in the books. Ge’ez languageinherently uses some of the characters more frequently than others.For example, as shown in Figure 3.2 the count of a few characters in

18 CHAPTER 3. METHODOLOGY
the dataset is higher than the rest, which then results in a poor gener-alisation of the model.
Figure 3.2: The count of individual characters in the dataset, that isgenerated from 134 books. Aswe can see in the plot themost dominantletter in the collection is the sixth character of the vowel row in Ge’ezscripts which is symbolised as (”እ” ). The second most dominantcharacter in the list is the script (”ል” ), which is also the sixth characterof the consonants that are found in the second row.
3.2.1 Dataset LabelingThe dataset labelling task is a subsequent task that follows data collec-tion. As described in section 3.2, we can pull several characters fromthe available books in a fraction of seconds. The question is, though,how we can identify the correctly segmented syllables and map theminto their right classes? There aremanyways to solve this kind of prob-lem.
The naive mechanism can be using human resources and labellingmanually, which we did here for the first 8000 characters. This ap-

CHAPTER 3. METHODOLOGY 19
proach requires human resource for the labelling task. Many engineersare still using this technique for some problems that are hard to use au-tomated tools. The problem with this approach is that it takes a lot oftime, and it decreases the quality of the data since it is error-prone.However, we have used this technique for our character label recogni-tion model.
The second and efficient way is to use auto labelling tools or algo-rithms. Especially if the algorithm is designed to the specific problemas we did in this project, it will provide a very accurate labelled data.However, in this thesis, we have used both techniques to label and trainboth character label and the end to end recognition tasks.
For the end to end model labelling, we have used a Ge’ez bible cor-pus and the cropped characters. We did the labelling by picking awordfrom the corpus, then concatenating cropped characters to form awordimage. This process is described more in detail in section 4.2.
3.3 Experimental SetupThe following configurationswere adjusted to perform the training andtesting of the two models.
3.3.1 Software and HardwareWe used several platforms to train and test the work. The character la-bel model was trained and tested on MacBook pro that has 2.6 GHzQuad-Core Intel Core i7 processor, with memory 16 GB 2133 MHzLPDDR3 and graphics, Radeon Pro 450 2 GB Intel HD Graphics 5301536 MB. Although it was possible to use this machine, we encountera prolonged processing speed and an unusual sound from the device.When our dataset gets bigger and bigger, we moved our platform togoogle cloud platform.
Here follows a description of some specific APIs and libraries thatwe used during the development of the project and the measurementsin the qualitative method.

20 CHAPTER 3. METHODOLOGY
Keras
Keras is an open-source neural-network API that is written in Python.As described by Keras documentation ”it offers consistent & simpleAPIs, it minimizes the number of user actions required for commonuse cases, and it provides clear & actionable error messages. It alsohas extensive documentation and developer guides.”[6] From 2017,Google’s TensorFlow team decided to support Keras in TensorFlow’score library.
Therefore Keras is capable of running on top of Tensorflow library.It is mainly designed to enable fast experimentation with deep neuralnetworks, it focuses on being user-friendly, modular, and extensible.In this thesis, we used the Tensorflow Keras version 2. We chose Kerasbecause of its simplicity and support to the connectionist temporal clas-sification (CTC).
Tensorflow
TensorFlow is a free and open-source API, available to be used inmanyareas, it is mainly used for machine learning applications such as deepneural networks. It is used to express mathematical calculations thatare used by machine learning algorithms, and used to implement andexecute such algorithms [16].
To be able to use all features of Tensorflow, we used the tensor-flow version of keras in this project. It is also possible to export Kerastf models to JavaScript to deploy them on web applications that can beconsumed by browsers.
OpenCV
OpenCV (Open Source Computer Vision Library) is an open sourcecomputer vision andmachine learning software library [7]. In this the-sis we used OpenCV 3.4.10 version for our data preprocessing tasks.The line detection, character segmentation, image resizing and wordformations are done using OpenCV algorithms.

CHAPTER 3. METHODOLOGY 21
Jupyter notebook
The Jupyter Notebook is an open-sourceweb application that is used tocreate and share documents that contain live code, equations, visual-izations and narrative text [5]. Since it has an interactive and easy webinterface for running and visualisation, we used it to test and visualisethe trained models in our local machine.
3.3.2 Cloud ConfigurationGoogle cloud platform (GCP) configurations: We used GCP for the train-ing since it has a better computation power. Thus, to allow the incom-ing and outgoing network communications, while reading andwritingfiles back and forth, the firewall rules were configured. The port num-bers 9042 and 9160 were opened explicitly on instances to facilitate theread-write operations of the dataset that is copied to the instancemem-ory.
Python 3, tensorflow and keras were installed on the instance thatwe used on gcp. OpenCV 3.4 was also installed on the instance sincewe used it to load and process the dataset on both models.
3.4 Data Analysis ToolWe used Jupyter Notebook as a statistical tool since it provides a widerange of tools for data visualization and simple statistics to generate asummary of metrics, and customisable graphics and figures.
In addition to the libraries we mentioned in section 3.3.1 we used afew python libraries such asmatplotlib, a python 2D plotting library ca-pable of generating production-quality visualizations with a few linesof code. Plotting is a term used for visualizing a data in data science ormachine learning fields.


