enhanced infrastructure for creation & collection of translation resources
DESCRIPTION
Enhanced Infrastructure for Creation & Collection of Translation Resources. Zhiyi Song, Stephanie Strassel (speaker), Gary Krug, Kazuaki Maeda. Introduction. LDC develops large scale parallel text corpora for sponsored research programs Manual creation of parallel text by human translators - PowerPoint PPT PresentationTRANSCRIPT

Enhanced Infrastructure for Creation & Collection of Translation Resources
Zhiyi Song, Stephanie Strassel (speaker), Gary Krug, Kazuaki Maeda

Introduction
LDC develops large scale parallel text corpora for sponsored research programsManual creation of parallel text by human
translatorsHarvesting, aligning potential parallel
documents from known repositories and the web
Recent expansion in scope and variety Requiring improvements in quality, efficiency
and cost-effectiveness

Context for Resource Creation
Previous focus primarily Chinese, Arabic newswire (NW) Current focus on "unstructured" data
Broadcast News (BN) and Broadcast Conversation (BC) Weblogs, Newsgroups (WB) Handwritten document images of many types (VAR)
New linguistic varieties Eight language pairs in the LCTL program Colloquial Arabic varieties for some projects
New evaluation requirements Multiple human translations, adjudication of multiple translations Translation alternatives for ambiguous source text Translation post-editing

Recent translation efforts
Language PairApproximate Volume (Words) Genres Methodology
Arabic > English 100M + BN, BC, NW, WB, VARmanual translation, parallel text harvesting, acquisition of existing manual translations
Chinese > English 100M + BN, BC, NW, WBmanual translation, parallel text harvesting, acquisition of existing manual translations
English > Chinese 250K + BN, BC, NW, WB manual translation
English>Arabic 250K + BN, BC, NW, WB manual translation
Bengali>EnglishPashto>EnglishPunjabi>EnglishTagalog>EnglishTamil>EnglishThai>EnglishUrdu>EnglishUzbek>English
250-500K + per language pair
manual translation, parallel text harvestingNW, WB
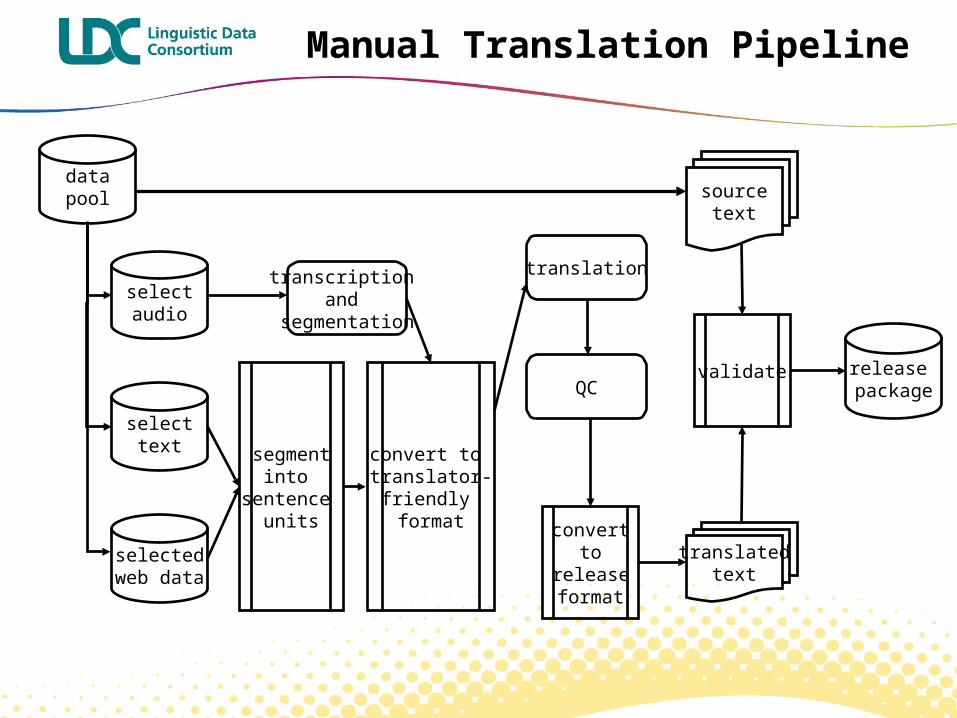
Manual Translation Pipeline
datapool
selectaudio
selecttext
selectedweb data
segmentinto
sentence units convert
toreleaseformat
sourcetext
translatedtext
validate release package
convert to translator-friendly format
translation
QC
transcription and
segmentation

