el ´ ements d’optimisation´ - mathappl.polymtl.ca · el´ ements d’optimisation´ complement...
TRANSCRIPT

ELEMENTS D’OPTIMISATION
Complement au cours et au livre deMTH 1101 - CALCUL I
CHARLES AUDETDEPARTEMENT DE MATHEMATIQUES
ET DE GENIE INDUSTRIELECOLE POLYTECHNIQUE DE MONTREAL
Hiver 2011
1 Introduction a l’optimisationL’optimisation vise a resoudre des problemes ou l’on cherche a determiner parmi un grand nombre de solutionscandidates celle qui donne le meilleur rendement. Plus precisement, on cherche a trouver une solution satisfaisantun ensemble de contraintes qui minimise ou maximise une fonction donnee. L’application de l’optimisation esten expansion croissante et se retrouve dans plusieurs domaines. Les problemes consideres dans ce documents’ecrivent sous la forme standard
minx∈Rn
f (x)
s.c. x ∈ S(1)
ou x = (x1,x2, . . . ,xn)T est un vecteur de Rn, f : Rn 7→ R est la fonction que l’on desire minimiser (appelee
fonction objectif), S ⊆ Rn est l’ensemble dans lequel les points doivent appartenir, et s.c. est l’abbreviation desous la ou les contraintes.
La formulation (1) signifie que l’on cherche a trouver une solution du domaine realisable x∗ ∈ S dont la valeurde la fonction objectif est la plus petite.
Definition 1.1 Une solution x∗ ∈ S est un minimum global de la fonction f sur le domaine S si
f (x∗) ≤ f (x) ∀x ∈ S.
La valeur optimale est f (x∗).
Notez que le minimum global n’est pas necessairement unique, mais la valeur optimale l’est. Par exemple, le
2
probleme d’optimisation suivantminx∈R
sinx
possede une infinite de minima globaux, soient {3π
2 +2kπ : k ∈ Z} mais une seule valeur optimale: −1.Definissons maintenant la notion d’optimalite dans un voisinage restreint. Pour introduire cette idee, on va
definir Bε(x∗) comme etant l’ensemble des points de Rn dont la distance a x∗ est inferieure a ε, un scalaire positifdonne. Cet ensemble est communement appele une boule de rayon ε centree en x∗, et s’ecrit formellement:
