enterprise hybrid cloud 4 - dell emc · pdf fileenterprise hybrid cloud 4.0 concepts and...
TRANSCRIPT

Solution Guide
ENTERPRISE HYBRID CLOUD 4.0 Concepts and Architecture Guide
EMC Solutions
Abstract
This Solution Guide provides an introduction to the concepts and architectural options available within Enterprise Hybrid Cloud. It should be used as an aid to deciding on the most suitable configuration for the initial deployment of Enterprise Hybrid Cloud.
October 2016

Copyright
2 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Copyright © 2016 EMC Corporation. All rights reserved. Published in the USA.
Published October 2016
EMC believes the information in this publication is accurate as of its publication date. The information is subject to change without notice.
The information in this publication is provided as is. EMC Corporation makes no representations or warranties of any kind with respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a particular purpose. Use, copying, and distribution of any EMC software described in this publication requires an applicable software license.
EMC2, EMC, Avamar, Data Domain, Data Protection Advisor, Enginuity, GeoSynchrony, Hybrid Cloud, PowerPath/VE, RecoverPoint, SMI-S Provider, Solutions Enabler, VMAX, Syncplicity, Unisphere, ViPR, EMC ViPR Storage Resource Management, Virtual Storage Integrator, VNX, VPLEX, VPLEX, Geo, VPLEX Metro, and the EMC logo are registered trademarks or trademarks of EMC Corporation in the United States and other countries. All other trademarks used herein are the property of their respective owners.
For the most up-to-date listing of EMC product names, see EMC Corporation Trademarks on EMC.com.
Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide Solution Guide
Part Number H15192.2

Contents
3 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Contents
Chapter 1 Executive Summary 5
Enterprise Hybrid Cloud .............................................................................................. 6
Document purpose ..................................................................................................... 6
Audience .................................................................................................................... 6
Essential reading ........................................................................................................ 6
Solution purpose ........................................................................................................ 7
Business challenge .................................................................................................... 7
Technology solution ................................................................................................... 8
We value your feedback!............................................................................................. 8
Chapter 2 Cloud Management Platform Options 9
Overview .................................................................................................................. 10
Cloud management platform components ................................................................ 11
Cloud management platform model .......................................................................... 14
Component high availability ..................................................................................... 15
Chapter 3 Object Model 17
Object model overview ............................................................................................. 18
Foundational objects ................................................................................................ 19
Data protection (backup) objects .............................................................................. 26
Chapter 4 Multi-Site and Multi-vCenter Protection Services 31
vCenter endpoints .................................................................................................... 32
Protection services ................................................................................................... 32
Single-site protection service ................................................................................... 34
Continuous Availability (Single-site) protection service ............................................ 35
Continuous Availability (Dual-site) Protection Service ............................................... 37
Disaster recovery (RecoverPoint for Virtual Machines) Protection Service ................. 42
Disaster recovery (VMware Site Recovery Manager) Protection Service ..................... 43
Combining protection services ................................................................................. 47
Multi-vCenter and Multi-site topologies .................................................................... 58
VCE platforms and Enterprise Hybrid Cloud .............................................................. 69
Chapter 5 Network Considerations 74
Overview .................................................................................................................. 75
Cross-vCenter VMware NSX....................................................................................... 75

Contents
4 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Physical connectivity considerations ........................................................................ 76
Logical network considerations ................................................................................ 77
Network virtualization .............................................................................................. 84
Network requirements and best practices ................................................................. 89
Enterprise Hybrid Cloud validated network designs using VMware NSX .................... 93
Chapter 6 Storage Considerations 106
Single-site and RecoverPoint for Virtual Machines DR storage considerations......... 107
Continuous availability storage considerations ...................................................... 111
Disaster recovery (Site Recovery Manager) storage considerations ......................... 122
Chapter 7 Data Protection (Backup-as-a-Service) 125
Overview ................................................................................................................ 126
Concepts ................................................................................................................ 127
Chapter 8 Ecosystem Interactions 144
Enterprise Hybrid Cloud ecosystems ....................................................................... 145
Chapter 9 Maximums, Rules, Best Practices, and Restrictions 149
Overview ................................................................................................................ 150
Maximums ............................................................................................................. 150
VMware Platform Services Controller rules .............................................................. 154
VMware vRealize tenants and business groups ...................................................... 156
EMC ViPR tenant and projects rules ........................................................................ 157
General storage considerations .............................................................................. 158
Bulk import of virtual machines .............................................................................. 159
Resource sharing .................................................................................................... 159
Data protection considerations............................................................................... 160
RecoverPoint for Virtual Machines best practices .................................................... 160
Software resources ................................................................................................. 160
Sizing guidance ...................................................................................................... 161
Restrictions ............................................................................................................ 161
Component options ................................................................................................ 163
Chapter 10 Conclusion 164
Conclusion ............................................................................................................. 165

Chapter 1: Executive Summary
5 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 1 Executive Summary
This chapter presents the following topics:
Enterprise Hybrid Cloud ............................................................................................. 6
Document purpose ..................................................................................................... 6
Audience .................................................................................................................... 6
Essential reading ....................................................................................................... 6
Solution purpose........................................................................................................ 7
Business challenge .................................................................................................... 7
Technology solution ................................................................................................... 8
We value your feedback! ............................................................................................ 8

Chapter 1: Executive Summary
6 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Enterprise Hybrid Cloud
Enterprise Hybrid Cloud 4.0 is a converged cloud platform that provides a completely virtualized data center, fully automated by software. It starts with a foundation that delivers IT as a service (ITaaS), with options for high availability, backup and recovery, and disaster recovery (DR) as tiers of service within the same environment. It also provides a framework and foundation for add-on modules, such as database as a service (DaaS), platform as a service (PaaS), and cloud brokering.
Document purpose
This solution guide provides an introduction to the concepts and architectural options available within Enterprise Hybrid Cloud. It should be used as an aid to deciding on the most suitable configuration for the initial deployment of Enterprise Hybrid Cloud.
Audience
This solution guide is intended for executives, managers, architects, cloud administrators, security manager, developers, and technical administrators of IT environments who want to implement a hybrid cloud infrastructure as a service (IaaS) platform. Readers should be familiar with the VMware® vRealize® Suite, storage technologies, general IT functions and requirements, and how a hybrid cloud infrastructure accommodates these technologies and requirements.
Essential reading
The Enterprise Hybrid Cloud 4.0 Reference Architecture describes the reference architecture for Enterprise Hybrid Cloud. The guide introduces the features and functionality of the solution, the solution architecture and key components, and the validated hardware and software environments.
The following guides provide further information about various aspects of Enterprise Hybrid Cloud:
Enterprise Hybrid Cloud 4.0 Reference Architecture
Enterprise Hybrid Cloud 4.0 Administration Guide
Enterprise Hybrid Cloud 4.0 Infrastructure and Operations Management Guide
Enterprise Hybrid Cloud 4.0 Security Management Guide

Chapter 1: Executive Summary
7 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Solution purpose
Enterprise Hybrid Cloud enables customers to build an enterprise-class, multisite, scalable infrastructure that enables:
Complete management of the infrastructure service lifecycle
On-demand access to and control of network bandwidth, servers, storage, and security
On-demand provisioning, monitoring, protection, and management of the infrastructure services by the line of business users
On-demand provisioning of application blueprints with associated infrastructure resources by line-of-business application owners
Simplified provisioning of backup, continuous availability (CA), and disaster recovery services as part of the cloud service provisioning process
Maximum asset use
Increased scalability with centrally managed multisite platforms spanning IT services to all data centers
Business challenge
While many organizations have successfully introduced virtualization as a core technology within their data center, the benefits of virtualization have largely been restricted to the IT infrastructure owners. End users and business units within customer organizations have not experienced many of the benefits of virtualization, such as increased agility, mobility, and control.
Transforming from the traditional IT model to a cloud-operating model involves overcoming the challenges of legacy infrastructure and processes, such as:
Inefficiency and inflexibility
Slow, reactive responses to customer requests
Inadequate visibility into the cost of the requested infrastructure
Limited choice of availability and protection services
The difficulty in overcoming these challenges has given rise to public cloud providers who have built technology and business models catering to the requirements of end-user agility and control. Many organizations are under pressure to provide similar service levels within the secure and compliant confines of the on-premises data center. As a result, IT departments must create cost-effective alternatives to public cloud services, alternatives that do not compromise enterprise features such as data protection, DR, and guaranteed service levels.

Chapter 1: Executive Summary
8 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Technology solution
Enterprise Hybrid Cloud integrates the best of EMC, VCE, and VMware products and services, and empowers IT organizations to accelerate implementation and adoption of a hybrid cloud infrastructure, while still enabling customer choice for the compute and networking infrastructure within the data center. The solution caters to customers who want to preserve their investment and make better use of their existing infrastructure and to those customers who want to build out new infrastructures dedicated to a hybrid cloud.
This solution takes advantage of the strong integration between EMC technologies and the vRealize Suite. The solution, developed by EMC and VMware product and services teams includes EMC scalable storage arrays, VCE converged infrastructure, integrated EMC and VMware monitoring, and data protection suites to provide the foundation for enabling cloud services within the customer environment.
Enterprise Hybrid Cloud offers several key benefits to customers:
Rapid implementation: Enterprise Hybrid Cloud offers the foundations IaaS and can be designed and implemented in a validated, tested, and repeatable way based on VCE converged infrastructure. This increases the time-to-value for the customer while simultaneously reducing risk. Deliver ITaaS with add-on modules for backup, DR, CA, virtual machine encryption, applications, application lifecycle automation for continuous delivery, ecosystem extensions, and more.
Supported cloud platform: Implementing Enterprise Hybrid Cloud through EMC results in a cloud platform that EMC supports and further reduces risk that is associated with the ongoing operations of your hybrid cloud.
Defined upgrade path: Customers implementing Enterprise Hybrid Cloud receive upgrade guidance based on the testing and validation completed by the engineering teams. This upgrade guidance enables customers, partners, and EMC services teams to perform upgrades faster and with much less risk.
Validated and tested integration: Build guides have been developed and extensive integration testing has been carried out by engineering across the solution, making it simpler to use and manage, and more efficient to operate.
We value your feedback!
EMC and the authors of this document welcome your feedback on the solution and the solution documentation. Please contact us at [email protected] with your comments.
Authors: Ken Gould, Fiona O’Neill

Chapter 2: Cloud Management Platform Options
9 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 2 Cloud Management Platform Options
This chapter presents the following topics:
Overview .................................................................................................................. 10
Cloud management platform components ................................................................ 11
Cloud management platform model ......................................................................... 14
Component high availability .................................................................................... 15

Chapter 2: Cloud Management Platform Options
10 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Overview
The Cloud Management Platform supports the entire management infrastructure for this solution. This management infrastructure is divided into three pods (functional areas), which consist of one or more VMware vSphere® ESXi™ clusters and/or vSphere resource groups, depending on the model deployed. Each pod performs a solution-specific function.
This chapter describes the components of the management platform and the models available for use. After reading it, you should be able to decide on the model that suits your environment.
To understand how the management platform is constructed, it is important to understand how a number of terms are used throughout this guide. Figure 1 shows the relationship between platform, pod, and cluster and their relative scopes as used in Enterprise Hybrid Cloud.
Note: It is important to understand that the term pod does not imply a vSphere cluster. A pod may be distributed across multiple vSphere clusters.
Figure 1. Cloud management terminology and hierarchy
The following distinctions exist in terms of the scope of each term:
Platform (cloud management platform) is an umbrella term intended to represent the entire management environment.
Pod (management pod). Each management pod is a subset of the overall management platform and represents a distinct area of functionality. Management pod functions may be distributed between vSphere clusters or consolidated onto vSphere clusters, depending on the individual Enterprise Hybrid Cloud managed vCenter endpoint requirements.
Cluster (technology cluster) is used in the context of the individual technologies. While it may refer to vSphere clusters, it can also refer to EMC VPLEX® clusters, EMC RecoverPoint® clusters, and so on.
Purpose
Management terminology and hierarchy

Chapter 2: Cloud Management Platform Options
11 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Resource pools. Non-default resource pools are used only when two or more management pods are collapsed onto the same vSphere cluster. In this case, they are used to control and guarantee resources to each affected pod.
Cloud management platform components
When Enterprise Hybrid Cloud is deployed, the first location requires a full management stack to be deployed. Figure 2 shows how the components of the full management stack are distributed among the management pods.
Figure 2. Enterprise Hybrid Cloud full management stack
The Core Pod function provides the base set of resources to establish Enterprise Hybrid Cloud services. It consists of:
Cloud VMware vCenter Server: This vCenter instance is used to manage the components and compute resources that host the Network Edge Infrastructure (NEI) Pod functions (Edge and distributed logical router (DLR) components) cluster, and Automation Pod functions. VMware vRealize® Automation™ uses this vCenter Server as its endpoint from which the vSphere clusters are reserved for use by vRealize Automation business groups.
Full management stack components
Core Pod function

Chapter 2: Cloud Management Platform Options
12 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: While Figure 2 depicts vCenter, Update Manager, and Platform Services Controller (PSC) as one cell of related components, they are deployed as separate virtual machines.
Microsoft SQL Server: Hosts SQL Server databases used by the Cloud vCenter Server and VMware Update Manager™. It also hosts the VMware vCenter Site Recovery Manager™ (SRM) database when SRM-based DR protection is deployed.
VMware NSX®: Used to deploy and manage the virtual networks for the management infrastructure and Workload Pods.
EMC SMI-S Provider: Management infrastructure required by EMC ViPR®.
Log Insight Forwarders and vRealize Operations Manager collectors
When deployed on a VCE converged system such as VxBlock, the Core Pod function resides on the VCE Advanced Management Pod (AMP) system and overlays with the existing AMP components for maximum efficiency.
All storage should be redundant array of independent disks (RAID) protected and all vSphere ESXi servers should be configured with EMC PowerPath®/VE for automatic path management and load balancing.
The Network Edge Infrastructure (NEI) Pod function is only required where VMware NSX is deployed, and is made up of NSX controllers, north-south NSX Edge Services Gateway (ESG) devices, and NSX DLR control virtual machines.
Use vSphere Distributed Resource Scheduler (DRS) rules to ensure that NSX controllers are separated from each other, and also to ensure that primary ESGs are separated from primary DLRs so that a host failure does not affect network availability. The NEI Pod function provides the convergence point for the physical and virtual networks.
Like the Core Pod function, storage for this pod should be RAID protected, Enterprise Hybrid Cloud recommends Fibre Channel (FC) connections. vSphere ESXi hosts should run PowerPath/VE for automatic path management and load balancing.
The Automation Pod function is made up of the remaining virtual machines used for automating and managing the cloud infrastructure. It supports the services responsible for functions such as the user portal, automated provisioning, monitoring, and metering.
It is managed by the Cloud vCenter Server instance but is dedicated to automation and management services. Therefore, the compute resources that support the Automation Pod function are not exposed to vRealize Automation business groups.
To ensure independent failover capability, the Automation Pod function may not share storage resources with the workload clusters. For the same reasons, it may not share networks and should be on a distinctly different Layer 3 network to both the Core and NEI management pod functions. Storage provisioning for the Automation Pod function follows the same guidelines as the NEI Pod function. Automation Pod networks may be VxLANs managed by NSX.
Network Edge Infrastructure Pod function
Automation Pod function

Chapter 2: Cloud Management Platform Options
13 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: While Figure 2 depicts vRealize IaaS as one cell of related components, the individual vRealize Automation roles are actually deployed as separate virtual machines.
Workload Pods are configured and assigned to fabric groups in vRealize Automation. Available resources are used to host tenant workload virtual machines deployed by business groups in the Enterprise Hybrid Cloud environment. All business groups can share the available vSphere ESXi cluster resources.
ViPR service requests are initiated from the vRealize Automation catalog to provision Workload Pod storage.
When an additional vCenter endpoint is configured for use in Enterprise Hybrid Cloud, that endpoint only requires a subset of the management stack to operate. Figure 3 shows how the components of the endpoint management stack are distributed among the management pods.
Figure 3. Enterprise Hybrid Cloud endpoint management stack
As with the full management stack, the NEI Pod function is only required if VMware NSX is used.
vRealize Automation agents are deployed for each endpoint to follow best practice and are geographically co-located to ensure predictable performance. While they are Automation Pod components from an Enterprise Hybrid Cloud perspective, the location of any of the pods in terms of physical infrastructure is flexible, based on the platform of choice. Additional vRealize distributed execution managers (DEMs) may also be required, depending on the overall run rate of tasks in the cloud environment.
Workload Pods
Endpoint Management Stack
Chapter 2: Cloud Management Platform Options
14 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Cloud management platform model
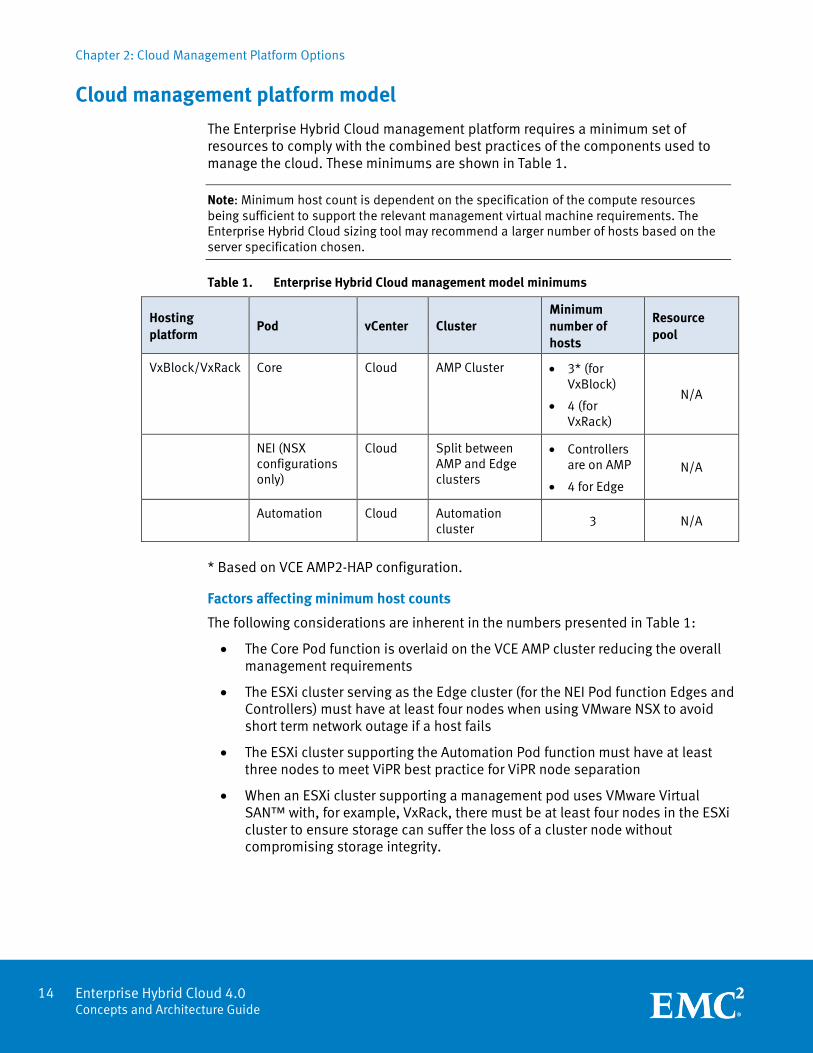
The Enterprise Hybrid Cloud management platform requires a minimum set of resources to comply with the combined best practices of the components used to manage the cloud. These minimums are shown in Table 1.
Note: Minimum host count is dependent on the specification of the compute resources being sufficient to support the relevant management virtual machine requirements. The Enterprise Hybrid Cloud sizing tool may recommend a larger number of hosts based on the server specification chosen.
Table 1. Enterprise Hybrid Cloud management model minimums
Hosting platform
Pod vCenter Cluster Minimum number of hosts
Resource pool
VxBlock/VxRack Core Cloud AMP Cluster 3* (for VxBlock)
4 (for VxRack)
N/A
NEI (NSX configurations only)
Cloud Split between AMP and Edge clusters
Controllers are on AMP
4 for Edge N/A
Automation Cloud Automation cluster
3 N/A
* Based on VCE AMP2-HAP configuration.
Factors affecting minimum host counts
The following considerations are inherent in the numbers presented in Table 1:
The Core Pod function is overlaid on the VCE AMP cluster reducing the overall management requirements
The ESXi cluster serving as the Edge cluster (for the NEI Pod function Edges and Controllers) must have at least four nodes when using VMware NSX to avoid short term network outage if a host fails
The ESXi cluster supporting the Automation Pod function must have at least three nodes to meet ViPR best practice for ViPR node separation
When an ESXi cluster supporting a management pod uses VMware Virtual SAN™ with, for example, VxRack, there must be at least four nodes in the ESXi cluster to ensure storage can suffer the loss of a cluster node without compromising storage integrity.

Chapter 2: Cloud Management Platform Options
15 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: For ultimate resilience and ease of use during maintenance windows, creating vSphere cluster sizes based on N+2 sizing may be appropriate based on customer preference, where N is calculated as the number of hosts required to support the management pod functions based on the CPU and RAM requirements for the hosted virtual machines plus host system overhead. The Enterprise Hybrid Cloud sizing tool sizes vSphere clusters based on an N+1 algorithm by default, but allows N+2 selection too.
Enterprise Hybrid Cloud employs a management model that by default uses a single vCenter Server instance to host all Core, Automation, and NEI Pod functions as well as the Workload Pods. The NSX Edge and DLR components of the NEI Pod function are hosted by an Edge cluster. A second cluster hosts all of the Automation Pod function components, except the vRealize Automation agents, which are located on the AMP for co-locality with the Cloud vCenter they connect to.
Note: This is important when the Automation Pod is moved to another site through disaster recovery mechanisms, because it maintains the co-locality.
This management model:
Provides the highest level of resource separation (that is, host level) between the Core, Automation, and NEI Pod functions.
Places the NEI Edge and DLR components of the NEI Pod function on an Edge cluster that serves as the single intersection point between the physical and virtual networks configured within the cloud. This eliminates the need to have critical networking components compete for resources as the cloud scales and the demands of other areas of the cloud management platform increase.
Is compatible with VxBlock and VxRack NSX factory deployments, and uses the VCE AMP vCenter as the Cloud vCenter.
Component high availability
The use of vSphere ESXi clusters with VMware vSphere High Availability (HA) provides general virtual machine protection across the management platform. Further levels of availability can be provided by using nested clustering technologies between the component virtual machines, such as Windows Failover Clustering, PostgreSQL clustering, load balancer clustering, or farms of machines that work together natively in an N+1 architecture, to provide a resilient architecture.
Enterprise Hybrid Cloud requires the use of distributed vRealize Automation installations. In this model, multiple instances of each vRealize Automation role are deployed behind a load balancer to ensure scalability and fault tolerance.
Note: All-in-one vRealize Automation installations are not supported for production use.
VMware NSX load balancing technology is fully supported, tested, and validated by Enterprise Hybrid Cloud. Other load balancer technologies supported by VMware for use in vRealize Automation deployments are permitted, but configuration assistance for those technologies should be provided by VMware or the specific vendor.
Management model
Distributed vRealize Automation

Chapter 2: Cloud Management Platform Options
16 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: Use of a load balancer technology not officially supported by Enterprise Hybrid Cloud or VMware with vRealize Automation requires an Enterprise Hybrid Cloud RPQ.
Both clustered and stand-alone VMware vRealize Orchestrator™ installations are supported by Enterprise Hybrid Cloud.
Table 2 details the specific component high availability options.
Table 2. vRealize Automation and vRealize Orchestrator High Availability options
Management model
Distributed vRealize Automation
Minimal vRealize Automation (AIO)
Clustered vRealize Orchestrator (active/active)
Stand-alone vRealize Orchestrator
Distributed Supported Not supported Supported Supported
Highly available configurations for VMware Platform Services Controller are not supported in Enterprise Hybrid Cloud 4.0.
The cloud management platform for Enterprise Hybrid Cloud may be made resilient across sites using any of the supported multi-site protection models that are deployed in the Enterprise Hybrid Cloud environment.
Note: EMC recommends that when multi-site protection is available within the Enterprise Hybrid Cloud environment, that the management platform should also be protected, as it may not be possible to recover tenant workloads to a secondary site without recovering elements of the management platform first. We also recommend that you protect the management platform with the highest form of multi-site protection available in your Enterprise Hybrid Cloud environment.
Clustered vRealize Orchestrator
Highly available VMware Platform Services Controller
Multi-site protection for the management platform

Chapter 3: Object Model
17 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 3 Object Model
This chapter presents the following topics:
Object model overview ............................................................................................. 18
Foundational objects ................................................................................................ 19
Data protection (backup) objects ............................................................................. 26

Chapter 3: Object Model
18 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Object model overview
Enterprise Hybrid Cloud 4.0 introduces an object model that provides the framework for storing and referencing metadata related to infrastructure and compute resources. It acts as the rules engine for provisioning storage, backup service levels, and inter-site or intra-site protection services.
Note: Upgrade of existing Enterprise Hybrid Cloud environments to the object model is fully supported and covered by the included upgrade procedure.
The Enterprise Hybrid Cloud object model is presented to vRealize Orchestrator through a combination of the Enterprise Hybrid Cloud vRealize Orchestrator plug-in and the VMware Dynamic Data Types plug-in. All model data is stored in a Microsoft SQL Server database on the Automation Pod SQL Server instance, and can be referenced by all vRealize Orchestrator nodes.
Figure 4 shows the Enterprise Hybrid Cloud object model and the relationships between the individual object types.
Overview

Chapter 3: Object Model
19 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 4. Enterprise Hybrid Cloud object model
Foundational objects
The Enterprise Hybrid Cloud object model requires several fundamental connections to establish operations. These connections are:
VMware vRealize Automation
VMware vRealize IaaS
VMware vRealize Orchestrator
EMC ViPR
Active Directory
Simple Mail Transfer Protocol (SMTP) (optional)
Connections

Chapter 3: Object Model
20 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Additional connections are required when disaster recovery as a service (DRaaS) using SRM is deployed in the Enterprise Hybrid Cloud environment. These connections are:
VMware NSX Manager (if used)
Simple Object Access Protocol (SOAP) connections for SRM
SQL Server connections for SRM
All of these connections are configured within the object model as part of the Day 1 installation and configuration of the Enterprise Hybrid Cloud environment. They can also be re-configured as required via Day 2 catalog items in the vRealize Automation portal.
Figure 5 shows an example of Enterprise Hybrid Cloud connection objects created in the Enterprise Hybrid Cloud object model as presented and referenceable through vRealize Orchestrator.
Figure 5. vRealize Orchestrator view of on-boarded Enterprise Hybrid Cloud connections
The Enterprise Hybrid Cloud object model contains many options that can be used to control behavior of the system across all sites and infrastructure. Some of these are internal controls that are visible but cannot be manipulated directly by an Enterprise Hybrid Cloud administrator. Other options may be manipulated by the cloud administrator through the Global Options Maintenance vRealize catalog item.
Items that may be manipulated by the administrator are:
san_boot_hlu
ehc_vpc_disabled
ca_enabled
data_domain_available
hwi_srp_policy_enabled
Options

