freebsd network stack performance srinivas krishnan university of north carolina at chapel hill
Post on 22-Dec-2015
221 views
TRANSCRIPT

FreeBSD Network Stack Performance
Srinivas KrishnanUniversity of North Carolina at
Chapel Hill

Outline
Introduction Unix network stack improvements Bottlenecks
Memory Copies Interrupt Processing
Zero Copy Implementation Receive Live Lock Solution
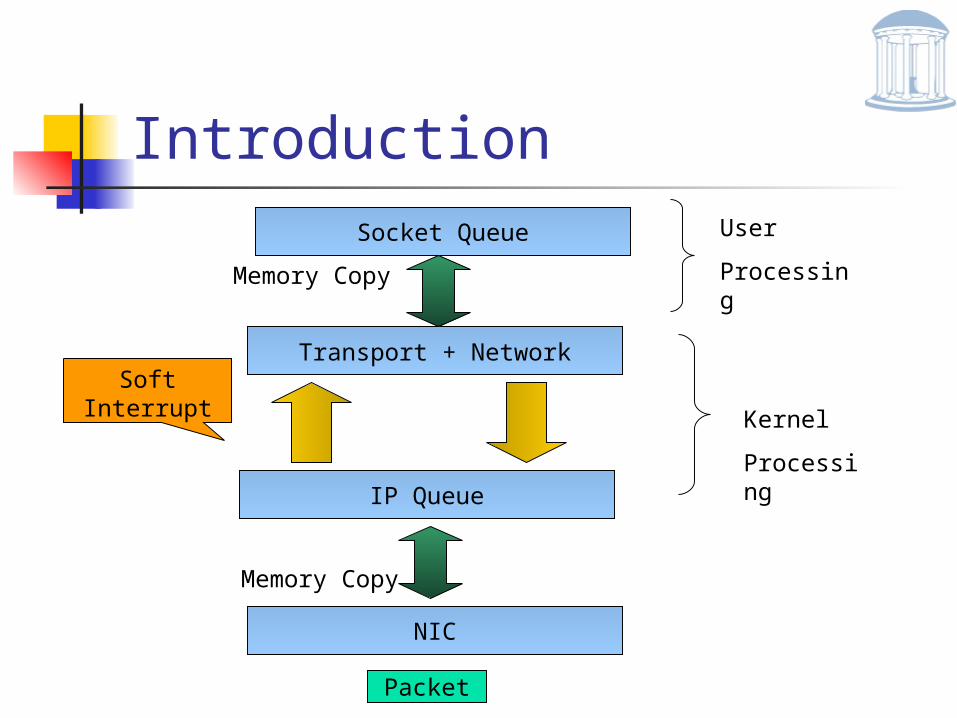
Introduction
NIC
IP Queue
Packet
Transport + Network
Socket Queue
SoftInterrupt
Memory Copy
Memory Copy
Kernel
Processing
User
Processing

Network Stack Reinvented
Van Jacobson Net Channels Create a High Speed Channel from
NIC to User space Push all processing to the user space Applying E2E “truly” Preserve cache coherency for multi-
processor systems
BETTER INTERRUPT PROCESSING

Network Stack Reinvented
Ulrich Drepper’s Asynchronous Network I/O Asynchronous sockets True Zero Copy No Locking Event Channels
BETTER MEMORY PROCESSING

