google appengine: desafios da adoção de cloud computing no ... · backoffice no mainframe (cobol...
TRANSCRIPT

Google AppEngine:Desafios da adoção de cloud computing no mercado de seguros
Gustavo Concon

Quem sou eu?!
● Bacharel Análise de Sistemas PUC-Campinas
● Arquiteto de Sistemas
● Especializando-se em tecnologias Cloud
● Recém-carioca!ghconcon
@gconcon

● Fundada em 1995 (18 anos)
● Ofertas de Cloud Computing (Google/Amazon / Salesforce Partner)
● Application Development & Management / SAP & BI / Mobile …
● Cresce numa taxa média de 40% ao ano! Desde sua fundação.
● Recrutando talentos!
Sobre a CI&T


Contexto Tecnológico

● Infra-estrutura complexa e sistemas legados (JEE 1.3, Oracle, DB2, WebSphere 5 e 7)
● Alto custo com manutenção da infra
● Grande parte do processamento backoffice no Mainframe (COBOL Batch e COBOL CICS)
Contexto tecnológico

● Já era cliente do Google Apps for Business (E-Mail, Calendar, Docs, Sites)
● Decisão do Move to the Cloud por redução de custos e complexidade de suporte
● Natural escolha do Google AppEngine
Contexto tecnológico

O que já temos na núvem

● 4 aplicações em produção + 2 de suporte
● Uma média de 20k usuários/dia
● Aplicações diretas (front-office)
O que já temos na núvem
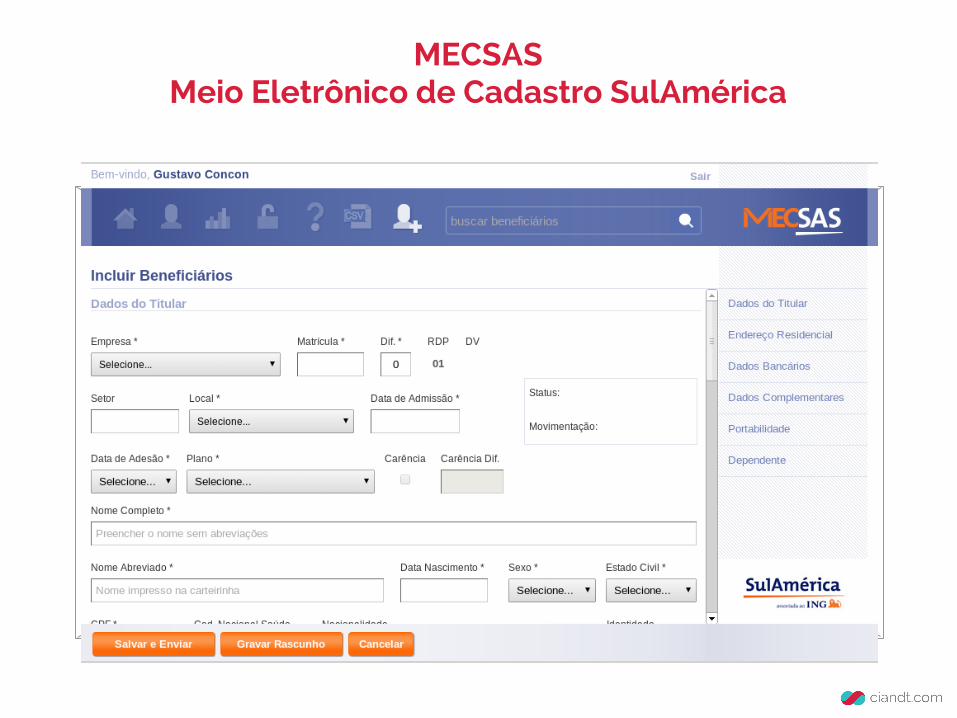
MECSASMeio Eletrônico de Cadastro SulAmérica
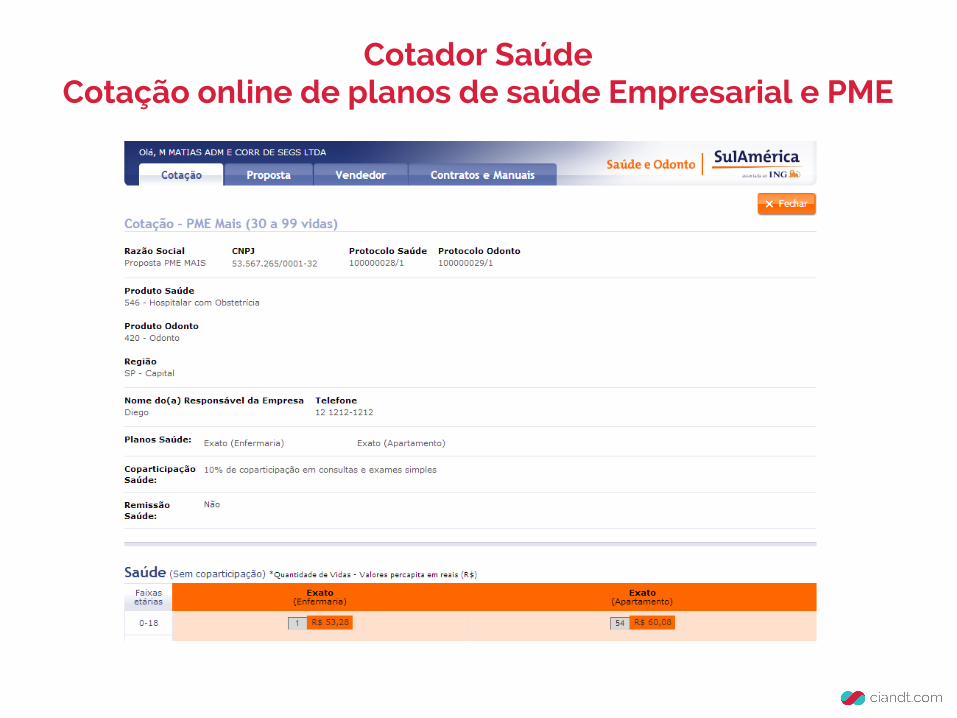
Cotador SaúdeCotação online de planos de saúde Empresarial e PME
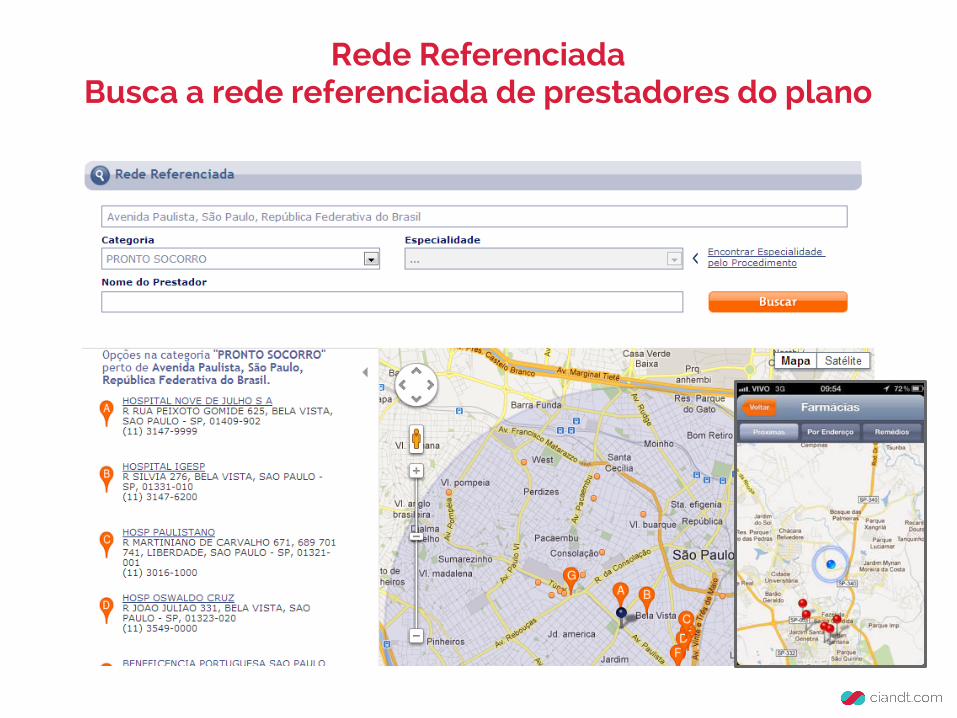
Rede ReferenciadaBusca a rede referenciada de prestadores do plano