Chapter 3: Object Model
21 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
log_level
default_vipr_project
avamar_replication_port
Descriptions on each of these options are presented in context in the relevant chapters.
Figure 6 shows an example of Enterprise Hybrid Cloud options in the Enterprise Hybrid Cloud object model as presented and referenceable through vRealize Orchestrator.
Figure 6. vRealize Orchestrator view of Enterprise Hybrid Cloud options
Enterprise Hybrid cloud now supports up to five sites, depending on the combination of protection services deployed in the environment. In the object model, the sites are the first items to be created and all other items depend on one or more sites. The following objects all contain a site property:
vCenter Endpoints
Hardware Islands
Clusters
Avamar Grids
Avamar Site Relationships
Sites

Chapter 3: Object Model
22 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
In Enterprise Hybrid Cloud, a site is a geographic location and is the key factor in determining the following:
The workloads that may share the same Avamar and EMC Data Domain® backup infrastructure.
All workloads determined to be on the same site (irrespective of their hardware island, vCenter, or cluster) may share the same backup infrastructure for efficiencies in terms of data center space and backup deduplication.
The vCenters that may be used as partner vCenters for DR relationships
The Enterprise Hybrid Cloud object model enforces the rule that vCenters in a DR relationship must contain two distinct sites.
From a metadata perspective, a site object contains just one user-defined property, that is, the user-provided name for the site.
Figure 7 shows an example of a site created in the Enterprise Hybrid Cloud object model as presented and referenceable through vRealize Orchestrator.
Figure 7. vRealize Orchestrator view of an on-boarded Enterprise Hybrid Cloud site
Enterprise Hybrid Cloud supports up to four Enterprise Hybrid Cloud-managed VMware vCenters endpoints. Each managed vCenter endpoint can be configured as a vRealize Automation vCenter endpoint with the ability to provide any of the following services:
Infrastructure as a service (IaaS)
Storage as a service (STaaS)
Backup as a service (BaaS)
Disaster recovery as a service (DRaaS)
vCenters

Chapter 3: Object Model
23 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
To facilitate DRaaS, each vCenter endpoint may be configured with a vCenter partner for SRM or RecoverPoint for Virtual Machines purposes. This allows the solution to scale out in the following ways:
Increases the number of workload virtual machine s that may be protected by either Site Recovery Manager or RecoverPoint for Virtual Machines
Increases the number of target sites that workloads can be protected to (via different vCenter DR relationships)
vCenter endpoints can be added to the Enterprise Hybrid Cloud model as a Day 2 operation through the vRealize Automation Catalog item vCenter Endpoint Maintenance.
Figure 8 shows an example of a vCenter endpoint created in the Enterprise Hybrid Cloud object model as presented and referenceable through vRealize Orchestrator.
Figure 8. vRealize Orchestrator view of an on-boarded vCenter endpoint
Hardware islands allow multiple converged infrastructure platforms to be logically aggregated (for scale) or partitioned (for isolation) inside a single vCenter while retaining awareness of physical network, storage and site boundaries. This awareness is then used to ensure that correct inter-site and intra-site protection services are applied to cloud workloads. As a result, the hardware island concept is the key determining factor in configuring vSphere clusters that offer inter or intra site resilience, that is, these services must span more than one hardware island by definition or they would not be in different fault domains.
The properties of a hardware island can be defined as follows:
It is a set of ESXi clusters and ViPR virtual arrays.
A hardware island can belong to only one vCenter. Therefore, clusters assigned to a hardware island must be from the corresponding vCenter.
It can be smaller than a single storage area network or storage array (in line with the capability of a virtual array.
Hardware islands

Chapter 3: Object Model
24 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
A hardware island can include multiple storage arrays if they are all in the same storage area network.
It may include items from different storage area networks if all clusters and arrays assigned to the hardware island are connected to each of those networks. This allows for independent SAN fabrics for redundancy.
A virtual array cannot not be a member of more than one hardware island
A vCenter can contain multiple hardware islands
When workloads reside on different hardware islands on the same site, they may share the same backup infrastructure, if required.
Figure 9 shows an example of a hardware island created in the Enterprise Hybrid Cloud object model as presented and referenceable through vRealize Orchestrator.
Figure 9. vRealize Orchestrator view of an on-boarded hardware island
A cluster object is created in the Enterprise Hybrid Could object model when a vSphere cluster is on-boarded through the vRealize Automation catalog. When on boarding clusters, each cluster must be given a type, which then dictates the type of storage that may be provisioned to the cluster.
Table 3 shows the cluster types available in the model.
Table 3. Cluster types
Datastore type Storage description
LC1S Local Copy on One Site
CA1S CA VPLEX Metro Storage on One Site
CA2S CA VPLEX Metro Storage across Two Sites
DR2S DR RecoverPoint Storage across Two Sites
Clusters

Chapter 3: Object Model
25 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
RecoverPoint for Virtual Machines workloads use LC1S clusters, as the storage itself is single-site storage and workloads are selectively replicated by RecoverPoint for Virtual Machines rather than underlying LUN level storage technology.
Figure 10 shows an example of a vSphere cluster on-boarded in the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Figure 10. vRealize Orchestrator view of an on-boarded vSphere Cluster
Datastore objects are created in the Enterprise Hybrid Cloud model when a storage provisioning operation is carried out by storage-as-a-service workflows against an on-boarded Enterprise Hybrid Cloud cluster. The cluster type is used to guide the user to provisions only suitable storage to that cluster.
After it is created, the datastore, properties regarding its service level offering (Storage Reservation Policy), and other details that support the backup-as-a-Service operations, are recorded.
Table 4 shows the available datastore types that can be created, in keeping with the cluster types that may be on-boarded.
Table 4. Datastore types
Cluster type Storage description
LC1S Local Copy on One Site
CA1S CA VPLEX Metro Storage on One Site
CA2S CA VPLEX Metro Storage across Two Sites
DR2S DR RecoverPoint Storage across Two Sites
Figure 11 shows an example of a datastore created in the Enterprise Hybrid Cloud object model by storage-as-a-service workflows, as presented and referenceable through vRealize Orchestrator.
Datastores

Chapter 3: Object Model
26 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 11. vRealize Orchestrator view of a STaaS-created datastore
Data protection (backup) objects
Avamar grids are introduced into the Enterprise Hybrid Cloud object model after the data protection packages have been installed and initialized. They are described in detail in Avamar grids.
Figure 12 shows an example of an Avamar grid on-boarded into the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Figure 12. vRealize Orchestrator view of an on-boarded Avamar grid
Avamar grids

Chapter 3: Object Model
27 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Backup types are the fixed rulesets that are automatically applied to Enterprise Hybrid Cloud workloads based on their protection service. They are described in detail in Backup types.
Table 5 shows the backup types available within Enterprise Hybrid Cloud, as well as the description of each type
Table 5. Backup types
Type Description
1C1VC One backup copy. Virtual machines are only on one site (one vCenter).
2C1VC Two backup copies. Virtual machines move between two sites (one vCenter).
2C2VC Two backup copies. Virtual machines move between two sites (two vCenters).
MC2VC Mixed number of copies. Virtual machines can be in up to two sites (two vCenters).
Figure 13 shows an example of an Avamar Site Relationship (ASR) created in the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Figure 13. vRealize Orchestrator view of a backup type
An Avamar Site Relationship (ASR) is a relationship between sites for backup purposes. They are described in detail in the corresponding Avamar Site Relationships.
Figure 14 shows an example of an ASR created in the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Backup types
Avamar Site Relationships

Chapter 3: Object Model
28 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 14. vRealize Orchestrator view of an Avamar Site Relationship
An Avamar Replication Relationship (ARR) is a relationship between two Avamar grids and is the object that determines the specific Avamar grids that are responsible for backup operations on an individual Enterprise Hybrid Cloud workload. They are described in detail in the corresponding Avamar Replication Relationships.
Figure 15 shows an example of an ARR created in the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Figure 15. vRealize Orchestrator view of an Avamar Replication Relationship
Avamar Replication Relationships

Chapter 3: Object Model
29 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Backup service levels are created through the Enterprise Hybrid Cloud vRealize Automation catalog item Create Backup Service Level. These backup service levels map to Backup Policies, which an IaaS user can elect to apply when deploying a workload as a Day 2 operation to an existing workload.
Each backup service level may have different settings for short and long term retention as well as backup and replication schedules.
Figure 16 shows an example of a backup service level created in the Enterprise Hybrid Cloud object model as presented and referenceable through vRealize Orchestrator.
Figure 16. vRealize Orchestrator view of an backup service level
Avamar backup groups are created on Avamar grids. They control the vCenter elements that are monitored by scheduled backup policies and triggered by on-demand backups. These backup groups are recorded in the object model and used to ensure that backup policies can follow their workloads as they are recovered to different sites.
Figure 17 shows an example of an Avamar backup group created in the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Backup service levels
Avamar backup groups

Chapter 3: Object Model
30 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 17. vRealize Orchestrator view of an Avamar backup group
Avamar replication groups are created on Avamar grids when multi-site ASRs and ARRs exist. They control the replication settings for scheduled backup and are triggered by on-demand backups. These replication groups are recorded in the object model and used to ensure that replication policies can follow their workloads as they are recovered to different sites.
Figure 18 shows an example of an Avamar replication group created in the Enterprise Hybrid Cloud object model, as presented and referenceable through vRealize Orchestrator.
Figure 18. vRealize Orchestrator view of an Avamar replication group
Avamar replication groups

Chapter 4: Multi-Site and Multi-vCenter Protection Services
31 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 4 Multi-Site and Multi-vCenter Protection Services
This chapter presents the following topics:
vCenter endpoints .................................................................................................... 32
Protection services................................................................................................... 32
Single-site protection service .................................................................................. 34
Continuous Availability (Single-site) protection service ........................................... 35
Continuous Availability (Dual-site) Protection Service ............................................. 37
Disaster recovery (RecoverPoint for Virtual Machines) Protection Service ............... 42
Disaster recovery (VMware Site Recovery Manager) Protection Service ................... 43
Combining protection services ................................................................................. 47
Multi-vCenter and Multi-site topologies ................................................................... 58
VCE platforms and Enterprise Hybrid Cloud .............................................................. 69

Chapter 4: Multi-Site and Multi-vCenter Protection Services
32 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
vCenter endpoints
An Enterprise Hybrid Cloud managed vCenter endpoint implies that all Enterprise Hybrid Cloud STaaS, BaaS, DRaaS, continuous availability as a service, and encryption as a service can be provided to that vCenter endpoint.
An IaaS vCenter endpoint implies that this endpoint, while configured as a vRealize Automation endpoint, can only avail of the virtual machine lifecycle operations provided as part of vRealize Automation and cannot avail of Enterprise Hybrid as-a-service offerings.
Protection services
Enterprise Hybrid Cloud offers five types of protection services as follows:
Single-site protection—Designed to operate when only a single site is available, or when workloads do not require replicated storage or backups. It can be used in its own right or as the base deployment on top of which you can layer additional multi-site protection services. Suitable when you have just a single site and therefore do not require inter-site protection.
Continuous Availability (Single-site) protection—Designed to provide storage and compute resilience for workloads on the same site, using shared backup infrastructure but maintaining non-replicated backups. Suitable when you want to provide additional resilience for single site workloads.
Continuous Availability (Dual-site) protection—Designed to provide storage and compute resilience for workloads across sites, using local shared backup infrastructure and replicating backup images between sites. It is intended for metro-distance geographic separation. Suitable when you want to provide inter-site resilience for workloads and have two sites within a 10 ms latency of each other.
Disaster recovery (RecoverPoint for Virtual Machines) protection—Designed to provide storage and compute resilience for workloads across sites, using local shared backup infrastructure and replicating backup images between sites. It is intended for distances outside the metro range, allowing virtual machine workloads to be recovered individually. Suitable when you want to provide inter-site resilience for workloads, want individual workload level failover, but have sites greater than 10ms latency apart.
Disaster recovery (Site Recovery Manager) protection—Designed to provide storage and compute resilience for workloads across sites, using local shared backup infrastructure and replicating backup images between sites. It is intended for distances outside the metro range, allowing virtual machine workloads to be recovered at the ESXi cluster level of granularity. Suitable when you want to provide inter-site resilience for workloads, but have sites greater than 10ms latency apart.
Enterprise Hybrid Cloud managed vCenter endpoint
Infrastructure-as-a-service vCenter endpoint
Protection service offerings

Chapter 4: Multi-Site and Multi-vCenter Protection Services
33 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The detailed features of each protection service are described in subsequent sections.
Enterprise Hybrid Cloud provides the following intra-site and inter-site protection features, which can be combined to offer multiple tiers of service to different workloads within the same Enterprise Hybrid Cloud deployment. The attributes of the protection services are:
Converged infrastructure redundancy—Virtual machine workloads with this availability attribute benefit from the redundancy of the internal componentry of a converged infrastructure platform, such as VxBlock or VxRack, including redundant compute, network, and storage components.
Inter-converged infrastructure redundancy—Virtual machine workloads with this availability attribute benefit are insulated against the failure of a converged infrastructure platform by replicating that workload to a second converged infrastructure platform on the same site.
Inter-site redundancy—Virtual machine workloads with this availability attribute-benefit are insulated against failure of an entire site location by replicating that workload to a second converged infrastructure platform on an alternate site.
Local backup—Virtual machine workloads with this availability attribute are backed up locally to shared backup infrastructure with a single copy of each backup image retained.
Replicated backup—Virtual machine workloads with this availability attribute are backed up locally to shared backup infrastructure, and each backup image is replicated to, and restorable from, a shared backup infrastructure on an alternate site.
Table 6 presents these options and their attributes.
Table 6. Available Enterprise Hybrid Cloud protection services
Protection service Converged infrastructure redundancy
Inter-converged infrastructure redundancy
Inter-site
redundancy Local backup
Replicated backup
Single site √ √
Continuous availability
(Single site)
√ √ √
Continuous availability
(Dual site)
√ √ √ √ √
Disaster recovery (RecoverPoint for Virtual Machines)
√ √ √ √ √
Disaster recovery (Site Recovery Manager)
√ √ √ √ √
Protection service availability attributes

Chapter 4: Multi-Site and Multi-vCenter Protection Services
34 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Single-site protection service
The single-site Enterprise Hybrid Cloud service should be used when restart or recovery of virtual machine workloads or cloud management infrastructure to another data center is not required. It can also be used as the base deployment on top of which you can layer additional multi-site protection services.
Figure 19 displays an example of single-site protection service, where multiple vCenters and hardware islands are used on a single site, managed by Enterprise Hybrid Cloud.
Figure 19. Enterprise Hybrid Cloud single-site service
The single-site protection service has the following attributes:
Allows a maximum of four VMware vCenter endpoints to be configured for use as Enterprise Hybrid Cloud managed vCenter endpoints. This allows up to four sites to be configured like this when no other protection service are available.
Each vCenter endpoint can have between one and four hardware islands configured (where a hardware island is an island of compute and storage such as a converged infrastructure from VCE).
Workloads that use this protection service are bound by the confines of the site to which they were deployed such that:
Virtual machine workloads cannot be restarted on any other sites.
Virtual machine backup images are not replicated to any another site.
There is no inter-converged infrastructure (intra-site) protection available to the virtual machine workloads.
Architecture

Chapter 4: Multi-Site and Multi-vCenter Protection Services
35 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Workloads on any vCenter, hardware island, or cluster may share the same backup infrastructure
Continuous Availability (Single-site) protection service
The Continuous Availability (Single-site) Enterprise Hybrid Cloud service should be used when restart or recovery of virtual machine workloads and cloud management infrastructure to another converged infrastructure platform within the same data center is a requirement.
Figure 20 displays an example of Continuous Availability (Single-site) protection service, where one vCenter and two hardware islands are used on a single site, managed by Enterprise Hybrid Cloud. Additional vCenters could be added that replicate the configuration.
Figure 20. Enterprise Hybrid Cloud Continuous Availability (Single-site) service
The Continuous Availability (Single-site) protection service has the following attributes:
This service allows a maximum of four vCenter endpoints to be configured for use as Enterprise Hybrid Cloud-managed vCenter endpoints. This allows up to four sites to be configured like this when no other protection services are available.
Architecture

Chapter 4: Multi-Site and Multi-vCenter Protection Services
36 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Each vCenter endpoint may have between one and four hardware islands configured (where a hardware island is an island of compute and storage, such as a converged infrastructure from VCE).
Workloads using this protection service are bound by the confines of the site to which they were deployed such that:
Virtual machine workloads cannot be restarted on any other sites.
Virtual machine backup images are not replicated to any another site.
Virtual machine workloads using this service may be recovered from one converged infrastructure platform to another on the same site using vSphere Metro Stretched Cluster (vMSC) backed by VPLEX® Metro storage.
This combination allows the use of VMware vSphere vMotion® for proactive movement of workloads before a known event, or the use of vSphere HA for reactive restart of those workloads if an unpredicted failure event occurs.
Workloads may exist on both sides of the continuous availability clusters in active/active fashion.
Workloads on any vCenter, hardware island, or cluster may use shared backup infrastructure.
When single-site continuous availability is deployed, there are two copies of storage volumes on the same site controlled by VPLEX metro. In this case, each leg of the stretched cluster is provided by a different hardware island associated with the same vCenter and the same site. Each hardware island should be backed by a different converged infrastructure platform (such as VxBlock) to provide inter-converged infrastructure redundancy.
To maximize uptime of workloads in a failure scenario, virtual machine workloads deployed to a CA1S (CA VPLEX Metro Storage on One Site) cluster are automatically added to VMware DRS Affinity groups. The affinity group that an individual workload is associated with is based on the storage chosen by the user, and the hardware island that hosts the winning leg for that distributed storage if a storage partition event occurs.
As a result, only the failure of the winning leg of a distributed storage volume requires a vSphere HA restart of that virtual machine workload on another member of the vSphere cluster that is associated with the other hardware island.
When using continuous availability protection, Enterprise Hybrid Cloud STaaS provisioning operations can create vRealize Storage Reservation Policies (SRPs) in one of two formats based on the hwi_srp_policy_enabled global option. When this value is set to False, SRPs are created in a format that conveys to the user which site will be the winning site if a storage partition occurs. When hwi_srp_policy_enabled is set to True, the SRP will convey both the winning site and hardware island within that site.
To avail of single-site continuous availability protection, the hwi_srp_policy_enabled global option must be set to True. This ensures that Enterprise Hybrid Cloud STaaS
Hardware island affinity for tenant virtual machines

Chapter 4: Multi-Site and Multi-vCenter Protection Services
37 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
operations create vRealize SRPs that convey to the user which hardware island is the winning site when selecting storage for use by a virtual machine workload.
Changing the value of this option can be done with the vRealize Automation catalog item entitled Global Options Maintenance.
If the Enterprise Hybrid Cloud management stack is protected by single-site continuous availability, then the management component virtual machines should be configured in affinity groups in a similar way as tenant workloads. This is done as part of the Enterprise Hybrid Cloud deployment process.
Continuous Availability (Dual-site) Protection Service
The Continuous Availability (Dual-site) Enterprise Hybrid Cloud service should be used when restart or recovery of virtual machine workloads and cloud management infrastructure to another converged infrastructure platform on an alternate site is a requirement.
Figure 21 shows an example of Continuous Availability (Dual-site) protection service, where one vCenter and two hardware islands are used across two different sites, and managed by Enterprise Hybrid Cloud.
Additional vCenters could be added that replicate the configuration shown in Figure 21 to provide additional scale, or to provide the same type of protection service between a different combination of sites.
Figure 21. Enterprise Hybrid Cloud Continuous Availability (Dual-site) service
Hardware island affinity for management platform machines
Architecture

Chapter 4: Multi-Site and Multi-vCenter Protection Services
38 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The Continuous Availability (Dual-site) protection service has the following attributes:
This service allows a maximum of four vCenter endpoints to be configured for use as Enterprise Hybrid Cloud managed vCenter endpoints. This allows up to eight sites to be configured in this manner when no other protection service are available.
Each vCenter endpoint may have between one and four hardware islands configured (where a hardware island is an island of compute and storage such as a converged infrastructure from VCE).
Workloads using this protection service may operate on either of the two sites participating in any given CA relationship such that:
Virtual machine workloads may be restarted on either of the two sites.
Virtual machine backup images are replicated to the other site and are available for restore
Virtual machine workloads using this service may be recovered from one converged infrastructure platform to another on different sites using vSphere Metro Stretched Cluster back by VPLEX Metro storage.
This combination allows the use of vMotion for proactive movement of workloads before a known event or the use of vSphere HA to for reactive restart of those workloads if an unpredicted failure event occurs.
Workloads may exist on both sides of the continuous availability clusters in active/active fashion.
Workloads on hardware islands or clusters on the same site may all use the shared backup infrastructure local to that site. When workloads move to the other site, the shared backup infrastructure on that site will take ownership of executing backups for those workloads.
When dual-site continuous availability is deployed, there are two copies of storage volumes on different sites controlled by VPLEX Metro. In this case, each leg of the stretched cluster is provided by a different hardware island, on a different site, but associated with the same vCenter. Each hardware island should be backed by a different converged infrastructure platform (such as VxBlock) to provide inter-converged infrastructure redundancy.
To maximize uptime of workloads in a failure scenario, virtual machine workloads deployed to a CA2S (CA VPLEX Metro Storage across Two Sites) cluster are automatically added to VMware DRS affinity groups. These groups are used to subdivide the vSphere ESXi hosts in each workload cluster into groupings of hosts corresponding to their respective sites.
The specific affinity group that an individual workload is associated with is based on the storage chosen by the user, and the hardware island or site that hosts the winning leg for that distributed storage if a storage partition event occurs.
As a result, only the failure of the winning leg of a distributed storage volume requires a vSphere HA restart of that virtual machine workload on another member of the vSphere cluster that is associated with the other hardware island.
Site affinity for tenant virtual machines

Chapter 4: Multi-Site and Multi-vCenter Protection Services
39 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
When using continuous availability protection, Enterprise Hybrid Cloud STaaS provisioning operations can create vRealize SRPs in one of two formats based on the hwi_srp_policy_enabled global option. When this value is set to False, SRPs are created in a format that conveys to the user which site will be the winning site in the event of a storage partition. When hwi_srp_policy_enabled is set to True, the SRP will convey both the winning site and hardware island within that site.
If only dual-site continuous availability protection is required, then the hwi_srp_policy_enabled global option must be set to True or False. If both single-site and dual-site continuous availability is required, hwi_srp_policy_enabled must be set to True.
Changing the value of this option can be done with the vRealize Automation catalog item entitled Global Options Maintenance.
Example scenario
This section provides an example of how the system will operate when hwi_srp_policy_enabled is False and only dual-site continuous availability is in use.
Step 1: Cluster on-boarded The Onboard CA Cluster option in the Cluster Maintenance vRealize Automation
catalog item was run, which:
Created VMware host DRS groups in the format SiteName_Hosts based on sites on-boarded to the Enterprise Hybrid Cloud object model.
Created VMware virtual machine DRS groups in the format SiteName_VMs.
Created virtual machines to host DRS rules to bind virtual machines to the preferred site by configuring the SiteName_VMs virtual machine DRS group with a setting of should run on the respective SiteName_Hosts host DRS group. This ensures that virtual machines run on the required site, while allowing them the flexibility of failing over if the infrastructure on that site becomes unavailable.
Figure 22 shows how the virtual machine DRS groups and affinity rules might look after this configuration.

Chapter 4: Multi-Site and Multi-vCenter Protection Services
40 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 22. Sample view of site affinity DRS group and rule configuration
Note: The values SiteA and SiteB shown in Figure 22 and Figure 23 should be replaced with meaningful site names in a production environment. They must correlate with the site name values onboarded through the Site Maintenance vRealize Automation catalog item.
Step 2: Storage provisioned The Provision Cloud Storage vRealize Automation catalog item was run once for
each site to create storage that is preferred in each location which:
Provisioned storage to the chosen CA2S cluster
Created SRPs that were automatically named to indicate the preferred site in which that storage should run.
Step 3: Workloads deployed from vRealize Automation catalog The user deploys VM1 with affinity to Site A:
During virtual machine deployment, the user selects a storage reservation policy named SiteA_Preferred_CA_Enabled.
This storage reservation policy choice filters the suitable clusters to only those clusters with that reservation policy. In this case cluster 1.
Based on the selected storage reservation policy, Enterprise Hybrid Cloud lifecycle operations programmatically determine that Site A is the preferred location, and therefore locates the virtual machine DRS affinity group corresponding with Site A, namely SiteA_VMs.
The expected result is:
VM1 is deployed into SiteA_VMs, residing on host CL1-H1 or CL1H2.