Manual Translation
Commercial agencies vetted, trained by LDC Required to use LDC's project-specific guidelines
Accuracy and fidelity over fluencyGeneral principles, language-specific requirementsRules for named entities, disfluencies, emoticons, etc.Requirements for formatting and validationMultiple examples of preferred translation
Separate guidelines for specialized tasksPost-editing machine translation outputTranslation alternativesTranslation of novel single sentencesTranslation of handwritten document images

Translation QC
All translations undergo additional QC at LDCTypically 10% of training data, 100% of evaluation data
reviewed Standardized QC rating system deducts points
for each type of errorQC report including score, examples sent to translatorsFailing score requires re-translation of full data set
QC process facilitated by customized TransQC GUI

QCTrans GUI

Translation Project Management
Translation database is core management tool Document ID, language, genre, token count, LDC file server path Data set information including project, phase, partition, restrictions Translator assignment, due date, status, QC score, payment info
Backend to LDC Translator Extranet Translators access and submit assignments, validate submissions,
view QC reports, generate invoices, check payment status
Queries support status tracking but also assignment generation, data selection, cross-project coordination What translation assignments are pending delivery this week? What is average QC score for this translator on Chinese BC? List Arabic NW files from 2007 that have never been released as
GALE training data and are not part of any project's eval set

LDC Translation Database

Parallel text harvesting
Manual translation supplemented by harvesting and alignment of potential parallel textHarvest text from multilingual sites
E.g. newswire providers
Standardize markup formatUse BITS document mapping module to find likely
parallel documentsUse Champollion to find sentence alignments
High yields in GALE program82,000 Arabic-English document pairs67,000 Chinese-English document pairs

Conclusion
Robust, flexible translation infrastructure to support multiple, distinct, concurrent projects
Much of this infrastructure freely available from LDCTask specifications, guidelines available for all projects
http://projects.ldc.upenn.edu/gale/Translation/
QCTrans GUI slated for free, open-source distribution
Many resulting parallel text corpora already in LDC Catalog
Newly emerging data sets to be added over time

Recent corpora
Catalog Number Title
LDC2007T23 GALE Phase 1 Chinese Broadcast News Parallel Text - Part 1
LDC2008T08 GALE Phase 1 Chinese Broadcast News Parallel Text - Part 2
LDC2008T18 GALE Phase 1 Chinese Broadcast News Parallel Text - Part 3
LDC2007T24 GALE Phase 1 Arabic Broadcast News Parallel Text - Part 1
LDC2008T09 GALE Phase 1 Arabic Broadcast News Parallel Text - Part 2
LDC2009T02 GALE Phase 1 Chinese Broadcast Conversation Parallel Text - Part 1
LDC2009T06 GALE Phase 1 Chinese Broadcast Conversation Parallel Text - Part 2
LDC2008T02 GALE Phase 1 Arabic Blog Parallel Text
LDC2008T06 GALE Phase 1 Chinese Blog Parallel Text
LDC2009T03 GALE Phase 1 Arabic Newsgroup Parallel Text - Part 1
LDC2009T09 GALE Phase 1 Arabic Newsgroup Parallel Text - Part 2
LDC2009T15 GALE Phase 1 Chinese Newsgroup Parallel Text - Part 1
LDC2010T03 GALE Phase 1 Chinese Newsgroup Parallel Text - Part 2

Acknowledgements
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this paper does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.