Portal RGERecurso de Glosa Eletrônica

Plataforma tecnológica

Visão Geral da Arquitetura
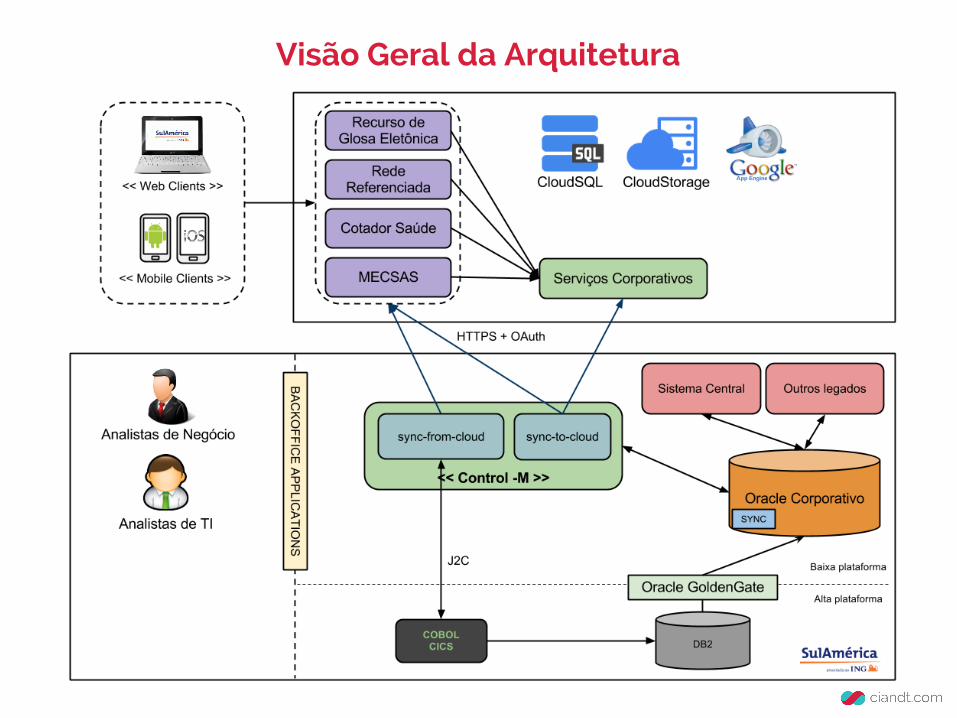
Visão Geral da Arquitetura

