grdi2020 final roadmap · pdf filethe grdi2020 roadmap is an official grdi2020 project...
TRANSCRIPT

GRDI2020 – A Coordination Action:
Towards a 10-year vision for global research data infrastructures
Funded under the Seventh Framework Programme (FP7) - Infrastructures,
“Capacities – Research Infrastructures” - Project Number: 246682
GRDI2020 Final Roadmap Report
Global Research Data Infrastructures: The Big Data Challenges
This document has been generated by the GRDI2020 Consortium and its principal author is CNR-
ISTI. The GRDI2020 roadmap is an official GRDI2020 project deliverable submitted to the European
Commission in February 2012.

GRDI2020 Final Roadmap Report Page 2 of 108
DISCLAIMER
GRDI2020 is funded by the European Commission under the 7th Framework
Programme (FP7).
The goal of GRDI2020 project, Towards a 10-year vision for global research data
infrastructures, is to establish a framework for obtaining technological,
organisational, and policy recommendations guiding the development of ecosystems
of global research data infrastructures. Mobilising user communities, large initiatives,
projects, leading experts, and policy makers throughout the world and involving
them in GRDI2020 activities will achieve the establishment of this framework.
This document contains information on core activities, findings, and outcomes of
GRDI2020. It also contains information from the distinguished experts who are in two
external groups – the Advisory Board Members (AB), and the Technological and
Organisational Working Groups. Any reference to content in this document should
clearly indicate the authors, source, organisation, and date of publication.
The document has been produced with the funding of the European Commission. The content of this
publication is the sole responsibility of the GRDI2020 Consortium and its experts, and it cannot be
considered to reflect the views of the European Commission.
The European Union (EU) was established in accordance with the Treaty on the European Union
(Maastricht). There are currently 27 member states of the European Union. It is based on the European
Communities and the member states’ cooperation in the fields of Common Foreign and Security Policy and
Justice and Home Affairs. The five main institutions of the European Union are the European Parliament,
the Council of Ministers, the European Commission, the Court of Justice, and the Court of Auditors
(http://europa.eu.int/).
Copyright © The GRDI2020 Consortium. 2010.
See http://www.grdi2020.eu/StaticPage/About.aspx for details on the copyright holders.
GRDI2020 (“Towards a 10-Year Vision for Global Research Data Infrastructures”) is a project funded by the European Commission
within the framework of the 7th Framework Programme for Research and Technological Development (FP7), Research
Infrastructures Coordination Action under the Capacities Programme - Géant & eInfrastructures Unit. For more information on the
project, its partners and contributors please see http://www.grdi2020.eu. You are permitted to copy and distribute verbatim
copies of this document containing this copyright notice, but modifying this document is not allowed. You are permitted to copy
this document in whole or in part into other documents if you attach the following reference to the copied elements:
“Copyright © 2010. The GRDI2020 Consortium. http://www.grdi2020.eu/StaticPage/About.aspx”
The information contained in this document represents the views of the GRDI2020 Consortium as of the date they are published.
The GRDI2020 Consortium does not guarantee that any information contained herein is error-free, or up to date. THE GRDI2020
CONSORTIUM MAKES NO WARRANTIES, EXPRESS, IMPLIED, OR STATUTORY, BY PUBLISHING THIS DOCUMENT.
GRDI2020 Final Roadmap Report Page 3 of 108
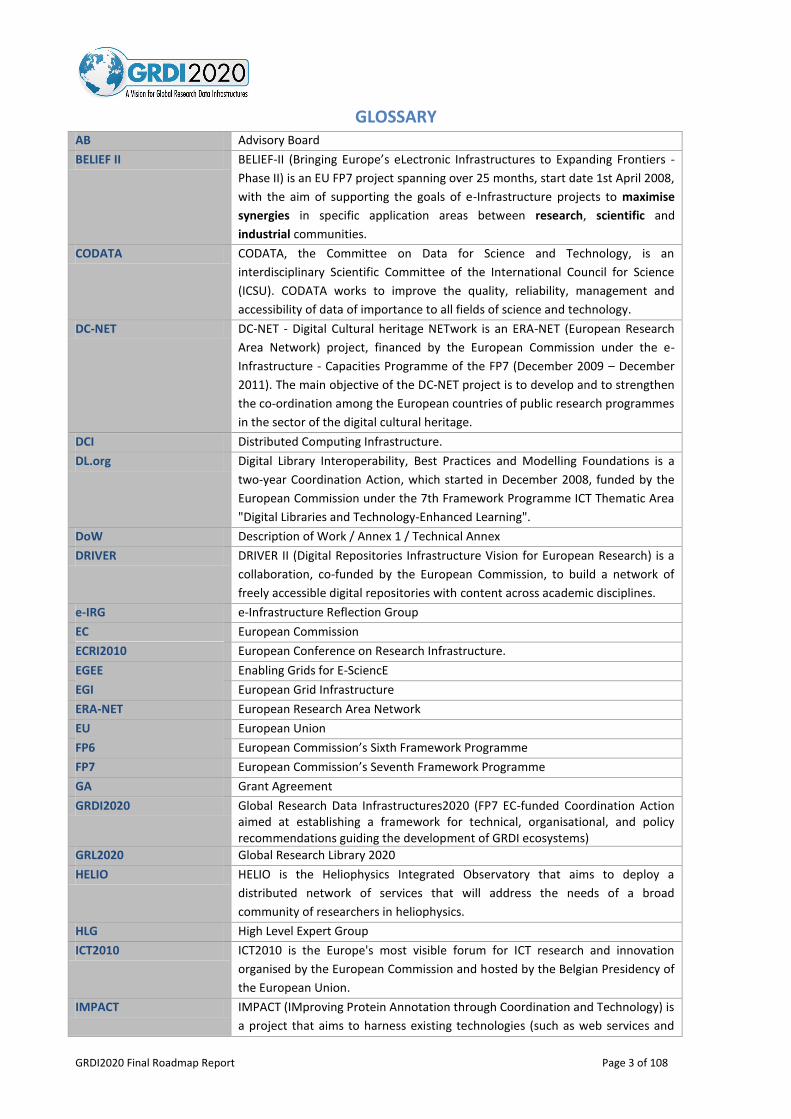
GLOSSARY AB Advisory Board
BELIEF II BELIEF-II (Bringing Europe’s eLectronic Infrastructures to Expanding Frontiers -
Phase II) is an EU FP7 project spanning over 25 months, start date 1st April 2008,
with the aim of supporting the goals of e-Infrastructure projects to maximise
synergies in specific application areas between research, scientific and
industrial communities.
CODATA CODATA, the Committee on Data for Science and Technology, is an
interdisciplinary Scientific Committee of the International Council for Science
(ICSU). CODATA works to improve the quality, reliability, management and
accessibility of data of importance to all fields of science and technology.
DC-NET DC-NET - Digital Cultural heritage NETwork is an ERA-NET (European Research
Area Network) project, financed by the European Commission under the e-
Infrastructure - Capacities Programme of the FP7 (December 2009 – December
2011). The main objective of the DC-NET project is to develop and to strengthen
the co-ordination among the European countries of public research programmes
in the sector of the digital cultural heritage.
DCI Distributed Computing Infrastructure.
DL.org Digital Library Interoperability, Best Practices and Modelling Foundations is a
two-year Coordination Action, which started in December 2008, funded by the
European Commission under the 7th Framework Programme ICT Thematic Area
"Digital Libraries and Technology-Enhanced Learning".
DoW Description of Work / Annex 1 / Technical Annex
DRIVER DRIVER II (Digital Repositories Infrastructure Vision for European Research) is a
collaboration, co-funded by the European Commission, to build a network of
freely accessible digital repositories with content across academic disciplines.
e-IRG e-Infrastructure Reflection Group
EC European Commission
ECRI2010 European Conference on Research Infrastructure.
EGEE Enabling Grids for E-SciencE
EGI European Grid Infrastructure
ERA-NET European Research Area Network
EU European Union
FP6 European Commission’s Sixth Framework Programme
FP7 European Commission’s Seventh Framework Programme
GA Grant Agreement
GRDI2020 Global Research Data Infrastructures2020 (FP7 EC-funded Coordination Action aimed at establishing a framework for technical, organisational, and policy recommendations guiding the development of GRDI ecosystems)
GRL2020 Global Research Library 2020
HELIO HELIO is the Heliophysics Integrated Observatory that aims to deploy a
distributed network of services that will address the needs of a broad
community of researchers in heliophysics.
HLG High Level Expert Group
ICT2010 ICT2010 is the Europe's most visible forum for ICT research and innovation
organised by the European Commission and hosted by the Belgian Presidency of
the European Union.
IMPACT IMPACT (IMproving Protein Annotation through Coordination and Technology) is
a project that aims to harness existing technologies (such as web services and

GRDI2020 Final Roadmap Report Page 4 of 108
distributed computing) and use them to dramatically improve existing
information resources.
METAFOR METAFOR (Common Metadata for Climate Modelling Digital Repositories) is a
project that aims to develop a Common Information Model (CIM) to describe
climate data and the models that produce it in a standard way, and to ensure
the wide adoption of the CIM.
OGF Open Grid Forum
OpenAIRE OpenAIRE (Open Access Infrastructure for Research in Europe) is an initiative
that aims to support the implementation of Open Access in Europe by
establishing the infrastructure for researchers to support them in complying
with the EC OA pilot and the ERC Guidelines on Open Access.
SDI Science Data Infrastructures
SEALS SEALS (Semantic Evaluation At Large Scale) is a co-funded project that aims to
provide an independent, open, scalable, extensible and sustainable
infrastructure (the SEALS Platform) that allows the remote evaluation of
semantic technologies thereby providing an objective comparison of the
different existing semantic technologies.
WG Working Group
WP WorkPackage
Table 1 - Glossary

GRDI2020 Final Roadmap Report Page 5 of 108
TABLE OF CONTENTS
Acknowledgments ...................................................................................................................... 7
1. Executive Summary ............................................................................................................. 8
2. Methodology..................................................................................................................... 10
3. The New Science Paradigm ................................................................................................ 12
4. Research Data Infrastructures ........................................................................................... 13
4.1 Data-Intensive Science .......................................................................................................... 15
4.2 Multidisciplinary – Interdisciplinary Science ........................................................................... 15
5. A Strategic Vision for a Global Research Data Infrastructure .............................................. 17
5.1 Defining the Digital Science Ecosystem................................................................................... 17
5.1.1 Digital Data Libraries (Science Data Centres) .......................................................................... 18
5.1.2 Digital Data Archives ................................................................................................................ 19
5.1.3 Digital Research Libraries ........................................................................................................ 20
5.1.4 Communities of Research ........................................................................................................ 20
5.2 Digital Science Ecosystem Concepts ....................................................................................... 20
5.3 Global Research Data Infrastructures: The GRDI2020 Vision ................................................... 21
6. Technological Challenges ................................................................................................... 27
6.1 Data Challenges ..................................................................................................................... 27
6.1.1 Data Modeling ......................................................................................................................... 27
6.1.2 Metadata Modeling ................................................................................................................. 28
6.1.3 Data Provenance Modeling ..................................................................................................... 28
6.1. 4 Data Context Modeling ............................................................................................................ 29
6.1.5 Data Uncertainty Modeling ..................................................................................................... 30
6.1.6 Data Quality Modeling ............................................................................................................. 30
6.2 Data Management Challenges ............................................................................................... 31
6.2.1 Data Curation ........................................................................................................................... 31
6.3 Data Tools Challenges ............................................................................................................ 31
6.3.1 Data Visualization .................................................................................................................... 32
6. 3.2 Massive Data Mining ............................................................................................................... 33
7. System Challenges ............................................................................................................. 34
7.1 Virtual Research Environment (VRE) ...................................................................................... 34
7.2 Science Gateways .................................................................................................................. 35
7.3 Ontology Management .......................................................................................................... 35
7.4 Scientific Workflow Management .......................................................................................... 40
7.5 Interoperability and Mediation Software ............................................................................... 44
7.5.1 Exchangeability – The Heterogeneity Problem ....................................................................... 45
7.5.2 Compatibility – The Logical Inconsistency Problem ................................................................ 45
7.5.3 Usability – The Usage Inconsistency Problem ......................................................................... 45
7.5.4 Mediation Software ................................................................................................................. 46
8. Infrastructural Challenges .................................................................................................. 48

GRDI2020 Final Roadmap Report Page 6 of 108
8.1 Data and Data Service/Tool Findability .................................................................................. 48
8.1.1 Data Registration ..................................................................................................................... 49
8.1.2 Data Citation ............................................................................................................................ 52
8.1.3 Data Discovery ......................................................................................................................... 56
8.1.4 Data Tool/Service Discovery .................................................................................................... 58
8.2 Data Federation .................................................................................................................... 62
8.2.1 Data Integration....................................................................................................................... 62
8.2.2 Data Harmonization ................................................................................................................. 64
8.2.3 Data Linking ............................................................................................................................. 65
8.3 Data Sharing.......................................................................................................................... 66
9. Application Challenges ...................................................................................................... 71
9.1 Complex Interaction Modes ................................................................................................... 71
9.2 Multidisciplinary – Interdisciplinary Research ........................................................................ 71
9.2.1 Boundary Objects .................................................................................................................... 73
9.3 Globalism and Virtual Proximity ............................................................................................ 74
10. Organizational Challenges .............................................................................................. 75
10.1 Digital Data Libraries (Science Data Centres) ....................................................................... 75
10.2 Digital Data Archives .......................................................................................................... 76
10.3 Personal Workstations ....................................................................................................... 77
11. A New Computing Paradigm: Cloud Computing .............................................................. 78
12. A New Programming Paradigm: MapReduce .................................................................. 86
13. Policy Challenges ........................................................................................................... 90
14. Open Science – Open Data ............................................................................................. 95
15. Recommendations ....................................................................................................... 100
16. References .................................................................................................................. 104

GRDI2020 Final Roadmap Report Page 7 of 108
Acknowledgments
The GRDI2020 Consortium would like to thank all those who have provided feedback and suggestions to
the roadmap, in particular;
Malcolm Atkinson, GRDI2020 Advisory Board Member
Dan Atkins, Univ. of Michigan, Vice-President for Research Cyber-infrastructure & GRDI2020 Advisory
Board Member
Antonella Fresa, DC-Net Project Coordinator, Italy
Fabrizio Gagliardi, EMEA Director, Microsoft Research Connections (External Research), Microsoft
Research, UK & GRDI2020 Advisory Board Member
David Giaretta, STFC and Alliance for Permanent Access, United Kingdom & HLG-SDI Rapporteur*
Stephen M. Griffin, Program Director Information Integration and Informatics (III) cluster, National Science
Foundation, US
Ray Harris, Emeritus Professor, University College London & GRDI2020 Advisory Board Member
Jane Hunter, University of Queensland, Australia
Simon Lin, Academia Sineca & GRDI2020 Advisory Board Member
Monica Marinucci , Director, Oracle Public Sector, Education & Research Business Unit & HLG-SDI
Member*
Reagan Moore, Director of the Data Intensive Cyber Environments (DICE Center) & Prof. in School of
Library Information Science at the Univ. of North Carolina at Chapel Hill, US
Vanderlei Perez Canhos, President Director of the Reference Center on Environmental Information (CRIA),
Brazil & GRDI2020 Advisory Board Member
Laurent Romary, INRIA & Humboldt University & HLG-SDI Member*
Michael Wilson, e-Science Department, STFC Rutherford Appleton Laboratory, United Kingdom
Peter Wittenburg, Technical Director, Max Planck Institute for Psycholinguistics, The Netherlands & HLG-
SDI Member*
*European Commission, Directorate General Information Society & Media High Level Expert Group on Scientific Data
The GRDI2020 Consortium is composed of Trust-IT Services Ltd. (UK), Consiglio Nazionale delle Ricerche, -
Istituto di Scienza e Tecnologie dell' Informazione A. Faedo (CNR-ISTI) (IT), ATHENA Research & Innovation
Center in Information Communication & Knowledge Technologies (GR) PDC Center for High Performance
Computing, Kungliga Tekniska Hoegskolan (SE)

GRDI2020 Final Roadmap Report Page 8 of 108
1. Executive Summary
New high-throughput scientific instruments, telescopes, satellites, accelerators, supercomputers,
sensor networks and running simulations are generating massive amounts of data.
The availability of huge volumes of data is a big opportunity and at the same time is a big
challenge for scientists.
This data availability can revolutionize the way research is carried out and lead to a new data-
centric way of thinking, organizing and carrying out research activities.
However, in order to be able to exploit these huge volumes of data, new techniques and
technologies are needed. A new type of e-infrastructure, the Research Data Infrastructure, must
be developed for harnessing the accumulating data and knowledge produced by the communities
of research.
Research Data Infrastructures can be defined as managed networked environments for digital
research data consisting of services and tools that support: (i) the whole research cycle, (ii) the
movement of research data across scientific disciplines, (iii) the creation of open linked data
spaces by connecting data sets from diverse disciplines, (iv) the management of scientific
workflows, (v) the interoperation between research data and literature and (vi) an integrated
Science Policy Framework.
Science is a global undertaking and research data are both national and global assets. Therefore,
there is a need for global research data infrastructures for overcoming language, policy, and social
barriers and reducing geographic temporal, and National barriers in order to discover, access and
use of data.
The next generation of global scientific data infrastructures is facing two main challenges:
To effectively and efficiently support data-intensive Science
To effectively and efficiently support multidisciplinary/interdisciplinary Science
In this Report an organizational model of the science universe is defined, based on the ecosystem
metaphor, in order to conceptualize all the “research relationships “ between the components of
the science universe.
According to this metaphor a digital science ecosystem is a complex system composed of Digital
Data Libraries (Data Centres), Digital Data Archives, Digital Research Libraries and Communities of
Research. A Global Research Data Infrastructure should act as: an enabler of an open, extensible
and evolvable digital science ecosystem; a facilitator of data, information and knowledge
discovery; and an enhancer of problem–solving processes.
The Report describes a core set of functionality that must be provided by Global Research Data
Infrastructures in order to make the holdings (data collections and data tools) of the science
ecosystem components discoverable, interoperable, correlatable and usable.

GRDI2020 Final Roadmap Report Page 9 of 108
To make this happen several technological breakthroughs must be achieved in the fields of
research data modelling and management, data tools and services. In addition, several system,
application, organization, and policy challenges must be successfully tackled.
This Report, whose intended audience are policy makers, scientists, engineers, computer scientists
and theoreticians, highlights some of the many difficult technological problems that must be
solved in order to make feasible the building of theoretically founded global scientific data
infrastructures.
To pursue a strategy aimed at achieving our vision for global scientific data infrastructures a
number of recommendations are given and explained in detail in Section 15:
1. Science social and organizational aspects should be taken in due consideration when
designing global research data infrastructures as well as potential tensions which could be
faced or provoked by them.
2. Global Research Data Infrastructures must be based on scientifically sound foundations.
3. Formal models and query languages for data, metadata, provenance, context, uncertainty
and quality must be defined and implemented.
4. New advanced data tools must be developed.
5. Future Research Data Infrastructures must support open linked data spaces.
6. Future Research Data Infrastructures must support interoperation between science data
and literature.
7. New advanced infrastructural services must be developed.
8. The principles of open science and open data in order to be widely accepted must be
realized within an integrated science policy framework to be implemented and enforced by
global research data infrastructures.
9. A new international research community must be created
10. New Professional Profiles must be created

GRDI2020 Final Roadmap Report Page 10 of 108
2. Methodology
When producing a Roadmap Report on scientific data infrastructures the main difficulty faced by
the authors is how to distinguish it from a plethora of roadmaps and white papers produced by
international organizations (ICSU, ESFRI, e-IRG, etc.), projects & initiatives (PARADE, e-SciDR, etc.),
funding agencies (EC, ERC, NSF, NSTC, etc.), and expert committees (HLG, WGs, etc.).
The challenge is to avoid repetitions and lists of well-known application requirements and
recommendations.
There are two main constituencies which play a crucial role in the development of scientific data
infrastructures: one that uses data-intensive methods and another that creates these methods.
So far, most of the roadmaps/white papers/visions that are circulating have been produced or
heavily influenced by members of the first constituency with very little involvement by the second
constituency. Consequently, these reports mainly describe the application requirements that must
be met by the future data infrastructures. The challenges that the researchers of the second
constituency have to overcome in order to make feasible the building of the next generation of
data infrastructures are generally ignored. The current reports concentrate on the application
constituency.
The approach taken by the authors of this report is the opposite. We take for granted a number of
core application requirements which can be found in almost all the existing reports and investigate
and describe the technical/scientific challenges, from the computer science point of view, that
must be overcome in order to meet them.
We think that this approach on one hand highlights the many difficult technical problems that
must be solved in order to make feasible the building of research data infrastructures and on the
other hand presents a complementary vision, with respect to the other roadmaps reports, to the
problems which hinder the implementation of these systems.
In order to be able to carry out this task, the GRDI2020 project mobilized the international
research community. Two Working Groups on technological and organizational/policy issues have
been created and were composed of internationally recognized experts with the mandate of
identifying and describing the most critical technical and organizational problems in terms of
state-of-the-art and current practices, recommendations for research directions and potential
impact.
In addition, two international GRDI2020 workshops were organized over the lifetime of the
project, Cape Town, South Africa (Oct. 2010) and Brussels (Oct. 2011) where intermediate versions
of the GRDI2020 Roadmap Report as well as the findings of the two Working Groups were
presented to a selected representation of the international research community for further
validation.
Two versions of the GRDI2020 Roadmap Report were published. This first preliminary version was
delivered at the end of the first year of the project (January 2011), mainly, addressing some of the
main data, system, application and organization challenges to be faced by global research data
infrastructures and its primary target audience were policy makers and scientists. This first version
of the Roadmap Report was widely circulated among the interested scientific communities in

GRDI2020 Final Roadmap Report Page 11 of 108
order to collect their feedback. It took into consideration discussions at the working group
meetings and at GRDI2020 South Africa workshop (Oct 2010).
The Final Version of the Report is an enriched and enhanced version of the First version and has
mainly focused on the description of the services to be provided by a global research data
infrastructure in order to enable global collaboration and to create, thus, a science collaborative
environment. The policy challenges faced by global research data infrastructures as well as new
computing and programming paradigms relevant for data intensive processing are also described.
This version was delivered at the end of the project (January 2012) and took into consideration
suggestions and recommendations of the international research community as well as feedback
collected from the main stakeholders, including relevant scientific organizations/foundations such
as CODATA, ESFRI, e-IRG, e-Science Centre, NSF and on-going projects implementing data
infrastructures.
In addition, a Short Version of the Final version of the Report was produced, printed and widely
distributed and presented in several scientific events (Workshop on “Global Scientific Data
Infrastructures: The Big Data Challenges”, Capri May 2011 , “Data-Intensive Research Theme Final
Workshop”, Edinburgh June 2011, Workshop on “Global Research Data Infrastructures: The GRDI
Vision”, Brussels October 2011, Workshop on “Global Research Data Infrastructures: The GRDI
Vision”, Stockholm December 2011, organized in conjunction with the international e-Science
Conference, “GCOE-NGIT 2012 Conference on Knowledge Discovery and Federation”, Sapporo-
Japan, January 2012).
Finally, a journalistic level version of the Short Version was produced. This version was edited by a
professional journalist (Richard Hudson CEO & Editor Science/Business). This Report was also
widely disseminated.

GRDI2020 Final Roadmap Report Page 12 of 108
3. The New Science Paradigm
Some areas of science are currently facing from a hundred – to a thousand-fold increase in
volumes of data compared to the volumes generated only a decade ago. This data is coming from
satellites, telescopes, high-throughput instruments, sensor networks, accelerators,
supercomputers, simulations, and so on [1]. The availability and use of huge datasets presents
both new opportunities and at the same time new challenges for scientific research.
Often referred to as a data deluge massive datasets is revolutionizing the way research is carried
out and resulting in the emergence of a new fourth paradigm of science based on data-intensive
computing [2]. New data-dominated science will lead to a new data-centric way of
conceptualizing, organizing and carrying out research activities which could lead to a rethinking of
new approaches to solve problems that were previously considered extremely hard or, in some
cases, even impossible to solve and also lead to serendipitous discoveries.
The new availability of huge amounts of data, along with advanced tools of exploratory data
analysis, data mining/machine learning and data visualization, offers a whole new way of
understanding the world. One view put forward is that in the new data-rich environment
correlation supersedes causation, and science can advance even without coherent models, unified
theories, or really any mechanistic explanation at all [3].
In order to be able to exploit these huge volumes of data, new techniques and technologies are
needed. A new type of e-infrastructure, the Research Data Infrastructure, must be developed for
harnessing the accumulating data and knowledge produced by the communities of research,
optimizing the data movement across scientific disciplines, enabling large increases in multi- and
inter- disciplinary science while reducing duplication of effort and resources, and integrating
research data with published literature.
To make this happen several breakthroughs must be achieved in the fields of research data
modelling, management and data tools and services.

GRDI2020 Final Roadmap Report Page 13 of 108
4. Research Data Infrastructures
Research Data Infrastructures can be defined as managed digital research data and resources in
networked environments that include services and tools that support: (i) the whole research cycle,
(ii) the movement of scientific data across scientific disciplines, (iii) the creation of open linked
data spaces by connecting data sets from diverse disciplines, (iv) the management of scientific
workflows, (v) the interoperation between scientific data and literature, and (vi) an Integrated
Science Policy Framework.
Research data infrastructures are not systems in the traditional sense of the term; they are
networks that enable locally controlled and maintained digital data and library systems to
interoperate more or less seamlessly. Genuine research data infrastructures should be ubiquitous,
reliable, and widely shared resources operating on national and transnational scales.
A research data infrastructure should include organizational practices, technical infrastructure
and social forms that collectively provide for the smooth operation of collaborative scientific work
across multiple geographic locations. All three should be objects of design and engineering; a data
infrastructure will fail if any one is ignored [4].
Another school of thought considers (data) infrastructure as a fundamentally relational concept. It
becomes infrastructure in relation to organized (research) practices [5]. The relational property of
(data) infrastructure talks about that which is between – between communities and
data/publications collections mediated by services and tools. According to this school of thought
the exact sense of the term (data) infrastructure and its “betweenness” are both theoretical and
empirical questions.
In [6] (data) infrastructure emerges with the following dimensions:
Embeddedness: Infrastructure is “sunk” into, inside of, other structures, social
arrangements and technologies
Transparency: Infrastructure is transparent to use, in the sense that it does not have to be
reinvented each time or assembled for each task, but invisibly supports those tasks.
Reach of scope: Infrastructure has reach beyond a single event or one-site practice.
Learned as part of membership: The taken-for-grantedness of artifacts and organizational
arrangements is a sine qua non of membership in a community of practice. Strangers and
outsiders encounter infrastructure as a target object to be learned about. New participants
acquire a naturalized familiarity with its objects as they become members.
Links with conventions of practice: Infrastructure both shapes and is shaped by the
conventions of a community of practice.
Embodiment of standards: Modified by scope and often by conflicting conventions,
infrastructure takes on transparency by plugging into other infrastructures and tools in a
standardized fashion.
Build on an installed base: Infrastructure does not grow de novo; it wrestles with the
“inertia of the installed base” and inherits strengths and limitations from that base.

