fast full parsing by linear-chain conditional random fields yoshimasa tsuruoka, jun’ichi tsujii,...
TRANSCRIPT

Fast Full Parsing by Linear-Chain Conditional Random Fields
Yoshimasa Tsuruoka, Jun’ichi Tsujii, and Sophia Ananiadou
The University of Manchester

Outline• Motivation
• Parsing algorithm• Chunking with conditional random fields• Searching for the best parse
• Experiments• Penn Treebank
• Conclusions

Motivation• Parsers are useful in many NLP applications– Information extraction, Summarization, MT, etc.
• But parsing is often the most computationally expensive component in the NLP pipeline
• Fast parsing is useful when– The document collection is large
– e.g. MEDLINE corpus: 70 million sentences– Real-time processing is required
– e.g. web applications

Parsing algorithms
• History-based approaches– Bottom-up & left-to-right (Ratnaparkhi, 1997)– Shift-reduce (Sagae & Lavie 2006)
• Global modeling– Tree CRFs (Finkel et al., 2008; Petrov & Klein 2008)– Reranking (Collins 2000; Charniak & Johnson, 2005)– Forest (Huang, 2008)

Chunk parsing• Parsing Algorithm
1. Identify phrases in the sequence.2. Convert the recognized phrases into new non-
terminal symbols.3. Go back to 1.
• Previous work– Memory-based learning (Tjong Kim Sang, 2001)• F-score: 80.49
– Maximum entropy (Tsuruoka and Tsujii, 2005)• F-score: 85.9

Parsing a sentence
Estimated volume was a light 2.4 million ounces .
VBN NN VBD DT JJ CD CD NNS .
QP
NP
VP
NP
S
Estimated volume was a light 2.4 million ounces .
VBN NN VBD DT JJ CD CD NNS .
QPNP
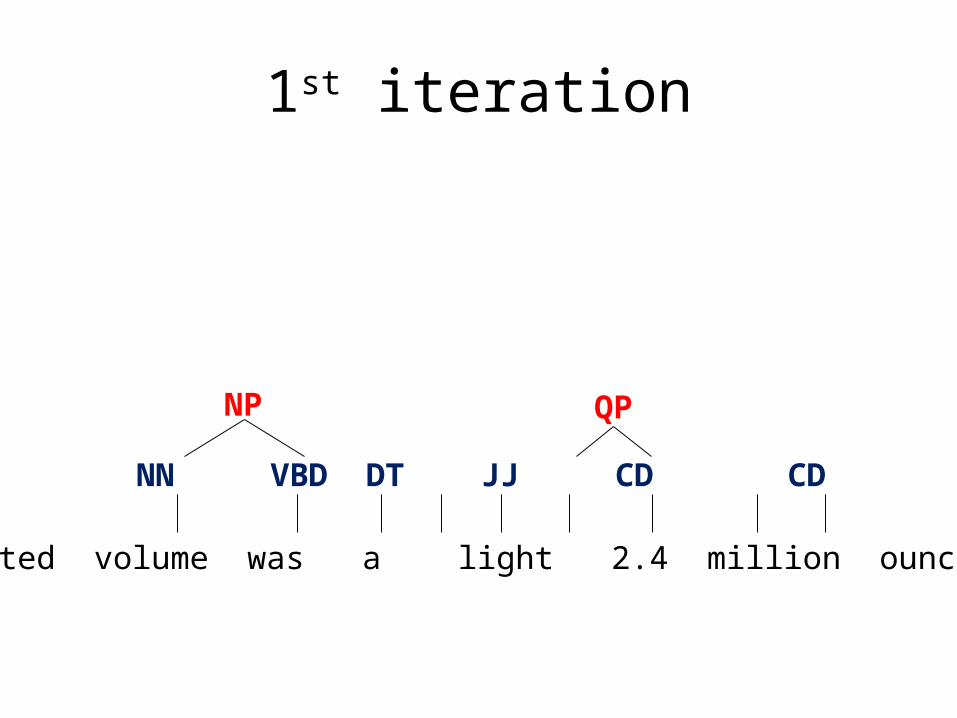
1st iteration