Chapter 4: Multi-Site and Multi-vCenter Protection Services
41 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
VM1 is deployed onto a datastore from the SiteA_Preferred_CA_Enabled storage reservation policy, for example:
VPLEX_Distributed_LUN_SiteA_Preferred_01 or VPLEX_Distributed_LUN_SiteA_Preferred_02
The user deploys VM1 with affinity to Site B:
During virtual machine deployment, the user chooses a storage reservation policy named SiteB_Preferred_CA_Enabled.
This storage reservation policy choice filters the suitable clusters to only those clusters with that reservation policy. In this case cluster 1.
Based on the selected storage reservation policy, Enterprise Hybrid Cloud lifecycle operations programmatically determine that Site B is the preferred location, and therefore locates the virtual machine DRS affinity group corresponding with Site B, namely SiteB_VMs.
The expected result is:
VM2 is deployed into SiteB_VMs, meaning it resides on hosts CL1-H3 or CL1H4.
VM1 is deployed onto a datastore from the SiteB_Preferred_CA_Enabled storage reservation policy. For example:
VPLEX_Distributed_LUN_SiteB_Preferred_01 or VPLEX_Distributed_LUN_SiteB_Preferred_02
Figure 23 shows how this example would look after the virtual machines were deployed to the CA2S cluster
Figure 23. Virtual machines deployed with site affinity

Chapter 4: Multi-Site and Multi-vCenter Protection Services
42 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
If the Enterprise Hybrid Cloud management stack is protected by dual-site continuous availability then the management component virtual machines should be configured in affinity groups in a similar fashion to tenant workloads. This is done as part of the Enterprise Hybrid Cloud deployment process.
Disaster recovery (RecoverPoint for Virtual Machines) Protection Service
The RecoverPoint for Virtual Machines-based disaster recovery Enterprise Hybrid Cloud protection service should be used when restart or recovery of virtual machine workloads and cloud management infrastructure to another converged infrastructure platform on an alternate site is a requirement.
Figure 24 displays an example of a RecoverPoint for Virtual Machines-based disaster recovery protection service, where two vCenters and two hardware islands are used across two different sites, and managed by Enterprise Hybrid Cloud.
Additional vCenters could be added that replicate the configuration shown in Figure 24 to provide additional scale, or to provide the same type of protection service between a different combination of sites.
Figure 24. Enterprise Hybrid Cloud RecoverPoint for Virtual Machines disaster recovery service
The RecoverPoint for Virtual Machines-based disaster recovery protection service has the following attributes:
This service allows a maximum of four vCenter endpoints to be configured for use as Enterprise Hybrid Cloud managed vCenter endpoints. This allows up to
Site affinity for management platform machines
Architecture

Chapter 4: Multi-Site and Multi-vCenter Protection Services
43 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
four sites to be configured in this manner when no other protection services are available.
Each vCenter endpoint may have between one and four hardware islands configured (where a hardware island is an island of compute and storage, such as a converged infrastructure from VCE).
Workloads using this protection service may operate on either of the two sites participating in any given DR relationship such that
Virtual machine workloads may be recovered on either of the two sites.
Virtual machine backup images are replicated to the other site and are available for restore
Virtual machine workloads using this service may be individually recovered from one converged infrastructure platform to another on different sites using the failover mechanisms provided by RecoverPoint for Virtual Machines.
Tenant workload clusters are logically paired across vCenters and sites to ensure networking and backup policies operate correctly both before and after failover.
Workloads may exist on both sides of the cluster pairing in active/active fashion
Workloads on hardware islands or clusters on the same site may all use the shared backup infrastructure local to that site. When workloads move to the other site, the shared backup infrastructure on that site takes ownership of executing backups for those workloads.
Disaster recovery (VMware Site Recovery Manager) Protection Service
The VMware SRM-based disaster recovery Enterprise Hybrid Cloud service should be used when restart or recovery of virtual machine workloads and cloud management infrastructure to another converged infrastructure platform on an alternate site is a requirement.
Figure 25 shows an example of the SRM-based disaster recovery service, where two vCenters and two hardware islands are used across two different sites, and managed by Enterprise Hybrid Cloud.
Architecture

Chapter 4: Multi-Site and Multi-vCenter Protection Services
44 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 25. Enterprise Hybrid Cloud Site Recovery Manager disaster recovery service
Additional vCenters can be added that replicate the configuration shown in Figure 25 to provide additional scale, or to provide the same type of protection service between a different combination of sites.
The SRM-based disaster recovery protection service has the following attributes:
This service allows a maximum of two vCenter endpoints to be configured for use as Enterprise Hybrid Cloud-managed vCenter endpoints. This allows up to two sites to be configured in this manner when no other protection service are available.
Each vCenter endpoint may have between one and four hardware islands configured (where a hardware island is an island of compute and storage such as a converged infrastructure from VCE).
Workloads using this protection service may operate on either of the two sites participating in any given DR relationship such that:
Virtual machine workloads may be recovered on either of the two sites.
Virtual machine backup images are replicated to the other site and are available for restore
Tenant workload clusters are logically paired across vCenters and sites to ensure networking and backup policies operate correctly both before and after failover, and failover is at a cluster-level granularity, in that all virtual machine workloads on a specified cluster pair must fail over and back as a unit.
Virtual machine workloads using this service can recover from one converged infrastructure platform to another on a different site using the failover mechanisms provided by VMware SRM.

Chapter 4: Multi-Site and Multi-vCenter Protection Services
45 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Workloads may exist on only one side of the cluster pairing in active/passive fashion. Additional active/passive clusters in an opposite configuration are required to achieve active/active sites.
Workloads on hardware islands or clusters on the same site may all use the shared backup infrastructure local to that site. When workloads move to the other site, the shared backup infrastructure on that site takes ownership of executing backups for those workloads.
SRM integrates with RecoverPoint storage replication and ViPR automated storage services with Storage Replication Adapters (SRAs). The SRAs control the RecoverPoint replication process. The RecoverPoint SRA controls the Automation Pod datastores, while the ViPR SRA controls protected Workload Pod datastores.
To support SRM-based DR protection, the SRM configuration must include resource mappings between the vCenter Server instance on the protected site and the vCenter Server instance on the recovery site.
These mappings enable the administrator to define automated recovery plans for failing over application workloads between the sites according to defined recovery time objectives (RTOs) and recovery point objectives (RPOs). Map resources such as resource pools, virtual machine folders, networks, and the placeholder datastore. The settings must be configured on both the protected and recovery sites to support application workload recovery between the two sites.
Resource pool mappings
An SRM resource pool specifies the compute cluster, host, or resource pool that is running a protected application. Resource pools must be mapped between the protected site and the recovery site in both directions so that, when an application fails over, the application can then run on the mapped compute resources on the recovery site.
Folder mappings
When virtual machines are deployed in the Enterprise Hybrid Cloud, the virtual machines are placed in specific folders in the vCenter Server inventory to simplify administration. By default, virtual machines are deployed in a folder named VRM. This folder must be mapped between the protected and recovery sites in both directions. When used with Enterprise Hybrid Cloud backup services, the folders used by backup as a service are automatically created in both vCenters and mapped in SRM.
Network mappings
Virtual machines can be configured to connect to different networks when deployed. Applications deployed with SRM DR support must be deployed on networks that have been configured as defined in Chapter 5. The networks must be mapped in SRM between the protected and recovery sites in both directions. For testing recovery plans, you should deploy a test network and use test network mappings when you create the recovery plan.
RecoverPoint and ViPR Storage Replication Adapters
Site mappings

Chapter 4: Multi-Site and Multi-vCenter Protection Services
46 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: When failover occurs with the SRM-based disaster recovery protection service, all Layer 3 networks associated with the protected cluster are failed over entirely. Active machines in a specified Layer 3 network must reside only in the site with the "permit" route redistribution policy.
Placeholder datastore
For every protected virtual machine, SRM creates a placeholder virtual machine on the recovery site. The placeholder virtual machine retains the virtual machine properties specified by the global inventory mappings or specified during protection of the individual virtual machine.
A placeholder datastore must be accessible to the compute clusters that support the DR services. The placeholder datastore must be configured in SRM and must be associated with the compute clusters.
Enterprise Hybrid Cloud used several components that are deployed as a vSphere vApp. This includes:
EMC ViPR Controller
EMC ViPR SRM
SRM protects virtual machines, but does not preserve the vApp structure required for EMC ViPR Controller and EMC ViPR SRM virtual machines to function.
The high-level steps to recover vApps are:
1. Deploy the vApp identically in both sites.
2. Vacate the vApp on the recovery site (delete the virtual machines, but retain the virtual machine container).
3. Protect the vApp on the protected site through SRM, mapping the vApp containers from both sites.
4. Reapply virtual machine vApp settings on placeholder virtual machines.
A protection group is the unit of failover in SRM. Enterprise Hybrid Cloud supports failover at a Workload Pod level.
In the context of the SRM-based disaster recovery protection, two Workload Pods are assigned to a DR cluster pair, where one pod is the primary and is considered to be the protected cluster, and the second pod is the alternate site and is considered the recovery cluster. All protection groups associated with a DR cluster pair and all the virtual machines running on a particular pod must fail over together.
With SRM-based disaster recovery protection there is a 1:1 mapping between a DR cluster pair and a recovery plan, and each recovery plan contains one or more protection groups.
Each protection group contains a single replicated vSphere datastore, and all the virtual machines that are running on that datastore. When you deploy new virtual machines to a Workload Pod using vRealize Automation, Enterprise Hybrid Cloud
Disaster recovery support for Automation Pod vApps
Protection groups

Chapter 4: Multi-Site and Multi-vCenter Protection Services
47 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
lifecycle customizations automatically add them to the corresponding protection group so that they will fail over successfully.
Recovery plans enable administrators to automate the steps required for recovery between the primary and recovery sites. A recovery plan may include one or more protection groups.
You can test recovery plans to ensure that protected virtual machines recover correctly to the recovery site.
Tenant Pod recovery plans
The automated network re-convergence capabilities of SRM-based disaster recovery protection for Enterprise Hybrid Cloud eliminates the need to change the IP addresses of workload virtual machines when they fail over from one site to the other. Instead, the tenant networks move with the virtual machines and support virtual machine communication outside the network once on the recovery site.
When using VMware NSX, Enterprise Hybrid Cloud can automate network re-convergence of the tenant workload pods and, through a custom SRM step of the SRM recovery plan, ensure security policy compliance on the recovery site during a real failover. However, running a test SRM recovery plan with VMware NSX does not affect the production virtual machines, because the network convergence automation step has the required built-in intelligence to know that the networks should not be re-converged in that scenario.
If non-NSX alternatives are used, then this network re-convergence is not automated, and therefore needs to be done manually during a pause in the SRM recovery plan, or via an automated SRM task created as part of a professional services engagement.
Note: A recovery plan must be manually created per DR-enabled workload cluster before any STaaS operations are executed - two per pair to enable failover and failback.
Automation Pod recovery plans
Network re-convergence of the network supporting the Enterprise Hybrid Cloud Automation Pod is a manual task irrespective of the presence of VMware NSX.
Note: This reflects the default solution experience. Automated network re-convergence for the Automation Pod may be achieved with a professional services engagement.
Combining protection services
Protection services may be combined within a single Enterprise Hybrid Cloud environment to offer the multiple tiers of service. The protection levels described earlier can be combined in the following ways:
Two services: Single site plus RecoverPoint for Virtual Machines DR
Two services: Single site plus VMware Site Recovery Manager-based DR
Three services: Single site plus single/dual-site CA
Recovery plans

Chapter 4: Multi-Site and Multi-vCenter Protection Services
48 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Three services: Single site plus RecoverPoint for Virtual Machines DR plus Site Recovery Manager DR
Four services: Single site plus single/dual-site CA and RecoverPoint for Virtual Machines based DR
Four services: Single site plus single/dual-site CA and Site Recovery Manager based DR
Five services: Single site plus single/dual-site CA plus RecoverPoint for Virtual Machines based DR and Site Recovery Manger-based DR
The RecoverPoint for Virtual Machines-based disaster recovery service inherently offers both single site and RecoverPoint for Virtual Machines protection services, because the compute and storage resources to provide both options are the same.
When deployed in Enterprise Hybrid Cloud, any virtual machine workload can be individually “toggled” from the single-site protection service to RecoverPoint for Virtual Machines protection service and back again, as required. When this is done, the backup protection level automatically changes from local to replicated backup as appropriate.
Figure 26 shows an example where RecoverPoint for Virtual Machines has been deployed within the Enterprise Hybrid Cloud environment, using two vCenter endpoints.
Figure 26. Combining single site and RecoverPoint for Virtual Machines based disaster recovery protection services
Two services: Single site plus RecoverPoint for Virtual Machines DR

Chapter 4: Multi-Site and Multi-vCenter Protection Services
49 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 26 shows an example where two protection services are provided within the same Enterprise Hybrid Cloud environment, using a single vCenter endpoint:
Single-site workloads—These workloads are not associated with any RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure only. In Figure 26, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
RecoverPoint for Virtual Machines workloads—RecoverPoint for Virtual Machines protected workloads are associated with the RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 26, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
Additional vCenters can be added (in keeping with the parameter in Supported topologies) to provide additional scale, or to provide the same type of protection service between a different combination of sites.
When single-site and SRM-based disaster recovery protection levels are combined in an Enterprise Hybrid Cloud environment, virtual machine workloads can choose from two different tiers of protection service, as shown in Figure 27.
Figure 27. Combining single site and Site Recovery Manager based disaster recovery protection services
Two services: Single site plus VMware Site Recovery Manager-based DR

Chapter 4: Multi-Site and Multi-vCenter Protection Services
50 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 27 shows an example where both protection services are provided within the same Enterprise Hybrid Cloud environment, using two vCenter endpoints:
Single-site workloads—Are automatically directed to compute resources, storage, and backup policies that reflect that tier of service, that is, non-replicated storage and non-replicated backups. They are not associated with SRM replication components. In Figure 27, these workloads reside on the compute resource labelled Local Clusters. Backups occur to the relevant local backup infrastructure only.
Site Recovery Manager workloads—SRM-protected workloads are associated with SRM replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 27, these workloads reside on the compute resource labelled DR Clusters.
Additional vCenters can be added (in keeping with the parameter in the section Supported topologies) to provide additional scale, or to provide the same type of protection service between a different combination of sites.
Note: Only one Enterprise Hybrid Cloud-managed vCenter endpoint is permitted to offer Site Recovery Manager based disaster recovery protection services.
When single site and continuous availability protection levels are combined in an Enterprise Hybrid Cloud environment, virtual machine workloads can choose from three different tiers of protection service, as shown in Figure 28.
Three services: Single site plus single/dual-site CA

Chapter 4: Multi-Site and Multi-vCenter Protection Services
51 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 28. Combining single site and continuous availability protection services
Figure 28 shows an example where all three protection services are provided within the same Enterprise Hybrid Cloud environment, using a single vCenter endpoint:
Single-site workloads—Are automatically directed to compute resources, storage, and backup policies that reflect that tier of service, that is, non-replicated storage and non-replicated backups. In Figure 28 these workloads reside on the compute resource labelled Local Clusters. Backups occur to the backup infrastructure on Site A only.
CA single site—If multiple VPLEX clusters are deployed on the same site, then workloads may avail of the replicated storage on the same site, but continue to use non-replicated backups. In Figure 28 these workloads reside on the compute resource labelled Continuous Availability Clusters (Single Site). Backups occur to the backup infrastructure on Site A only.
CA dual site—If VPLEX clusters are deployed to both sites, then workloads may avail of the replicated storage to a different site, but additionally avail of replicated backups. In Figure 28 these workloads reside on the compute resource labelled Continuous Availability Clusters (Dual Site). Backups occur to the relevant local backup infrastructure and are replicated to the backup infrastructure on the other site.
Additional vCenters can be added (in keeping with the parameter in Supported topologies) to provide the same type of protection service between a different combination of sites.

Chapter 4: Multi-Site and Multi-vCenter Protection Services
52 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
When single site, RecoverPoint for Virtual Machines-based disaster recovery and SRM-based disaster recovery protection levels are combined in an Enterprise Hybrid Cloud environment, virtual machine workloads can choose from three different tiers of protection service, as shown in Figure 29.
Figure 29. Combining single site, RecoverPoint for Virtual Machines disaster recovery, and Site Recovery Manager based disaster recovery protection services
In this combination, Site Recovery Manager and RecoverPoint for Virtual Machines protection services can be provided by the same or different vCenter pairs. Figure 29 shows an example where all three protection services are provided within the same Enterprise Hybrid Cloud environment, using two vCenter endpoints.
Single-site workloads—These workloads are not associated with any RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure only. In Figure 29, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
RecoverPoint for Virtual Machines workloads—RecoverPoint for Virtual Machines protected workloads are associated with the RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 29, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
Three services: Single site plus RecoverPoint for Virtual Machines DR plus Site Recovery Manager DR

Chapter 4: Multi-Site and Multi-vCenter Protection Services
53 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Site Recovery Manager workloads—SRM-protected workloads are associated with SRM replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 29, these workloads reside on the compute resource labelled DR Clusters.
Additional vCenters can be added (in keeping with the parameter in Supported topologies) to provide additional scale, or to provide the same type of protection service between a different combination of sites.
Note: Only one Enterprise Hybrid Cloud managed vCenter endpoint is permitted to offer Site Recovery Manager based disaster recovery protection services.
When single site, continuous availability, and RecoverPoint for Virtual Machines protection levels are combined in an Enterprise Hybrid Cloud environment, virtual machine workloads can choose from four different tiers of protection service, as shown in Figure 30.
Figure 30. Combining single site, continuous availability, and RecoverPoint for Virtual Machines based disaster recovery protection services
Four services: Single site plus single/dual-site CA and RecoverPoint for Virtual Machines based DR

Chapter 4: Multi-Site and Multi-vCenter Protection Services
54 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 30 shows an example where all four protection services are provided within the same Enterprise Hybrid Cloud environment, using two vCenter endpoints:
Single-site workloads—Are automatically directed to compute resources, storage, and backup policies that reflect that tier of service, that is, non-replicated storage and non-replicated backups. These workloads are not associated with any RecoverPoint for Virtual Machines replication components. In Figure 30, these workloads reside on the compute resource labelled Local/RP4VM Clusters. Backups occur to the relevant local backup infrastructure only.
CA single site—If multiple VPLEX clusters are deployed on the same site, then workloads may avail of the replicated storage on the same site, but continue to use non-replicated backups. In Figure 30, these workloads reside on the compute resource labelled Continuous Availability Clusters (Single Site). Backups occur to the backup infrastructure on Site A only.
CA dual site—If VPLEX clusters are deployed to both sites, then workloads may avail of the replicated storage to a different site, but additionally avail of replicated backups. In Figure 30, these workloads reside on the compute resource labelled Continuous Availability Clusters (Dual Site). Backups occur to the relevant local backup infrastructure and are replicated to the backup infrastructure on the other site.
RecoverPoint for Virtual Machines workloads—RecoverPoint for Virtual Machines protected workloads are associated with the RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 30, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
Additional vCenters can be added (in keeping with the parameter in Supported topologies) to provide additional scale, or to provide the same type of protection service between a different combination of sites.
When single site, continuous availability, and Site Recovery Manager protection levels are combined in an Enterprise Hybrid Cloud environment, virtual machine workloads can choose from four different tiers of protection service, as shown in Figure 31.
Four services: Single site plus single/dual-site CA and Site Recovery Manager based DR

Chapter 4: Multi-Site and Multi-vCenter Protection Services
55 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 31. Combining single site, continuous availability, and Site Recovery Manager based disaster recovery protection services
Figure 31 shows an example where all four protection services are provided within the same Enterprise Hybrid Cloud environment, using two vCenter endpoints:
Single-site workloads—Are automatically directed to compute resources, storage, and backup policies that reflect that tier of service, that is, non-replicated storage and non-replicated backups. In Figure 31, these workloads reside on the compute resource labelled Local Clusters. Backups occur to the relevant local backup infrastructure only.
CA single site—If multiple VPLEX clusters are deployed on the same site, then workloads may avail of the replicated storage on the same site, but continue to use non-replicated backups. In Figure 31, these workloads reside on the compute resource labelled Continuous Availability Clusters (Single Site). Backups occur to the backup infrastructure on Site A only.

Chapter 4: Multi-Site and Multi-vCenter Protection Services
56 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
CA dual site—If VPLEX clusters are deployed to both sites, then workloads may avail of the replicated storage to a different site, but additionally avail of replicated backups. In Figure 31, these workloads reside on the compute resource labelled Continuous Availability Clusters (Dual Site). Backups occur to the relevant local backup infrastructure and are replicated to the backup infrastructure on the other site.
Site Recovery Manager workloads—SRM-protected workloads are associated with SRM replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 31, these workloads reside on the compute resource labelled DR Clusters.
Additional vCenters can be added (in keeping with the parameter in Supported topologies) to provide additional scale, or to provide the same type of protection service between a different combination of sites.
Note: Only one Enterprise Hybrid Cloud managed vCenter endpoint is permitted to offer Site Recovery Manager-based disaster recovery protection services.
When single site, RecoverPoint for Virtual Machines-based disaster recovery and SRM-based disaster recovery protection levels are combined in an Enterprise Hybrid Cloud environment, virtual machine workloads can choose from five different tiers of protection service, as shown in Figure 32.
Five services: Single site plus single/dual-site CA plus RecoverPoint for Virtual Machines based DR and Site Recovery Manger-based DR

Chapter 4: Multi-Site and Multi-vCenter Protection Services
57 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 32. Combining single site, continuous availability, RecoverPoint for Virtual Machines based disaster recovery, and Site Recovery Manager based disaster recovery protection services
In this combination, Site Recovery Manager and RecoverPoint for Virtual Machines protection services can be provided by the same or different vCenter pairs. Figure 32 shows an example where all five protection services are provided within the same Enterprise Hybrid Cloud environment, using two vCenter endpoints.
Single-site workloads—These workloads are not associated with any RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure only. In Figure 32, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
CA single site—If multiple VPLEX clusters are deployed on the same site, then workloads may avail of the replicated storage on the same site, but continue to use non-replicated backups. In Figure 32, these workloads reside on the

Chapter 4: Multi-Site and Multi-vCenter Protection Services
58 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
compute resource labelled Continuous Availability Clusters (Single Site). Backups occur to the backup infrastructure on Site A only.
CA dual site—If VPLEX clusters are deployed to both sites, then workloads may avail of the replicated storage to a different site, but additionally avail of replicated backups. In Figure 32, these workloads reside on the compute resource labelled Continuous Availability Clusters (Dual Site). Backups occur to the relevant local backup infrastructure and are replicated to the backup infrastructure on the other site.
RecoverPoint for Virtual Machines workloads—RecoverPoint for Virtual Machines protected workloads are associated with the RecoverPoint for Virtual Machines replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 32, these workloads reside on the compute resource labelled Local/RP4VM Clusters.
Site Recovery Manager workloads—SRM-protected workloads are associated with SRM replication components. Backups occur to the relevant local backup infrastructure, and are replicated to the backup infrastructure on the other site. In Figure 32, these workloads reside on the compute resource labelled DR Clusters.
Additional vCenters can be added (in keeping with the parameter in Supported topologies) to provide additional scale, or to provide the same type of protection service between a different combination of sites.
Note: Only one Enterprise Hybrid Cloud managed vCenter endpoint is permitted to offer Site Recovery Manager-based disaster recovery protection services.
Note: RecoverPoint for Virtual Machines-based disaster recovery and Site Recovery Manager-based disaster recovery services can both be provided from the same pair of hardware islands. Figure 32 shows them in separate hardware islands simply to demonstrate that this is also possible.
Multi-vCenter and Multi-site topologies
Enterprise Hybrid Cloud supports up to four fully managed vCenters endpoints across up to five sites depending on the chosen combination of protection services deployed in the environment. This section provides some sample topologies, and guidance on the parameters you need to consider when designing a topology that meets your requirements.

Chapter 4: Multi-Site and Multi-vCenter Protection Services
59 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The following topologies represent samples of the configurations that Enterprise Hybrid Cloud can support. You can configure the supplied topologies as they are, or variants thereof, as long as you abide by the following parameters:
Scalability limits
Each Enterprise Hybrid Cloud instance can support up to four managed vCenter Endpoints
Each managed vCenter may have up to two associated sites (a maximum eight sites: two per managed vCenter endpoint when using continuous availability protection service)
Each managed vCenter may have up to four associated VxBlocks/VxRack or hardware islands
The Site Recovery Manager-based disaster recovery protection service supports 5,000 protected virtual machine workloads
The RecoverPoint for Virtual Machines based disaster recovery protection service supports 1,000 protected virtual machine workloads per vCenter pair
Data protection support
Each managed vCenter can support backup as a service
Each managed vCenter can support the continuous availability single-site and continuous availability dual-site protection services
Each vCenter endpoint may be partnered with one other vCenter endpoint in DR relationship forming a maximum of two vCenter pairs
Each vCenter pair can support the RecoverPoint for Virtual Machines-based disaster recovery protection service
Only one vCenter pair can support the Site Recovery Manager-based disaster recovery protection service
Supported topologies

Chapter 4: Multi-Site and Multi-vCenter Protection Services
60 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 33 shows how four vCenters on the same site might be deployed. The first vCenter requires the full management stack while other vCenters require just the endpoint management stack.
Figure 33. Four vCenters on one site sample topology
A topology such as this is suitable when you:
Have a single site, but have multiple vCenter endpoints
Want to provide STaaS and BaaS services to all vCenters on the site
Sample topology: Four vCenters on a single site

Chapter 4: Multi-Site and Multi-vCenter Protection Services
61 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 34 shows how four vCenters across five sites might be deployed. The first vCenter requires the full management stack to be deployed, and in this example that vCenter is protected via continuous availability between sites. Subsequent vCenters require just the endpoint management stack.
Figure 34. Four vCenters across five sites with all services sample topology
A topology such as this is suitable when you:
Have five geographical sites
Want to provide STaaS, BaaS and DRaaS services to all sites/vCenters
Want to provide CAaaS services to Site A and Site B vCenters
Have two sites with 10 ms latency of each other to provide Continuous Availability (Dual Site) protection
Sample topology: Four vCenters across five sites with all protection services

Chapter 4: Multi-Site and Multi-vCenter Protection Services
62 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Have other sites that exceed 10 ms latency from each other but that still need inter-site protection for virtual machine workloads. In this case, the topology offers RecoverPoint for Virtual Machines disaster recovery and Site Recovery Manager-based disaster recovery protection for those workloads
Figure 35 shows how four vCenters across four sites might be deployed. The first and second vCenters both require the full management stack in this example because the Automation Pod is to be protected between sites A and B via either Site Recovery Manager and RecoverPoint for Virtual Machines. Subsequent vCenters require just the endpoint management stack.
Sample topology: Four vCenters across four sites with RecoverPoint for Virtual Machines and SRM-based DR protection services

Chapter 4: Multi-Site and Multi-vCenter Protection Services
63 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 35. Four vCenters across four sites with DR services sample topology

Chapter 4: Multi-Site and Multi-vCenter Protection Services
64 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
A topology such as this is suitable when you:
Have four sites and four vCenters
Want to provide STaaS, BaaS and DRaaS services to all sites/vCenters
Want to provide inter-site protection for the management platform.
Want to provide both RecoverPoint for Virtual Machines and Site Recovery Manager based disaster recovery protection services to virtual machine workloads
Do not want to provide continuous availability protection services, or the distances between sites exceed 10 ms and therefore preclude that option
Figure 36 shows how four vCenters across three sites might be deployed. The first vCenter and second vCenters between Site A and Site B both require the full management stack to be deployed, because the Automation Pod is protected between those vCenters using RecoverPoint for Virtual Machines. Subsequent vCenters require just the endpoint management stack.
Figure 36. Four vCenters across three sites with DR services sample topology
A topology such as this is suitable when you:
Have three sites and four vCenters
Want to provide STaaS, BaaS and DRaaS services for all sites/vCenters
Want to provide inter-site protection for the management platform.
Want to provide both RecoverPoint for Virtual Machines and Site Recovery Manager based disaster recovery protection services to virtual machine workloads
Do not want to provide continuous availability protection services, or the distances between sites exceed 10 ms and therefore preclude that option
Sample topology: Four vCenters across three sites with RecoverPoint for Virtual Machines and SRM-based DR protection services

