gpu環境へ! hpe engineering vdi · gpu gpu gpu gpu プリエンプション処理....
TRANSCRIPT

HPE HPC & AI フォーラム 2018
日本ヒューレット・パッカード株式会社ハイブリッドIT事業統括 コアソリューション部久保田 隆志
より使いやすいGPU環境へ!HPEのEngineering VDI最新情報

本日の内容
–Engineering VDI 技術変遷
–HPE SimpliVity 380
–パブリック クラウド環境の利用
–NVIDIA GRID最新情報
–まとめ
1

Engineering VDI 技術変遷おさらい
2

Engineering VDIの振り返り
3
Single Image管理
HA対応
Live Migration対応
Bare MetalGPU
PassthroughvGPU
NVIDIA GRIDHCI & Cloud
NVENC対応
2008 2012 2014 2018
GPU
VDI技術
画面転送プロトコル
※ プリエンプション対応
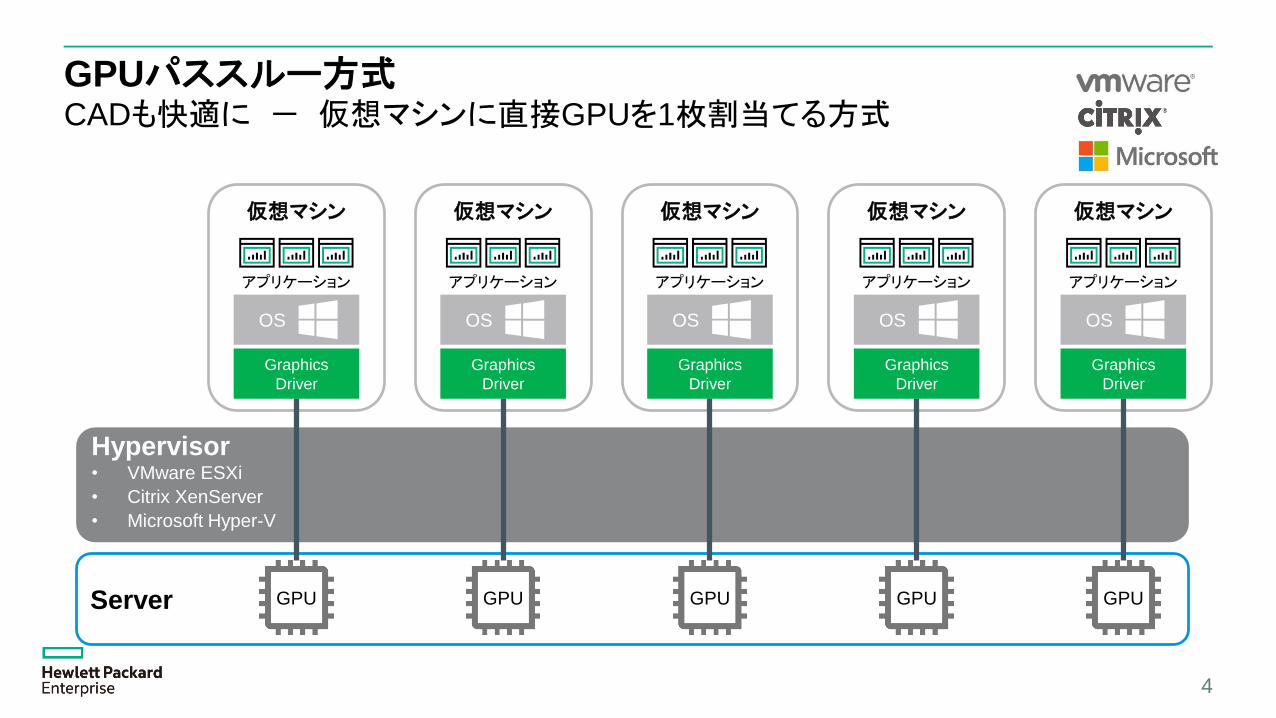
仮想マシン
アプリケーション
OS
仮想マシン
アプリケーション
OS
仮想マシン
アプリケーション
OS
仮想マシン
アプリケーション
OS
仮想マシン
アプリケーション
OS
GPUパススルー方式CADも快適に - 仮想マシンに直接GPUを1枚割当てる方式
4
Hypervisor• VMware ESXi
• Citrix XenServer
• Microsoft Hyper-V
Server GPU
Graphics
Driver
GPU
Graphics
Driver
GPU