Integração com a núvem

● Dados gerados na núvem
● Processados no backoffice (Mainframe)
● Retorno do processamento para o cliente
● Plano futuro de remover dependência do Mainframe
Requisito
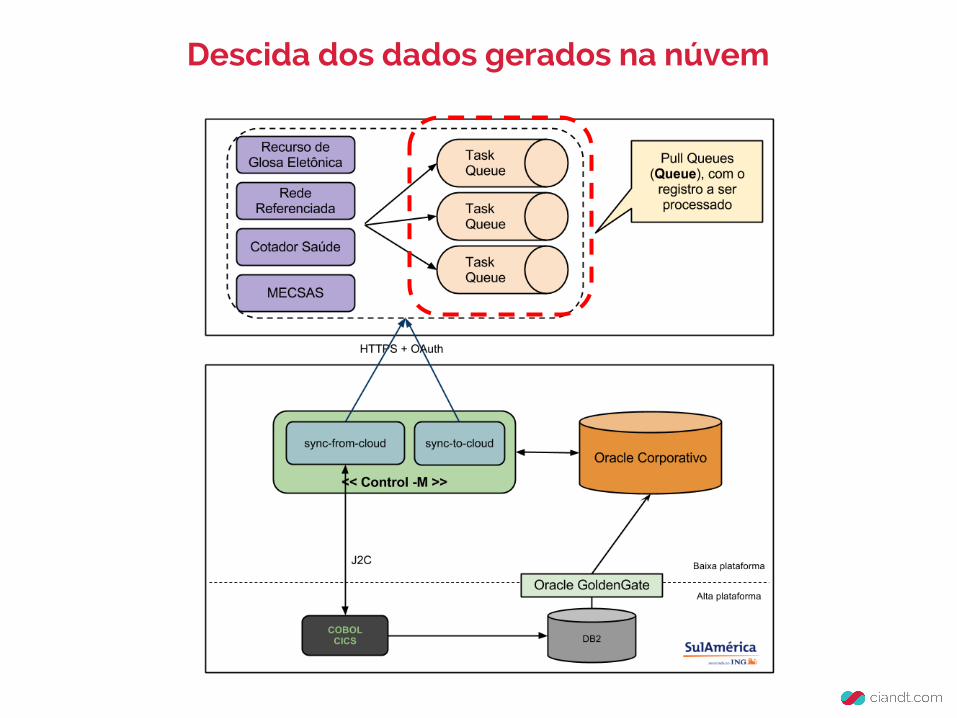
Descida dos dados gerados na núvem

● Não há conexão Núvem > Rede Local (Quebra de DMZ), sempre o local consume a núvem
● Registros já separados para processamento (Evita overhead de identificar o que mudou)
● Dados enfileirados de maneira escalável
Uso do TaskQueue (Pull Queue)
Para o usuário
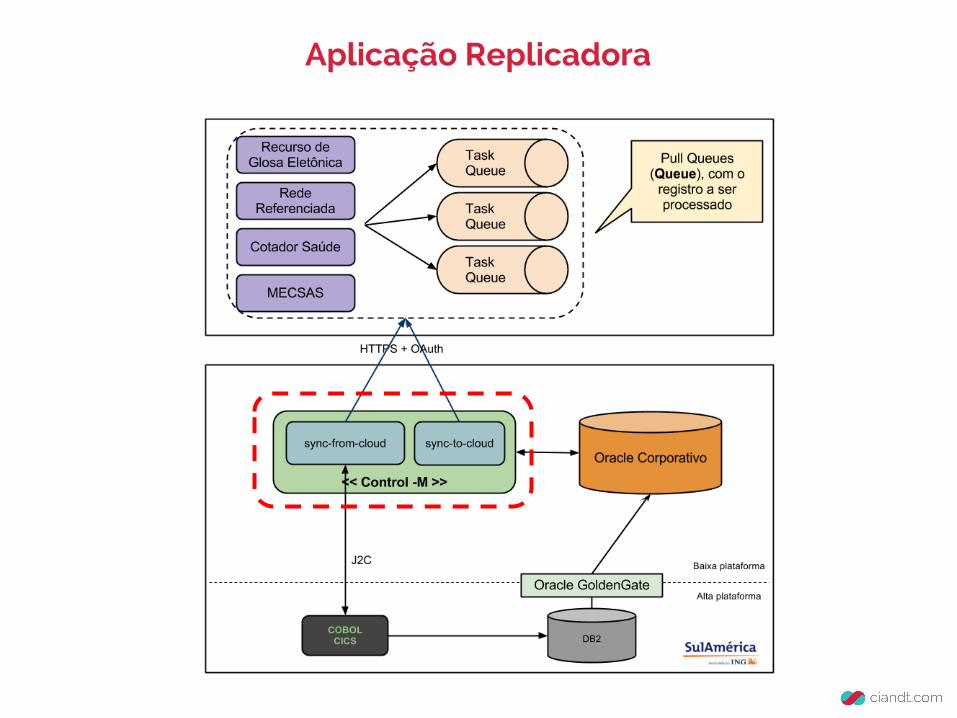
Aplicação Replicadora

