energy-precision tradeoffs in the graphics pipeline jeff pool march 19 th, 2012
TRANSCRIPT

Energy-Precision Tradeoffs in the Graphics Pipeline
Jeff PoolMarch 19th, 2012

2
Motivation
Why energy?
It matters everywhere:- Mobile devices- Desktop computers- Servers, data centers
It’s a bottleneck to performance!
http://img717.imageshack.us/img717/3936/1101771coolitomni.jpg
http://www.ornl.gov/ornlhome/images/casl/TVA%20Watts%20Bar.jpg

3
Motivation
Why precision?
Sign Exponent Mantissa
IEEE 754-2008 Single-Precision Floating-Point Representation

4
Don’t do Unnecessary Work
• Max precision isn’t needed:– 8-10 bit color buffers– FP32 => 24 bits of precision– Potentially lots of wasted effort!
• It’s certainly more complicated, but worth exploring

5
My Approach
Variable-precision computations- Reduce the precision when possible: 12.5 mantissa
bits used- Save energy in arithmetic: 70% less
energy- Low errors: 0.086%
difference
Full-Precision Arithmetic Reduced-Precision Arithmetic

6
My Approach
Communicate fewer bits - Since fewer bits are used in computation - Most DRAM traffic is already compressed
Crysis, 2007
Variable-precision compression:(on sample frame)
- Geometry improved by 12%- Depth improved by 83%

7
GPU Global Memory Texture Frame-
Data Buffer
The Graphics Pipeline
Vertex Shader
Rasterization
Pixel Shader
Background
8
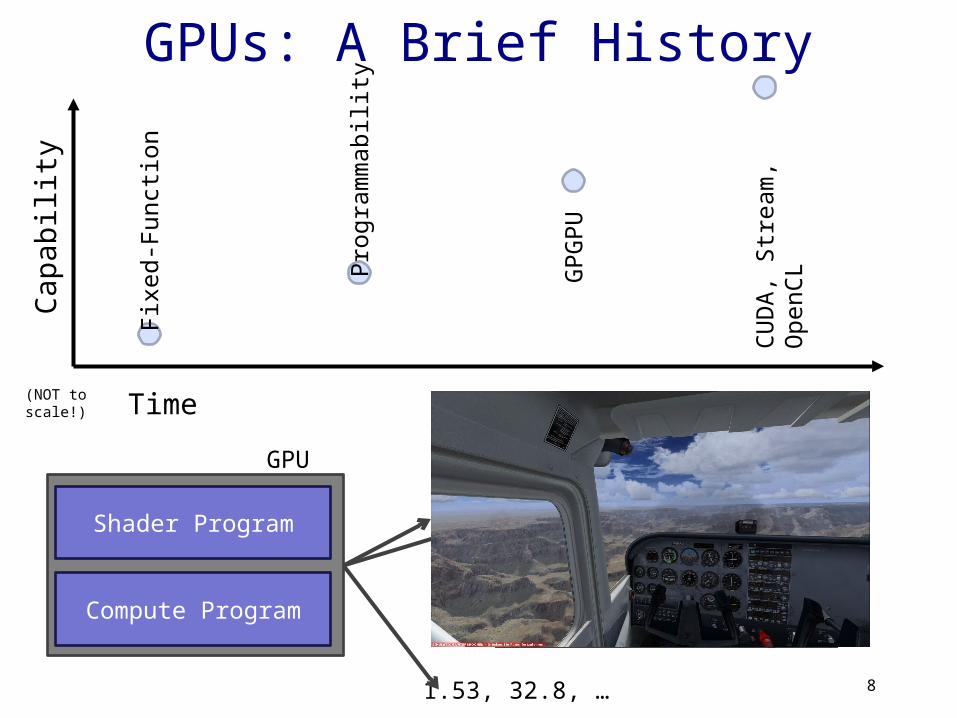
GPUs: A Brief History
Time
Cap
ab
ilit
y
GPU
(NOT to scale!)
Fix
ed
-Fu
nct
ion
Pro
gra
mm
ab
ilit
y
GP
GP
U
CU
DA
, S
tream
, O
pen
CL
Shader Program
Compute Program
1.53, 32.8, …

10
Thesis Statement
Reducing the work done in the modern graphics pipeline through novel communication and variable-precision computation techniques can enable a tradeoff between energy savings and image fidelity, leading to significant energy savings without perceptible loss of image quality.