Chapter 4: Multi-Site and Multi-vCenter Protection Services
65 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 37 shows another example of how four vCenters across four sites might be deployed. The first vCenter and second vCenters both require the full management stack to be deployed, because the Automation Pod is protected between those vCenters using Site Recovery Manager. Subsequent vCenters require just the endpoint management stack.
Figure 37. Four vCenters across four sites including SRM and two remote/branch endpoints
Sample topology: Four vCenters across four sites with SRM-based DR protection service and remote endpoints

Chapter 4: Multi-Site and Multi-vCenter Protection Services
66 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
A topology such as this is suitable when you:
Have four sites and four vCenters
Want to provide STaaS and BaaS services for all sites/vCenters.
Want to provide DR services between two sites/vCenters only
Want to provide just Site Recovery Manager based disaster recovery protection services to virtual machine workloads between those two sites
Want to provide single site protection only to the remaining two sites/vCenters
Want to provide inter-site protection for the management platform.
Do not want to provide continuous availability protection services, or the distances between sites exceed 10 ms and therefore preclude that option
Figure 38 shows another example of how four vCenters across four sites might be deployed. The first vCenter and second vCenters both require the full management stack to be deployed, because the Automation Pod is protected between those vCenters using RecoverPoint for Virtual Machines. Subsequent vCenters require just the endpoint management stack.
Sample topology: Four vCenters across four sites with RecoverPoint for Virtual Machines -based DR protection service and remote endpoints

Chapter 4: Multi-Site and Multi-vCenter Protection Services
67 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 38. Four vCenters across four sites including RP4VMs and two remote/branch endpoints
A topology such as this is suitable when you:
Have four sites and four vCenters
Want to provide STaaS and BaaS services for all sites/vCenters.
Want to provide DR services between two sites/vCenters only

Chapter 4: Multi-Site and Multi-vCenter Protection Services
68 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Want to provide just RecoverPoint for Virtual Machines based disaster recovery protection services to virtual machine workloads between those two sites
Want to provide single site protection only to the remaining two sites/vCenters
Want to provide inter-site protection for the management platform.
Do not want to provide continuous availability protection services, or the distances between sites exceed 10 ms and therefore preclude that option
Figure 39 shows another example of how four vCenters across four sites might be deployed. The first vCenter and second vCenters both require the full management stack to be deployed, as the Automation Pod is protected between those vCenters using RecoverPoint for Virtual Machines. Subsequent vCenters require just the endpoint management stack.
Figure 39. Four vCenters across four sites with RecoverPoint for Virtual Machines protection
Sample topology: Four vCenters across four sites RP4VM-based DR protection service

Chapter 4: Multi-Site and Multi-vCenter Protection Services
69 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
A topology such as this is suitable when you:
Have four sites and four vCenters
Want to provide STaaS, BaaS and DRaaS services to all sites/vCenters
Want to provide just RecoverPoint for Virtual Machines based disaster recovery protection services to virtual machine workloads
Want to provide inter-site protection for the management platform
Do not want to provide continuous availability protection services, or the distances between sites exceed 10 ms and therefore preclude that option
VCE platforms and Enterprise Hybrid Cloud
VCE’s converged infrastructure offerings are the ideal platforms on which to build an Enterprise Hybrid Cloud. The following sections show how an Enterprise Hybrid Cloud management platform overlays on VCE converged infrastructure platforms based on the available protection services, while maintaining component efficiencies.
Note: Refer to the EHC Support Matrix for up-to-date information on supported converged systems.
You should use the following information to understand which of the management platform architectural overlays is relevant to your deployment:
Single Site protection (VxBlock and VxRack): Use this overlay when you have a single-site deployment and do not intend to provide inter-site protection for the Cloud Management Platform.
Continuous availability protection (VxBlock only): Use this overlay when you have a multi-site deployment, and want to provide inter-site protection for the Cloud Management Platform via continuous availability
RecoverPoint for Virtual Machines DR protection (VxBlock and VxRack): Use this overlay when you have a multi-site deployment and want to provide inter-site protection for the Cloud Management Platform via RecoverPoint for Virtual Machines
Site Recovery Manager DR protection (VxBlock only): Use this overlay when you have a multi-site deployment and want to provide inter-site protection for the Cloud Management Platform via Site Recovery Manager
When Enterprise Hybrid Cloud is deployed with single-site protection:
The high performance Advanced Management Platform (AMP-2HAP) option from VCE is required. AMP-2HAP ensures sufficient compute resources exist to run all native AMP management components as well as the Enterprise Hybrid Cloud Core Pod components.
A single vCenter is the default as the Enterprise Hybrid Cloud ‘Cloud vCenter’ role is provided by the VCE AMP vCenter.
Overview
Understanding which architectural overlay to use
Architecture overlay: Single-site protection (VxBlock and VxRack)

Chapter 4: Multi-Site and Multi-vCenter Protection Services
70 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Core and NEI Pod functions are deployed and configured in the VCE factory.
The Enterprise Hybrid Cloud NEI Pod function is split across the AMP and Edge clusters.
The Edge cluster uses VCE UCS C-Series (configurable based on bandwidth requirements).
Automation Pod components consume production blades. They are deployed in the VCE factory but are configured onsite.
Figure 40 shows how Enterprise Hybrid Cloud and VCE components overlay in this configuration.
Figure 40. Enterprise Hybrid Cloud on VxBlock/VxRack with single-site protection
When Enterprise Hybrid Cloud is deployed with continuous availability protection:
The high performance AMP-2HAP option from VCE is required. AMP-2HAP ensures sufficient compute resources exist to run all native AMP management components, as well as the Enterprise Hybrid Cloud Core Pod components.
A single vCenter is the default as the Enterprise Hybrid Cloud ‘Cloud vCenter’ is provided by the VCE AMP vCenter.
Core and NEI Pod functions are deployed and configured in the VCE factory.
Selected components are deployed on each site and use local storage. The remaining components are shared across sites and use VPLEX storage.
The Enterprise Hybrid Cloud NEI Pod function is split across the AMP and Edge clusters.
Architecture overlay: Continuous availability-protection (VxBlock only)

Chapter 4: Multi-Site and Multi-vCenter Protection Services
71 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The Edge cluster uses VCE UCS C-Series (configurable based on bandwidth requirements).
Automation Pod components consume production blades. They are deployed in the VCE factory but are configured onsite.
VPLEX Metro is required for storage replication.
Figure 41 shows how Enterprise Hybrid Cloud and VCE components overlay in this configuration.
Figure 41. Enterprise Hybrid Cloud on VxBlock with continuous availability protection
When Enterprise Hybrid Cloud is deployed with RecoverPoint for Virtual Machines disaster recovery protection:
The high performance AMP-2HAP option from VCE is required. AMP-2HAP ensures sufficient compute resources exist to run all native AMP management components as well as the Enterprise Hybrid Cloud Core Pod components.
A single vCenter per site is the default as the Enterprise Hybrid Cloud ‘Cloud vCenter’ role is provided by the VCE AMP vCenter.
Core and NEI Pod functions are deployed and configured in the VCE factory.
Architecture overlay: RecoverPoint for Virtual Machines DR protection (VxBlock and VxRack)

Chapter 4: Multi-Site and Multi-vCenter Protection Services
72 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The Enterprise Hybrid Cloud NEI Pod function is split across AMP and Edge clusters.
The Edge cluster uses VCE UCS C-Series (configurable based on bandwidth requirements).
Automation Pod components consume production blades. They are deployed in the VCE factory but are configured onsite.
RecoverPoint for Virtual Machines is required for virtual machine replication.
Reserved compute capacity in the secondary for Automation Pod failover is required.
Virtual RecoverPoint Appliances (vRPAs) are deployed to tenant resource pods and scale in line with the number of protected virtual machines.
Figure 42 shows how Enterprise Hybrid Cloud and VCE components overlay in this configuration.
Figure 42. Enterprise Hybrid Cloud on VxBlock with RecoverPoint for Virtual Machines DR protection
When Enterprise Hybrid Cloud is deployed with SRM-based disaster recovery protection:
The high performance AMP-2HAP option from VCE is required. AMP-2HAP ensures sufficient compute resources exist to run all native AMP management components as well as the Enterprise Hybrid Cloud Core Pod components.
A single vCenter per site is the default as the Enterprise Hybrid Cloud ‘Cloud vCenter’ role is provided by the VCE AMP vCenter.
Core and NEI Pod functions are deployed and configured in the VCE factory.
The Enterprise Hybrid Cloud NEI Pod function is split across AMP and Edge clusters.
Architecture overlay: Site Recovery Manager DR protection (VxBlock only)

Chapter 4: Multi-Site and Multi-vCenter Protection Services
73 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The Edge cluster uses VCE UCS C-Series (configurable based on bandwidth requirements).
Automation Pod components consume production blades. They are deployed in the VCE factory but are configured onsite.
RecoverPoint is required for storage replication.
Reserved compute capacity in the secondary for Automation Pod failover is required.
Figure 43 shows how Enterprise Hybrid Cloud and VCE components overlay in this configuration.
Figure 43. Enterprise Hybrid Cloud on VxBlock with Site Recovery Manager DR protection

Chapter 5: Network Considerations
74 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 5 Network Considerations
This chapter presents the following topics:
Overview .................................................................................................................. 75
Cross-vCenter VMware NSX ...................................................................................... 75
Physical connectivity considerations ....................................................................... 76
Logical network considerations ............................................................................... 77
Network virtualization .............................................................................................. 84
Network requirements and best practices ................................................................ 89
Enterprise Hybrid Cloud validated network designs using VMware NSX ................... 93

Chapter 5: Network Considerations
75 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Overview
Enterprise Hybrid Cloud provides a network architecture that is resilient in the event of failure, enables optimal throughput, and secure separation.
This chapter presents a number of generic logical network topologies, details on the requirements for networking under the different protection services available within Enterprise Hybrid Cloud and the networking designs that are pre-validated by Enterprise Hybrid Cloud.
Cross-vCenter VMware NSX
Enterprise Hybrid Cloud permits the use of cross-vCenter VMware NSX and universal objects in all except the SRM-based DR protection service.
This feature allows multiple NSX managers to be federated together in a primary/secondary relationship. One primary NSX manager can be linked to up to seven secondary NSX managers. This enables the deployment of some NSX network and security components across multiple vCenters.
These cross-vCenter network and security components are referred to as “universal” and can only be managed on the primary manager. Some network and security objects are not universal; they are referred to as standard or local objects, and must be managed from their associated NSX manager. Replication of universal objects takes place from the primary NSX managers to the secondary managers so that each manager has the configuration details for all universal objects. This allows a secondary NSX manager to be promoted if that primary NSX manager has failed.
The universal distributed logical router (uDLR) and the universal logical switch (uLS) are used to span networks and east-west routing across vCenters.
Note: The version of vRealize Automation used with Enterprise Hybrid Cloud 4.0 supports universal network objects.
The universal section of the Distributed Firewall (DFW) and universal security group can be used to apply firewall rules across vCenters.
Note: The version of vRealize Automation used with Enterprise Hybrid Cloud 4.0 does NOT support universal security objects.
There is a single primary NSX manager and a single universal controller cluster in a federated NSX environment, therefore the placement and protection of these components must be considered carefully. The primary NSX manager will be connected to one of cloud vCenters in the Enterprise Hybrid Cloud system. The universal controllers cluster can only be deployed to clusters that are part of that cloud vCenter. Take into account the following considerations in the placement of the primary NSX manager and the universal controller cluster:
Introduction to Enterprise Hybrid Cloud networking
Using cross-vCenter NSX
Universal network objects
Universal security objects
Primary NSX manager and the universal controller cluster

Chapter 5: Network Considerations
76 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
If the Enterprise Hybrid Cloud system uses VPLEX to support Continuous Availability (Single-site) protection, then the primary NSX manager and the universal controller cluster should be VPLEX protected.
If the Enterprise Hybrid Cloud system uses VPLEX to support Continuous Availability (Dual-site) protection, then the primary NSX manager and the universal controller cluster should be VPLEX protected.
Physical connectivity considerations
In designing the physical architecture, the main considerations are high availability, performance, and scalability. Each layer in the architecture should be fault tolerant with physically redundant connectivity throughout. The loss of any one infrastructure component or link should not result in loss of service to the tenant; if scaled appropriately, there is no impact on service performance.
Physical network and FC connectivity to the compute layer may be provided over a converged network to converged network adapters on each compute blade, or over any network and FC adapters that are supported by the hardware platform and vSphere.
VCE VxBlock was designed with NSX in mind, so configuring NSX on a VxBlock for Enterprise Hybrid Cloud is relatively straightforward. Relevant considerations are:
VxBlocks are built with ToR switches that are configured for Layer 3. This is ideal for NSX deployments.
VxBlocks already have a disjointed Layer 2 (DJL2) configuration between the fabric interconnects and the ToR switches to support dynamic routing.
VxBlocks, since they have ToR switches that are configured for Layer 3, are not normally deployed with virtual port channel connections between the ToR switches and the customer’s switches.
When deploying NSX on a VxBlock, some servers need to be dedicated to the edge cluster. This edge cluster forms the physical to virtual demarcation point between NSX and the customer’s physical network. All north-south traffic flows through the edge cluster. VxBlocks support C-series servers for use in the edge cluster. C-series servers have an excellent throughput profile. Two different types of C-series are offered. One that supports 10Gbps of throughput, and one that supports 20Gbps of throughput, so sizing the edge cluster is still important.
VxBlock

Chapter 5: Network Considerations
77 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Logical network considerations
Each logical topology is designed to address the requirements of secure separation of the tenant resources. It is also designed to align with security best practices for segmenting networks according to the purpose or traffic type.
There must be at least one distributed vSwitch in the Cloud vCenter if NSX is in use. Multiple distributed vSwitches are supported.
Note: While the minimum is one distributed vSwitch per vCenter, Enterprise Hybrid Cloud recommends two distributed switches in the Cloud vCenter. The first distributed switch should be used for cloud management networks and the second distributed switch for tenant workload networks. The sample layouts provided later in this chapter use this model and indicate which networks are on each distributed switch by indicating vDS1 or vDS2. Additional distributed switches can be created for additional tenants if required.
The following network layouts are sample configurations to assist in understanding the elements that need to be catered for in an Enterprise Hybrid Cloud network design. They do not represent a prescriptive list of the permitted configurations for logical networks in Enterprise Hybrid Cloud. The network layout should be designed based on individual requirements.
Layout 1
Figure 44 shows one possible logical-to-physical network layout where standard vSphere switches are used for the basic infrastructural networks.
This layout may be preferable where:
Additional network interface cards (NICs) are available in the hosts to be used.
Increased protection against errors in configuration at a distributed vSwitch level is required. It does this by placing the network file system (NFS), Internet SCSI (iSCSI), and vSphere vMotion networks on standard vSwitches.
Dynamic networking technology is required through the use of VMware NSX.
Note: All VLAN suggestions are samples only and should be determined by the network team in each environment.
Distributed vSwitch requirements
Sample logical network layouts

Chapter 5: Network Considerations
78 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 44. Network layout 1
Descriptions of each network are provided in Table 7.
Table 7. Network layout 1 descriptions
Name Type Switch type Location VLAN Description
vmk_ESXi_MGMT VMkernel Standard vSwitch
vSphere ESXi hosts
100 VMkernel on each vSphere ESXi host that hosts the management interface for the vSphere ESXi host itself. DPG_Core network should be able to reach this network.
vmk_NFS VMkernel Standard vSwitch
External vCenter and Cloud vCenter
200 Optional VMkernel used to mount NFS datastores to the vSphere ESXi hosts. NFS file storage should be connected to the same VLAN/subnet, or routable from this subnet.
vmk_iSCSI VMkernel
Standard vSwitch
External vCenter and Cloud vCenter
300 Optional VMkernel used to mount iSCSI datastores to the vSphere ESXi hosts. iSCSI network portals should be configured to use the same VLAN/subnet, or routable from this subnet.
vmk_vMOTION VMkernel
Standard vSwitch
External vCenter and Cloud vCenter
400 VMkernel used for vSphere vMotion between vSphere ESXi hosts.

Chapter 5: Network Considerations
79 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Name Type Switch type Location VLAN Description
DPG_Core vSphere distributed port group
Distributed vSwitch 1
External vCenter
500 Port group to which the management interfaces of all the core management components connect
DPG_NEI vSphere distributed port group
Distributed vSwitch 1
Cloud vCenter
600 Port group to which the NSX controllers on the NEI Pod connect. DPG_Core network should be able to reach this network.
DPG_Automation vSphere distributed port group
Distributed vSwitch 1
Cloud vCenter
700 Port group to which the management interfaces of all the Automation Pod components connect
DPG_Tenant_Uplink vSphere distributed port group
Distributed vSwitch 2
Cloud vCenter
800 Port group used for all tenant traffic to egress from the cloud. Multiples may exist.
VXLAN_Transport NSX distributed port group
Distributed vSwitch 2
Cloud vCenter
900 Port group used for VTEP endpoints between vSphere ESXi hosts to allow VXLAN traffic.
ESG_DLR_Transit NSX logical switch
Distributed vSwitch 2
Cloud vCenter
Virtual wire
VXLAN segments connecting Tenant Edge and Tenant DLRs. Multiples may exist.
Workload NSX logical switch
Distributed vSwitch 2
Cloud vCenter
Virtual wire
Workload VXLAN segments. Multiples may exist.
Avamar_Target
(optional)
Primary PVLAN
N/A Physical switches
1000 Promiscuous primary PVLAN to which physical Avamar grids are connected. This PVLAN has an associated secondary isolated PVLAN (1100) in which the Avamar proxies are placed
DPG_AV_Proxies
(optional)
Secondary PVLAN/ vSphere distributed port group
Distributed vSwitch 2
Physical switches/Cloud vCenter
1100 Isolated secondary PVLAN to which Avamar proxies virtual machines are connected. This PVLAN enables proxies to communicate with Avamar grids on the Avamar_Target network but prevents proxies from communicating with each other
Layout 2
Figure 45 shows a second possible logical to physical network layout where distributed vSphere switches are used for all basic infrastructural networks, except the vSphere ESXi management network.
This layout may be preferable where:
Fewer NICs are available in the hosts to be used.

Chapter 5: Network Considerations
80 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Increased consolidation of networks is required. It does this by placing all, except the ESXi management interfaces, on distributed vSwitches.
Dynamic networking technology is required through the use of VMware NSX.
Note: All VLAN suggestions are samples only and should be determined by the network team in each environment.
Figure 45. Network layout 2
Descriptions of each network are provided in Table 8.
Table 8. Network layout 2 descriptions
Name Type Switch type Location VLAN Description
vmk_ESXi_MGMT VMkernel Standard vSwitch
ESXi hosts 100 VMkernel on each vSphere ESXi host that hosts the management interface for the vSphere ESXi host itself. DPG_Core network should be able to reach this network.
vmk_NFS VMkernel Distributed vSwitch 1
External vCenter and Cloud vCenter
200 Optional VMkernel used to mount NFS datastores to the vSphere ESXi hosts. NFS File Storage should be connected to the same VLAN/subnet or routable from this subnet.

Chapter 5: Network Considerations
81 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Name Type Switch type Location VLAN Description
vmk_iSCSI VMkernel Distributed vSwitch 1
External vCenter and Cloud vCenter
300 Optional VMkernel used to mount iSCSI datastores to the vSphere ESXi hosts. iSCSI network portals should be configured to use the same VLAN/subnet or routable from this subnet.
vmk_vMOTION VMkernel Distributed vSwitch 1
External vCenter and Cloud vCenter
400 VMkernel used for vSphere vMotion between vSphere ESXi hosts.
DPG_Core vSphere distributed port group
Distributed vSwitch 1
External vCenter
500 Port group to which the management interfaces of all the core management components connect
DPG_NEI vSphere distributed port group
Distributed vSwitch 1
Cloud vCenter
600 Port group to which the NSX controllers on the NEI Pod connect. DPG_Core network should be able to reach this network.
DPG_Automation vSphere distributed port group
Distributed vSwitch 1
Cloud vCenter
700 Port group to which the management interfaces of all the Automation Pod components connect
DPG_Tenant_Uplink vSphere distributed port group
Distributed vSwitch 2
Cloud vCenter
800 Port group used for all tenant traffic to egress from the cloud. Multiples may exist.
VXLAN_Transport NSX distributed port group
Distributed vSwitch 2
Cloud vCenter
900 Port group used for VTEP endpoints between vSphere ESXi hosts to allow VXLAN traffic.
ESG_DLR_Transit NSX logical switch
Distributed vSwitch 2
Cloud vCenter
Virtual wire
VXLAN segments connecting Tenant Edge and Tenant DLRs. Multiples may exist
Workload NSX logical switch
Distributed vSwitch 2
Cloud vCenter
Virtual wire
Workload VXLAN segments. Multiples may exist.
Avamar_Target
(optional)
Primary PVLAN
N/A Physical switches
1000 Promiscuous primary PVLAN to which physical Avamar grids are connected. This PVLAN has an associated secondary isolated PVLAN (1100) in which the Avamar proxies are placed

Chapter 5: Network Considerations
82 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Name Type Switch type Location VLAN Description
DPG_AV_Proxies
(optional)
Secondary PVLAN/
vSphere distributed port group
Distributed vSwitch
Physical switches/ Cloud vCenter
1100 Isolated secondary PVLAN to which Avamar proxies virtual machines are connected. This PVLAN enables proxies to communicate with Avamar Grids on the Avamar_Target network but prevents proxies from communicating with each other
Layout 3
Figure 46 shows a third possible logical-to-physical network layout where distributed vSphere switches are used for all networks other than the management network.
This layout may be preferable where:
There is no requirement for dynamic networking.
Reduction of management host count is paramount, because it removes the need for the NEI Pod.
Note: All VLAN suggestions are samples only and should be determined by the network team in each environment.
Figure 46. Network layout 3
Descriptions of each network are provided in Table 9.

Chapter 5: Network Considerations
83 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Table 9. Network layout 3 descriptions
Name Type Switch type Location VLAN Description
vmk_ESXi_MGMT VMkernel Standard vSwitch
ESXi Hosts 100 VMkernel on each vSphere ESXi host that hosts the management interface for the ESXi Host itself. DPG_Core network should be able to reach this network.
vmk_NFS VMkernel
Standard vSwitch
External vCenter and Cloud vCenter
200 Optional VMkernel used to mount NFS datastores to the vSphere ESXi hosts. NFS File Storage should be connected to the same VLAN/subnet or routable from this subnet.
vmk_iSCSI VMkernel
Standard vSwitch
External vCenter and Cloud vCenter
300 Optional VMkernel used to mount iSCSI datastores to the vSphere ESXi hosts. iSCSI network portals should be configured to use the same VLAN /subnet or routable from this subnet.
vmk_vMOTION VMkernel
Standard vSwitch
External vCenter and Cloud vCenter
400 VMkernel used for vSphere vMotion between vSphere ESXi hosts.
DPG_Core vSphere distributed port group
Distributed vSwitch 1
External vCenter
500 Port group to which the management interfaces of all the core management components connect
DPG_Automation vSphere distributed port group
Distributed vSwitch 1
Cloud vCenter
600 Port group to which the management interfaces of all the Automation Pod components connect
DPG_Tenant_Uplink vSphere distributed port group
Distributed vSwitch 2
Cloud vCenter
700 Port group used for all tenant traffic to egress from the cloud. Multiples may exist.
DPG_Workload_1 vSphere distributed port group
Distributed vSwitch 2
Cloud vCenter
800 Port group used for workload traffic
DPG_Workload_2 vSphere distributed port group
Distributed vSwitch 2
Cloud vCenter
900 Port group used for workload traffic
Avamar_Target
(optional)
Primary PVLAN
N/A Physical switches
1000 Promiscuous primary PVLAN to which physical Avamar grids are connected. This PVLAN has an associated secondary isolated PVLAN (1100) in which the Avamar proxies are placed

Chapter 5: Network Considerations
84 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Name Type Switch type Location VLAN Description
DPG_AV_Proxies
(optional)
Secondary PVLAN /
vSphere distributed port group
Distributed vSwitch 2
Physical switches/Cloud vCenter
1100 Isolated secondary PVLAN to which Avamar proxies virtual machines are connected. This PVLAN enables proxies to communicate with Avamar grids on the Avamar_Target network but prevents proxies from communicating with each other
Enterprise Hybrid Cloud has validated network designs using both Open Shortest Path First (OSPF) and Border Gateway Protocol (BGP) in DR environments. BGP is recommended over OSPF, but both have been validated.
Network virtualization
Enterprise Hybrid Cloud supports two different virtual networking technologies as follows:
VMware NSX for vSphere (recommended)
VMware vSphere Distributed Switch (VDS) (backed by appropriate technologies)
The dynamic network services with vRealize Automation highlighted in this document require NSX. VDS supports static networking configurations only, precluding the use of VXLANs.
Table 10 compares the attributes, support, and responsibility for various aspects of the Enterprise Hybrid Cloud protection services when used with, and without, VMware NSX.
Table 10. Comparing Enterprise Hybrid Cloud attributes with and without VMware NSX
Protection service Attributes with NSX Attributes without NSX
Single Site and Continuous Availability (Single-site)
Provides the fully tested and validated load balancer component for vRealize Automation and other Automation Pod components.
vRealize Automation multi-machine blueprints may use networking components provisioned dynamically by NSX.
Supports the full range of NSX functionality supported by VMware vRealize Automation.
Requires a non-NSX load balancer for vRealize Automation and other Automation Pod components. Load balancers listed as supported by VMware are permitted, but support burden falls to VMware and/or the relevant vendor.
vRealize Automation blueprints must use pre-defined vSphere networks only (no dynamic provisioning of networking components is possible.)
Possesses fewer security features due to the absence of NSX.
Reduces network routing efficiency due to the lack of east-west kernel level routing options provided by NSX.
Supported routing protocols
Supported technologies
Enterprise Hybrid Cloud attributes with and without VMware NSX

Chapter 5: Network Considerations
85 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Protection service Attributes with NSX Attributes without NSX
Continuous Availability (Dual-site)
Provides the fully tested and validated load balancer component for vRealize Automation and other Automation Pod components.
vRealize Automation multi-machine blueprints may use networking components provisioned dynamically by NSX.
Supports the full range of NSX functionality supported by VMware vRealize Automation.
Enables automatic path fail over when the ‘preferred’ site fails.
Enables VXLAN over Layer 2 or Layer 3 DCI to support tenant workload networks being available in both physical locations.
Requires a non-NSX load balancer for vRealize Automation and other Automation Pod components. Load balancers listed as supported by VMware are permitted, but the support burden falls to VMware and/or the relevant vendor.
vRealize Automation blueprints must use pre-defined vSphere networks only (no dynamic provisioning of networking components is possible.)
Possesses fewer security features due to the absence of NSX.
Reduces network routing efficiency due to the lack of east-west kernel level routing options provided by NSX.
Requires Layer 2 VLANs present at both sites to back tenant virtual machine vSphere port groups.
RecoverPoint for Virtual Machines-based disaster recovery
Provides the fully tested and validated load balancer component for vRealize Automation and other Automation Pod components.
Does not support inter-site protection of dynamically provisioned VMware NSX networking artefacts.
Supports consistent NSX security group membership by ensuring virtual machines are placed in corresponding predefined security groups across sites via Enterprise Hybrid Cloud workflows.
Provides IP mobility and simultaneous network availability on both sites for cross-vCenter NSX network configuration and universal NSX objects for both the management pods as well as the tenant workloads.
Honors NSX security tags applied to a virtual machine on the protected site prior to failover.
Requires a non-NSX load balancer for vRealize Automation and other Automation Pod components. Load balancers listed as supported by VMware are permitted, but the support burden falls to VMware and/or relevant vendor.
vRealize Automation blueprints must use pre-defined vSphere networks only (no dynamic provisioning of networking components is possible.)
Possesses fewer security features due to the absence of NSX.
Reduces network routing efficiency due to the lack of east-west kernel level routing options provided by NSX.
Requires customer-supplied technology to ensure network is available simultaneously on both sites to enable IP mobility.