Bε(x∗) = {x ∈ Rn : ‖x− x∗‖< ε}.
Definition 1.2 Une solution x∗ ∈ S est un minimum local de la fonction f sur le domaine S si
f (x∗) ≤ f (x) ∀x ∈ S∩Bε(x∗).
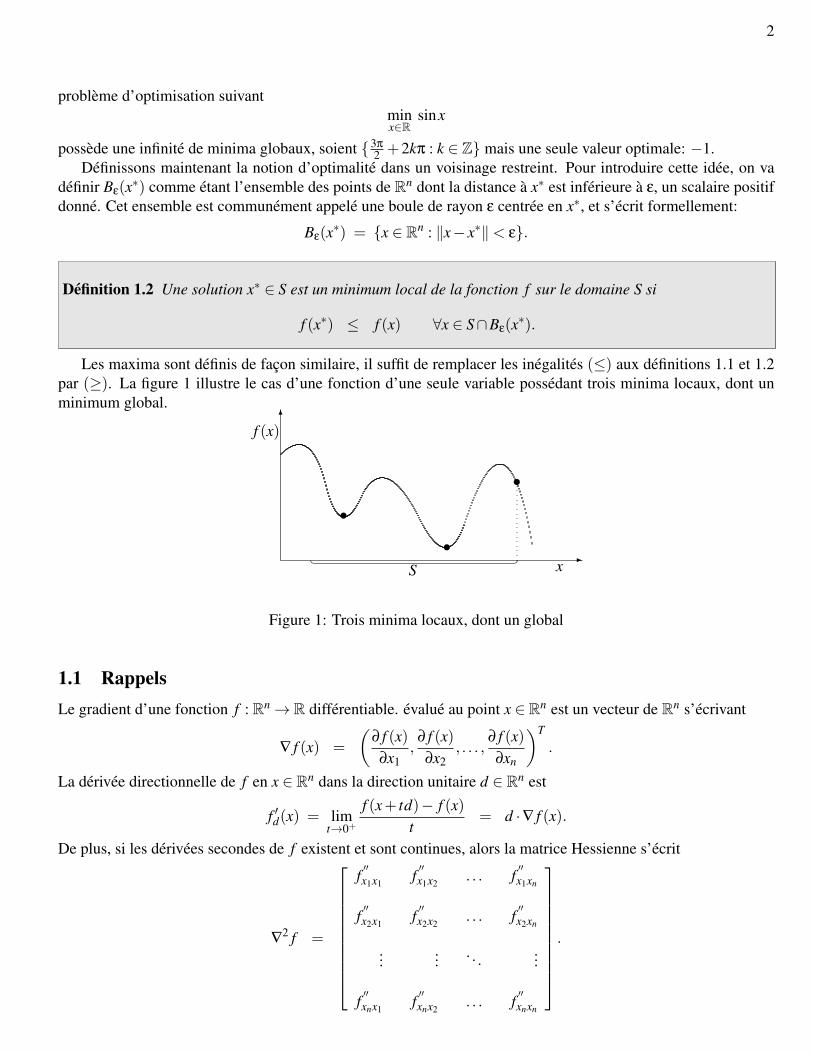
Les maxima sont definis de facon similaire, il suffit de remplacer les inegalites (≤) aux definitions 1.1 et 1.2par (≥). La figure 1 illustre le cas d’une fonction d’une seule variable possedant trois minima locaux, dont unminimum global.
-
6
x
f (x)
� �S
•
•
•
Figure 1: Trois minima locaux, dont un global
1.1 RappelsLe gradient d’une fonction f : Rn→ R differentiable. evalue au point x ∈ Rn est un vecteur de Rn s’ecrivant
∇ f (x) =
(∂ f (x)∂x1
,∂ f (x)∂x2
, . . . ,∂ f (x)∂xn
)T
.
La derivee directionnelle de f en x ∈ Rn dans la direction unitaire d ∈ Rn est
f ′d(x) = limt→0+
f (x+ td)− f (x)t
= d ·∇ f (x).
De plus, si les derivees secondes de f existent et sont continues, alors la matrice Hessienne s’ecrit
∇2 f =
f′′x1x1
f′′x1x2
. . . f′′x1xn
f′′x2x1
f′′x2x2
. . . f′′x2xn
...... . . . ...
f′′xnx1
f′′xnx2
. . . f′′xnxn
.

3
Exemple 1.3 Le gradient et la matrice Hessienne de la fonction f (x) =−(x1−2x2)2− ex1 sont
∇ f (x) = (−2(x1−2x2)− ex1, 4(x1−2x2))T , ∇
2 f (x) =[−2− ex1 4
4 −8
].
Des notions d’algebre serviront au classement des optima.
Definition 1.4 Une matrice symetrique A de dimension n×n est dite
semi-definie positive si yT Ay≥ 0 ∀y ∈ Rn,
definie positive si yT Ay > 0 ∀y 6= 0 ∈ Rn,
semi-definie negative si yT Ay≤ 0 ∀y ∈ Rn,
definie negative si yT Ay < 0 ∀y 6= 0 ∈ Rn.
Si aucune des proprietes ci-dessus n’est satisfaite, la matrice A est dite indefinie.
Une facon simple de verifier si une matrice est definie positive est de considerer les determinants des n sous-matrices suivantes de A
d1 = det([a11]),
d2 = det([
a11 a12a21 a22
]),
d3 = det
a11 a12 a13a21 a22 a23a31 a32 a33
, . . . , dn = det
a11 a12 . . . a1na21 a22 . . . a2n
...... . . . ...
an1 an2 . . . ann
.