Chapter 4
Implementation
This chapter covers the implementation of an end-to-end handwrittenrecognition system, mechanisms to generate datasets from availablesources, ways to label datasets using trained models, and the descrip-tion of the building and testing the models.
4.1 Character Recognition ModelIn this section, we explain to the firstmodel, as shown in Figure 4.1, thatwe built to recognize geez characters for different purposes. First, wecreated the model to see if it is possible to recognize the handwrittencharacters individually by using the available books as the data source.Aswe are dealingwith a deep learning problemwithout prior availabledataset, we have to generate an appropriate and efficient amount ofdataset for the training, testing and validation tasks. Thus, we built thefirst model, that is the character level recognition model to generate alist of labelled images from a given text. We believe that exhaustivelylabelled data results in better training data, which then results in anaccurate prediction.
4.1.1 Character SegmentationCharacter segmentation in this context is an operation thatwe attemptedto chop the full image of text into Ge’ez letters. The task can be done inseveral ways using computer vision algorithms. As shown in Listing1, we define a function that requires the location of the scanned doc-ument and the output images. The naming can the image characters
22

CHAPTER 4. IMPLEMENTATION 23
Figure 4.1: Model 1, character label recognition with CNN. The modelrequires an explicit segmentation of the characters with some specificsize (32x32).
are prefixedwith a word syllable meaning letter followed by a number.We updated the name index after each iteration to protect overridingthe previously named characters.
The process starts by reading the list of input scanned pages basedon the specified path. While there are more scanned pages in the di-rectory do the following:
1. Read the scanned page from the list
2. Make a copy of the original scanned page
3. Convert the three channel image (BGR color ) into two channelimage (gray scale)
4. Apply Gaussian filter to the gray scale image by using 1x1 kernelsize.
5. Apply thresholding on the blurred image
6. Find contours on the page, meaning return pixel values whichhas higher values after applying the threshold and blurring.
7. For each contour in the page
• get the co-ordinates of the location with their width andheight

24 CHAPTER 4. IMPLEMENTATION
• if the width and height is below some value (23) skip thatcontour
• draw a bounding box on the copied image (for demonstra-tion purpose only)
• save the image which has higher pixel value• append images into the file using the specified file name.
The problem of this approach is that a black point in the book pageis considered as a character. As described in section 3.2, scripts thathave lines and strokes on top are more challenging when getting thebounding box. The algorithm sometimes considers them as standalonecharacters while they are parts of the script.

CHAPTER 4. IMPLEMENTATION 25
def character_segmenter(input_dir_path, output_dir_path, name_index):ip = os.listdir(input_dir_path)for scanned_doc in ip:
scanned_image = cv2.imread(input_dir_path+'/'+scanned_doc)scanned_image_in_gray = cv2.cvtColor(scanned_image,cv2.COLOR_BGR2GRAY)scanned_image_blured = cv2.GaussianBlur(scanned_image_in_gray,(1,1), 0)ret,th = cv2.threshold(scanned_image_blured, 0, 255,cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)image, contours, hierarchy = cv2.findContours(th,cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)for contour in contours:
[x, y, w, h] = cv2.boundingRect(contour)if w < 23 and h < 23:
continue
cropped = scanned_image[y :y + h , x : x + w]s ='fidel_' + str(name_index) + '.png'if not os.path.exists(output_dir_path):
os.makedirs(output_dir_path)cv2.imwrite(os.path.join(output_dir_path, s) , cropped)name_index = name_index + 1
Listing 1: A segmenter function used to crop characters from the giveninput image.

26 CHAPTER 4. IMPLEMENTATION
4.1.2 Building CNN for Character RecognitionA character-level recognition in this thesis is handled in two steps;
1. Detecting and identifying bounding boxes that contains a text inthe image.
2. Identifying the characters.
In the process, the CNN model typically learns the pattern. The wholeprocess involves pre-processing the data as described in section 4.1.1,that is converting the image into suitable size and colour channel, train-able feature extraction and classification.
As shown in Figure 4.1, we fed the network’s first layer, a 32x32grayscale image. Most of the characters on the books are written inblack colour, so we used it as an advantage to optimise the computa-tional power by reducing the number of channels fromRGB to grayscale.The first layer computes weighted sums of the input image pixels. Sub-sequent layers, on the other hand, add weighted sums of the outputsof the previous layers.
The last layer on our character recognition model has 200 neurons.Although the language we are recognising has more than 235 charac-ters, we are dealing with only the most common characters of it. Thusthe last layer neurons tell us that we want to classify handwritten geezcharacters into 200 classes. For this reason, we used a softmax activa-tion layer to calculate the probability of each character being predicted.
Why is it not enough building Character level recognition?
The process that we have performed so far recognises characters, andone may ask, why are you building another model to identify charac-ters in the image? The questions seem fair enough to ask. However,segmentation is still the most demanding task to crop texts in the im-age, including the small colons which separate words in Ge’ez. So, wehave to learn patterns regardless of their alignment in the image to de-tect and identify characters, which is our next task in this thesis.