● Conjunto Spring Batch + Control-M (Scheduler)
● Autenticação com a núvem via OAuth
● Consumo do TaskQueue
● Envio do processamento ao COBOL CICS (online) - Regra de negócio!
Aplicação Replicadora

● Processamentos com erro são devolvidos na hora
● ATOMICIDADE da transação MANUAL! Não há suporte a XAÚltima linha do processo é excluir a Task
Aplicação Replicadora
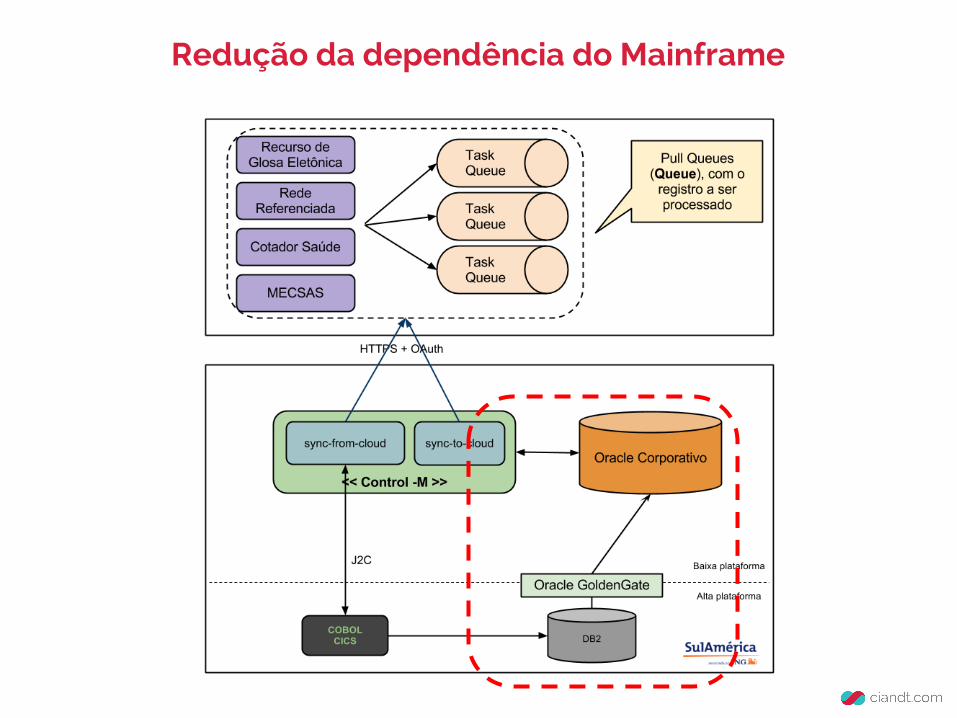
Redução da dependência do Mainframe

● Replicação de dados Online (Quente) do DB2 Mainframe para o Oracle via Oracle GoldenGate
● Replicação via UNDO tablespace, baixo custo na origem!
● Timestamp de replicação (Temos o Delta!)
Redução da dependência do Mainframe

Subida do resultado do processamento

● Uso do Remote API do AppEngine (Acesso direto ao Datastore)
● Conexão JDBC/OAuth com CloudSQL
● Liberação do registro ou críticas de processamento ao usuário
● Throughput atende!~2k registros/seg = 4mb/seg
Replicação - Resultado do processamento

Governança dos Dados

● Dados corporativos, comuns a todas as aplicações
● Rastreabilidade e consistência das informações
Requisito