Chapter 5: Network Considerations
86 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Protection service Attributes with NSX Attributes without NSX
Site Recovery Manager-based disaster recovery
Provides the fully tested and validated load balancer component for vRealize Automation and other Automation Pod components.
Does not support inter-site protection of dynamically provisioned VMware NSX networking artefacts.
Supports consistent NSX security group membership by ensuring virtual machines are placed in corresponding predefined security groups across sites via Enterprise Hybrid Cloud workflows.
Allows fully automated network re-convergence for tenant resource pods networks on the recovery site via Enterprise Hybrid Cloud workflows, the redistribution capability of BGP/OSPF and the use of NSX redistribution polices.
Does not honor NSX security tags applied to a virtual machine on the protected site prior to failover.
Requires a non-NSX load balancer for vRealize Automation and other Automation Pod components. Load balancers listed as supported by VMware are permitted, but the support burden falls to VMware and/or relevant vendor.
vRealize Automation blueprints must use pre-defined vSphere networks only (no dynamic provisioning of networking components is possible.)
Possesses fewer security features due to the absence of NSX.
Reduces network routing efficiency due to lack of east-west kernel level routing options provided by NSX.
Requires customer-supplied IP mobility technology.
Requires manual or customer provided re-convergence process for tenant resource pods on the recovery site.
This section describes the additional multitier security services available to virtual machines deployed in Enterprise Hybrid Cloud when used with VMware NSX.
NSX security policies
NSX security policies use security groups to simplify security policy management. A security group is a collection of objects, such as virtual machines, to which a security policy can be applied. To enable this capability the machines contained in the multi-machine blueprint must be configured with one or more security groups. A network security administrator or application security administrator configures the security policies to secure application traffic according to business requirements.
To ensure consistent security policy enforcement for virtual machines on the recovery site, you must configure the security policies on both the primary and recovery sites.
NSX perimeter Edge security
Perimeter edges are deployed using NSX Edges on both the primary and recovery sites. The perimeter NSX Edge provides security features, such as stateful firewalls, and other services such as dynamic host configuration protocol (DHCP), network address translation (NAT), virtual private network (VPN), and load balancer.
The configuration of various services must be manually maintained on both the primary and recovery site perimeter edges. This ensures consistent security policy enforcement in case of DR or planned migration of virtual machines to the recovery site.
VMware NSX-based security design

Chapter 5: Network Considerations
87 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
NSX distributed firewall
Enterprise Hybrid Cloud supports the distributed firewall capability of NSX to protect virtual machine communication and optimize traffic flow.
The distributed firewall is configured though the Networking and Security > Service Composer > Security Groups section of the vSphere web client. Figure 47 shows various security groups that may be pre-created in the NSX security configuration.
Figure 47. Security groups on the primary and recovery sites
Enterprise Hybrid Cloud provides an option to associate security group information with a machine blueprint. When a business user deploys the blueprint, the virtual machine is included in the security group configuration. This ensures enforcement of the applicable security policy as soon as the virtual machine is deployed.
As shown in Figure 48, a corresponding security group of the same name must be created on the recovery site. To ensure that workloads are consistently protected after failover, both primary and recovery site security policies must be identically configured.
NSX security tags
NSX security tags are supported with the RecoverPoint for Virtual Machines-based DR protection service. Tags must be pre-created on both NSX instances associated with the relevant vCenters. When workloads are failed over using RecoverPoint for Virtual Machines, the security tags are honored on the recovery site.

Chapter 5: Network Considerations
88 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 48. Creating NSX security tags
EMC Enterprise Hybrid Cloud with VMware NSX can coexist with Cisco ACI, but integration with Cisco ACI is not supported.
Supported with Enterprise Hybrid Cloud RPQ
ACI as data center fabric: In this configuration, the ToR switches are in NX-OS mode and connected to ACI leaf switches.
ACI as underlay:
In this configuration, the ToR switches are configured as ACI leaf switches.
The configuration must match the VMware reference design, refer to https://communities.vmware.com/docs/DOC-30849
Support for any issues that arise with this configuration is provided by VMware's Network and Security Business Unit (NSBU)
Not supported
ACI integration with vSphere/vCenter: This includes the use of Cisco AVS or VMM integration (APIC controlled VDS)
Enterprise Hybrid Cloud integration with Cisco ACI: There are currently no plans to integrate EHC with Cisco ACI
NSX co-existence with Cisco ACI

Chapter 5: Network Considerations
89 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Network requirements and best practices
Single site
Single site workloads do not migrate from one site to another; therefore, there is no requirement for IP mobility technology to support this protection level.
Continuous Availability (Single-site)
Single-site continuous availability workloads do not migrate from one site to another; therefore, there is no requirement for IP mobility technology to support this protection level.
Continuous Availability (Dual-site)
Continuous availability workloads can operate on either site, or be divided between sites. As virtual machine workloads may potentially migrate at any time, the network they use should span sites so that the workloads continue to operate successfully if this happens.
When using VMware NSX, this can be provided by VXLAN technology.
Disaster recovery (Site Recovery Manager)
All SRM-based disaster recovery workloads on a DR2S (DR RecoverPoint storage across two sites) cluster pair may operate on one site, or the other at any given time. The networks for that cluster therefore only need to be active on the protected side of that cluster pair. During failover, those networks need to be re-converged to the other site so that the workloads can benefit from using the same IP addressing.
When using VMware NSX, this can be provided by Enterprise Hybrid Cloud customizations that dynamically find those networks and interact with multiple NSX manager instances to achieve that re-convergence.
Disaster recovery (RecoverPoint for Virtual Machines)
RecoverPoint for Virtual Machine-based DR workloads may move individually between sites and vCenter endpoints. This requires that the underlying network infrastructure is able to support two or more virtual machines with IPv4 addresses from the same subnet, running on different sites and vCenters at the same time.
When using VMware NSX, this can be achieved using cross-vCenter NSX VXLAN networking configurations.
Best practices common to all protection services
VMware anti-affinity rules should be used to ensure that the following conditions are true during optimum conditions:
NSX controllers reside on different hosts.
NSX ESGs configured for high availability reside on different hosts.
NSX DLR Control virtual machines reside on different hosts.
NSX ESG and DLR Control virtual machines reside on different hosts.
IP mobility
VMware NSX best practices

Chapter 5: Network Considerations
90 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Continuous availability additional best practices
VMware anti-affinity rules should be used to ensure that the following conditions are true during optimum conditions:
All NSX controllers reside on a converged infrastructure (CI) platform/site, and move laterally within that platform/site before moving to the alternate platform/site.
Single site
With the single-site protection service, when NSX is used, all NSX controllers, Edges, and DLR components reside in the same site. NSX best practice recommends that each NSX controller be placed on a separate physical host. This enforces a three-node minimum on the cluster hosting the NSX controllers.
Combining NSX best practices for this protection service enforces a four-node minimum on the cluster hosting the NSX Edges and DLRs.
Continuous Availability (Single-site) protection service
With the Continuous Availability (Single-site) protection service, the goal is to provide inter-converged infrastructure redundancy for tenant workloads by stretching the tenant workload pods between two CI platforms.
This leaves a number of options for protecting the networks those tenant workloads use:
Option 1: Place the NEI Pod on vSphere Metro storage clusters Protect the NEI Pod with the same mechanism as the tenant pods using vSphere Metro storage (stretched) clusters between the two CI platforms. NSX best practice recommends that each NSX controller is placed on a separate physical host. This enforces a six-node minimum on the cluster hosting the NSX controllers.
Combining NSX best practices for this protection service enforces an eight-node minimum on the cluster hosting the NSX Edges and DLRs.
Option 2: Place the NEI Pod on common infrastructure in a third fault domain Place the NEI Pod in a third fault domain on the same site, so that it is not affected by the failure of either individual CI platform, but as a result it does not have the same level of protection as the tenant workloads. NSX best practice recommends that each NSX controller is placed on a separate physical host. This enforces a three-node minimum on the cluster hosting the NSX controllers.
Combining NSX best practices for this protection service enforces a four-node minimum on the cluster hosting the NSX Edges and DLRs.
Option 3: Place the NEI Pod on one of the two CI platforms Place the NEI Pod in one of the two CI platforms, failure of that individual CI platform would result in the tenant workloads surviving on the remaining CI platform but potentially without full network access. NSX best practice recommends that each NSX controller is placed on a separate physical host. This enforces a three-node minimum on the cluster hosting the NSX controllers.
NEI Pod considerations

Chapter 5: Network Considerations
91 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Combining NSX best practices for this protection service enforces a four-node minimum on the cluster hosting the NSX Edges and DLRs.
Continuous Availability (Dual-site)
With the Continuous Availability (Dual-site) protection service, the NEI Pod is protected with the same mechanism as the tenant pods using vSphere Metro Storage (stretched) clusters between the two CI platforms. NSX best practice recommends that each NSX controller is placed on a separate physical host. This enforces a six-node minimum on the cluster hosting the NSX controllers.
Combining NSX best practices for this protection service enforces an eight-node minimum on the cluster hosting the NSX Edges and DLRs.
Disaster Recovery (Site Recovery Manager and RecoverPoint for Virtual Machines)
With both DR protection services, the NEI Pod is duplicated, with one instance residing in each of the two CI platforms. NSX best practice recommends that each NSX controller is placed on a separate physical host. This enforces a three-node minimum (per site) on the cluster hosting the NSX controllers.
Combining NSX best practices for this protection service enforces a four-node minimum (per site) on the cluster hosting the NSX Edges and DLRs.
Single site
With single-site protection both the tenant workloads and their respective edge gateways are always on the same site and cannot move so there are no special traffic routing considerations for these workloads.
Continuous Availability (Single-site)
With Continuous Availability (Single-site) protection both the tenant workloads and their respective edge gateways are always on the same site and cannot move so there are no traffic latency concerns in relation to these workloads.
The manner in which the NEI Pod is protected, especially the infrastructure hosting the NSX Edge and DLR devices, should be considered. Review the options for this protection service in NEI Pod considerations and how this would affect traffic routing and bandwidth between the converged infrastructure platforms involved.
Continuous Availability (Dual-site)
With Continuous Availability (Dual-site) protection, it is recommended to create two sets of networks for traffic routing efficiencies– one that is preferred on Site A and a second that is preferred at Site B. In real terms, this results in two sets of NSX Edge devices on the NSX Edge cluster.
Under normal conditions, the Site A NSX Edges will be located on the Site A half of the cluster providing local ingress/egress for workloads designated as Site A preferred. Likewise, the Site B NSX Edges would reside on the Site B half of the cluster and provide Site B ingress/egress.
Traffic ingress and egress considerations

Chapter 5: Network Considerations
92 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
If a site fails or the majority of workloads on a network are moved to the alternate site, then the appropriate NSX Edge gateways can be migrated to the remaining half of the cluster and continue to provide network access.
Disaster recovery (Site Recovery Manager)
With SRM-based DR protection all networks for a DR2S cluster are active only on the protected side of that cluster pair. All workloads reside only on the member of the cluster pair that is currently designated as the protected cluster.
Each member of the cluster pair resides in a different vCenter and therefore all workloads use only the NSX Edges relevant to that vCenter and site. As a result, all network traffic to those Edge devices is always local (intra-site) so there are no special traffic routing considerations for these workloads.
Disaster recovery (RecoverPoint for Virtual Machines)
With RecoverPoint for Virtual Machines-based DR all networks on LC1S clusters are simultaneously across two different sites and vCenters.
However, the NSX Edge gateway for any given network can only reside on one site, or the other. As a result, any virtual machine on that network residing on the opposite site to the Edge gateway will need to cross inter-site link to exit the network.
To mitigate this, it is recommended to create two sets of networks for traffic routing efficiencies– one that is preferred on Site A and a second that is preferred at Site B. In real terms, this results in two sets of NSX Edge devices on the NSX Edge cluster (four sets in total.)
Under normal conditions, the Network 1 NSX Edges on Site A provide ingress and egress for Site A preferred workloads. Similarly, Network 2 NSX Edges on Site B provide ingress and egress for Site B preferred workloads. When Network 1 workloads move to Site B, they continue to ingress/egress through Site A and vice versa.
If a site fails or the majority of workloads on a network are moved to the alternate site, then the appropriate networks can be re-converged to the opposite site, for example, Network 1 NSX Edges on Site B would begin to provide ingress/egress for that network.

Chapter 5: Network Considerations
93 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Enterprise Hybrid Cloud validated network designs using VMware NSX
Figure 49 shows an example of an environment that uses the VMware NSX-based network configuration for the single-site protection service, as tested and validated by Enterprise Hybrid Cloud.
Figure 49. Verified single site network configuration
Supported configurations
While the diagram in Figure 49 shows the use of standard (local) DLRs and logical switches, universal DLRs and logical switches are also supported, although they would not provide any additional benefits in this scenario.
Single site network design

Chapter 5: Network Considerations
94 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Network configuration
This network configuration has the following attributes:
Egress routing: BGP neighbor relationships configured on the DLR are weighted as follows to influence egress routing:
Site-A ESGs: BGP weight = default
Ingress routing: The ingress path from the customer’s network, is influenced by using the following technique:
Via Site-A: None (this is the primary path)
Normal operation
Under normal operating conditions, the network operates as follows:
Egress from the DLR: Routes learned by the ESGs from the ToR switches via External Border Gateway Protocol (eBGP) are advertised to the DLR. All routes from the ESGs are installed in the routing table.
Ingress to the DLR: Routes learned by the ESGs from the DLR via Interior Border Gateway Protocol (iBGP) are advertised to the ToR switches.
Figure 50 shows an example of an environment that uses the VMware NSX-based network configuration for the Continuous Availability (Single-site) protection service as tested and validated by Enterprise Hybrid Cloud.
Continuous Availability (Single-site) network design

Chapter 5: Network Considerations
95 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 50. Verified Continuous Availability (Single-site) network configuration
Supported configurations
While the diagram in Figure 50 show the use of standard (local) DLRs and logical switches, universal DLRs and logical switches are also supported, although they do not provide any additional benefits in this scenario. This statement is true for two reasons:
The local egress feature in VMware NSX is not utilized.
Because a single vCenter is in use, a standard or a universal DLR are both capable of spanning hardware islands or sites.
In Figure 50, Hardware Island 1 is the primary egress/ingress path for the tenant cluster(s). It is also possible to make Hardware Island 2 the primary egress/ingress path for the tenant cluster(s). This network design allows the egress/ingress path to switch to Hardware Island 2 automatically if Hardware Island 1 fails (and vice versa, if Hardware Island 2 is primary).

Chapter 5: Network Considerations
96 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: To influence the routing of ingress traffic, this network design uses BGP autonomous system (AS) path prepend. This requires support for BGP routing in the customer network.
Network configuration
This network configuration has the following attributes:
Egress routing: BGP neighbor relationships configured on the DLR are weighted as follows to influence egress routing:
To Hardware Island 1 ESGs: BGP weight = 120
To Hardware Island 2 ESGs: BGP weight = 80
Ingress routing: The ingress path from the customer’s network, is influenced by using the following techniques:
Via Hardware Island 1: None (this is the primary path)
Via Hardware Island 2: Path prepend is configured in the ToR switches to elongate the path via Hardware Island 2 to ensure it is the less desirable path under normal operations.
Normal operation
Under normal operating conditions, the network operates as follows:
Egress from the DLR: Routes learned by the ESGs from their respective ToR switches via eBGP are advertised to the DLR. Only routes from Hardware Island 1 ESGs are installed in the DLR routing table due to a higher BGP weight.
Ingress to the DLR: Routes advertised by the DLR are learned by both the Hardware Island 1 and Hardware Island 2 ESGs via iBGP. The ESGs will in turn advertise these routes to their respective ToR switches. The Hardware Island 1 ToR switches will advertise the DLR routes to the customer’s network without manipulation. The Hardware Island 2 ToR switches will also advertise the DLR routes to the customer’s network, but will first elongate the AS path, using AS path prepend. This will result in the DLR routes learned from the Hardware Island 1 ToR switches being installed in upstream routing tables (shortest path length).
Operation if Hardware Island 1 fails
If Hardware Island 1 fails, the network operates as follows:
Egress from the DLR: The DLR will no longer be peered with the Hardware Island 1 ESGs. Routes learned from the Hardware Island 1 ESGs will timeout and routes learned from the Hardware Island 2 ESGs will now become the best (and only) option and will be installed in the DLR routing table.
Ingress to the DLR: DLR routes learned by the customer’s network from the Hardware Island 1 ToR switches will timeout and the DLR routes learned from the Hardware Island 2 ToR switches (elongated AS path), will now become the best (and only) option and will be installed in upstream routing tables.

Chapter 5: Network Considerations
97 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Operation if Hardware Island 1 is restored
When Hardware Island 1 is restored, the network operates as follows:
Egress from the DLR: The peering relationship between the DLR and the Hardware Island 1 ESGs are automatically restored. Routes from the Hardware Island 1 ESGs will again be learned by the DLR. These routes will have a higher BGP weight and are installed in the DLR routing table, replacing the routes from the Hardware Island 2 ESGs.
Ingress to the DLR: The peering relationship between the ToR switches and the customer’s network are automatically restored. The customer’s network will again learn DLR routes from the Hardware Island 1 ToR switches. These routes are installed in upstream routing tables (shortest path length), replacing the routes from the Hardware Island 2 ToR switches.
Figure 51 shows an example of an environment that uses the VMware NSX-based network configuration for the Continuous Availability (Dual-site) protection service as tested and validated by Enterprise Hybrid Cloud.
Figure 51. Verified Continuous Availability (Dual-site) network configuration
Continuous Availability (Dual-site) network design

Chapter 5: Network Considerations
98 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Supported configurations
While the diagram in Figure 51 show the use of standard (local) DLRs and logical switches, universal DLRs and logical switches are also supported, although they would not provide any additional benefits in this scenario. This statement is true for two reasons:
The local egress feature in VMware NSX is not utilized.
Because a single vCenter is in use, a standard or universal DLR are both capable of spanning hardware islands or sites
In Figure 51, Site A is the primary egress/ingress path for the tenant cluster(s). It is also possible to make Site B the primary egress/ingress path for the tenant cluster(s). This network design allows the egress/ingress path to switch to Site B automatically if Site A fails (and vice versa, if Site B is primary).
Note: To influence the routing of ingress traffic, this network design uses BGP AS path prepend. This requires support for BGP routing in the customer network.
Note: Using a stretched Edge cluster to support the ESGs and DLR is also supported.
Network configuration
This network configuration has the following attributes:
Egress routing: BGP neighbor relationships configured on the DLR are weighted as follows to influence egress routing:
To Site A ESGs: BGP weight = 120
To Site B ESGs: BGP weight = 80
Ingress routing: The ingress path from the customer’s network, is influenced by using the following techniques:
Via Site A: None (this is the primary path)
Via Site B: As path prepend is configured in the ToR switches to elongate the path via Site B to ensure it is the less desirable path under normal operations.
Normal operation
Under normal operating conditions, the network operates as follows:
Egress from the DLR: Routes learned by the ESGs from their respective ToR switches via eBGP are advertised to the DLR. Only routes from Site A ESGs are installed in the DLR routing table due to a higher BGP weight.
Ingress to the DLR: Routes advertised by the DLR are learned by both the Site A and Site B ESGs via iBGP. The ESGs turn advertise these routes to their respective ToR switches. The Site A ToR switches will advertise the DLR routes to the customer’s network without manipulation. The Site B ToR switches also advertises the DLR routes to the customer’s network, but first elongates the AS path, using AS path prepend. This results in the DLR routes learned from the Site A ToR switches being installed in upstream routing tables (shortest path length).

Chapter 5: Network Considerations
99 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Operation if Site A fails
If Site A fails, the network will operate as follows:
Egress from the DLR: The DLR will no longer be peered with the Site A ESGs. Routes learned from the Site A ESGs will time out and routes learned from the Site B ESGs will now become the best (and only) option and will be installed in the DLR routing table.
Ingress to the DLR: DLR routes learned by the customer’s network from the Site A ToR switches will time out and the DLR routes learned from the Site B ToR switches (elongated AS path), will now become the best (and only) option and will be installed in upstream routing tables.
Operation if Site A is restored
When Site A is restored, the network will operate as follows:
Egress from the DLR: The peering relationship between the DLR and the Site A ESGs will be automatically restored. Routes from the Site A ESGs will again be learned by the DLR. These routes will have a higher BGP weight and will be installed in the DLR routing table, replacing the routes from the Site B ESGs.
Ingress to the DLR: The peering relationship between the ToR switches and the customer’s network will be automatically restored. The customer’s network will again learn DLR routes from the Site A ToR switches. These routes will be installed in upstream routing tables (shortest path length), replacing the routes from the Site B ToR switches.

Chapter 5: Network Considerations
100 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 52 shows an example of an environment that uses the VMware NSX-based network configuration for the SRM-based disaster recovery protection service as tested and validated by Enterprise Hybrid Cloud.
Figure 52. Verified Site Recovery Manager-based disaster recovery network configuration
Supported configurations
The SRM-based DR service currently supports only standard (local) DLR usage as Enterprise Hybrid Cloud network convergence customizations were built to work with standard DLRs only.
In Figure 52, Site A is the primary egress/ingress path for workloads on the DR cluster pair. It is also possible to make Site B the primary egress/ingress path for a DR cluster pair (this is done by the Enterprise Hybrid Cloud network convergence
Disaster recovery (Site Recovery Manager) network design

Chapter 5: Network Considerations
101 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
customizations during failover). For active/active sites, it is possible to have separate tenant clusters active at each site, each with a primary egress/ingress path at the active site.
Note: As the SRM-based DR protection service does not influence upstream routing in the same way as the continuous availability protection services, BGP is not required to be supported on the customer network (upstream of the ToR switches). Other routing protocols such as OSPF or Enhanced Interior Gateway Routing Protocol (EIGRP) can be used.
Network configuration
This network configuration has the following attributes:
Egress routing: BGP neighbor relationships configured on each DLR use the default weight, since there is only one egress path per DLR:
To ESGs (either site): BGP weight = 60 (default)
Ingress routing: The ingress path from the customer’s network is influenced by using the following techniques via:
Via Site A: A redistribution policy of permit is configured on the DLR. This allows DLR routes to be advertised to the Site A ESGs, then the ToR switches, and finally the customer’s network.
Via Site B: A redistribution policy of deny is configured on the DLR. This prevents DLR routes from being advertised to the Site B ESGs. This prevents the customer’s network from learning about DLR routes via Site B.
Normal operation
Under normal operating conditions, the network operates as follows:
Egress from the DLR: At each site, routes learned by the ESGs from the ToR switches via eBGP are advertised to the DLR via iBGP. These routes are installed in the DLR routing table.
Ingress to the DLR: At Site A, routes are advertised by the DLR, since a redistribution policy of permit is configured. These DLR routes are learned by the ESGs via iBGP and then advertised to the ToR switches via eBGP. The ToR switches then advertises these DLR routes to the customer’s network. At Site B, routes are NOT advertised by the DLR, since a redistribution policy of deny is configured. No DLR routes are learned by the ESGs, ToR switches or the customer’s network.
Operation if Site A fails
If Site A fails, the network will operate as follows:
Egress from the DLR: If Site A fails, then the Site A DLR and ESGs will be down. Since no failover operation has been performed, all virtual machines lose the ability to reach the external network and there is no egress traffic.
Ingress to the DLR: DLR routes learned by the customer’s network from the Site A ToR switches will timeout. Since no DLR routes were ever learned by the customer’s network from the Site B ToR switches, there will no longer be any DLR routes in upstream routing tables. Since no failover operation has been

Chapter 5: Network Considerations
102 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
performed, all virtual machines are no longer reachable from the external network and there would be no endpoint for ingress traffic.
Programmatic failover
As part the of SRM failover process, the network “convergence” scripts are run. These scripts perform the following:
On the Site A DLR, attempts to change the redistribution policy from permit to deny. Since Site A is down, this operation will fail. The operation is attempted in case this is a scheduled failover, in which case the Site A DLRs would have been online.
On the Site B DLR, changes the redistribution policy from deny to permit.
Operation if Site A is restored
When Site A is restored, the network will operate as follows:
Egress from the DLR: The peering relationship between the Site A DLR and the ESGs will be automatically restored. Routes from the Site A ESGs will again be learned by the DLR and installed in the DLR routing table.
Ingress to the DLR: If Site A is restored, then the peering relationship between the Site A DLR and the ESGs will be automatically restored, but since the redistribution policy was set to deny during the programmatic failover, the ESGs will NOT learn any routes from the DLR and will NOT advertise any DLR routes to the ToR switches. The peering relationship between the ToR switches and the customer’s network will also be automatically restored, but the customer’s network will NOT learn DLR routes from the Site A ToR switches, since none were learned from the Site A ESGs.
Programmatic failback
As part the of SRM failback process, the network “convergence” scripts are run. These scripts perform the following actions:
On the Site B DLR, changes the redistribution policy from permit to deny.
On the Site A DLR, changes the redistribution policy from deny to permit.