11
How?
Proving this thesis:– Show that induced errors are imperceptible– Show significant energy savings
• Find energy consumed by entire pipeline• Find energy savings possible in each stage

12
Roadmap
• My work– Energy model– Energy savings in computation– Energy savings in communication
• Conclusions• Future work

13
Roadmap
• My work– Energy model– Energy savings in computation– Energy savings in communication
• Conclusions• Future work

14
Why an Energy Model?
So I’ll know how much difference saving energy in different stages actually makes, know where to focus• Provides researchers/developers a tool to
predict energy usagePast Work Validated? Graphics? Simple
?
Brooks et al., 2000
Eisley et al., 2006
Shaeffer et al., 2004
Ramani et al., 2007
Nagasaka et al., 2010
Hong and Kim, 2010
Zhang et al., 2011

15
Strategy
• Model construction– Experimentally measure energy for each
operation• Energy prediction
– Profile a scene for operations performed– Predict total energy consumption (dot
product)• Validation
– Compare prediction with measured energy

16
What Operations?
• Arithmetic– ADD, MUL, SIN/COS, POW, LOG, …
• Memory– Local/Global Load/Store
• Programmable– Vertex/Pixel Shaders
• Fixed-function– Rasterization, Texture filtering
Explicit
Implicit

17
Measuring Energy in the GPU
Explicit• GPGPU
– Runs on same hardware as graphics
– No ambiguity in operations
• Simple microkernels– Little/no overhead– 10s runtime– Directed tests per
operation
Implicit• OpenGL• Enable/Disable
operation in question– Difference in energy is
the operation’s contribution
– Not as straightforward• Ex.: Texture filtering

18
Experimental Setup• NVIDIA 8300GS graphics card• Adex Electronics’ PEX16LX PCI riser to
interrupt power from motherboard
• Supply metered power to the card– 12V– 3.3V– 12V (fan, not counted in energy)
• Log runtimes/framerates, measure current as tests run
http://www.pretaktovanie.sk/obr/spotreba/eng/PICTURES/P1010283_ENG.jpg

19
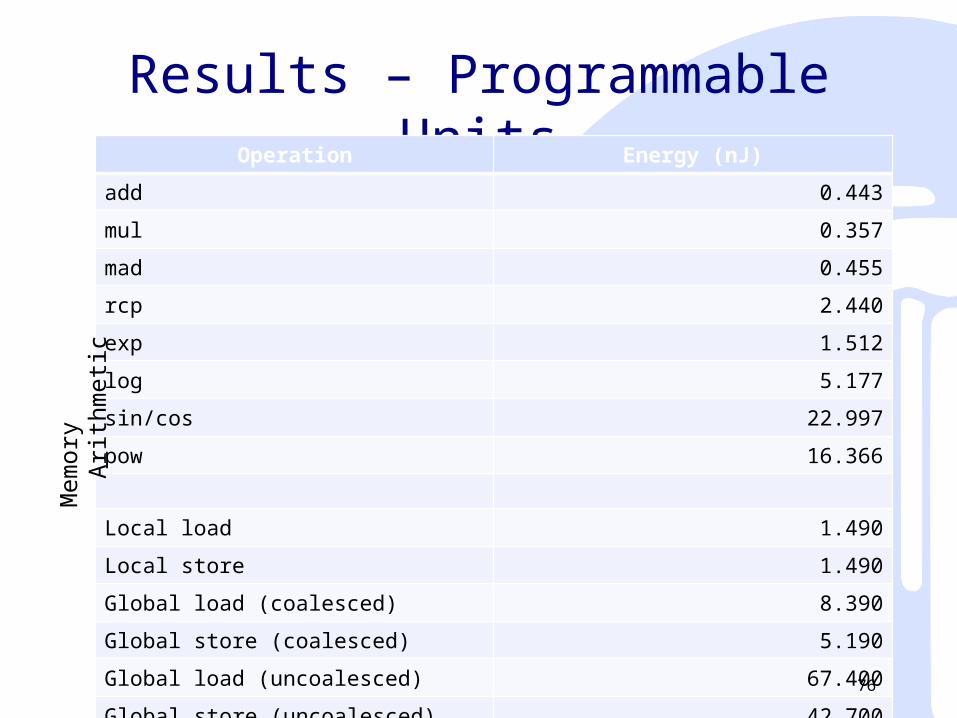
ResultsOperation Energy (nJ)
Arithmetic 0.4 – 22.9
Memory
Local load 1.49
Local store 1.49
Global load* 8.39 – 67.40
Global store* 5.19 – 42.70 *Depending on type of access
Rasterization (per pixel) 0.24
Texture filtering (per pixel) 7.0 – 13.8