GRDI2020 Final Roadmap Report Page 14 of 108
Becomes visible upon breakdown: The normally invisible quality of working infrastructure
becomes visible when breaks: the server is down, the bridge washes out, there is a power
blackout. Even when there are back-up mechanisms or procedures, their existence further
highlights the now-visible infrastructure.
Research data infrastructures should be science-and engineering-driven and when coupled with
high performance computational systems increase the overall capacity and scope of scientific
research. Optimization for specific applications may be necessary to support the entire research
cycle but work in this area is mature in many problem domains.
Science is a global undertaking and research data are both national and global assets. There is a
need for a seamless infrastructure to facilitate collaborative arrangements necessary for the
intellectual and practical challenges the world faces.
Therefore, there is a need for global research data infrastructures able to interconnect the
components of a distributed worldwide science ecosystem by overcoming language, policy,
methodology, and social barriers. Advances in technology should enable the development of
global research data infrastructures that reduce geographic, temporal, social, and National
barriers in order to discover, access, and use of data.
Their ultimate goal should be to enable researchers to make the best use of the world’s growing
wealth of data.
The next generation of global research data infrastructures is facing two main challenges:
To effectively and efficiently support data-intensive Science
To effectively and efficiently support multidisciplinary/interdisciplinary Science By data we mean any digitally encoded information that can be stored, processed and transmitted
by computers, including [7]:
Collections of data from instruments, observatories, surveys and simulations;
Results from previous research and earlier surveys;
Data from engineering and built-environment design, planning and production processes;
Data from diagnostic, laboratory, personal and mobile devices;
Streams of data from sensors in man-made and natural environments;
Data from monitoring digital communications;
Data transferred during transactions that enable business, administration, healthcare, and
government;
Digital material produced by news feeds, publishing, broadcasting and entertainment;
Documents in collections and held privately, texts and multi-media “images” in web pages,
wikis, blogs, emails and tweets; and
Digitized representations of diverse collections of objects, e.g. of museums’ curated
objects.

GRDI2020 Final Roadmap Report Page 15 of 108
4.1 Data-Intensive Science
By data-intensive science we mean any scientific research activity whose progress is heavily
dependent on careful thought about how to use data. Such research activities are characterized
by:
increasing volumes and sources of data,
complexity of data and data queries,
complexity of data processing,
high dynamicity of data,
high demand for data,
complexity of the interaction between researchers and data, and
importance of data for a large range of end-user tasks.
Fundamentally, data-intensive disciplines face two major challenges [8]:
Managing and processing exponentially growing data volumes, often arriving in time-sensitive
streams from arrays of sensors and instruments, or as the outputs from simulations; and
Significantly reducing data analysis cycles so that researchers can make timely decisions.
4.2 Multidisciplinary – Interdisciplinary Science
By multidisciplinary approach to a research problem we mean an approach that draws
appropriately from multiple disciplines in order to redefine the problem outside of normal
boundaries and reach solutions based on a new understanding of complex situations.
There are several barriers to the multidisciplinary approach of behavioural and technological
nature.
Among the major technological barriers we identify those that must be overcome when moving
data, information, and knowledge between disciplines. There is the risk of interpreting
representations in different ways caused by the loss of the interpretative context. This can lead to
a phenomenon called “ontological drift” as the intended meaning becomes distorted as the
information object moves across semantic boundaries (semantic distortion) [9].
A relatively similar concept is the interdisciplinary approach to a research problem. It involves the
connection and integration of expertise belonging to different disciplines for the purpose of
solving a common research problem.
Again, the barriers faced by an interdisciplinary approach are of two types: behavioural and
technological.
Among the major technological barriers we identify the need for integrating data, information,
and knowledge created by different disciplines. In fact, one of the major barriers to be overcome
concerns the integration of activities that are taking place on different ontological foundations.

GRDI2020 Final Roadmap Report Page 16 of 108
The requirements described above, imposed by data-intensive multidisciplinary-interdisciplinary
science are the motivations for building the theoretical foundations of the next generation data
infrastructures. To make this happen a considerable number of difficult data, application, system,
organizational, and policy challenges must be successfully tackled.
The breakthrough technologies needed to address many of the critical problems in data-intensive
multidisciplinary-interdisciplinary computing will come from collaborative efforts involving many
domain application disciplines as well as computer science, engineering and mathematics.

GRDI2020 Final Roadmap Report Page 17 of 108
5. A Strategic Vision for a Global Research Data Infrastructure
We envision that in the future several Digital Science Ecosystems will be established.
We use the ecosystem metaphor in order to conceptualize all the “research relationships “
between the components of the science universe.
The traditional notion of an ecosystem in biological sciences describes a habitat for a variety of
different species that co-exist, influence each other, and are affected by a variety of external
forces. Within the ecosystem, the evolution of one species affects and is affected by the evolution
of other species.
We think that a model of digital ecosystem of scientific research allows to have a better
understanding of its dynamic nature. We believe that the ecological metaphor for understanding
the complex network of data-intensive multidisciplinary research relationships is appropriate as it
is reminiscent of the interdependence between species in biological ecosystems. It emphasizes
that advances and transformations in scientific disciplines are as much a result of the broader
research environment as of simply technological progress.
In the world of science, there are many factors that influence the evolution of a specific scientific
discipline. By considering the digital science ecosystem as an interrelated set of data collections,
services, tools, computations, technologies and communities of research we can contribute to
identifying the factors that impact scientific progress.
5.1 Defining the Digital Science Ecosystem
We introduce a digital science ecosystem approach that considers a complex system composed of
Digital Data Libraries, Digital Data Archives, Digital Research Libraries, and Communities of
Research (see figure below).

GRDI2020 Final Roadmap Report Page 18 of 108
Figure 1 – GRDI2020 Digital Science Ecosystem
5.1.1 Digital Data Libraries (Science Data Centres)
Increasingly, the volumes of data produced by high-throughput instruments and simulations are so
large, and the application programs are so complex, that it is far more economical to move the
end-user’s programs to the data rather than moving the source data and its applications to the
user’s local system. The volumes of data used in large-scale applications today simply cannot be
moved efficiently or economically, even over very high-bandwidth internet links.
From the organizational point of view moving end-user applications to data stores calls for the
creation of Service Stations called Digital Data Libraries or Science Data Centers [10].

GRDI2020 Final Roadmap Report Page 19 of 108
These should be designed to ensure the long-term stewardship and provision of quality-assessed
data and data services to the international science community and other stakeholders. Each Digital
Data Library will have responsibilities for curation of datasets and the applications that provide
access to them, and employ technical support staff that understand the data and manage the
growth, quality and inherent value of the datasets.
Digital Data Libraries fall into one of several categories [11]:
Research Digital Data Libraries: contain the products of one or more focused research
projects. Typically, these data require limited processing or curation. They may or may not
conform to community standards for file formats, metadata structure, or content access
policies. Quite often, applicable standards may be nonexistent or rudimentary because the
data types are novel and the size of the user community small. Research data collections
may vary greatly in size but are intended to serve a specific group for specific purpose for
an identifiable period of time. There may be no intention to preserve the collection beyond
the end of a project.
Discipline or Community Digital Data Libraries: serve a single science or engineering
disciplinary or scholarly community. These digital data libraries often establish community-
level standards either by selecting from among preexisting standards or by bringing the
community together to develop new standards where they are absent or inadequate.
Reference Digital Data Libraries: are intended to serve large segments of the scientific and
education community. Characteristic features of this category of digital data libraries are
their broad scope and diverse set of user communities including scientists, students, and
educators from a wide variety of disciplinary, institutional, and geographical settings. In
these circumstances, conformance to robust, well-established, and comprehensive
standards is essential, and the selection of standards often has the effect of creating a
universal standard.
Specialized Service Digital Data Libraries: while the data libraries described above are
intended to provide access to data collections and a set of basic services (including
collection, curation, provision, short-term preservation, and publishing), another category
of data libraries will emerge offering specialized data services, i.e., data analysis, data
visualization, massive data mining, etc. These will play a very important role in advancing
data-intensive research.
5.1.2 Digital Data Archives
Scientific Data archiving refers to the long-term storage of scientific data and methods, that is, the
process of moving data that is no longer actively used to a separate data storage device for long-
term preservation. Data archives consist of older data that is still important and necessary for
future reference, as well as data that must be retained for regulatory compliance. Provisions for
long-term preservation (including means for continuously assessing what to keep and for how
long) should be provided.
Data archiving is more important in some fields than others. The requirement of digital data

GRDI2020 Final Roadmap Report Page 20 of 108
archiving is a recent development in the history of science and has been made possible by
advances in information technology allowing large amounts of data to be stored and accessed
from central locations.
Data Archives should be indexed and have search capabilities so that files and parts of files can be
easily located and retrieved [12].
Data Preservation issues become very important in data archiving. All storage media deteriorates
over time, although some more rapidly than others. As systems change, data formats and access
methods also change and it is already the case that a considerable amount of digital data cannot
be retrieved because the systems and software that created these data no longer exist. Data
preservation is an active area of computer science research and its importance will continue to
grow as data archives become larger and more numerous.
5.1.3 Digital Research Libraries
A Digital Research Library is a collection of electronic documents. The mission of research libraries
is to acquire information, organize it, make it available and preserve it. To meet user needs, the
founders of a Digital Research Library must accomplish two general tasks: establishing the
repository of electronic scholarly materials, and implementing the tools to use it. More
importantly, sustainability models must be established and put into place so that scholarly
information in a repository will be available to future generations of researchers. This implies
strong and enduring organizational commitments, fiscal commitments and institutional
commitments [13].
5.1.4 Communities of Research
Science is conducted in a dynamic, evolving landscape of communities of research organized
around disciplines, methodologies, model systems, project types, research topics, technologies,
theories, etc. These communities facilitate scientific progress and can provide a coherent voice for
their constituents, enhancing communication and cooperation and enabling processes for quality
control, standards development, and validation [14].
5.2 Digital Science Ecosystem Concepts
Digital Science Ecosystem Views
A community of research is interested in performing a research activity based on specific set of data
and tools. A specific ecosystem view can be defined by identifying a community of research and a
set of data collections, data services, and data tools necessary for the research activity undertaken
by this community. Ecosystem views are materialized by Science Gateways or Virtual Research
Environments.

GRDI2020 Final Roadmap Report Page 21 of 108
Digital Science Ecosystem Channels
Research channels can be established across the components of a science ecosystem. The data
and information exchanged between these components flow through the ecosystem channels. We
classify these eco system channels according to the resulting research results.
Channels enabling Multidisciplinary/interdisciplinary research: research channels across different
types of digital data libraries allow scientists belonging to different communities of research
and/or to different disciplines to work together.
Channels enabling Data Preservation: channels across digital data libraries and digital data
archives allow data together with the appropriate preservation information to move from short-
term to long-term preservation states based on well defined provision policies.
Channels enabling Unification of Research Data with Scientific Literature: channels across digital
data libraries and digital research libraries make it possible to merge scientific data with research
literature resulting in new document models in which the data and text gain new functionalities. By
integrating scientific data and research publications it will become possible for one to read a paper
and examine the original data on which the paper’s conclusions or claims are based. It will be also
be possible to reuse the data and replicate the research and data analysis. Yet another possibility
will be to locate all the literature referencing the data [15].
Channels enabling Cooperative research: channels across the members of communities of
research allow scientific cooperation and collaboration.
Digital Science Ecosystem Services
Digital ecosystem services are necessary in order to enable researchers to efficiently and
effectively carry out research activities. They include data registration, data discovery, data
citation, data service/tool discovery, data search, data integration, data sharing, data linking, data
transportation, data service transportation, ontology/taxonomy management, workflow
management and policy management.
5.3 Global Research Data Infrastructures: The GRDI2020 Vision
The Vision
We envision a Global Research Data Infrastructure as vital to the realization of an open,
extensible and evolvable digital science ecosystem. A Global Research Data Infrastructure both
creates and sustains a reliable operational digital science ecosystem environment.
Therefore it must support:
the creation and maintenance of science ecosystem views through:
o Science Gateways: A Science Gateway is a community-specific set of tools,
applications, and data collections that are integrated together and accessed via a
portal or a suite of applications.
o Virtual Research Environments: A Virtual Research Environment (VRE) is a

GRDI2020 Final Roadmap Report Page 22 of 108
“technological framework”, i.e., digital infrastructure and services, that together
allow on-demand creation of “virtual working environments” in which
“communities of research” can effectively and efficiently conduct their research
activities.
the creation and maintenance of research channels across the several components of the
ecosystem.
This implies that all the components of the ecosystem are able, along the research channels, to
exchange data and information without semantic distortions within a negotiated framework of
shared policies. The final result is a highly productive “interoperable science ecosystem” that
reduces fragmentation of science due to disparate data and contributes to both reducing
geographic fragmentation of datasets and at the same time accelerates the rate at witch data and
information can be made available and used to advance science.
In addition, a mediation technology capable of reconciling data and language heterogeneities
associated with different scientific disciplines must be developed in order to enable the next
generation data infrastructures to support ecosystem research paths.
the creation and maintenance of Service Environments that enable the efficient delivery of
ecosystem services. They include:
o Data Registration Environment: By Data Registration Environment we mean an
environment enabling researchers to make data citable as a unique piece of work
and not only as a part of a publication. Once accepted for deposit and archived,
data is assigned a “Digital Object Identifier” (DOI) for registration. A Digital Object
Identifier (DOI) [16] is a unique name (not a location) within a science ecosystem
and provides a system for persistent and actionable identification of data. DOIs
could logically be assigned to every single data point in a set; however in practice,
the allocation of a DOI is more likely to be to a meaningful set of data. Identifiers
should be assigned at the level of granularity appropriate for an envisaged
functional use. The Data Registration Environment should be composed of a
number of capabilities, including a specified numbering syntax, a resolution service,
a data model, and an implementation mechanism determined by policies and
procedures for the governance and application of DOIs.
o Data Discovery Environment: By Data Discovery Environment we mean an
environment enabling researchers to quickly and accurately identify and find data
that supports research requirements within the science ecosystem. It should be
composed of a number of capabilities and tools that support the pinpointing of the
location of relevant data.

GRDI2020 Final Roadmap Report Page 23 of 108
o Data Citation Environment: By Data Citation Environment we mean an
environment enabling researchers to provide a reference to data in the same way
as researchers routinely provide a bibliographic reference to printed resources.
Data citation is recognized as one of the key practices underpinning the recognition
of data as a primary research output rather than as a by-product of research. The
essential information provided by a citation links it and the cited data set.
Therefore, a Data Citation Environment should support a number of capabilities
including a standard for citing data sets that addresses issues of confidentiality,
verification, authentication, access, technology changes, existing subfield-specific
practices, and possible future extensions, as well as a naming resolution service.
Data citation will ensure scholarly recognition and credit attribution.
o Data Service/Tool Discovery Environment: By Data Service/Tool Environment we
mean an environment enabling the automatic location of data services/tools that
fulfill a researcher goal. The Data Service/Tool Environment should support a
number of capabilities, including ontology-based descriptions both of the
researcher’s goal and the data service/tool functionality as well as a mediation
support in case these descriptions use different ontologies.
o Data Search Environment: By Data Searching Environment we mean an
environment in which researchers can identify, locate and access required data. It
should support a number of capabilities that support a complex search process
characterized by multiple steps, spanning multiple data sources that may require
long-term sessions and continuous refinement of the search process.
o Data Integration Environment: By Data Integration Environment we mean an
environment enabling researchers to combine data residing at different sources,
and provide them with a unified view of these data. The Data Integration
Environment should include capabilities and tools that support data
transformation, duplicate detection and data fusion.
o Data Sharing Environment: By Data Sharing Environment we mean an environment
enabling the sharing of research results among the members of the Communities
of Research of the science ecosystem. It should be composed of a number of
capabilities and tools that support the contexts for shared data use.
o Data Linking Environment: By Data Linking Environment we mean an environment
enabling the connection of data sets from diverse domains of the science
ecosystem. It should be composed of a number of capabilities and tools that
support the creation of common data spaces that allow researchers to navigate
along links into related data sets.
o Ontology/Taxonomy Management Environment: By Ontology/Taxonomy
Management Environment we mean an environment enabling a wide range of
semantic science ecosystem data services. Ontologies and taxonomies provide the
semantic underpinning enabling intelligent data services including data and service
discovery, search, access, integration, sharing and use of research data. This type
of Service Environment should contain numerous capabilities including, but not

GRDI2020 Final Roadmap Report Page 24 of 108
limited to ontology and taxonomy models, ontology and taxonomy metadata, and
reasoning engines. These are necessary in order to efficiently create, modify,
query, store, maintain, integrate, map, and align top-level and domain ontologies
and taxonomies within the larger science ecosystem.
o Transportable Data Environment: By Transportable Data Environment we mean an
environment enabling researchers to copy data from a source database to a target
database. This environment should be based on a transport technology supporting
the creation of transportable modules which function like a shipping service that
moves a package of objects from one site to another at the fasted possible speed.
Transportable modules enables one to rapidly copy a group of related database
objects from one database to another. The physical and logical structures of the
objects contained in the transportable modules being restored are re-created in
the target database [17].
o Transportable Data Services/Tools Environment: Increasingly, the volumes of data
produced by high-throughput instruments and simulations are so large, that it is
much more economical to move computation to the data rather than moving the
data to the computation. A Transportable Data Services/Tools Environment should
support this model made possible through service-oriented architectures (SOA)
that encapsulate computation into transportable compute objects that can be run
on computers that store targeted data. SOA compute objects function like
applications that are temporarily installed on a remote computer, perform an
operation, and then are uninstalled [18].
o Scientific Workflow Management Environment: By Scientific Workflow we mean a
precise description of a scientific procedure-a multi-step process to coordinate
multiple tasks. Each task represents the execution of a computational process.
Scientific Workflows orchestrate e-Science services so that they cooperate to
efficiently perform a scientific application. A Workflow Management Service should
support the creation, maintenance, and operation of scientific workflows.
o Policy Management Environment: By Policy Management Environment we mean
an integrated set of formal semantic policies that enhances the authorization,
obligation, and trust processes that permit regulated access and use of data and
services (data policies). The same formal semantic policies are also used to
estimate trust based on parties’ properties (trust management policies). A Policy
Management Environment should provide accurate and explicit policy
representation and specification languages, policy editor tools, policy administrator
tools, algorithms for conflict detection and resolution, and graphical tools for
editing, updating, removing, and browsing policies as well as de-conflicting newly
defined policies.
The ultimate aim of a Global Research Data Infrastructure is to enable global collaboration in key
areas of science by supporting science ecosystem views, channels, and services and creating, thus,
a science collaborative environment.

GRDI2020 Final Roadmap Report Page 25 of 108
Social and Organizational Dimensions of a Research Data Infrastructure
A Digital Science Ecosystem model must also consider the fact that external environmental forces
influence research advances. Specifically, three major types of external environmental forces
should be considered: social and governmental forces, economic forces, and technical forces [19].
A viable vision of research data infrastructure must take into account social and organizational
dimensions that accompany the collective building of any complex and extensive resource.
A robust Global Research Data Infrastructure must consist not only of a technical infrastructure
but also a set of organizational practices and social forms that work together to support the full
range of individual and collaborative scientific work across diverse geographic locations. A data
infrastructure will fail or quickly become encumbered if any one of these three critical aspects is
ignored. By considering data infrastructure as just a technical system to be designed, the
importance of social, institutional, organizational, legal, cultural, and other non-technical problems
are marginized and the outcome is almost always flawed or less useful than originally anticipated
[4].
Tensions
New research data infrastructures are encountering and often provoking a series of tensions [4].
Because of its potential to upset or recast previously accepted relations and practices the
development of new data infrastructures may generate, in some degree, what economists have
labeled “creative destruction”. This occurs when established practices, organizational norms,
individual and institutional expectations adjust in a positive or negative fashion in reaction to the
new possibilities and challenges posed by infrastructure. In the best circumstances, individuals and
institutions take advantage of and build upon new resources. In other cases, the inertia of long-
standing organizational arrangements, scholarly approaches and research practices prove to be
too difficult to change with resulting disastrous consequences. Tensions should be thought of as
both barriers and resources to infrastructural development, and should be engaged constructively.
A second class of tensions can be identified in instances where changing infrastructures bump up
against the constraints of political economy: intellectual property rights regimes, public/private
investment models, ancillary policy objectives, etc. Clearly, the next generation of research data
infrastructures pose new challenges to existing regimes of intellectual property. Indeed,
intellectual property concerns are likely to multiply with the advent of increasingly networked and
collaborative forms of research supported by the data infrastructures [4].
Similar tensions arise in determining relationships between national policy objectives and the
transnational pull of science. Put simply, where large-scale policy interests (in national economic
competitiveness, security interests, global scientific leadership, etc.) stop at the borders of the
nation-state, the practice of science spills into the world at large, connecting researchers and
communities from multiple institutional and political locales. This state of affaires has a long
history of creating tension in science and education policy, revealing in very practical terms the
complications of co-funding arrangements across multiple national agencies [4].

GRDI2020 Final Roadmap Report Page 26 of 108
To the extent that research data infrastructures support research collaborations across national
borders, such national/transnational tensions must be carefully considered and efforts must be
continually undertaken to resolve them.

GRDI2020 Final Roadmap Report Page 27 of 108
6. Technological Challenges
6.1 Data Challenges
Data challenges include research data modelling, data management and data tools challenges.
There is a need for radically new data models and query languages and tools that enable scientists
to follow new paths, try new techniques, build new models and test them in new ways that
facilitate innovative research activities.
Data Modeling Challenges
There is a need for radically new approaches to research data modelling. In fact, the current data
models (relational model) and management systems (relational database management systems)
were developed by the database research community for business/commercial data applications.
Research data has completely different characteristics from business/commercial data and thus
the current database technology is inadequate to handle it efficiently and effectively.
There is a need for data models and query languages that:
more closely match the data representation needs of the several scientific disciplines;
describe discipline-specific aspects (metadata models);
represent and query data provenance information;
represent and query data contextual information;
represent and manage data uncertainty;
represent and query data quality information.
6.1.1 Data Modeling
While most scientific users can use relational tables and have been forced to do so by current
systems, we can find only a few users for whom tables are a natural data model that closely
matches their data. Conventional tabular (relational) database systems are adequate for analysing
objects (galaxies, spectra, proteins, events, etc.), but the support for time-sequence, spatial, text
and other data types is awkward.
For some scientific disciplines (astronomy, oceanography, fusion and remote sensing) an array
data model is more appropriate. Database systems have not traditionally supported science’s core
data type: the N-dimensional array. Simulating arrays on top of tables is difficult and results in
poor performance.
Some other disciplines, i.e., biology and genomics, consider more appropriate for their needs
graphs and sequences.
Lastly, solid modelling applications want a mesh data model [20].
The net result is that “one size will not fit all” and science users will need a mix of specialized
database management systems.

GRDI2020 Final Roadmap Report Page 28 of 108
This collection of problems is generally called the “impedance mismatch” – meaning the mismatch
between the programming model and the database capabilities. The impedance mismatch has
made it difficult to map many science applications into conventional tabular database systems.
6.1.2 Metadata Modeling
Metadata is the descriptive information about data that explains the measured attributes, their
names, units, precision, accuracy, data layout and ideally a great deal more. Most importantly,
metadata includes the data lineage that describes the data was measured, acquired, or computed.
The metadata is as valuable as the data itself [10].
If the data is to be analysed by generic tools, the tools need to “understand” the data. The tool will
want to know the metadata.
If scientists are to read data collected by others, then the data must be carefully documented and
must be published in forms that allow easy access and automated manipulation. In the next
generation data infrastructures, there will be powerful tools to make it easy to capture, organize,
analyse, visualize, and publish data. The tools will do data mining and machine learning on the
data, and will make it easy to script workflows and analyse the data. Good metadata for the inputs
is essential to make these tools automatic. Preserving and augmenting this metadata as part of the
processing (data lineage) will be a key benefit for next generation tools.
All the derived data that the scientist produces must also be carefully documented and published
in forms that allow easy access. Ideally, much of this metadata would be automatically generated
and managed as part of the workflow, reducing the scientist’s intellectual burden.
The use of purpose-oriented descriptive data models is of paramount importance to achieve data
usability.
The type of descriptive information to be provided by the data producer depends very much on
the requirements imposed by the data consumer tasks. For example, if the consumer entity wants
to perform a data analysis task on the imported information then quality of the information is of
paramount importance; without such information the task of data analysis cannot be performed.
Consequently, if a researcher is willing to export/publish the data produced, its possible uses by
the potential users must be carefully taken into account and it must be endowed with appropriate
descriptive information. Appropriate purpose-oriented metadata models to represent the
descriptive information must be chosen and used.
6.1.3 Data Provenance Modeling
In its most general form, provenance (also sometimes called lineage) captures where data came
from, how it has been updated over time. Provenance can serve a number of important functions:
Explanation: Users may be particularly interested in or wary of specific portions of a derived data
set. Provenance supports “drilling down” to examine the sources and the evolution of data
elements of interest, enabling a deeper understanding of the data [21].

GRDI2020 Final Roadmap Report Page 29 of 108
Verification: Derived data may appear suspect – due to possible bugs in data processing and
manipulation, due to stale data, or even due to maliciousness. Provenance enables auditing on
how data was produced, either to verify its correctness, or to identify the erroneous or out-dated
source data or processing nodes that are responsible for erroneous or out-dated data.
Recomputation / Repeatability: Having found out-dated or incorrect source data, or buggy
processing nodes, users may want to correct the errors and propagate the corrections forward to
all “downstream” data that is affected. Provenance helps to recompute only those data elements
that are affected by the corrections.
There has been a large body of very interesting work in lineage and provenance over the past two
decades. Nevertheless, there are still many limitations and open areas. Specifically, the primary
focus is on modelling and capturing provenance: how is provenance information represented?
How is it generated? There has been considerably less work on querying provenance: What can we
do with provenance information once we’ve captured it?
On the long-term, it is necessary the development of a standard open representation and query
model.
6.1. 4 Data Context Modeling
Humans are quite successful at conveying ideas to each other and reacting appropriately. This is
due to many factors: the richness of the language they share, the common understanding of how
the world works, and an implicit understanding of everyday situations. When humans talk with
humans, they are able to use implicit situational information, or context, to increase the
conversational bandwidth. Unfortunately, this ability to convey ideas does not transfer well to
humans interacting with computers. In fact, context is a poorly used source of information in our
computing environments. As a result, we have an impoverished understanding of what context is
and how it can be used.
Contextual information is any information which can be used to characterize the situation of a
digital information object. In essence, this information documents the relationship of the data to
its environment [22].
Context is the set of all contextual information that can be used to characterize the situation of a
digital information object.
Several context modelling approaches exist and are classified by the scheme of data structures
which are used to exchange contextual information in the respective system [23]:
Key-value Models,
Mark-up Scheme Models,
Object Oriented Models,
Logic Based Models,
Ontology Based Models.
Future scientific data infrastructures should be context-aware, i.e. they should use context to
provide relevant information and/or services to the user, where relevancy depends on the user’s
task.

