explicit negative feedback in information retrieval
TRANSCRIPT

Explicit Negative Feedback inInformation Retrieval
Dhruv Tripathi
Master of Science
Artificial Intelligence
School of Informatics
University of Edinburgh
2018

Abstract
Relevance feedback has always been a popular topic of discussion in
the field of information retrieval. This project explores the possibilities
of explicit negative feedback as it is fundamental when using machine
learning algorithms to design better information retrieval systems.
We conducted an experimental study to investigate differences in user
behaviour towards positive and negative relevance feedback. The study also
helped in assessing people’s perception towards giving explicit negative
feedback. In the study, participants were asked to flag scholarly literature
articles in the two feedback conditions. We found no significant difference
in the number of articles retrieved as relevant in both conditions. However,
on analysing the questionnaires and interview data we found that factors
like knowledge and comfort levels play a key role in assisting retrieval
tasks. Additionally, we observed a difference in flagging of ambiguous
documents in the two feedback tasks.
The results discussed in this thesis will help in designing better in-
formation retrieval systems.
Keywords: explicit negative feedback, information retrieval, percep-
tion, relevance feedback, user behaviour
i

Acknowledgements
First and foremost, I would like to thank my supervisor Dr. Dorota
Glowacka for giving me this opportunity, and continuously supporting me
throughout the project with her expertise. I would also like to thank Dr.
Alan Medlar for constantly assisting me with his valuable insight and dis-
cussions. Thanks to them this project was a wonderful learning experience.
I would also like to thank all the participants who volunteered to be a part of
this study. Last but not least, an immense gratitude to my parents, for being
supportive throughout my life.
ii

Declaration
I declare that this thesis was composed by myself, that the work contained
herein is my own except where explicitly stated otherwise in the text, and
that this work has not been submitted for any other degree or professional
qualification except as specified.
(Dhruv Tripathi)
iii

Table of Contents
1 Introduction 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Dissertation Structure . . . . . . . . . . . . . . . . . . . . . 4
2 Background 5
2.1 Relevance Feedback . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Positive Relevance Feedback . . . . . . . . . . . . . . . . . 7
2.3 Negative Relevance Feedback . . . . . . . . . . . . . . . . 8
2.3.1 Methods for Negative Relevance Feedback . . . . . 9
2.3.2 Perception of Negative Relevance Feedback . . . . . 10
2.4 Search Models . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.1 Information Forging theory . . . . . . . . . . . . . . 10
2.4.2 Berry-Picking . . . . . . . . . . . . . . . . . . . . . 11
2.4.3 Faceted Search . . . . . . . . . . . . . . . . . . . . 12
3 Study Design 14
3.1 Participants . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 System Overview . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Experimental Design . . . . . . . . . . . . . . . . . . . . . 16
3.4 Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.5 Measurements . . . . . . . . . . . . . . . . . . . . . . . . . 18
iv

3.5.1 Pre-test questionnaire . . . . . . . . . . . . . . . . . 19
3.5.2 Intermediate questionnaire . . . . . . . . . . . . . . 20
3.5.3 Post-test questionnaire . . . . . . . . . . . . . . . . 21
3.5.4 Interview . . . . . . . . . . . . . . . . . . . . . . . 21
4 Results and Analysis 22
4.1 User Interaction . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2 Questionnaire Feedback . . . . . . . . . . . . . . . . . . . . 24
4.3 Interview Feedback . . . . . . . . . . . . . . . . . . . . . . 26
5 Discussion 28
6 Conclusion and Future Work 31
6.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . 32
A Participant Information Sheet 33
B Consent Form 35
C Questionnaires 36
C.1 Intermediate questionnaire . . . . . . . . . . . . . . . . . . 36
C.2 Post-test Questionnaire . . . . . . . . . . . . . . . . . . . . 37
C.3 Interview questions . . . . . . . . . . . . . . . . . . . . . . 37
References 38
v

List of Figures
2.1 Faceted search on an online shopping site (Retrieved from
https://i.stack.imgur.com/tULdB.jpg, August 2018) . . . . . 12
3.1 System interface: Users can flag documents by clicking the
flag icon on the right hand side of each document . . . . . . 16
3.2 Pre-test questionnaire . . . . . . . . . . . . . . . . . . . . . 19
3.3 Intermediate questionnaire . . . . . . . . . . . . . . . . . . 20
3.4 Post-test questionnaire . . . . . . . . . . . . . . . . . . . . 21
4.1 Boxplots showing articles receiving positive feedback un-
der both treatments . . . . . . . . . . . . . . . . . . . . . . 23
4.2 Comparison in the time taken by expert and novice users on
the basis of the feedback treatment . . . . . . . . . . . . . . 23
4.3 Comparison of types of feedback on the basis of comfort,
speed and cognitive load . . . . . . . . . . . . . . . . . . . 25
vi

List of Tables
3.1 Participants Statistics . . . . . . . . . . . . . . . . . . . . . 15
3.2 Queries searched and displayed to the participants . . . . . . 17
3.3 Intermediate questionnaire - Likert Scale options . . . . . . 20
4.1 Participant flagging trends for ambiguous articles . . . . . . 25
vii

Chapter 1
Introduction
Information retrieval (IR) is the act of retrieving information related to
a user need from a collection of resources. IR allows users to satisfy
their information needs by searching for a document, information within
a document or exploring a variety of databases. IR is a comprehensive
field comprised of recommender or recommendation systems, text mining,
question answering (Larson, 2010). Van Rijsbergen (1979) described
the core concept of IR as the retrieval of all relevant sources along with
minimising the retrieval of irrelevant sources at the same time. Additionally,
IR also covers assisting users in browsing or filtering documents to further
produce a collection of retrieved documents (Frakes and Baeza-Yates,
1992). Moreover, the task which is used mainly for grouping documents on
the basis of their content is known as clustering.
The two key assumptions on which IR systems are based on (Belkin
et al., 1993), are:
(i) an existence of some need for information connected with the user,
which can be identified
(ii) a proper way to deal with that need of information, by searching and
selecting documents or texts which can solve that need
Furthermore, users search the web to extract information. This infor-
mation can be obtained by using search tasks categorised as look-up and
exploratory (Athukorala et al., 2016). Exploratory search is a general
1

Chapter 1. Introduction 2
search performed without a specific target and is likely to change with time,
whereas look-up searches are goal-oriented and often quicker (Athukorala
et al., 2016).
The main concept of IR which this project explores is that of relevancefeedback.
1.1 Motivation
Traditionally, relevance feedback was used as a form of feedback mecha-
nism where the user points out the type of documents or results that they
would prefer in response to a search query (Jung et al., 2007). This is be-
lieved to improve the results for users as they would get their desired out-
comes.
As seen above, the relevance feedback approach depends on the users ca-
pability to flag the documents as relevant, in turn leading to query reformu-
lation. Initial interactive IR systems used relevance feedback mechanism
(Kelly and Fu, 2006). However, the sole use of relevance feedback has be-
come rare in recent times, firstly, because it might lead to context traps
meaning that obtained results may cycle between comparable searches de-
pending on previously acquired results (Medlar et al., 2016), and secondly,
because providing relevance feedback is considered cognitively challenging
(Kelly and Fu, 2006). All this shows the inability of this feedback mecha-
nism alone to improve the retrieval results which are considered unsatisfac-
tory when the top-ranked outcomes are not relevant to the query in context
(Wang et al., 2007).
The main research questions that will be investigated in this project are the
following:
• Whether people use relevance feedback and if there is a difference in
user behaviour when comparing positive and negative feedback.
• Exploring whether negative relevance feedback is truly disapproved
when compared to positive relevance feedback
• Analysing how people’s perception is towards using negative relevan-
ce feedback