volume was a light million ounces .
NP VBD DT JJ QP NNS .
NP
2nd iteration
volume was ounces .
NP VBD NP .
VP
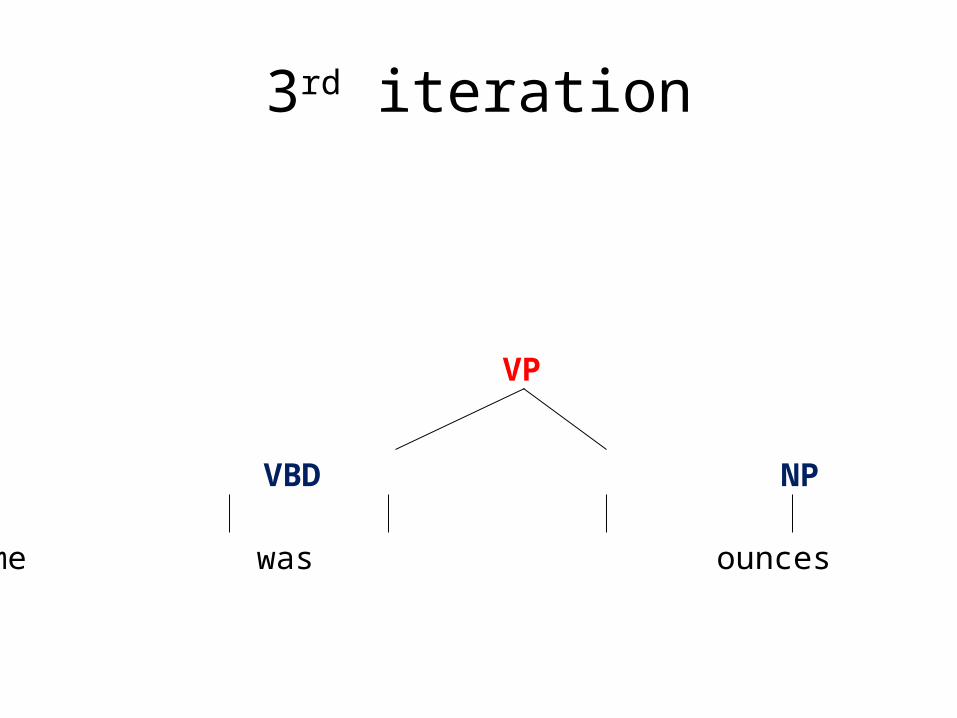
3rd iteration

volume was .
NP VP .
S
4th iteration

was
S
5th iteration

Estimated volume was a light 2.4 million ounces .
VBN NN VBD DT JJ CD CD NNS .
QP
NP
VP
NP
S
Complete parse tree

Chunking with CRFs
• Conditional random fields (CRFs)
• Features are defined on states and state transitions
Feature functionFeature weight
F
i
n
tttiin yytf
ZyyP
1 111 ,,,exp
1)|...( xx
Estimated volume was a light 2.4 million ounces .
VBN NN VBD DT JJ CD CD NNS .
QPNP

Estimated volume was a light 2.4 million ounces .
VBN NN VBD DT JJ CD CD NNS .
Chunking with “IOB” tagging
B-NP I-NP O O O B-QP I-QP O O
NP QP
B : Beginning of a chunk I : Inside (continuation) of the chunkO : Outside of chunks

Features for base chunking
Estimated volume was a light 2.4 million ounces .
VBN NN VBD DT JJ CD CD NNS .
?

Features for non-base chunking
volume was a light million ounces .
NP VBD DT JJ QP NNS .
NP
VBN NN
Estimated volume
?

Finding the best parse
• Scoring the entire parse tree
• The best derivation can be found by depth-first search.
h
iiipscore
0
| xy

Depth first searchPOS tagging
Chunking (base)
Chunking
Chunking Chunking
Chunking
Chunking (base)
Chunking
Chunking

Finding the best parse

Extracting multiple hypotheses from CRF
• A* search– Uses a priority queue– Suitable when top n hypotheses are needed
• Branch-and-bound– Depth-first– Suitable when a probability threshold is given
CRF
BIOOOB
0.3
BIIOOB
0.2
BIOOOO
0.18

Experiments• Penn Treebank Corpus– Training: sections 2-21– Development: section 22– Evaluation: section 23
• Training– Three CRF models
• Part-of-speech tagger• Base chunker• Non-base chunker
– Took 2 days on AMD Opteron 2.2GHz

Training the CRF chunkers
• Maximum likelihood + L1 regularization
• L1 regularization helps avoid overfitting and produce compact modes– OWLQN algorithm (Andrew and Gao, 2007)
i
ij
jj CpL xy |log