GRDI2020 Final Roadmap Report Page 30 of 108
6.1.5 Data Uncertainty Modeling
As models of real world, scientific databases are often permeated with forms of uncertainty
including imprecision, incompleteness, vagueness, inconsistency, and ambiguity.
Uncertainty is the quantitative estimation of error presenting data; all measurements contain
some uncertainty generated through systematic error and/or random error. Acknowledging the
uncertainty of data is an important component of reporting the results of scientific investigation
[24].
Essentially, all scientific data is imprecise, and without exception science researchers have
requested a database management system that supports uncertain data elements. Of course,
current commercial products do not support uncertainty [20].
There is, among science users, a universal consensus on requirements in this area. Some of them
request a simple model of uncertainty while others request a more sophisticated model.
There has been a significant amount of work in areas variously known as “uncertain, probabilistic,
fuzzy, approximate, incomplete and imprecise” data management.
Undoubtedly, the development of suitable database theory to deal with uncertain database
information and transactions and the successful deployment of this theory in an actual database
system, remain challenges that have yet to be met.
6.1.6 Data Quality Modeling
Quality of data is a complex concept, the definition of which is not straightforward. There is no
common or agreed definition or measure for data quality, apart from such general notion as
fitness for use.
The consequences of poor data quality are often experienced in every scientific discipline, but
without making the necessary connections to its causes [25]. Awareness of the importance of
improving the quality of data is increasing in all scientific fields.
In order to fully understand the concept, researchers have traditionally identified a number of
specific quality dimensions. A dimension or characteristic captures a specific facet of quality. The
more commonly referenced dimensions include accuracy, completeness, and consistency.
An important aspect of data is how often it varies in time - stable data and time-variable data. In
order to capture aspects concerning temporal variability of data, different data quality dimensions
need to be introduced. The principal time-related dimensions are currency, timeliness and
volatility.
Data quality dimensions are not independent of each other but correlations exist among them. If
one dimension is considered more important than the others for a specific application, then the
choice of favouring it may imply negative consequences for the others. Establishing trade-offs
among dimensions is an interesting problem.

GRDI2020 Final Roadmap Report Page 31 of 108
The core set of data quality dimensions introduced here is shared by most proposals for data
quality dimensions in research literature. However, for specific categories of data and for specific
scientific disciplines, it may be appropriate to have more specific sets of dimensions. As an
example, for geographic information systems specific, standard sets of data quality dimensions are
under investigation (ISO 2005).
6.2 Data Management Challenges
If research data are well organized, documented, preserved and accessible, and their accuracy and
validity is controlled all times, the result is high quality data, efficient research, findings based on
solid evidence and the saving of time and resources. Researchers themselves benefit greatly from
good data management. It should be planned before research starts and may not necessarily incur
much additional time or costs if it is engrained in standard research practice. A data Management
Plan helps researchers consider, when research is being designed and planned, how data will be
managed during the research process and shared afterwards with the wider research community
[26].
6.2.1 Data Curation
By data curation we denote the activity of managing the use of data from its point of creation, to
ensure it is fit for contemporary purpose and available for discovery and re-use. For dynamic
datasets this may mean continuous enrichment or updating to keep it fit for purpose. Higher levels
of curation will also involve maintaining links with annotation and other published materials [27].
Most scientific data comes from instruments observing a physical process of some sort. Such
sensor readings enter a “curation process” whereby raw information is “curated” in order to
produce finished information. Curation entails converting sensor information into standard data
types, correcting for calibration information, etc. There are two schools of thought concerning
curation. One school suggests loading raw data into a database management system and the
performing all curation inside the system. The other school of thought suggests curating the data
externally, employing custom hardware if appropriate. In some applications the curation process is
under the control of a separate group, with little interaction with the storage group [20].
6.3 Data Tools Challenges
Currently, the available data tools for most scientific disciplines are not adequate. It is essential to
build better tools in order to make scientists more productive. There is a need for better
computational tools to visualize, analyze, and catalog the available enormous research datasets in
order to enable a data-driven research.
Scientists will need better analysis algorithms that can handle extremely large datasets with
approximate algorithms (ones with near-linear execution time), they will need parallel algorithms

GRDI2020 Final Roadmap Report Page 32 of 108
that can apply many processors and many disks to the problem to meet CPU-density and
bandwidth-density demands, and they will need the ability to “steer” long-running computations
in order to prioritize the production of data that is more likely to be of interest [28].
Scientists will need better data mining algorithms to automatically extract valid, authentic and
actionable patterns, trends and knowledge from large data sets. Data mining algorithms such as
automatic decision tree classifiers, data clusters, Bayesian predictions, association discovery,
sequence clustering, time series, neural networks, logistic regression integrated directly in
database engines will increase the scientist’s ability to discover interesting patterns in their
observations and experiments [28].
Large observational data sets, the results of massive numerical computations, and high-
dimensional theoretical work all share one need: visualization. Observational data sets such as
astronomic surveys, seismic sensor output, tectonic drift data, ephemeris data, protein shapes,
and so on, are infeasible to comprehend without exploiting the human visual system [28].
In essence, scientists need advanced tools that enable them to follow new paths, try new
techniques, build new models and test them in new ways that facilitate innovative
multidisciplinary/interdisciplinary activities and support the whole research cycle.
6.3.1 Data Visualization
Visual data analysis, facilitated by interactive interfaces, enables the detection and validation of
expected results while also enabling unexpected discoveries in science. It allows the validation of
new theoretical models, provides comparison between models and datasets, enables quantitative
and qualitative querying, improves interpretation of data and facilitates decision making. Scientists
can use visual data analysis systems to explore “what if” scenarios, define hypotheses, and
examine data using multiple perspectives and assumptions. They can identify connections among
large numbers of attributes and quantitatively assess the reliability of hypotheses. In essence,
visual data analysis is an integral part of scientific discovery and is far from a solved problem.
Many avenues for future research remain open [29].
Fundamentals advances in visualization techniques must be made to extract meaning from large
and complex datasets derived from experiments and from upcoming petascale and exascale
simulation systems. Effective data analysis and visualization tools in support of predictive
simulations and scientific knowledge discovery must be based on strong algorithmic and
mathematical foundations and must allow scientists to reliably characterize salient features in
their data. New mathematical methods in areas such as topology, high-order tensor analysis and
statistics will constitute the core of feature extraction and uncertainty modelling using forma
definition of complex shapes, patterns, and space-time distributions.
New visual data analysis techniques will need to dynamically consider high-dimensional probability
distributions of quantities of interest.
New approaches to visual data analysis and knowledge discovery are needed to enable
researchers to gain insight into the emerging forms of scientific data. Such approaches must take
into account the multi-model nature of the data; provide the means for scientists to easily

GRDI2020 Final Roadmap Report Page 33 of 108
transition views from global to local model data. Tools that leverage semantic information and
hide details of dataset formats will be critical to enabling visualization and analysis experts to
concentrate on the design of these approaches rather than becoming mired in the trivialities of
particular data representations [28].
6. 3.2 Massive Data Mining
Data mining, the extraction of hidden predictive information from large databases, is a powerful
new technology with great potential to help researchers conducting many of their research
activities. Data mining tools predict future trends and behaviours, allowing researchers to make
proactive, knowledge-driven decisions [30].
Data mining techniques are the result of a long process of research and product development.
Data mining overcomes the retrospective data access and navigation and allows for prospective
and proactive information delivery. Data mining is supported by three technologies that are now
sufficiently mature: massive data collection, powerful multiprocessor computers and data mining
algorithms.
The most commonly used techniques in data mining are: artificial neural networks, decision trees,
genetic algorithms, nearest neighbour method and rule induction. Many of these technologies
have been in use for more than a decade in specialized analysis tools that work with relatively
small volumes of data. These capabilities are now evolving to integrate directly with large data
warehouses.
Researchers need timely and sophisticated analysis on an integrated view of data stored in huge
warehouses. However, there is a growing gap between more powerful storage and retrieval
systems and the user’s ability to effectively analyse and act on the information they contain. Both
relational and OLAP technologies have tremendous capabilities for navigating massive data
warehouses, but brute force navigation of data is not enough. A new technological leap is needed
to structure and prioritize information for specific end-user problems. The data mining tools can
make this leap.
Massive data mining: In many scientific disciplines, data now arrives faster than we are able to
mine it. To avoid wasting this data, we must switch from the traditional “one-shot” data mining
approach to systems that are able to mine continuous, high-level, open-ended data streams as
they arrive.
Data mining systems that are able to “keep up” with massive data streams are required.

GRDI2020 Final Roadmap Report Page 34 of 108
7. System Challenges
System challenges include virtual research environments, science gateways, scientific workflow
management, and policy management.
7.1 Virtual Research Environment (VRE)
By Virtual Research Environment (VRE) we mean the “technological framework”, i.e., digital
infrastructure and services that enable the creation of “virtual working environments” in which
“communities of practice” can effectively and efficiently conduct their research activities.
A Virtual Research Environment is always associated with a community of practice.
Communities of practice are groups of researchers who share a concern for a research problem.
Three features characterize a community of practice [31]: the domain, the community, and the
practice.
The domain: A community is not merely a network of connections between people. It has an
identity defined by a shared scientific domain of interest. Membership implies a commitment to
the domain, and therefore a shared competence that distinguishes the members of the
community from other people.
The community: In pursuing their interest in the domain, members are engaged in joint activities,
share information and help each other. They build relationships that enable them to learn from
each other.
The practice: A community of practice is not merely a community of interest. Members of a
community of practice are practitioners. They develop a shared repertoire of results:
methodologies, approaches, and scientific results both theoretical and implementations.
A Virtual Research Environment can be viewed as a framework within which tools, services, and
resources can be plugged [32]. VREs are part of an e-Infrastructure rather than a free-standing
product. They are the result of joining together new and existing components to support the
research activities of a community of practice. It is usually assumed that a large proportion of
existing components will be distributed and heterogeneous. There is a difference between VREs
and an e-Infrastructure; a VRE presents a holistic view of the context in which research takes place
whereas an e-Infrastructure focuses on the core, shared services over which the VRE is expected
to operate. A VRE is more than middleware!
The development of VREs is of paramount importance for data-intensive science. Within a VRE
framework access to grid-based computing resources may be one suite of services among others.
VREs have the potential to be profoundly multidisciplinary, both in their use and in their
development. It is expected that computer science will act in partnership with other disciplines to
lay the foundations, integrating methods and knowledge from the relevant subject areas.
By facilitating data-intensive multidisciplinary research, a VRE should transform how research is
undertaken within a particular community of practice. This effect may apply at various points in
the research “life cycle”.

GRDI2020 Final Roadmap Report Page 35 of 108
The VRE vision is still evolving and should be informed by the various on-going e-Infrastructure
projects under the 7th FP.
Next generation scientific data infrastructures must provide the necessary architectural and
management tools in order to be able to build, support, and maintain VREs.
7.2 Science Gateways
Increasingly, scientists are using portals and desktop applications as gateways to access
computational resources (data services and tools), data, and even instruments that are integrated
within a data infrastructure [33].
The concept of a Science Gateway is a community-specific set of tools, applications, and data
collections that are integrated together and accessed within a research data infrastructure via a
portal or a suite of applications.
These gateways can support a variety of capabilities including workflows, visualization as well as
resource discovery and job execution services.
As more and more communities build science gateways, it will be useful to develop a set of
conventions (policies, technical approaches, interactions) by which a science gateway interacts
with a data infrastructure or data infrastructure resource.
7.3 Ontology Management
Rationale and Definition
Ontologies/taxonomies/thesauri constitute a key technology enabling a wide range of science
ecosystem services. The growing availability of data has shifted the focus from closed, relatively
data-poor applications, to mechanisms and applications for searching, integrating and making use
of the vast amounts of data that are now available. A global research data infrastructure faces,
thus, the problem of accessing several heterogeneous data resources by means of flexible
mechanisms that are both powerful and efficient. Ontologies are widely considered as a suitable
formal tool for sophisticated data access [34]. In fact, ontologies provide the semantic
underpinning enabling intelligent search, access, integration, sharing and use of research data.
Services, to be provided by a research data infrastructure, which require extensive use of
ontologies include also data/information discovery, data service/tool discovery, data classification,
data exchangeability and interoperability, dealing with inconsistent information, etc. In addition,
in several communities of research ontologies are considered as the ideal formal tool to provide a
shared conceptualization of the domain of interest.
“In the context of knowledge sharing, I use the term ontology to mean a specification of a
conceptualization. That is, an ontology is a description (like a formal specification of a program) of
the concepts and relationships that can exist for an agent or a community of agents. This
definition is consistent with the usage of ontology as a set-of-concept-definitions, but more
general” [35].

GRDI2020 Final Roadmap Report Page 36 of 108
Ontologies were initially developed by the Artificial Intelligence community to facilitate knowledge
sharing and reuse. An ontology consists of a set of concepts, axioms, and relationships that
describes a domain of interest.
While an ontology may be in principle an abstract conceptual structure, from the practical
perspective, it makes sense to express it in some selected formal language to realize the intended
shareable meaning.
An important issue regards the effort to be undertaken in order to understand which language
would be best suited for representing ontologies in a setting where an ontology is used for
carrying out an activity, for example, accessing large volumes of data.
Ontology Management
We are now entering a phase of knowledge system development, in which ontologies are
produced in large numbers and exhibit greater complexity. Therefore, ontology management is a
needed capability of a global research data infrastructure in order to be able to effectively support
the semantic science ecosystem services.
Three are the main components of an ontology management capability: ontology model, ontology
metadata, and reasoning engine [36].
The core component is the ontology model. The ontology model, typically an in-memory
representation, maintains a set of references to the ontologies, their respective contents and
corresponding instance data sources. From a logical perspective, it can be seen as a set of
(uninterpreted) axioms. The ontology model can be typically modified by means of an API or via
well-defined interfaces.
The ontology metadata store maintains metadata information about the ontologies themselves,
for example author, version, and compatibility information.
The reasoning engine operates on top of the ontology model, giving the set of axioms an
interpretation and thus deducing new facts from the given primitives. Obviously, the behavior of
the reasoning engine will depend on the supported semantics, e.g., Description Logics in the case
of the OWL reasoning engines. The interaction with the reasoning engine from outside takes place
either by means of a defined API or by means of a query interface. Again, the query interface
needs to support a standardized query language, e.g., SPARQL for OWL/RDF data. The basic
reasoning capabilities based on the ontology model can be further extended by means of external
builtins.
The following key requirements for ontology management have been identified [37]:
1. Scalability, Availability, Reliability and Performance – These are considered essential for any ontology management solution, both during the development and maintenance phase and the ontology deployment phase.
2. Ease of Use – The ontology development and maintenance process had to be simple, and the tools usable by ontologists as well as domain experts and analysts.

GRDI2020 Final Roadmap Report Page 37 of 108
3. Extensible and Flexible Knowledge Representation – The ontology model needs to incorporate the best knowledge representation practices available and be flexible and extensible enough to easily incorporate new representational features and incorporate and interoperate with different ontology models.
4. Distributed Multi-User Collaboration – Collaboration is considered to be a key to knowledge sharing and building. Ontologists, domain experts and analysts need a tool that allows them to work collaboratively to create and maintain ontologies even if they work in different geographic locations.
5. Security Management – The system needs to be secure to protect the integrity of the data, prevent unauthorized access, and support multiple access levels.
6. Difference and Merging – Merging facilitates knowledge reuse and sharing by enabling existing knowledge to be easily incorporated into an ontology. The ability to merging ontologies is also needed during the ontology development process to integrate versions created by different individuals into a single, consistent ontology.
7. Internationalization- A global research data infrastructure enables applications using ontological data that have to serve researchers around the world. The ontology management capability needs to allow users to create ontologies in different languages and support the display or retrieval of ontologies using different locales based on the user’s geographic location.
8. Versioning – Since ontologies continue to change and evolve, a versioning system for ontologies is critical. As an ontology changes over time, applications need to know what version of the ontology they are accessing and how it has changed from one version to another so that they can perform accordingly.
The requirements of scalability, reliability, availability, security, internationalization and versioning
are considered to be the most important for an industrial strength ontology management
capability.
Ontology Integration/Alignment and Mappings
In large distributed information systems, individual data sources, service functionalities, etc. are
often described based on different, heterogeneous ontologies. To enable interoperability across
these sources, it is necessary to specify how the resource residing at a particular node corresponds
to resource residing at another node. This is formally done using the notion of mapping. There are
mainly two lines of work connected to the problem of ontology mapping [36]:
(i) identifying correspondences between heterogeneous ontologies, (ii) representing these correspondences in an appropriate mapping formalism and using
the mappings for a given integration task.
The first task of identifying correspondences between heterogeneous ontologies is also referred to
as mapping discovery or ontology matching. Today, there exist a number of tools that support the
process of ontology matching in automated or semi-automated ways.
A generic process for ontology matching is described here below. It is composed of six main steps
[36]:

GRDI2020 Final Roadmap Report Page 38 of 108
1. Feature Engineering: The role of feature engineering is to select relevant features of the ontology to describe specific ontology entities, based on which the similarity with other entities will later be assessed.
2. Search Step Selection: The derivation of ontology matches takes place in a search space of candidate matches. This step may choose to compute the similarity of certain candidate element pairs and to ignore others in order to prune the search space.
3. Similarity Computation: For a given description of two entities from the candidate matches this step computes the similarity of the entities using the selected features and corresponding similarity measures.
4. Similarity Aggregation: In general, there may be several similarity values for a candidate pair of entities, e.g., one for the similarity of their labels and one for the similarity of their relationship to other entities. These different similarity values for one candidate pair have to be aggregated into a single aggregated similarity value. Often a weighted average is used for the aggregation of similarity values.
5. Interpretation: The interpretation finally uses individual or aggregated similarity values to derive matches between entities. The similarities need to be interpreted. Common mechanisms are to use thresholds or to combine structural and similarity criteria. In the end, a set of matches for the selected entity pairs is returned.
6. Iteration: The similarity of one entity pair influences the similarity of the neighboring entity pairs, for example, if the instances are equal this affects the similarity of the concepts and vice versa. Therefore, the similarity is propagated through the ontologies by following the links in the ontology. Several algorithms perform an iteration over the whole process in order to bootstrap the amount of structural knowledge. In each iteration, the similarities of a candidate alignment are recalculated based on the similarities of the neighboring entity pairs. Iteration terminates when no new alignments are proposed.
Output: The output is a representation of matches and possibly with additional confidence values
based on the similarity of the entities.
Mapping Representation
In contrast to the area of ontology languages where the Web Ontology Language OWL has
become a de facto standard for representing and using ontologies, there is no agreement yet on
the nature and the right formalism for defining mappings between ontologies.
Recent research works study formalisms for specifying the correspondences between elements
(concepts, relations, individuals) in different ontologies, ranging from simple correspondences
between atomic elements, to complex languages allowing for expressing complex mappings.
Here, some general aspects of formalisms for mapping representation are briefly discussed [36].
What do mappings define? We can see mappings as axioms that define a semantic relation
between elements in different ontologies. Most common are the following kinds of semantic
relations:
Equivalence: Equivalence states that the connected elements represent the same aspect of the
real world according to some equivalence criteria.

GRDI2020 Final Roadmap Report Page 39 of 108
Containment: Containment states that the element in one ontology represents a more specific
aspect of the world than the element in the other ontology.
Overlap: Overlap states that the connected elements represent different aspects of the world, but
have an overlap in some respect. In particular, it states that some objects described by the
element in one ontology may also be described by the connected element in the other ontology.
In some approaches, these relations are supplemented by their negative counterparts. The
corresponding relations can be used to describe that two elements are not equivalent, not
contained in each other or not overlapping respectively.
What do mappings connect? Most mapping languages allow defining the correspondences of
mappings between ontology elements of the same type, e.g., classes to classes, properties to
properties, etc. These mappings are often referred to as simple, or one-to-one mappings. While
this already covers many of the existing mapping approaches, there are a number of proposals for
mapping languages that rely on the idea of view-based mappings and use semantic relations
between queries to connect models, which leads to a considerably increased expressiveness.
Possible applications such mappings are manifold, including for example data transformation and
data exchange. However, most commonly mappings are applied for the task of ontology-based
information integration, which addresses the problem of integrating a set of local information
sources, each described using a local ontology.
Ontology Alignment
The Ontology Mapping Language of the Ontology Management Working Group is an ontology
alignment language that is independent of the language in which the two ontologies to be aligned
are expressed.
The alignment between two ontologies is represented through a set of mapping rules that specify
a correspondence between various entities, such as concepts, relations, and instances. Several
concept and relation constructors are offered to construct complex expressions to be used in
mappings.
Networked Ontologies [38]
In the context of a science ecosystem, ontologies are not standalone artifacts. They relate to each
other in ways that might affect their meaning, and are inherently distributed in a network of
interlinked semantic resources, taking into account in particular their dynamics, modularity and
contextual dependencies. It is important to investigate the entire development and evolution
lifecycle of networked ontologies that enable complex, semantic applications. Methodologies and
tools must be developed which support the:
management of the dynamics and evolution of ontologies in an open, networked environment;
collaborative development of networked ontologies

GRDI2020 Final Roadmap Report Page 40 of 108
facilitation of contextual awareness and using context for developing, sharing, adapting and maintaining networked ontologies
improvement of human-ontology interaction; i.e. making it easier for users with different leves of expertise and experience to browse and make sense of ontologies
Ontology and Science Ecosystem
For each science ecosystem, we envision the need for building a top-level ontology, domain-
independent, supplemented by several domain ontologies, one for each community of research
belonging to the same science ecosystem.
The top-level ontology would confine itself to the specification of such high level general (domain-
independent) categories as: time, space, inherence, instantiation, identity, measure, quantity,
functional dependence, process, event, attribute, boundary, and so on. The top-level ontology
would be designed to serve as common neutral backbone [39].
It would be supplemented by the work of ontologists working on more specialized domains, e.g.
the domain ontologies. Such ontologies should extend or specify the top-level ontology with
axioms and definitions to the objects in some given domain. Each community of research should
develop its own domain ontology.
A research data infrastructure should have the capability of managing and maintaining aligned the
top-level and domain ontologies of the science ecosystem.
7.4 Scientific Workflow Management
Today, scientists face many of the same challenges found in enterprise computing, namely
integrating distributed and heterogeneous resources. Scientists no longer use just a single
machine, or even a single cluster of machines, or a single source of data. Research collaborations
are becoming more and more geographically dispersed and often exploit heterogeneous tools,
compare data from different sources, and use machines distributed across several institutions
throughout the world. Therefore, the task of running and coordinating a scientific application
across several administrative domains remains extremely complex.
Definition
Scientific Workflow is a key component in a research data infrastructure. It orchestrates e-Science
services so that they co-operate to implement efficiently a scientific application.
Scientific Workflow has seen massive growth in recent years as science becomes increasingly reliant on the analysis of massive data sets and the use of distributed resources. The workflow programming paradigm is seen as a means of managing the complexity in defining the analysis, executing the necessary computations on distributed resources, collecting information about the analysis results, and providing means to record and reproduce the scientific analysis [40].
Workflows provide [41]:
A systematic and automated means of conducting analyses across diverse datasets and applications;

GRDI2020 Final Roadmap Report Page 41 of 108
A way of capturing this process so that results can be reproduced and the method can be reviewed, validated, repeated, and adapted;
A visual scripting interface so that computational scientists can create pipelines without low-level programming concern;
An integration and access platform for the growing pool of independent resource providers so that computational scientists need not specialize in each one.
The workflow is thus becoming a paradigm for enabling science on a large by managing data
preparation and analysis pipelines, as well as the preferred vehicle for computational knowledge
extraction.
Workflow Definition
A workflow is a precise description of a scientific procedure – a multi-step process to coordinate
multiple tasks, acting like a sophisticated script. Each task represents the execution of a
computational process, such as running a program, submitting a query to a database, submitting a
job to a compute cloud or grid, or invoking a service over the Web to use a remote resource. Data
output from one task is consumed by subsequent tasks according to a predefined graph topology
that “orchestrates” the flow of data [41].
Workflow Systems
Workflow systems generally have three components: an execution platform, a visual design suite,
and a development kit [41].
The platform executes the workflow on behalf of applications and handles common crosscutting
concerns, including: invocation of services and handling heterogeneities of data types, recovery
from failures, optimization of memory, storage, and execution including concurrency and
parallelization, data handling (mapping, referencing, movement, streaming and staging), security
and monitoring of access policies.
The design suite provides a visual scripting application for authoring and sharing workflows and
preparing the components that are to be incorporated as executable steps.
The development kit enables developers to extend the capabilities of the system and enables
workflows to be embedded into applications, Web portals, or databases.
Workflow Usage [41]
Workflows liberate scientists from the drudgery of routine data processing so they can
concentrate on scientific discovery. They shoulder the burden of routine tasks, they represent the
computational protocols needed to undertake data-centric science, and they open up the use of
processes and data resources to a much wider group of scientists and scientific application
developers. Workflows are ideal for systematically, accurately, and repeatedly running routine
procedures: managing data capture from sensors or instruments; cleaning, normalizing, and
validating data; securely and efficiently moving and archiving data; comparing data across
repeated runs; and regularly updating data warehouses.