Chapter 1. Introduction 3
We care about this because machine learning algorithms need positive and
negative examples, of one kind or the other in order to function. In recent
times, these machine learning algorithms are being used to design IR sys-
tems (Le and Mikolov, 2014; Lam et al., 2015; Joachims et al., 2017). Ad-
ditionally, we aim to explore whether users will be able to adapt to a new
system if designed in a way that expects them to use this form of feedback.
An important area of research is why systems do not usually use negative
feedback.
This project proposes a new approach on the relevance feedback mecha-
nism by using explicit negative feedback in order to evaluate retrieval re-
sults. Wang et al. (2007) described negative feedback as a method to use
irrelevant documents and information to improve search results. The pur-
pose of the project is, therefore, to find answers and explanations for the
above discussed questions. Furthermore, the results of the research will be
used for developing more effective feedback systems.
1.2 Contributions
As discussed in the section above, we were motivated to investigate areas
related to negative relevance feedback in order to assist future studies on
machine learning algorithms to build more effective IR systems. Machine
learning algorithms require negative feedback in some form or the other.
Our study was aimed at understanding whether the case that negative
feedback is not as likely to be used for retrieval, is true or not. Moreover,
we aimed to explore the possible reasons for it. In this experimental study,
we observe the different aspects of negative feedback and user behaviour.
We propose an experimental study seeking to compare positive and negative
feedback mechanisms on the basis of retrieved results and user perception.
Our study shows how people use negative feedback and how comfortable
they are using it in comparison to its positive counterpart.
Since our study dealt only with scientific literature, we found that knowl-
edge level was an important factor for determining what was found to
be relevant. Furthermore, our analysis shows how different factors like

Chapter 1. Introduction 4
knowledge levels, time and comfort levels of users have an affect on their
retrieval results.
With the help of the interviews conducted, we could understand the
user’s behaviour and their line of thought. This helped us comprehend
the perception people have towards providing explicit negative relevance
feedback.
1.3 Dissertation Structure
This thesis is divided into 6 chapters. The first chapter serves as an intro-
ductory chapter and discusses the motivation and objective of the project.
It also lists the contributions that were made by the study conducted along
with the structure of the thesis. Chapter 2 provides a background to the
field of research and drawbacks faced by conventional techniques in the
past. Furthermore, it provides an overview of negative relevance feedback.
Chapter 3 describes the experimental study undertaken in the project along
with all the different aspects of it. Chapter 4 provides an overview of the
results obtained from the study. Chapter 5 provides a discussion to the ob-
tained results along with their relation to the main research questions.
Finally, chapter 6 presents a conclusion to the thesis along with possible
future work.

Chapter 2
Background
This chapter gives a background of topics required to better comprehend
different types of relevance feedback. It introduces the concept of nega-
tive relevance feedback which is important for understanding the rest of the
project. Furthermore, it discusses drawbacks and methods of studies inves-
tigating the topic. It also describes previously developed search models and
how this study stands out from the ideas used in the past.
2.1 Relevance Feedback
A core concept in the field of IR is that of relevance feedback. Relevance
feedback was initially introduced in the 1960s (Rocchio, 1966), it is done by
involving the users, by taking appropriate information from them regarding
their requirements to answer their queries better (Zhou and Huang, 2003).
Relevance feedback can be seen as a way to involve the users and make
the IR system more interactive. A search system that takes into account
user cognition and knowledge levels can give rise to a better search system
(Kelly and Sugimoto, 2013). Human intervention can at times help improve
results, as a machine might not always relate words and phrases correctly
due to the presence of synonyms. Karlgren and Sahlgren (2001) argued that
words have several meanings and they cannot solely be used as matching
indicators to concepts and topics.
A study by Rocchio (1971) showed that in the case of text retrieval
relevance feedback could improve results. Furthermore, the idea behind
5

Chapter 2. Background 6
relevance feedback is to select terms and expressions which are acknowl-
edged by the users as relevant from the previously retrieved documents
and use them to formulate a new query (Salton and Buckley, 1990). This
process is called query reformulation. Conversely, terms that are comprised
in previously retrieved irrelevant documents are given reduced importance
in future query reformulation (Salton and Buckley, 1990). The aim of this
is to move towards relevant results and away from non-relevant ones for
future searches. Relevance feedback is found to be useful as it modifies the
query on the basis of the actions of the user. This guards the user from the
reconstruction process of the query. Moreover, users are not expected to
have intimate knowledge of the search environment(Salton and Buckley,
1990).
Relevance feedback can be classified into three main categories of
feedback: explicit, implicit and pseudo feedback.
Explicit feedback is acquired when users indicate the relevancy of a docu-
ment obtained for a query explicitly by either a binary or a graded relevance
system (Gay et al., 2009). Binary relevance system is based on categorising
documents as relevant or non-relevant for a given query (Boolean), whereas
graded relevance is the ranking of the retrieval results on a scale to indicate
their relevancy. In contrast, implicit feedback is indirectly inferred from
the users behaviour such as time spent on viewing a document, scrolling
or clicking (Jansen and McNeese, 2005). In most cases the user is unaware
that their behaviour will be used as a form of relevance feedback (Kelly and
Teevan, 2003). In comparison, explicit feedback is considered to give better
results than implicit feedback and requires users to carry out added tasks
(Balakrishnan et al., 2016). Finally, the pseudo-relevance feedback adopts
the fact that the most frequent terms in the pseudo-feedback documents are
beneficial for the retrieval (Cao et al., 2008).
Rocchio (1971) developed an algorithm based on relevance feedback which
in vector space, during query reformulation moves the query vector farther
from non-relevant vectors and closer to the relevant ones (Singhal et al.,
1997).

Chapter 2. Background 7
A search query in vector space could be written as:
Qo = (q1,q2, .....qt)
where qi represents the weight of the term i in query Qo. On numerous oc-
casions the term weights are confined to a range from 0 to 1, where 0 repre-
sents the absence of term from the vector and 1 represents a fully weighted
term (Salton and Buckley, 1990). The relevance feedback process generates
a new query vector by adding and removing weights to various terms:
Q0 = (q01,q02, .....q
0t)
where q0i represents the altered weight of the term for t indexes in query Q0
(Salton and Buckley, 1990).
2.2 Positive Relevance Feedback
Positive relevance feedback can help improve results as it boosts weights
of specific terms related to the search query and gets the user closer to the
target (Zhou and Huang, 2003). An advantage of positive feedback is that
the user can easily see the type of documents retrieved and can deduce the
change(s) made by the system (Belkin et al., 1998).
Muller et al. (2000) conducted a study for image retrieval which showed that
positive feedback when used alone is limited to the initial images provided
and is used to weigh the images on the basis of their features. It was demon-
strated that most of the highly ranked relevant images had many shared fea-
tures with non-relevant images that led to misleading results (Muller et al.,
2000). However, using a combination of both positive and negative feedback
showed to improve the image retrieval results significantly, as the inclusion
of negative feedback helped remove various results which were completely
irrelevant as a whole but still managed to possess features similar to relevant
images (Muller et al., 2000).
This study demonstrated that a query from a user using only positive feed-
back can be enhanced by applying a negative feedback to images which