Reduce Memory Copies
Sending Side Copy from User Buffer to Kernel Buffer Copy from Kernel Buffer to Device Buffer
Receive Side Copy from Device Buffer to Kernel Buffer Copy from Kernel Buffer to Socket Buffer
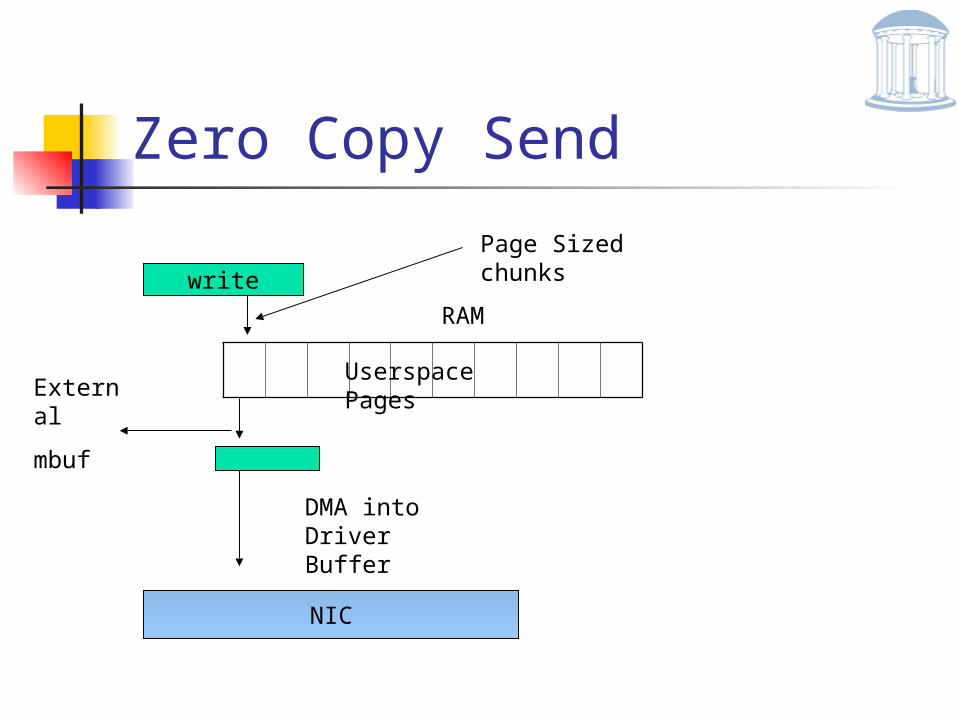
Zero Copy Send
write
Userspace Pages
RAM
Page Sized chunks
External
mbuf
DMA into Driver Buffer
NIC
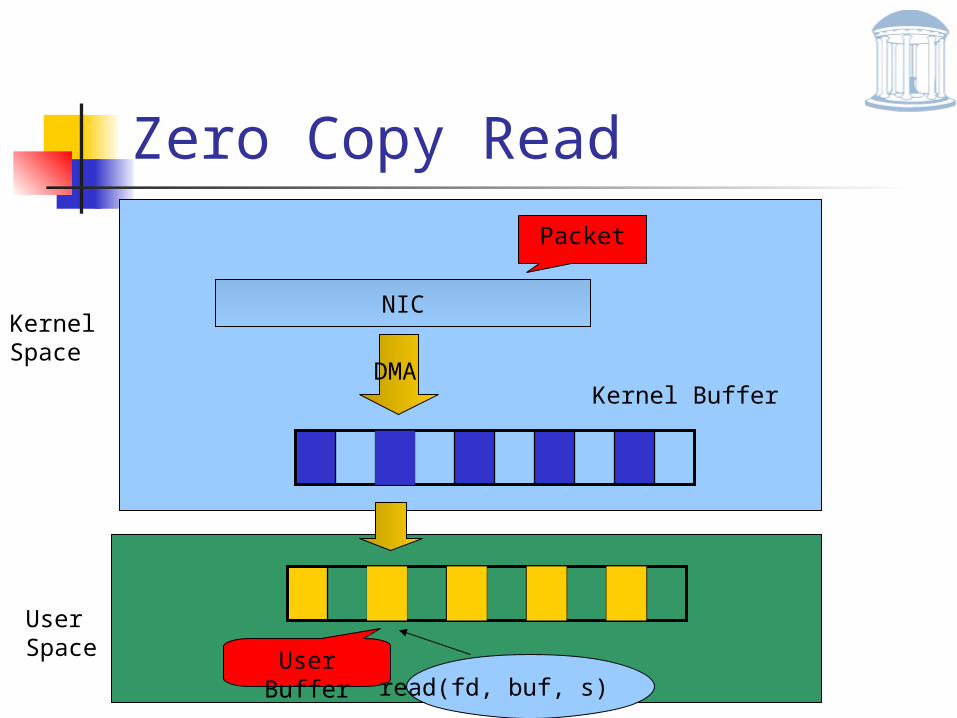
Zero Copy Read
NIC
Packet
Kernel BufferDMA
Kernel Space
User Space User Buffer
read(fd, buf, s)