GRDI2020 Final Roadmap Report Page 42 of 108
Workflow Types
In [40] four basic types of workflows encountered in business have been identified, and most have
direct counterparts in science and engineering. The first type of workflows, referred to as
collaborative workflows, are those that have high business value to the company and involve a
single large project and possibly many individuals. For example, the production, promotion,
documentation, and release of a major product fall into this category. The workflow is usually
specific to the particular project, but it may follow a standard pattern used by the company.
Within the scientific community, it can refer to the management of data produced and distributed
on behalf of a large scientific experiment such as those encountered in high-energy physics.
Another example may be the end-to-end tracking of the steps required by a biotech enterprise to
produce and release a new drug.
The second type of workflow is ad hoc. These activities are less formal in both structure and
required response; for example, a notification that a business practice or policy has changed that
is broadcast to the entire workforce. Any required action is up to the individual receiving the
notification.
Within science, notification-driven workflows are common. A good example is an agent process
that looks at the output of an instrument. Based on events detected by the instrument, different
actions may be required and sub-workflow instances may need to be created to deal with them.
The third type of workflow is administrative, which refers to enterprise activities such as internal
bookkeeping, database management, and maintenance scheduling, that must be done frequently
but are not tied directly to the core business of the company.
On the other hand, the fourth type of workflow, referred to as production workflow, is involved
with those business processes that define core business activities. For example, the steps involved
with loan processing are one of the central business processes of a bank. These are tasks that are
repeated frequently, and many such workflows may be concurrently processed.
Both the administrative and production forms of workflow have obvious counterparts in science
and engineering. For example, the routine tasks of managing data coming from instrument
streams or verifying that critical monitoring services are running are administrative in nature.
Production workflows are those that are run as standard data analyses and simulations by users
on a daily basis. For example, doing a severe storm prediction based on current weather
conditions within a specific domain or conducting a standard data-mining experiment on a new,
large data sample are all central to e-Science workflow practice.
Workflow-enabled e-Science [40]
Scientific workflows have emerged and been adapted from the business world as a means to
formalize and structure the data analysis and computations on the distributed resources.
There is a clear case for the role of workflow technology in e-Science; however, there are technical

GRDI2020 Final Roadmap Report Page 43 of 108
issues unique to science. Business workflows are typically less dynamic and evolving in nature.
Scientific workflows tend to change more frequently and may involve very voluminous data
translations. In addition, while business workflows tend to be constructed by professional
software and business flow engineers, scientific workflows are often constructed by scientists
themselves. While they are experts in their domains, they are not necessarily experts in
information technology, the software, or the networking in which the tools and workflows
operate. Therefore, the two cases may require considerably different interfaces and end-user
robustness both during the construction stage of the workflows and during their execution.
In composing a workflow, scientists often incorporate portions of existing workflows, making
changes where necessary. Business workflow systems do not currently provide support for storing
workflows in a repository and then later searching this repository during workflow composition.
The degree of flexibility that scientists have in their work is usually much higher than in the
business domain, where business processes are usually predefined and executed in a routine
fashion. Scientific research is exploratory in nature. Scientists carry out experiments, often in a
trial-and-error manner wherein they modify the steps of the task to be performed as the
experiment proceeds. A scientist may decide to filter a data set coming from a measuring device.
Even if such filtering was not originally planned, that is a perfectly acceptable option. The ability to
run, pause, revise, and resume a workflow is not exposed in most business workflow systems.
Finally, the control flow found in business workflows may not be expressive enough for highly
concurrent workflows and data pipelines found in leading edge simulation studies. Scientific
workflows may require a new control flow operator to succinctly capture concurrent execution
and data flow.
Workflow–Enabled Data–Centric Science [41]
Workflows offer techniques to support the new paradigm of data-centric science. They can be
replayed and repeated. Results and secondary data can be computed as needed using the latest
sources, providing virtual data (or on-demand) warehouses by effectively providing distributed
query processing.
The workflows as first class citizens in data-centric science, can be generated and transformed
dynamically to meet the requirements at hand. In a landscape of data in considerable flux,
workflows provide robustness, accountability, and full auditing.
Workflows enable data-centric science to be a collaborative endeavor on multiple levels. They
enable scientists to collaborate over shared data and shared services, and they grant non-
developers access to sophisticated code and applications without the need to install and operate
them. Consequently, scientists can use the best applications, not just the ones with which they are
familiar. Multidisciplinary workflows promote even broader collaboration. In this sense, a
workflow system is a framework for reusing community’s tools and datasets that represent the
original codes and overcomes diverse coding styles.

GRDI2020 Final Roadmap Report Page 44 of 108
Although the impact of workflow tools on data-centric science is potentially profound – scaling
processing to match the scaling of data – many challenges exist over and above the engineering
issues inherent in large-scale distributed software.
There are a confusing number of workflow platforms with various capabilities and purposes and
little compliance with standards. Workflows are often difficult to author, using languages that are
at an inappropriate level of abstraction and expecting too much knowledge of the underlying
infrastructure.
The reusability of a workflow is often confined to the project it was conceived in – or even to its
author- and it is inherently only as strong as its components. Although workflows encourage
providers to supply clean, robust, and validated data services, components failure is common.
Unfortunately, debugging failing workflows is a crucial but neglected topic. Contemporary
workflow platforms fall short of adequately supporting rapid deployment into the user
applications that consume them, and legacy application codes need to be integrated and
managed.
7.5 Interoperability and Mediation Software
There is a wide range of views as to what “interoperability” means. Interoperability intended as
the ability of two entities to work together very much depends on the working context in which
these two entities are embedded (Web services, DRM, Command and Control Systems, Digital
Libraries, e-Science, etc.). Due to this inherent complexity and multifaceted nature,
interoperability has been often misunderstood and confused with simple information
exchangeability or other forms of compatibility. Furthermore, when addressing interoperability
between two entities the fact that often these belong to two different organizations which have
their own policies has been ignored.
Based on the IEEE definition of interoperability - “The ability of two or more systems or
components to exchange information and to use the information that has been exchanged” - in
order to achieve interoperability between two entities (producer, consumer) three conditions
must be satisfied [42]:
the two entities must be able to exchange “meaningful” information objects
(exchangeability);
the two entities must be able to exchange “logically consistent” information objects (when
the exchanged information objects are descriptions of functionality, policy, or behaviour)
(Compatibility);
the consumer entity must be able to use the exchanged information in order to perform a
set of tasks that depend on the utilization of this information (Usability).

GRDI2020 Final Roadmap Report Page 45 of 108
7.5.1 Exchangeability – The Heterogeneity Problem
During the information object exchange process between producer and consumer entities
different sources of heterogeneity can be encountered depending on: how information objects are
requested by the consumer entity; the use of different terminologies; how information objects will
be represented; the semantic meaning of each information object; how information objects are
actually transported over a network.
Therefore, there are three types of heterogeneity to be overcome in order to achieve a
meaningful exchange of information objects:
Firstly, heterogeneity between the native data /query language (of the consumer entity) and the
target data /query language (of the producer entity). When this heterogeneity is resolved we say
that syntactic exchangeability between the two entities has been achieved.
Secondly, heterogeneity between the models adopted by the producer and the consumer entities
for representing information objects. When this heterogeneity is resolved we say that structural
exchangeability between the two entities has been achieved.
Finally, heterogeneity between the “semantic universe of discourse” of the producer and
consumer entities (differences in granularity, differences in scope, temporal differences,
synonyms, homonyms, etc.). When this heterogeneity is resolved we say that semantic
exchangeability between the two entities has been achieved.
These three levels of exchangeability, i.e., syntactic, structural, and semantic allow a meaningful
exchange of information objects between the two entities and thus guarantee the exchangeability
between them.
7.5.2 Compatibility – The Logical Inconsistency Problem
Some logical inconsistencies may arise between functional descriptions of services (producer) and
requests (consumer). In fact, when the exchanged information objects specify the functionality of
a service or what is required to satisfy a request, some inconsistencies may arise between the
logical relationships of these descriptions. When these inconsistencies are resolved we say that
the two entities/functionalities are compatible (a logic compatibility between the two entities has
been established – service compatibility, policy compatibility, etc.).
7.5.3 Usability – The Usage Inconsistency Problem
Usage inconsistency means that the consumer’s goal, that is, the objectives that she/he wants to
achieve by using the provider’s resources cannot be reached. Usage inconsistency may arise when
the consumer goal description and the producer resource description are inconsistent.
Possible causes for inability of the consumer entity to use the exchanged information objects are:
Quality mismatching
Data-incomplete mismatching

GRDI2020 Final Roadmap Report Page 46 of 108
Quality mismatching occurs when the quality profile associated with the exported information
object does not meet the quality expectations of the consumer entity.
Data-incomplete mismatching occurs when the exported information object is lacking some useful
information to enable the consumer entity to fully exploit the received information object. In fact,
in order to allow a consumer entity to use the exchanged information this must be complemented
with some “descriptive” information, such as contextual, provenance/lineage, quality, security,
privacy, etc. information which gives additional meaning. The descriptive information should be
modelled by purpose-oriented descriptive data models /metadata models.
The use of purpose-oriented descriptive data models is of paramount importance to achieve
usability.
7.5.4 Mediation Software
The main concept enabling interoperability of data/services/policies is mediation. This concept has
been used to cope with many dimensions of heterogeneity spanning data language syntaxes, data
models and semantics. The mediation concept is implemented by a mediator, which is a software
device capable of establishing interoperability of resources by resolving heterogeneities and
inconsistencies. It supports a mediation schema capturing user requirements, and an
intermediation function between this schema and the distributed information sources [43].
A key characteristic of the mediation process is the kind of intermediation function implemented
by a mediator. There are three main functions: mapping, matching and consistency checking.
Mapping refers to how information structures, properties, relationships are mapped from one
representation scheme to another one, equivalent from the semantic point of view.
Matching refers to the action of verifying whether two strings/patterns match, or whether
semantically heterogeneous data match.
Consistency checking refers to the action of checking whether the logical relationships between
functional/policy/organizational descriptions of two entities share a logical framework.
There are four main mediation scenarios:
Mediation of data structures: permits data to be exchanged according to syntactic, structural and
semantic matching. The functions of mapping, matching and integration are mainly adopted to
implement this kind of mediation.
Mediation of functionalities: makes it possible to overcome mismatching of functional
descriptions of two entities that are expressed in terms of pre- and post-conditions. The functions
of mapping, matching and consistency checking are mainly adopted to implement this kind of
mediation.
Mediation of policies/business logics: employs techniques to solve policy or business mismatches.
The functions of mapping, matching and consistency checking are mainly adopted to implement
this kind of mediation.
Mediation of protocols: makes it possible to overcome behavioural mismatches among protocols
run by interacting parties.

GRDI2020 Final Roadmap Report Page 47 of 108
Automated mediation: heavily relies on adequate modelling of the exchanged information. In
essence, the intermediation functions (mapping, matching and consistency checking) must
translate languages, data structures, logical representations and concepts between two systems.
The effectiveness, efficiency, and computational complexity of the intermediation function very
much depend on the characteristics of the information models (expressiveness, levels of
abstraction, semantic completeness, reasoning mechanisms, etc.) and languages adopted by the
two systems. Ideally, they must provide a framework for semantics and reasoning. Therefore, the
interoperable systems must adopt formally defined and scientifically sound information models
and ontologies. They constitute the conceptual (semantic) and syntactic basis for data languages.
Several formal information models and languages have been defined and developed for
representing, organizing and exchanging information objects (for example, RDF, XML, etc.).
Several discipline-specific standard models have been proposed and developed for representing
discipline-specific descriptive information (discipline-specific metadata models) which greatly
support the mediation process.
Logic-based and ontology-based models and languages have been defined for specifying
behaviour, functionality, and policy (for example, OWL-S).
An important role in the mediation process is played by ontologies. Several domain-specific
ontologies are being developed (CIDOC, etc.). Ontologies were initially developed by the Artificial
Intelligence community to facilitate knowledge sharing and reuse. An ontology is a set of concepts,
axioms, and relationships that describes a domain of interest.
Ontologies have been extensively used to support all the mediation functions, i.e. mapping,
matching and consistency checking because they provide an explicit and machine-understandable
conceptualization of a domain.
Therefore, automated mediation relies on:
Adequate modelling of structural, formatting, and encoding constraints of the exchanged
information resources;
Adequate modelling of data descriptive information (metadata);
Formal domain-specific Ontologies;
Abstracts models and languages for policy specification;
Abstract models and languages for functionality specification; and
Formally defined transfer and message exchange protocols.
The ultimate aim should be the definition and implementation of an “integrated mediation
framework” capable of providing the means to handle and resolve all kinds of heterogeneities and
inconsistencies that might hamper the effective usage of the resources of a global scientific data
infrastructure information infrastructure [44].
We envision that one of the most important features of the future scientific data infrastructures
will be the mediation software.

GRDI2020 Final Roadmap Report Page 48 of 108
8. Infrastructural Challenges
An infrastructural service is defined as a network-enabled entity that provides some capability.
Entities are network-enabled when they are accessible from other computers than the one they
are residing on. Research data infrastructures must provide some network-enabled “support
services” in order to achieve the conditions needed to facilitate effective collaboration among
spatially and institutionally separated communities of research.
A support service should be [45]:
Shareable: it must be able to be used by any set of users in any context consistent with its overall
goals.
Common: it must present a common consistent interface to all users, accessible by a standard
mean. The term “common” may be synonymous with the term “standard”.
Enabling: it must provide the basis for any user or set of users to create, develop, and implement
any applications, utilities, or services consistent with its goals.
Enduring: it must be capable of lasting for an extensive period of time. It must have the capability
of changing incrementally and in an economical feasible fashion to meet the slight changes of the
environment, but be consistent with the worlds view. In addition, it must change in a fashion that
is transparent to the users.
Scale: the service can add any number of users or uses and can by its very nature expand in a
structured manner in order to ensure consistent levels of service.
Economically sustainable: it must have economic viability.
The infrastructural services must make the holdings of the components of a digital science
ecosystem findable, aggregable and interoperable.
8.1 Data and Data Service/Tool Findability By findability we mean ease in discovering data/information/knowledge as well as data tools/services for specific researcher needs while taking into account relevant aspects of data attributes, tool/service functionality and deployability, context, provenance, researcher profiles and goals, etc. Currently, there is a conceptual shift from search to findability as the Internet search paradigm is
characterized by a lack of context, where the search is conducted in an independent way from
professional profiles, context, provenance, and work goals.
In the context of a digital science ecosystem searching for data/information/knowledge, tools and
services is better served by findability.
A findability capability should be of paramount importance for the next generation of global
research data infrastructures. Such a capability must be supported by semantic data models,
semantically rich metadata models, ontology/logic based languages for specifying data
tool/service functionality, personalization and contextualization support, ontology/taxonomy
management, mapping/matching techniques, etc.

GRDI2020 Final Roadmap Report Page 49 of 108
8.1.1 Data Registration
Registration of scientific primary data, to make these data citable as a unique piece of work and
not only a part of a publication, has always been an important issue.
It has long been recognized that unique identifiers are essential for the management of
information in any digital environment.
Once accepted for deposit and archived, data is assigned by a Registration Agency a “Digital
Object Identifier” (DOI) for registration. A Digital Object Identifier (DOI) [46] is a unique name (not
a location) within a networked data environment and provides a system for persistent and
actionable identification of data. DOIs provide persistent identification together with current
information about the object. By this, scientific data is not exclusively understood as part of a
scientific publication, but has its own identity.
The data itself is accessible through resolving the DOI in any web browser.
If a scientist reads a publication where the registered data is used, he might be interested in
analyzing the data under different aspects. After gaining permission to do so by the research
institution maintaining the data, he can cite the data in his own publications using its DOI,
referring to the uniqueness and own identity of the original data.
Identifiers assigned in one context may be encountered, and may be re-used, in another place (or
time) without consulting the assigner, who cannot guarantee that his assumptions will be known
to someone else. To enable such interoperability requires the design of identifiers to enable their
use in services outside the direct control of the issuing assigner. The necessity of allowing
interoperability adds the requirement of persistence to an identifier: it implies interoperability
with the future. Further, since the services outside the direct control of the issuing assigner are by
definition arbitrary, interoperability implies the requirement of extensibility: users will need to
discover and cite identifiers issued by different bodies, supported by different metadata
declarations, combine these on the basis of a consistent data model, or assign identifiers to new
entities in a compatible manner. Hence DOI is designed as a generic framework applicable to any
digital object, providing a structured, extensible means of identification, description and
resolution. The entity assigned a DOI can be a representation of any logical entity.
DOI may be used to offer an interoperable common system for identification of science data.
A DOI system should be composed of the following components:
a specified numbering syntax, a resolution service, a data model, and an implementation mechanism through policies and procedures for the

GRDI2020 Final Roadmap Report Page 50 of 108
governance and application of DOIs
Specified Numbering Syntax
The DOI syntax is a standard for constructing an opaque string with naming authority and
delegation. It provides an identifier “container” which can accommodate any existing identifier.
The word identifier can mean several things: (i) labels: the output of numbering schemes : e.g.
“ISBN 3-540-40465-1”; (ii) specifications for using labels: e.g. on internet URL, URN, URI; or (iii)
implemented systems: labels, following a specification, in a system – e.g. the DOI system, which is
a packaged system offering labels, tools and implementation mechanisms [46].
DOI Resolution
Resolution is the process in which an identifier is the input (a request) to a network service to
receive in return a specific output of one or more pieces of current information (state data)
related to the identified entity: e.g. a location (such as URL) where the object can be found.
Resolution provides a level of managed indirection between an identifier and the output.
DOI Data Model
The DOI data model consists of a data dictionary and a framework for applying it [46]. Together
these provide tools for defining what a DOI specifies (through use of a data dictionary), and how
DOIs relate to each other, (through a grouping mechanism, Application Profiles, which associate
DOIs with defined common properties). This provides semantic interoperability, enabling
information that originates in one context to be used in another in ways that are as highly
automated as possible.
The data dictionary is built from an underlying ontology. It is designed to ensure maximum
interoperability with existing metadata element sets; the framework allows the terms to be
grouped in meaningful ways (DOI Application Profiles) so that certain types of DOIs all behave
predictably in an application through association with specified Services.
A data dictionary is a set of terms, with their definitions, used in a computerized system. Some
data dictionaries are structured, with terms related through hierarchies and other relationships:
structured data dictionaries are derived from ontologies. An interoperable data dictionary
contains terms from different computerized systems or metadata schemes, and shows the
relationships they have with one another in a formal way. The purpose of an interoperable data
dictionary is to support the use together of terms from different systems.
Metadata defined through a dictionary is not essential to all applications of DOIs: their use as
persistent links for example can be supported without metadata, once the link is defined.
However, many other systems have their own metadata declarations, often using quite different
terminology and identifiers.
DOI Implementation

GRDI2020 Final Roadmap Report Page 51 of 108
DOI is implemented through a federation of Registration Agencies which use policies and tools
developed through a parent body, the Governance Body of the DOI system. It safeguards (owns or
licences on behalf of registrants) all intellectual property rights relating to the DOI System. It works
with RAs and with the underlying technical standards of the DOI components to ensure that any
improvements made to the DOI system (including creation, maintenance, registration, resolution
and policymaking of DOIs) are available to any DOI registrant, and that no third party licenses
might reasonably be required to practice the DOI standard.
DOIs and Scientific Data
The identification of scientific data is logically a separate issue from the identification of the
primary publication of such data to the scientific community in the form of articles, tables, etc. DOI
is already the core technology for maintaining cross-references via persistent links between a
citation and internet access to article.
The DOI as a long-term linking option from data to source publication is of fundamental
importance.
Some projects or communities have developed their own identifier schemes, which may be useful
for their own area. Such identifiers can be incorporated into a DOI to make them globally
interoperable and extensible and take advantage of other features provided in a DOI system.
DOIs for Scientific Data Sets
DOIs could logically be assigned to every single data point in a set; however in practice, the
allocation of a DOI is more likely to be to a meaningful set of data following the indecs Principle of
Functional Granularity [47]: identifiers should be assigned at the level of granularity appropriate
for a functional use which is envisaged.
This use of DOI will provide for the effective publication of primary data using a persistent
identifier for long-term data referencing, allowing scientists to cite and re-use valuable primary
data. The DOI’s persistent and globally resolvable identifier, associated to both a stable link to the
data and also a standardized description of the identified data, offers the necessary functionality
and also ready interoperability with other material such as scientific articles. The DOI as a long-
term linking option from data to source publication is of fundamental importance.
A key problem regards the reliable re-use of existing data sets, in terms both of attribution of
data source, and the archiving of data in context so as to be discoverable and interoperable
(usable by others). The extensibility of the mechanism is provided by allocating DOIs for data sets,
with associated metadata using a core management metadata (applicable to all datasets) and
structured metadata extensions (mapped to a common ontology) applicable to specific science
disciplines.
DOIs for Taxonomic Data
DOIs can also act as persistent identifiers of taxonomic definitions.
A name ascribed to a given group in a biological taxonomy is fixed in both time and scope and may

GRDI2020 Final Roadmap Report Page 52 of 108
or may not be revised when new information is available. Change occurs resulting in changes of
names, genera, families, classes, and relationships over time. When taxonomic revisions do occur,
resulting in the division or joining of previously described taxa, authors frequently fail to address
synonymies or formally emend the descriptions of higher taxa that are affected. DOI has been
proposed as a tool to manage a data model of nomenclature and taxonomy (enabling
disambiguation of synonyms and competing taxonomies) using a metadata resolution service
(enabling dissemination of archived and updated information objects through persistent links to
articles, strain records, gene annotations and any other data [48].
A Global Research Data Infrastructure must create and operate a Data Registration Environment
enabling an efficient identification of research data.
8.1.2 Data Citation
Data citation refers to the practice of providing a reference to data in the same way as researchers
routinely provide a bibliographic reference to printed resources. The need to cite data is starting
to be recognized as one of the key practices underpinning the recognition of data as a primary
research output rather than as a by-product of research. While data has often been shared in the
past, it is seldom cited in the same way as a journal article or other publication might be. This
culture is, however, gradually changing. If datasets were cited, they should have enabled scholarly
recognition and credit attribution [49].
Unfortunately, no universal standards exist for citing quantitative data. Practices vary from field to
field, archive to archive, and often from article to article. The data cited may no longer exist, may
not be available publicly, or may have never been held by anyone but the investigator. Data listed
as available from the author are unlikely to be available for long and will not be available after the
author retires or dies. Sometimes URLs are given, but they often do not persist.
A standard for citing quantitative data set, should go beyond the technologies available for printed
matter and responds to issues of confidentiality, verification, authentication, access, technology
changes, existing subfield-specific practices, and possible future extensions, among others.
A quantitative data set represents a systematic compilation of measurements intended to be
machine readable. The measurements may be the intentional result of scientific research for any
purpose, so long as it is systematically organized and described [50].
A data set must be accompanied by “metadata”, which describes the information contained in the
data set, details of data formatting and coding, how the data were collected and obtained,
associated publications, and other research information. Metadata formats range from a text
“readme” file, to elaborate written documentation, to systematic computer-readable definitions
based on common standards.

GRDI2020 Final Roadmap Report Page 53 of 108
A Minimal Citation Standard [50]
Citations to numerical data should include, at a minimum, five required components. The first
three components are traditional, directly paralleling print documents. They include:
The author of the data set
The date the data set was published or otherwise made
public
The data set title
The author, data, and title are useful for quickly understanding the nature of the data being cited,
and when searching for the data. However, these attributes alone do not unambiguously identify a
particular data set, nor can they be used for reliable location, retrieval, or verification of the study.
Thus, at least two additional components using modern technology, each of which is designed to
persist even when the technology inevitably changes, are needed. They are designed to take
advantage of the digital form of quantitative data.
The fourth component is a Unique Global Identifier, which is a short name or character string
guaranteed to be unique among such names, that permanently identifies the data set
independent of its location. The chosen naming scheme must:
unambiguously identify the data set object;
be globally unique;
be associated with a naming resolution service that takes the
name as input and shows how to find one or more copies of
the identical data set
Some examples of unique global identifiers include the Life-Science Identifier (LSID), the Digital
Object Identifier (DOI), and the Uniform Resource Names (URN). All are used to name data sets in
some places, and under specific sets of rules and practices.
All unique global identifiers are designed to persist (and remain unique) even if the particular
naming authority that created it goes out of business or changes names or location. Including such
identifier provides enough information to identify unambiguously and locate a data set, and to
provide many value-added services, such as on-line analyses, or forward citation to printed works
that cite the data set, for any automated systems that are aware of the naming scheme chosen.
Uniqueness is also guaranteed across naming schemes, since they each begin with a different
identifying string.
It is recommended that the unique identifier resolve to a page containing the descriptive and
structural metadata describing the data set, presented in human readable form to web browsers,
instead of the data set itself. This metadata description page should include a link to the actual
data set, as well as a textual description of the data set, the full citation in standard format,
complete documentation, and any other pertinent information. The advantage of this general

GRDI2020 Final Roadmap Report Page 54 of 108
approach is that identifiers in citations can always be resolved, even if the data are proprietary,
require licensing agreements to be signed prior to access, are confidential, demand security
clearance, are under temporary embargo until the authors execute their right of first publication,
or for other reasons. Metadata description pages like these also make it easier for search engines
to find data.
The fifth component is a Universal Numeric Fingerprint (UNF). The need for introducing a fifth
component is justified by the fact that unique global identifiers do not guarantee that the data
does not change in any meaningful way when the data storage formats change. The UNF is a short,
fixed-length string of numbers and characters that summarize all the content in the data set, such
that a change in any part of the data would produce a completely different UNF. A UNF works by
first translating the data into a canonical form with fixed degrees of numerical precision and then
applies a cryptographic hash function to produce the short string. The advantage of
canonicalization is that UNFs are format-independent: they keep the same value even if the data
set is moved between software programs, file storage systems, compression schemes, operating
systems, or hardware platforms. Finding an altered version of a data set that produces the same
UNF as the original data is theoretically possible given enough time and computing power, but the
time necessary is so vast and the task so difficult that for good hash functions no examples have
ever been found.
The metadata page to which the global unique identifier resolves should include a UNF calculated
from the data, even if the data are highly confidential, available only to those with proper security
clearance, or proprietary. The one-way cryptographic properties of the UNF mean that it is
impossible to learn about the data from its UNF and so UNF’s can always be freely distributed.
Most importantly, this means that editors, copyeditors, or others at journals and book publishers
can verify whether the actual data exists and is cited properly even if they are not permitted to see
a copy. Moreover, even if they can see a copy, having the UNF as a short summary that verifies the
existence, and validates the identity, of an entire data set is far more convenient than having to
study the entire original data set.
The essential information provided by a citation is that which enables the connection between it
and the cited data set. Yet, authors, editors, publishers, data producers, archives, or others may
still wish to add optional features to the citation, such as to give credit more visibly to specific
organizations, or to provide advertising for aspects of the data set.
Institutional Commitment
The persistence of the connection between data citation and the actual data ultimately must also
depend on some form of institutional commitment.
This means that, at least early on, readers, publishers, and archives will have to judge the degree
of institutional commitment implied by a citation, just as with print citations. Obviously, if the
citation is backed by a major archive, i.e., a major university/ research center, there is less to
worry about than there might otherwise be. Journal publishers may wish to require that data be
deposited in places backed by greater institutional commitment, such as established archives.