CHAPTER 4. IMPLEMENTATION 27
Figure 4.2: The character recognition model

28 CHAPTER 4. IMPLEMENTATION
4.2 Dataset GenerationThis section presents the process of generating a dataset to our nextmodel. Dataset generation in this context is creating a newdataset fromscratch provided a set of character images with a corpus which is a col-lection of different texts.
The previous model that we built as a character recognition modelplays a crucial role in creating the new dataset. As we mentioned inListing 1, the segmenter function only generates a list of small imagecharacters. But the trained character recognition model was able toidentify these images and puts with their corresponding label values.Thus, the cropped images are now classified into 200 classes.
Now the setups are ready to create the magical ancient handwrit-ten lines of texts on the image. Figures 4.2 and 4.3 are lines of texts thatare formed and taken from the ancient Ge’ez books, respectively. Theformer line of text is formed by our text_to_image() function. The textson the line are taken from our set of images which are generated byour character segmenter script. In contrast, the later Figure 4.3 imageis directly cropped from one of the original books that we used as adata source.
Figure 4.3: A single line of text, formed by using Listing 2 script, whilethe individual characters, including the spaces, are taken randomlyfrom different handwritten documents.
Figure 4.4: A single line of text taken from the original book, presentedto show the differences of the synthetic data and the original document.
The above two lines of images have insignificant differences exceptfor the weight of the pixels on the synthetic image. To this end, the full

CHAPTER 4. IMPLEMENTATION 29
set of labelled images are produced by using our script, as shown inListing 2.
The core idea of the function text_to_image() is that it is possibleto generate a dataset that does not require augmentation techniquessince all the images are from different sources with a different size andpixel weight.
The script requires the paths of both the cropped images and thecorpus. The detailed explanation of the text to the image generator isas follows. While there are characters in the corpus:
1. if the character is from the corpus and if it is available from thelabels list then, get the directory of the images named with thecurrent character
2. if the character is a new line or a space:
• thenwrite the concatenated images a single image andnameit with the characters
• reset the concatenated word_images to None• reset the set of characters to empty to hold the next word
3. if the directory that you gave me in step 1 is available:
• get all the image names and store into a list• if there is any other file inside the directory like some hidden
objects, filter them, only save the file names that ends with.jpg.
• from the set select one randomly• based on the selected name read the image, then resize it to
a 32x32• if the word_image is None, then save the selected one• otherwise concatenate the resized image with the previous
images• similarly concatenate characters until you find a space or a
new line terminator.
Once the text to image writer is done, then we are ready to build theCRNN model with CTC as a cost function.

30 CHAPTER 4. IMPLEMENTATION
def text_to_image(lbl_img_path="data", corpus_path="corpus.docx"):corpus = docx2txt.process(corpus_path)word_image = None word_chars = ""for g_char in corpus:
if not g_char == " " and g_char in allowed_g_chars:g_char_dir = os.path.join(".", "c_dataset", lbl_ime_path,
g_char)if g_char == " ":
cv.imwrite(os.path.join(".", "txt_img", word_chars +".png"), word_image)
word_image = None word_chars = ""if os.path.exists(g_char_dir):
g_char_files = os.listdir(g_char_dir)g_char_files = list(filter(lambda x: x.endswith(".jpg"),
g_char_files))if not g_char_files:
continuetry:
selected_file = os.path.join(g_char_dir,g_char_files[random.randint(0, len(g_char_files)-1)])
except Exception as e:print(e)
selected_image = cv.imread(selected_file)selected_image = cv.resize(selected_image, (32,32))
if word_image is None:word_image = selected_image
else:word_image = np.concatenate((word_image,
selected_image), axis= 1)word_chars += g_character
Listing 2: A text to image generator script, whichmakes images of textsby selecting characters from the corpus and randomly taking respectedimages from the list of labelled images using the previous model.