Zero Copy
Allocate an External Mbuf Pool NIC MTU has to be >= 4K Intel Pro1000 NIC with Jumbo
Frames 3Com NIC turn on DMA
Buffer and stitch the data together Added Overhead

Page Flipping
Check Mbuf len
Page Size
! 1 PageUse
copyout
Usevm_pgmoveco (……)
Kernel Page <->User Pageread(….)
Atleast 1 Page
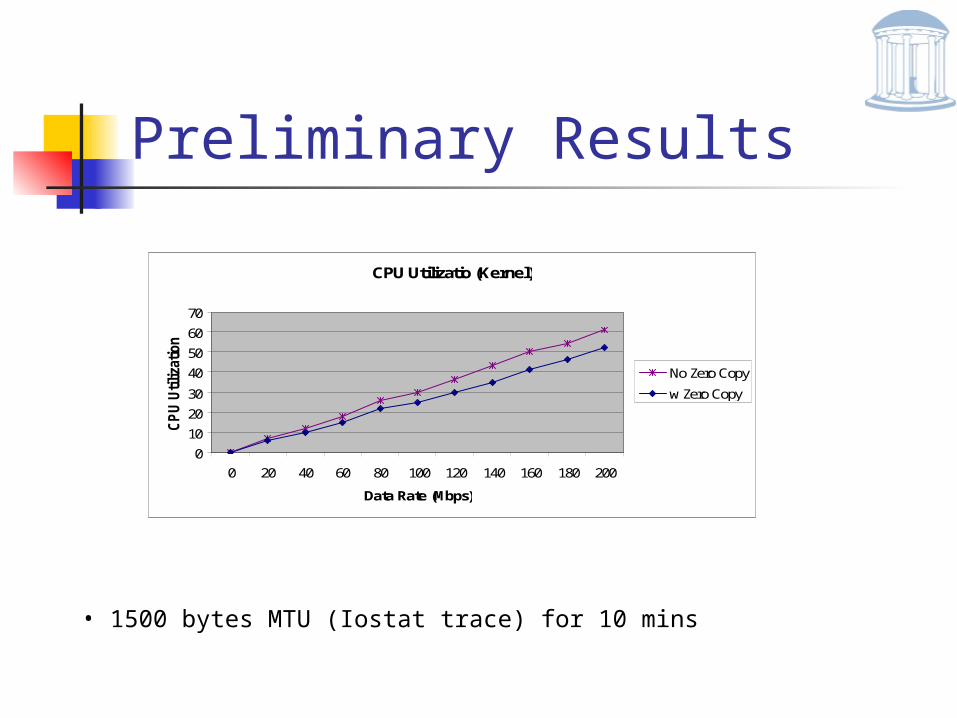
Preliminary Results
CPU Utilizatio (Kernel)
0
10
20
30
40
50
60
70
0 20 40 60 80 100 120 140 160 180 200
Data Rate (Mbps)
CP
U U
tiliza
tion (%
)
No Zero Copy
w Zero Copy
• 1500 bytes MTU (Iostat trace) for 10 mins

Processing Interrupts
Main Processing Hard Interrupt from NIC to driver Soft Interrupt from IP Queue to
processing Reduce user level and interrupt
thread processing Problem: Receive Live Locks