GRDI2020 Final Roadmap Report Page 55 of 108
A science ecosystem should be strongly committed in the development of a distributed archive
that keeps and organizes all data used by its communities of research creating, thus, a trustworthy
structure.
Deep Citation
“Deep Citation” refers to references to subsets of data sets, and are analogous to page references
in printed matter. Data may be subsetted by row, by column, or both. Subsets also often include
additional processing, such as imputation of missing data.
Devising a simple standard for describing the chain of evidence from the data set to the subset
would be highly valuable. The task of creating subsets is relatively easy and is done in a large
variety of ways by researchers. It is suggested that a citation be made to the entire data set as
described above, and that scholars provide an explanation for how each subset is created in the
text, and refer to a subset by reference to the full data set citation with the addition of a UNF for
the subset (i.e., just as occurs now for page numbers in citations to printed matter).
Huge data sets sometimes come with more specific methods of referencing data subsets, and may
easily be added as optional elements. Any ambiguity in what constitutes a definable “data set”
which may be an issue in very large collections of quantitative information, is determined by the
author who creates the global unique identifier and UNF. If the subset includes substantial value-
added information, such as imputation of missing data or corrections for data errors, then it will
often be more convenient to store and cite the subset as a new data set, with documentation that
explains how it was created.
Versioning
It is recommended the treatment of subsequent versions of the same data set as separate data
sets, with links back to the first from the metadata description page. Forward links to new versions
from the original are easily accomplished via a search on the unique global identifier. New versions
of very large data sets (relative to available storage capacity) can be kept by creating a data set
that contains only differences from the original, and describing how to combine the differences
with the original on the data set’s metadata description page. Version changes may also be noted
in the title, date, or using the extended citation elements.
Concluding Remarks
Together, the global unique identifier and UNF ensure permanence, verifiability, and accessibility
even in the situations where the data are confidential, restricted, or proprietary; the sponsoring
organization changes names, moves, or goes out of business; or new citation standards evolve.
Together with the author, title, and date, which are easier for humans and search engines to
understand, all elements of the proposed citation scheme for quantitative data should achieve
what print citations do and, in addition to being somewhat less redundant, take advantage of the
special features of digital data to make it considerably more functional. The proposed citation
scheme enables forward referencing from the data set to subsequent citations or versions

GRDI2020 Final Roadmap Report Page 56 of 108
(through the persistent identifier) and even a direct search for all citations to any data set (by
searching for the UNF and appropriate version number).
A Global Research Data Infrastructure must efficiently and effectively support a data citation
scheme.
8.1.3 Data Discovery
One big challenge faced by researchers when conducting a research activity in a networked
multidisciplinary environment is pinpointing the location of relevant data.
The ability to determine where data sets are located, what is in those data sets, and who can
access them is a critical but necessary step in order to be able to access all the data stored in
several data collections distributed in a science ecosystem that are relevant to her/his research
activities.
By Data Discovery we mean the capability to quickly and accurately identify and find data that
supports research requirements.
The process of discovering data that exist within a data set is supported by search and query
capabilities which exploit metadata descriptons contained in data categorization/classification
schemes, data dictionaries, data inventories, and metadata registries.
8.1.3.1 Data Classification Data classification is the categorization of data for its most effective and efficient use. In a basic
approach to storing computer data, data can be classified according to its critical value or how
often it needs to be accessed, with the most critical or often-used data stored on the fastest media
while other data can be stored on slower (and less expensive) media. This kind of classification
tends to optimize the use of data storage for multiple purposes - technical, administrative, legal,
and economic. Data can be classified according to any criteria. A well-planned data classification
system makes essential data easy to find. This can be of particular importance in data discovery.
In the field of data management data classification as a part of Information Lifecycle Management (ILM) process can be defined as tool for categorization of data to enable/help researchers to effectively answer following questions:
What data types are available? Where are certain data located? What access levels are implemented? What protection level is implemented and does it adhere to compliance regulations?
Data Classification Tools: Data classification is typically a manual process; however, there are
many tools from different vendors that can help gather information about the data. They help
“categorie” data, primarily for the purpose of tiered storage and are focused on finding
unstructured data on a variety of file shares. This data can be categorized by content, file type,
usage and many other variables.

GRDI2020 Final Roadmap Report Page 57 of 108
8.1.3.2 Data Dictionary Data Dictionaries contain the information about the data contained in large data collections. Each
data element is defined by its data type, the location where it can be found, and the location that
it came from. Often the data dictionary includes the logic when a field is derived. The logic can be
business logic or research logic but it must be defined.
The data dictionary also includes the physical location, such as a server DNS (domain name
system) name or the IP address. The data collection name, the instance, the table, and the field
name are particularly important for the researcher seeking for relevant data. This information is
even more important if the researcher must cross multiple systems to gather the necessary pieces
of information for her/his research.
A data collection administration should be responsible for keeping this important information up
to date and accurate. Typically each data collection has its own data dictionary. It is a good
practice to have one owner of each data dictionary.
8.1.3.3 Metadata Registry Metadata registries are used whenever data must be used consistently within a research community or in a multidisciplinary context. Examples of these situations include:
Communities that transmit data using structures such as XML, Web Services or EDI Communities that need consistent definitions of data across time, between databases,
between communities or between processes, for example when a community builds a large data collection
Communities that are attempting to break down "silos" of information captured within applications or proprietary file formats
Central to the charter of any metadata management program is the process of creating trusting relationships with stakeholders and that definitions and structures have been reviewed and approved by appropriate parties. A metadata registry typically has the following characteristics:
Protected environment where only authorized individuals may make changes Stores data elements that include both semantics and representations Semantic areas of a metadata registry contain the meaning of a data element with precise
definitions Representational areas of a metadata registry define how the data is represented in a
specific format, such as in a database or a structured file format (e.g., XML)
8.1.3.4 Data Inventory Research communities will need to develop their own “data inventory” focused on identifying and
describing all the data elements contained across their different data collections.
The goal of a data inventory is to inventory the data researchers actually need. Inventorying the
data that moves between systems, data collections and scientific communities accomplishes two
things: it identifies the most valuable data elements in use, and it will also help identify data that’s
not high-value, as it is not being shared or used. This approach also provides a way to tackle initial
data quality efforts by identifying the most “active” data used by a research community. It

GRDI2020 Final Roadmap Report Page 58 of 108
ultimately helps the data management team understand where to focus its efforts, and prioritize
accordingly.
Legacy data inventory and profiling is a structured and comprehensive way of learning about the
corporate data asset. This activity is centered on a professional data analyst who gathers
information, runs a variety of reports and ad hoc queries to assess the existing data and creates or
updates documentation about the existence, scope, meaning and quality of the data asset.
The resulting documentation (including high-level summaries and easily navigated detail data
behavior documentation) should provide answers to the following key questions:
What data do we have? Where can it be found? What constraints limit read-only access? Where did each unit of data come from? What is its age distribution? What is its scope? What is its quality? Does it include test data? What is the business meaning of the data? Are there ambiguities in usage, meaning and expectations?
In addition to the technical issues of where the data is located, the lead data analyst should also
assess and document the political issues surrounding the data—an issue such as who “owns” any
portion of the data or who seeks to limit read-only access to the data.
A Research Data Infrastructure must efficiently support a Data Discovery Environment composed
of query and search capabilities as well as data discovery tools including data
categorization/classification schemes and/or data dictionaries and/or data inventories and/or
metadata registries.
8.1.4 Data Tool/Service Discovery
Acceptance of the open science principle entails open access not only to research data but also to
data services/tools/analyses/methods which enable researchers to conduct efficiently and
effectively their research activities.
Enabling automated location of data services/tools that adequately fulfill a given research need is
an important challenge for a global research data infrastructure.
Description of Data Services/Tools
Publishing a data service/tool requires a description of the data service/tool capability, i.e., what
functionality the data service/tool provides.
We have identified three different levels of service description:

GRDI2020 Final Roadmap Report Page 59 of 108
a first level which describes the static characteristics of the service also called abstract capabilities; the abstract capabilities of a service describe only what a published service can provide but no longer under which circumstances a concrete service can actually be provided [51].
a second level which describes the dynamic characteristics of the service also called contracting capabilities; the contracting capabilities describe what input information is required for providing a concrete service and what conditions it must fulfill (i.e. service pre conditions), and what conditions the objects delivered fulfill depending on the input given (i.e. post conditions) [51]. The abstract capability might be automatically derived from the contracting capability and both must be consistent with each other.
a third level which describes the characteristics of the operational environment where the service will be hosted, i.e., the operational conditions, capacity requirements, the service’s resource dependencies, and integrity and access constraints, also called deployment capabilities; the deployment capabilities describe the hosting operational environment.
Description of Researcher Needs [52]
Researchers may describe their desires in a very individual and specific way that makes immediate
mapping with data service/tool descriptions very complicated. Therefore, each service discovery
attempt requires a process where user expectations are mapped on more generic need
descriptions.
A researcher is expected to specify her/his needs in terms of what he wants to achieve by using a
concrete data service/tool. We assume that a researcher will in general care about what she/he
wants to get from a concrete service, but not about how it is achieved. Her/his desire is formally
described by the so-called goal. In particular, goals describe what kind of outputs and effects are
expected by the researcher.
Data service/tool requesters (researchers) are not expected to have the required background to
formally describe their goals. Thus, either goals can be expressed in a language they are familiar
with (like natural language) or appropriate tools should be available which can support requesters
to express their precise needs in a simpler manner. Hence, a possible approach could be the
availability of pre-defined, generic, formal and reusable goals defining generic objectives
requesters may have. They can be refined (or parameterized) by the requester to reflect his
concrete needs, as requesters are not expected to write formalized goals from scratch. It is
assumed that there will be a way for requesters to easily locate such pre-defined goals e.g.
keyword matching.

GRDI2020 Final Roadmap Report Page 60 of 108
Modeling Approaches to Goals and Data Services/Tools [52]
Keyword based Representation Models
By adopting this model, both requester and provider use keywords to describe their goals and
services respectively.
Controlled vocabularies
Another approach assumes that requester and provider use (not necessarily the same) controlled
vocabularies in order to describe goals and services respectively.
Ontologies
The border between controlled vocabularies and ontologies is thin and open for a smooth and
incremental evolvement. Ontologies are consensual and formal conceptualizations of a domain.
Controlled vocabularies organized in taxonomies resemble all necessary elements of an ontology.
Ontologies may simply add some logical axioms for further restricting the semantics of the
terminological elements. Notice that a service requester or provider gets these logical definitions
"for free". She/He can select a couple of concepts for annotating her/his service/request, but
she/he does not need to write logical expressions as long as she/he only reuses the ones already
included in the ontology.
Full-fledged Logic
Simply reusing existing concept definitions as described in the previous section has the advantage
of the simplicity in annotating services and in reasoning about them. However, this approach has
limited flexibility, expressivity, and grain-size in describing services and request. Therefore, it is
only suitable for scenarios where a more precise description of requests and services is not
required. For these reasons, a full-fledged logic is required when a higher precision in the results
of the discovery process is required.
The Data Service/Tool Location Process
Based on formal models for the description of data services/tools and goals, a conceptual model
for the semantic-based location process of services can be defined [51].
This process is composed of five steps:
Goal Discovery: starting from a user desire (expressed using natural language or any other means), goal discovery will locate the pre-defined goals, resulting on a selected pre-defined goal. Such a pre-defined goal is an abstraction of the requester desire into a generic and reusable goal.
Goal Refinement: The selected pre-defined goal is refined, based on the given requester desire, in order to actually reflect such desire. This step will result on a formalized requester goal.

GRDI2020 Final Roadmap Report Page 61 of 108
Service Discovery: Available services that can, according to their abstract capabilities, potentially fulfill the requester goal are discovered.
Service Contracting: Based on the contracting capability, the abstract services selected in the previous step will be checked for their ability to deliver a suitable concrete service that fulfills the requester’s goal. Such service(s) will be selected. This step might involve interaction between service requester and provider.
Service Workability: the final step has to verify whether the hosting computing environment is suitable for efficiently running the selected service(s).
Mediation Support in the Data Service/Tool Discovery Process
Data service/tool discovery is based on matching abstracted goal and service descriptions. In order
to lift discovery process on an ontological level two processes are required: a) the concrete user
input has to be generalized to more abstract goal descriptions, and b) concrete services and their
descriptions have to be abstracted to the classes of services a science ecosystem can provide [52].
In order to successfully carry out the data service/tool discovery process a mediation support must
be offered by the data infrastructure; such mediation support should establish a mapping
between the controlled vocabularies or ontologies used to describe goals and services. In fact, we
assume that goals and data services/tools most likely use different controlled vocabularies or
ontologies.
Depending on the modeling approach adopted for representing goals and data services/tools,
different mediation support should be provided:
Keyword based Representation Models
The mediation process consists in matching a set of keywords extracted from a goal description
against a set of keywords extracted from a service description.
Controlled vocabularies
The mediation process consists in mapping a set of concepts extracted from a goal description into
a set of concepts contained in a data service/tool description and equivalent from the semantic
point of view. Reasoning over hierarchical relationships may be required in case of taxonomies.
Mediation support is needed in case the requester and provider use different controlled
vocabularies.
Ontologies
The descriptions of abstract services and goals are based on ontologies that capture general
knowledge about the problem domains under consideration.
The mediation process consists in mapping the set of concepts describing the goal into
semantically equivalent concepts contained in the service description.
Mediation support is needed in case the requester and provider use different ontologies.

GRDI2020 Final Roadmap Report Page 62 of 108
Full-fledged Logic
If a full-fledged logic is adopted for describing goals and services, a mediation support can only be
provided if the terminology used in the logical expressions is grounded in ontologies. Therefore,
the mediation support required is the same as for ontology-based discovery.
Data Service/Tool Registration
A research data infrastructure should maintain a registry where all the abstract static, dynamic
and deployment data service/tool descriptions, made publicly available by the communities of
research of the science ecosystem, as well as pre-defined, generic, formal and reusable goals are
contained. These descriptions contain all the information necessary to enable an efficient and
effective automated location of data services/tools that adequately fulfill a given research need.
In addition, research data infrastructures should maintain the appropriate tools, i.e., controlled
vocabularies, ontologies, etc. as well as mapping algorithms in order to be able to provide an
efficient mediation support.
8.2 Data Federation
Data federation is an umbrella term for a wide range of decentralized data practices.
At one extreme of this range we have data integration. It is the process of combining data residing
at different sources, and providing the user with a unified view of these data. Data integration has
two broad goals: increasing the completeness and increasing the conciseness of data that is
available to users and applications.
A slightly different concept is data harmonization; it refers to the process of comparing similar
conceptual and logical data models to determine the common data elements, similar data
elements and dissimilar data elements in order to produce a resulting unified data model that can
be used consistently across organizational units.
On the other extreme of the range we have the concept of data linking. It refers to the process of
publishing data on a scientific data space in such a way that its meaning is explicitly defined, it is
linked to other external data sets and can in turn be linked to from external data sets.
A data linking capability does not act as a data integration system as this requires semantic
integration before any service can be provided; instead it follows a co-existence approach, i.e., to
provide base functionality over all data sets, regardless of how integrated they are.
An aggregation/federation capability should be of paramount importance for the next generation
of global research data infrastructures.
8.2.1 Data Integration
Data Integration is the problem of combining data residing at different sources, and providing the
user with a unified view of these data. Data integration has two broad goals [53]: increasing the

GRDI2020 Final Roadmap Report Page 63 of 108
completeness and increasing the conciseness of data that is available to users and applications. An
increase in completeness is achieved by adding more data sources (more objects, more attributes
describing objects) to the system. An increase in conciseness is achieved by removing redundant
data, by fusing duplicate entries and merging common attributes into one.
The problem of designing data integration systems is important in current scientific applications
and is characterized by a number of issues that are interesting from a theoretical point of view
[54]. The data integration systems are characterized by an architecture based on a global schema
and a set of sources. The sources contain the real data, while the global schema provides a
reconciled, integrated, and virtual view of the underlying sources.
Data integration is a three-step process: data transformation, duplicate detection, and data
fusion[53].
8.2.1.1 Data Transformation This step is concerned with the transformation of the data present in the sources into a common
representation (renaming, restructuring). Data from the data sources must be transformed to be
conform to the global schema of an integrated information system.
Modelling the relation between the sources and the global schema is therefore a crucial aspect.
Two basic approaches have been proposed for this purpose. The first approach, called global-as-
view (or schema integration), requires the global schema is expressed in terms of the data
sources. In essence, this approach regards the individual schemata and tries to generate a new
schema that is complete and correct with respect to the source schemata, that is minimal and
understandable. The second approach, called local-as-view (or schema mapping), requires the
global schema to be specified independently from the sources, and the relationships between the
global schema and the sources are established by defining every source as a view over the global
schema. This approach is driven by the need to include a set of sources in a given integrated
information system. A set of correspondences between elements of a source schema and
elements of the global schema are generated to specify how data is to be transformed.
The goal of both approaches is the same: transform data of the sources so that it conforms to a
common global schema.
8.2.1.2 Duplicate Detection This step regards the identification of multiple, possibly inconsistent representations of the same
real-world objects. The basic input to data fusion. The result of the duplicate detection step is the
assignment of an object-ID to each representation. Two representations with the same object-ID
indicate duplicates. Note that more than two representations can share the same object-ID, thus
forming duplication clusters. It is the goal of data fusion to fuse these multiple representations
into a single one.
8.2.1.3 Data Fusion This step combines and fuses the duplicate representations into a single representation while
inconsistencies in the data are resolved. A number of data fusion strategies have been defined.
Conflict-ignoring strategies do not make a decision as to what to do with conflicting data. They
escalate conflicts to user or application or create all possible value combinations.

GRDI2020 Final Roadmap Report Page 64 of 108
Conflict-avoiding strategies acknowledge the existence of possible conflicts in general, but do not
detect and resolve single existing conflicts.
Conflict resolution strategies regard all data and metadata before deciding on how to resolve a
conflict. They can further be subdivided into deciding and mediating strategies, depending on
whether they choose a value from all the already present values (deciding) or choose a value that
does not necessarily exist among conflicting values (mediating).
When handling the data integration problem special attention must be devoted to the following
aspects: modelling a data integration application, processing queries in data integration, dealing
with inconsistent data sources and reasoning on queries.
8.2.2 Data Harmonization
By and large, most of information is stored in databases on mainframe computers. Most of these
systems are not accessible via network connections due to security concerns. This has hindered
development of “real time” data aggregation efforts. Additionally, most of the data models for
these systems are not harmonized since most have evolved separately from different sets of
requirements. To further complicate matters, many different vendors have implemented most
existing systems using different products and information models [55].
Data Harmonization is the process of comparing similar conceptual and logical data models to
determine the common data elements, similar data elements and dissimilar data elements in order
to produce a resulting unified data model that can be used consistently across organizational units,
business systems, and Data Warehouses.
Data Harmonization covers both the data as well as the underlying business definitions.
There is a need for efficient harmonization tools to support the harmonization process. Some
possible features of a harmonization tool are:
The ability to import data models into the tool from various representation formats.
The ability to linguistically and semantically analyze the components of multiple data
models to determine equivalence, similarity and dissimilarity.
The ability to construct multi-modal views of the data models to assist in comparison
analysis.
The ability to harmonize and visualize models with multiple users simultaneously and to
jointly create the resultant data model.
The automated ability to extract common data elements across models to produce a new
resultant skeleton model that can be further refined by a manual process.
The ability to save the resultant data model in multiple representations (the same set of
representations available to import).
Data harmonization has a number of dimensions [56]:

GRDI2020 Final Roadmap Report Page 65 of 108
Legal requirements: in essence they concern political commitments.
Technical aspects: modalities applied in the data harmonization.
Operational aspects: adoption of international standards related to data length, format,
attributes and semantic interoperability.
A real time, event-driven and harmonized view of all data is desired. To facilitate this
development, a methodology and practice must be used to ensure any future work has a strong
foundation of data harmonization to be built upon.
8.2.3 Data Linking
In the context of a Science ecosystem linking data becomes an imperative as it allows users to
benefit from the use of multiple datasets created by different research communities/organizations
including the connection of publications with the subject data.
A scientific data infrastructure must lower the barrier to publishing and accessing data leading,
thus, to the creation of scientific data spaces by connecting data sets from diverse domains,
disciplines, regions and nations. The concept of scientific data space is an answer to the rapidly-
increasing demands of researchers for data-everywhere.
Linking data refers to the capability, supported by a scientific data infrastructure, of publishing
data on a scientific data space in such a way that it is machine-readable, its meaning is explicitly
defined, it is linked to other external data sets and can in turn be linked to from external data sets.
A data infrastructure supporting a data space does not act as a data integration system as this
requires semantic integration before any service can be provided; instead it follows a co-existence
approach, i.e., to provide base functionality over all data sets, regardless of how integrated they
are [57].
A scientific data infrastructure should offer the possibility for researchers to start browsing in one
data set and then navigating along links into related data sets; or it can support data search
engines that crawl the data space by following links between data sets and provide expressive
query capabilities over aggregated data. To achieve this, the data infrastructure must support the
creation of typed links between data from different sources.
Data providers willing to add their data to a scientific data space which allows data to be
discovered and used by various applications must publish them according to some principles.
These provide a basic recipe for publishing and connecting data using the scientific data
infrastructure architecture, services, and standards. The principles should include [58]:
the assignment of permanent universal data identifiers, i.e., strings or tokens that are
unique within a data space;
setting links to other data sources so that users can navigate the data space as a whole by
following the links; and
the provision of metadata so that users can assess the quality of published data.
A scientific data space enabled by a data infrastructure enjoys the following properties [58]:

GRDI2020 Final Roadmap Report Page 66 of 108
it contains data specific of the scientific disciplines supported by the data infrastructure;
any scientific community belonging to the disciplines supported by the data infrastructure
can publish on the scientific data space;
data providers are not constrained in choice of vocabularies with which to represent data;
data is connected by links, supported by the data infrastructure, creating a global data
graph that spans data sets and enables the discovery of new data sets.
From an application development perspective the scientific data space should have the following
characteristics [58]:
data is strictly separated from formatting and presentational aspects;
data is self-describing;
the scientific data space is open, meaning that applications do not have to be implemented
against a fixed set of data sets, but can discover new data sets at run time by following the
data links
From a system perspective, a data infrastructure should provide:
a registry service whose purpose is to manage a collection of identifiers and make it
actionable and interoperable, where that collection can include identifiers from many
other controlled collections;
a name resolution system, which resolves the data identifiers into the information
necessary to locate, and access them;
automated or semi-automated generation of links.
8.3 Data Sharing
Definition
Openness in the sharing of research results is one of the norms of modern science. The
assumption behind this openness is that progress in science demands the sharing of results within
the scientific community as early as possible in the discovery process.
Data Sharing is the use of information by one or more consumers that is produced by another
source other than the consumer.
Why Share Research Data [59]
Research data are a valuable resource, usually requiring much time and money to be produced.
Many data have a significant value beyond usage for the original research.
Sharing research data is important for several reasons:
Encourages scientific enquiry and debate
Promotes innovation and potential new data uses
Leads to new collaborations between data users and data creators

GRDI2020 Final Roadmap Report Page 67 of 108
Maximizes transparency and accountability
Enables scrutiny of research findings
Encourages the improvement and validation of research methods
Reduces the cost of duplicating data collection
Increases the impact and visibility of research
Promotes the research that created the data and its outcomes
Can provide a direct credit to the researcher as a research output in its own right
Provides important resources for education and training.
How to Share Data [59]
There are various ways to share research data, including:
Depositing them with a specialist data center, data archive or data bank
Submitting them to a journal to support a publication
Depositing them in an institutional repository
Making them available online via a project or institutional website
Making them available informally between researchers on a peer-to-peer basis
Approaches to data sharing may vary according to research environments and disciplines, due to
the varying nature of data types and their characteristics.
Data Documentation [59]
A crucial part of making data user-friendly, shareable and with long-lasting usability is to ensure
they can be understood and interpreted by any user. This requires clear and detailed data
description, annotation and contextual information.
Data documentation explains how data were created or digitized, what data mean, what the
content and structure are and any data manipulations that may have taken place. Documenting
data should be considered best practice when creating, organizing and managing data and is
important for data preservation. Whenever data are used sufficient contextual information is
required to make sense of that data.
Good data documentation includes information on:
The context of data collection: project history, aim, objectives and hypotheses
Data collections methods: sampling, data collection processes, instruments used, hardware and software used, scale and resolution, temporal and geographic coverage and secondary data sources used
Dataset structure of data files, study cases, relationships between files
Data validation, checking, profiling, cleaning and quality assurance procedures carried out
Changes made to data over time since their original creation and identification of different versions of data files
Information on access and use conditions or data confidentiality
Difficulties in Data Sharing [60]

GRDI2020 Final Roadmap Report Page 68 of 108
Despite its importance, however, sharing data is not easy. There are three categories of problems
hindering data sharing: (i) willingness to share, (ii) locating shared data, and (iii) using shared data.
First, there is a strong sense in which the scientist’s ability to profit from data collection depends
on maintaining exclusive control over the data – economists would say that the data are a source
of “monopoly rents” for the scientist. In this case, however, the profit, or rent, accrues largely in
the form of scientific reputation and its accompanying benefits, such as publications, grants, and
students [61].The point here is that the competition (and its associated benefits) in science is
intense, and there may be a strong reluctance on the part of scientists to share data, as such
sharing may amount to a sacrifice of future rents that could be extracted from the data were they
not shared.
Second, researchers must become aware of who has the data they need or where the data are
located, which can be a nontrivial problem [62]. After finding appropriate data, they often must
negotiate with the owner or develop trusting relationships to gain access [63].
Third, once in possession of a data set, understanding it requires knowledge of the context of its
creation [64]. How was each datum collected and analyzed? What format are the data in? If the
data are in electronic form, is there a key or metadata available to indicate what the various fields
in the database mean? Researchers also need to know something about the quality of the data
they are receiving, and if the original purpose of the data set is compatible with the proposed use.
Answering these questions requires a large amount of effort on the part of the data creator, but
the benefit of such effort goes largely to the secondary user. This renders it unlikely that adequate
documentation will be produced.
Even if documentation is provided, however, it is often the case that much of the knowledge
needed to make sense of data sets is tacit. Scientists are not necessarily able to explicate all of the
information that is required to understand someone else’s work.
Approaches to Data Sharing
Shared data is only useful if sufficient context is provided about the data such that collaborators
may comprehend and effectively apply it. Typically, data context is passed among collaborating
scientists via one-to-one discussion (f2f interactions, over the phone, and through emails).
More recently, data sharing environments have developed a number of approaches to the above
issues. For example, standardized reporting formats and metadata protocols can allow the same
data to be read across different hardware or software. Password and security systems can give a
certain degree of control over who does and does not have access to data sets. Metadata may
provide context about who collected data and how they were processed.
While these approaches deal effectively with the explicit technological problems inherent in data
sharing, it is not clear that they adequately deal with many of the tacit and social issues outlined
above. Indeed, a metadata model can only provide so much contextual information, leading to a
potentially recursive situation in which metadata models require “meta-metadata” in order to be
effectively understood.