Graphics
Driver
GPU
Graphics
Driver
GPU
Graphics
Driver
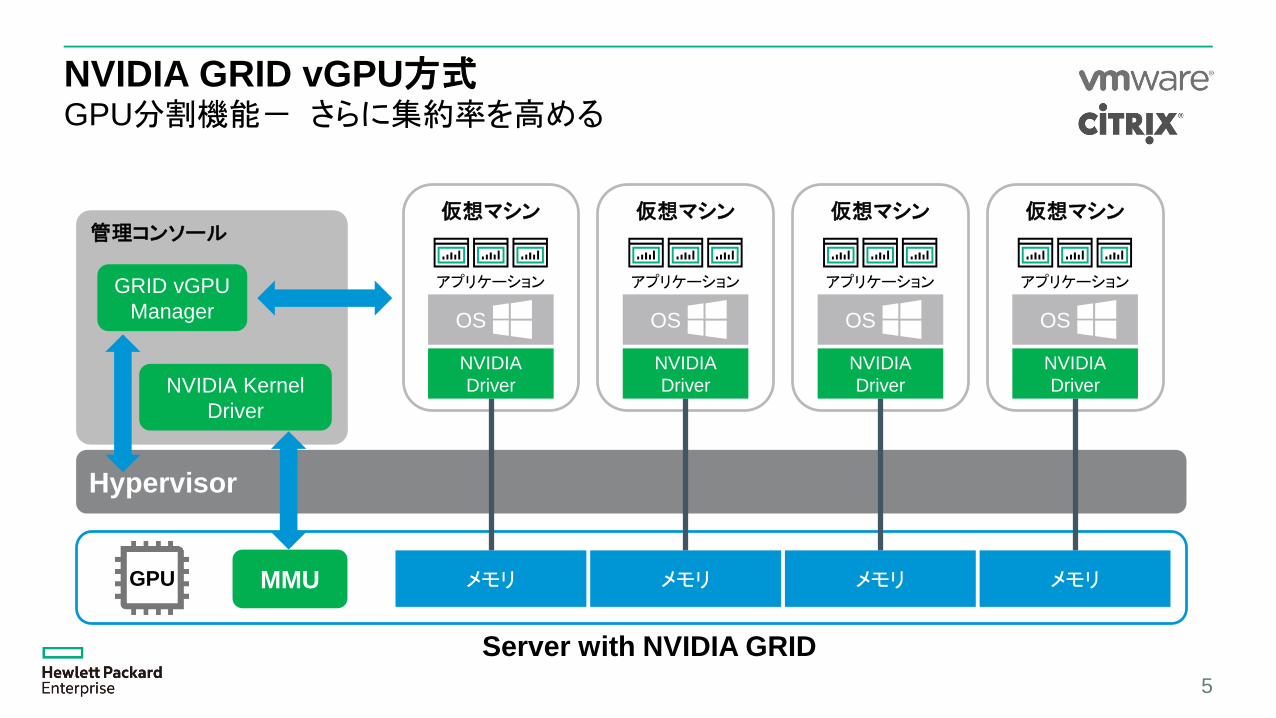
NVIDIA GRID vGPU方式GPU分割機能- さらに集約率を高める
5
Hypervisor
GPU
管理コンソール
GRID vGPU
Manager
MMU
NVIDIA Kernel
Driver
Server with NVIDIA GRID
仮想マシン
アプリケーション
OS
メモリ
NVIDIA
Driver
仮想マシン
アプリケーション
OS
メモリ
NVIDIA
Driver
仮想マシン
アプリケーション
OS
メモリ
NVIDIA
Driver
仮想マシン
アプリケーション
OS
メモリ
NVIDIA
Driver
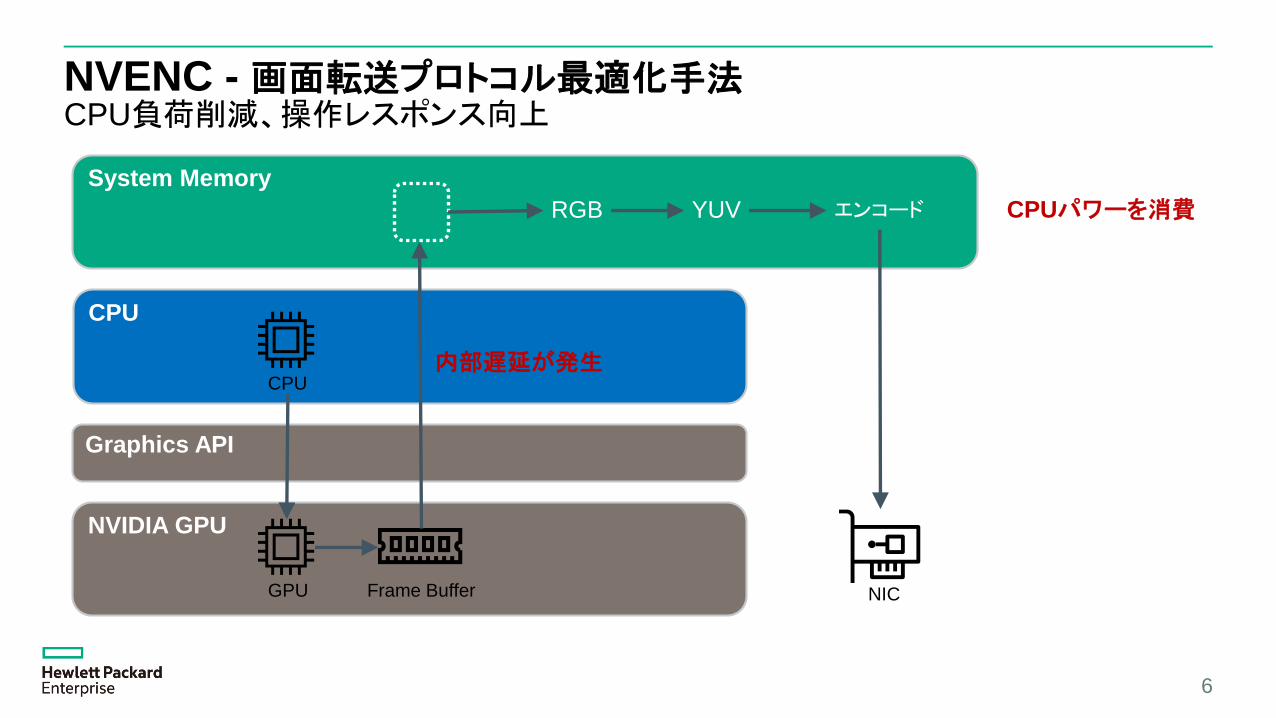
NVENC - 画面転送プロトコル最適化手法CPU負荷削減、操作レスポンス向上
6
NVIDIA GPU
System Memory
RGB YUV エンコード
GPU Frame Buffer
CPU
Graphics API
CPU
NIC
内部遅延が発生
CPUパワーを消費
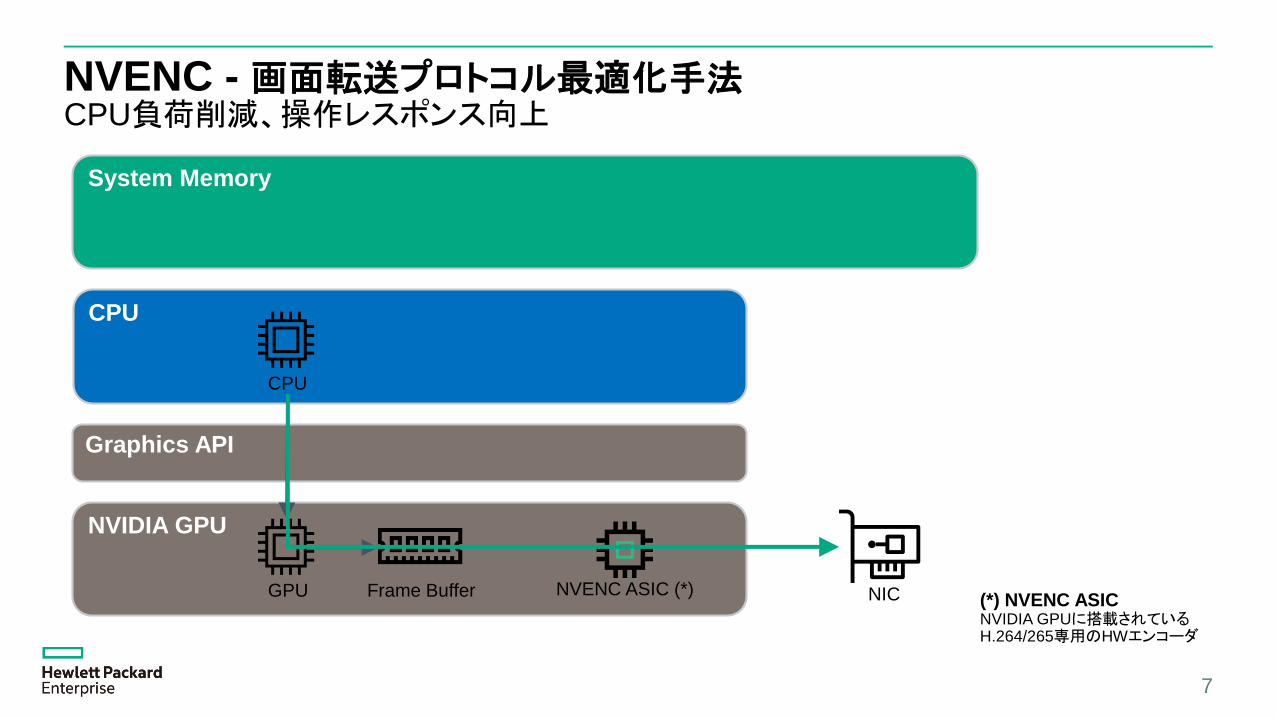
NVENC - 画面転送プロトコル最適化手法CPU負荷削減、操作レスポンス向上
7
NVIDIA GPU
System Memory
GPU Frame Buffer NVENC ASIC (*)
CPU
Graphics API
CPU
NIC (*) NVENC ASICNVIDIA GPUに搭載されているH.264/265専用のHWエンコーダ