Ces n determinants sont appeles les mineurs principaux dominants. Dans le cas ou la matrice est inversible, etdonc lorsque dn 6= 0, il est toujours facile de determiner si une matrice est definie positive, definie negative oubien indefinie. En effet, il suffit d’analyser le signe de chacun des mineurs principaux dominants.
Classement d’une matrice inversible.
Soit d1,d2, . . . ,dn les mineurs principaux dominants d’une matrice A symetrique inversible de dimension n×n,et e1,e2, . . . ,en les mineurs principaux dominants de la matrice −A.
• Si di > 0 pour chaque i ∈ {1,2, . . . ,n} alors A est definie positive;
• si e j > 0 pour chaque j ∈ {1,2, . . . ,n} alors A est definie negative;
• sinon A est indefinie.
La verification qu’une matrice singuliere est semi-definie positive, semi-definie negative ou indefinie requiertbeaucoup plus de calculs. Par exemple, pour montrer qu’une matrice est semi-definie positive, il ne suffit pas deverifier que les mineurs principaux dominants sont tous positifs ou nuls. Une possibilite consiste a analyser toutesvaleurs propres de la matrice. Ce sujet sera aborde dans des cours plus avances.

4
Exemple 1.5 (suite de l’exemple 1.3...) Les determinants des sous-matrices principales dominantes de
∇2 f (x) =
[−2− ex1 4
4 −8
].
sont respectivement
d1 = det([−2− ex1 ]) =−2− ex1 < 0 et d2 = det([−2− ex1 4
4 −8
])= (−2− ex1)(−8)− (4)(4) = 8ex1 > 0.
Leurs signes sont independant de la valeur de x. La matrice ∇2 f (x) n’est donc pas definie positive ni memesemi-definie positive.
Cependant, on remarque que les mineurs principaux dominants de la matrice −∇2 f (x) sont
e1 = det([2+ ex1 ]) = 2+ ex1 > 0 et e2 = det([
2+ ex1 −4−4 8
])= (2+ ex1)(8)− (−4)(−4) = 8ex1 > 0.
On peut alors conclure que la matrice−∇2 f (x) est definie positive, et donc la matrice ∇2 f (x) est definie negative,et ce pour toutes les valeurs de x.
2 Optimisation sans contraintesDans cette section nous considerons le cas particulier du probleme d’optimisation (1) sans contraintes ou S =Rn,c’est-a-dire:
minx∈Rn
f (x) (2)
ou f ∈ C 2 (cette notation signifie f est differentiable aux moins deux fois, et que ses derivees sont continues).
2.1 Conditions d’optimaliteSoit x∗ un minimum local de f sur S = Rn. La definition 1.2 assure qu’il existe un scalaire ε > 0 tel que
f (x∗) ≤ f (x) ∀x ∈ Bε(x∗),
en particulier pour n’importe quelle direction unitaire d ∈ Rn et scalaire t > 0 suffisamment petit, le point x =x∗+ td appartient a la boule Bε(x∗), et donc
f (x∗) ≤ f (x∗+ td).
Ceci implique que la derivee directionnelle de f en x∗ dans n’importe la direction unitaire d ∈ Rn satisfait
f ′d(x∗) = lim
t→0+
f (x∗+ td)− f (x∗)t
≥ 0.
Le resultat precedent est valide pour n’importe quelle direction unitaire d, et donc il est valide en particulier pourd =− ∇ f (x∗)
‖∇ f (x∗)‖ . Il s’ensuit que
0 ≤ f ′d(x∗) = d ·∇ f (x∗) = −∇ f (x∗) ·∇ f (x∗)
‖∇ f (x∗)‖= −‖∇ f (x∗)‖,

5
et donc ∇ f (x∗) = 0 (car on a montre que 0 ≤ −‖∇ f (x∗)‖, or ‖∇ f (x∗)‖ est toujours positif). Nous avons doncmontre la condition d’optimalite suivante.
Condition necessaire de premier ordre.
Si x∗ est un minimum local de la fonction f sur Rn, alors ∇ f (x∗) = 0 (c’est-a-dire, x∗ est un point critique).