Chapter 5: Network Considerations
103 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 53 shows an example of an environment that uses the VMware NSX-based network configuration for the RecoverPoint for Virtual Machines-based DR protection service as tested and validated by Enterprise Hybrid Cloud.
Figure 53. Verified RecoverPoint for Virtual Machines-based DR network configuration
Supported configurations
The RecoverPoint for Virtual Machines-based DR service currently only supports universal DLR usage. This is a requirement to have VMware NSX-based networks federated across two vCenters and NSX Manager instances.
In Figure 53, Site A is the primary egress/ingress path for virtual machines running at either site (see above configuration). Switching the egress/ingress path to Site B can only be done programmatically.
Disaster recovery (RecoverPoint for Virtual Machines) network design

Chapter 5: Network Considerations
104 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Network configuration
This network configuration has the following attributes:
Egress routing: BGP neighbor relationships configured on the uDLR are weighted as follows to influence egress routing:
To Site-A ESGs: BGP weight = 120
To Site B ESGs: BGP weight = 80
Ingress Routing: The ingress path from the customer’s network, is influenced by using the following techniques:
Via Site A: None (this is the primary path)
Via Site B: BGP route filters are configured between the uDLR and the Site B ESGs to prevent the Site B ESGs from learning routes from the uDLR and therefore advertising them to the customer
Normal operation
Under normal operating conditions, the network operates as follows:
Egress from the uDLR: Routes learned by the ESGs from their respective ToR switches via eBGP, are advertised to the uDLR. Only routes from Site A ESGs are installed in the routing table due to BGP weighting.
Ingress to the uDLR: Routes learned from the uDLR by the Site A ESGs via iBGP are advertised to the Site A ToR switches. The Site B ESGs will not learn any routes from the uDLR due to the BGP route filters. The Site A ToR switches will advertise the uDLR routes to the customer without manipulation. The Site B ToR switches did not learn any uDLR routes from the Site B ESGs, so they will not advertise any uDLR routes to the customer.
Operation if Site A fails
If Site A fails, the network will operate as follows:
Egress from the uDLR: The uDLR will no longer be peered with the Site A ESGs. Routes learned from the Site A ESGs will timeout and routes learned from the Site B ESGs will now become the best (and only) option and will be installed in the uDLR routing table. Since no failover operation has been performed, all virtual machines lose the ability to reach the external network and there is no egress traffic.
Ingress to the uDLR: uDLR routes learned by the customer’s network from the Site A ToR switches will timeout. Since no uDLR routes were ever learned by the customer’s network from the Site B ToR switches, there will no longer be any uDLR routes in upstream routing tables. Since no failover operation has been performed, all virtual machines are no longer reachable from the external network and there would be no endpoint for ingress traffic.

Chapter 5: Network Considerations
105 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Programmatic failover
To programmatically failover the networks in this configuration:
On the uDLR, raise the BGP weights for the neighbor relationships with Site B ESGs from 40 to 140. This will preserve Site B as the primary egress path, even if Site A comes back online.
On the uDLR, remove the BGP filters, so that the Site B ESGs will learn routes from the uDLR.
On the uDLR, add the BGP filters, so that the Site A ESGs will NOT learn routes from the uDLR.
Operation if Site A is restored
When Site A is restored, the network will operate as follows:
Egress from the DLR: The peering relationship between the uDLR and the Site A ESGs will be automatically restored. Routes from the Site A ESGs will again be learned by the uDLR. These routes will have a lower BGP weight, due to changes made during programmatic failover, and therefore will NOT be installed in the uDLR routing table.
Ingress to the DLR: The peering relationship between the uDLR and the Site A ESGs will be automatically restored, but since BGP filters were added during the programmatic failover, the ESGs will NOT learn any routes from the uDLR and will NOT advertise any uDLR routes to ToR switches. The peering relationship between the ToR switches and the customer’s network will also be automatically restored, but the customer’s network will NOT learn uDLR routes from the Site A ToR switches, since none were learned from the Site A ESGs.
Programmatic failback
To programmatically failback the networks in this configuration:
On the uDLR, lower the BGP weights for the neighbor relationships with Site B ESGs from 140 to 40. This allows Site A to become the primary egress path.
On the uDLR, remove the BGP filters, so that the Site A ESGs will learn routes from the uDLR.
On the uDLR, add the BGP filters, so that the Site B ESGs will NOT learn routes from the uDLR.

Chapter 6: Storage Considerations
106 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 6 Storage Considerations
This chapter presents the following topics:
Single-site and RecoverPoint for Virtual Machines DR storage considerations ...... 107
Continuous availability storage considerations ..................................................... 111
Disaster recovery (Site Recovery Manager) storage considerations ....................... 122

Chapter 6: Storage Considerations
107 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Single-site and RecoverPoint for Virtual Machines DR storage considerations
Non-replicated storage is used for the single-site protection and RecoverPoint for Virtual Machines DR service. This section will address the storage considerations for such storage.
Single-site workloads
With single-site protection, storage provisioned to serve these workloads has no logical unit number (LUN)-based replicas, and therefore by definition, it is bound to a single site and hardware island.
LC1S clusters are created using hosts from that hardware island, therefore workloads placed on these clusters do not require any form of site or hardware island affinity.
RecoverPoint for Virtual Machines disaster recovery workloads
RecoverPoint for Virtual Machines-based DR workloads also use LC1S clusters and storage without any LUN-based replicas, as replication for these workloads is carried out at the Virtual Machine Disk (VMDK) level and not at the datastore level.
While the storage these workloads use are bound to one site, the replicated version of the workload uses a second set of storage bound to a different site.
Enterprise Hybrid Cloud presents storage in the form of storage service offerings that greatly simplify virtual storage provisioning.
The storage service offerings are based on ViPR virtual pools, which are tailored to meet the performance requirements of general IT systems and applications. Multiple storage system virtual pools, consisting of different disk types, are configured and brought under ViPR management.
ViPR presents the storage to Enterprise Hybrid Cloud as virtual storage pools, abstracting the underlying storage details and enabling provisioning tasks to be aligned with the application’s class of service. In Enterprise Hybrid Cloud, each ViPR virtual pool represents a storage service offering can be supported or backed by multiple storage pools of identical performance and capacity. This storage service-offering concept is summarized in Figure 54.
Applicability
Storage tier design

Chapter 6: Storage Considerations
108 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 54. Storage service offerings for the hybrid cloud
Note: The storage service offerings in Figure 54 are suggestions only. Storage service offerings can be configured and named as appropriate to reflect their functional use.
The storage service examples in Figure 54 suggest the following configurations:
All flash: Can be provided by either EMC XtremIO™, EMC VNX® as all-flash storage, or EMC VMAX® Fully Automated Storage Tiering for Virtual Pools (FAST® VP) where only the flash tier is used.
Tiered: Provides VNX or VMAX block or file-based VMFS or NFS storage devices and is supported by multiple storage pools using EMC FAST VP and EMC Fully Automated Storage Tiering (FAST®) Cache.
Single tier: Provides VNX® block- or file-based VMFS or NFS storage and is supported by multiple storage pools using a single storage type of NL-SAS in this example.
We suggest these storage service offerings only to highlight what is possible in an Enterprise Hybrid Cloud environment. The full list of supported platforms includes:
EMC VMAX
EMC VNX
EMC XtremIO
EMC ScaleIO®
EMC VPLEX
EMC RecoverPoint
EMC Isilon® (Workload use only)

Chapter 6: Storage Considerations
109 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
As a result, many other storage service offerings can be configured to suit business and application needs, as appropriate.
Note: EMC recommends that you follow the best practice guidelines when deploying any of the supported platform technologies. Enterprise Hybrid Cloud does not require any variation from these best practices.
Note: Enterprise Hybrid Cloud does not support the use of VMware raw device mappings (RDMs).
For block-based provisioning, ViPR virtual arrays should not contain more than one protocol. For Enterprise Hybrid Cloud, this means that ScaleIO storage and FC block storage must be provided via separate virtual arrays.
Note: Combining multiple physical arrays into fewer virtual arrays to provide storage to virtual pools is supported.
vRealize Automation provides the framework to build relationships between vSphere storage profiles and business groups so that they can be consumed through the service catalog.
Initially, physical storage pools are configured on the storage system and made available to ViPR where they are configured into their respective virtual pools. At provisioning time, LUNs or file systems are configured from these virtual pools and presented to vSphere as VMFS or NFS datastores. The storage is then discovered by vRealize Automation and made available for assignment to business groups within the enterprise.
This storage service offering approach greatly simplifies the process of storage administration. Instead of users having to configure the placement of individual VMDKs on different disk types such as serial-attached storage (SAS) and FC, they simply select the appropriate storage service level required for their business need.
Virtual disks provisioned on FAST VP storage benefit from the intelligent data placement. While frequently accessed data is placed on disks with the highest level of service, less frequently used data is migrated to disks reflecting that service level.
When configuring virtual machine storage, a business group administrator can configure blueprints to deploy virtual machines onto any of the available storage service levels. In the example in Figure 55, a virtual machine can be deployed with a blueprint including a SQL Server database, to a storage service offering named Prod-2, which was designed with the performance requirements of such an application in mind.
ViPR virtual pools
Storage consumption

Chapter 6: Storage Considerations
110 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 55. Blueprint storage configuration in vRealize Automation
The devices for this SQL Server database machine have different performance requirements, but rather than assigning different disk types to each individual drive, each virtual disk can be configured on the Prod-2 storage service offering. This allows the underlying FAST technology to handle the best location for each individual block of data across the tiers. The vRealize Automation storage reservation policy ensures that the VMDKs are deployed to the appropriate storage.
The storage presented to vRealize Automation can be shared and consumed across the various business groups using the capacity and reservation policy framework in vRealize Automation.
Storage is provisioned to the Workload Pods in the environment using the Provision Cloud Storage catalog item that can provision VNX, VMAX, XtremIO, ScaleIO, and VPLEX Local storage to LC1S workload clusters.
The workflow interacts with both ViPR and vRealize Automation to create the storage, present it to the chosen vSphere cluster and add the new volume to the relevant vRealize Storage Reservation Policy.
vSphere clusters are made eligible by on-boarding them through the Onboard Local Cluster option of the Enterprise Hybrid Cloud Cluster Maintenance vRealize Automation catalog item. When creating a LC1S cluster in an environment where RecoverPoint for Virtual Machines is also enabled, this catalog item also ensures a partner cluster is configured to allow machines to fail over to the other site.
RecoverPoint for Virtual Machines based disaster recovery functionality can be enabled or disabled globally using the rp4vms_enabled global option. Changing the value of this option may be done via the vRealize Automation catalog item entitled Global Options Maintenance.
This process ensures that only the correct type of storage is presented to the single-site (LC1S) vSphere clusters and no misplacement of virtual machines intended for LUN based inter-site protection occurs.
Storage provisioning

Chapter 6: Storage Considerations
111 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Continuous availability storage considerations
VPLEX Metro is used in both the Continuous Availability (Single-Site) and Continuous Availability (Dual-site) protection services. This section addresses the storage considerations for the VPLEX metro configuration.
Continuous Availability (Single-site) protection
With Continuous Availability (Single-site) protection, both VPLEX clusters reside in the same geographical location, but are logically associated with two different hardware islands, creating distributed storage volumes that span the storage arrays from both islands.
CA1S (CA VPLEX Metro Storage on One Site) clusters are created using hosts from both hardware islands to create a VMware vSphere Metro storage cluster. Workloads placed on these clusters have affinity to the hardware island they were deployed to as described in Hardware island affinity for tenant virtual machines.
Continuous Availability (Dual-site) protection
With Continuous Availability (Dual-site) protection, both VPLEX clusters reside in different geographical locations, and are logically associated with two different hardware islands, creating distributed storage volumes that span the storage arrays from both islands.
CA2S (CA VPLEX Metro Storage across Two Sites) clusters are created using hosts from both hardware islands to create a VMware vSphere Metro Storage Cluster. Workloads placed on these clusters have affinity to the site and hardware island they were deployed to as described in Site affinity for tenant virtual machines.
Storage tier design for continuous availability workloads should follow the same user and application driven requirements as described for single site workloads.
The only difference is in the supported underlying storage arrays that can be used to compose the physical and virtual pools used by ViPR. With continuous availability protection, all virtual pools must be VPLEX distributed virtual pools. Those pools may be backed by the following storage arrays:
EMC VMAX
EMC VNX
EMC XtremIO
There must be at least one virtual array for each hardware island/site. By configuring the virtual arrays in this way, ViPR can discover the VPLEX and storage topology.
Enterprise Hybrid Cloud ensures this is the case by mandating that continuous availability CA1S or CA2S clusters span hardware islands and that each hardware island must have its own set of ViPR virtual arrays.
Applicability
Storage tier design
ViPR virtual arrays

Chapter 6: Storage Considerations
112 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
ViPR virtual pools for block storage offer two options under high availability: VPLEX local and VPLEX distributed. Continuous availability protection uses VPLEX Distributed only. If you specify VPLEX distributed high availability for a virtual pool, the ViPR storage provisioning services create VPLEX distributed virtual volumes.
To configure a VPLEX distributed virtual storage pool through ViPR:
Ensure a virtual array exists for both sides of the distributed pool relationship. With single-site continuous availability, these virtual arrays are associated with different hardware islands on the same site. With dual-site continuous availability, these virtual arrays are associated with different hardware islands on different sites.
Each vArray should have the relevant physical arrays associated with those virtual arrays. Each VPLEX cluster must be a member of the virtual array at its own hardware island/site only.
Before creating a VPLEX high-availability virtual pool at the primary hardware island or site, create a local pool at the secondary hardware island or site. This is used as the target virtual pool when creating VPLEX distributed virtual volumes.
When creating the VPLEX high-availability virtual pool on the source hardware island/site, select the source storage pool from the primary hardware island/site, the remote virtual array, and the remote pool. This pool is used to create the remote mirror volume that makes up the remote leg of the VPLEX virtual volume.
Note: This pool is considered remote when creating a high-availability pool because it belongs to VPLEX cluster 2 and we are creating the high availability pool from VPLEX cluster 1.
Figure 56 shows this configuration in the context of Continuous Availability (Dual-site), where VPLEX High-Availability Virtual Pool represents the VPLEX high-availability pool created.
ViPR virtual pools

Chapter 6: Storage Considerations
113 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 56. Interactions between local and VPLEX distributed pools
As described in Site affinity for tenant virtual machines Enterprise Hybrid Cloud workflows use the “winning” site in a VPLEX configuration to determine which site to map virtual machines to. To enable active/active clusters, you must create two sets of datastores – one set that will win on Hardware Island/Site A and another set that will win on Hardware Island/Site B.
To enable this, you need to configure an environment similar to the one shown in Figure 56 for Hardware Island/Site A, and the inverse of it for Hardware Island /Site B (where the local pool is on Hardware Island/Site A, and the high availability pool is configured from Hardware Island/Site B).
Storage consumption operates in the same way as it does for single-site protection, that is, with vRealize Storage Reservation Policies and blueprints.
In a continuous availability context, Enterprise Hybrid Cloud automatically creates storage reservation polices in vRealize Automation that convey to the end user the site and, optionally, the hardware island that the storage will win on if a VPLEX partition event occurs.
This storage choice by the user is then used by Enterprise Hybrid Cloud vRealize Automation lifecycle operations to ensure site and/or hardware island affinity, as well as backup infrastructure affinity for the workload that the user is deploying.
Storage consumption

Chapter 6: Storage Considerations
114 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Storage is provisioned to the Workload Pods in the environment using the Provision Cloud Storage catalog item that can provision VPLEX volumes backed by VMAX, VNX, or XtremIO arrays to CA1S (CA VPLEX Metro Storage on One Site) or CA2S (CA VPLEX Metro Storage across Two Sites) workload clusters.
Note: Enterprise Hybrid Cloud recommends that you follow the best practice guidelines when deploying any of the supported platform technologies. Enterprise Hybrid Cloud does not require any variation from these best practices.
The workflow interacts with both ViPR and vRealize Automation to create the storage, presents it to the chosen vSphere cluster, and adds the new volume to the relevant vRealize storage reservation policy.
vSphere clusters are made eligible by on-boarding them through the Onboard CA Cluster option of the Enterprise Hybrid Cloud Cluster Maintenance vRealize Automation catalog item.
This process ensures that only the correct type of storage is presented to the continuous availability (CA1S or CA2S) vSphere clusters and no misplacement of virtual machines intended for LUN based inter-site protection occurs.
Continuous availability functionality may be enabled or disabled globally using the ca_enabled global option. Changing the value of this option may be done via the vRealize Automation catalog item entitled Global Options Maintenance.
VPLEX Witness is an optional component deployed in customer environments where the regular preference rule sets are insufficient to provide seamless zero or near-zero RTO storage availability if site disasters or VPLEX cluster and inter-cluster failures occur.
Without VPLEX Witness, all distributed volumes rely on configured rule sets to identify the preferred cluster if a cluster partition or cluster/site failure occurs. However, if the preferred cluster fails (because of a disaster event), VPLEX is unable to automatically enable the surviving cluster to continue I/O operations to the affected distributed volumes. VPLEX Witness is designed to overcome this.
The VPLEX Witness server is deployed as a virtual appliance running on a customer’s vSphere ESXi host that is deployed in a failure domain separate from both of the VPLEX clusters. The third fault domain must have power and IP isolation from both the Hardware Island /Site A and Hardware Island /Site B fault domains, which host the VPLEX Metro Clusters.
This eliminates the possibility of a single fault affecting both the cluster and VPLEX Witness. VPLEX Witness connects to both VPLEX clusters over the management IP network. By reconciling its own observations with the information reported periodically by the clusters, VPLEX Witness enables the clusters to distinguish between inter-cluster network partition failures and cluster failures and automatically resume I/O operations in these situations.
Storage provisioning
VPLEX Witness

Chapter 6: Storage Considerations
115 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 57 shows an example of a high-level deployment of VPLEX Witness and how it can augment an existing static preference solution. The VPLEX Witness server resides in a fault domain separate from the VPLEX clusters on Site A and Site B.
Figure 57. High-level deployment of EMC VPLEX Witness
VMware classifies the stretched VPLEX Metro cluster configuration with VPLEX into the following categories:
Uniform host access configuration with VPLEX host cross-connect: vSphere ESXi hosts in a distributed vSphere cluster have a connection to the local VPLEX system and paths to the remote VPLEX system. The remote paths presented to the vSphere ESXi hosts are stretched across distance.
Non-uniform host access configuration without VPLEX host cross-connect: vSphere ESXi hosts in a distributed vSphere cluster have a connection only to the local VPLEX system.
Use the following guidelines to help you decide which topology suits your environment:
Uniform (cross-connect) is typically used where:
Inter-site latency is less than 5 ms.
Stretched SAN configurations are possible.
Non-Uniform (without cross-connect) is typically used where:
Inter-site latency is between 5 ms and 10 ms.
Stretched SAN configurations are not possible.
VPLEX topologies
Deciding on VPLEX topology

Chapter 6: Storage Considerations
116 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
EMC GeoSynchrony® supports the concept of a VPLEX Metro cluster with cross-connect. This configuration provides a perfect platform for a uniform vSphere stretched-cluster deployment. VPLEX with host cross-connect is designed for deployment in a metropolitan-type topology with latency that does not exceed 5 ms round-trip time (RTT).
vSphere ESXi hosts can access a distributed volume on the local VPLEX cluster and on the remote cluster if a failure occurs. When this configuration is used with VPLEX Witness, vSphere ESXi hosts are able to survive through multiple types of failure scenarios. For example, if a VPLEX cluster or back-end storage array failure occurs, the vSphere ESXi hosts can still access the second VPLEX cluster with no disruption in service.
In the unlikely event that the preferred site fails, VPLEX Witness intervenes and ensures that access to the surviving cluster is automatically maintained. In this case, vSphere HA automatically restarts all affected virtual machines.
Figure 58 shows that all ESXi hosts are connected to the VPLEX clusters at both sites. This can be achieved in a number of ways:
Merge switch fabrics by using Inter-Switch Link (ISL) technology used to connect local and remote SANs.
Connect directly to the remote data center fabric without merging the SANs.
Figure 58. Deployment model with VPLEX host cross-connect
This type of deployment is designed to provide the highest possible availability for an Enterprise Hybrid Cloud environment. It can withstand multiple failure scenarios including switch, VPLEX, and back-end storage at a single site with no disruption in service.
For reasons of performance and availability, Enterprise Hybrid Cloud recommends that separate host bus adapters be used for connecting to local and remote switch fabrics.
Uniform host access configuration with VPLEX host cross-connect

Chapter 6: Storage Considerations
117 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: VPLEX host cross-connect is configured at the host layer only and does not imply any cross connection of the back-end storage. The back-end storage arrays remain locally connected to their respective VPLEX clusters.
From the host perspective, in the uniform deployment model with VPLEX host cross-connect, the vSphere ESXi hosts are zoned to both the local and the remote VPLEX clusters. Figure 59 displays the VPLEX storage views for a host named DRM-ESXi088, physically located in Site A of our environment.
Here, the initiators for the host are registered and added to both storage views with the distributed device being presented from both VPLEX clusters.
Figure 59. VPLEX storage views with host cross-connect
This configuration is transparent to the vSphere ESXi host. The remote distributed volume is presented as an additional set of paths.
Figure 60 shows the eight available paths that are presented to host DRM-ESXi088, for access to the VPLEX distributed volume hosting the datastore named CC-Shared-M3. The serial numbers of the arrays are different because four of the paths are presented from the first VPLEX cluster and the remaining four are presented from the second.

Chapter 6: Storage Considerations
118 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 60. Datastore paths in a VPLEX with host cross-connect configuration
PowerPath/VE autostandby mode
Neither the host nor the native multipath software can by themselves distinguish between local and remote paths. This poses a potential impact on performance if remote paths are used for I/O in normal operations because of the cross-connect latency penalty.
PowerPath/VE provides the concept of autostandby mode, which automatically identifies all remote paths and sets them to standby (asb:prox is the proximity-based autostandby algorithm). This feature ensures that only the most efficient paths are used at any given time.
PowerPath/VE groups paths internally by VPLEX cluster. The VPLEX cluster with the lowest minimum path latency is designated as the local/preferred VPLEX cluster, while the other VPLEX cluster within the VPLEX Metro system is designated as the remote/non-preferred cluster.
A path associated with the local/preferred VPLEX cluster is put in active mode, while a path associated with the remote/non-preferred VPLEX cluster is put in autostandby mode. This forces all I/O during normal operations to be directed towards the local VPLEX cluster. If a failure occurs where the paths to the local VPLEX cluster are lost, PowerPath/VE activates the standby paths and the host remains up and running on the local site, while accessing storage on the remote site.

Chapter 6: Storage Considerations
119 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The non-uniform host configuration can be used for an Enterprise Hybrid Cloud deployment if greater distances are required. The supported latency of this configuration requires that the round-trip time is within 10 ms to comply with VMware HA requirements. Without the cross-connect deployment, vSphere ESXi hosts at each site have connectivity to only that site’s VPLEX cluster.
Figure 61 shows that hosts located at each site have connections only to their respective VPLEX cluster. The VPLEX clusters have a link between them to support the VPLEX Metro configuration, and the VPLEX Witness is located in a third failure domain.
Figure 61. VPLEX architecture without VPLEX cross-connect
The major benefit of this deployment option is that greater distances can be achieved to protect the infrastructure. With the EMC VPLEX AccessAnywhereTM feature, the non-uniform deployment offers the business another highly resilient option that can withstand various types of failures including front-end and back-end single path failure, single switch failure, and single back-end array failure.
Figure 62 shows the storage views from VPLEX cluster 1 and cluster 2. In the example non-uniform deployment, hosts DRM-ESXi077 and DRM-ESXi099 represent hosts located in different data centers. They are visible in their site-specific VPLEX cluster’s storage view. With AccessAnywhere, the hosts have simultaneous write access to the same distributed device, but only via the VPLEX cluster on the same site.
Non-uniform host access configuration without VPLEX cross-connect

Chapter 6: Storage Considerations
120 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 62. VPLEX Storage views without VPLEX cross-connect
Figure 63 shows the path details for one of the hosts in a stretched cluster that has access to the datastores hosted on the VPLEX distributed device. The World Wide Name (WWN) on the Target column shows that all paths to that distributed device belong to the same VPLEX cluster. PowerPath/VE has also been installed on all of the hosts in the cluster, and it has automatically set the VPLEX volume to the adaptive failover mode. The autostandby feature is not used in this case because all the paths to the device are local.
Figure 63. vSphere datastore storage paths without VPLEX cross-connect
With vSphere HA, the virtual machines are also protected against major outages, such as network partitioning of the VPLEX WAN link, or an entire site failure. To prevent any unnecessary down time, we recommend that the virtual machines reside on the site that would win ownership of the VPLEX distributed volume if such a partitioning occurs.