Receive Live Lock
Send large stream of UDP packets > receiver buffer capacity
CPU spent processing network packets
Goodput = 0
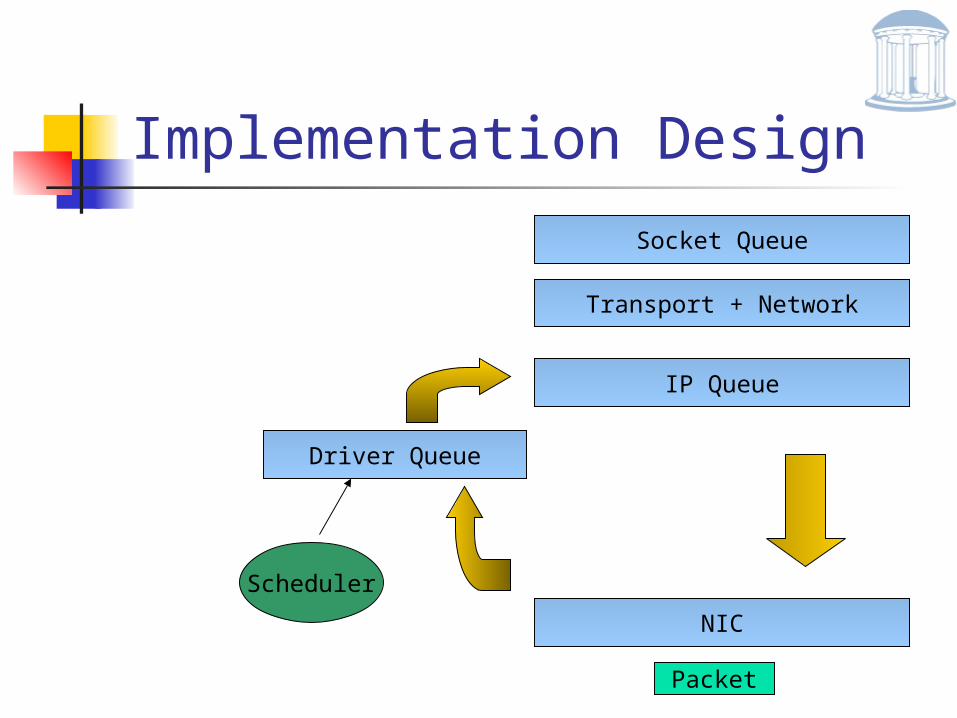
Implementation Design
NIC
IP Queue
Packet
Transport + Network
Socket Queue
Driver Queue
Scheduler

Components All UDP packets are queued in
driver queue Scheduler is triggered with the
arrival of first UDP packet Checks the queue every n ms
(currently 1-2ms) Schedules packet departure rate
based on timestamps

Driver Queue Algorithm
Set maximum rate and average rates
Driver Queue maintains Average Queue Length (Weighted
over time) Current Rate of transfer Time stamp of packets

Algorithm (cont) If current_rate > average rate
Drop N packets such that current_rate == average_rate
If current_rate > max rate (Spike) Drop all packets
Reduce Time Wait in Queue If Current Queue Size < threshold
Schedule packet exit such that rate == average_rate
Appends an exit time to each packet