● Cada App possui seu próprio domínio de dados (Datastore e/ou CloudSQL)
● Quem produz o dado é responsável por ele
● Dados comuns (corporativos) centralizados
Solução
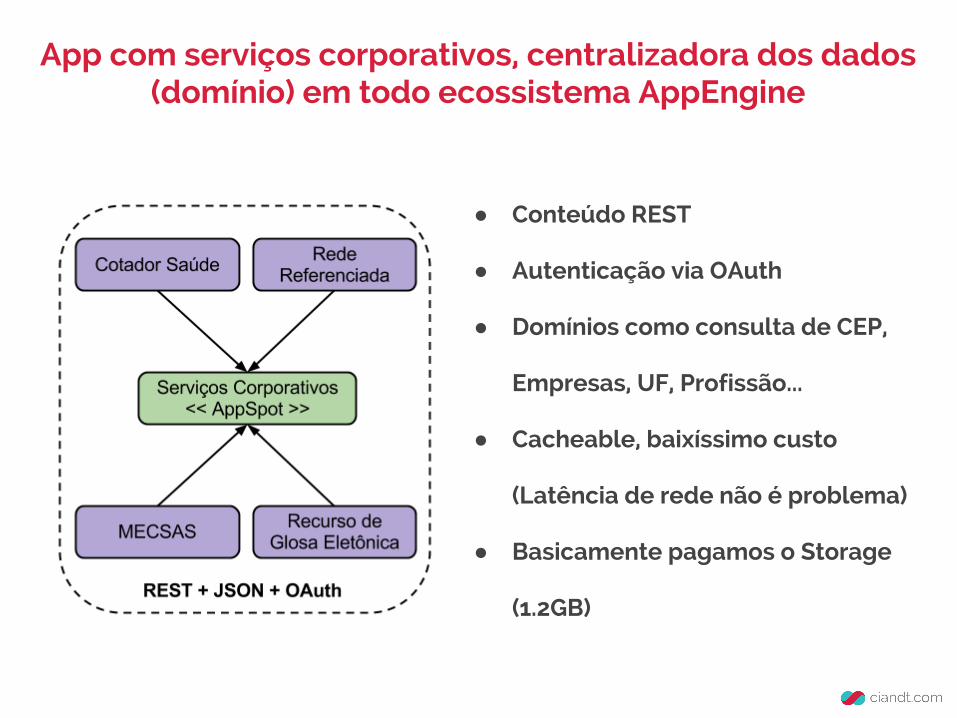
App com serviços corporativos, centralizadora dos dados (domínio) em todo ecossistema AppEngine
● Conteúdo REST
● Autenticação via OAuth
● Domínios como consulta de CEP,
Empresas, UF, Profissão...
● Cacheable, baixíssimo custo
(Latência de rede não é problema)
● Basicamente pagamos o Storage
(1.2GB)

● Gestão de volume, autorizações e escalabilidade no contexto específico da app corporativa
● Dashboard do AppEngine específico, gestão mais eficaz
Controle da aplicação corporativa

Busca Geolocalizada por proximidade

O Objetivo

● Endereços na base armazenados como “Avenida Paulista, 1000, São Paulo”
● Conversão para Latitude/Longitude
● Google Geocoding API
Geocodificação dos endereços

● Limite de até 2,5k conversões por dia (100k para clientes premier ;) )
● Free
● Só pode usar se plotar o resultado no Mapa do Google Maps!!!
Geocodificação dos endereços

Mas como fazer as buscas por proximidade??

● Janeiro de 2011!
● Ferramenta promissora da Google, recém lançada!
● Em fase Experimental!
“É o risco da inovação!”
Cenário

Google Fusion Tables
● Cláusulas e funções como ORDER
BY DISTANCE, CIRCLE, INTERSECTs
● Performance OK! Escalabilidade
não tão ok...
Bateria Throughput %90 Samples
1 5 req/seg ~1 seg 70k
2 8,3 req/seg 3.3 segs 250k

● Mudanças constantes no comportamento da API (App parada em produção)
● API foi descontinuada 6 meses depois
● Hoje ainda existe, API reestruturada
“É o risco da inovação!”
Google Fusion Tables
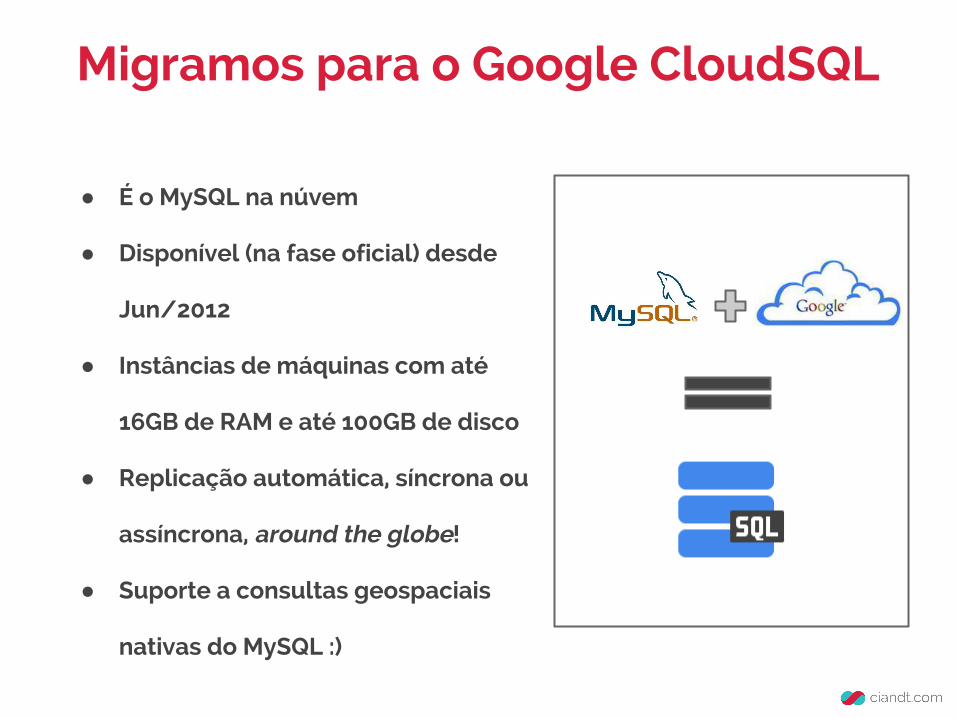
Migramos para o Google CloudSQL
● É o MySQL na núvem
● Disponível (na fase oficial) desde
Jun/2012
● Instâncias de máquinas com até
16GB de RAM e até 100GB de disco
● Replicação automática, síncrona ou
assíncrona, around the globe!
● Suporte a consultas geospaciais
nativas do MySQL :)