Chapter 6: Storage Considerations
121 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
VPLEX uses consistency groups to maintain common settings on multiple LUNs. To create a VPLEX consistency group using ViPR, a ViPR consistency group must be specified when creating a new volume. ViPR consistency groups are used to control multi-LUN consistent snapshots and have a number of important rules associated with them when creating VPLEX distributed devices:
All volumes in any given ViPR consistency group must contain only LUNs from the same physical array. As a result of these considerations, Enterprise Hybrid Cloud STaaS workflows create a new consistency group per physical array, per vSphere cluster per site.
All VPLEX distributed devices in a ViPR consistency group must have source and target backing LUNS from the same pair of arrays.
As a result of these two rules, it is a requirement of Enterprise Hybrid Cloud that an individual ViPR virtual pool is created for every physical array that provides physical pools for use in a VPLEX distributed configuration.
Enterprise Hybrid Cloud STaaS workflows use the name of the ViPR virtual pool chosen as part of the naming for the vRealize SRP that the new datastore is added to. The Virtual Pool Collapser (VPC) function of Enterprise Hybrid Cloud collapses the LUNs from multiple virtual pools into a single SRP.
The VPC function can be used where multiple physical arrays provide physical storage pools of the same configuration or service level to VPLEX, but through different virtual pools and where required, to ensure that all LUNS provisioned across those physical pools are collapsed into the same SRP.
VPC can be enabled or disabled at a global Enterprise Hybrid Cloud level using the ehc_vpc_disabled global option. Changing the value of this option can be done with the vRealize Automation catalog item entitled Global Options Maintenance.
When ehc_vpc_disabled is set to False, Enterprise Hybrid Cloud STaaS workflows examine the naming convention of the virtual pool selected to determine which SRP it should add the datastore to. If the virtual pool includes the string ‘_VPC-’, then Enterprise Hybrid Cloud knows that it should invoke VPC logic.
Figure 64 shows an example of VPC in use. In this scenario, the administrator has enabled the VPC function and created two ViPR virtual pools:
GOLD_VPC-000001, which has physical pools from Array 1
GOLD_VPC-000002, which has physical pools from Array 2
When determining how to construct the SRP name to be used, the VPC function will only use that part of the virtual pool name that exists before ‘_VPC-’. This example results in the term ‘GOLD’, which then contributes to the common SRP name of: SITEA_GOLD_CA_Enabled. This makes it possible to conform to the rules of ViPR consistency groups, as well as providing a single SRP for all datastores of the same type, which maintains abstraction and balanced datastore usage at the vRealize layer.
ViPR and VPLEX consistency groups interaction
Virtual Pool Collapser function
Virtual Pool Collapser example

Chapter 6: Storage Considerations
122 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 64. Virtual Pool Collapser example
In the example shown in Figure 64, all storage is configured to win on a single site (Site A). To enable true active/active vSphere Metro storage clusters, additional pools should be configured in the opposite direction.
Disaster recovery (Site Recovery Manager) storage considerations
This SRM-based DR protection service for Enterprise Hybrid Cloud incorporates storage replication using RecoverPoint, storage provisioning using ViPR, and integration with SRM to support DR services for applications and virtual machines deployed in the hybrid cloud. SRM natively integrates with vCenter and NSX to support DR, planned migration, and recovery plan testing.
Disaster recovery (Site Recovery Manager) workloads
With DR SRM protection, two ESXi clusters reside in different geographical location and are logically associated with two different hardware islands. RecoverPoint replicated storage is created and presented to the two clusters, creating storage that is write-enabled on one side or the other at any given time.
DR2S clusters are created using hosts from both hardware islands to create a DR cluster pair. Workloads placed on these clusters are automatically protected by SRM as a result of Enterprise Hybrid Cloud custom lifecycle operations.
Applicability

Chapter 6: Storage Considerations
123 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Storage tier design for SRM-based DR workloads should follow the same user and application driven requirements as described for single site workloads.
The only difference is in the supported underlying storage arrays that may be used to compose the physical and virtual pools used by ViPR. With SRM-based DR protection, all virtual pools must be RecoverPoint-protected virtual pools. Those pools may be backed by the following storage arrays:
EMC VMAX
EMC VNX
EMC XtremIO
EMC VMAX3™ (must reside behind an EMC VPLEX unit)
There must be at least one virtual array for each site. By configuring the virtual arrays in this way, ViPR can discover the RecoverPoint and storage topology.
Enterprise Hybrid Cloud ensures this is the case by mandating that DR DR2S cluster pair members must be from different hardware islands associated with different sites, and that each hardware island must have its own set of ViPR virtual arrays.
When you specify RecoverPoint as the protection option for a virtual pool, the ViPR storage provisioning services create the source and target volumes and the source and target journal volumes, as shown in Figure 65.
Figure 65. ViPR/EMC RecoverPoint protected virtual pool
Each SRM DR-protected/recovery cluster pair has storage that replicates (under normal conditions) in a given direction, for example, from Site A to Site B. To allow active/active site configuration, additional SRM DR cluster pairs should be configured whose storage replicates in the opposite direction. You must create two sets of datastores – one set that will replicate from Site A and another set that will replicate from Site B. To enable this, you need to configure an environment similar to Figure 65 for Site A, and the inverse of it for Site B (where the protected source pool is Site B, and local target pool is on Site A).
Storage tier design
ViPR virtual arrays
ViPR virtual pools

Chapter 6: Storage Considerations
124 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Storage consumption operates in the same way as it does for single-site protection, that is, with vRealize SRPs and blueprints.
In an SRM-based disaster recovery context, Enterprise Hybrid Cloud automatically creates storage reservation polices in vRealize Automation that convey to the end user the site and optionally the hardware island that the storage will normally reside on.
This storage choice by the user is then used by Enterprise Hybrid Cloud vRealize Automation lifecycle operations to ensure backup infrastructure affinity for the workload that the user is deploying.
Storage is provisioned to the Workload Pods in the environment using the Provision Cloud Storage catalog item that can provision RP protected volumes backed by VMAX, VNX, or XtremIO or VMAX3 (behind a VPLEX) to DR2S workload clusters.
Note: EMC recommends that you follow the best practice guidelines when deploying any of the supported platform technologies. Enterprise Hybrid Cloud does not require any variation from these best practices.
The workflow interacts with both ViPR and vRealize Automation to create the storage, presents it to the chosen vSphere cluster, and adds the new volume to the relevant vRealize SRP.
vSphere clusters are made eligible by on-boarding them through the Onboard DR Cluster option of the Enterprise Hybrid Cloud Cluster Maintenance vRealize Automation catalog item.
This process ensures that only the correct type of storage is presented to the disaster recovery (DR2S) vSphere clusters and no misplacement of virtual machines intended for LUN based inter-site protection occurs.
SRM-based DR functionality may be enabled or disabled globally using the dr_enabled global option. Changing the value of this option may be done via the vRealize Automation catalog item entitled Global Options Maintenance.
Every RecoverPoint-protected LUN requires access to a journal LUN to maintain the history of disk writes to the LUN. The performance of the journal LUN is critical in the overall performance of the system attached to the RecoverPoint-protected LUN and therefore its performance capability should be in line with the expected performance needs of that system.
By default, ViPR uses the same virtual pool for both the target and the journal LUN for a RecoverPoint copy, but it does allow you to specify a separate or dedicated pool. In both cases, the virtual pool and its supporting physical pools should be sized to provide adequate performance.
Storage consumption
Storage provisioning
RecoverPoint journal considerations

Chapter 7: Data Protection (Backup-as-a-Service)
125 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 7 Data Protection (Backup-as-a-Service)
This chapter presents the following topics:
Overview ................................................................................................................ 126
Concepts ................................................................................................................ 127

Chapter 7: Data Protection (Backup-as-a-Service)
126 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Overview
This chapter discusses the considerations for implementing data protection, also known as backup as a service (BaaS) in the context of Enterprise Hybrid Cloud.
Backup and recovery of a hybrid cloud is a complicated undertaking in which many factors must be considered, including:
Backup type and frequency
Impact and interaction with replication
Recoverability methods and requirements
Retention periods
Automation workflows
Interface methods (workflows, APIs, GUI, CLI, scripts, and so on)
Implementation that supports multiple inter and intra-site protection services such as continuous availability or disaster recovery in an appropriate way
VMware vRealize Orchestrator, which is central to all of the customizations and operations used in this solution, is used as the engine to support operations across several EMC and VMware products, including:
VMware vRealize Automation
VMware vCenter
EMC Avamar and EMC Data Protection Advisor™
This solution uses Avamar as the technology to protect your datasets. Using Avamar, this backup solution includes the following characteristics:
Abstracts and simplifies backup and restore operations for cloud users
Uses VMware storage APIs for data protection, which provides changed block tracking for faster backup and restore operations
Provides full image backups for running virtual machines
Eliminates the need to manage backup agents for each virtual machine in most cases
Minimizes network traffic by de-duplicating and compressing data
Note: Enterprise Hybrid Cloud recommends that you engage an Avamar product specialist to design, size, and implement a solution specific to your environment and business needs.

Chapter 7: Data Protection (Backup-as-a-Service)
127 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Concepts
Enterprise Hybrid Cloud backup configurations add scalable backup by adding the ability to configure multiple Avamar instances (also known as grids) per site across multiple sites. Enterprise Hybrid Cloud BaaS workflows automatically distribute the workload in a round-robin way across the available Avamar instances, and provide a catalog item to enable additional Avamar grids and or multi-site backup relationships to be added to the configuration.
Additional Avamar grids, or new relationships between existing Avamar grids can be added to increase the scalability. By using Avamar Site Relationships and Avamar Replication Relationships, this new capacity is transparently discovered and used as new workloads are deployed. Both concepts are described in detail in Avamar Site Relationships and Avamar Replication Relationships,
The configuration of the Avamar instances is stored by Enterprise Hybrid Cloud workflows for later reference when reconfiguring or adding instances.
Avamar grids are the physical targets for Enterprise Hybrid Cloud backup data. They may be optionally backed by Data Domain infrastructure for even greater efficiencies. Avamar grids are introduced into the Enterprise Hybrid Cloud object model once the data protection packages have been installed and initialized.
Once initialized, Day 2 catalog items are made available through vRealize Automation that can be used to on-board the grids and their details. Part of the on-boarding process assigns the grid to one of the sites that exist in the model. That information is subsequently used to ensure that user is guided to choose from only the applicable grids when setting up ARRs.
An Avamar Site Relationship (ASR) is a relationship between sites for backup purposes. Each ASR maps to a single backup type and this defines the structure of the backup policies that are applied to any workloads that reside on vSphere clusters mapped to the ASR.
The following rules apply to an ASR:
Each ASR must correspond to a single backup type, as shown in Backup types.
Each ASR may have between one or two sites associated with it.
The sites and type of an ASR become the “rule-set” for all Avamar Replication Relationships (ARRs) that are added to it.
ASRs may contain multiple ARRs.
On-boarded Enterprise Hybrid Cloud clusters may be associated with a single ASR. Therefore, all workloads on a specified cluster will follow the backup policy structure of the mapped ASR.
ASRs provide an abstraction between the vSphere cluster and the ARRs that are children of the mapped ASR. This allows additional ARRs to be added and used without altering the cluster mapping.
Scalable backup architecture
Avamar grids
Avamar Site Relationships

Chapter 7: Data Protection (Backup-as-a-Service)
128 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
During provisioning of backup services to an individual workload, round robin algorithms will determine ARR the workload will use.
Multiple ASRs of the same type can exist at the same time.
There are several use cases for using multiple ASRs of the same time in the same environment:
There could be a 1C1VC ASR in each of several sites.
There could be multiple 2C1VC ASRs if multiple CA relationships exist in the Enterprise Hybrid Cloud environment.
There could be multiple 2C2VC ASRs if multiple DR relationships exist in the Enterprise Hybrid Cloud environment.
Multiple ASRs with the same set of sites could also be used to separate clusters onto dedicated sets of Avamar infrastructure.
Note: In the previous version of Enterprise Hybrid Cloud, Avamar grids were paired, resulting in a single backup type being available for any given Avamar grid. ASRs and ARRs break this dependency and allow multiple backup types to co-exist on the same physical grid infrastructure.
An Avamar Replication Relationship (ARR) is a relationship between up to two Avamar grids.
When creating an ARR, you must assign it to a parent ASR. This ensures that the grids available for selection are only the ones defined in the ASR itself. When an ARR is created, and the ASR type it is added to implies that multi-site protection backup policies are required, this automatically configures replication destinations objects in Avamar between the chosen grids.
Avamar grids may participate in multiple ARRs. In this way, the same grid may:
Provide multiple protection levels between the same set of sites by being a member of multiple ARRs whose parent ASR has the same set of sites but a different ASR type.
Provide protection between different sets of sites by being a member of multiple ARRs whose parent ASRs have different combinations of sites.
Both of the above at the same time.
The following rules are associated with an ARR:
An ARR must be associated with an ASR.
When creating an ARR, it inherits its type based on the parent ASR to which it is associated.
Enterprise Hybrid Cloud workflows will only present Avamar grids from the relevant sites for inclusion in the ARR based on the choice of ASR.
As ARRs are added to an ASR, vSphere clusters associated with that ASR will automatically pick up new ARRs and use them without the cluster mapping needing to be modified.
Avamar Replication Relationships

Chapter 7: Data Protection (Backup-as-a-Service)
129 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Avamar image-level backups work by mounting snapshots of VMDKs to Avamar proxy virtual machines and then backing up the data to the Avamar instance that the Avamar proxy is registered with.
In a fully deployed Enterprise Hybrid Cloud with up to 10,000 user virtual machines per vCenter and hundreds of vSphere clusters, this could lead to Avamar proxy sprawl if not properly configured and controlled.
To do this, Enterprise Hybrid Cloud associates vSphere clusters to a subset of ASRs (of which there may be many). In this way, different clusters may be mapped to different ASRs to enable backup to distinct sets of Avamar infrastructure.
This means that a reduced number of Avamar proxy virtual machines are required to service the cloud. Associations between a vSphere cluster and an ASR are made via the Enterprise Hybrid Cloud Cluster Maintenance vRealize Automation catalog item.
Note: When a cluster is mapped to a 2C2VC or MC2VC ASR, its partner cluster is automatically associated with the same ASR to ensure full access to all backup images taken before, during or after failover or virtual machine workloads.
Backup types are the rulesets that are automatically applied to Enterprise Hybrid Cloud workloads based on the type of cluster they reside on and the protection options that are available within the environment
One-Copy One-vCenter (1C1VC)
The 1C1VC backup model is designed to back up workloads that are bound to a single site and may never move. As a result, the backup strategy that is applied to these workloads has a single copy per backup image (that is, non-replicated) on a single Avamar grid. The same grid is responsible for all scheduled and on-demand backups as well as restores for that workload.
Multiple Avamar grids may be deployed in the environment to enable scale, and backup will be automatically balanced across the number of grids deployed. Figure 66 shows an example of the folders and backup groups involved in a 1C1VC backup type.
ASRs to vSphere cluster association
Backup types

Chapter 7: Data Protection (Backup-as-a-Service)
130 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 66. 1C1VC folders and backup groups
Two-Copy One-vCenter (2C1VC)
The 2C1VC backup model is designed to back up dual-site CA workloads that may move between sites, but remain in the same vCenter endpoint regardless of site they are operating on. As a result, the backup strategy that is applied to these workloads has two copies per backup image replicated from the grid that took the backup to the partner grid in the ARR that corresponds with the vCenter folder the workload resided in. The same grids are responsible for all scheduled and on-demand backups as well as restores for that workload.
In this configuration, two sets of vCenter folders are created (one per site) in the same vCenter and each member of the ARR has primary ownership of the set of folders local to its own site with ability to take over ownership of the set corresponding to the other site. When workloads move sites, the same Avamar grid will continue to backup those workloads until the backup policies on the Avamar grid are “toggled” so that the other member of the ARR will take over monitoring of the vCenter folder the workloads reside in.
Multiple Avamar grids may be deployed in the environment to enable scale and backup is automatically balanced across the number of grids deployed. Figure 67 shows an example of the folders, backup groups, and replication groups involved in a 2C1VC backup type.

Chapter 7: Data Protection (Backup-as-a-Service)
131 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 67. 2C1VC folders, backup groups, and replication groups
Two-Copy Two-vCenter (2C2VC)
The 2C2VC backup model is designed to back up DR (SRM) workloads that may move between sites and that change vCenter endpoint when they do so. As a result, the backup strategy that is applied to these workloads has two copies per backup image replicated from the grid that took the backup to the partner grid in the ARR that corresponds with the vCenter folder the workload resided in. The same grids will be responsible for all scheduled and on-demand backups as well as restores for that workload.
In this configuration, two sets of vCenter folders are created (one per site) with one set residing in each vCenter endpoint. Each member of the ARR has sole ownership of the set of folders local to its own site or vCenter. When workloads move sites, the Avamar grid on the target site will automatically commence backing up those workloads when they appear in the vCenter folders that it is monitoring.
Multiple Avamar grids may be deployed in the environment to enable scaling and backup is automatically balanced across the number of grids deployed. Figure 68 shows an example of the folders, backup groups, and replication groups involved in a 2C2VC backup type.

Chapter 7: Data Protection (Backup-as-a-Service)
132 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 68. 2C2VC folders, folder mappings, backup groups, and replication groups
Mixed-Copy Two-vCenter (MC2VC)
The MC2VC backup model is designed to back up disaster recovery (RecoverPoint for Virtual Machine) workloads. This is slightly different to the other models in that two different types of workloads may coexist on the same tenant compute cluster, and those workloads may change type from single-site to RecoverPoint for Virtual Machines-based DR protection and back again at any time.
As the cluster itself is the object mapped to the ASR, the MC2VC model allows for two types of protection based on whether or not the workload is protected by RecoverPoint for Virtual Machines.
Single site workloads reside in folders designated for local protection only. Therefore, they are backed up by a single grid and the backup image is not replicated, similar in concept to the 1C1VC model.
RecoverPoint for Virtual Machines DR workloads reside in folders designated for dual-site protection. Therefore, they are backed up by a single grid and the backup image is replicated, similar in concept to the 2C2VC model.
When a workload changes RecoverPoint for Virtual Machines DR protection status, it is moved from one vCenter folder to another, thereby self-adjusting its backup strategy to stay in line with its overall protection status, while maintaining all of the previous backup images that were taken of that workload.

Chapter 7: Data Protection (Backup-as-a-Service)
133 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
The same grids are responsible for all scheduled and on-demand backups as well as restores for that workload.
In this configuration, four sets of vCenter folders are created (two per site) with two sets residing in each vCenter endpoint. Each member of the ARR has sole ownership of the set of folders local to its own site / vCenter. When workloads move sites, the Avamar grid on the target site automatically commences backing up those workloads when they appear in the vCenter folders that it is monitoring.
Multiple Avamar grids may be deployed in the environment to enable scale and backup is automatically balanced across the number of grids deployed. Figure 69 shows an example of the folders, backup groups and replication groups involved in a MC2VC backup type.
Figure 69. MC2VC folders, folder mappings, backup groups and replication groups

Chapter 7: Data Protection (Backup-as-a-Service)
134 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Mapping Enterprise Hybrid Cloud cluster types to backup types
Table 11 shows how individual cluster types map to backup types.
Table 11. Cluster type to backup type mapping
Cluster type Backup type
LC1S 1C1VC (without RecoverPoint for Virtual Machines)
MC2VC (with RecoverPoint for Virtual Machines)
CA1S 1C1VC
CA2S 2C1VC
DR2S 2C2VC
Figure 70 shows an example of two types of clusters mapped to different ASRs, showing how those different ASRs can use the ARR concept to load balance multiple different backup types across the same physical Avamar grids.
Figure 70. Cluster to ASR to ARR mappings
Backup service levels appear to the user as the available options when specifying the tier of backup that a virtual machine workload will use.
A backup service level includes the following attributes:
Cadence: At what frequency a backup should run (daily, weekly, monthly, or custom)
Backup Schedule: Time of day/window that the backup should execute
Replication Schedule: Time of day when backup images should be replicated to another site (where appropriate)
Retention: How long the backup image should be retained for
Example cluster to ASR mapping
Backup service levels

Chapter 7: Data Protection (Backup-as-a-Service)
135 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
When a backup service level is created using the Backup Service Level Maintenance vRealize Automation catalog item, it creates an associated set of folders in the cloud vCenter endpoints that have been added to the Enterprise Hybrid Cloud object model.
When doing this, the Enterprise Hybrid Cloud workflows will cycle through all available ASRs and find vCenter endpoints that match the site relationships. They then cycle through the associated ARRs so that new vCenters folders are created appropriately.
The number of folders created depends on how many ARRs are present, and these folders become part of the mechanism for distributing the backup load. The format of the folder name varies slightly depending on the ASR/ARR type, as shown in Table 12.
Table 12. vCenter folder name structure by backup type
Backup type Folders Folder name structure
1C1VC 1 BackupServiceLevelName-ARRName-Site, for example, Gold-ARR00001-NewYork
2C1VC 2 BackupServiceLevelName-ARRName-Site for each site, for example:
Gold-ARR00002-NewYork
Gold-ARR00002-Boston
2C2VC 4 BackupServiceLevelName-ARRName-Site plus BackupServiceLevelName-ARRName-Site_PH for each site, for example,:
Gold-ARR00003-NewYork
Gold-ARR00003-NewYork_PH
Gold-ARR00001-Boston
Gold-ARR00001-Boston_PH
MC2VC 6 BackupServiceLevelName-ARRName-Site-Protected plus BackupServiceLevelName-ARRName-Site-Protected_PH plus BackupServiceLevelName-ARRName-Site-Local for each site, for example:
Gold-ARR00003-NewYork-Protected
Gold-ARR00003-NewYork-Protected _PH
Gold-ARR00003-NewYork-Local
Gold-ARR00001-Boston-Protected
Gold-ARR00001-Boston-Protected _PH
Gold-ARR00001-Boston-Local
VMware vCenter folder structure and backup service level relationship

Chapter 7: Data Protection (Backup-as-a-Service)
136 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
When Enterprise Hybrid Cloud custom lifecycle operations need to enable a workload for backup, they:
1. Check the cluster the workload resides on.
2. Check the cluster to ASR mapping.
3. Enumerate the ARRs assigned to that ASR and determine which of the grids local to that workload has the least current load.
4. Look up the appropriate vCenter folder for the chosen grid.
5. Move the workload to the correct vCenter folder.
Avamar proxies virtual machines must be deployed to each Enterprise Hybrid Cloud-enabled cluster to mount VMDKs directly from the datastores on that cluster. Each cluster type has its own proxy requirements, as described below.
LC1S clusters without RecoverPoint for Virtual Machines protection
To determine the required number of Avamar proxy virtual machines for an LC1S clusters, use the following logic:
1. Identify the 1C1VC ASR to which the cluster is mapped.
2. Determine the number of ARRs associated with the cluster’s ASR.
3. For each ARR discovered:
Deploy a minimum of one proxy virtual machine, registered to the Avamar grid that is a member of the 1C1VC ARR.
Two proxies are recommended for high availability, if there is scope within the overall number of proxies that can be deployed to the environment. Ideally, this number should be approximately 60 to 80 proxies per vCenter.
Figure 71 shows an example of how this might look when deployed.
Avamar proxy server configuration

Chapter 7: Data Protection (Backup-as-a-Service)
137 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 71. LC1S without RecoverPoint for Virtual Machines proxy example
LC1S clusters with RecoverPoint for Virtual Machines protection
To determine the required number of Avamar proxy virtual machines for a 1C1S cluster, use the following logic:
1. Identify the MC2VC ASR to which the cluster is mapped.
2. Determine the number of ARRs associated with the cluster’s ASR.
3. For each ARR discovered:
Deploy a minimum of two proxy virtual machines.
One proxy should be on the LC1S cluster on the first site and registered to the Avamar grid member of the MC2VC ARR that is on the same site.
The second proxy should be on the LC1S cluster’s partner cluster on the second site, and be registered to the Avamar grid member of the MC2VC ARR that is on the same site as the partner cluster.
If there is scope within the overall number of proxies that can be deployed to the environment, four proxies are recommended for high availability. Ideally, this number should be approximately 60 to 80 proxies per vCenter.
Figure 72 shows an example of how this might look when deployed.

Chapter 7: Data Protection (Backup-as-a-Service)
138 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 72. LC1S with RecoverPoint for Virtual Machines proxy example
Note: In this configuration, if a failure of a single Avamar instance occurs without the failure of the vCenter infrastructure on the same site, then the second member of the ARR will not automatically assume responsibility to backup virtual machines. To further protect against this scenario, additional resilience can be added on each site by using an Avamar Redundant Array of Independent Nodes (RAIN) grid. Alternatively, workloads may be moved to the site that is fully operational to continue availing of backup services.
CA1S clusters
To determine the required number of Avamar proxy virtual machines for a CA1S cluster, use the following logic:
1. Identify the 1C1VC ASR to which the cluster is mapped.
2. Determine the number of ARRs associated with the cluster’s ASR.
3. For each ARR discovered:
Deploy a minimum of one proxy virtual machine, registered to the Avamar grid that is a member of the 1C1VC ARR.
If there is scope within the overall number of proxies that can be deployed to the environment, two proxies are recommended for high availability. Ideally, this number should be approximately 60 to 80 proxies per vCenter.

Chapter 7: Data Protection (Backup-as-a-Service)
139 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: Which hardware island these proxies normally reside on the CA1S cluster is of no significant importance to the backup solution, as it is assumed that latency from either side of the half of the CA1S cluster to the Avamar infrastructure is the same, because both hardware islands are on the same site.
Figure 73 shows an example of how this might look when deployed.
Figure 73. CA1S proxy example
CA2S clusters
To determine the required number of Avamar proxy virtual machines for a CA2S cluster, use the following logic:
1. Identify the 2C1VC ASR to which the cluster is mapped.
2. Determine the number of ARRs associated with the clusters ASR.
3. For each ARR discovered:
Deploy a minimum of two proxy virtual machines. One proxy should be registered to each Avamar grid that is a member of the 2C1VC ARR.