Pros and Cons
Easy implementation requires no scheduling changes
Reduces CPU utilization in worst case by ~25%
Low Overhead Introduces added jitter
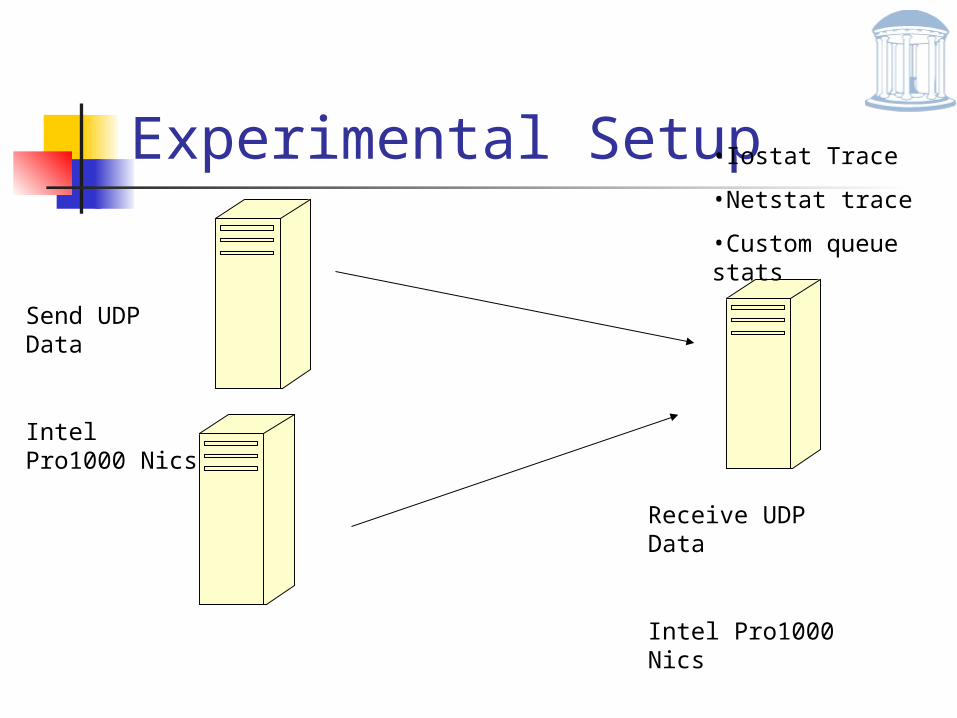
Experimental Setup
Receive UDP Data
Intel Pro1000 Nics
Send UDP Data
Intel Pro1000 Nics
•Iostat Trace
•Netstat trace
•Custom queue stats

Queue Stats
At the Receiver Collect Average Queue Size CPU Utilization Packet Drops Total Number of packets processed
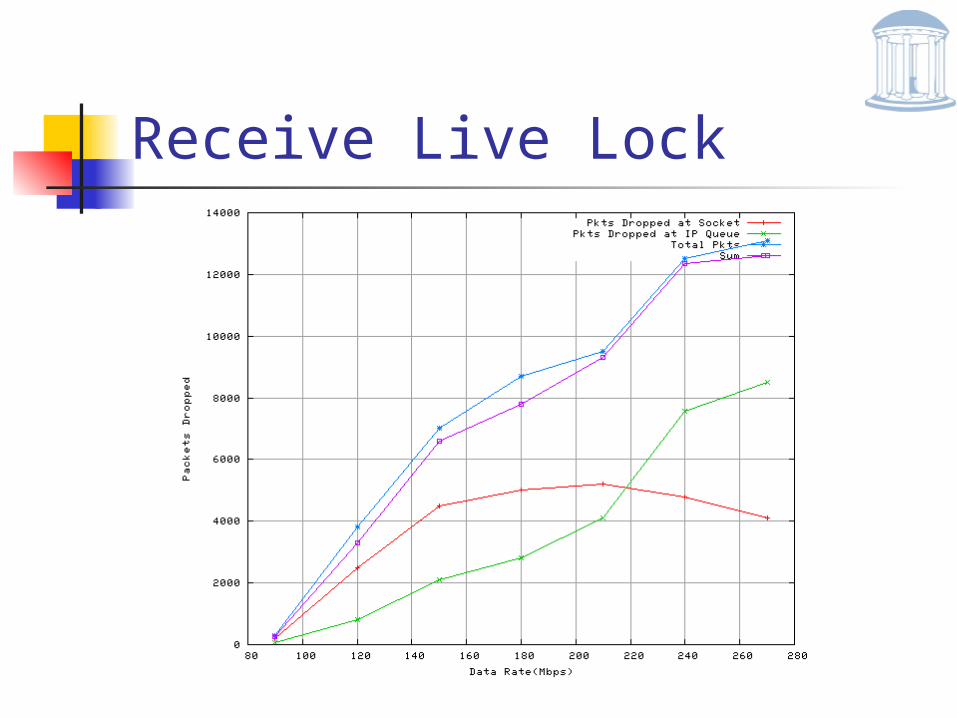
Receive Live Lock

Receive Live Lock (soln)

Future Work
Feedback from Socket Queue and IP queue such that Weighted Average computed over all 3 queues
Drop at driver before DMA Driver buffer not large enough to keep
weighted queue size Feedback from Driver Queue Scheduler
to driver to drop

Questions ?