20
Profiling Operations Performed
• Use Microsoft’s PIX to log a frame of a running application:– Framebuffer contents– Vertex data– Render states– Vertex shaders– Pixel shaders– Per draw call
(100-1000s per frame)
• From all this data, extract operations

21
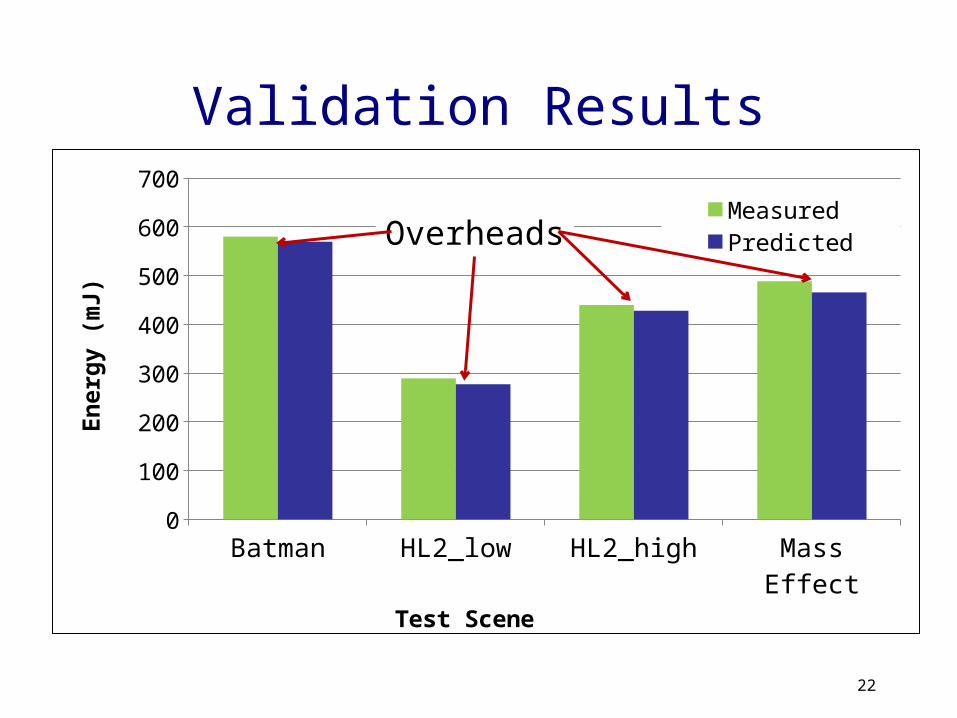
Validation• Three different applications, four scenes
– Real-world games to test the developed model• Harvested data, predict energy usage• Measured real energy usage, compare
Half Life 2: Lost Coast(High/Low Rendering
Qualities)
Batman: Arkham Asylum
Mass Effect
22
Validation Results
Batman HL2_low HL2_high Mass Effect0
100
200
300
400
500
600
700MeasuredPredicted
Test Scene
En
erg
y (
mJ)
Overheads