NVIDIA GPU プリエンプション対応
– Maxwell世代までのGPUはプリエンプションがなかった(グラフィックスだけを考えればこれでもよかった)
– Pascalからはプリエンプション対応なので以下のような処理が可能
8
Graphcis
Graphcis
Graphcis
Graphcis
VM1
VM2
VM3
VM4
time
GPU
VM1
VM2
VM3
VM4
time
GPU GPU
GPU
GPU
プリエンプション処理

プリエンプション対応によるメリット
–vGPU環境でもCUDAを利用可能(これまではGPU占有して使用しない限りCUDAを利用できなかった)
–GPU ModeSwitchが不要に(*)
9
Hypervisor
Server + NVIDIA
GraphicsVM
CUDAVM
Hypervisor
Server + NVIDIA
CADVM
CUDA
Server + NVIDIA
OS
GPUModeSwitch
(要再起動)
Graphics Compute
Maxwellまで Pascal以降
(*) ECCメモリの扱いには注意が必要

Engineering VDI進化のまとめ
10
NVIDIA GRIDの登場
• 柔軟なGPUリソースの割り当てが可能
VDI技術のGPU対応
• GPUがあっても一般のVDIと同じ管理が可能
NVENC対応
• CPU負荷の削減および操作レスポンスが向上
NVIDIA GPUのプリエンプション対応
• CAD/CUDAの仮想マシンの共存が可能

HPE SimpliVity 380Hyper Converged Infrastructure
11

ビジネスに必要不可欠なあらゆる機能をビルトインで提供する高性能かつ多機能なハイパーコンバージドインフラストラクチャ( )
データ効率PCI Acceleratorカードを用いたFPGA
テクノロジでCPU/メモリのリソースを
専有せずにデータ圧縮・重複排除
データ保護1TBの仮想マシンの
ローカルバックアップ
ローカルリストアを1分で完了
シンプルコンソール画面から3クリックで
仮想マシンのバックアップ、リストア、
移行、複製が可能
管理性複数サイトにまたがる1000もの仮想マ
シンに対して1分未満でバックアップポ
リシーの作成・更新が可能
可用性ローカルもしくはリモートサイトへ
停止時間ゼロでシステム追加
リプレイス可能
マーケットリーダー の 製品を信頼の サーバーで提供開始
2018 年 5 月
Hyper-V 版も登場

HPE SimpliVity による画期的な VDI 運用
– SimpliVity は 30 年来の不可能を “可能” にできる
13
RPOバックアップによる性能影響がないため、
最短 10 分おき に PC 状態を保存できる
RTO容量に限らず、
バックアップもリストアも一瞬 で処理完了
NOTALL
すべてのVDI仮想マシンを一台一台、
PC 丸ごとイメージバックアップ できる
※ ファイル単位で戻すことも可能