Chapter 2. Background 8
were not selected. However, they argued that too much negative feedback
could potentially destroy the query. Muller et al. (2000) believed that auto-
matically feeding back neutral images as negative, if they remained unse-
lected, could give better results to novice users.
2.3 Negative Relevance Feedback
Generally, IR systems allocate a numeric score corresponding to each
document. This score is in turn used for ranking these documents (Singhal
et al., 2001). There are two types of irrelevant documents - first, the
documents which explicitly receive a negative feedback i.e. are judged to
contain no relevant information (Ruthven and Lalmas, 2003), and second,
the documents which might be retrieved but not assessed explicitly, or they
are implicitly rejected (Ruthven and Lalmas, 2003). Moreover, the type
of feedback in which documents are explicitly termed as non-relevant is
known as negative relevance feedback.
In some cases a search query can fail to return relevant results; these
queries are called difficult queries. When dealing with difficult queries
a user is either expected to reformulate the query or explore the ranked
list far beyond usual to find any relevant results. In most cases, most
of the top-ten results are irrelevant to the query (Peltonen et al., 2017).
Moreover, when a query is difficult, it is very challenging to find positive
documents for feedback and hence, it is best to use negative documents to
perform negative feedback (Wang et al., 2008). However, a query may be
termed as difficult due to reasons like poor formulation of search phrases,
or because it is hard to describe, or because it describes a wide range of
related documents which cannot be distinguished easily by a simple query
(Buckley, 2004, 2009). In such cases, feedback offered by users whether
implicit or explicit, is completely negative.
Peltonen et al. (2017) showed that retrieval results could not be improved
with positive feedback alone and required the use of negative feedback.
The aim of the study was to yield results which were more relevant than the

Chapter 2. Background 9
ones obtained by a baseline, positive feedback only systems. Furthermore,
it assured to enhance the user experience. The study made use of intent
model which allow users to direct their search represented as interactive
visualisations, the system used probabilistic scoring (machine learning
solutions) for the retrieval of documents. Moreover, studies have shown
that results were more diverse when using negative relevance feedback as
compared to positive relevance feedback in the case of difficult queries
(Karimzadehgan, 2012; Karimzadehgan and Zhai, 2011). The logic behind
this is that when giving explicit negative feedback a user removes the
chances of having any unwanted terms, and documents having those terms
are penalised and the results are more varied since the search is not trapped
in only limited relevant subtopics. The intent model system discussed in the
study comprised of both discrete and continuous-valued feedback which
was used substantially by users. In other words, discrete-valued feedback
was obtained by placing articles in either positive (+1) or negative (-1)
regions of the model whereas, continuous-valued feedback was achieved
by using intermediate positions (Peltonen et al., 2017).
2.3.1 Methods for Negative Relevance Feedback
The two main methods used for calculating negative relevance feedback are
query modification and score combination.
In query modification, more weights are assigned to relevant documents
and less or negative weight is assigned to documents with more occur-
rences in non-relevant documents (Wang et al., 2008). Furthermore, feed-
back methods such as Rocchio, already have this component of negative
information, hence can be used directly to obtain negative feedback (Wang
et al., 2008). Using such feedback allows a system to develop a modified
query to get better results for future searches (Singhal et al., 2001). In scorecombination, unlike the query modification method which uses both pos-
itive and negative information in a single query model, score combination
allows maintaining positive and negative query representation separately
(Kuhn and Eickhoff, 2016). Negative query representation can signify neg-
ative examples with a score based on the likelihood of documents being
irrelevant. For instance, a document with a higher relevance score to a neg-

Chapter 2. Background 10
ative query is considered to be less relevant.
The above discussed are general strategies for negative relevance feedback.
However, Wang et al. (2008) discussed variations in these strategies as
shown in a study by Hearst and Pedersen (1996) that negative documents
tend not to cluster together. Therefore, they concluded that it was more ef-
fective to use numerous negative models, as negative documents had more
chances of getting separated (Wang et al., 2008).
2.3.2 Perception of Negative Relevance Feedback
User perception is a key when dealing with negative relevance feedback.
Past studies with negative relevance feedback have shown bad feedback
from users, due to the apprehension of losing relevant information (Belkin
et al., 1998; Ruthven and Lalmas, 2003). However, in the study by Peltonen
et al. (2017), the negative relevance feedback was given to keywords rather
than documents, preventing the risk of losing crucial information. Once the
user gave negative relevance feedback to a keyword, the system would auto-
matically build a negative language model to add a penalty to the documents
and display these with the lowest lower-confidence bound (Peltonen et al.,
2017).
2.4 Search Models
This section describes conventional search models and shows how in the
past, models were designed on an idea revolving around positive relevance
feedback. Contrary to popular belief, our study explores the concept of neg-
ative feedback.
2.4.1 Information Forging theory
Information seeking can be defined as a task of attempting to find some-
thing with the consequence of satisfying a goal (Wilson, 2000). Humans are
considered to be a species which are associated with gathering and storing
information in order to adapt to the world (Pirolli, 2007). It is believed that

Chapter 2. Background 11
humans process information in different ways, to develop various adaptive
techniques and hence ensuring their survival (Cole, 2011).
Pirolli and Card (1999) proposed a theory called information foraging,
describing the information retrieval behaviour of internet searching.
Information Foraging Theory is a perspective used for interpreting how
techniques and technologies for information gathering and seeking are
adapting to the continuous change in the world (Pirolli and Card, 1999).
Moreover, the theory assumes that people, when feasible, mould or evolve
their strategies or restructure the environment to maximise their rate of
gaining useful information (Anderson and Milson, 1989). It can be used to
predict and improve human information interaction.
Technological innovation has led to an explosive growth of recorded
information. Information Foraging Theory can provide a scientific foun-
dation that can lead to newer innovations that improve the quality of
information that people process (Pirolli and Card, 1999).
2.4.2 Berry-Picking
Berry picking, is a form of nonlinear online searching which provides
results depending on the needs of the user (Bates, 1989). These changes
can be made to search techniques or even the search database. This model
is considered to be very close to real human behaviour whilst searching
for information when compared to conventional models of information re-
trieval. Bates (1989) believes retrieval effectiveness and efficiency depends
on the variations in strategies. Furthermore, this model is expected to guide
human thinking better when designing effective interfaces. Past research
by Line (1969); Stone (1982); Hogeweg-de Haart (1984) have shown the
popularity of this way of thinking for finding results, instead of leading to
a single best retrieved set. At each stage, the user identifies information
useful to their search query. In other words, the query is satisfied by a series
of selections of distinct references and fragments of information built over
the ever-modifying search. This is analogous to picking berries in a forest
as berries do not come in a bunch and are required to be selected one at a
time. A bit-at-a-time retrieval of this sort is called berry-picking. Similarly,

Chapter 2. Background 12
it is believed that while searching for information people tend to pick from
a variety of sources and ultimately gather them together into a single group
(Hassan, 2017).
The model by Bates (1989) suggests that information needs of users
can be satisfied by a number of sources along the information search
process. According to this model, the user, modifies the query when
observing the given results, but retains the original information required
(Cole, 2011). Moreover, berry-picking of information can be completed
with either the search query continuously evolving or staying the same.
2.4.3 Faceted Search
Faceted search or browsing refers to extracting information from an organ-
ised collection of data, providing users with an ability to use filters to refine
their search and analyse each aspect of the content. The use of facets al-
lows users to remove any objects which don't match the search criteria. Yee
et al. (2003) discussed that faceted search aimed at avoiding context traps
by using global filters.
Figure 2.1: Faceted search on an online shopping site (Retrieved from
https://i.stack.imgur.com/tULdB.jpg, August 2018)

Chapter 2. Background 13
A facet can have one or more than one levels. When a label under a facet is
selected and modified, all the items allotted to that are displayed. Therefore,
a change in the labels under a hierarchy is equivalent to modifying over all
labels beneath it (Hearst, 2006). Faceted navigation is believed to be very
flexible and highly effective for large data sets (Hearst, 2006). However, the
search can quickly become highly demanding, as users have a wide variety
of options to choose from (Yee et al., 2003).