● MySQL possui suporte a datatypes de geometria, GEOMETRY, POINT, CURVE, POLYGONOpenGIS Geometry Model
● Tabelas do tipo MyISAM, InnoDB não tem suporte!
● Índice R-Tree para consulta geométricaCREATE SPATIAL INDEX sp_index ON mytable (g);
How it works?!

● O conceito permite buscas indexadas retornando se o ponto está dentro de um polígono (MBRWithin / MBRContains)
● Ou se polígonos se cruzam
● Não dá pra indexar busca por distância
How it works?!

● O jeito é montar um polígono e obter os pontos que estão dentro!
● E depois calcular a distância “na mão”
( 6371 * acos( cos( radians(Latitude) ) * cos( radians( X(LATLONG) ) ) * cos( radians( Y(LATLONG) ) - radians(Longitude) ) + sin( radians(Latitude) ) * sin( radians( X(LATLONG) ) ) ) ) AS DISTANCE !!!!!!
How it works?!

How it works?!

SELECT *FROM (
SELECT *, ( 6371 * acos( cos( radians(1) ) * cos( radians( X(LATLONG) ) ) * cos( radians( Y(LATLONG) ) - radians(1.1) ) + sin( radians(1) ) * sin( radians( X(LATLONG) ) ) ) ) AS DISTANCE
FROM MAPA_ATENDIMENTO
WHERE MBRWithin( LATLONG, Envelope( GeomFROMText( 'LineString( X Y , X Y)'))
) innerWHERE inner.DISTANCE <= Z
How it works?!

● Performance bastante adequada nas consultas
Performance do CloudSQL

● O CloudSQL trabalha nativamente com replicação around the globe.
● Configurável: Síncrona ou Assíncrona
● Síncrona: Insert/Update/Delete são replicados dentro do statement
● Assíncrona: Insert/Update/Delete são replicados fora do statement
Ponto interessante sobre o CloudSQL

● A percepção de performance é notável, fizemos o teste:
○ Síncrono: 10K inserts com commit de 500 em 50010 segundos
○ Assíncrono: 10k inserts com commit de 500 em 5005 segundos
Ponto interessante sobre o CloudSQL

● Recomendação:
○ Configure assíncrono sempre que possível!
Acredito que atende 99% dos projetos que tenham constantes atualizações de dados
Ponto interessante sobre o CloudSQL

Upload & Download de Arquivos

● Resumable Uploads
● Espaço ilimitado
● Billing por volume armazenado + network traffic
Google CloudStorage

● API de integração no AppEngine SDK (Blobstore API)
blobstoreService.createUploadUrl("/uploaded",
UploadOptions uploadOptsWithBucketName);
blobstoreService.getUploads(request); //File info (BlobKey)
Uploading files