CHAPTER 4. IMPLEMENTATION 31
4.3 The End-to-End Recognition ModelIn this section, we present amodel that does not require an explicit seg-mentation of characters to recognize the line of texts on the image. Themodel, as shown below 4.5 is built using CNN, RNNandConnectionistTemporal Classification (CTC).
Figure 4.5: Model 2, an end to end recognition model architecturewhich utilizes CNN, RNN specifically MDLSTM and CTC
In the network;
1. The input image is fed to the standard CNN layers. The few lay-ers of the CNN layer extracts the feature maps from the givenimage and transfers the output to the next layer.The challenge in this approach is, standard CNN layers only ac-cept an image that has a specified size (width and height). It isimpractical to find lines of texts that have equal length.However, we took the longest line in the list and padded the restof line images with a white pixel value.
2. Then the outputs of the CNN layer, which are feature maps arefed into an RNN layer specifically to the bidirectional long shorttermmemory (BLSTM) layer. As described in section 2.3.1, LSTMnetworks are capable of handling sequences, which identifies therelationship between the characters.
3. Finally, the output of the BLSTM layer is fed into a CTC layerwhich is a transcription layer. The CTC layer takes the sequenceof characters and learns their alignment with the image, includ-ing redundant characters, and uses the probability distributionto transcribe the output.

