figure 11.1 an 8-puzzle problem instance: (a) initial ...karypis/parbook/figures/chap11.pdf · 9 1...
TRANSCRIPT

(a)
Blank tile
(b)
Last tile moved
(c)
1 4
1
4
2
7 7
8
5 2
3
3
8
5
1
6
3
6
6
8
6
3
2 5
8
7 6
3 4
5
8
7 4
1
2
4
1
7 6
5 2 5
7
4
8
1
7 6
3
2 5
4
4
8
1
5
7 6
3
2
2
2
4
8
1
5
7 6
3
2 3
4
8
1
5 6
7
3
2 3
4
8
1
5
7 6
8
1up up
left
left down
down
leftupup
Figure 11.1 An 8-puzzle problem instance: (a) initial configuration; (b) final configuration; and (c)a sequence of moves leading from the initial to the final configuration.

Non-terminal node
Terminal node (goal)
Terminal node (non-goal)
x1 = 0 x1 = 1
x2 = 0 x2 = 1
x3 = 0 x3 = 0x3 = 1 x3 = 1
x4 = 0x4 = 0 x4 = 1x4 = 1
f (x) = 0 f (x) = 2
Figure 11.2 The graph corresponding to the 0/1 integer-linear-programming problem.
(a)
4
3
2
1
3
1
2
4
5 6
7
8
10
9 8
32
6
44
565
7 7 7 7
(b)
89
10 10
9
10 10
8 9 8
1
10 10
9
10 10
2
98
7
98
7
6
7
98
6 5
4
3
1
5
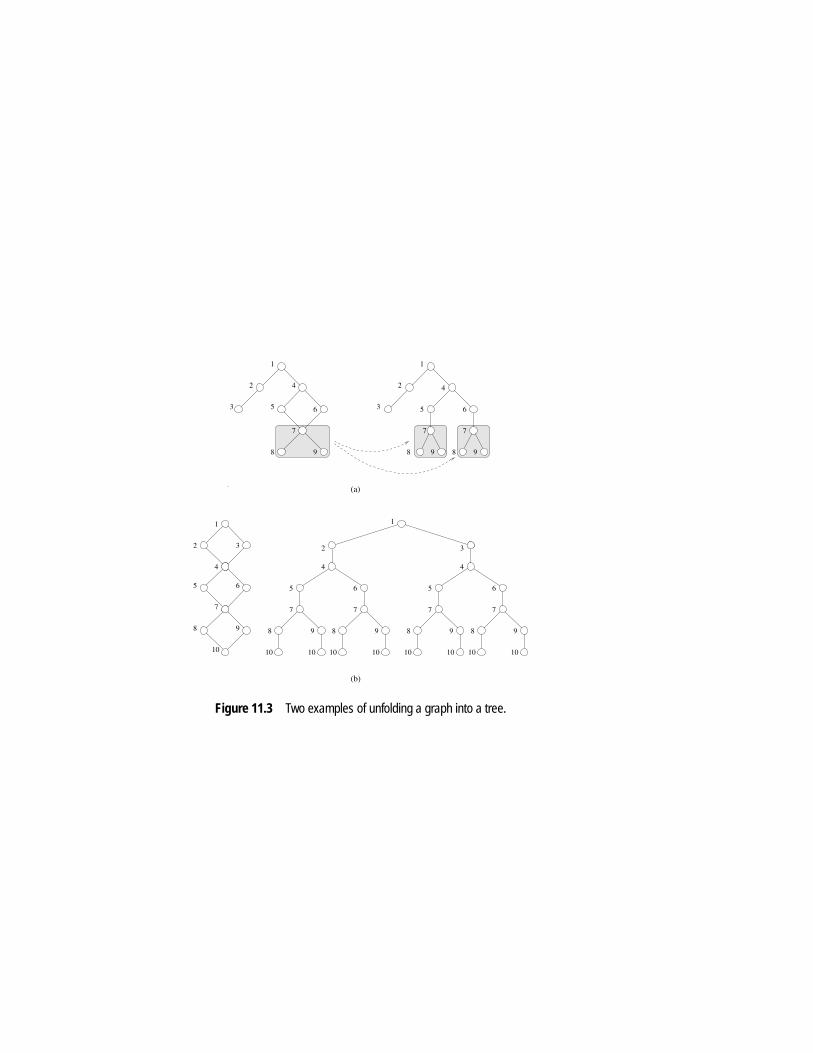
Figure 11.3 Two examples of unfolding a graph into a tree.