Chapter 3
Study Design
This chapter describes the experimental study conducted as a part of this
project. The purpose of the study is to evaluate the hypothesis that explicit
negative relevance feedback can be equivalent in terms of what is selected
by the users along with their preferences when compared to explicit positive
feedback. It also evaluates the perception people have towards providing
negative feedback and if that seems to affect their thought process during
the study.
We divided this chapter into five main sections namely: Participants, Sys-
tem Overview, Experimental Design, Procedure and Measurements. Each
section gives an overview of the different aspects of the study.
3.1 Participants
Twenty-four participants (8 females and 16 males) aged 18 to 35 (M =
25.00; SD = 2.37) with a proficient knowledge of the English language
were recruited to participate in the study (Table 3.1). The female to male
ratio of 1:2 reflects the gender distribution in the field of Informatics. All
of the participants were students at the University of Edinburgh with a de-
gree in either Artificial Intelligence (AI), Informatics, Computer Science or
similar. Two of the participants were PhD students whilst 22 were finishing
their Masters degree. Moreover, all participants were required to be from an
AI and machine learning domain as the system data set used in this study
covered only this domain.
14

Chapter 3. Study Design 15
Table 3.1: Participants Statistics
Before exclusionParticipants (M/F) 24 (16/8)
Age M(SD) 25.00(2.37)
After exclusionParticipants (M/F) 20 (14/6)
Age M(SD) 25.20 (2.50)
Primary literature search tool Google Scholar (20)
Out of 24 participants, two of them participated in the pilot study. Data
from two participants were excluded as after the study they admitted to have
flagged the documents incorrectly. Therefore, data from 20 participants (6
females and 14 males; age M = 25.20; SD = 2.50) was included in the
analysis.
Participants were informed about the study (see Appendix A) and their rights
such as the right to terminate their participation at any point and right to
have their data erased. After answering to participants questions, they gave
their written consent by signing a consent form (see Appendix B).
3.2 System Overview
The system in the experimental study is based on relevance feedback. The
five queries used in the study display their top 10 results (articles) (Figure
3.1), ranked on the basis of the Okapi BM25 algorithm (Jones et al., 2000).
The system is comprised of a database of 170,367 articles which were all
extracted from ArXiv. This is a pre-print server which means that it con-
tains documents yet to be reviewed and published (Hu et al., 2010). The
documents belong to different branches of computer science. Furthermore,
the system consists of a collection of journal, research and technical papers
familiar to researchers in the field. However, the articles displayed during
the study were associated with machine learning, wireless systems and AI.

Chapter 3. Study Design 16
Figure 3.1: System interface: Users can flag documents by clicking the
flag icon on the right hand side of each document
The system is based on the Representational State Transfer (REST) API
(Application Programming Interface) which allows the user to give a query
and accordingly returns the documents (Lai and Chan, 2013). The feedback
given is binary relevance feedback. The front-end framework is based on
AngularJS (https://angularjs.org/).
3.3 Experimental Design
We designed a within-subject study, where each participant was asked to
flag documents as either relevant or irrelevant based on the task. The rea-
son we chose this design was that it does not require as many participants
as in case of between-subject design. Furthermore, it reduces error caused
individual differences. In order to avoid order effects, we counter-balanced
the tasks by randomising the tasks and further by randomising whether one
does relevant or irrelevant flagging first.
The topics that were to be reviewed by the participants were picked on the
basis of the top ten results displayed when searched on ArXiv. We inspected
the 10 documents each topic displayed and then decided the ones which

Chapter 3. Study Design 17
would have a good mix of relevant, irrelevant and ambiguous articles. Fi-
nally, five main topics were selected from the machine learning domain on
the basis of their availability in ArXiv.
Table 3.2: Queries searched and displayed to the participants
True query Stated queryGender recognition Face recognition
Sentiment analysis Twitter sentiment analysis
Wireless sensor networks Wireless network energy efficiency
Fake news twitter Fake news detection
Deep learning medicine Clinical applications of deep learning
The selected topics were gender recognition, sentiment analysis, wireless
sensor networks, twitter fake news and deep learning in medicine. The main
criteria to select these topics was that they served as a broader topic for the
queries that were displayed to the participants. For instance, we selected
gender recognition as our search query to display the results. However, we
asked the participants to mark documents on the topic of face recognition
for the same results. This was done because the top ten results that gender
recognition returned had a mix of documents which were related to the field
of face recognition as well. This created a sense of ambiguity while flagging
the documents which would be used later to evaluate the task. Table 3.2
shows the true query which was searched along with what was stated in the
experiment.
The participants had two main tasks whether to mark the documents as rel-
evant or irrelevant. All the documents, as well as the queries, were ran-
domised. Each of the questions was reversed and repeated after a gap of
five questions as this ensured the longest period between them. This was
done to prevent participants from memorising the feedback they provided
to the documents in the first phase of the study. Furthermore, the partici-
pants were asked to answer three distinct questionnaires through the course
of the study followed by an interview.

Chapter 3. Study Design 18
3.4 Procedure
Prior to the study, the participants were provided with information about the
study via an instructional video. The video gave an overview of the system
design and how to use it to complete the tasks. The participants were not
informed about the structure of the study i.e. they were not aware that they
will be repeating the task for the opposite type of feedback. After the first
five queries, the participants were shown the same queries in the same order
but this time asked to provide the opposite feedback. For instance, if the
first-time participants were asked to mark relevant articles for a topic, the
next time around they were asked to mark irrelevant articles for the same
topic. However, the participants were unaware about this structure of the
study.
All the studies were conducted in a soundproof room preventing any ex-
ternal intervention or distractions. The system was presented on a 13-inch
MacBook Air laptop. At the start of the study, the participants were asked
to fill in their basic information in a pre-test questionnaire. Every partici-
pant performed the flagging task to provide explicit feedback, based on the
instructions given in the task. The flagging was followed by filling of the
intermediate questionnaire at the end of each task. After the fifth task, all
the query topics were repeated, however, the type of feedback required was
reversed. At the end of the ten tasks, the participant was asked to answer a
final questionnaire. On completion of the post-test questionnaire, the system
automatically terminated.
To conclude the study, we conducted a semi-structured interview enquiring
about the participant’s personal experience with the system and their views
on the nature of the task. Each study lasted approximately 50 minutes and
each participant was compensated £10 for their time.
3.5 Measurements
Data collected throughout the study was both qualitative and quantitative in
nature. The questionnaires were classified as pre-test, intermediate and post-
test. Finally, the study was concluded by an interview by the researcher. The

Chapter 3. Study Design 19
data collected was used to measure different factors that might affect user
behaviour and perception.
Figure 3.2: Pre-test questionnaire
3.5.1 Pre-test questionnaire
The aim of this questionnaire was to collect basic participant information,
such as gender, age and other demographics along with their educational
background. Similarly, it also gathered information about the participant’s
experience with scientific literature search engine systems. This informa-
tion was also used to clarify results when outliers were detected in the final
data set. The form of response used in this questionnaire was structured to
provide quantitative data used to observe the characteristics of the sample
(O’Cathain and Thomas, 2004). The questionnaire comprised of ten ques-

Chapter 3. Study Design 20
tions (Figure 3.2). Furthermore, all the questions used were close-ended
questions (Reja et al., 2003).
3.5.2 Intermediate questionnaire
A set of three questions was used during the course of the study, at the
end of each task. The main aim of this questionnaire was to evaluate the
knowledge level of the participant for each of the topics in the study along
with how often they searched articles on that topic in past academic year.
Additionally, it also assessed their comfort level for the type of feedback
they were providing.
Figure 3.3: Intermediate questionnaire
The questionnaire was presented in a dropdown style (Figure 3.3). However,
questions were in the form of a Likert scale. Furthermore, the end of each
task was time stamped, to compare the time taken by participants to com-
plete each task. Table 3.3 shows the options displayed to the participants for
each of the categories.
Table 3.3: Intermediate questionnaire - Likert Scale options
Knowledge level No knowledge Limited understanding Familiar Good understanding Expert
Search frequency (past year) Never Occassionally Frequently
Comfort level while flagging articles Very uncomfortable Uncomfortable Not sure Comfortable Very comfortable
Likert scales are useful as they provide participants with the freedom to
express their views by indicating the strength of their response. If required,
they can even give neutral opinions (Nemoto and Beglar, 2014).