32 CHAPTER 4. IMPLEMENTATION
As explained in section 2.3, recurrent neural networks work best forthe sequence to sequence problems. They can preserve the informationthey have seen in the past and use the knowledge they have to predictthe next sequence in the output. In addition to inferring the knowledgethey learn from sequences inputs to sequences outputs, they are capa-ble of learning in both forward and backward directions.
Hence, predicting the output based on the previously learned datais not sufficient. Training the network in two directions can reveal bet-ter information by getting the information from past to future and viceversa. That is done using bidirectional LSTM. When running in thebackwards direction, we are preserving the data from the end, and thesame analogy applies for running in the forward direction. Thus, wemaintain the information from both directions.
The pictorial representation of the model is shown below in Figure4.4. As an example, the model takes an image which has a sequenceof characters on it and fed to the CNN layer. The CNN layer extractshandy information such as vertical edges, horizontal edges etc. Asshown in Figure 4.5, we added some noises to protect overfitting themodel, since we have not generated enough dataset for the training.
Figure 4.6: An end-to-end model which is capable of predicting a lineof text without using an explicit segmentation of characters from theline.
The CNN layers pool features to the bidirectional layers. As shownin Figure 4.6, four bidirectional layers learn in both directions and thenconcatenated for the next CTC layer.
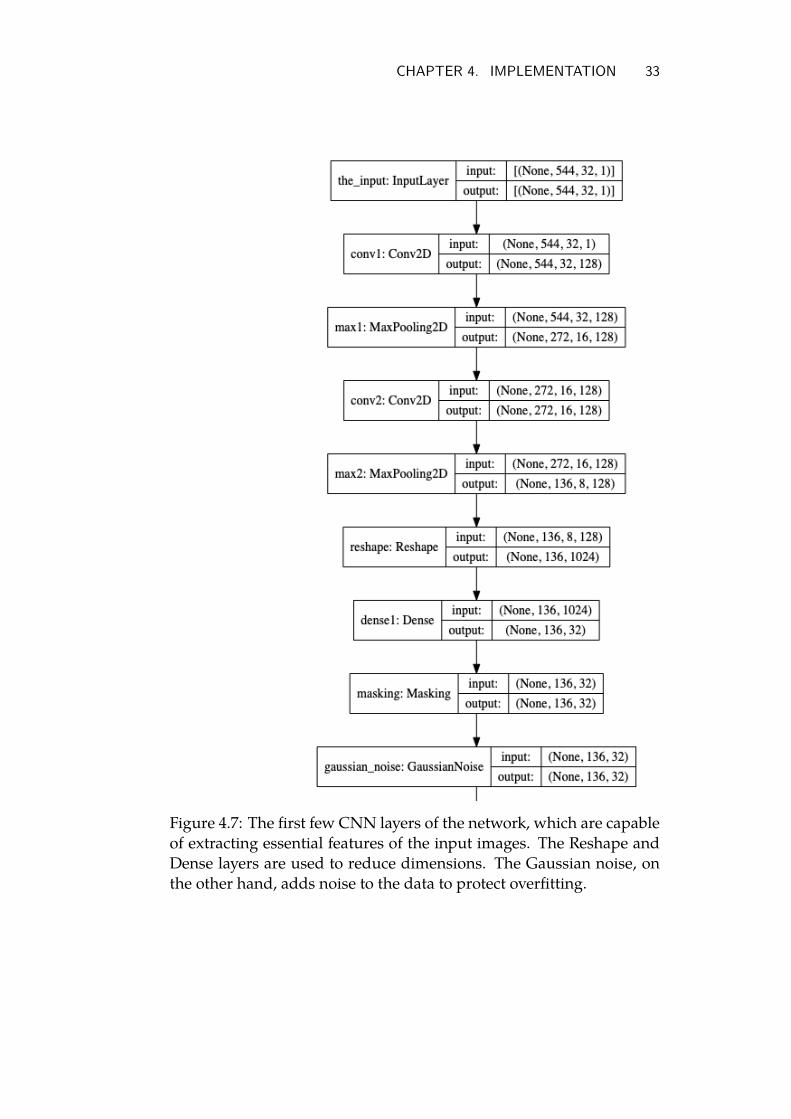
CHAPTER 4. IMPLEMENTATION 33
Figure 4.7: The first few CNN layers of the network, which are capableof extracting essential features of the input images. The Reshape andDense layers are used to reduce dimensions. The Gaussian noise, onthe other hand, adds noise to the data to protect overfitting.
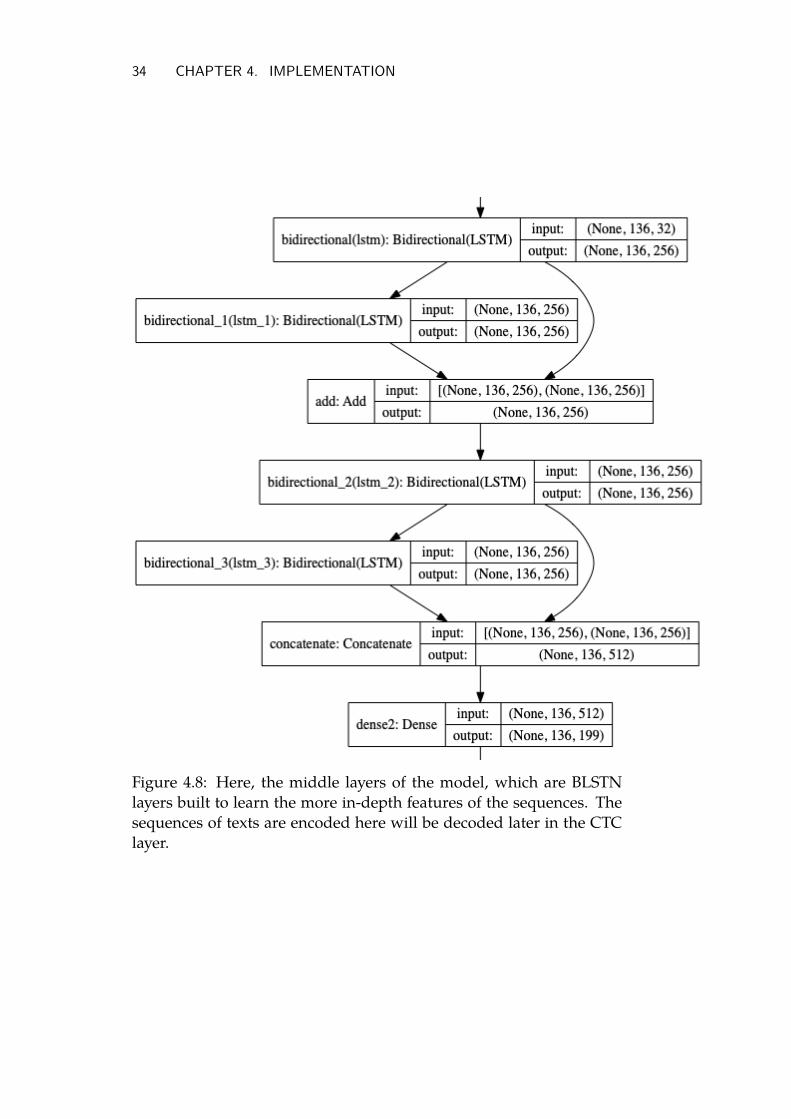
34 CHAPTER 4. IMPLEMENTATION
Figure 4.8: Here, the middle layers of the model, which are BLSTNlayers built to learn the more in-depth features of the sequences. Thesequences of texts are encoded here will be decoded later in the CTClayer.
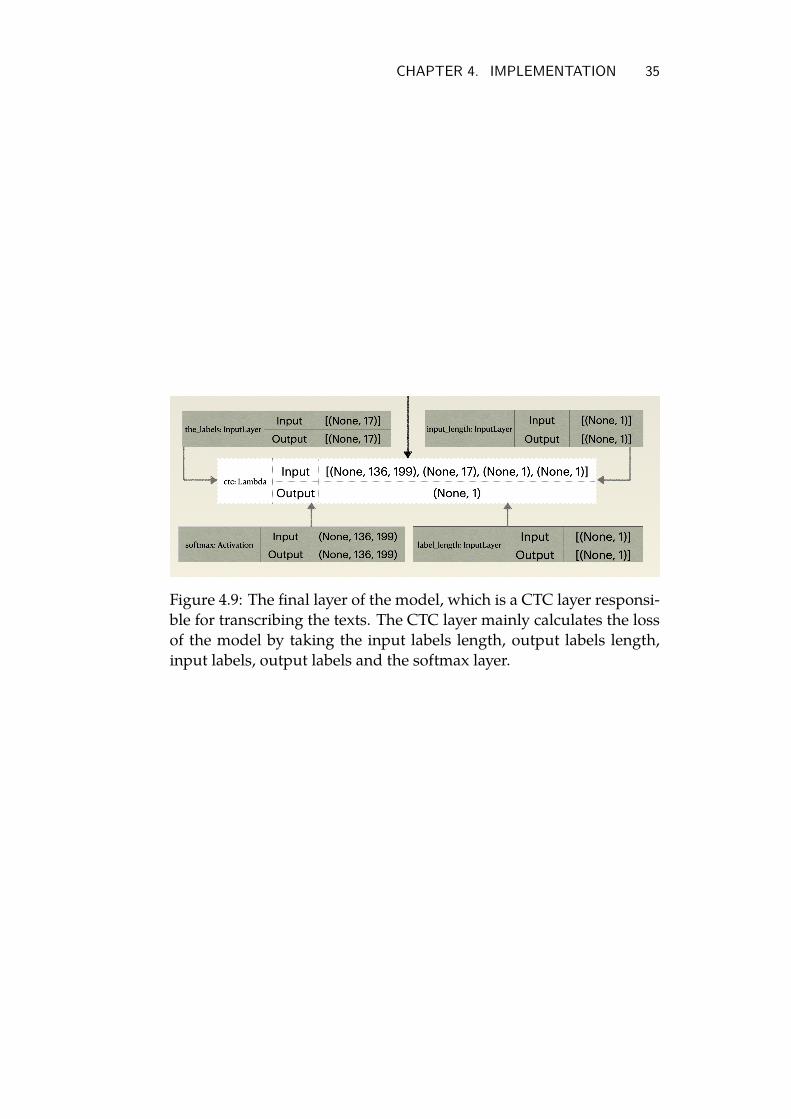
CHAPTER 4. IMPLEMENTATION 35
Figure 4.9: The final layer of the model, which is a CTC layer responsi-ble for transcribing the texts. The CTC layer mainly calculates the lossof the model by taking the input labels length, output labels length,input labels, output labels and the softmax layer.