Exportação da base, de forma analítica (~600.000 registros) em CSV
Requisito
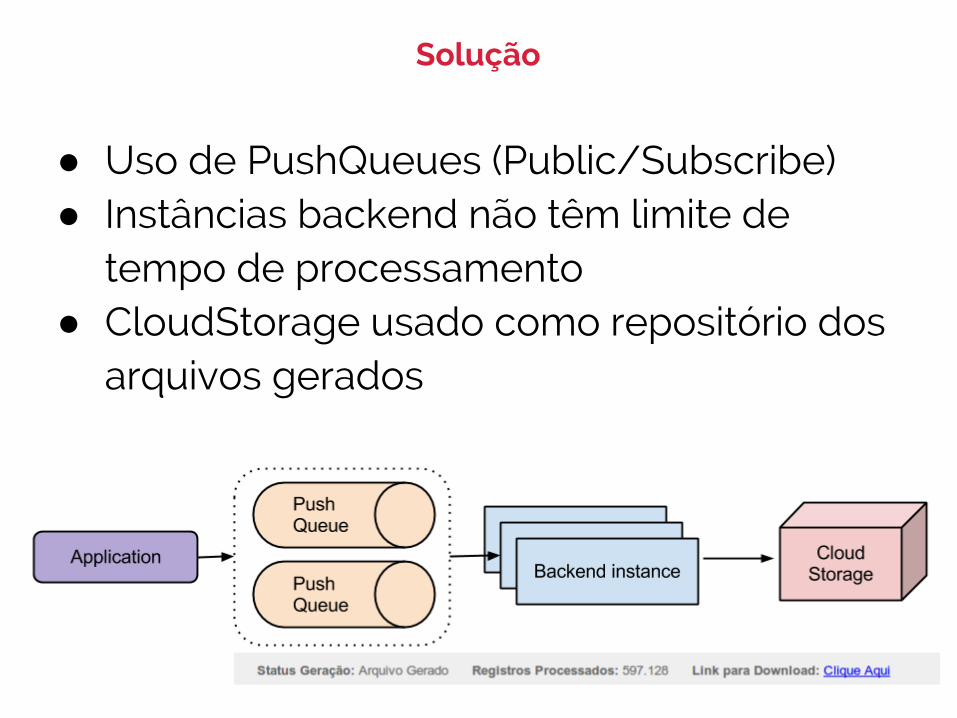
● Uso de PushQueues (Public/Subscribe)● Instâncias backend não têm limite de
tempo de processamento● CloudStorage usado como repositório dos
arquivos gerados
Solução

Lições aprendidas

● A SDK não implementa 100% da especificação
● Mas calma, é quase lá…
AppEngine SDK não é JEE

● Java Data Objects (JDO) ● Java Persistence API (JPA) ● Java Server Faces (JSF) 1.1 - 2.0● Java Server Pages (JSP) + JSTL ● Java Servlet API 2.4● JavaBeans™ Activation Framework (JAF)● Java Architecture for XML Binding (JAXB)● Java API for XML Web Services (JAX-WS)● JavaMail● XML processing APIs including DOM, SAX, and XSLT
Componentes mais comuns suportados

● Enterprise Java Beans (EJB)● JAX-RPC● Java Database Connectivity (JDBC)● Java EE™ Connector Architecture (JCA)● Java Management Extensions (JMX)● Java Message Service (JMS)● Java Naming and Directory Interface (JNDI)● Remote Method Invocation (RMI)
Tentativa de categorizar o que funciona ou não::
https://code.google.com/p/googleappengine/wiki/WillItPlayInJava
O que não é compatível

● Spring Framework 3.2
● Hibernate 4.2 (Apenas com CloudSQL)
● JSF 2.1 + Primefaces 3.5 (Precisamos de alguns
workarounds)
● iText 2.1.7 (Adaptado)
● Objectify 3.1
O que usamos

● Framework ORM para Datastore● Encapsula acessos através de annotations com a
mesma nomenclatura do JPA (@Transaction, @Entity) e outras extensões
● Cache automático usando o MemCache
@Entityclass Car { @Id String vin; // Can be Long, long, or String String color;}ofy().save().entity(new Car("123123", "red")).now();Car c = ofy().load().type(Car.class).id("123123").get();ofy().delete().entity(c);
Objectify
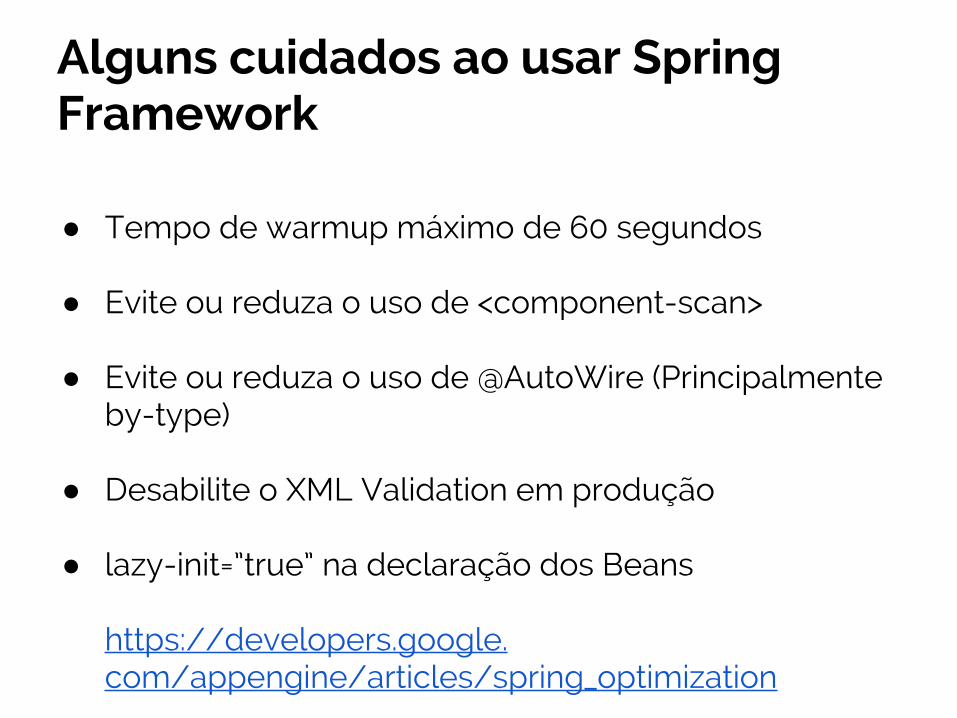
Alguns cuidados ao usar Spring Framework
● Tempo de warmup máximo de 60 segundos
● Evite ou reduza o uso de <component-scan>
● Evite ou reduza o uso de @AutoWire (Principalmente by-type)
● Desabilite o XML Validation em produção
● lazy-init=”true” na declaração dos Beans
https://developers.google.com/appengine/articles/spring_optimization