Chapter 7: Data Protection (Backup-as-a-Service)
140 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
If there is scope within the overall number of proxies that can be deployed to the environment, four proxies are recommended for high availability. Ideally, this number should be approximately 60 to 80 proxies per vCenter.
Proxies should be bound to hosts in the cluster that are physically on the same site as the Avamar grid to which they are registered by:
Adding the proxy virtual machines to DRS virtual machine affinity groups created on a per site basis.
Adding a DRS virtual machine to host rule that sets those virtual machines to must run on the DRS host group created by the CA2S onboarding process.
This ensures no unnecessary cross-WAN backups occur, as Avamar can use vStorage APIs for data protection to add VMDKs (from the local leg of the VPLEX volume) to proxy virtual machines bound to physical hosts on the same site as the Avamar grid.
Figure 74 shows an example of how this might look when deployed.
Figure 74. CA2S proxy example

Chapter 7: Data Protection (Backup-as-a-Service)
141 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
DR2S clusters
To determine the required number of Avamar proxy virtual machines for a DR2S cluster, use the following logic:
1. Identify the 2C2VC ASR to which the cluster is mapped.
2. Determine the number of ARRs associated with the cluster’s ASR.
3. For each ARR discovered:
Deploy a minimum of two proxy virtual machines.
One proxy should be on the DR2S cluster on the first site and registered to the Avamar grid member of the 2C2VC ARR that is on the same site.
The second proxy should be on the DR2S cluster’s partner cluster on the second site, and be registered to the Avamar grid member of the 2C2VC ARR that is on the same site as the partner cluster.
If there is scope within the overall number of proxies that can be deployed to the environment, four proxies are recommended for high availability. Ideally, this number should be approximately 60 to 80 proxies per vCenter.
Figure 72 shows an example of how this might look when deployed.
Figure 75. DR2S with RecoverPoint for Virtual Machines proxy example

Chapter 7: Data Protection (Backup-as-a-Service)
142 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Note: In this configuration, if a failure of a single Avamar instance occurs without the failure of the vCenter infrastructure on the same site, then the second member of the ARR will not automatically assume responsibility to back up virtual machines. To further protect against this scenario, additional resilience can be added on each site by using an Avamar RAIN grid. Alternatively, workloads may be moved to the site that is fully operational to continue availing of backup services.
Determining that a backup target, in this case an Avamar instance, has reached capacity can be based on a number of metrics of the virtual machines it is responsible for protecting, including:
The number of virtual machines assigned to the instance
The total capacity of those virtual machines
The rate of change of the data of those virtual machines
The effective deduplication ratio that can be achieved while backing up those virtual machines
The available network bandwidth and backup window size
Because using these metrics can be subjective, Enterprise Hybrid Cloud enables an administrator to preclude an Avamar instance (and therefore any ARRs it participates in) from being assigned further workload by setting a binary Admin Full flag set via the Avamar Grid Maintenance vRealize Automation catalog item.
When a virtual machine is enabled for data protection via Enterprise Hybrid Cloud BaaS workflows, the available ARRs are assessed to determine the most suitable target. If an ARR has had the Admin Full flag set, then that relationship is excluded from the selection algorithm but continues to back up its existing workloads through on-demand or scheduled backups.
If workloads are retired and an Avamar grid is determined to have free capacity, the Admin Full flag can be toggled back, including it in the selection algorithm again.
Policy-based replication provides granular control of the replication process. With policy-based replication, you create replication groups in Avamar Administrator to define the following replication settings:
Members of the replication group, which are either entire domains or individual clients
Priority for the order in which backup data replicates
Types of backups to replicate based on the retention setting for the backup or the date on which the backup occurred
Maximum number of backups to replicate for each client
Destination server for the replicated backups
Schedule for replication
Retention period of replicated backups on the destination server
Avamar instance full
Policy-based replication

Chapter 7: Data Protection (Backup-as-a-Service)
143 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Enterprise Hybrid Cloud backup types that involve replication between Avamar grids automatically create a replication group associated with each backup policy and configure it based on the replication schedule associated with each backup service level.
If Data Domain is used as a backup target, Avamar is responsible for replication of Avamar data from the source Data Domain system to the destination Data Domain system. As a result, all configuration and monitoring of replication is done via the Avamar server. This includes the schedule on which Avamar data is replicated between Data Domain units.
You cannot schedule replication of data on the Data Domain system separately from the replication of data on the Avamar server. There is no way to track replication by using Data Domain administration tools.
Note: Do not configure Data Domain replication to replicate data to another Data Domain system that is configured for use with Avamar. When you use Data Domain replication, the replicated data does not refer to the associated remote Avamar server.
Replication control

Chapter 8: Ecosystem Interactions
144 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 8 Ecosystem Interactions
This chapter presents the following topics:
Enterprise Hybrid Cloud ecosystems ...................................................................... 145

Chapter 8: Ecosystem Interactions
145 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Enterprise Hybrid Cloud ecosystems
Figure 76 shows how the concepts in this guide combine under the single-site protection service.
Figure 76. Single-site protection ecosystem
Single-site ecosystem

Chapter 8: Ecosystem Interactions
146 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 77 shows how the concepts in this guide combine under the Continuous Availability (Dual-site) protection service.
Figure 77. Continuous Availability (Dual-site) protection ecosystem
Continuous Availability (Dual-site) ecosystem

Chapter 8: Ecosystem Interactions
147 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 78 shows how the concepts in this guide combine under the RecoverPoint for Virtual Machines-based disaster recovery protection service.
Figure 78. RecoverPoint for Virtual Machines-based disaster recovery protection ecosystem
Disaster recovery (RecoverPoint for Virtual Machines) ecosystem

Chapter 8: Ecosystem Interactions
148 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 79 shows how the concepts in this guide combine under the SRM-based DR protection service.
Figure 79. SRM-based disaster recovery protection ecosystem
Disaster recovery (Site Recovery Manager) ecosystem

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
149 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 9 Maximums, Rules, Best Practices, and Restrictions
This chapter presents the following topics:
Overview ................................................................................................................ 150
Maximums ............................................................................................................. 150
VMware Platform Services Controller rules ............................................................ 154
VMware vRealize tenants and business groups ...................................................... 156
EMC ViPR tenant and projects rules ....................................................................... 157
General storage considerations ............................................................................. 158
Bulk import of virtual machines ............................................................................. 159
Resource sharing ................................................................................................... 159
Data protection considerations .............................................................................. 160
RecoverPoint for Virtual Machines best practices .................................................. 160
Software resources ................................................................................................ 160
Sizing guidance ..................................................................................................... 161
Restrictions ............................................................................................................ 161
Component options ................................................................................................ 163

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
150 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Overview
This chapter looks at the maximums, rules, best practices, restrictions, and dependencies between Enterprise Hybrid Cloud components and their constructs, outlining how this influences the supported configurations within the cloud.
Maximums
Table 13 shows the maximums related to vCenter endpoints in Enterprise Hybrid Cloud.
Table 13. vCenters per Enterprise Hybrid Cloud instance
Total number of Maximum
vCenter endpoints with full Enterprise Hybrid Cloud services 4
vCenter endpoints associated with more than one Enterprise Hybrid Cloud site
4
vCenter IaaS-only endpoints (no Enterprise Hybrid Cloud services) 10*
vCenters that may offer continuous availability protection 4
vCenters pairs that may offer SRM-based disaster recovery protection
1
vCenters pairs that may offer RecoverPoint for Virtual Machines based disaster recovery protection
2
* This figure is the total supported number of vCenters that Enterprise Hybrid Cloud can support. It is also the total of the Enterprise Hybrid Cloud-managed vCenter endpoints and infrastructure-as-a-service vCenter endpoints.
Table 14 shows the maximums that apply per vCenter endpoint.
Table 14. Per vCenter maximums
Total number of Maximum
Enterprise Hybrid Cloud sites 2
Hosts per cluster 64
Virtual machines per cluster 8,000
Hosts per vCenter Server 1,000
Powered-on virtual machines per vCenter Server 10,000
Registered virtual machines per vCenter Server 15,000
vCenter maximums

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
151 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Table 15 shows the maximums that apply Enterprise Hybrid Cloud sites.
Table 15. Site maximums
Total number of Maximum
Standalone Sites per Enterprise Hybrid Cloud instance 4
Sites where all managed vCenter endpoints provide continuous availability protection
8
Note: Enterprise Hybrid Cloud supports a maximum of four sites when using single-site protection or DR protection. This may be increased to eight sites when all of the vCenters in the solution have two sites associated with it. Also, the number of sites supported is influenced by the number of vCenters per site. For instance, if four vCenters are provisioned on the first site, then vCenter maximums take precedence and only one site may be supported.
Table 16 shows the maximums that apply for Platform Service Controllers (PSCS).
Table 16. PSC maximums
Total number of Maximum
PSCs per vSphere domain 8
PSCs per site, behind a load balancer 4
Active Directory or OpenLDAP Groups per user for best performance 1,015
VMware Solutions* connected to a single PSC 4
VMware Solutions* in a vSphere domain 10
* VMware Solutions is a term provided by VMware. In the case of Enterprise Hybrid Cloud, this equates to VMware vCenter Server instances.
Table 17 shows the maximums that apply for virtual machines.
Table 17. Virtual machines maximums
Total number of Maximum
Virtual machines managed by Enterprise Hybrid Cloud 40,000
Powered-on virtual machines protected by CA 10,000
Registered virtual machines protected by CA 15,000
Virtual machines protected by SRM-based DR 5,000
Virtual machines protected RecoverPoint for Virtual Machines-based DR (individually recoverable) per vCenter
1,024
Virtual machines protected RecoverPoint for Virtual Machines-based DR (using multi-machine consistency groups) per vCenter
2,048
Site maximums
PSC maximums
Virtual machine maximums

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
152 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Total number of Maximum
Virtual machines protected RecoverPoint for Virtual Machines-based DR (individually recoverable)
2,048
Virtual machines protected RecoverPoint for Virtual Machines-based DR (using multi-machine consistency groups)
4,096
Table 18 shows the maximums that apply with respect to latencies in the solution.
Table 18. Latency maximums
Context Maximum
VPLEX uniform (cross-connect) configuration 5ms
VPLEX non-uniform (Non-cross-connect) configuration 10ms
Cross-vCenter NSX network latency 150ms
RecoverPoint for Virtual Machines latency between sites 200ms
Protection maximums
Table 19 shows the maximums that apply for SRM-protected resources.
Table 19. SRM protection maximums
Total number of Maximum
Virtual machines configured for protection using array-based replication
5,000
Virtual machines per protection group 500
Protection groups 250
Recovery plans 250
Protection groups per recovery plan 250
Virtual machines per recovery plan 2,000
Replicated datastores (using array-based replication) and >1 RecoverPoint cluster
255
Recovery maximums
Table 20 shows the maximums that apply for SRM recovery plans.
Table 20. SRM protection maximums
Total number of Maximum
Concurrently executing recovery plans 10
Concurrently recovering virtual machines using array-based replication
2,000
Latency maximums
Site Recovery Manager maximums

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
153 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Storage maximums
Table 21 indicates the storage maximums with SRM-based DR in Enterprise Hybrid Cloud, when all other maximums are taken into account.
Table 21. Implied Enterprise Hybrid Cloud storage maximums
Total number of Maximum
DR-enabled datastores per RecoverPoint consistency group 1
DR-enabled datastores per RecoverPoint cluster 128
DR-enabled datastores per Enterprise Hybrid Cloud environment 250
To ensure maximum protection for DR-enabled vSphere clusters, Enterprise Hybrid Cloud STaaS workflows create each LUN in its own RecoverPoint consistency group. This ensures that ongoing STaaS provisioning operations have no effect on either the synchronized state of existing LUNs or the history of restore points for those LUNs maintained by RecoverPoint.
Because there is a limit of 128 consistency groups per RecoverPoint cluster, there is therefore a limit of 128 Enterprise Hybrid Cloud STaaS provisioned LUNs per RecoverPoint cluster. To extend the scalability further, additional RecoverPoint clusters are required.
Each new datastore is added to its own SRM protection group. Because there is a limit of 250 protection groups per SRM installation, this limits the total number of datastores in a DR environment to 250, irrespective of the number of RecoverPoint clusters deployed.
RecoverPoint cluster limitations
There is also a limit of 64 consistency groups per RecoverPoint appliance and 128 consistency groups per RecoverPoint cluster. Therefore, the number of nodes deployed in the RecoverPoint cluster should be sized to allow appropriate headroom for surviving appliances to take over the workload of a failed appliance.
Table 22 shows the maximums that apply for latencies in the solution.
Table 22. RecoverPoint for Virtual Machines maximums
Total number of Maximum
Enterprise Hybrid Cloud vCenter endpoints connected to a vRPA cluster
1*
vRPA clusters connected to a vCenter Server instance 8
Best practice number of vRPA clusters per ESXi cluster 4
Virtual machines protected by a single Enterprise Hybrid Cloud LC1S cluster
512
Virtual machines in a vCenter protected 2,048
RecoverPoint maximums
RecoverPoint for Virtual Machines maximums

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
154 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Total number of Maximum
Protected VMDKs per vRPA cluster 2,048
Protected VMDKs per ESXi cluster 5,000
ESXi hosts with a splitter that can be attached to a vRPA cluster 32
Enterprise Hybrid Cloud LC1S clusters connected to a vRPA cluster 1*
Consistency groups per vRPA cluster 128
Virtual machines per consistency group 128
Replica sites per RecoverPoint for Virtual Machines system 1*
Replica copies per consistency group 1*
Capacity of a single VMDK 10 TB
Capacity of a replicated virtual machine 40 TB
* These figures are Enterprise Hybrid Cloud best practices based on architecture design and differ from the numbers that RecoverPoint for Virtual Machines natively supports.
VMware Platform Services Controller rules
This solution uses VMware Platform Services Controller (PSC) in place of the vRealize Automation Identity Appliance. A VMware PSC is deployed on a dedicated virtual machine in each Core Pod (multiple Core Pods in multi-site environments) and an additional PSC (Auto-PSC) is deployed on in the Automation Pod.
The Auto-PSC provides authentication services to all the Automation Pod management components requiring PSC integration. This configuration enables authentication services to fail over with the other automation components and enables a seamless transition between sites. There is no need to change IP addresses, domain name system (DNS), or management component settings.
Enterprise Hybrid Cloud uses one or more PSC domains, depending on the management platform deployed. PSC instances are configured within those domains according to the following model:
External PSC domain (external core function only)
First external PSC
Additional external PSCs (multi-site/multi-vCenter configurations)
Cloud single sign-on (SSO) domain (all topologies)
First Cloud PSC
Automation Pod PSC
Additional Cloud PSCs (multi-site/multi-vCenter configurations only)
Platform Services Controller domains

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
155 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 80 shows an example of how the PSC domains and each PSC instance and domain required could be configured in an environment with the following characteristics:
Three sites, each with their own Cloud vCenter endpoint
Site A is the primary location for the cloud management platform
Inter-site protection of the cloud management platform is required between Site A and Site B
No external PSC domain is required because the environment is using default Enterprise Hybrid Cloud configuration
Figure 80. SSO domain and vCenter SSO instance relationships
This first VMware PSC deployed in each single sign-on domain is deployed by creating a new vCenter SSO domain and enabling it to participate in the default vCenter SSO namespace (vsphere.local). This primary PSC server supports identity sources, such as Active Directory, OpenLDAP, local operating system users, and SSO embedded users and groups.
This is the default deployment mode when you install VMware PSC.
Additional VMware PSC instances are installed by joining the new PSC to an existing SSO domain, making them part of the existing domain but in a new SSO site. When you create PSC servers in this way, the deployed PSC instances become members of the same authentication namespace as the PSC instance. This deployment mode should only be used after you have deployed the first PSC instance in each SSO domain.
First PSC instance in each single sign-on domain
Subsequent PSC instances in each single sign-on domain

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
156 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
In vSphere 6.0, VMware PSC SSO data (such as policies, solution users, application users, and identity sources) is automatically replicated between each PSC instance in the same authentication namespace every 30 seconds.
VMware vRealize tenants and business groups
Enterprise Hybrid Cloud is designed for use in single vRealize Automation tenant configurations. Enterprise multi-tenancy may be provided by using a single vRealize Automation tenant with multiple vRealize Automation business groups. To deploy multiple vRealize Automation tenants, you should use separate Enterprise Hybrid Cloud instances. As the vRealize Automation IaaS administrator is a system-wide role, having multiple vRealize Automation tenants within the same vRealize Automation instance may not provide any additional value over and above the use of a single tenant with multiple business groups.
Enterprise Hybrid Cloud uses two system business groups. The first, EHCSystem, is used as the target for installation of the vRealize Automation advanced services, EHC Configuration and Storage-as-a-Service catalog items. It does not require any compute resources. The second system business group, EHCOperations, is used as the group where Enterprise Hybrid Cloud administrators are configured. It is given entitlements to Storage-as-a-Service and EHC Configuration service catalog items. It has no compute resource requirements.
Enterprise Hybrid Cloud recommends that applications provisioned using vRealize Automation Application Services each have a separate business group per application type to enable administrative separation of blueprint creation and manipulation.
Figure 81 shows an example where the EHCSystem and EHCOperations system business groups are configured alongside three tenant business groups (IT, HR, and Manufacturing) and three application business groups used by vRealize Automation Application Services for Microsoft SharePoint, Oracle, and Microsoft Exchange.
vRealize Automation Multi-tenancy
vRealize Automation Business Group Design
vRealize Automation business group best practice

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
157 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Figure 81. Software-defined data center tenant design and endpoints
EMC ViPR tenant and projects rules
Enterprise Hybrid Cloud uses a single ViPR tenant. The default provider tenant or an additional non-default tenant may be used.
Enterprise Hybrid Cloud storage-as-a-service operations use a single ViPR project as defined by the default_vipr_project global option. Changing the value of this option is done using the vRealize Automation catalog item entitled Global Options Maintenance.
ViPR consistency groups are an important component of the CA and SRM-based DR protection services for Enterprise Hybrid Cloud. Consistency groups logically group volumes within a project to ensure that a set of common properties is applied to an entire group of storage volumes during a fault event. This ensures host-to-cluster or application-level consistency when a failover occurs.
Consistency groups are created by Enterprise Hybrid Cloud storage-as-a-service operations and are specified when VPLEX or RecoverPoint protected volumes are provisioned. Consistency group names must be unique within the ViPR environment.
When used with VPLEX in the CA protection service, these consistency groups are created per physical array, per vSphere cluster, and per site.
When used with RecoverPoint in the SRM-based DR protection service, these consistency groups are created in 1:1 relationship with the vSphere datastore/LUN.
ViPR tenants
ViPR projects
ViPR consistency groups

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
158 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
General storage considerations
Enterprise Hybrid Cloud does not support vSphere datastore clusters for the following reasons:
Linked clones do not work with datastore clusters, causing multi-machine blueprints to fail unless configured with explicitly different reservations for edge devices.
vRealize Automation already performs capacity analysis during initial placement.
VMware Storage DRS operations can result in inconsistent behavior when virtual machines report their location to vRealize Automation. Misalignment with vRealize reservations can make the virtual machines un-editable.
Enterprise Hybrid Cloud storage-as-a-service operations do not place new LUNs into datastore clusters, therefore all datastore clusters would have to be manually maintained.
Specific to SRM-based DR protection service:
a. Day 2 storage DRS migrations between datastores would break the SRM protection for the virtual machines moved.
b. Day 2 storage DRS migrations between datastores would result in re-replicating the entire virtual machine to the secondary site.
VMware raw device mappings are not created by or supported by Enterprise Hybrid Cloud storage-as-service operations. If created outside of STaaS services, then any issues arising from their use will not be supported by Enterprise Hybrid Cloud customer support. If changes are required in the environment to make them operate correctly, then an Enterprise Hybrid Cloud RPQ should be submitted first for approval. If issues arise related to these changes, then Enterprise Hybrid Cloud support teams may request that you back them out to restore normal operation.
vSphere datastore clusters
VMware raw device mappings (RDMs)

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
159 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Bulk import of virtual machines
For environments that require existing virtual machines to be imported into Enterprise Hybrid Cloud, the bulk import feature of vRealize Automation enables the importation of one or more virtual machines.
This functionality is available only to vRealize Automation users who have Fabric Administrator and Business Group Manager privileges. The bulk import feature imports virtual machines intact with defining data such as reservation, storage path, blueprint, owner, and any custom properties.
Enterprise Hybrid Cloud offers the ability to layer Enterprise Hybrid Cloud services onto pre-existing virtual machines by using and extending the bulk import process. Before beginning the bulk import process, the following conditions must be true:
Target virtual machines are located in an Enterprise Hybrid Cloud vCenter endpoint.
Target virtual machines must be located on the correct vRealize Automation managed compute resource cluster and that cluster must already be on-boarded as an Enterprise Hybrid Cloud cluster, where:
SRM-based DR protection is required for the target virtual machines, they must be on a DR2S cluster.
Data protection services are required for the target virtual machines, they must be on a cluster that is associated with an ASR.
Target virtual machines must be located on the correct vRealize Automation managed datastore, where:
SRM-based DR protection is required for the target virtual machines, they must be on a datastore protected by EMC RecoverPoint.
Data protection services are required for the target virtual machines, they must be on a datastore that is already registered with an Avamar proxy.
Note: The process for importing these virtual machines and adding Enterprise Hybrid Cloud services is in the Enterprise Hybrid Cloud 4.1 Administration Guide.
Resource sharing
As vRealize Automation endpoints are visible to all vRealize Automation IaaS administrators, resource isolation in the truest sense is not possible. However, use of locked blueprints and storage reservation policies can be used to ensure that certain types of workload (such as those whose licensing is based on CPU count) can be restricted to only a subset of the Workload Pods available in the environment. This includes the ability to control those licensing requirements across tenants by ensuring that all relevant deployments are on the same set of compute resources.
Importing from virtual machines and adding Enterprise Hybrid Cloud services
Resource isolation

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
160 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
All endpoints configured across the vRealize Automation instance by an IaaS administrator are available to be added to fabric groups, and therefore consumed by any business group across any of the vRealize Automation tenants.
Provisioning to vCenter endpoints, however, can still only be done through the tenant configured as part of the Enterprise Hybrid Cloud process.
Enterprise Hybrid Cloud recommends that applications provisioned using vRealize Automation application services each have their own business group by application type to enable administrative separation of blueprint creation and manipulation.
Data protection considerations
Enterprise Hybrid Cloud supports physical Avamar infrastructure only. It does not support Avamar Virtual Edition.
RecoverPoint for Virtual Machines best practices
Use of RecoverPoint for Virtual Machines requires the deployment of virtual RecoverPoint Appliances (vRPAs). These vRPAs are considered tenant workloads, and are therefore deployed to the tenant pods and not to the Enterprise Hybrid Cloud management pods.
Best practice suggests that distinct tenant resource pods are used to host the vRPAs to separate the vRPAs from the workloads that they are protecting. The Enterprise Hybrid Cloud sizing tool provides sizing for RecoverPoint for Virtual Machines based on this best practice.
Enterprise Hybrid Cloud recommends a default ratio of four vRPA clusters to every on-boarded LC1S (Local Copy on One Site) cluster. This allows for up to 512 individually recoverable virtual machines on that cluster.
The Enterprise Hybrid Cloud sizing tool provides sizing for RecoverPoint for Virtual Machines based on this best practice.
Software resources
For information about components required for the initial release of Enterprise Hybrid Cloud 4.1, refer to Enterprise Hybrid Cloud 4.1 Foundation Infrastructure Reference Architecture. For up-to-date supported version information, refer to the EHC Support Matrix.
Resource sharing
Application tenant integration
Supported Avamar platforms
Resources for Virtual RecoverPoint Appliances
Ratio of Virtual RecoverPoint Appliances to vSphere clusters
Enterprise Hybrid Cloud software resources

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
161 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Sizing guidance
For all Enterprise Hybrid Cloud sizing operations, refer to the EMC Mainstay Sizing tool: mainstayadvisor.com/go/emc.
Restrictions
Load balancers cannot be deployed as part of a DR-protected multi-machine blueprint, as the corresponding load balancers would not be deployed on the secondary site. However, you can manually edit the upstream Edge to include load-balancing features for a newly deployed multi-machine blueprint.
SRM-based disaster recovery protection failover state operations
Provisioning of virtual machines to a protected DR2S cluster is permitted at any time, as long as that site is operational. If you provision a virtual machine while the recovery site is unavailable due to vCenter SRM DR failover, you need to run the DR Remediatior catalog item to bring it into protected status when the recovery site is back online.
During storage-as-a-service provisioning of a protected datastore to a DR2S cluster, Enterprise Hybrid Cloud workflows issue a DR auto-protect attempt for the new datastore within vCenter SRM. If both sites are operational when the request is issued, this should be successful. However, if one site is offline when the request is made, the datastore will be provisioned, but you must run the DR Remediatior catalog item to bring it into a protected status.
Note: The DR Remediatior catalog item can be run at any time to ensure that all DR items are protected correctly.
SRM-based DR protection
While replication is at the datastore level, the unit of failover with SRM-based DR protection DR2S-enabled cluster, that is, all workloads on a specified DR2S cluster must fail over at the same time. It is not possible to fail over a subset of virtual machines on a single DR2S cluster. This is because all networks supporting these virtual machines are converged to the recovery site during a failover.
RecoverPoint for Virtual Machines-based DR protection
With RecoverPoint for Virtual Machines-based DR protection, failover granularity is set at the RecoverPoint for Virtual Machines consistency group level in that all workloads in a specified consistency group must fail over at the same time. Given that it is possible to have just one virtual machine in a consistency group, this means that failover can happen at an individual virtual machine level.
Enterprise Hybrid Cloud sizing
Multi-machine blueprints
vRealize Automation
Disaster recovery failover granularity

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
162 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Supports VMAX, VNX, XtremIO, and VMAX3 (behind VPLEX) only.
SRM-based DR protection
Enterprise Hybrid Cloud provides fully automated network re-convergence during disaster recovery failover when using VMware NSX only. The use of VMware vSphere distributed switches backed by other networking technologies is also permitted, but requires that network re-convergence is carried out manually in accordance with the chosen network technology or that automation of network re-convergence is developed as a professional services engagement.
RecoverPoint for Virtual Machines-based DR protection
In this case, the networking requirements for the solution mandate that the network is simultaneously available on both sites. Enterprise Hybrid Cloud fully tests and supports the use of cross-vCenter VMware NSX to achieve this. The use of VMware vSphere distributed switches backed by other networking technologies is also permitted, but requires that network configuration is designed and carried out independently of Enterprise Hybrid Cloud implementation or as part of a professional services engagement.
Enterprise Hybrid Cloud only supports the assignment of blueprint virtual machines to a security group. It does not support the assignment of blueprints to security policies or security tags.
Enterprise Hybrid Cloud supports RecoverPoint CL-and EX-based licensing only. It does not support RecoverPoint SE.
SRM-based DR protection—storage support
Disaster recovery network support
Disaster recovery NSX security support
Supported RecoverPoint licensing types

Chapter 9: Maximums, Rules, Best Practices, and Restrictions
163 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Component options
The following assumptions and justifications apply to Enterprise Hybrid Cloud:
VMware PSC is used instead of the vRealize Automation identity appliance because it supports the multi-site, SSO requirements of Enterprise Hybrid Cloud
Appliance-based VMware PSCs are the default, but Windows-based instances are supported for backwards compatibility with older versions of Enterprise Hybrid Cloud. New deployments should use the appliance-based version.
Appliance-based vCenter Server instances are the default, but Windows-based instances are supported for backwards compatibility with older versions of Enterprise Hybrid Cloud. New deployments should use the appliance-based version.
Assumption and justifications

Chapter 10: Conclusion
164 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Chapter 10 Conclusion
This chapter presents the following topics:
Conclusion ............................................................................................................. 165

Chapter 10: Conclusion
165 Enterprise Hybrid Cloud 4.0 Concepts and Architecture Guide
Conclusion
Enterprise Hybrid Cloud provides on-demand access and control of infrastructure resources and security while enabling customers to maximize asset use across a multi-site deployment. Specifically, it integrates all the key functionality that customers demand of a hybrid cloud and provides a framework and foundation for adding other services.
Enterprise Hybrid Cloud provides the following features and functionality:
Continuous availability
Disaster recovery
Data protection
Automation and self-service provisioning
Workload-optimized storage
Elasticity and service assurance
Monitoring
Metering and showback
Encryption
Enterprise Hybrid Cloud uses the best of EMC, VMware, and VCE products and services to empower customers to accelerate the implementation and adoption of hybrid cloud while still enabling customer choice for the compute and networking infrastructure within the data center.