Cette definition donne une condition necessaire mais pas suffisante. En effet, il est possible que le gradientsoit nul en un point et que ce point ne soit pas un minimum local (par exemple, ce point peut etre un maximumlocal ou un point de selle).
Un point critique x ∈ Rn est un point de selle si pour n’importe quel ε > 0, il existe deux points a ∈ Bε(x∗)et b ∈ Bε(x∗) qui soient tels que f (a) < f (x∗) < f (b). Un point de selle n’est donc ni un minimum local ni unmaximum local.
Les conditions de second ordre nous permettent de distinguer ces cas. Considerons encore une fois x∗ unminimum local de f sur S = Rn. A l’aide du developpement de Taylor d’ordre 2 de f autour du minimum localx∗ on obtient pour toute direction unitaire d ∈ Rn et pour t ∈ R suffisament petit
f (x∗) ≤ f (x∗+ td) ≈ f (x∗)+ td ·∇ f (x∗)+t2
2dT
∇2 f (x∗)d
= f (x∗)+t2
2dT
∇2 f (x∗)d.
Pour passer de la premiere a la deuxieme ligne, on a utilise le fait que ∇ f (x∗) = 0 en un minimum local. Ensimplifiant cette derniere expression, et en divisant par t2 > 0 on obtient
12
dT∇
2 f (x∗)d ≥ 0,
une expression independante de t. On a alors la condition suivante.
Condition necessaire de second ordre.Si x∗ est un minimum local de la fonction f sur Rn, alors ∇ f (x∗) = 0 et yT ∇2 f (x∗)y ≥ 0 pour tout y ∈ Rn
(c’est-a-dire, la matrice Hessienne ∇2 f (x∗) est semi-definie positive).
La contraposee de cette condition assure que si la matrice des derives secondes ∇2 f (x∗) n’est pas semi-definie positive, alors x∗ n’est pas un minimum local de f . De facon similaire, si la matrice n’est pas semi-definienegative, alors x∗ n’est pas un maximum local de f . Et donc, si la matrice est indefinie en un point critique x∗ dela fonction f , alors x∗ est un point selle. En effet, si la matrice est indefinie alors elle n’est ni semi-definie positiveni semi-definie negative, et consequemment x∗ n’est ni un minimum ni un maximum local de f .
De plus, si la condition de second ordre est strictement satisfaite, on obtient la condition suffisante suivante.
Condition suffisante de second ordre.Soit x∗ ∈ Rn. Si ∇ f (x∗) = 0, et si yT ∇2 f (x∗)y > 0 pour tout y ∈ Rn \ {0} (c’est-a-dire, la matrice Hessienne∇2 f (x∗) est definie positive), alors x∗ est un minimum local de la fonction f sur Rn.
Nous pouvons specialiser les conditions d’optimalites de deuxieme ordre aux fonctions de deux variables(voir les exercices).
Pour s’attaquer a un probleme d’optimisation, on procedera de la facon suivante. En un premier temps, onutilisera les conditions necessaires du premier ordre pour identifier tous les points critiques de f . C’est-a-dire,

6
on trouvera tous les points ou le gradient s’annule. Ensuite, pour chacun de ces points, on evaluera la matricedes derivees secondes, et on utilisera les conditions d’optimalite de deuxieme ordre pour classer les points. Onne pourra conclure seulement lorsque cette matrice sera inversible. Et dans ce cas, si elle est definie positive ils’agira d’un minimum local, si elle est definie negative il s’agira d’un maximum local, et autrement (c’est-a-diresi la matrice est indefinie) il s’agira d’un point selle.
Exemple 2.1 Considerons la fonction de trois variables f (x) = 6x21 + x3
2 +6x1x2 +3x22 +
14x4
3−13x3
3. Nous allonsidentifier tous les points critiques de cette fonction, et allons utiliser les conditions d’optimalite afin de determinerleur nature (minimum, maximum ou point de selle). Le gradient et la matrice Hessienne de cette fonction sont
∇ f (x) =
12x1 +6x23x2
2 +6x1 +6x2x3
3− x23
et ∇2 f (x) =
12 6 06 6x2 +6 00 0 3x2
3−2x3
.• Etape 1: Identification des points critiques.