GRDI2020 Final Roadmap Report Page 69 of 108
Recent calls for data sharing suggest that funding agencies believe that groundbreakings scientific
research requires more data sharing among scientists. Even if we provide the technical means to
move data from one lab to another, however, there may be social barriers to effectively using this
data in practice. To design technologies that truly support the conduct of science and not just the
sharing of a data set, the designer must understand both the scientific role that data play in
producing knowledge, and the social role that data play in the conduct of scientific work.
Data features and properties
Among the most prominent data features and properties which enable the sharing of data we
include [65]:
General data set properties (Basic data set properties such as owner, creation date, size, format, etc)
Experimental properties (Conditions and properties of the scientific experiment that generated or is to be applied to the data)
Data provenance (Relationship of data to previous versions and other data sources)
Integration (Relationship of data subsets within a full data set)
Analysis and interpretation ( Notes, experiences, interpretations, and knowledge generated from analysis of data)
Physical organization (Mapping of data sets to physical storage structure such as a file system, database, or some other data repository)
Project organization (Mapping of data sets to project hierarchy or organization)
Task (Research task(s) that generated or applies data set)
Experimental process (Relationship of data and tasks to overall experimental process)
User community (Application of data sets to different organizations of users)
Data Sharing Environments
A data sharing environment is composed of a number of capabilities and tools that support the
contexts for shared data use. Here, we list some of these data sharing capabilities/tools:
Data Browsing tools
Data Viewing tools
Data Translations capabilities and tools
Capabilities for accessing and applying external databases
Database Connection tools
Subscription capabilities
Notification capabilities
Annotation tools
Data Provenance tools

GRDI2020 Final Roadmap Report Page 70 of 108
As one important objective of the research data infrastructures is the creation of scientific
collaborative environments, they have to support efficient and effective data sharing
environments which constitute a key component of the collaborative environments.

GRDI2020 Final Roadmap Report Page 71 of 108
9. Application Challenges
9.1 Complex Interaction Modes
Scientific data infrastructures must tackle challenges that emerge when solving data-intensive
problems that take into account interaction. Interaction includes the ways in which researchers
interact with running analyses and visualizations, and the longer-term succession of operations
that researchers perform to progressively find, understand and use data. Many problems will
involve geographically distributed teams. Collaboration across institutions and disciplines is
becoming the norm, to gather skills and knowledge and to access sufficient information for
statistical significance. This leads to privacy and ownership issues, especially where sensitive
personal data is involved.
Challenges in supporting researchers interacting with data include: finding the right or sufficient
data, coping with missing or poor quality data, integrating data from diverse sources with
significant differences in form and semantics, understanding and dealing with the complexity of
the data, re-purposing or inventing and implementing analysis strategies that can extract the
relevant signal, planning and composing multiple steps from raw data to presentable answers,
engineering technology that can handle the data scale, the computational complexity of the data
and the demand created by many practitioners pursuing myriads of answers, accommodating
ways in which data and practices are changing, etc. [7].
Challenges are not restricted to interaction with large data or even complex data. It is important to
understand users have different skill sets and objectives, which lead to different patterns of
interaction. To ensure an inclusive community, users should be able to access technology at
different levels of intuitiveness. This calls for “learning ramps” to help everyone to progress as far
as they wish towards expert usage modes.
Data-intensive environments are often highly dynamic. It is important to understand how, in this
context, researchers build up their portfolio of data and analysis providers, and how they react as
new data and tools become available. The social behaviour and networks involved in making and
influencing choices will have an impact on what data and which tools become an established
standard [66].
9.2 Multidisciplinary – Interdisciplinary Research
The characteristics of knowledge that drive innovative problem solving “within” a discipline
actually hinder problem solving and knowledge creation “across” disciplines. In fact, knowledge
can be described as “localized’, “embedded” and “invested” [67].
Firstly, knowledge is localized around particular problems faced by a given discipline.
Secondly, knowledge is embedded in the technologies, methods, and rules of thumb used by
individuals in a given discipline.

GRDI2020 Final Roadmap Report Page 72 of 108
Thirdly, knowledge is invested in practice – invested in methods, ways of doing things, and
successes that demonstrate the value of the knowledge developed.
This specialization of “knowledge in practice” makes working across discipline boundaries and
accommodating the knowledge developed in another discipline especially difficult.
In essence, data/information/knowledge when moving between disciplines have to cross a
number of “knowledge boundaries”.
A first boundary (syntactic boundary) is constituted by the different syntax of the languages used
by the communities/disciplines in order to interact between them. One shared and stable syntax
across a given boundary could guarantee an accurate communication between two
communities/disciplines. Alternatively, a function that maps the syntax used by one
community/discipline into a semantically equivalent syntax used by the other
community/discipline is sufficient to overcome the syntactic boundary.
A second boundary (semantic boundary) can arise even if a common syntax or language is present
due to the fact that interpretations are often different. Different communities/disciplines could
interpret representations in different ways leading to serious problems caused by loss of
interpretative context which goes with the representation of information (semantic distortion). A
shared and stable ontology together with “portable” contexts or representations across a given
boundary could allow the interacting communities/disciplines to share the meaning of the
exchanged information. Particular attention must be paid to the challenges of “conveyed
meaning” and the possible interpretations by individuals; context specific aspects of creating and
transferring knowledge must also be considered.
Overcoming syntactic and semantic boundaries guarantees that a “meaningful” exchange of
data/information/knowledge between different communities/disciplines is achieved
(exchangeability). By meaningful information object exchange between two
communities/disciplines we mean that the information flow between them crosses the existing
syntactic and semantic boundaries without any semantic distortion. However, pure
exchangeability does not guarantee that the members of two different communities/disciplines
can work together. For this to occur a third boundary must be overcome.
A third boundary (pragmatic boundary) arises when a community/discipline is trying to influence
or transform the knowledge created by another community/discipline. A shared syntax and
meaning are not always sufficient to permit the cooperation between communities/disciplines. In
fact, some aspects of the information for example the quality or policies or rules that ‘discipline”
the activities of the communities/disciplines can hinder the exploitation of the information
received by them.
Compatible quality dimensions or policies established by cooperating communities/disciplines can
assist in overcoming pragmatic boundaries.
Therefore, a global scientific data infrastructure must ensure that the
“data/information/knowledge flow” between cooperating communities/disciplines can cross
syntactic and semantic boundaries without distortions. In addition, it must be able to check the
logical consistency of the policies and the quality dimensions adopted by these communities.

GRDI2020 Final Roadmap Report Page 73 of 108
9.2.1 Boundary Objects
A useful means of representing, learning about and transforming knowledge to resolve the
consequences that exist at a given boundary is known as the “boundary object” [68].
‘….both plastic enough to adapt to local needs and constraints of the several parties employing
them, yet robust to maintain a common identity across sites. They are weakly structured in
common use, and become strongly structured in individual site-use. Like a blackboard, a boundary
object “sits in the middle” of a group of actors with divergent viewpoints…”
The concept of a boundary object, developed by Star, describes information objects that are
shared and shareable across different problem solving contexts.
Here below we have adapted Star’s four categories of boundary objects (repositories,
standardized forms and methods, objects or models, and maps of boundaries) to describe the
information objects and their use by individuals in the settings present in a
multidisciplinary/interdisciplinary environment.
A boundary object should establish a shared syntax, a shared means for representing and
specifying differences, and a shared means for representing and specifying dependencies in order
to overcome a syntactic/semantic/pragmatic boundary.
At a syntactic boundary, a boundary object should establish a shared (meta) data model, a shared
data language, a shared database, a shared taxonomy, etc.
At a semantic boundary, a boundary object should provide a concrete means for all individuals to
specify and learn about their differences. Examples are a shared ontology, a shared methodology,
etc.
At a pragmatic boundary, a boundary object should facilitate a process where individuals can
jointly transform their knowledge. Examples are a shared quality framework, a shared policy
framework, etc.
Communities of practice in order to be able to work together must create a consistent set of
boundary objects at syntactic, semantic, and pragmatic boundaries.
A data infrastructure supporting cooperation of communities of practice has to efficiently
implement their set of boundary objects.
It is easy to foresee the development, in the future, of discipline specific boundary objects
(metadata models, data models, data languages, taxonomies, ontologies, quality and policy
frameworks, etc.) in order to allow the interoperation between communities of practice belonging
to the same discipline. By interoperation between two “communities of practice” we mean the
ability of their members to exchange meaningful information objects and effectively use them.
In fact, in many disciplines a major effort towards the definition of such discipline specific
boundary objects is currently underway.
A number of projects currently funded by the EC FP7 aim to develop “disciplinary data
infrastructures”. “Disciplinary data infrastructure” means a data infrastructure which implements
a consistent number of “discipline specific” boundary objects at the syntactic, semantic, and
pragmatic boundaries that allows different “communities of practice” involved a given discipline
to work effectively together.

GRDI2020 Final Roadmap Report Page 74 of 108
We, thus, envisage that one of the most important features of future “disciplinary data
infrastructures” will be the efficient implementation of a set of boundary objects defined by the
members of the disciplines being supported.
The definition of boundary objects between different scientific disciplines is more problematic.
We foresee that in order to enable multidisciplinary/interdisciplinary research new methods and
techniques must be developed which implement “a mediation function” between boundary
objects of different disciplines.
By mediation function we mean a function able to map a boundary object defined by a discipline
into a semantically equivalent boundary object of another discipline.
The future “multidisciplinary/interdisciplinary data infrastructures” must effectively support
multidisciplinary/interdisciplinary research by developing a mediation technology [see section
7.5.4].
9.3 Globalism and Virtual Proximity
Globalism refers to “any description and explanation of a world which is characterized by
networks of connections that span multi-continental distances”. The concept of globalism referred
to scientific data infrastructures means an infrastructure able to interconnect the components of a
science ecosystem (digital data libraries, digital data archives, and digital research libraries)
distributed worldwide by overcoming language, policy, methodology, social, etc. barriers.
Science is a global undertaking and scientific data are both national and global assets. There is a
need for a seamless infrastructure to facilitate collaborative (multi/inter-disciplinary) behaviour
necessary for the intellectual and practical challenges the world faces.
Therefore, the technology should enable the development of global scientific data infrastructures
which diminish geographic, temporal, social, and National barriers to discovery, access, and use of
data.
Virtual Proximity
Working together in the same time and place continues to be important, but through the next
generation of global scientific data infrastructures this can be augmented to enable collaboration
between people at different locations, at the same (synchronous) or different (asynchronous)
times. The distance dimension can be generalized to include not only geographical but also
organizational and/or disciplinary distance.
Future data infrastructures will contribute to collapsing the barrier of distance and removing
geographic location as an issue.

GRDI2020 Final Roadmap Report Page 75 of 108
10. Organizational Challenges
From the organizational point of view a research data infrastructure must support the Research
and Publication Process.
This process is composed of the following phases: (i) the original scientist produces, through
research activity, primary, raw data; (ii) this data is analysed to create secondary data, results
data; (iii) this is then evaluated, refined, to be reported as tertiary information for publication; (iv)
with the mediation of the pre-print and peer review mechanisms, this then goes into the
traditional publishing process and feeds publication archives. In alternative to phase (i), a scientist
may perform research based on data, i.e. using data to make new discoveries or to obtain further
insights [27].
Primary data is archived into dynamic digitally curated data repositories (Digital Data Libraries).
By curated data we mean that this data is associated with metadata and kept dynamic with
annotations and linking to other research.
Two roles are important: the data archivist and the data curator.
Data archivist: in general people in this role need to interact with the data generator to prepare
data for archiving (such as generating metadata which will ensure that it can be found, and can be
rendered or used in the future).
Data curator: people in this role need to keep data dynamic with annotations and linked to other
research as well as continuously reviewing the information in their care, though they may still
maintain archival responsibilities. They should also take an active role in promoting and adding
value to his holdings, and managing the value of his collection.
Static digital data is stored into Digital Data Archives for long-term preservation.
The relationship between constantly curated, evolving datasets and those in static digital archives
is one which needs to be explored, through research and accumulation of practical experience.
Publications are archived into publication archives (Digital Research Libraries).
Future research data infrastructures must guarantee interoperability between Digital Data
Libraries, Digital Data Archives and Digital Research Libraries in order to be able to support the
scientific processes.
10.1 Digital Data Libraries (Science Data Centres)
Why archive and curate primary research data? Major reasons to keep primary research data
include [69]:
Re-use of data for new research;
Retention of unique observational data which is impossible to re-create;
More data is available for research projects;
Compliance with legal requirements;
Ability to validate research results;
Use of data in teaching;

GRDI2020 Final Roadmap Report Page 76 of 108
For the public good.
Indirect benefits include the provision of primary research data to commercial entities, and use in
commercial products.
However, increasingly, the datasets are so large and the application programs are so complex, that
it is much more economical to move the end-user’s programs to the data and only communicate
questions and answers rather than moving the source data and its applications to the user’s local
system. This will require a new work style.
From the organizational point of view, this new work style has to be supported by service stations
called Science Data Centers or Digital Data Libraries [10]. Each scientific discipline should have its
own science data centre(s) and it should provide access to both the data and the applications that
analyse the data.
Each of these Digital Data Libraries curates one or more massive datasets, curates the applications
that provide access to that dataset, and supports staff that understand the data and are constantly
adding to and improving the dataset.
This new work style consists in sending questions to applications running at a Digital Data Library
and receiving answers, rather than to bulk-copy raw data from the Digital Data Library to a local
server for further analysis. Many scientists will prefer doing much of their analysis at Digital Data
Libraries because it will save them from having to manage local data and computer farms. Some
scientists may bring the small data extracts “home” for local processing, analysis and visualization
– but it will be possible to do all the analysis at the Digital Data Library.
Future Scientific Data Infrastructures should support the federation of these Digital Data Libraries.
10.2 Digital Data Archives
A Digital Data Archive is an archive, consisting of an organization of people and systems that have
accepted responsibility to preserve data and make it available for a designated scientific
community. The data being maintained has been deemed to need long-term preservation. Long-
term is long enough to be concerned with the impact of changing technologies, including support
for new media and data formats, or within a changing user community [69].
Mandatory responsibilities of a Digital Data Archive are to [69]:
Negotiate for and accept appropriate information from data generators;
Obtain sufficient control of the data provided at the level needed to ensure log-term
preservation;
Determine which communities should become the designated community and, therefore,
should be able to understand the data provided;
Ensure that the data to be preserved is independently understandable to the designated
community. In other words, the community should be able to understand the data without
needing the assistance of the experts who generated the data;

GRDI2020 Final Roadmap Report Page 77 of 108
Follow documented policies and procedures which ensure that the data is preserved
against all reasonable contingencies, and which enables the data to be disseminated as
authenticated copies of the original, or as traceable to the original;
Make the preserved data available to the designated community.
Scientific Data Infrastructures must support the following three categories of archive association
[12]:
Cooperating: Archives with potential data generators, common submission standards and
common dissemination standards, but no common finding aids.
Federated: Archives with both a local community (i.e., the original Designated Community served
by the archive) and a global community (i.e., an extended Designated Community) which has
interests in the holdings of several Data Archives and has influenced those activities to provide
access to their holdings via one or more common finding aids.
Shared Resources: Archives that have entered into agreements with other archives to share
resources, perhaps to reduce cost.
10.3 Personal Workstations
There is an emerging trend to store a personal workspace at Digital Data Libraries and deposit
answers there. This minimizes data movement and allows collaboration among a group of
scientists doing joint analysis. Longer term, personal workspaces at the Digital Data Library could
become a vehicle for data publication – posting both the scientific results of an experiment or
investigation along with the programs used to generate them in public read-only databases [10].

GRDI2020 Final Roadmap Report Page 78 of 108
11. A New Computing Paradigm: Cloud Computing
Definition
Cloud Computing is a new term for a long-held dream of computing as a utility, which has recently
emerged as a commercial reality.
In fact, five decades ago, in 1961, computing pioneer John McCarthy predicted that “computation
may someday be organized as a “public utility”. Cloud Computing is that realization, as the
paradigm facilitates the delivery of computing-on-demand much like other public utilities, such as
electricity and gas. However, Cloud Computing isn’t a new concept. Other computing paradigms –
utility computing, grid computing, and on-demand computing – precede Cloud Computing by
addressing the problems of organizing computational power as publicly available and easily
accessible resource.
By Cloud Computing it is meant a large-scale distributed computing paradigm that is driven by
economies of scale, in which a pool of abstracted, virtualized, dynamically-scalable, managed
computing power, storage, platforms, and services are delivered on demand to external customers
over the Internet [70].
The key points of this definition are:
Cloud computing is a specialized distributed computing paradigm.
It is massively scalable.
It can be encapsulated as an abstract entity that delivers different levels of services to customers outside the Cloud.
It is driven by economies of scale.
The services can be dynamically configured (via virtualization or other approaches) and delivered on demand.
Three main factors have contributed to the surge and interests in Cloud Computing:
Rapid decrease in hardware costs and increase in computer power and storage capacity and the advent of multi-core architecture and modern supercomputers consisting of hundreds of thousands of cores.
The exponentially growing data size in scientific instrumentations/simulations and Internet publishing and archiving.
The wide-spread adoption of Services Computing and Web 2.0 applications.
Key Characteristics
Here we highlight the key characteristics of the Cloud Computing paradigm [70]:
Business Model: a customer will pay the provider on a consumption basis, very much like the
utility companies charge for basic utilities and the model relies on economies of scale in order to
drive prices down for users and profit up for providers.

GRDI2020 Final Roadmap Report Page 79 of 108
Architecture: There are multiple versions of definition for Cloud architecture, we adopt the
definition given in [71] which consists of a four-layer architecture for Cloud Computing:
The fabric layer contains the raw hardware level resources, such as compute resources, storage
resources, and network resources.
The unified resource layer contains resources that have been abstracted/encapsulated (usually by
virtualization) so that they can be exposed to upper layer and end users as integrated resources,
for instance, a virtual computer/cluster, a logical file system, a database system, etc.
The platform layer adds on a collection of specialized tools, middleware and services on top of the
unified resources to provide a development and/or deployment platform. For instance, a Web
hosting environment, a scheduling service, etc.
The application layer contains the applications that would run in the Clouds.
Services: Clouds in general provide services at three different levels (IaaS, PaaS, and Saas) as
follows, although some providers can choose to expose services at more than one level.
Infrastructure as a Service (IaaS)[71] provisions hardware, software, and equipments (mostly at
the unified resource layer, but can also include part of the fabric layer) to deliver software
application environments with a resource usage-based pricing model. Infrastructure can scale up
and down dynamically based on application resource needs and different resources may be
provided via a service interface:
Data and Storage Clouds deal with reliable access to data of potentially dynamic size, weighting
resource usage with access requirements and/or quality definition [72].
Examples: Amazon S3, SQL Azure.
Compute Clouds provide computational resources, i.e. CPUs.
Examples: Amazon EC2, Zimory, Elastichosts.
Platform as a Service (PaaS)[71] offers a high-level integrated environment to build, test, and
deploy custom applications. Generally, developers will need to accept some restrictions on the
type of software they can write in exchange for built-in application scalability. PaaS typically makes
use of dedicated APIs to control the behavior of a server hosting engine which executes and
replicates the execution according to user requests.
Examples: Force.com, Google App Engine, Windows Azure (Platform)
Software as a Service (SaaS) [71] delivers special-purpose software that is remotely accessible by
consumers through the Internet with a usage-based pricing model.
Examples: Google Docs, Salesforce CRM, SAP Business by Design.
Overall, Cloud Computing is not restricted to Infrastructure/Platform/Software as a service
systems, even though it provides enhanced capabilities which act as (vertical) enablers to these
systems. As such I/P/SaaS can be considered specific “usage patterns” for cloud systems which
relate to models already approached by Grid, Web Services, etc. Cloud systems are a promising

GRDI2020 Final Roadmap Report Page 80 of 108
way to implement these models and extend them further [72].
Compute Model [70]: Cloud Computing compute model will likely look very different wrt the Grid
‘s compute model with resources in the Cloud being shared by all users at the same time (in
contrast to dedicated resources governed by a queuing system). This should allow latency
sensitive applications to operate natively on Clouds, although ensuring a good enough level of QoS
is being delivered to the end users will not be trivial, and will likely be one of the major challenges
for Cloud Computing as the Clouds grow in scale, and number of users.
Combining compute and data management [70]: The combination of the compute and data
resource management is critical as it leverages data locality in access patterns to minimize the
amount of data movement and improve end-application performance and scalability. Attempting
to address the storage and computational problems separately forces much data movement
between computational and storage resources, which will not scale to tomorrow’s peta-scale
datasets and millions of processors, and will yield significant underutilization of the raw resources.
It is important to schedule computational tasks close to the data, and to understand the costs of
moving the work as opposed to moving the data. Data-aware schedulers and dispersing data close
to processors are critical in achieving good scalability and performance.
Virtualization [70]: Virtualization has become an indispensable ingredient for almost every Cloud,
the most obvious reasons are for abstraction and encapsulation. Clouds need to run multiple (or
even up to thousands or millions of) user applications, and all the applications appear to the users
as if they were running simultaneously and could use all the available resources in the Cloud.
Virtualization provides the necessary abstraction such that the underlying fabric (raw compute,
storage, network resources) can be unified as a pool of resources and resource overlays (e.g. data
storage services, Web hosting environments) can be built on top of them. Virtualization also
enables each application to be encapsulated such that they can be configured, deployed, started,
migrated, suspended, resumed, stopped, etc., and thus provides better security, manageability,
and isolation.
Elasticity [72]: Elasticity is an essential core feature of cloud systems and circumscribes the
capability of the underlying infrastructure to adapt to changing, potentially non-functional
requirements, for example amount and size of data supported by an application, number of
concurrent users, etc. One can distinguish between horizontal and vertical scalability, whereby
horizontal scalability refers to the amount of instances to satisfy e.g. changing amount of requests,
and vertical scalability refers to the size of the instances themselves and thus implicit to the
amount of resources required to maintain the size. Cloud scalability involves both (rapid) up-and
down-scaling.
Elasticity goes one step further, tough, and does also allow the dynamic integration and extraction
of physical resources to the infrastructure.
Security [70]: Clouds mostly comprise dedicated data centers belonging to the same organization,

GRDI2020 Final Roadmap Report Page 81 of 108
and within each data center, hardware and software configurations, and supporting platforms are
in general more homogeneous as compared with those in Grid environments. Interoperability can
become a serious issue for cross-data center, cross-administration domain interactions. Currently,
the security model for Clouds seems to be relatively simpler and less secure than the security
model adopted by Grids. Cloud infrastructure typically rely on Web forms (over SSL) to create and
manage account information for end-users, and allows users to reset their passwords and receive
new passwords via Emails in an unsafe and unencrypted communication.
New Application Opportunities [73]
While we have yet to see fundamentally new types of applications enabled by Cloud Computing,
there are several important classes of existing applications which will become even more
compelling with Cloud Computing and contribute further to its momentum. Here we are
examining what kinds of applications represent particularly good opportunities and drivers for
Cloud Computing:
Mobile interactive applications: Such services will be attracted to the cloud not only because they
must be highly available, but also because these services generally rely on large datasets that are
most conveniently hosted in large datacenters.
Parallel batch processing: Although thus far we have concentrated on using Cloud Computing for
interactive SaaS, Cloud Computing presents a unique opportunity for batch-processing and
analytics jobs that analyze terabytes of data and can take hours to finish. If there is enough data
parallelism in the application, users can take advantage fo the cloud’s new “cost associativity”:
using hundreds of computers for a short time costs the same as using a few computers for a long
time.
Extension of compute-intensive desktop applications: The latest versionsof the mathematics
software packages Matlab and Mathematica are capable of using Cloud Computing to perform
expensive evaluations. Other desktop applications might similarly benefit from seamless extension
into the cloud.
“Earthbound” applications: Some applications that would otherwise be good candidates for the
cloud’s elasticity and parallelism may be thwarted by data movement costs, the fundamental
latency limits of getting into and out of the cloud, or both. Until the cost of wide-area data transfer
decrease, such applications may be less obvious candidates for the cloud.
Deployment Types [72]
Similar to P/I/SaaS, clouds may be hosted and employed in different fashions, depending on the
use case, respectively the business model of the provider.
The following deployment types can be distinguished:

GRDI2020 Final Roadmap Report Page 82 of 108
Private Clouds (example: eBay)
Public Clouds (example: Amazon, Google Apps, Windows Azure)
Hybrid Clouds (there are not many hybrid clouds in use today, though initial initiatives such as the one by IBM and Juniper already introduce base technologies for their realization)
Community Clouds: Community (Community Clouds as such are still just a vision); and
Special Purpose Clouds ( example: Google App Engine).
Obstacles and Opportunities for Cloud Computing
In [73] a ranked list of 10 obstacles to the growth of Cloud Computing is offered:
Availability of a Service: Organizations worry about whether Utility Computing services will have
adequate availability, and this makes some wary of Cloud Computing.
Data Lock-In: Software stacks have improved interoperability among platforms, but the APIs for
Cloud Computing itself are still essentially proprietary, or at least have not been the subject of
active standardization. Thus, customers cannot easily extract their data and programs from one
site to run on another. Concern about the difficult of extracting data from the cloud is preventing
some organizations from adopting Cloud Computing. Customer lock-in may be attractive to Cloud
Computing providers, but Cloud Computing users are vulnerable to price increases, to reliability
problems, or even to providers going out of business.
Security( including Data Confidentiality and Auditability):
Current cloud offerings are essentially public (rather than private) networks, exposing the system
to more attacks. There are also requirements for auditability.
There are no fundamental obstacles to making a cloud-computing environment as secure as the
vast majority of in-house IT environments and that many of the obstacles can be overcome with
well understood technologies such as encrypted storage, virtual local area networks, and network
middleboxes.
Similarly, auditability could be added as an additional layer beyond the reach of the virtualized
guest OS, providing facilities arguably more secure than those built into the applications
themselves and centralizing the software responsibilities related to confidentiality and auditability
into a single logical layer.
Data Transfer Bottlenecks: Applications continue to become more data-intensive. If we assume
applications may be “pulled apart” across the boundaries of clouds, this may complicate data
placement and transport. Cloud users and cloud providers have to think about the implications of
placement and traffic at every level of the system if they want to minimize costs.
Performance Unpredictability: One unpredictability obstacle regards the fact that multiple Virtual