HPE SimpliVityを利用した構成例通常サーバーを組み合わせた柔軟な構成が可能
14
HPE SimpliVity 380メイン
HPE SimpliVity 380バックアップ
HPE ProLiantDL380 Gen10
ComputeNode
VDI管理サーバー群が稼働ストレージ領域として利用
バックアップサーバーとして利用
eVDIホストとして利用
NFS
SimpliVityFederation
GTC Japan 2018で事例発表9/14(金) 14:00 – 14:25
@ Room 2-2

パブリック クラウド環境の利用ハイブリッド環境への適合
15
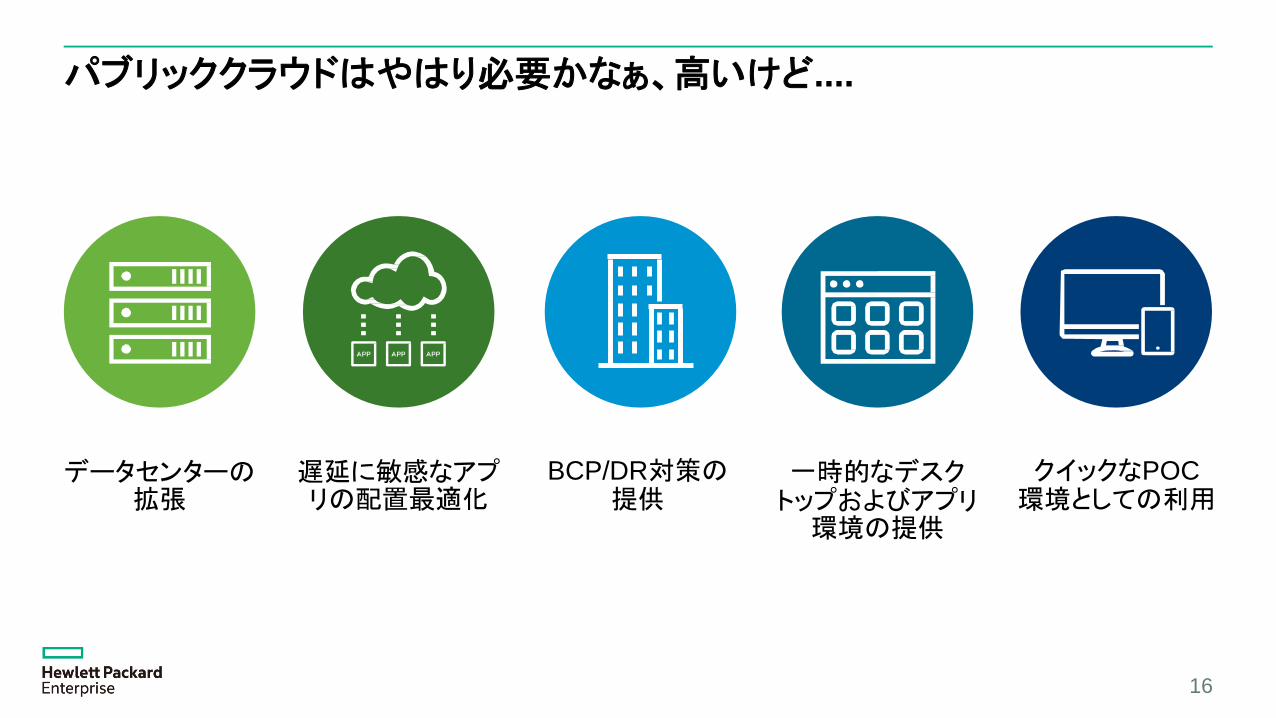
パブリッククラウドはやはり必要かなぁ、高いけど....
16
データセンターの拡張
遅延に敏感なアプリの配置最適化
BCP/DR対策の提供
一時的なデスクトップおよびアプリ環境の提供
クイックなPOC環境としての利用
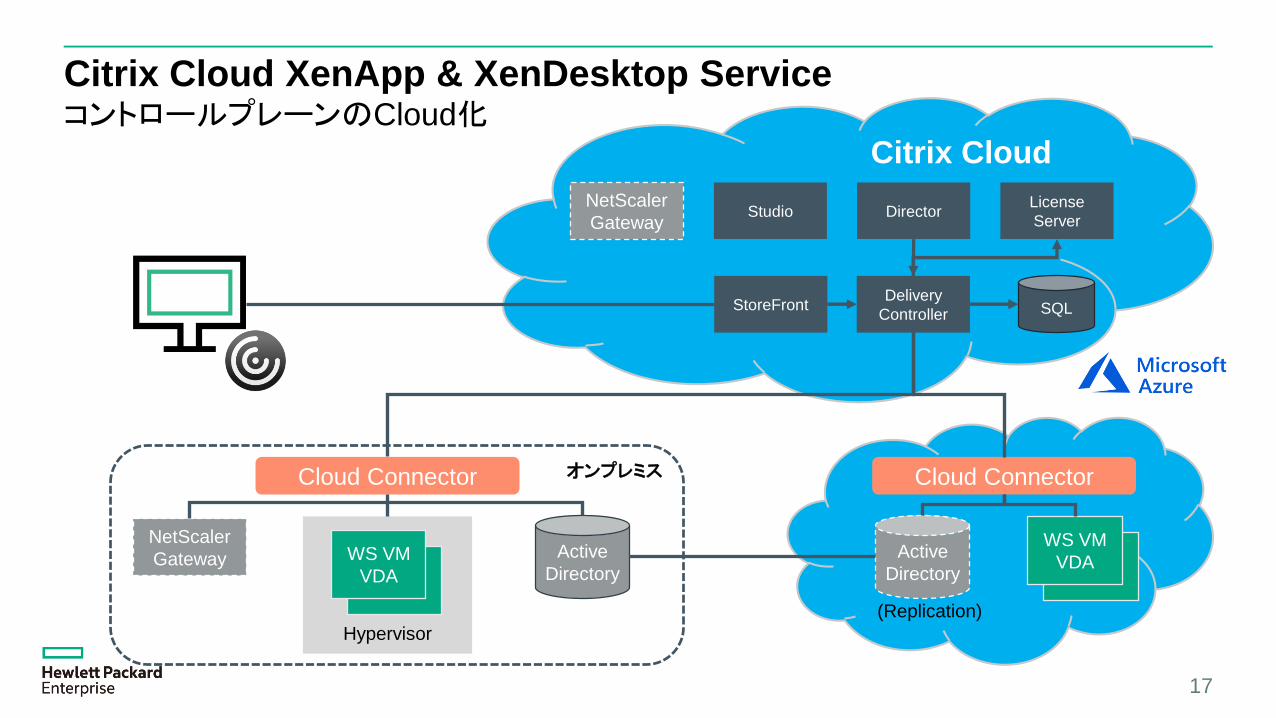
Citrix Cloud
NetScaler
Gateway
オンプレミス
Citrix Cloud XenApp & XenDesktop ServiceコントロールプレーンのCloud化
17
SQL
Active
Directory
NetScaler
Gateway
License
ServerStudio Director
Delivery
ControllerStoreFront
Hypervisor
WS VM
VDA
WS VM
VDA
Cloud Connector
Active
Directory
Cloud Connector
WS VM
VDA
WS VM
VDA
(Replication)