Chunking performance
Symbol # Samples Recall Precison F-score
NP 317,597 94.79 94.16 94.47
VP 76,281 91.46 91.98 91.72
PP 66,979 92.84 92.61 92.72
S 33,739 91.48 90.64 91.06
ADVP 21,686 84.25 85.86 85.05
ADJP 14,422 77.27 78.46 77.86
: : : : :
All 579,253 92.63 92.62 92.63
Section 22, all sentences
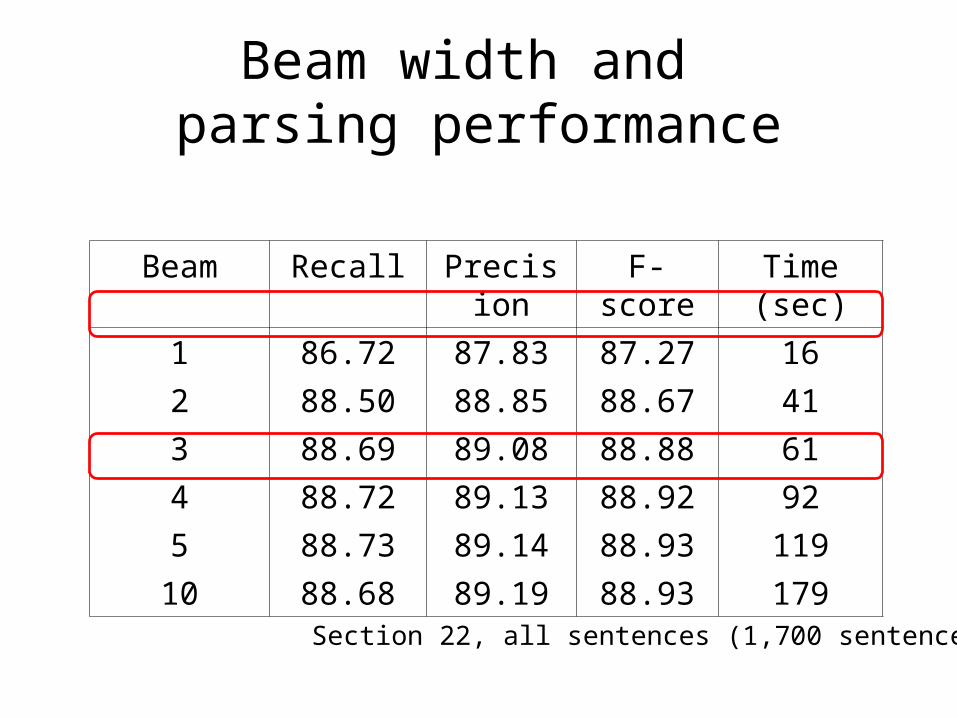
Beam width and parsing performance
Beam Recall Precision F-score Time (sec)
1 86.72 87.83 87.27 16
2 88.50 88.85 88.67 41
3 88.69 89.08 88.88 61
4 88.72 89.13 88.92 92
5 88.73 89.14 88.93 119
10 88.68 89.19 88.93 179
Section 22, all sentences (1,700 sentences)

Comparison with other parsers
Recall Prec. F-score Time (min)
This work (deterministic) 86.3 87.5 86.9 0.5
This work (beam = 4) 88.2 88.7 88.4 1.7
Huang (2008) 91.7 Unk
Finkel et al. (2008) 87.8 88.2 88.0 >250
Petrov & Klein (2008) 88.3 3
Sagae & Lavie (2006) 87.8 88.1 87.9 17
Charniak & Johnson (2005) 90.6 91.3 91.0 Unk
Charniak (2000) 89.6 89.5 89.5 23
Collins (1999) 88.1 88.3 88.2 39
Section 23, all sentences (2,416 sentences)

Discussions
• Improving chunking accuracy– Semi-Markov CRFs (Sarawagi and Cohen, 2004)– Higher order CRFs
• Increasing the size of training data– Create a treebank by parsing a large number of
sentences with an accurate parser– Train the fast parser using the treebank

Conclusion
• Full parsing by cascaded chunking– Chunking with CRFs– Depth-first search
• Performance– F-score = 86.9 (12msec/sentence)– F-score = 88.4 (42msec/sentence)
• Available soon