Chapter 5
Result and Analysis
This chapter explains the collected results from both character labeland end-to-end models based on the outputs we get from the train-ing of the models. It covers the performances of the models and thebenchmarking network results of the end-to-end recognition system.The first part discusses the accuracy and loss of the first model, whilethe second section shows the different outputs of our second model.
5.1 Analysis of the Character Level ModelThe proposed character label model outperforms best when the num-ber of training data gets bigger and bigger. Our benchmark in thisanalysis is the size of the dataset and the batch size during the train-ing. Since the images are tiny in size, we used the batch size of 256,which then works well. As we can in Figure 5.1, the training convergesfaster, in only 20 epochs. After 20 periods, the model starts overfittingthe data, and we stopped the training by using a technique called earlystopping.
The validation accuracy seemed to be stabled, indicating that themodel predicts well when it gets new data, as we classified our datasetinto a training set and validation set. The training accuracy tests themodel performance using the data it has already while the validationaccuracy is the measure of the accuracy of the model in new data thatit has not seen yet.
However, when the number of epochswas increased, the validation
36

CHAPTER 5. RESULT AND ANALYSIS 37
accuracy drops drastically indicating that the model is getting weakerto generalise and predict accurately the data that it brings. But we usedan early stopping mechanism to prevent the model from overfitting.
Figure 5.1: Shows the training and validation accuracies for the char-acter level recognition, as we can see here, the model performs 0.9875(98.75 %), 0.9777 (97.77 %) and 0.9778 (97.78 %) training, validationand test accuracies respectively.

38 CHAPTER 5. RESULT AND ANALYSIS
Similarly, the losses of the training set and validation set are illus-trated in Figure 5.2. The training loose keeps decreasing while the val-idation loss starts bending upwards. The reason is that the model be-gins overfitting the data after iterating over it for 20 rounds. Since thevalidation loss stops the improvement over time, we call the EarlyStop-ing call back object to stop further training iterations.
Figure 5.2: The losses of the training and the validation sets during thetraining of the model.
5.2 Analysis of the End-to-end ModelThe proposed end-to-end model has been benchmarked with severalnetworks. First, we build and train the model without the first fewCNN layers. In this approach, the raw image was fed to the bidirec-tional RNN network. The second approach was using unidirectionalLSTM instead of bidirectional LSTM. Finally, we perform using CNNfor the first few layers to extract valuable features, bidirectional LSTM