GRDI2020 Final Roadmap Report Page 83 of 108
Machines can share CPUs and main memory surprisingly well in Cloud Computing, but that I/O
sharing is more problematic. There is a problem of I/O interference between virtual machines.
Another unpredictability obstacle concerns the scheduling of virtual machines for some classes of
batch processing programs, specifically for high performance computing.
Scalable Storage: There are three properties whose combination gives Cloud Computing its
appeal: short-term usage (which implies scaling down as well as up when resources are no longer
needed), no up-front cost, and infinite capacity on-demand. While it’s straightforward what this
means when applied to computation, it’s less obvious how to apply it to persistent storage. The
challenge is to create a storage system able not only to support the complexity of data structures
(e.g., schema-less blobs vs. column-oriented storage) but also to combine them with the cloud
advantages of scaling arbitrarily up and down on-demand, as well as meeting programmer
expectations in regard to resource management for scalability, data durability, and high
availability.
Bugs in Large-Scale Distributed Systems: One of the difficult challenges in Cloud Computing is
removing errors in these very large scale distributed systems. A common occurrence is that these
bugs cannot be reproduced in smaller configurations, so the debugging must occur at scale in the
production datacenters.
Scaling Quickly: Pay-as-you-go certainly applies to storage and to network bandwidth, both of
which count bytes used. Computation is slightly different, depending on the virtualization level.
There is a need for automatically scaling quickly up and down in response to load in order to save
money, but without violating service level agreements.
Reputation Fate Sharing: Reputations do not virtualize well. One customer’s bad behavior can
affect the reputation of the cloud as a whole. Another legal issue is the question of transfer of
legal liability—Cloud Computing providers would want legal liability to remain with the customer
and not be transferred to them.
Software Licensing: Current software licenses commonly restrict the computers on which the
software can run. Users pay for the software and then pay an annual maintenance fee. Hence,
many cloud computing providers originally relied on open source software in part because the
licensing model for commercial software is not a good match to Utility Computing.
Cloud Computing Interoperability – Intercloud [74]
More and more service providers are adopting the Cloud Computing paradigm for offering various
computational services on a “utility basis”. In fact, as software and expertise becomes more
available, enterprises and smaller service providers are also building Cloud Computing
implementations.
With next generation services being developed in Cloud environments, these services effectively

GRDI2020 Final Roadmap Report Page 84 of 108
become more centralized. Federated Clouds may facilitate the ability to openly discover the
service residing within them. To realize this opportunity, the Cloud community must investigate
new approaches to cross-cloud connectivity.
The concept of a Cloud operated by one service provider interoperating with a Cloud operated by
another is a powerful idea. So far that is limited to use cases where code running on one Cloud
references a service on another Cloud. There is no implicit and transparent interoperability.
Cloud Computing services are offered with a self-contained set of conventions, file formats, and
programmer interfaces. If one wants to utilize that variation of Cloud, one must create
configurations and code specific to that Cloud.
Of course from within one Cloud, explicit instructions can be issued over the Internet to another
Cloud. However there is no implicit ways that Cloud resources and services can be exported or
caused to interoperate.
Active work needs to occur to create interoperability amongst varied implementations of Clouds.
From the lower level challenges around network addressing, to multicast enablement, to virtual
machine mechanics, to the higher level interoperability desires of services, this is an area
deserving of much progress and will require the cooperation of several large industry players.
In conclusion, we can affirm that the long dreamed vision of computing as a utility is finally
emerging. The elasticity of a utility matches the need of businesses providing services directly to
customers over the Internet, as workloads can grow (and shrink) far faster than 20 years ago. It
used to take years to grow a business to several million customers – now it can happen in months.
From the Cloud provider’s view, the construction of very large datacenters at low cost sites using
commodity computing, storage, and networking uncovered the possibility of selling those
resources on a pay-as-you-go model below the costs of many medium-sized datacenters, while
making a profit by statistically multiplexing among a large group of customers.
From the Cloud user’s view, it would be as startling for a new software startup to build its own
datacenter as it would for a hardware startup to build its own fabrication line [73].
Data-Intensive Science and Cloud Computing
Current grid computing environments are primarily built to support large-scale batch
computations, where turnaround may be measured in hours or days – their primary goal is not
interactive data analysis.
While these batch systems are necessary and highly useful for the repetitive “pipeline processing”
of many large scientific collaborations, they are less useful for subsequent scientific analyses of
higher level data products, usually performed by individual scientists or small groups. Such
exploratory, interactive analyses require turnaround measured in minutes or seconds so that the
scientist can focus, pose questions and get answers within one session. The databases, analysis
tasks and visualization tasks involve hundreds of computers and terabytes of data. Of course this
interactive access will not be achieved by magic – it requires new organizations of storage,

GRDI2020 Final Roadmap Report Page 85 of 108
networking and computing, new algorithms, and new tools.
As CPU cycles become cheaper and data sets double in size every year, the main challenge for a
rapid turnaround is the location of the data relative to the available computational resources –
moving the data repeatedly to distant CPUs is becoming the bottleneck.
Interactive users measure a system by its time-to-solution: the time to go from hypothesis to
results. The early steps might move some data from a slow long-term storage resource. But the
analysis will quickly form a working set of data and applications that should be co-located in a high
performance cluster of processors, storage, and applications.
A data and application locality scheduling system can observe the workload and recognize data
and application locality. Repeated requests for the same services lead to a dynamic rearrangement
of the data: the frequently called applications will have their data “diffusing” into the grid, most
residing in local, thus fast storage, and reach a near-optimal thermal equilibrium with their
competitor processes for the resources. The process arbitrating data movement is aware of all
relevant costs, which include data movement, computing, and starting and stopping applications.
Such an adaptive system can respond rapidly to small requests, in addition to the background
batch processing applications. The system architecture requires aggressive use of data partitioning
and replication among computational nodes, extensive use of indexing, pre-computation,
computational caching, detailed monitoring of the system and immediate feedback
(computational steering) so that execution plans can be modified. It also requires resource
scheduling mechanisms that favor interactive uses.
The key to a successful system will be “provisioning”, i.e., a process that decides how many
resources to allocate to different workloads.
We think that all these requirements of data-intensive scientific applications can be efficiently, and
cost effectively addressed by the Cloud Computing paradigm.
Although data-intensive applications may not be typical applications that Cloud deal with today, as
the scales of Cloud grow, it may just be a matter of time for many Clouds.
We envision that the future Digital Data Libraries (Science Data Centers) will be based on cloud
philosophy and technology. Each scientific community of practice will have its own Cloud(s); the
federation of these Clouds will allow collaboration among.

GRDI2020 Final Roadmap Report Page 86 of 108
12. A New Programming Paradigm: MapReduce
Many data-intensive applications require hundreds of special-purpose computations that process
large amounts of raw data. Most such computations are conceptually straightforward. However,
the input data is usually large and the computations have to be distributed across hundreds or
thousands of machines in order to finish in a reasonable amount of time. The main issues for such
kind of applications are how to parallelize the computation, distribute the data, and handle
failures.
What is MapReduce?
MapReduce is a programming model and an associated implementation for processing and
generating large data sets while hiding the messy details of parallelization, fault-tolerance, data
distribution, and load balancing.
The basic idea of Map Reduce is straightforward. It consists of two programs that the user writes
called map and reduce plus a framework for executing a possibly large number of instances of
each program on a compute cluster [75].
The map program reads a set of “records” from an input file, does any desired filtering and/or transformations, and then outputs a set of records of the form (key, data). As the map program produces output records, a “split” function partitions the records into M disjoint buckets by applying a function to the key of each output record. This split function is typically a hash function, though any deterministic function will suffice. When a bucket fills, it is written to disk. The map program terminates with M output files, one for each bucket. In general, there are multiple instances of the map program running on different nodes of a compute cluster. Each map instance is given a distinct portion of the input file by the MapReduce scheduler to process. If N nodes participate in the map phase, then there are M files on disk storage at each of N nodes, for a total of N * M files; Fi,j, 1 ≤ i ≤ N, 1 ≤ j ≤ M.
The key thing to observe is that all map instances use the same hash function. Hence, all output
records with the same hash value will be in corresponding output files.
The second phase of a MapReduce job executes M instances of the reduce program, Rj, 1 ≤ j ≤
M. The input for each reduce instance Rj consists of the files Fi,j, 1 ≤ i ≤ N. Again notice that all
output records from the map phase with the same hash value will be consumed by the same
reduce instance — no matter which map instance produced them. After being collected by the
map-reduce framework, the input records to a reduce instance are grouped on their keys (by
sorting or hashing) and feed to the reduce program. Like the map program, the reduce program is
an arbitrary computation in a general-purpose language. Hence, it can do anything it wants with
its records. For example, it might compute some additional function over other data fields in the
record. Each reduce instance can write records to an output file, which forms part of the “answer”
to a MapReduce computation.

GRDI2020 Final Roadmap Report Page 87 of 108
The MapReduce Framework
The MapReduce Framework is composed of the following components/functions:
Input reader: It divides the input into appropriate size 'splits' (in practice typically 16MB to 128MB)
and the framework assigns one split to each Map function. The input reader reads data from
stable storage (typically a distributed file system) and generates key/value pairs.
Map Function: Each Map function takes a series of key/value pairs, processes each, and generates
zero or more output key/value pairs. The input and output types of the map can be (and often are)
different from each other.
Partition Function: Each Map function output is allocated to a particular reducer by the application's partition function for sharding purposes. The partition function is given the key and the number of reducers and returns the index of the desired reduce. A typical default is to hash the key and modulo the number of reducers. It is important to pick a partition function that gives an approximately uniform distribution of data per shard for load balancing purposes, otherwise the MapReduce operation can be held up waiting for slow reducers to finish. Between the map and reduce stages, the data is shuffled (parallel-sorted / exchanged between nodes) in order to move the data from the map node that produced it to the shard in which it will be reduced. The shuffle can sometimes take longer than the computation time depending on network bandwidth, CPU speeds, data produced and time taken by map and reduce computations. Compare Function: The input for each Reduce is pulled from the machine where the Map ran and
sorted using the application's comparison function.
Reduce Function: The framework calls the application's Reduce function once for each unique key
in the sorted order. The Reduce can iterate through the values that are associated with that key
and output 0 or more values.
Output Writer: It writes the output of the Reduce to stable storage, usually a distributed file
system.
An Example
Consider the problem of counting the number of occurrences of each word in a large collection of
documents [76]. The user would write code similar to the following pseudo-code:
Map (String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");

GRDI2020 Final Roadmap Report Page 88 of 108
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
The map function emits each word plus an associated count of occurrences (just `1' in this simple
example). The reduce function sums together all counts emitted for a particular word.
Advantage of MapReduce
The advantage of MapReduce is that it allows for distributed processing of the map and reduction
operations. Provided each mapping operation is independent of the others, all maps can be
performed in parallel — though in practice it is limited by the data source and/or the number of
CPUs near that data. Similarly, a set of 'reducers' can perform the reduction phase - all that is
required is that all outputs of the map operation which share the same key are presented to the
same reducer, at the same time. While this process can often appear inefficient compared to
algorithms that are more sequential, MapReduce can be applied to significantly larger datasets
than "commodity" servers can handle — a large server cluster can use MapReduce to sort a
petabyte of data in only a few hours. The parallelism also offers some possibility of recovering
from partial failure of servers or storage during the operation: if one mapper or reducer fails, the
work can be rescheduled — assuming the input data is still available.
In fact, MapReduce achieves an excellent fault-tolerance by parceling out a number of operations on the set of data to each node in the network. Each node is expected to report back periodically with completed work and status updates. If a node falls silent for longer than that interval, the master node records the node as dead and sends out the node's assigned work to other nodes. Individual operations use atomic operations for naming file outputs as a check to ensure that there are not parallel conflicting threads running. When files are renamed, it is possible to also copy them to another name in addition to the name of the task. The reduce operations operate much the same way. Because of their inferior properties with regard to parallel operations, the master node attempts to schedule reduce operations on the same node, or in the same rack as the node holding the data being operated on. This property is desirable as it conserves bandwidth across the backbone network of the datacenter.
Criticisms
The database research community has expressed some concerns regarding this new computing
paradigm [75]:
MapReduce is a step backwards in database access.

GRDI2020 Final Roadmap Report Page 89 of 108
The database community has learned three important lessons: (i) schemas are good, (ii)
separation of the schema from the application is good, and (iii) high-level access languages
are good. MapReduce has learned none of these lessons.
MapReduce is a poor implementation.
All modern DBMSs use hash and B-tree indexes to accelerate access to data. In addition,
there is a query optimizer to decide whether to use an index or perform a brute-force
sequential search.
MapReduce has no indexes and therefore has only brute force as a processing option.
MapReduce is not novel.
The MapReduce community seems to feel that they have discovered an entirely new
paradigm for processing large data sets. In actuality, the techniques employed by
MapReduce are more than 20 years old.
MapReduce is missing features. All of the following features are routinely provided by
modern DBMSs, and all are missing from MapReduce: Bulk loader, Indexing, Updates,
Transactions, Integrity constraints, Referential integrity, Views.
MapReduce is incompatibile with the DBMS tools. A modern SQL DBMS has available all of
the following classes of tools: Report writers, Business intelligence tools, Data mining tools,
Replication tools, Database design tools. MapReduce cannot use these tools and has none
of its own.
The advocates of the MapReduce paradigm reject these views. They assert that DeWitt and Stonebraker's entire analysis is groundless as MapReduce was never designed nor intended to be used as a database. MapReduce is not a data storage or management system — it’s an algorithmic technique for the distributed processing of large amounts of data. However, it is worthwhile to note that some database researchers are beginning to explore using
the MapReduce framework as the basis for building scalable database systems. The Pig project at
Yahoo! Research is one such effort.
Factors of success
The MapReduce programming model has been successfully used for many different purposes. This
success can be attributed to several reasons. First, the model is easy to use, even for
programmers without experience with parallel and distributed systems, since it hides the details of
parallelization, fault-tolerance, locality optimization, and load balancing. Second, a large variety of
problems are easily expressible as MapReduce computations. For example, MapReduce is used
for the generation of data for Google's production web search service, for sorting, for data mining,
for machine learning, and many other systems. Third, several implementations of MapReduce
have been developed that scale to large clusters of machines comprising thousands of machines.
These implementations make efficient use of these machine resources and therefore are suitable
for use on many of the large computational problems encountered in data-intensive applications.

GRDI2020 Final Roadmap Report Page 90 of 108
13. Policy Challenges
The need for using semantic policies in science ecosystem environments is widely recognized.
It is important to adopt a broad notion of policy, encompassing not only access control policies,
but also trust, quality of service, and others. In addition, all these different kinds of policies should
eventually be integrated into a single coherent framework, so that (i) this policy framework can be
implemented and maintained by a research data infrastructure, and (ii) the policies themselves
can be harmonized and synchronized [77].
Policy Management
The interactions between the different components of a science ecosystem should be governed by
formal semantic policies which enhance their authorization processes allowing to regulate access
and use of data and services (data policies), and to estimate trust based on parties’ properties
(trust management policies).
Policies are means to dynamically regulate the behavior of system components without changing
code and without requiring the consent or cooperation of the components being governed [78].
Policies, which constrain the behavior of system components, are becoming an increasingly
popular approach to dynamic adjustability of applications in academia and industry.
Policies are pervasive in distributed and networked environments, for example in web and Grid
applications. They play crucial roles in enhancing security, privacy, and usability of distributed
services, and indeed may determine the success (or failure) of a service. However, users will not
be able to benefit from these protection mechanisms unless they understand and are able to
personalize policies applied in such contexts.
Many are the benefits of policy-based approaches; they include reusability, efficiency,
extensibility, context-sensitivity, verifiability, support for both simple and sophisticated
components, and reasoning about component behavior. In particular, policy-based network
management has been the subject of extensive research over the last decade.
Policy based Interaction [77]
Policies allow for security, privacy, authorization, obligation and etc. descriptions in a machine
understandable way. More specifically, service or data providers may use security policies to
control access to resources by describing the conditions a requester must fulfill (e.g. a requester to
resource A must belong to institution B and prove it by means of a credential). At the same time,
service or data consumers may regulate the data they are willing to disclose by protecting it with
privacy policies. Given two sets of policies, an engine may check whether they are compatible, that
is, whether they match. The complexity of this process varies depending on the sensitivity of
policies (and the expressivity of the policies). If all policies are public at both sides, provider and
requester may initially already provide the relevant policies together with the request and the
evaluation process can be performed in one-step evaluation by the provider policy engine and
return a final decision. Otherwise, if policies may be private, this process may consist of several

GRDI2020 Final Roadmap Report Page 91 of 108
steps negotiation in which new policies and credential are disclosed at each step, therefore,
advancing after each iteration towards a common agreement.
Policy Specification [77]
Multiple approaches for policy specification have been proposed that range from formal policy
languages that can be processed and interpreted easily and directly by a computer, to rule-based
policy notation using if-then-else format, and to the representation of policies as entries in a table
consisting of multiple attributes. There are also ongoing standardization efforts toward common
policy information models and frameworks.
Policy specification tools like the KAoS Policy Administrator Tool [79] and the PeerTrust Policy
Editor provide an easy to use application to help policy writers. This is important because the
policies will be enforced automatically and therefore errors in their specification or
implementation will allow outsiders to gain inappropriate access to resources, possibly inflicting
huge and costly damages. In general, the use of ontologies on policy specification reduces the
burden on administrators, helps them with their maintenance and decreases the number of
errors.
Policy language provides a framework for specifying both authorization policies and obligation
policies. A policy in KAoS may be a positive (respectively negative) authorization, i.e., constraints
that permit (respectively forbid) the execution of an action, or a positive (respectively negative)
obligation, i.e., constraints that require an action to be executed. A policy is then represented as
an instance of the appropriate policy type, associating values to its properties, and giving
restrictions on such properties.
In Rei [80] policies are described in terms of deontic concepts: permissions, prohibitions,
obligations and dispensations, equivalently to the positive/negative authorizations and
positive/negative obligations of KAoS.
Rule-based languages are commonly regarded as the best approach to formalizing policies due to
its flexibility, formal semantics and closeness to the way people think.
Policy Constraints. A constraint can optionally be defined as part of a policy specification to restrict
the applicability of the policy. It is defined as a predicate referring to global attributes such as time
(temporal constraints) or action parameters (parameter value constraints). Preconditions could
define the resources which must be available for a management policy to be accomplished.
Propagation to Sub-domains. Policies apply to sets of objects within domains, but domains may
contain sub-domains. To avoid having to re-specify policy for each sub-domain, policy applying to
a parent domain, should propagate to member sub-domains of the parent. A sub-domain is said to
inherit, the policy applying to parent domains.
Policies can be specified in many different ways and multiple approaches have been proposed in
different application domains. There are, however, some general requirements that any policy
representation should satisfy regardless of its field of applicability:

GRDI2020 Final Roadmap Report Page 92 of 108
Expressiveness to handle the wide range of policy requirements arising in the system being managed;
Simplicity to ease the policy definition tasks for administrators with different degrees of expertise;
Enforceability to ensure a mapping of policy specifications into implementable policies for various platforms;
Scalability to ensure adequate performance; and
Analyzability to allow reasoning about policies.
The existing policy languages differ in expressivity, kind of reasoning required, features and
implementation provided, etc. However, specifying policies, getting a policy right and maintaining
a large number of them is hard. Fortunately, ontologies and policy reasoning may help users and
administrators on specification, conflict detection and resolution of such policies.
An ontology-based description of the policy enables the system to use concepts to describe the
environments and the entities being controlled, thus simplifying their description and facilitating
the analysis and the careful reasoning over them. Several capabilities can benefit by this powerful
feature, such as the policy conflict detection and harmonization.
In addition, ontology-based approaches simplify the access to policy information, with the
possibility of dynamically calculating relations between policies and environments, entities or
other policies based on ontology relations rather than fixing them in advance.
Ontologies can also simplify the sharing of policy knowledge thus increasing the possibility for
entities to negotiate policies and to agree on a common set of policies.
Policy Classification
Authorization Policy defines what activities a subject is permitted to do in terms of the operations
it is authorized to perform on a target object. In general an authorization policy may be positive
(permitting) or negative (prohibiting) i.e. not permitted = prohibited.
Activity Based Authorization: The simplest policies are expressed purely in terms of subject, target
and activity.
State Based Authorization policies include a predicate based on object state (i.e. a value of an
object attribute) in the policy specification.
Obligation policy defines what activities a subject must (or must not) do. The underlying
assumption is that all subjects are well behaved, and attempt to carry out obligation policies with
no freedom of choice. Obligation policies are subject based in that the subject is responsible for
interpreting the policy and performing the activity specified.
Activity based Obligations: Simple obligation policies can also be expressed in terms of subject,
target and activity, but may also specify an event which triggers the activity.
State Based Obligation: An obligation may also be specified in terms of a predicate on object state.
Conflict Detection and Resolution [77]

GRDI2020 Final Roadmap Report Page 93 of 108
A conflict may occur between any two policies if one policy prevents the activities of another
policy from being performed or if the policies interfere in some way that may result in the
managed objects being put into unwanted states. As the activity of a policy can specify a set of
actions, there may also be conflicts between these actions within a single policy.
Policy languages allow for advanced algorithms for conflict detection and its resolution. Conflicts
may arise between policies either at specification time or runtime. A typical example of a conflict
is when several policies apply to a request and one allows access while another denies it (positive
vs negative authorization). Description Logic based languages may use subsumption reasoning to
detect conflicts by checking if two policies are instances of conflicting types and whether the
action classes, that the policies control, are not disjoint. Both KAoS and Rei handle such conflicts
within their frameworks and both provide constructs for specifying priorities between policies,
hence the most important ones override the less important ones.
KAoS also provides a conflict resolution technique called “policy harmonization”. If a conflict is
detected the policy with lower priority is modified by refining it with the minimum degree
necessary to remove the conflict.
Policy Management
The adoption of a policy based-approach for controlling a system requires an appropriate policy
representation and the design and development of a policy management framework.
The scope of policy management is increasingly going beyond these traditional applications in
significant ways. New challenges for policy management include:
Sources and methods protection, digital rights management, information filtering and transformation, capability-based access;
Active networks, agile computing, pervasive and mobile systems;
Organizational modeling, coalition formation, formalizing cross-organizational agreements;
Trust models, trust management, information pedigrees;
Effective human-machine interaction: interruption/notification management, presence management, adjustable autonomy, teamwork facilitation, safety; and
Intelligent retrieval of all policies relevant to some situation.
Graphical tools should be provided for editing, updating, removing, and browsing policies as well
as de-conflicting newly defined policies.
Policy Enforcement [77]
Cooperative policy enforcement involves both machine-to-machine and human-machine aspects.
The former is handled by negotiation mechanisms: published policies, provisional actions, hints,
and other metalevel information can be interpreted by the client to identify what information is
needed to access a resource and how to obtain that information.

GRDI2020 Final Roadmap Report Page 94 of 108
It is recommended a cooperative policy enforcement, where negative responses are enriched with
suggestions and other explanations wherever such information does not violate confidentiality.
For these reasons greater user awareness and control on policies is one of our main objectives,
making policies easier to understand and formulate to the common user in the following ways: (i)
adopt a rule-based policy specification language, (ii) make the policy specification language more
friendly, and (iii) develop advanced explanation mechanisms.
Trust Management [77]
Currently, two major approaches for managing trust exist: policy-based and reputation-based trust
management. The two approaches have been developed within the context of different
environments. On the one hand, policy-based trust relies on “strong security” mechanisms such as
signed certificates and trusted certification authorities in order to regulate access of users to
services. On the other hand, reputation-based trust relies on a “soft computational” approach to
the problem of trust. In this case, trust is typically computed from local experiences together with
the feedback given by other entities in the network. The reputation-based approach is more
suitable for environments such as Peer-to-Peer, Semantic Web and Science Ecosystems, where the
existence of certifying authorities can not always be assumed but where a large pool of individual
user ratings is often available.
Another approach -very common in today’s applications- is based on forcing users to commit to
contracts or copyrights by having users click an “accept” button on a pop-up window.
During the past few years, some of the most innovative ideas on security policies arose in the area
of automated trust negotiation. That branch of research considers peers that are able to
automatically negotiate credentials according to their own declarative, rule-based policies. Rules
specify for each resource or credential request which properties should be satisfied by the
subjects and objects involved. At each negotiation step, the next credential request is formulated
essentially by reasoning with the policy, e.g. by inferring implications or computing abductions.
Applying Policies on Science Ecosystems
The need for using semantic policies in science ecosystem environments is widely recognized.
It is important to adopt a broad notion of policy, encompassing not only access control policies,
but also trust, quality of service, and others. In addition, all these different kinds of policies should
eventually be integrated into a single coherent framework, so that (i) this policy framework can be
implemented and maintained by a research data infrastructure, and (ii) the policies themselves
can be harmonized and synchronized.
In the general view depicted above, policies may also establish that some events must be logged,
that user profiles must be updated, and that when an operation fails, the user should be told how
to obtain missing permissions. In other words, policies may specify actions whose execution may
be interleaved with the decision process. Such policies are called provisional policies. In this
context, policies act both as decision support systems and as declarative behavior specifications.