Horizon 7 with VMware Cloud on Amazon Web Services
–柔軟なデプロイメント
–Horizon7 CPAを用いたハイブリッドクラウド環境の構築
–Horizon 7 on VMC on AWSスタンドアローン環境・展開のサポート
–シンプルなvSphere環境の展開と時間課金の選択肢
–HorizonおよびWorkspace ONEサブスクリプションライセンスの提供
18
AWSもしくはオンプレミスのPods
Horizon 7 Connection Servers
vSphere / VMware Cloud
AWSもしくはオンプレミスのPods
グローバルデータレイヤー
Horizon 7 Connection Servers
vSphere / VMware Cloud
ポッド間コミュニケーション通信
Cloud Pod アーキテクチャ (CPA)

Horizon on VMCはDaaS (Desktop-as-a-Service)ではない
19
顧客の管理スコープ
デスクトップ&アプリ
Horizonインフラ
SDDC
ハードウェア
オンプレミスのインフラ
デスクトップ&アプリ
Horizonインフラ
SDDC
ハードウェア
VMware Cloudon AWS
デスクトップ&アプリ
Horizonインフラ
SDDC
ハードウェア
マネージドクラウドサービス

Software-Defined Data Centerのデプロイ
20

こまめな消灯をお忘れなく
21
電源管理はCloudではとても大事

NVIDIA GRID 最新情報最適なGPU選択のためのヒント
22
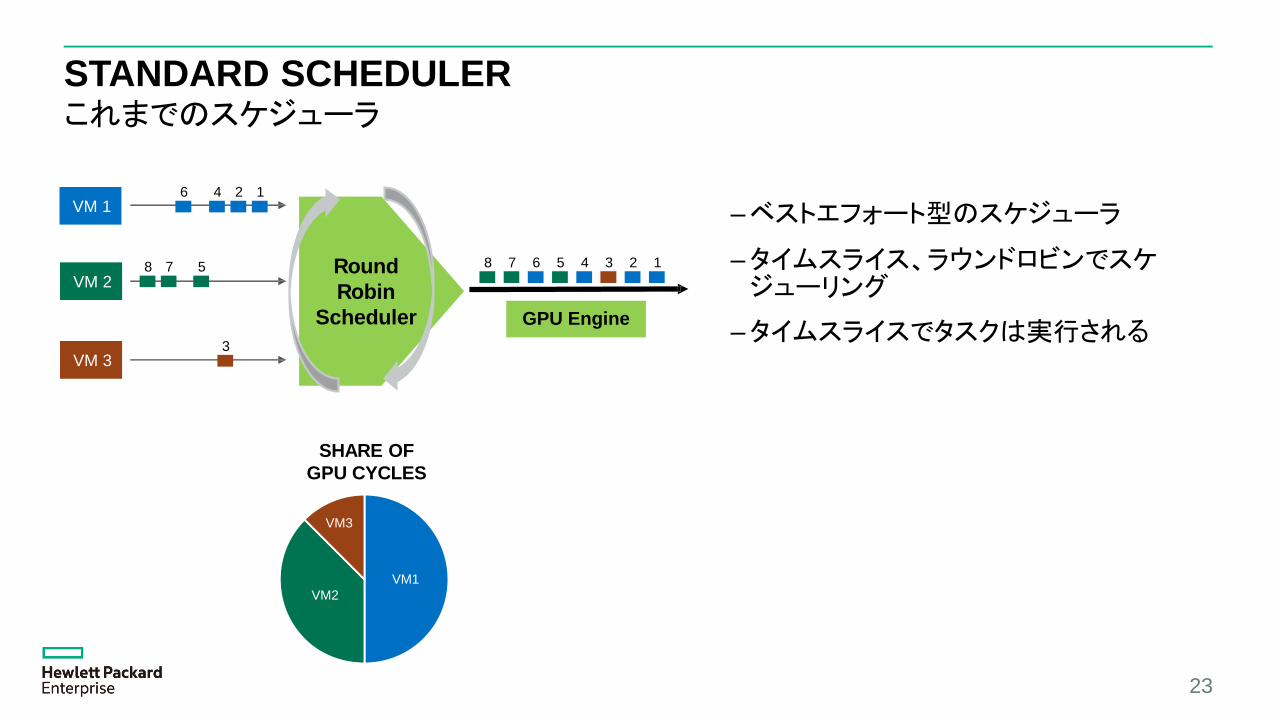
STANDARD SCHEDULERこれまでのスケジューラ
23
VM 1
VM 2
VM 3
Round
Robin
Scheduler
SHARE OF
GPU CYCLES
8 7 6 5 4 3 2 1
GPU Engine
6 4 2 1
8 7 5
3
VM1
VM3