23
What Uses the Energy?
Batm
an
HL2
_low
HL2
_hig
h
Mas
s Effec
t0
100
200
300
400
500
600
700
FB-WriteFB-ReadZ-WriteZ-ReadPS-MemoryPS-ArithmeticRasterizationVSRead Geometry
Test Scene
Est
imate
d E
nerg
y (m
J)

24
Roadmap
• My work– Energy model– Energy savings in computation– Energy savings in communication
• Conclusions• Future work

25
Where Does the Power Go?
Ptotal = Pdynamic + Pstatic
Power
Ground
CMOS Inverter

26
Energy-Saving Techniques
Clock gating (Park et al., 2010)Signal gating (Huang and Ercegovac, 2003)Power gating
– Coarse (Usami et al., 2009, Sjalander et al., 2005)
– Fine (My work)
Ptotal = Pdynamic + Pstatic

27
!Enable
Example: 1-Bit Adder
Cin
A
BCout
S

28
HW Results
SPICE simulations of:Adders: linear savings
Multipliers: quadratic savings

29
Precision in Rendering
Variable-Precision fixed-function CPU rendering– Hao and Varshney, 2001– 3 key differences: GPU, FP32,
programmability
Depth buffer comparator– Hensley, Singh, and Lastra, 2005
Triangle separation for correct occlusion– Akeley and Su, 2006

30
VARIABLE-PRECISION PIXEL SHADERS
So, we have hardware, let’s see what happens in

31
A Pixel Shader

32
Exaggerated Texture Coordinate Errors
Blocky textures(8 mantissa bits)
Original frame(24 mantissa bits)

33
Arithmetic Errors
… Different?(8 mantissa bits)
Original frame(24 mantissa bits)

34
Exaggerated Arithmetic Errors
Clearly different(4 mantissa bits)
Original frame(24 mantissa bits)

35
Different Errors,Different Tolerances
• Colors can be pushed far lower– 12, 10, 8 bits for color components (plus
one for rounding)
• Texture coordinates may need to be fully precise!

36
So, Treat Them Separately

37
So, Treat Them Separately
A
Could contribute to texture coordinates

38
So, Treat Them Separately
A
B
Could contribute to texture coordinates
Will NOT contribute to texture coordinates

39
Precision Selection Strategies
• Statically• Artist-directed• Automatic closed-loop

40
Static Program Analysis
9 bits10 bits
12 bits
9 bits10 bits And so on…
11 bits

41
Artist-Directed Precisions
Precisions are chosen as the effect is designed

42
Automatic Closed-Loop Precision Selection
Run time feedback controlPer-shader error detection and precision
control
Error DetectionRenderer
Controller
Display
Pre
cisi
on
Reduced Pixel
Full Pixel(sparsely sampled)
Erro
r
Reduced Pixel

43
Experimental Setup
Static analysis– Analyze shaders to find minimum safe
operating precision
Artist-directed– Modify several demo applications– Allow the artist to choose precisions
Automatic closed-loop– Modify the ATTILA GPU simulator– Apply several feedback control schemes– Several test scenes

44
Data SetsData Set Static Directed Automatic
Closed-Loop
Depth of Field
Parallax Mapping
SSAO
Half Life 2: Lost Coast
Doom 3
Need for Speed: Undercover
Metaballs