GRDI2020 Final Roadmap Report Page 95 of 108
14. Open Science – Open Data
The Concept
There is an emerging consensus among the members of the academic research community that
“e-science” practices should be congruent with “open science”. The essence of the e-science is
“global collaboration” in key areas of science and the next generation of data infrastructures must
enable it. Global scientific collaboration takes many forms, but from the various initiatives around
the world a consensus is emerging that collaboration should aim to be “open” or at least should
be a substantial measure of “open access” to data and information underlying published research,
and to communication tools [81].
The concept of Open Data is not new; but although the term is currently in frequent use, there are
no commonly agreed definitions (unlike, for example, Open Access where several formal
declarations have been made and signed).
The Organization for Economic Co-operation and Development, OECD, an international
organization helping governments tackle the economic, social, and governance challenges of a
globalized economy has produced a Report “Recommendations of the Council concerning Access
to Research Data from Public Funding” [82] where the following definition of openness is given:
“Openness means access on equal terms for the international research community at the lowest
possible cost, preferably at no more than the marginal cost of dissemination. Open access to
research data from public funding should be easy, user-friendly and preferable Internet-based”
Open Data is focused on data from scientific research. Problems often arise because these are commercially valuable or can be aggregated into works of value. Access to, or re-use of, the data are controlled by organisations, both public and private. Control may be through access restrictions, licenses, copyright, patents and charges for access or re-use. Open Data has a similar ethos to a number of other "Open" movements and communities such as open source and open access. However these are not logically linked and many combinations of practice are found. The practice and ideology itself is well established but the term "open data" itself is recent. An essential prerequisite for successful adoption of Open Data principle is the willingness of
scientific communities to share data. Researchers acknowledge that data sharing increases the
impact, utility, and profile of their work. Conversely, research is highly competitive, and
publications depend on individual ability to produce novel data, which can be a disincentive for
collaboration.
There are also major ethical considerations in sharing data between researchers and between
countries and in making data available for open access. Acceptance of the open data principle
entails a cultural shift in the science regarding the importance of data sharing and mining.
Much data is made available through scholarly publication, which now attracts intense debate under "Open Access". The Budapest Open Access Initiative (2001) coined this term:

GRDI2020 Final Roadmap Report Page 96 of 108
By "open access" to this literature, we mean its free availability on the public internet, permitting any users to read, download, copy, distribute, print, search, or link to the full texts of these articles, crawl them for indexing, pass them as data to software, or use them for any other lawful purpose, without financial, legal, or technical barriers other than those inseparable from gaining access to the internet itself. The only constraint on reproduction and distribution, and the only role for copyright in this domain, should be to give authors control over the integrity of their work and the right to be properly acknowledged and cited.
The logic of the declaration permits re-use of the data although the term "literature" has connotations of human-readable text and can imply a scholarly publication process. In Open Access discourse the term "full-text" is often used which does not emphasize the data contained within or accompanying the publication. While “open data” will enhance and accelerate scientific advance, there is also a need for “open science”—where not only data but also analyses and methods are preserved, providing better transparency and reproducibility of results. The extent of openness is an important issue that must be regulated by rules and norms governing
the disclosure of data and information about research methods and results [81]:
How fully and quickly is information about research procedures and data released?
How completely is it documented and annotated so as to be not only accessible but also useable by those outside the immediate research group?
On what terms and with what delays are external researchers able to access materials, data and project results?
Are findings held back, rather than being disclosed in order to first obtain IPRs on a scientific project’s research results, and if so how long is it usual for publication to be delayed?
The Open Data Principle has three dimensions: policy, legal, and technological. Technology must
render physical and semantic barriers irrelevant, while policies and laws must allow to overcome
legal jurisdictional boundaries
Policy Dimension There are several political reasons advocating for open access to data:
“Data belong to human race”. Typical examples are genomes, environmental data, medical science data, etc.
Public money was used to fund the work and so it should be universally available.
In scientific research, the rate of discovery is accelerated by better access to data.
Facts cannot legally be copyrighted.
Sponsors of research do not get full value unless the resulting data are freely available

GRDI2020 Final Roadmap Report Page 97 of 108
There are also some important economic and social reasons in the pursuit of knowledge, and making explicit the supportive role played by norms that tend to reinforce cooperative behaviors among scientists. In brief, rapid disclosures abet:
rapid validation of findings,
reduces excess duplication of research effort,
enlarge the domain of complementarities and
yield beneficial “spill-overs”among research programs. Advocates of open data argue that access restrictions are against the communal good and that these data should be made available without restriction or fee. In addition, it is important that the data are re-usable without requiring further permission, though the types of re-use (such as the creation of derivative works) may be controlled by license. As the term Open Data is relatively new it is difficult to collect arguments against it. Unlike Open Access where groups of publishers have stated their concerns, Open Data is normally challenged by individual institutions. Their arguments may include:
this is a non-profit organisation and the revenue is necessary to support other activities (e.g. learned society publishing supports the society)
the government gives specific legitimacy for certain organizations to recover costs (NIST in US, Ordnance Survey in UK)
government funding may not be used to duplicate or challenge the activities of the private sector (e.g. PubChem)
It may be noted that it is the difficulty of monitoring research effort that make it necessary for
both the open science system and the intellectual property regime to tie researchers’ rewards in
one way or another to priority in the production of observable “research outputs” that can be
transmitted to “validity tests and valorization” – whether directly by peer assessment, or indirectly
through their application in the markets for goods and services.
An acceptable compromise between open and closed data could be the introduction of a data-
disclosure norm where a limited, in time, embargo period is defined. During this period of time
the novel data produced by a researcher remains closed thus allowing him/her to produce
publications based on this data without running the risk of fraudulent publications. After the
embargo period has elapsed the data become open (publicly available). The length of the embargo
period must be agreed among the scientific communities and could be discipline dependent.
The issues around consent and ownership are yet more complex within networked science
environments.
Indeed, we appear to be in the midst of a massive collision between unprecedented increases in
data production and availability and the privacy rights of human beings worldwide.
Common frameworks and defined principles first need to be established if an Open Science Data
space is to be established, particularly when it comes to the ethical and privacy issues.
The key strategy in ensuring that international policies requiring “full and open exchange of data”

GRDI2020 Final Roadmap Report Page 98 of 108
are effectively acted on in practice lies in the development of a coherent policy and legal
framework at a national level. The national framework must support the international principles
for data access and sharing but also be clear and practical enough for researchers to follow at a
research project level [83].
The development of a national framework for data management based on principles promoting
data access and sharing (such as the OECD recommendations) would help to incorporate
international policy statements and protocols such as the Antarctic Treaty and the GEOSS
Principles into domestic law.
Legal Dimension
It is generally held that factual data cannot be copyrighted. However publishers frequently add their copyright statements (often forbidding re-use) to scientific data accompanying (supporting, supplementing) a publication. It is also usually unclear whether the factual data embedded in full text are part of the copyright. While the human abstraction of facts from paper publications is normally accepted as legal there is often an implied restriction on the machine extraction by robots. Some Open Access publishers do not require the authors to assign copyright and the data associated with these publications can normally be regarded as Open Data. Some publishers have Open Access strategies where the publisher requires assignment of the copyright and where it is unclear that the data in publications can be truly regarded as Open Data. The ALPSP and STM publishers have issued a statement about the desirability of making data freely available : “Publishers recognise that in many disciplines data itself, in various forms, is now a key output of research. Data searching and mining tools permit increasingly sophisticated use of raw data. Of course, journal articles provide one ‘view’ of the significance and interpretation of that data – and conference presentations and informal exchanges may provide other ‘views’ – but data itself is an increasingly important community resource. Science is best advanced by allowing as many scientists as possible to have access to as much prior data as possible; this avoids costly repetition of work, and allows creative new integration and reworking of existing data.” And “We believe that, as a general principle, data sets, the raw data outputs of research, and sets or sub-sets of that data which are submitted with a paper to a journal, should wherever possible be made freely accessible to other scholars. We believe that the best practice for scholarly journal publishers is to separate supporting data from the article itself, and not to require any transfer of or ownership in such data or data sets as a condition of publication of the article in question.” Even though this statement was without any effect on the open availability of primary data related to publications in journals of the ALPSP and STM members. Data tables provided by the authors as supplement with a paper are still available to subscribers only.
Technological Dimension

GRDI2020 Final Roadmap Report Page 99 of 108
The importance of building scientific data infrastructures in which research findings can be readily
made available to and used by other researchers has long been recognized in international
scientific collaborations. However, creating and maintaining conditions of openness might mean
not simply putting data on-line but making them sufficiently robust and well-documented to be
widely utilized.
There are two main options in making data openly accessible and sharable:
Open access to data/metadata with re-use restrictions
Open access to data/metadata without re-use restrictions
In order to implement the Open access to data/metadata with re-use restrictions policy the data
producer/provider must make them understandable to the researchers belonging to the same or
different scientific disciplines.
Therefore, the data must be endowed with some auxiliary information which contribute to enrich
its semantics. Such auxiliary information could include contextual information as well as open
access community ontologies, terminologies and taxonomies.
In addition, the adoption of annotation practices based on standardized terminologies will greatly
increase the understandability of the published data.
In order to implement the Open access to data/metadata without re-use restrictions policy the
data producer/provider must make them not only understandable but also usable.
Therefore, the data must be endowed with some auxiliary information which contribute to make
them usable. Such auxiliary information could include provenance, quality, and uncertainty
information.
The challenge for the next generation of global scientific data infrastructures is to support
automated agents and search engines able to crawl the science data space in order to discover,
mine, relate and interpret data from datasets as well as the literature.
We envision that the future research data infrastructures will constitute infrastructures for open
scientific research.
The principles of open science data and open science can be widely accepted only if realized
within an Integrated Science Policy Framework to be implemented and enforced by global
research data infrastructures.

GRDI2020 Final Roadmap Report Page 100 of 108
15. Recommendations
1. Future Scientific Data Infrastructures must enable Science Ecosystems.
Several discipline-specific Digital Data Libraries, Digital Data Archives and Digital Research
Libraries are under development or will be developed in the near future. These systems
must be able to interwork and constitute disciplinary and/or multidisciplinary ecosystems.
The next generation of global research data infrastructures must enable the creation of
efficient and effective Science Ecosystems.
2. Science organizational aspects should be taken in due consideration when designing
global research data infrastructures as well as potential tensions which could be faced or
provoked by them.
A viable vision of research data infrastructure must take into account social and
organizational dimensions that accompany the collective building of any complex and
extensive resource. A robust Global Research Data Infrastructure must consist not only of a
technical infrastructure but also a set of organizational practices and social forms that work
together to support the full range of individual and collaborative scientific work across
diverse geographic locations. A data infrastructure will fail or quickly become encumbered
if any one of these critical aspects is ignored.
New research data infrastructures are encountering and often provoking a series of
tensions. Tensions should be thought of as both barriers and resources to infrastructural
development, and should be engaged constructively.
3. Global Research Data Infrastructures must be based on scientifically sound foundations.
It is widely recognized that current database technology is not adequate to support data-
intensive multidisciplinary research.
Existing research data infrastructures suffer from the following main limitations:
not based on scientifically sound foundations
application-specific software of limited long term value coupled with the absence
of a consistent computer science perspective
discipline-specific
Science re-builds rather than re-uses software and has not yet come up with a set of
common requirements.
It is time to develop the theoretical foundations of research data infrastructures. They will
allow the development of generic data infrastructure technology and incorporate it into
industrial-strength systems.
4. Formal models and query languages for data, metadata, provenance, context,
uncertainty and quality must be defined and implemented.

GRDI2020 Final Roadmap Report Page 101 of 108
Radically new approaches to scientific data modelling are required. In fact, the data models
(relational model) developed by the database research community are appropriate for
business/commercial data applications. Scientific data has completely different
characteristics from business/commercial data and therefore current database technology
is inadequate to handle it efficiently and effectively.
Data models and query languages that more closely match the data representation needs
of the several scientific disciplines, describe discipline-specific aspects (metadata models),
represent and query data provenance information, represent and query data contextual
information, represent and manage data uncertainty, and represent and query data quality
information are necessary.
Formally defined data models and data languages will allow the development of
automatized data tools and services (i.e., mediation software, curation, etc.) as well as
generic software.
5. New advanced data tools (data analysis, massive data mining, data visualization) must be
developed.
Current data management tools as well as data tools are completely inadequate for most
science disciplines. It is essential to build better tools and services in order to make
scientists more productive; tools helping them to capture, curate, analyze and visualize
their data; in essence tools and services that support the whole research cycle.
Advanced tools and services are needed so as to enable scientists to follow new paths, try
new techniques, build new models and test them in new ways that facilitate innovative
multidisciplinary/interdisciplinary activities.
6. New advanced infrastructural services (data discovery, tool discovery, data integration,
data/service transportation, workflow management, ontology/taxonomy management,
policy management, etc) must be developed.
The ultimate aim of a Global Research Data Infrastructure is to enable global collaboration
in key areas of science. Therefore, the infrastructural services must achieve the conditions
needed to facilitate effective collaboration among geographically and institutionally
separated communities of research. To this end a Global Research Data Infrastructure must
provide advanced support services that make the components of a science ecosystem
interoperable and their holdings discoverable, aggregable and usable.
7. Future Research Data Infrastructures must support open linked data spaces.
A research data infrastructure must lower the barrier to publishing and accessing data
leading, therefore, to the creation of open scientific data spaces by connecting data sets
from diverse domains, disciplines, regions and nations. Researchers should be able to
navigate along links into related data sets.

GRDI2020 Final Roadmap Report Page 102 of 108
8. Future Research Data Infrastructures must support interoperation between science data
and literature.
In future all scientific literature and data will be on-line. The scientific data must be unified
with all the literature to create a world in which the data and the literature interoperate
with each other. Such a capability will increase the “information velocity” of the sciences
and will improve the scientific productivity of researchers. Future research data
infrastructures must make this happen by supporting the interoperation between digital
data libraries and digital research libraries.
9. The principles of open science and open data in order to be widely accepted must be
realized within an Integrated Science Policy Framework to be implemented and enforced
by global research data infrastructures.
There is an emerging consensus among the members of the academic research community
that “e-science” practices should be congruent with “open science”. The open science
principle entails not only open access to data but also to scientific analyses, methods, etc.
This principle has not only a technological dimension but also policy and legal dimensions.
Policies and laws must deal with legal jurisdictional boundaries and they must be
integrated into a shared Science Policy Framework.
10. A new international research community must be created.
The building of scientifically sound research data infrastructures can only be achieved if
supported by an active new international research community capable of tackling all the
scientific and technological challenges that such an enterprise implies. This community
would embrace two main components:
researchers who use data-intensive methods and tools (biologists, astronomers,
etc.), and
researchers who create or enable these models and methods (computer scientists,
mathematicians, engineers, etc.).
So far, these two components have operated in isolation and have only come together
sporadically. We firmly believe that the development of the new Data-Intensive
Multidisciplinary Science must spring from a synergetic action between these two
components. We firmly believe that without the creation and active involvement of such a
research community it is illusory to think about the development of the Data-Intensive
Multidisciplinary Science.
11. New Professional Profiles must be created.
In order to be able to exploit the huge volumes of data available and the expected new
data and network technologies, new professional profiles must be created: data scientist,

GRDI2020 Final Roadmap Report Page 103 of 108
data-intensive distributed computation engineer, data curator, data archivist, and data
librarians.
These professionals must be capable of operating in the fast moving world of network and
data technologies. Education and training activities to enable them to use and manage the
data and the infrastructures must be defined and put in action.

GRDI2020 Final Roadmap Report Page 104 of 108
16. References
[1] G. Bell, T. Hey, and A. Szalay, “Beyond the Data Deluge”, Science, 323, 1297-1298, March
2009
[2] T. Hey, S. Tansley and K. Tolle (Eds.), The Fourth Paradigm: Data Intensive Scientific
Discovery. Redmond, WA: Microsoft, 2009.
[3] C. Anderson, “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete”,
Wired Magazine: 16.07 . Retrieved from
http://www.wired.com/science/discoveries/magazine/16-07/pb_theory
june 2011
[4] P. Edwards, S. Jackson, G. Bowker and C. Knobel, Understanding Infrastructure: Dynamics,
Tensions, and Design, Final Report of the Workshop on History & Theory of Infrastructure:
Lessons for New Scientific Cyberinfrastructures, Jan. 2007. Retrieved from
http://hdl.handle.net/2027.42/49353
June 2011
[5] T. Jewett, R. Kling, “The dynamics of computerization in a social science research team: a case
study of infrastructure, strategies, and skills”, Social Science Computer Review, 9 (2), 246-275,
1991.
[6] S. Star, and K. Ruhleder, “Steps toward an ecology of infrastructure: Design and access for
large information spaces”, Information Systems Research, 7 (1), 111-134, 1996.
[7] D. De Route and M. Atkinson, “Realizing the Power of Data-Intensive Research”
[8] I. Gordon, P. Greenfiels, A. Szalay and R. Williams, “Data Intensive Computing in the 21st
Century”, Computer, 41 (4), 30-32, April 2008.
[9] L. Bannon, and S. Bodker, “Constructing Common Information Spaces” in: J. Hughes, T.
Rodden, W. Prinz and K. Schmidt (eds.), ECSCW’97: Proceedings of the Fifth European
Conference on Computer-Supported Cooperative Work, Kluwer Academic Publishers, 1997.
[10] J. Gray, D. Liu, A. Szalay, D. DeWitt and G. Heber, “Scientific Data management in the Coming
Decade”, SIGMOD Record, 34 (4), 35-41, Dec. 2005
[11] National Science Board, Long-Lived Digital Data Collections: Enabling Research and Education
in the 21st Century, National Science Foundation, 2005
Retrieved from
http://www.nsf.gov/pubs/2005/nsb0540/
June 2011
[12] What is Data Archiving? [Definition]
Retrieved from
http://searchdatabackup.techtarget.com/definition/data-archiving
June 2011
[13] P. Graham, The Digital Research Library: Tasks and Commitments, 1995.
Retrieved from
www.csdl.tamu.edu/DL95/papers/graham/graham.html

GRDI2020 Final Roadmap Report Page 105 of 108
June 2011
[14] NSF’ Cyberinfrastructure Vision for 21st Century Discovery, NSF Cyberinfrastructure Council,
March 2007.
Retrieved from
http://www.nsf.gov/pubs/2007/nsf0728/index.jsp
June 2011
[15] “Jim Gray on eScience: A Transformed Scientific Method”, in: The Fourth Paradigm: Data
Intensive Scientific Discover [2], xix-xxxiii.
[16] N. Paskin ,“Digital Object Identifiers for scientific data”, Data Science Journal, 4, 12-20,
March 2005
[17] “Moving Large Volumes of Data Using Transportable Modules” in Oracle® Warehouse Builder
Data Modeling, ETL, and Data Quality Guide” 11g Release 2 (11.2)
Retrieved from
http://download.oracle.com/docs/cd/E14072_01/owb.112/e10935/trans_mod.htm
June 2011
[18] S. Kahn, “On the Future of Genomic Data”, Science, 331 (6018), 728-729.
[19] G. Adomavicius, J. Bockstedt, A. Gupta and R. Kauffman, “Understanding Patterns of
Technology Evolution: An Ecosystem Perspective”, in: System Sciences, 2006. HICSS '06.
Proceedings of the 39th Annual Hawaii International Conference on , vol.8, pp. 189a, 04-07 Jan. 2006.
[20] M. Stonebraker, J. Becla, D. DeWitt, K. Lim, D. Maier, O. Ratzesberger, S. Zdonik,
“Requirements for Science Data Bases and SciDB” in CIDR Perspectives, 2009
[21] R. Ikeda, J. Widom, “Panda: A System for Provenance and Data” in IEEE Data Engineering
Bulletin, Special Issue on Data provenance, 33(3), September 2010
[22] “Reference Model for an Open Archival Information System (OAIS)” CCSDS 650.0-B-1, BLUE
BOOK, 2002
[23] T. Strang, C. Linnhoff-Popien, “A Context Modeling Survey” in Workshop on Advanced Context
Modelling, Reasoning and Management associated with the Sixth International Conference on
Ubiquitous Computing (UbiComp 2004), Nottingham/England
[24] A. Carpi, A. Egger, “Data: Uncertainty, Error, and Confidence”
[25] C. Batini, M. Scannapieco, “Data Quality: Concepts, Methodologies and Techniques” Springer
[26] V. Van den Eynden, L. Corti, M. Woollard, L. Bishop and L. Horton, Managing and Sharing
Data: Best Practices for Researchers. UK Data Archive, University of Essex, May 2011
[27] P. Lord, A. Macdonald, “Data Curation for e-Science in the UK”, Report, 2004
[28] Microsoft Draft Roadmap “Towards 2020 Science”
Retrieved from: http://www. Jyu.edu.cn
[29] C. Hansen, C. Johnson, V. Pascucci, C. Silva, “Visualization for Data-Intensive Science” in “The
Fourth Paradigm” [2]
[30] K. Thearling, “An Introduction to Data Mining”
http://www.thearling.com/dmintro/dmintro_2.htm
[31] E. Wenger, “Communities of practice: An brief introduction”, 2006
www.ewenger.com/theory/

GRDI2020 Final Roadmap Report Page 106 of 108
[32] M. Fraser, “Virtual Research Environments: Overview and Activity” in Ariadne issue 44 July
2005
[33] N. Wilkins-Diehr, “Special Issue: Science Gateways – Common Community Interfaces to Grid
Resources”, Concurrency and Computation: Practice and Experience, 19 (6) 743-749, April
2007.
[34] A. Poggi, D. Lembo, D. Calvanese, G. de Giacomo, M. Lenzerini, R. Rosati, “Linking Data to
Ontologies”
[35] T. R. Gruber,”Towards principles for the design of ontologies used for knowledge sharing” Intl.
Journal of Human-Computer Studies 43 (5/6) 1993
[36] S. Bloehdorn, P. Haase, Z. Huang, Y. Sure, J. Voelker, F. van harmelen, R. Studer, “Ontology
Management” In J. davies et al. (eds), Semantic Knowledge Management, Springer-Verlag
Berlin Heidelberg 2009
[37] A. Das, W. Wu, D. McGuinness, “Industrial Strength Ontology Management”, Stanford
Knowledge Systems Laboratory Technical Report KSL-01-09 2001; in the Proc. Of the
International Semantic Web Working Symoosium, Stanford, CA, July 2001
[38] NeOn Project Deliverable D1.1.1: Networked Ontology Model
[39] Barry Smith, “Ontology” Preprint version of chapter “Ontology” in L. Floridi (ed.), Blackwell
Guide to the Philosophy of Computing and Information, Oxford: Blackwell, 2003
[40] I. Taylor, D, Gannon, and M. Shields (eds), “Workflows for e-Science”, Springer, ISBN 978-1-
84628-519-6
[41] C. Goble and D. De Roure, “The Impact of Workflows on Data-centric Research” in [2]
[42] C. Thanos, Interoperability: A Holistic Approach, Manuscript, 2010.
[43] G. Wiederhold, “Mediators in the architecture of future information systems”, Computer, 25
(3), 38-49, March 1992.
[44] M. Stollberg, E. Cimpian, A. Mocan and D. Fensel, “A Semantic Web Mediation
Architecture”, in: Proceedings of the 1st Canadian Semantic Web Working Symposium (CSWWS
2006), 22 pp., Springer, 2006.
[45] O. Nanseth and E. Monteiro, Understanding Information Infrastructure, Manuscript, 1998.
[46] N. Paskin, “Digital Object Identifiers for Scientific Data”, Paper presented at the 19th
International CODATA Conference, Berlin, 2004
[47] G. Rust, M. Bide, “The <indecs>Metadata Framework: Principles, model and data dictionary”
http://www.indecs.org/pdf/framework.pdf
[48] G. Garrity, C. Lyons, “Future-proofing Biological Nomenclature”. Omics, 2003, Volume 7,
Number 1
[49] Australian National Data Service, “Data Citation Awareness”
http://www.ands.org.au/guides/data-citation-awareness.html
[50] M. Altman and G. King “A Proposed Standard for the Scholarly Citation of Quantitative
Data”, in D-Lib Magazine March/April 2007
[51] U. Keller, U. Lara, H. Lausen, A. Polleres, D. Fensel, “Automatic Location of Services”, Proc. of
2nd European Semantic Web Conference (ESWC), 2005
[52] U. Keller, R. Lara (eds), WSMO Web Service Discovery” Deliverable D5.1vo.1, Nov. 12, 2004
[53] J. Bleiholder, F. Naumann, “Data Fusion” ACM Computing Surveys, Vol. 41, No. 1, Dec. 2008

GRDI2020 Final Roadmap Report Page 107 of 108
[54] M. Lenzerini, “Data Integration: A Theoretical Perspective” Proc. PODS 2002
[55] D. Nickul, “A Modelling Methodology to Harmonize Disparate Data Models” (A White Paper to
aid intelligence gathering capabilities for the Office of Homeland Security)
[56] “ASW&Data Harmonization” Uniscap Symposium 2009
[57] M. Franklin, A. Halevy, D. Maier, “From Databases to Dataspaces: A New Abstraction for
Information Management” in ACM SIGMOD Record, December 2005
[58] C. Bizer, T. Heath, T. Berners-Lee, C. Bizer, “Linked Data” in Special Issue on Linked Data,
International Journal on Semantic Web and Information Systems
[59] V. Van den Eynden, L. Corti, M. Woollard, L. Bishop and L. Horton “Managing and Sharing
Data” Published by: UK Data Archive, University of Essex, Third edition 2011
[60] J. Birnholtz, M. Bietz, “Data at Work: Supporting Sharing in Science and Engineering” in
GROUP’03, Nov 9-12, 2003, Sanibel Island, Florida, USA
[61] R. Whitley, “The Intellectual and Social Organization of the Sciences” Oxford University Press,
Oxford, 2000
[62] A. Zimmerman, “Data Sharing and Secondary Use of Scientific Data: Experiences of
Ecologists”, Unpublished Dissertation, Information and Library Studies, University of Michigan,
Ann Arbor, 2003
[63] N. Van House, M. Butler, and L. Schiff, “Cooperative knowledge work and practices of trust:
Sharing environmental planning data sets” in (eds) Proc. Of CSCW 1998
[64] J. Haas, H. Samuels, and B. Simmons, “Appraising the records of modern science and
technology: A guide”, MIT Press, Cambridge, MA, 1985
[65] G. Chin Jr and C. Lansing, “Capturing and Supporting Contexts for Scientific Data Sharing via
Biological Science Collaboratory” in CSCW’04, 2004, Chicago, Illinois, USA
[66] “Data-Intensive Research Workshop Report” run by the e-Science Institute at the University of
Edinburgh, 15-19 March 2010
[67] P. Carlile, “A Pragmatic View of Knowledge and Boundaries: Boundary Objects in New Product
Development” in Organization Science Vol. 13, No. 4, 2002
[68] S. Star, “The structure of ill-structured solutions: Boundary Objects and heterogeneous
distributed problem solving” in Readings in Distributed Artificial Intelligence, 1989
[69] “Reference Model for an Open Archival Information System (OAIS)” CCSDS 650.0-B-1, BLUE
BOOK, 2002
[70] I. Foster, Y. Zhao, I. Raicu, S. Lu, “Cloud Computing and Grid Computing 360-Degree
Compared”, ”, in: Proc. IEEE Grid Computing Environments Workshop, IEEE Press, 2008
[71] “What is Cloud Computing”, Whatis.com.
http://searchsoa.techtarget.com/sDefinition/0,,sid26_gci12788,00html, 200 [72]
[73] M. Armbrust et al, “Above the Clouds: A Berkeley View of Cloud Computing” Technical Report No.
UCB/EECS-2009-28
[73] “The Future of Cloud Computing” Expert Group Report, Version 1.0, European Commission
[74] D. Bernstein, E. Ludvigson, K. Sankar, S. Diamond, M. Morrow, “Blueprint for the Intercloud –
Protocols and Formats for Cloud Computing Interoperability” in Proc. 4th International
Conference on Internet and Web Applications and Services, 2009

GRDI2020 Final Roadmap Report Page 108 of 108
[75] D. DeWitt, M. Stonebraker, “MapReduce: A major step backwards”, craig-
henderson.blogspot.com. Retrieved 2008-08-27.
[76] J. Dean and S. Ghemawat, “Mapreduce: Simplified Data Processing on Large Clusters”, ”, in:
OSDI 2004, USENIX Symposium on Operating System Design and Implementation, 137-150.
Retrieved from
http://www.usenix.org/events/osdi04/tech/dean.html , June 2011
[77] P. Bonatti, D. Olmedilla, “Rule-Based Policy Representation and Reasoning for the Semantic
Web”
[78] N. Damianou, N. Dulay, E. Lupu, M. Sloman, “The Ponder Policy Specification language” in
Proc. of Workshop on Policies for Distributed Systems and Networks, Springer-Verlag , LNCS
1995, Bristol, UK, 2001
[79] A. Uszok, et al., “”KAoS policy and domain services: Towards a description-logic approach to
policy representation, deconfliction, and enforcement” in POLICY, 2003
[80] L. Kagak, T. Finin, A. Johshi, “A Policy language for Pervasive Computer Environment” in
Proc. of IEEE Fourth International Workshop on Policy (POLICY 2003)
[81] P. David, M. den Besten, R. Schroeder, “Will e-Science be Open Science?” in World Wide
Research, W. Dutton, P. Jeffreys (eds), MIT Press
[82] OECD Recommendations of the Council concerning Access to Research Data from Public
Funding” C (2006)184, Dec. 14, 2006.
[83] A. Fitzgerald, B. Fitzgerald, K. Pappalardo, “The Future of Data Policy” in The Fourth Paradigm
[2]