CHAPTER 5. RESULT AND ANALYSIS 39
to encode the internal representation of the characters and the CTClayer to calculate the loses and to decode texts.
As shown in the graphs 5.3 and 5.4, the bidirectional LSTM layersperform better. The bidirectional layers maintain the information fromboth directions, which makes them suitable for text analysis problems.In contrast, unidirectional LSTM layers only keep the past data and tryto infer that knowledge through prediction.
The accuracy of the model is shown in Figure 5.5. During the train-ing, we intentionally used shorter lines of images which padded withwhite pixels to save the training resource requirements. The paddedwhite pixels will be collapsed by the CTC algorithm later in the tran-scription. However, we added a few long lines of texts in training tothe model to get a better result. But the training time and the accuracywas not as expected due to less number of long lines of images in thedataset.
Figure 5.3: Illustration of the training validation loss for the modelcontaining bidirectional LSTM layers. Although we have a minimaltraining resource and dataset size, themodel keeps improving throughtime.

40 CHAPTER 5. RESULT AND ANALYSIS
Figure 5.4: Illustration of the training validation loss for themodel con-taining unidirectional LSTM layers. In this model, there was no anyimprovement when we introduce a new data during the training. Thepossible reason is that, only the forward pass was not enough to learnthe sequences and be able to predict accurately.
Figure 5.5: Predictions during the training, lines of texts are differentin the dataset. As we can see the encoded texts are predicted with 99%accuracy

CHAPTER 5. RESULT AND ANALYSIS 41
Generally, the two models showed an outstanding and promisingresult. As the character level recognition model has a 97.78% of ac-curacy, it was enough to detect and recognize characters if we had anaccurate text extractor in the documents. Moreover, words in the doc-ument are separated by a colon so that we could have taken advantageof it. But due to the lack of such algorithms, we could not be able touse this model to convert texts into the desired format fully.
However, the second model, which is the end-to-end recognitiongives us an encouraging result. Due to the lack of prior dataset and ap-propriate hardware, we restricted the model to only train and predictlines of texts in the documents.


Chapter 6
Conclusion and Future Work
This section summarises the goal and the main features of the thesiswork. Then, it points out the limitations and suggestions of the projectfor future works.
6.1 ConclusionGe’ez is an unstudied language while it kept the mysteries of humandevelopment both in science and spirituality. In this thesis, we in-vestigated the ways to convert handwritten documents into machine-readable and editable formats. We successfully generated the datasetfrom scratch that can be used in further studies. We have also imple-mented the character label and end-to-end recognition systems. Wetested our models which are built using the current state-of-the-artdeep-learning algorithms and achieved our goal on how we can useand combine them to recognize patterns on an image and transcribethem into text.
CNNwithRNNremains the best approach to solve a problemwhichhas a sequence to sequence image data. Although the CNN layer re-quires an equal-sized input image, it performs well in extracting thepatterns that are relevant for encoding texts in the image. BidirectionalLSTMs have been an excellent choice to learn in both directions by il-luminating gradient vanishing problems. The connectionist temporalclassification (CTC) algorithm is used to calculate the loss of the net-work by collecting the loss from different layers, the label length, inputlength and the label from input layers and the output from the output
42

CHAPTER 6. CONCLUSION AND FUTURE WORK 43
layer.
Moreover, a better training device and a massive amount of datasetcan help to fully convert the scanned images of ancient documents intothe desired format.
6.2 LimitationsThe study is limited only to recognize 200 syllables (characters) out of230 available characters in Ge’ez language as mentioned in 1.1 owingto several reasons
1. Inherently the shapes of the characters (syllables) are not suit-able to the existing segmenter algorithms. Mostly the contoursof the numbers; they are not connected pixels in the form of lineor circle instead they have separated curved lines on top and bot-tom of each symbol which makes it challenging to consider it asa corresponding pixel value during segmentation.
2. Hardware problem: weusedpersonal computers, which hasmin-imal resources like GPU and CPU to train and test the modelwhile expecting to classify 230 classes in the output layer of themodels that require powerful hardware.
Furthermore, the size of the dataset that we generated is not sufficient,as deep-learning algorithms are hunger in data. Although the writingsystem in the ancient Ge’ez document is very similar, the number ofbooks that we used to generate the dataset is somehow limited to 134.Additionally, the corpus that we had in hand seemed to be boundedsince we used some parts of the bible.
6.3 Future WorkThis thesis project sets the necessary foundations of converting ancientGe’ez handwritten documents intomachine-readable formats. Our nextgoal is to generate more data from different books and include the re-maining characters to convert documents into the desired format fully.