45
Data Sets

46
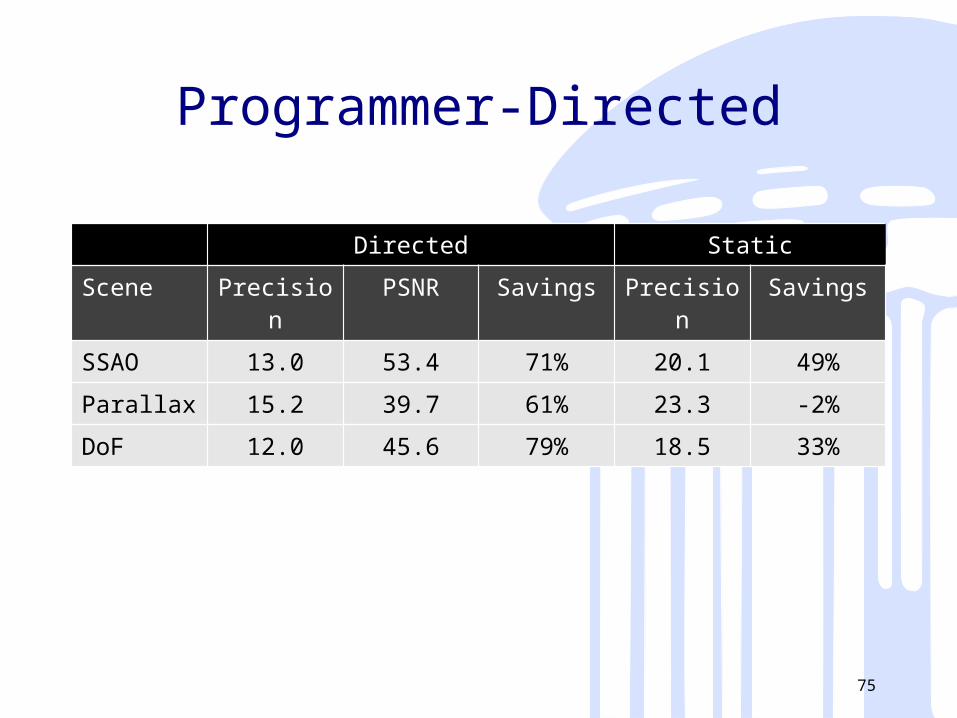
Results: PrecisionsData Set Static Directed Automatic
Closed-Loop
Depth of Field 18.5 12.0 -
Parallax Mapping 23.3 15.2 -
SSAO 20.1 13.0 -
Half Life 2: Lost Coast 19.1 - 13.2
Doom 3 19.7 - 14.7
Need for Speed: Undercover
21.8 - 16.5
Metaballs 9.7 - 8.9
Lower is Better!

47
Results: Closed-Loop Errors
Unnoticeable in practice

48
Results: % Energy SavingsData Set Static Directed Automatic
Closed-Loop
Depth of Field 33% 79% -
Parallax Mapping -2% 61% -
SSAO 49% 71% -
Half Life 2: Lost Coast 33% - 75%
Doom 3 15% - 69%
Need for Speed: Undercover
2% - 50%
Metaballs 87% - 90%
Higher is Better!
Overall Energy: 2/3 1/5

49
Which Precision Selection Method?
Approach Savings HW Complexity
Artist Effort
Static Low Low Low
Directed High Low Medium
Automatic Closed-Loop
High High Low

50
Directed Approach
• High savings– 70-80% in arithmetic– 10-20% overall GPU energy
• (by arithmetic alone!)
• Low errors– Acceptable by design– Quantitatively low (PSNR, % error)

51
Variable Precision Geometry
• Vertex shaders• Similarly high savings (55-80%)• Different types of errors
– XY Screen-space– Depth

52
XY Screen-Space Errors
8 bits of precision

53
Depth Errors
16 bits of precision

54
Depth Matters (Some)
• Far before XY errors• Even in unmodified commercial games
http://underpop.free.fr/j/java/developing-games-in-java/1592730051_ch10lev1sec5.htmlhttps://encrypted-tbn3.google.com/images?q=tbn:ANd9GcRWhmviKHKMGVAU1ooXrAzJxa_2IlknTI6cRT4MGfJyTpaZNYw-MA