Chapter 3. Study Design 21
3.5.3 Post-test questionnaire
The questions were regarding the participant’s experience and provided
dropdowns for selections. A selection of ten questions were presented to the
participants (Figure 3.4). The aim of this questionnaire was to investigate
whether giving negative relevance feedback was any different from giving
positive feedback. Moreover, it used factors like comfort, speed, cognitive
load and ambiguous articles to assess these differences.
Figure 3.4: Post-test questionnaire
3.5.4 Interview
The final part of the study was the interview. This was done to collect qual-
itative feedback on the experiment along with the participants’ views on
providing explicit negative feedback. This helped in investigating the partic-
ipants’ perception about negative feedback and the search techniques used
for flagging. Furthermore, it helped in analysing whether people had differ-
ent approaches while marking relevant and irrelevant documents.

Chapter 4
Results and Analysis
We analysed the data acquired from the task, questionnaires and the inter-
view. The primary interest of the analysis was to examine the difference
in user behaviour between positive and negative relevance feedback. More-
over, it was investigated how this performance can be explained by user
perception and various other factors.
4.1 User Interaction
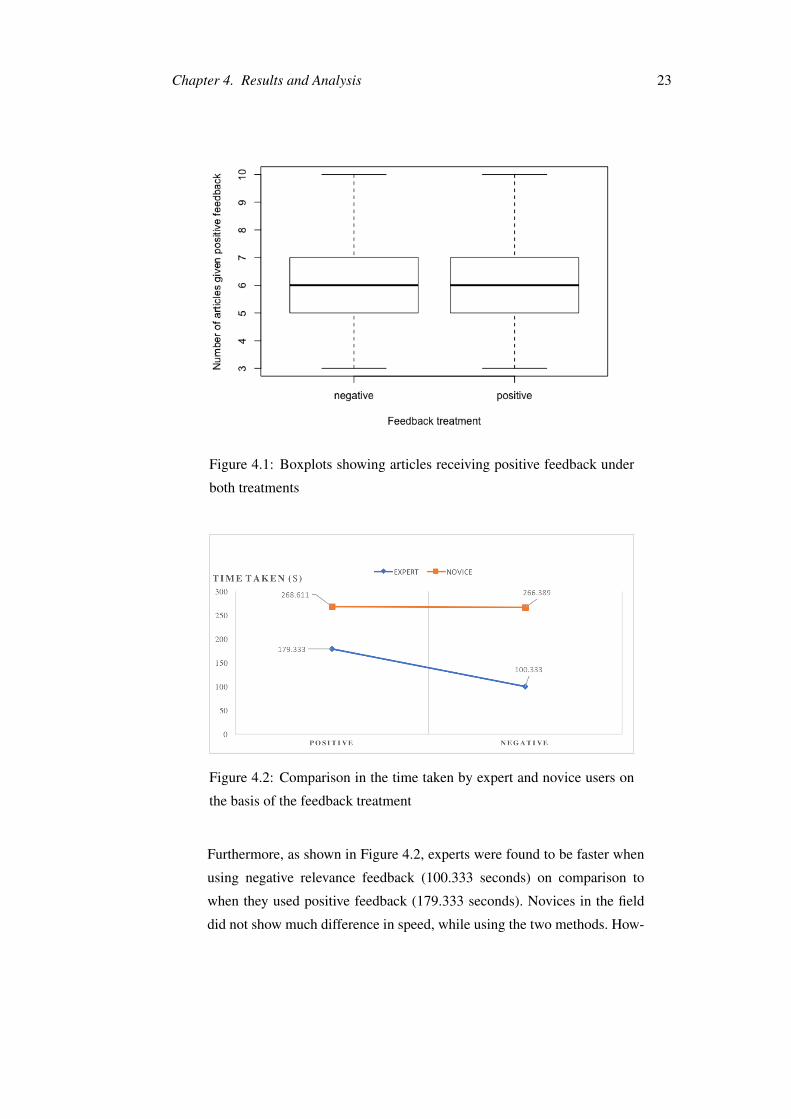
Participants flagged an average of 6 (SD = 1.552) articles positively during
negative feedback and 6 (SD = 1.488) articles during positive feedback. We
performed a repeated measures ANOVA on the number of articles that re-
ceived positive feedback in two types of flagging. The difference was shown
to be insignificant (F(1,179) = 0.602; p = 0.439; Figure 4.1).
For both positive and negative feedback tasks, participants were asked to
mark their comfort levels when performing the task along with their knowl-
edge in that field. The relation between the participants’ comfort level while
flagging articles to their knowledge level was shown to be significant (c2 =
72.626; df = 16; p < 0.001). Experts and people with good understanding
of the topics were more likely to find flagging tasks comfortable. Average
time taken by experts (139.833 seconds) per task was lower than by novice
users (293.541 seconds).
22
Chapter 4. Results and Analysis 23
Figure 4.1: Boxplots showing articles receiving positive feedback under
both treatments
Figure 4.2: Comparison in the time taken by expert and novice users on
the basis of the feedback treatment
Furthermore, as shown in Figure 4.2, experts were found to be faster when
using negative relevance feedback (100.333 seconds) on comparison to
when they used positive feedback (179.333 seconds). Novices in the field
did not show much difference in speed, while using the two methods. How-

Chapter 4. Results and Analysis 24
ever, in both cases experts were faster at flagging tasks compared to novice
users.
4.2 Questionnaire Feedback
The data was collected from 3 questionnaires during the study. The first
questionnaire gave demographic details. However, we analysed the data
collected from the other two questionnaires namely: intermediate and
post-test questionnaire.
The data used from the intermediate questionnaire (see Appendix C.1) was
the participants’ self-reported knowledge levels and their comfort levels
while performing a the two feedback tasks on the given topics.
The post-test questionnaire (see Appendix C.2) was longer (10 questions)
and provided an overview of the user experience after all the tasks were
completed. The topics covered by the questionnaire included: comfort,
speed, and cognitive load. These categories were selected to answer our
research question (Section 1.1) related to user perception towards negative
feedback and the differences it has when compared to positive relevance
feedback.
We investigated the difference in comfort, speed, and self-reported
cognitive demand between providing positive and negative feedback.
Participants were asked to mark their experience comparing the two
feedback assessments. The results of the questionnaire were solely based
on the participant’s perception about the tasks.
70% of participants reported positive flagging tasks to be more comfort-
able than negative and 10% reported both tasks were of equal comfort.
Concerning the speed, 60% reported they perceived marking relevant
articles to be faster than marking irrelevant ones. 3 participants did not
perceive a difference in the speed between the two tasks. Moreover, 60% of
participants identified irrelevant flagging to be more cognitively demanding
than relevant flagging tasks. Only 1 participant reported no difference in
perceived cognitive demand between tasks. Figure 4.3 shows the different
categories investigated during the study for the two types of feedback
tasks. These categories were obtained from specific questions in the final

Chapter 4. Results and Analysis 25
questionnaire (see Appendix C.2).
Figure 4.3: Comparison of types of feedback on the basis of comfort,
speed and cognitive load
Participants seemed to be stricter in flagging when looking for relevant ar-
ticles using negative feedback as in comparison to positive feedback, there
was a 20% decrease in the number participants who marked ambiguous ar-
ticles as relevant during negative feedback. Table 4.1 shows the flagging
choice for ambiguous documents under the two feedback tasks for the par-
ticipants (20).
Table 4.1: Participant flagging trends for ambiguous articles
Ambiguous articles duringFlag Positive feedback Negative feedback
Relevant 10 6
Irrelevant 10 14
In the final questionnaire, participants were asked what was the best de-
scription of the unflagged articles in their opinion. During the relevant doc-
ument marking phase, half of the participants believed that unflagged ar-
ticles were probably not relevant to the topic. On the other hand, during