VM2
–ベストエフォート型のスケジューラ
–タイムスライス、ラウンドロビンでスケジューリング
–タイムスライスでタスクは実行される
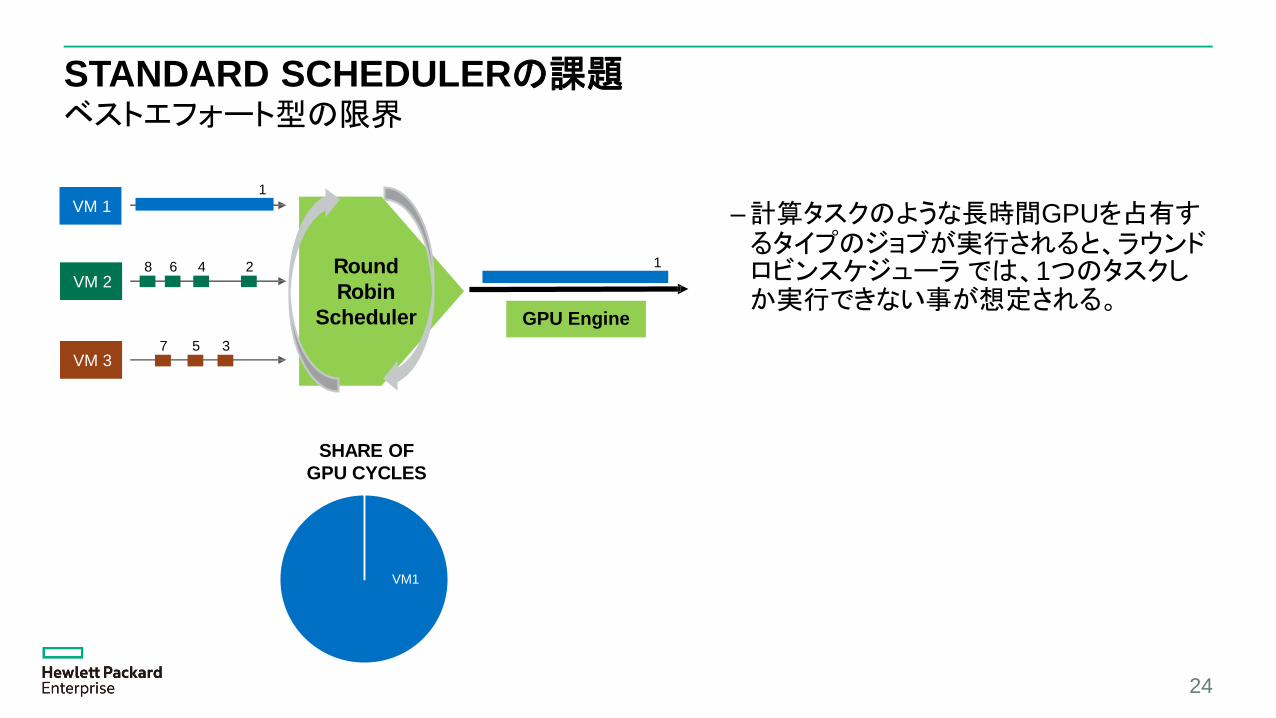
STANDARD SCHEDULERの課題ベストエフォート型の限界
24
VM 1
VM 2
VM 3
Round
Robin
Scheduler
SHARE OF
GPU CYCLES
1
GPU Engine
8 6 4
5
VM1
–計算タスクのような長時間GPUを占有するタイプのジョブが実行されると、ラウンドロビンスケジューラでは、1つのタスクしか実行できない事が想定される。
1
7 3
2

EQUAL SHARE SCHEDULERQoSを保証するスケジューラ
25
VM 1
VM 2
VM 3
Equal
Share
Round
Robin
Scheduler
SHARE OF
GPU
GPU Engine
8 6 4
5
–新しいスケジュラー: Equal ShareScheduler (Pascal以降のHWのみ)
–長時間実行されているタスクはプリエンプトされ、再スケジューリング時にコンテキストを保存して再開される
–VM単位でGPUサイクルが決定される
– vGPU対応VMは、GPUサイクルを同等にシェアされる
1
7 3
2
VM1VM3
VM2
8 1 7 6 1 5 4 1

FIXED SHARE SCHEDULER固定型のスケジューラ
26
VM 1
VM 2
VM 3
Fixed
Share
Round
Robin
Scheduler
SHARE OF
GPU
GPU Engine
6 4 2 1
8 7 5
3
VM1
VM3 VM2
–Fixed Share Round Robin Scheduler
–タイムスライスでスケジュールされる
–VM単位でGPUの利用率は固定
–GPUプロファイル(分割数)で性能が決まる。 各VMの性能は、1/vGPU分割数
–クラウド事業者向けを想定(常に一定の性能を保証する)
None
13254768