Nosso warmup
● 250 beans (@Component)
● Usando component-scanning = Estourou os 60 segs com ~160 Beans
● Warmup de 38 segundos apenas removendo o component-scanning + lazy-init

Environment & Delivery
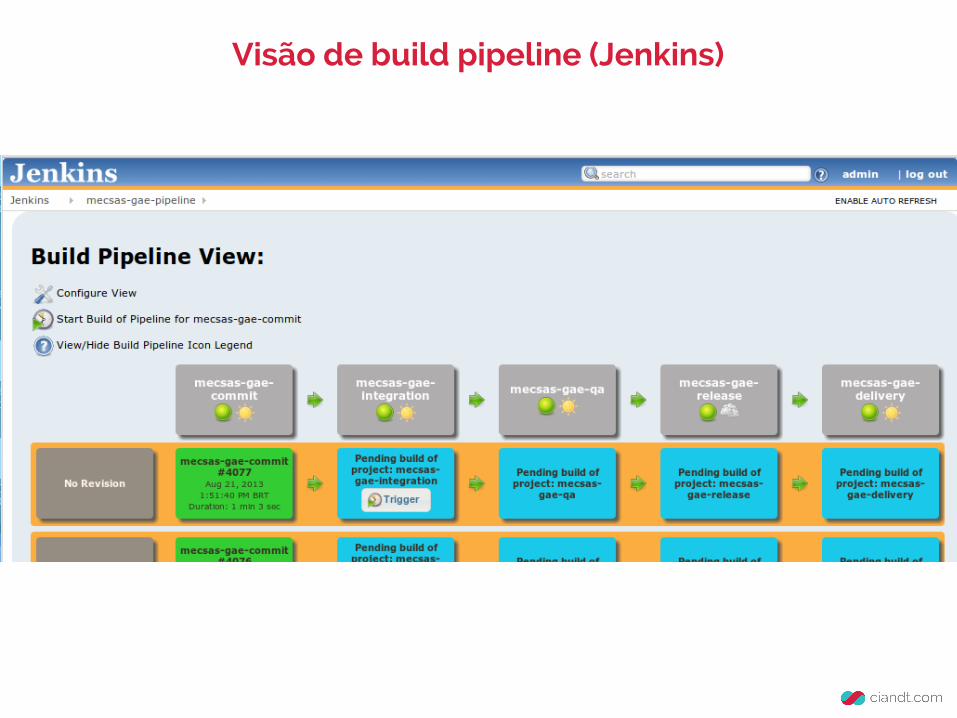
Visão de build pipeline (Jenkins)

● Fácil integração Jenkins + AppCfg para deployment automatizado
● Baixíssimo custo para termos ambientes de Integration + QA + UAT
● Gastamos hoje US$ 400,00 com:○ Amazon: Máquina Jenkins + Sonar + Nexus + RDS
(Sonar)○ Ambientes AppEngine e CloudSQL (Uma app p/
cada ambiente)
Deployment ágil

● Versão atribuída na build via Maven Release Plugin dentro do appengine-web.xml
● Permite deployment e acesso a versões separadas no ambientehttp://1-2-1.minhaapp.appspot.com
● Usuário homologa defeitos em “pré-produção” antes de liberá-la
Versionamento

● Ambientes na mesma infra de produção
● Testes de carga/stress não necessitam usar produção
● AppEngine Dashboard extremamente útil
Architecture Validation

Pra finalizar!

● Cliente extremamente “comprado” na tecnologia
● A conversa de novos projetos inicia com “Faz sentido fazermos no AppEngine?”
● Segundo a Google, é o cliente que mais usa a suite de produtos Google Enterprise no Brasil!
Satisfação geral!

● Hoje a SulAmérica gasta com todas as aplicações + CloudStorage + CloudSQL + Ambientes QA/UAT/PRD+ Premier Support
Em média US$ 1600,00
● Uma máquina de servidor de aplicação tradicional, com backup e hospedada no fornecedor:~ US$ 30.000,00
E o principal… CUSTO!

VISITEM NOSSO
ESTANDE!!