8
7
1
6 5 4
2
4
3
1
6 5
8
2 7
4
8
7 3
6
5
2 3
4
8
7
1
6 5
2
1
7
1
6
5
3
8
2 3
4
8
7
1 5
6
2 3
4
8
7
1
6
5
4
4
8
7
1
6
5
3
2
3 2
A
D E F
G H
CB
down
downrightup
up right
right
The last tile moved
Blank tile
Step 3
Step 2
Step 1
Figure 11.4 States resulting from the first three steps of depth-first search applied to an instanceof the 8-puzzle.

(c)(a) (b)
15 16 17
20
18 19
21
22 23 24
1
2
7 8 9
10 11
12 13 14
Bottom of the stack
11
Top of the stackCurrent State
3
545
4
9
811
14
19
14
17
16
19
24
23
6
543 1
242321
18
15
171613
10
7
98
Figure 11.5 Representing a DFS tree: (a) the DFS tree; successor nodes shown with dashed lineshave already been explored; (b) the stack storing untried alternatives only; and (c) the stack storinguntried alternatives along with their parent. The shaded blocks represent the parent state and theblock to the right represents successor states that have not been explored.

(a)
(c)
(b)
2 3
4
7
1
6 5
8
2 3
4
8
7
1
6
5
2 3
4
8
7
1
6 5
7
6
7
Step 1
2 3
4
8
7
1
6 5
2 3
4
8
7
1
6
5
2 3
4
7
1
6 5
8
2
4
8
7
1
6
5
3
2 3
4
8
7
1 5
6
2 3
4
7
1 5
6
3
4
8
7
1 5
6
2 3
8
7
1 5
6 8 2 4
6
7 7
Step 2
8 6
7
7
7
Step 1
2 3
4
8
7
1
6 5
1 2 3
4 5 6
7 8 The last tile moved
Blank Tile
2 3
4
8
7
1
6 5
2
8
7
1
6
5
2 3
4
7
1
6 5
8
2 3
4
8
7
1 5
2
4
8
7
1
6 6
5
3
6
7
Step 2
7
8 6
Step 1
2 3
4
7
6 5
8 1
2 3
4
8
7
1
6 5
2 3
4
8
7
1
6
5
2 3
4
7
1
6 5
8
3
2 3
4
7
1
5
8 6
7
2
4
8
7
1
6
5
3
2 3
4
8
7
1 5
6
2 3
4
7
1 5
6
3
4
8
7
1 5
6
2 3
8
7
1 5
6 8 2 4
6
7
Step 2 Step 4
8
6 8
7
7
7
8
Step 1
Step 3
4
Figure 11.6 Applying best-first search to the 8-puzzle: (a) initial configuration; (b) final configura-tion; and (c) states resulting from the first four steps of best-first search. Each state is labeled withits h-value (that is, the Manhattan distance from the state to the final state).

C E F
BA
(a) (b)
D
Figure 11.7 The unstructured nature of tree search and the imbalance resulting from static parti-tioning.

Service any pending
messages
Do a fixed amount of work
Select a processor and
request work from it
Service any pending
messages
Finished
available
work
Got
work
Issued a request
Got a reject
Processor idle
Processor active
Figure 11.8 A generic scheme for dynamic load balancing.

(a) (b)
14
43
16
1413
10
87
1
4
8
16
5
23
24
19
17
11
9
1
7 9
10 11
13
15 17
18 19
21
22 23 24
3 5
Cutoff depth
Current State
Figure 11.9 Splitting the DFS tree in Figure 11.5. The two subtrees along with their stack repre-sentations are shown in (a) and (b).