NVIDIA Tesla 製品一覧仮想環境向けのグラフィックス製品
M10 P4 P40 P100 V100 P6
GPU 4 Maxwell GPUs 1 Pascal GPUs 1 Pascal GPUs 1 Pascal GPUs 1 Volta GPUs 1 Pascal GPUs
CUDA cores 2,560 2,560 3,840 3,584 5,120 2,048
Memory Size32GB GDDR5
(8GB per GPU)8GB GDDR5 24GB GDDR5 16GB HBM2 16GB HBM2 16GB GDDR5
H.264 1080p30
streams28 24 24 36 36 24
Max vGPU
instances
64
(512MB Profile)
8
(1GB Profile)
24
(1GB Profile)
16
(1GB Profile)
16
(1GB Profile)
16
(1GB Profile)
vGPU Profiles0.5GB, 1GB, 2GB,
4GB, 8GB
1GB, 2GB, 4GB,
8GB
1GB, 2GB, 3GB,
4GB, 6GB, 8GB,
12GB, 24GB
1GB, 2GB, 4GB,
8GB, 16GB
1GB, 2GB, 4GB,
8GB, 16GB
1GB, 2GB, 4GB,
8GB, 16GB
Form FactorPCIe 3.0 Dual Slot
(rack servers)
PCIe 3.0 Single Slot
(rack servers)
PCIe 3.0 Dual Slot
(rack servers)
PCIe 3.0 Dual Slot
(rack servers)
PCIe 3.0 Dual Slot
(rack servers)
MXM
(blade servers)
Power 225W 50 – 75W 250W 250W 250W90W
(70W opt)
Thermal passive passive passive passive passive bare board
27
USER DENSITYOptimized
PERFORMANCEOptimized
BALDEOptimized

NVIDIA Tesla 製品一覧仮想環境向けのグラフィックス製品
M10 P4 P40 P100 V100 P6
28
USER DENSITYOptimized
PERFORMANCEOptimized
BALDEOptimized
32G 8G 24G 12G
16G
16G
32G
16G
16G
50W
8G
75W

無視してはいけない大事な疑問
29
どのGPUを選択するのが賢い?
どのスケジューラを使用するのが賢い?
同じビデオメモリサイズのプロファイルならGPUが違ってもパフォーマンスは同じ?
分割数上げても本当に大丈夫?
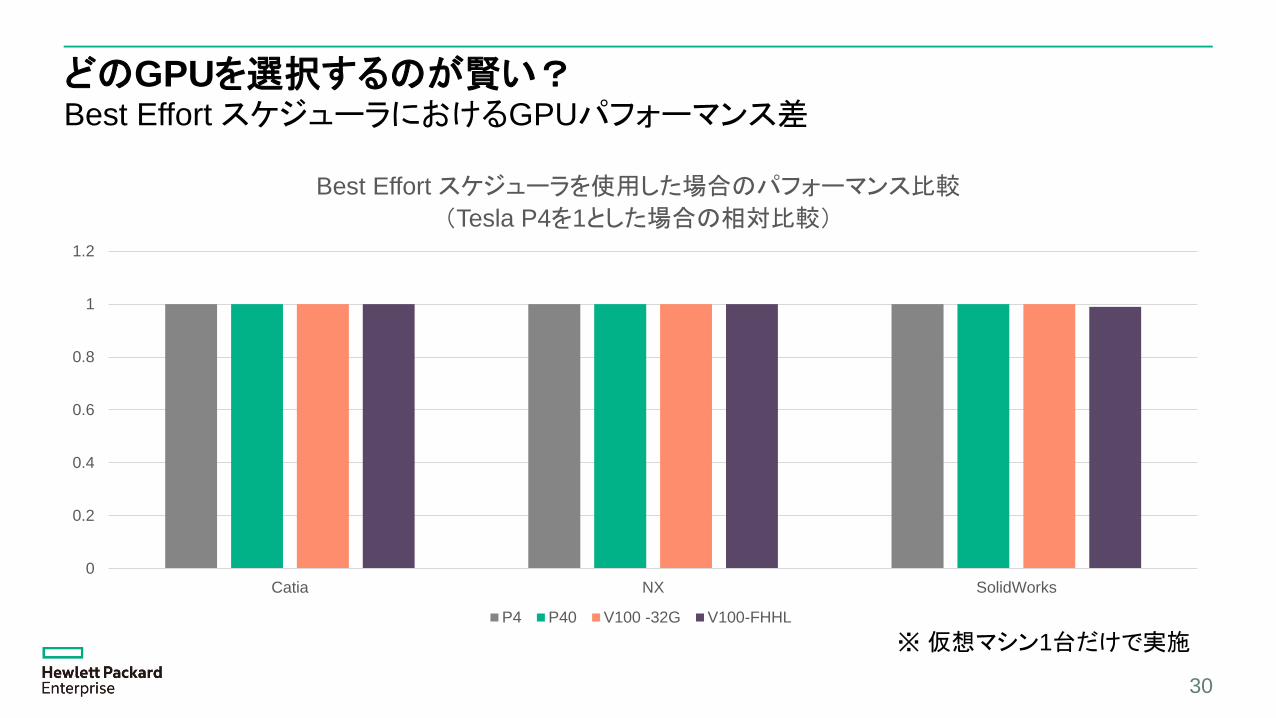
どのGPUを選択するのが賢い?Best Effort スケジューラにおけるGPUパフォーマンス差
0
0.2
0.4
0.6
0.8
1
1.2
Catia NX SolidWorks
Best Effort スケジューラを使用した場合のパフォーマンス比較
(Tesla P4を1とした場合の相対比較)
P4 P40 V100 -32G V100-FHHL
30
※仮想マシン1台だけで実施

どのGPUを選択するのが賢い?
えっ、違わないの?
[正しい理解]
はい。
–Best Effort では、ピーク性能はFRL(Frame Rate Limitter)でキャップされてしまう(仮想マシン1台だけでは差が全くないように見える)
–GPUの性能差は多重度を上げたときに現れる(多重度を上げてもパフォーマンス劣化の度合いが少ない)
31

どのGPUを選択するのが賢い?本来のGPU性能差の確認
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
3dsmax-06 catia-05 energy-02 maya-05 medical-02 showcase-02 snx-03 sw-04
SPEC viewperf 13ベンチマーク
(Tesla P4を1とした時の相対比較)
Tesla P4 Tesla P40 Tesla V100 -32G Tesla V100 -FHHL
32
Equal Share を使用し、全て2Gのプロファイルを使用(仮想マシン1台だけで実施)