55
COMMUNICATING LESS DATA
Variable-precision computation works. Let’s look at

56
Energy Savings in Communication
• Off-chip: compression (most data!)– Strom et al. (2008), Rasmussen et al. (2007,
2009)• 16 bit positive color/depth values• I adapt their approach to my needs
– Negative numbers– 32 bits– General values
• On-chip: bus encoding, caching– Reduced precision data freeze unused
lines

57
Unified Compressor
Key idea behind compression:• Encode numbers as differences between them• Similar numbers lead to smaller representations
What’s tricky about adding geometry, GPGPU data?
• Negative values• Arbitrary data/attribute layout• Random access
• Each will limit how complicated the compressor’s design can be

58
Handling Negative Values
Color and depth data is all positive – sign bit unused! Not so for general data.
• Overflow can occur during prediction and difference encoding
• My approach– Generalized past work to handle negative values– Drastically simplified processing of differences
• Limitation: can’t do any processing
33 Bit Adder
EncoderProcessing

59
Arbitrary Data Layout
X Y Zx1 y1 z1x2 y2 z2… … …
Geometry?
Color is simple
X Y Z U V Nx Ny Nz …
x1 y1 z1 u1 v1 …
x2 y2 z2 u2 v2 …
… … … … …

60
Arbitrary Data Layout
Our approach: encode vectors of data (rather than blocks)
• Color– Alpha channel for free!
• Geometry– Intra-attribute coherence!
Limitation: no 2D coherence
X Y Zx1 y1 z1x2 y2 z2… … …… … …… … …xN yN zN

61
Random Access
Random access is necessary for graphics• Color data maps well – 4x4, 8x8 tiles• Geometry?
– Simply encode a subset, C, of the vertices at a time
X x1 x2 … … xC xC+1 … … x2C ...
Y y1 y2 … … yC yC+1 … … y2C ...
Z z1 z2 … … zC zC+1 … … z2C ...

62
DoF
HDR_1
HDR_2
Paralla
xM
ap
Smoke
Crysis
NFS:U Car
Carava
n
Soldie
r0
20
40
60
80
100
TiledUnified
Color Depth
Co
mp
ress
ed
Siz
e (
%)
Unified Compressor
Compared to (Ström 2008) (“Tiled”)Smaller is better!
Color channel coherence!

63
Unified Compressor
Geometric data sets – uncompressed in past work!
Data Set Compressed Bandwidth (%)
Crysis 30.3
Crysis: Warhead 55.6
Need For Speed: Undercover 37.0
Half Life 2: Lost Coast (Scene 1)
28.6
Half Life 2: Lost Coast (Scene 2)
23.8

64
Improvements to Existing Compressors
Just a brief mention of my other work:• Dynamic Bucket Selection
– Average of 1.25x improvement• Fibonacci Encoding
– Up to 1.7x improvement– Average of 1.12x for unified compressor
• Dynamic Range Reduction– Extra 5-20%, depending on application

65
On-Chip Communication
Freeze (signal gate) unused bus lines from register file to L1 cache
Application Average Precision
Energy (%)
Half-Life 2: Lost Coast (1) 10.9 63.7
Half-Life 2: Lost Coast (2) 10.2 55.9
Doom 3 9.8 62.5
Need For Speed: Undercover
19.4 86.9
Metaballs 8.2 52.7

66
SUMMARY

67
Thesis Statement
Reducing the work done in the modern graphics pipeline through novel communication and variable-precision computation techniques can enable a tradeoff between energy savings and image fidelity, leading to significant energy savings without perceptible loss of image quality.

