fast data intelligence in the iot - real-time data analytics with spark
TRANSCRIPT

Fast Data Intelligence in the IoTReal-time Data Analytics with Spark Streaming and MLlib
Bas Geerdink
#iottechday

ABOUT ME
• Chapter Lead in Analytics area at ING• Academic background in Artificial
Intelligence and Informatics• Working in IT since 2004, previously as
developer and software architect• Spark Certified Developer
• Twitter: @bgeerdink• Github: geerdink


WHAT’S NEW IN THE IOT?• More data– Streaming data from multiple sources
• New use cases– Combining data streams
• New technology– Fast processing and scalability
FrontEnd
BackEnd
Data

PATTERNS & PRACTICES FOR FAST DATA ANALYTICS
• Lambda Architecture• Reactive Principles• Pipes & filters• Event Sourcing• REST, HATEOAS• …

LAMBDA ARCHITECTURE
Source: Nathan Marz & James Warren (2015)

REACTIVE PRINCIPLES
Source: Reactive Manifesto (2014)
USE CASE
nest
WWW

FAST DATA ARCHITECTURE
Products
UsersAPI
App
Web
…
Batch(Machine Learning)
SocialMedia
SearchHistory
GPSData
…
Message Broker
Events
Streaming(Business Logic)
VisualizeProcessing Database

A SHIFT IN TECHNOLOGY PARADIGMS
Disk In-memoryDatabase StreamObjects FunctionsCentralized DistributedShared Memory/CPU/Disk Shared Nothing

TOOLS FOR THE JOB
• Apache Kafka• Apache Cassandra• Apache Spark• Apache Zeppelin• Akka• Scala

FAST DATA ARCHITECTURE
Products
UsersAPI
App
Web
…
BatchMachine Learning
SocialMedia
SearchHistory
GPSData
GPSData
Message Broker
StreamingBusiness Logic
Events VisualizeProcessing Database

KAFKA
• Distributed Message broker• Built for speed, scalability, fault-tolerance• Works with topics, producers, consumers• Created at LinkedIn, now open source• Written in Scala

CODE: KAFKA• build.sbt:
"org.apache.kafka" %% "kafka" % kafkaVersion
• Application.conf: kafka { producer … consumer }
• KafkaConnection.scala: def producer, def consumer
• KafkaProducerActor.scala: producer.send(msg)
• KafkaConsumerActor.scala:val kafkaStream =
connection.createMessageStreams(Map(topic -> 1))(topic)(0)

CASSANDRA
• NoSQL database• Built for speed, scalability, fault-tolerance• Works with CQL, consistency levels, replication factors• Created at Facebook, now open source• Written in Java

CODE: CASSANDRACREATE TABLE products (user_name text, product_category text, product_name text, score int, insertion_time timeuuid, PRIMARY KEY (user_name, product_category, product_name));
val cluster = new Cluster.Builder(). addContactPoints(uri.hosts.toArray: _*). withPort(uri.port). withQueryOptions(new QueryOptions().setConsistencyLevel(defaultConsistencyLevel)).build
val session = cluster.connectsession.execute(s"USE ${uri.keyspace}")
def insertScore(productScore: ProductScore): Unit = { val query = s”INSERT INTO products (user_name, product_category, product_name, score, insertion_time) VALUES ('${productScore.userName}', '${productScore.productCategory}', '${productScore.productName}', ${productScore.score}, now())"
session.execute(query)}

SPARK• Fast, parallel, in-memory, general-purpose data
processing engine• Winner of Daytona Gray Sort benchmark 2014• Runs on Hadoop YARN, Mesos, cloud, or standalone• Created at AMPLab UC Berkeley, now open source• Written in Scala

CODE: SPARK BASICSval l = List(1,2,3,4,5)val p = sc.parallelize(l) // create RDDp.count() // action
def fun1(x: Int): Int = x * 2p.map(fun1).collect() // transformation
p.map(i => i * 2).filter(_ < 6).collect() // lambda

SPARK
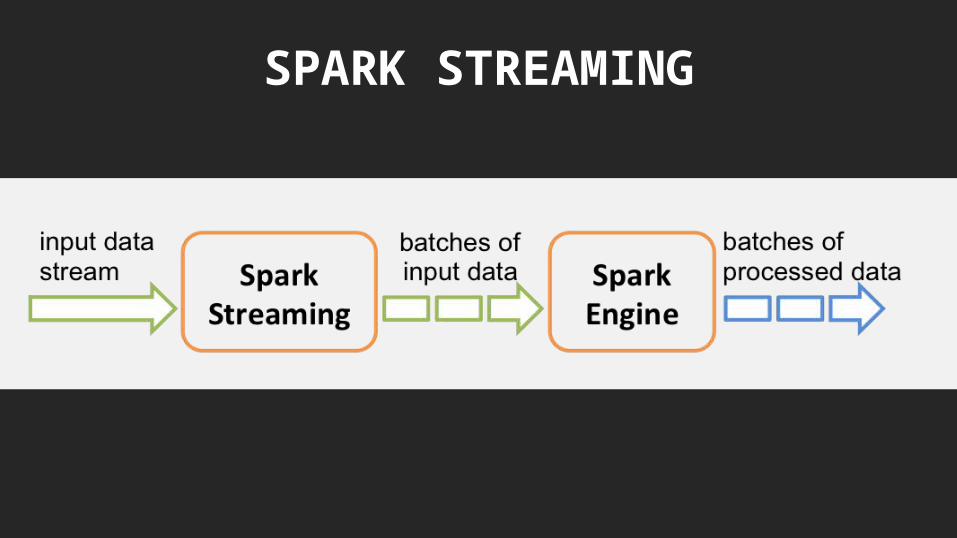
SPARK STREAMING

CODE: SPARK STREAMINGval conf = new SparkConf().setAppName("fast-data-search-history").setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(2)) // batch interval = 2 sec
val kafkaParams = Map[String, String]("metadata.broker.list" -> "localhost:9092")val kafkaDirectStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, Set("search_history"))
kafkaDirectStream .map(rdd => ProductScoreHelper.createProductScore(rdd._2)) .filter(_.productCategory != "Sneakers") .foreachRDD(rdd => rdd.foreach(CassandraHelper.insertScore))
ssc.start() // it's necessary to explicitly tell the StreamingContext to start receiving datassc.awaitTermination() // wait for the job to finish

CODE: SPARK MLLIB// initialize Spark MLlib val conf = new SparkConf().setAppName("fast-data-social-media").setMaster("local[2]")val sc = new SparkContext(conf)
// load machine learning model from diskval model = LinearRegressionModel.load(sc, "/home/social_media.model")
def processEvent(sme: SocialMediaEvent): Unit = { // feature vector extraction val vector = new DenseVector(Array(sme.userName, sme.message)) // get a new prediction for the top user category val value = model.predict(vector) // store the predicted category value val user = new User(sme.userName, UserHelper.getCategory(value)) CassandraHelper.updateUserCategory(user)}

THREE KEY TAKEAWAYS
• The IoT comes with new architecture: reactive and scalable are the new normal
• Be aware of the paradigm shift: in-memory, streaming, distributed, shared nothing
• Open source tooling such as Kafka, Cassandra, and Spark can help to process the fast data flows

Thank You!“please rate my talk in the offical IoT Tech Day app”
@bgeerdink
#iottechday