どのスケジューラを使用するのが賢い?
Best Effort と Equal Share どちらが良い?(Fixed Shareはクラウド事業者向けなので普通使わないのはわかったけど)
[正しい理解のために]
ベンチマーク結果を見てみましょう
33

どのスケジューラを使用するのが賢い?スケジューラの比較: Best Effort vs. Equal Share
3.37
5.28
2.91
0
1
2
3
4
5
6
Catia NX SolidWorks
Tesla P40におけるスケジューラの比較
(Best Effortを1とした時の相対比較)
Best Effort Equal Share
34
※仮想マシン1台だけで実施

どのスケジューラを使用するのが賢い?
じゃ、Equal Shareを使用すればOK?
[正しい理解]
そうとは限りません。
–Equal Shareは、ホスト上で稼働している仮想マシン数で「必ず」等分される(GPUの性能を使いきれない状況が発生する可能性)
–Best Effortは、FRLでキャップされた状態だが、GPUリソースを使えるだけ使える(分割数は多いが、同時に負荷の高い仮想マシンが少ない場合は有利)
35

3.5
5.4
2.9
2.3 2.5
2.2
1.5 1.5 1.7
1.1 1.1 1.4
0.7 0.7 1.1
0.5 0.5
0.9
0.3 0.4 0.7
0.00
1.00
2.00
3.00
4.00
5.00
6.00
Catia NX SolidWorks
Best Effort (VM=1) と Fixed Shareのパフォーマンス劣化について
(Best Effort (VM=1)を1とした場合の相対比較)
Best Effort 1分割 2分割 3分割 4分割 6分割 8分割 12分割
どのスケジューラを使用するのが賢い?ベンチマーク結果 - Tesla P40 分割数による違い
36

同じビデオメモリサイズのプロファイルならパフォーマンスは同じ?
P4-2G vs. V100D-2G
パフォーマンスは同じなんだよね?
[正しい理解]
先のベンチマーク結果からご想像いただけると思いますが、分割数がパフォーマンスに影響を与えます。ベンチマーク結果を見てみましょう。
37

同じビデオメモリサイズのプロファイルならパフォーマンスは同じ?分割数がパフォーマンスに与える影響度 (2GBのプロファイルを使用)
0
0.2
0.4
0.6
0.8
1
1.2
Catia Creo NX SolidWorks
Fixed Share スケジューラを使用した場合のパフォーマンス比較
(Tesla P4を1とした場合の相対比較)
Tesla P4
(4分割)Tesla P40
(12分割)Tesla V100 - 32G
(16分割)Tesla V100 - FHHL
(8分割)
38

NVIDIA GRIDまとめ
39
Best Effortでは、GPUの性能差がパフォーマンス差として現れない
• ただし、性能の高いGPUは多重度を上げてもパフォーマンスの劣化度は少なくなる
分割数には注意
• 単純にGPUの集約率を上げてしまうと期待したパフォーマンスが得られない可能性
スケジューラの選択について
• Best Effortの方が失敗する確率は低い。明確にEqual Shareを選ぶ方が良いケースは、CUDAを利用する仮想マシンの共存を考える場合と分割数が少なめの場合に限られる

まとめ
40

まとめ
41
VDI環境においてGPUがあることによる制限はほとんどなくなった
HCI製品を利用した展開によって管理がより容易に
全てクラウドに移行するのではなくコントロールプレーンのみ移行等、より柔軟な選択(ハイブリッド環境)が可能に
NVIDIA GRIDの進化により、CADとCAEの垣根がさらに低くなった
GPUの選択(とくに分割数)は注意が必要

様々な製品でEngineering VDIを支援していきます
42
HPE ProLiantDL380 Gen10
HPE Apollo 2000
XL190r Gen10
HPE Synergy 480 Gen10HPE SimpliVity 380
引き続き、日本ヒューレット・パッカード株式会社をよろしくお願いいたします

Thank you
43

ベンチマーク環境について
項目 構成 備考
Server HPE ProLiant DL380 Gen9• CPU: Intel Xeon E5-2667 (3.2GHz, 2P/16Core)• Memory: 160GB
• Storage: 15krpm SAS 600GB (RAID 5)
GPU NVIDIA Tesla P4 / P40 / V100-32G / V100-FHHL NVIDIA GRID 6.2
VDI vSphere ESXi 6.5U1
VMware Horizon 7.5
Virtual Machine Windows 10 64bit Enterprise (1709)• CPU: 4vCPU
• Memory: 16GB
• HDD: 200GB
Benchmark Software SPEC viewperf 13 現時点では、Best Effort および Equal Shareでcreoのベンチマークを取得できない
44

搭載可能 NVIDIA GPUラインアップ
DL380 SimpliVity 380 Synergy 480 Apollo 2000
• Quadro P2000 (5)
• Quadro P4000 (5)
• Quadro P6000 (3)
• Quadro GV100 (3)
• Tesla M10 (2)
• Tesla P4 (5)
• Tesla P40 (3)
• Tesla P100-12G (3)
• Tesla P100-16G (3)
• Tesla V100-16G (3)
• Tesla V100-32G (3)
• Tesla V100-FHHL (5)
• Tesla M10 (1)
• Tesla P40 (1)
Single Wide
• Quadro M3000SE (1)
• Tesla P6 (1)
Expansion Module - MXM
• Quadro M3000SE (7)
• Tesla P6 (6)
Expansion Module - PCIe
• Quadro P6000 (2)
• Tesla M10 (2)
• Tesla P40 (2)
• Quadro P4000 (4)
• Tesla M10 (4)
• Tesla P40 (4)
• Tesla P100-12G (4)
• Tesla P100-16G (4)
• Tesla V100-16G (4)
• Tesla V100-32G (4)
45
• 括弧内は最大搭載枚数• 太字はvGPU対応• 緑字のものは今後搭載予定