Bibliography
[1] Marvin Lionel Bender. “The non-Semitic languages of Ethiopia.”In: (1976).
[2] YoshuaBengio et al. “Lerec:ANN/HMMhybrid for on-line hand-writing recognition.” In:Neural computation 7.6 (1995), pp. 1289–1303.
[3] Théodore Bluche. “Joint line segmentation and transcription forend-to-end handwritten paragraph recognition.” In: Advances inNeural Information Processing Systems. 2016, pp. 838–846.
[4] Jake Bouvrie. “Notes on convolutional neural networks.” In: (2006).[5] Jupyter Notebook Documentation. Jupyter Notebook Documenta-
tion. https://jupyter.org/documentation. [Online; accessed2020-02-02]. 2020.
[6] Keras Documentation. Keras API Reference. https://keras.io/api/. [Online; accessed 2020-02-02]. 2020.
[7] OpenCVDocumentation.OpenCVDocumentation. https://docs.opencv.org/3.4.10/d1/dfb/intro.html. [Online; accessed2020-02-02]. 2020.
[8] The National Library of France. Quelques manuscrits. https://gallica.bnf.fr/html/und/afrique/quelques- manuscrits.[Online; accessed 2019-08-02]. 2008.
[9] Felix A Gers, Jürgen Schmidhuber, and Fred Cummins. “Learn-ing to forget: Continual prediction with LSTM.” In: (1999).
[10] Georg-August-UniversitätGöttingen.Non-EuropeanCultural Stud-ies. https://www.sub.uni-goettingen.de/geisteswissenschaften-und-theologie/aussereuropaeische-kulturwissenschaften/thematische-suche/. [Online; accessed 2020-11-02]. 2020.
44

BIBLIOGRAPHY 45
[11] AlexGraves, Santiago Fernández, and Jürgen Schmidhuber. “Bidi-rectional LSTM networks for improved phoneme classificationand recognition.” In: International Conference on Artificial NeuralNetworks. Springer. 2005, pp. 799–804.
[12] AlexGraves and Jürgen Schmidhuber. “Offline handwriting recog-nitionwithmultidimensional recurrent neural networks.” In:Ad-vances in neural information processing systems. 2009, pp. 545–552.
[13] SeppHochreiter. “The vanishing gradient problemduring learn-ing recurrent neural nets and problem solutions.” In: Interna-tional Journal of Uncertainty, Fuzziness and Knowledge-Based Sys-tems 6.02 (1998), pp. 107–116.
[14] Takaaki Hori et al. “Advances in joint CTC-attention based end-to-end speech recognition with a deep CNN encoder and RNN-LM.” In: arXiv preprint arXiv:1706.02737 (2017).
[15] Saskia D Keesstra et al. “The significance of soils and soil sciencetowards realization of the United Nations Sustainable Develop-ment Goals.” In: Soil (2016).
[16] Martın Abadi et al. TensorFlow: Large-Scale Machine Learning onHeterogeneous Systems. Software available from tensorflow.org.2015. URL: https://www.tensorflow.org/.
[17] M. Meshesha and C. Jawahar. “Optical Character Recognition ofAmharic Documents.” In: Afr. J. Inf. Commun. Technol. 3 (2007).
[18] ChristopherOlah.Understanding LSTMs. http://colah.github.io/posts/2015-08-Understanding-LSTMs. [Online; accessed2020-02-02]. 2015.
[19] Ahmed El-Sawy, EL-Bakry Hazem, and Mohamed Loey. “CNNfor handwritten arabic digits recognition based on LeNet-5.” In:International conference on advanced intelligent systems and informat-ics. Springer. 2016, pp. 566–575.
[20] Baoguang Shi, Xiang Bai, and Cong Yao. “An end-to-end train-able neural network for image-based sequence recognition andits application to scene text recognition.” In: IEEE transactions onpattern analysis and machine intelligence 39.11 (2016), pp. 2298–2304.
[21] Suphat Sukamolson. “Fundamentals of quantitative research.”In: Language Institute Chulalongkorn University 1 (2007), pp. 2–3.

46 BIBLIOGRAPHY
[22] University of Toronto. The university is now one of the only places inthe world where students can learn Ge’ez. https://www.utoronto.ca/news/u-t-launches-class-ancient-ethiopian-language-very-nature-university. [Online; accessed 2020-10-08]. 2020.
[23] Chunpeng Wu et al. “Handwritten character recognition by al-ternately trained relaxation convolutional neural network.” In:2014 14th International Conference on Frontiers inHandwritingRecog-nition. IEEE. 2014, pp. 291–296.

Appendix A
Unnecessary Appended Material
47

48 APPENDIX A. UNNECESSARY APPENDED MATERIAL
Figure A.1: The accuracy of the the-end-to-end model on new data,as shown on the snippet output, the model makes mistakes on verysimilar characters. For example, on the ninth row, one can see howhard it is to identify the differences of the first character of the wordboth in the label and the prediction.
APPENDIX A. UNNECESSARY APPENDED MATERIAL 49
Figure A.2: The overall network of the end-to-end model

TRITA-EECS-EX-2020:834
www.kth.se