Chapter 4. Results and Analysis 26
the irrelevant marking phase, little more than half (11 participants) believed
that unflagged articles were probably relevant. These two questions helped
in comparing the change in user behaviour as well as the level of strictness
with which the participants flagged articles in the two tasks.
4.3 Interview Feedback
The interview (see Appendix C.3) allowed us to evaluate the user perception
aspect of our research. Four out of 20 participants believed that knowledge
level could influence the speed and ease of doing the task. Majority of the
participants claimed to have had difficulties when marking ambiguous ar-
ticles. Surprisingly, when it came to marking these ambiguous articles it
was evenly split with 10 participants marking them as relevant and the other
half (10) as irrelevant. “I usually marked them as irrelevant because if it
does not directly answer your query it will be of no use and might waste
time” [Participant 11]. 40% of the participants reported that they used the
same strategy when flagging relevant and irrelevant articles. When dealing
with ambiguous articles, 75% of the participants claimed to have made their
decision entirely based on the keywords used.
Three participants stated that the way the question was framed influenced
their response. Twelve participants reported that they preferred giving posi-
tive feedback and said they felt more natural doing so.
When asked about their views on giving negative feedback, two partici-
pants said: “It is a bit weird and unnatural. The idea of flagging is to get
things which are relevant because when you search for something you want
relevant results” [P11], “Negative feedback was more taxable because it re-
quired a deeper understanding of the topics” [P8]. However, almost half of
the participants confirmed that they felt more comfortable to using it once
they got used to it. Concerning their previous experience, only two par-
ticipants stated that they have conducted searches using negative feedback
often, either knowingly or unknowingly.
“No problems in providing negative feedback. I would not mind using it
again. We can save time by removing documents which are completely non-
relevant. ”[P9].

Chapter 4. Results and Analysis 27
In general, participants stated that after the experiment they were more open
to using negative feedback, contrary to their initial perception of it.

Chapter 5
Discussion
The study presented in this thesis was aimed at answering our three main
research questions - the first dealing with the difference in user behaviour
between positive and negative feedback, second examining whether it is ac-
tually the case that people prefer using positive feedback over negative, and
the final question aimed to understand people’s perception towards using
negative relevance feedback.
A study by Ruthven and Lalmas (2003) stated that people usually do not use
negative feedback due to the fear of losing important information. However,
our study showed that there was no such loss of information as the num-
ber of articles receiving positive feedback remained the same, i.e. the same
number of articles were retrieved in both the scenarios. According to the
analysis conducted on the user interaction data, we concluded that there was
no significant difference in the results obtained from positive and negative
feedback tasks. Contrary to this result, majority of the participants claimed
to have felt more natural while using positive relevance feedback. The ex-
planation for this can be found in a study by Belkin et al. (1997), where they
reported that users’ familiarity determined the success of a feedback type -
“the more familiar a user is with this option, the more comfortable they are
with using it.”
We found that flagging articles was considered more cognitively demanding
during negative feedback tasks. This can be associated with the effect of
negative feedback not being evident, as we cannot see the articles which get
concealed by the task (Belkin et al., 1998).
28

Chapter 5. Discussion 29
During the interview participants explained that irrelevant flagging was per-
ceived to be harder than relevant. However, their results in the tasks show
the opposite. Despite users being unaware of the potential adversities linked
to negative assessment, such as information loss, they tend to give positive
feedback to the same articles whether asked to give positive or negative
feedback.
Although the two feedback tasks are interpreted differently, our study sug-
gests that relevance and non-relevance assessments are in fact the same in
terms of retrieval results.
The correlation of comfort with knowledge level found in our experiment
is not surprising as a more knowledgeable person is more clear about their
expected results (Ruthven et al., 2007). Moreover, they know what they
are looking for and can filter out the important articles based on their vast
domain knowledge. This can be linked to a lookup search which is much
faster when compared to an exploratory search as the target is well defined
(Athukorala et al., 2016).
The same argument can be used in regards to the time taken between experts
and novices, in this case meaning that novices do not have as clear idea on
what kind of result they expect to find.
Although during the interview some participants reported that an expert
might take longer to flag documents because of their broad knowledge of
the topic which might make it more difficult to select only the ones directly
and obviously related to the topic (Ruthven and Lalmas, 2003), our results
show the contrary as experts overall needed less time to complete the tasks.
This is in line with research showing that expertise is associated with faster
task completion (Dillon and Song, 1997).
Generally, the participants perceived the two flagging tasks as different and
stated to have encountered trouble while flagging ambiguous articles. This
was considered cognitively challenging as the title and abstract did not di-
rectly indicate anything specifically related to the topic. Interviews further
confirmed that users perceive the two tasks differently and not just opposite
of one another.
A general search technique described by participants was using keywords
to determine the relevance of an article, especially for the ambiguous ones.

Chapter 5. Discussion 30
Keywords play an important role in linking user queries and retrieval results
(Palomino et al., 2009). People with a stricter approach of flagging articles
leaned towards marking ambiguous articles as irrelevant, since their strategy
was to find articles precisely relevant to the topic. In other words, documents
that satisfy the entire information need of a query are categorised as strictly
relevant documents (Jung et al., 2007).
Some participants explained that their experience using explicit negative
feedback was initially difficult, but that towards the end of the task they got
used to it and did not find that much of a difference as in the beginning.
All things considered, it seems reasonable to point out that people can pro-
vide negative feedback with ease and effectiveness comparable to positive
feedback after getting used to the task.

Chapter 6
Conclusion and Future Work
This chapter helps us summarise the main findings of our work with their
contribution to the field of relevance feedback. It also includes the short-
comings of our study along with the suggestions for future research.
6.1 Conclusion
We can now revisit the questions posed at the start of this thesis. Our study
allowed us to find the difference in user behaviour and retrieved documents
between positive and negative relevance feedback. Generally, people were
seen to be familiar with using relevance feedback. From our experiments
with the two types of relevance feedback approaches, we can conclude that,
although people prefer giving positive to negative feedback, we found no
significant difference between the number of documents retrieved as rel-
evant in both feedback techniques. We have successfully shown that peo-
ple, when unaware about the outcome, flag documents similarly for both
the tasks. However, when they are asked about their experience, they report
giving negative feedback to be harder than giving positive one. Surprisingly,
many people did not find a difference in the two tasks thus showing that neg-
ative feedback is not completely disapproved.
As we have shown in this study, a person’s knowledge level of the search
topic relates to the evaluation they make on the retrieved articles. We ob-
served a similar trend in search techniques. These search techniques also
seemed to differ when people were encountered with ambiguous articles.
31

Chapter 6. Conclusion and Future Work 32
Our study helped us understand the perception people have when dealing
with negative relevance feedback. Initially, people were apprehensive about
using explicit negative feedback, however, by the end of the study many
stated that they got used to the feedback technique. In short, the evidence
from our study strongly suggests that explicit negative feedback can be used
without information loss and further research in this field is promising.
6.2 Future Work
We see several opportunities in the future to improve this experimental
study. We observed that participants with higher knowledge of the included
topics found giving relevance feedback in both tasks as more comfortable
and required less time to complete the tasks compared to the novices in the
field. Since determining the expertise was based on self-report, in the future
we can conduct the experiment by recruiting the experts who have studied
the topics included in the study for several years to investigate whether the
difference observed in this study will be present in a bigger sample. Another
way to determine the knowledge level could be by using the grades achieved
by participants.
Next point concerns the difference in time between the experts and novices.
Our results show that novices took more time to complete the tasks. Even
though this is not a surprising finding, the observed difference between the
groups might have been made bigger because of the participants’ language
skills. For example, it is possible that more novices than experts were not
fluent in English which would then further increase the time needed to com-
plete the tasks. Therefore, it could be worthwhile to conduct this study with
only native speakers.
An important question to be explored further is how people can get accus-
tomed to using negative relevance feedback and in which situations it can
provide better retrieval results. The answer to this can help us generate better
IR systems using machine learning algorithms as negative feedback plays
an important role in their functioning.