La condition necessaire de premier ordre ∇ f (x1,x2,x3) = (0,0,0)T nous permet d’identifier quatre pointscritiques: xA = (0,0,0)T , xB = (0,0,1)T , xC = (1
2 ,−1,0)T et xD = (12 ,−1,1)T .
• Etape 2: Nature des points critiques.Les conditions de deuxieme ordre nous permettent de classer certains de ces points critiques.
Point ∇2 f −∇2 fConclusion
critique d1 d2 d3 e1 e2 e3
xA = (0,0,0)T 12 36 0 -12 36 0 matrice singuliere⇒ indetermine
xB = (0,0,1)T 12 36 36 -12 36 36 di > 0⇒ minimum local
xC = (12 ,−1,0)T 12 -36 0 -12 -36 0 matrice singuliere⇒ indetermine
xD = (12 ,−1,1)T 12 -36 -36 -12 -36 36
matrice inversibleet di 6> 0,ej 6> 0⇒ point selle
Cette analyse permet d’identifier un minimum local XB et un point selle xD. Une analyse plus approfondie seraitnecessaire pour classer les deux points critiques xA et xC.
2.2 Methode du gradientA partir d’un point initial connu x0 ∈ Rn, la methode du gradient genere une suite de points x0,x1,x2, . . . qui onl’espere s’approchera d’un minimum local d’une fonction f . Nous designerons par xk ∈ Rn le point considere al’iteration k. Notez qu’ici le nombre k designe un indice, et non un exposant.
A l’iteration k, la methode du gradient considere une solution xk ∈ Rn et une direction dk ∈ Rn dans laquellela fonction f decroıt, c’est-a-dire que dk est une direction de descente pour f en xk. Nous etudierons dans cettesection la question de trouver un scalaire α > 0 qui est tel que la valeur de f (xk +αdk) est petite. Pour ce faire,nous definissons une fonction d’une seule variable h : R→ R comme suit
h(α) = f (xk +αdk).
On observe que puisque dk est une direction de descente pour f alors h′(0)< 0. Idealement, la recherche dans ladirection dk consiste a determiner une petite valeur de α > 0 telle que h′(α) = 0.

7
La methode du gradient pour la resolution du probleme d’optimisation (2) sans contraintes peut s’ecrire de lafacon suivante.
METHODE DU GRADIENT (pour un probleme de minimisation)
• INITIALISATION:Soit x0 ∈ Rn un estime initial de la solution. Poser le compteur k← 0.
• EVALUATION DU GRADIENT:Calculer la direction dk = −∇ f (xk). Si ‖dk‖ = 0 alors on termine avec un point critique xk. Sinon onpoursuit a la prochaine etape.
• RECHERCHE DANS LA DIRECTION DE DESCENTE dk:Soit xk+1 la solution produite par la resolution du probleme de minimisation a une variable
minα≥0
h(α) ou h(α) = f (xk +αdk).
Poser k← k+1, et retourner a l’etape precedente.
Il est mentionne dans l’algorithme que dk = −∇ f (xk) 6= 0 est une direction de descente, c’est-a-dire unedirection dans laquelle la valeur de la fonction f decroıt. En effet, par le developpement de Taylor on obtient pourdes petites valeurs de α > 0
f (xk +αdk) ≈ f (xk)+α(dk)T∇ f (xk)
= f (xk)−α‖∇ f (xk)‖2 < f (xk).
Exemple 2.2 Considerons la minimisation de la fonction f (x) = (a−2)2+(b−3)2, avec x = (a,b)T , a partir dela solution initiale x0 = (a0,b0)T = (0,0)T . La premiere iteration de la methode du gradient avec une recherchedans la direction dk se calcule comme suit. Posons k = 0 et
dk = −∇ f (xk) = −[
2(ak−2)2(bk−3)
]=
[46
].