68
How Did I Do?• Show that induced errors are imperceptible
– Vertex and pixel shader precisions can be reduced significantly without loss of quality
• Show significant energy savings– Find energy consumed by entire pipeline
• Energy model accurate to within 5% for tested applications
– Find energy savings possible in each stage• Designed hardware that saves energy• Used this hardware and the reduced precisions to find energy
savings in computation• Used precision information to enable further savings in on-
and off-chip communication

69
Batman HL2_low HL2_high Mass Effect0
100
200
300
400
500
600
700
Test Scene
Est
imate
d E
nerg
y (m
J)Estimated Energy Savings
54%
49%
46%57%

70
Future Work
Along the same lines…– Variable-precision FPU– Other sections of the memory hierarchy– Recently-introduced stages (geometry,
tessellation, compute shaders)– GPGPU applications
Larger scale…– 2-bit granularity precision control– Scheduling for dynamic voltage/frequency scaling
(DVFS)– Architectural studies

71
List of Papers• Jeff Pool, Anselmo Lastra, and Montek Singh, “Lossless Compression of
Variable-Precision Floating-Point Buffers on GPUs,” ACM Interactive 3D Graphics and Games (I3D), 9-11 March 2012.
• Jeff Pool, Anselmo Lastra, and Montek Singh, “Precision Selection for Energy-Efficient Pixel Shaders,” High Performance Graphics, 5-7 Aug. 2011.
• Jeff Pool, Anselmo Lastra, and Montek Singh, “Power-Gated Arithmetic
Circuits for Energy-Precision Tradeoffs in Mobile Graphics Processing Units,” Journal of Low Power Electronics, Vol. 7, No. 2, 2011.
• Jeff Pool, Anselmo Lastra, and Montek Singh, “An Energy Model for Graphics Processing Units,” IEEE International Conference on Computer Design, 3-6 Oct. 2010.
• Jeff Pool, Anselmo Lastra, and Montek Singh, “Energy-Precision Tradeoffs in Mobile Graphics Processing Units,” IEEE International Conference on Computer Design, 12-15 Oct. 2008.

72
Acknowledgments
Advisers: Anselmo and MontekCommittee members: Dinesh Manocha, Steve
Molnar, John PoultonJustin Hensley for starting the variable-precision
work
Various folks around the department for their feedback
Family and friends for their support and encouragement
The NSF for funding

73
THANKS, QUESTIONS?

74
BACKUP
75
Programmer-Directed
Directed Static
Scene Precision PSNR Savings Precision Savings
SSAO 13.0 53.4 71% 20.1 49%
Parallax 15.2 39.7 61% 23.3 -2%
DoF 12.0 45.6 79% 18.5 33%
76
Results – Programmable UnitsOperation Energy (nJ)
add 0.443
mul 0.357
mad 0.455
rcp 2.440
exp 1.512
log 5.177
sin/cos 22.997
pow 16.366
Local load 1.490
Local store 1.490
Global load (coalesced) 8.390
Global store (coalesced) 5.190
Global load (uncoalesced) 67.400
Global store (uncoalesced) 42.700
Mem
ory
A
rith
meti
c

77
Results – Fixed-Function Units
Rasterization Off On
Energy/Pixel (pJ/P) 166.4 404.6
Rasterization Cost (pJ/P)
- 238.2
Texturing Mipmapping Energy/pixel (nJ/p)
Nearest - 13.3
Bilinear - 13.8
Nearest Nearest 7.07
Bilinear Nearest 7.76
Bilinear Linear 10.6
Qu
ali
ty
Low
High

78
Typical Cell Phone Energy Consumption
http://www.androidcentral.com/android-quick-app-juice-defender-ultimate
Varies drastically depending on workloadMore efficient GPU == more time watching movies, playing games,
HTML5 …
Advertised talk times dwarf video playback/game times!
http://www.howtogeek.com/wp-content/uploads/2010/08/image207.pnghttp://tapatalk.com/mu/5adc833a-beea-1bf3.jpg