Step 1 Step 3
Step 5
Step 2
Step 6Step 4
w0 = 0.5
w0 = 0.5
w0 = 0.5
w0 = 0.25
w0 = 0.25
w0 = 1.0
w1 = 0.5 w1 = 0.5
w1 = 0.5 w1 = 0.25w1 = 0.25
w2 = 0.25 w2 = 0.25
w3 = 0.25
w3 = 0.25
Figure 11.10 Tree-based termination detection. Steps 1–6 illustrate the weights at various pro-cessors after each work transfer.
0
100
200
300
400
500
600
700
0 200 400 600 800 1000 1200
ARRGRR
RP
p
Spee
dup
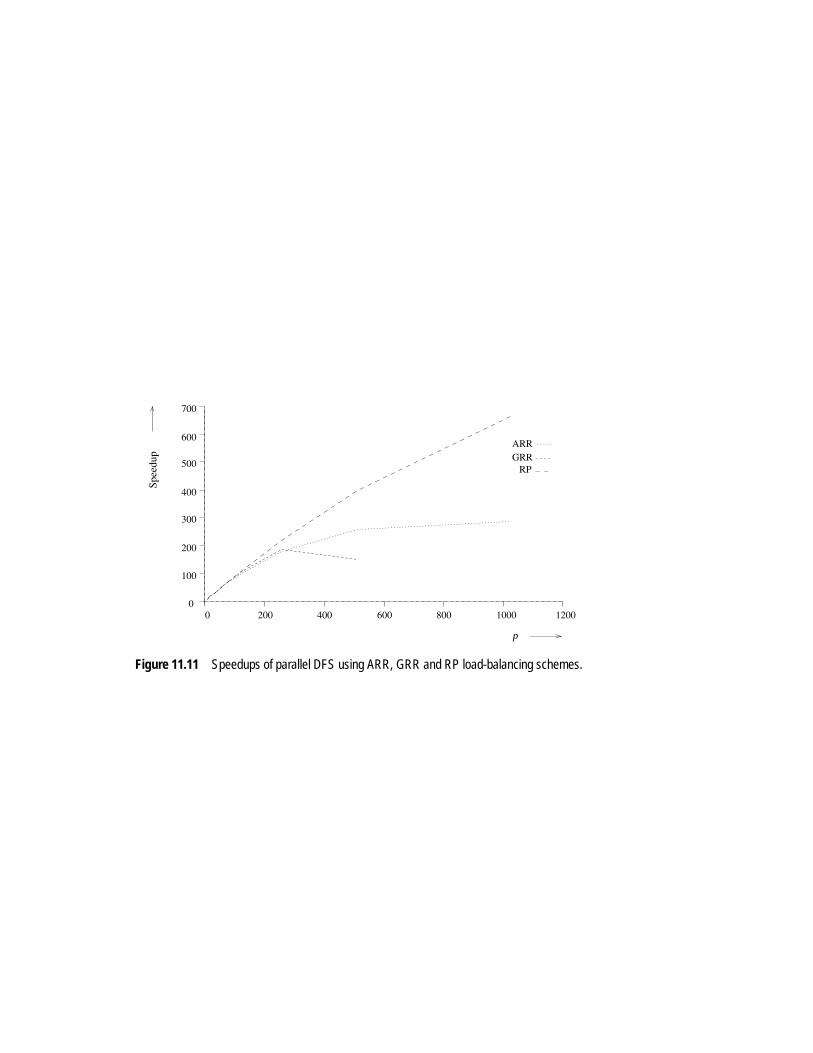
Figure 11.11 Speedups of parallel DFS using ARR, GRR and RP load-balancing schemes.

GRRExpected (GRR)
RPExpected (RP)
00
100000
300000
500000
700000
900000
200 400 600 800 1000 1200
p
Num
ber
of w
ork
requ
ests
Figure 11.12 Number of work requests generated for RP and GRR and their expected values(O(p log2 p) and O(p log p) respectively).

00
1.5e+07
2e+07
2.5e+07
5e+06
1e+07
E = 0.74E = 0.85E = 0.90
E = 0.64
20000 40000 60000 80000 100000 120000
W
p log p2
Figure 11.13 Experimental isoefficiency curves for RP for different efficiencies.