Appendix A
Participant Information Sheet
TITLE OF STUDYRelevance Feedback in Information Retrieval
INVITATIONYou are being asked to take part in a research study on the Relevance Feed-
back in Information Retrieval’. The aim of the study is to test a new in-
formation retrieval system for scientific literature. I am a MSc Artificial
Intelligence student at the University of Edinburgh and this study is a part
of my Masters Thesis supervised by Dr Dorota Glowacka.
WHAT WILL HAPPENIn this study, you will be asked to mark scholarly literature articles on vari-
ous topics as relevant or non-relevant depending on the question. It will be
followed by asking you to provide a brief feedback on the topics. At the
end of the study, you will be asked to fill in a questionnaire about the same.
Finally, I will be taking a small interview with you about how you felt about
the system and the study in general.
TIME COMMITMENTThe study typically takes 50-60 minutes which includes testing the system,
followed by filling a questionnaire and a small interview.
PARTICIPANTS RIGHTS1. You may decide to stop your participation at any time.
2. You have the right to ask that any data supplied to that point be with-
drawn/destroyed.
3. Feel free to ask questions at any point. If you have any questions as a re-
33

Appendix A. Participant Information Sheet 34
sult of reading this information sheet, you should ask the researcher before
the study begins.
BENEFITS AND RISKSThere are no known benefits or risks for you in this study.
COST, REIMBURSEMENT AND COMPENSATIONYour participation in this study is voluntary. However, we will reimburse
you with a compensation of 10 for your time, at the end of the study.
CONFIDENTIALITY/ANONYMITYThe data and information about you will be treated confidentially. Your
name or any other information which could identify you will not be made
public. The results of the study will be published in an anonymised form,
preventing the identification of any particular person.
When your role with this project is complete, your data will be anonymised.
From that time, there will be no record that links the data collected from
you with any personal data from which you could be identified (e.g., your
name, address, email, etc.). Up until the point at which your data have been
anonymised, you can decide not to consent to having your data included
in further analyses. Once anonymised, these data may be made available
to researchers via accessible data repositories and possibly used for novel
purposes.
FURTHER INFORMATIONFurthermore, Dr. Dorota Glowacka (supervisor) will be glad to answer your
questions about this study at any time, and can inform you about the re-
sults of the study once data collection is complete. You may contact her at:
Researcher: Dhruv Tripathi ([email protected])
Supervisor: Dr. Dorota Glowacka ([email protected])

Appendix B
Consent Form
TITLE OF STUDYRelevance Feedback in Information Retrieval
By signing below, you are agreeing that:
(1) you have read and understood the Participant Information Sheet,
(2) questions about your participation in this study have been answered
satisfactorily
(3) anonymised data only may be shared in public data repositories, and
(4) you are willing for to take part in this voluntary research study
voluntarily.
Name (Printed):
Signature:
Date:
Name of the person obtaining consent:
Signature of the person obtaining consent:
35

Appendix C
Questionnaires
C.1 Intermediate questionnaire
TOPICFace detection
Twitter sentiment analysis
Wireless network energy efficiency,
Fake news detection and
Clinical applications of deep learning.
For relevant flagging:
1. How would you rate your knowledge on TOPIC?
2. How frequently have you searched articles about TOPIC in the last
academic year?
3. How natural/comfortable did you ind flagging relevant documents for
TOPIC?
For irrelevant flagging:
1. How would you rate your knowledge on TOPIC?
2. How frequently have you searched articles about TOPIC in the last
academic year?
3. How natural/comfortable did you ind flagging irrelevant documents for
TOPIC?
36

Appendix C. Questionnaires 37
C.2 Post-test Questionnaire
1. Did it feel more natural/comfortable to flag documents as relevant or not
relevant?
2. Did you think it was faster to flag documents as relevant or not relevant?
3. When flagging relevant documents, did you tend to flag ambiguous
documents as relevant or not relevant?
4. When flagging not relevant documents, did you tend to flag ambiguous
documents as relevant or not relevant?
5. In your opinion, which option communicated more information: flagging
documents as relevant or not relevant?
6. Did you feel it was more cognitively demanding to flag documents as
relevant or not relevant?
7. Do you think a novice user would prefer flagging documents as relevant
or not relevant?
8. Do you think an expert user would prefer flagging documents as relevant
or not relevant?
9. When you were asked to flag relevant documents, what best describes
the set of unflagged documents?
10. When you were asked to flag not relevant documents, what best
describes the set of unflagged documents?
C.3 Interview questions
1. What are your thoughts about this experiment and search strategy
did you apply?
2. What are your thoughts on providing negative feedback?
3. What difference did you feel between the two flagging tasks?

References
Anderson, J. R. and Milson, R. (1989). Human memory: An adaptive perspective.
Psychological Review, 96(4):703.
Athukorala, K., Medlar, A., Oulasvirta, A., Jacucci, G., and Glowacka, D. (2016). Be-
yond relevance: Adapting exploration/exploitation in information retrieval. In Pro-
ceedings of the 21st International Conference on Intelligent User Interfaces, pages
359–369. ACM.
Balakrishnan, V., Ahmadi, K., and Ravana, S. D. (2016). Improving retrieval relevance
using users explicit feedback. Aslib Journal of Information Management, 68(1):76–
98.
Bates, M. J. (1989). The design of browsing and berrypicking techniques for the online
search interface. Online review, 13(5):407–424.
Belkin, N. J., Cabezas, A., Cool, C., Kim, K., Ng, K. B., Park, S., Pressman, R., Rieh,
S. Y., Savage-Knepshield, P. A., and Xie, H. (1997). Rutgers interactive track at
trec-5. NIST SPECIAL PUBLICATION SP, pages 257–266.
Belkin, N. J. et al. (1993). Interaction with texts: Information retrieval as information
seeking behavior. Information retrieval, 93:55–66.
Belkin, N. J., Perez Carballo, J., Lin, S., Park, S., Rich, S., Savage, P., Sikora, C., Xie,
H., Cool, C., and Allan, J. (1998). Rutgers’ trec-6 interactive track experience. In
TREC, pages 221–229.
Buckley, C. (2004). Why current ir engines fail. In Proceedings of the 27th annual
international ACM SIGIR conference on Research and development in information
retrieval, pages 584–585. ACM.
Buckley, C. (2009). Why current ir engines fail. Information Retrieval, 12(6):652.
38

References 39
Cao, G., Nie, J.-Y., Gao, J., and Robertson, S. (2008). Selecting good expansion
terms for pseudo-relevance feedback. In Proceedings of the 31st annual inter-
national ACM SIGIR conference on Research and development in information re-
trieval, pages 243–250. ACM.
Cole, C. (2011). A theory of information need for information retrieval that connects
information to knowledge. Journal of the American Society for Information Science
and Technology, 62(7):1216–1231.
Dillon, A. and Song, M. (1997). An empirical comparison of the usability for novice
and expert searchers of a textual and a graphic interface to an art-resource database.
Frakes, W. B. and Baeza-Yates, R. (1992). Information retrieval: Data structures &
algorithms, volume 331. prentice Hall Englewood Cliffs, New Jersey.
Gay, G., Haiduc, S., Marcus, A., and Menzies, T. (2009). On the use of relevance
feedback in ir-based concept location. In Software Maintenance, 2009. ICSM 2009.
IEEE International Conference on, pages 351–360. IEEE.
Hassan, M. D. (2017). Information seeking behavior among undergraduates students
engaged in twitter. Journal of Pan African Studies, 10(10):143–153.
Hearst, M. (2006). Design recommendations for hierarchical faceted search interfaces.
In ACM SIGIR workshop on faceted search, pages 1–5. Seattle, WA.
Hearst, M. A. and Pedersen, J. O. (1996). Reexamining the cluster hypothesis: scat-
ter/gather on retrieval results. In Proceedings of the 19th annual international ACM
SIGIR conference on Research and development in information retrieval, pages 76–
84. ACM.
Hogeweg-de Haart, H. (1984). Characteristics of social science information: A selec-
tive review of the literature. part ii. Social Science Information Studies, 4(1):15–30.
Hu, C., Zhang, Y., and Chen, G. (2010). Exploring a new model for preprint server: A
case study of cspo. The Journal of Academic Librarianship, 36(3):257–262.
Jansen, B. J. and McNeese, M. D. (2005). Evaluating the effectiveness of and patterns
of interactions with automated searching assistance. Journal of the Association for
Information Science and Technology, 56(14):1480–1503.

References 40
Joachims, T., Granka, L., Pan, B., Hembrooke, H., and Gay, G. (2017). Accurately in-
terpreting clickthrough data as implicit feedback. In ACM SIGIR Forum, volume 51,
pages 4–11. Acm.
Jones, K. S., Walker, S., and Robertson, S. E. (2000). A probabilistic model of infor-
mation retrieval: development and comparative experiments: Part 2. Information
processing & management, 36(6):809–840.
Jung, S., Herlocker, J. L., and Webster, J. (2007). Click data as implicit relevance
feedback in web search. Information Processing & Management, 43(3):791–807.
Karimzadehgan, M. (2012). Systematic optimization of search engines for difficult
queries. PhD thesis, University of Illinois at Urbana-Champaign.
Karimzadehgan, M. and Zhai, C. (2011). Improving retrieval accuracy of difficult
queries through generalizing negative document language models. In Proceedings of
the 20th ACM international conference on Information and knowledge management,
pages 27–36. ACM.
Karlgren, J. and Sahlgren, M. (2001). From words to understanding.
Kelly, D. and Fu, X. (2006). Elicitation of term relevance feedback: an investigation of
term source and context. In Proceedings of the 29th annual international ACM SI-
GIR conference on Research and development in information retrieval, pages 453–
460. ACM.
Kelly, D. and Sugimoto, C. R. (2013). A systematic review of interactive informa-
tion retrieval evaluation studies, 1967–2006. Journal of the American Society for
Information Science and Technology, 64(4):745–770.
Kelly, D. and Teevan, J. (2003). Implicit feedback for inferring user preference: a
bibliography. In Acm Sigir Forum, volume 37, pages 18–28. ACM.
Kuhn, L. and Eickhoff, C. (2016). Implicit negative feedback in clinical information
retrieval. arXiv preprint arXiv:1607.03296.
Lai, R. Y. and Chan, K. F. (2013). Method and apparatus for securely invoking a rest
api. US Patent 8,621,598.
Lam, A. N., Nguyen, A. T., Nguyen, H. A., and Nguyen, T. N. (2015). Combin-
ing deep learning with information retrieval to localize buggy files for bug reports

References 41
(n). In Automated Software Engineering (ASE), 2015 30th IEEE/ACM International
Conference on, pages 476–481. IEEE.
Larson, R. R. (2010). Introduction to information retrieval. Journal of the American
Society for Information Science and Technology, 61(4):852–853.
Le, Q. and Mikolov, T. (2014). Distributed representations of sentences and docu-
ments. In International Conference on Machine Learning, pages 1188–1196.
Line, M. B. (1969). Information requirements in the social sciences: some preliminary
considerations. Journal of librarianship, 1(1):1–19.
Medlar, A., Ilves, K., Wang, P., Buntine, W., and Glowacka, D. (2016). Pulp: A
system for exploratory search of scientific literature. In Proceedings of the 39th
International ACM SIGIR conference on Research and Development in Information
Retrieval, pages 1133–1136. ACM.
Muller, H., Muller, W., Marchand-Maillet, S., Pun, T., and Squire, D. M. (2000).
Strategies for positive and negative relevance feedback in image retrieval. In Pattern
Recognition, 2000. Proceedings. 15th International Conference on, volume 1, pages
1043–1046. IEEE.
Nemoto, T. and Beglar, D. (2014). Likert-scale questionnaires. In JALT 2013 Confer-
ence Proceedings, pages 1–8.
O’Cathain, A. and Thomas, K. J. (2004). ” any other comments?” open questions on
questionnaires–a bane or a bonus to research? BMC medical research methodology,
4(1):25.
Palomino, M. A., Oakes, M. P., and Wuytack, T. (2009). Automatic extraction of
keywords for a multimedia search engine using the chi-square test. In Proceedings
of the 9th Dutch–Belgian information retrieval workshop (DIR 2009), pages 3–10.
Peltonen, J., Strahl, J., and Floreen, P. (2017). Negative relevance feedback for ex-
ploratory search with visual interactive intent modeling. In Proceedings of the 22nd
International Conference on Intelligent User Interfaces, pages 149–159. ACM.
Pirolli, P. (2007). Information foraging theory: Adaptive interaction with information.
Oxford University Press.

References 42
Pirolli, P. and Card, S. (1999). Information foraging. Psychological review,
106(4):643.
Reja, U., Manfreda, K. L., Hlebec, V., and Vehovar, V. (2003). Open-ended vs.
close-ended questions in web questionnaires. Developments in applied statistics,
19(1):160–117.
Rocchio, J. J. (1966). Document retrieval system-optimization and.
Rocchio, J. J. (1971). Relevance feedback in information retrieval. The SMART re-
trieval system: experiments in automatic document processing, pages 313–323.
Ruthven, I., Baillie, M., and Elsweiler, D. (2007). The relative effects of knowl-
edge, interest and confidence in assessing relevance. Journal of Documentation,
63(4):482–504.
Ruthven, I. and Lalmas, M. (2003). A survey on the use of relevance feedback for
information access systems. The Knowledge Engineering Review, 18(2):95–145.
Salton, G. and Buckley, C. (1990). Improving retrieval performance by relevance
feedback. Journal of the American society for information science, 41(4):288–297.
Singhal, A. et al. (2001). Modern information retrieval: A brief overview. IEEE Data
Eng. Bull., 24(4):35–43.
Singhal, A., Mitra, M., and Buckley, C. (1997). Learning routing queries in a query
zone. In ACM SIGIR Forum, volume 31, pages 25–32. ACM.
Stone, S. (1982). Humanities scholars: information needs and uses. Journal of docu-
mentation, 38(4):292–313.
Van Rijsbergen, C. (1979). Information retrieval. dept. of computer science, university
of glasgow. URL: citeseer. ist. psu. edu/vanrijsbergen79information. html, 14.
Wang, X., Fang, H., and Zhai, C. (2007). Improve retrieval accuracy for difficult
queries using negative feedback. In Proceedings of the sixteenth ACM conference
on Conference on information and knowledge management, pages 991–994. ACM.
Wang, X., Fang, H., and Zhai, C. (2008). A study of methods for negative relevance
feedback. In Proceedings of the 31st annual international ACM SIGIR conference
on Research and development in information retrieval, pages 219–226. ACM.

References 43
Wilson, T. D. (2000). Human information behavior. Informing science, 3(2):49–56.
Yee, K.-P., Swearingen, K., Li, K., and Hearst, M. (2003). Faceted metadata for image
search and browsing. In Proceedings of the SIGCHI conference on Human factors
in computing systems, pages 401–408. ACM.
Zhou, X. S. and Huang, T. S. (2003). Relevance feedback in image retrieval: A com-
prehensive review. Multimedia systems, 8(6):536–544.