Number of busyProcessors
Number of busyProcessors
Number of busyProcessors
Time
(a)
(b)
(c)
Time
Time
Figure 11.14 Three different triggering mechanisms: (a) a high triggering frequency leads to highload-balancing cost, (b) the optimal frequency yields good performance, and (c) a low frequencyleads to high idle times.
Idle
Busy
1 2 3 4 5 6
4321765
Global pointer
Global pointer
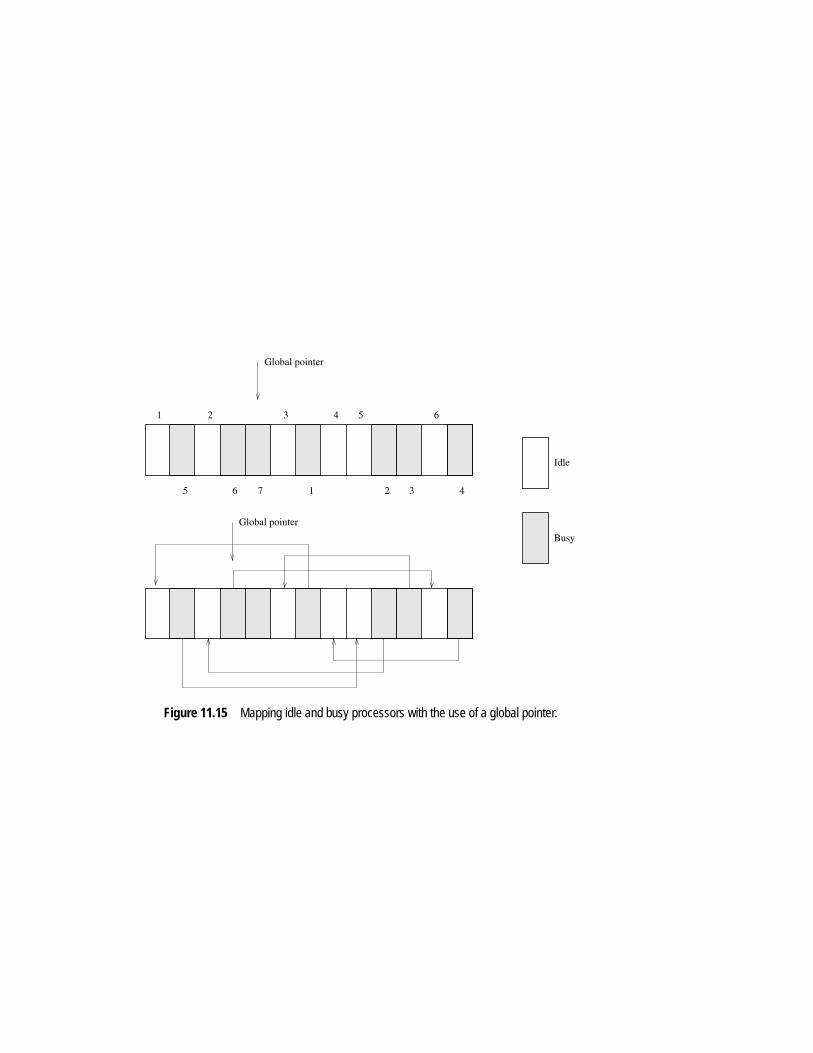
Figure 11.15 Mapping idle and busy processors with the use of a global pointer.

Expand the node to
generate successors
Expand the node to
generate successors
Expand the node to
generate successors
at designated processorGlobal list maintained
best node
nodes
Put expanded
Getcurrent
Pick the best node
from the list
Place generated
nodes in the list
Pick the best node
from the list
Place generated
nodes in the list
Unlock the list
Pick the best node
from the list
Place generated
nodes in the list
Unlock the listUnlock the list
Lock the list
Lock the list
Lock the list
P0
P1
Pp−1
Figure 11.16 A general schematic for parallel best-first search using a centralized strategy. Thelocking operation is used here to serialize queue access by various processors.

Exchangebest nodes
Exchangebest nodes
Exchangebest nodes
Local list
Local list
Local list
P0
P1
Pp−1
Figure 11.17 A message-passing implementation of parallel best-first search using the ring com-munication strategy.

Exchangebest nodes
Exchangebest nodesLocal list
Local list
Local list
blackboard
Exchangebest nodes
P0
P1
Pp−1
Figure 11.18 An implementation of parallel best-first search using the blackboard communicationstrategy.

Start node SStart node S
(a)
1
2
3
5
6
7
Total number of nodes generated bysequential formulation = 13
Total number of nodes generated by
(b)
Goal node G Goal node G
two-processor formulation of DFS = 9
9
12
10
4
8
11
13
R1
R3 L2
L3
L1R2
R4
R5
L4
Figure 11.19 The difference in number of nodes searched by sequential and parallel formulationsof DFS. For this example, parallel DFS reaches a goal node after searching fewer nodes than se-quential DFS.

L1
L2
L3
L4
L5R7
R6
R5
R4R3
R1
R2
1
2
3 4
5
6
7
Total number of nodes generated by
(a) (b)
Total number of nodes generated by
Start node S Start node S
Goal node GGoal node G
sequential DFS = 7 two-processor formulation of DFS = 12
Figure 11.20 A parallel DFS formulation that searches more nodes than its sequential counterpart.

x+2
1 2
x+3 x+4x+1
11
11
11
Initially,
x+2 1
32
x+1x
x
x+3
After Increment,
x
x+2
000 001
010
100
110
101
111
011
target
target = x+5
000 001 010 011 100 101 110 111
000
000
100
000
010
100
110
= x
Figure 11.21 Message combining and a sample implementation on an eight-processor hypercube.

(manager)
Processors
Search treeSubtasks
Subtask generator
Work request
Figure 11.22 The single-level work-distribution scheme for tree search.