On cherche la valeur du scalaire positif α qui minimise
h(α) = f (xk +αdk) = f (4α,6α) = (4α−2)2 +(6α−3)2.
On peut aisement minimiser la fonction h, car c’est une simple fonction quadratique. En effet, la conditionnecessaire du premier ordre ∇h(α) = 0 assure que α = 1
2 et donc
x1 = x0 +12
d0 = (0,0)T +12(4,6)T = (2,3)T .
De plus la condition suffisante du second ordre assure que ce point est un minimum local de h.La deuxieme iteration de la methode du gradient donne d1 =−∇ f (x1) = (0,0)T . L’algorithme arrete donc a
un point critique, et comme ∇2 f (x) est definie positive pour toute valeur de x (les determinants des sous-matricesprincipales sont 2 > 0 et 4 > 0) le point x1 est un minimum global.
Dans l’exemple precedent la direction opposee au gradient dk =−∇ f (xk) pointait dans la direction du mini-mum global, d’ou la convergence immediate. Normalement la convergence requiert beaucoup plus d’iterations.

8
Lorsque la minimisation de la fonction h est faite de facon exacte, les directions consecutives dk et dk+1
generes par la methode du gradient sont necessairement perpendiculaires. En effet, lorsqu’on prend un pas op-timal on va s’arreter de facon tangente a une courbe de niveau. A l’iteration suivante, on va se deplacer dans ladirection du gradient, perpendiculaire a cette courbe de niveau. La figure 2 illustre les trois premiers pas produitspar la methode du gradient sur un exemple ou seules les courbes de niveau de f sont donnees.
Figure 2: Les directions produites par la methode du gradient sont perpendiculaires.
Remarque: La methode du gradient peut s’appliquer directement a un probleme de maximisation d’une fonctionf . Il suffit alors de prendre d = ∇ f (xk) (au lieu du negatif du gradient), et de maximiser la fonction h(α) (au lieude la minimiser).
2.3 ExercicesDe breves solutions aux exercices se trouvent a la fin du document.
Exercice 2.1
Specialisez les conditions d’optimalites de deuxieme ordre pour classer le point critique (a,b) d’une fonctionf (x,y) deux fois differentiable sans contraintes.

9
Exercice 2.2
Soit la fonction f (x,y) = 3x− x3−2y2 + y4.
a) Sans faire l’analyse de points critiques indiquez si la fonction possede un minimum global et un maximumglobal.
b) Identifiez tous les points critiques de f (x,y) et determinez leur nature.
c) Parmi les points suivants, lequel peut etre obtenu en une iteration de l’application de la methode du gradientau probleme de maximisation a partir du point (x0, y0) = (0, 1
2).
(x1, y1) = (−1, 1) (x1, y1) = (1, 52)
(x1, y1) = (−1, −32) (x1, y1) = (1, 0).
Exercice 2.3
On applique la methode du gradient afin de minimiser une fonction de trois variables f (x) a partir du pointx0 = (2,2,1)T . On obtient que le gradient evalue en ce point est ∇ f (2,2,1) = (3,3,−1)T . A partir du grapheci-dessous,
Figure 3: Fonction h(α) = f (2−3α, 2−3α, 1+α).
a) Estimez f (x0).
b) Donnez la valeur de la derivee directionnelle de f en x0 dans la direction v = (−3,−3,1)T .
c) Donnez les coordonnees du prochain point, x1, produit par la methode du gradient.
d) Estimez f (x1).
e) Donnez la valeur de la derivee directionnelle de f en x1 dans la direction v = (−3,−3,1)T .

10
Exercice 2.4
On utilise la methode du gradient afin de resoudre un probleme de minimisation sans contraintes d’une fonctionf (x,y). Chacune des trois figures suivantes represente des courbes de niveau de f , ainsi qu’une suite de pointsgeneres par la methode du gradient. Les echelles en x et y sont identiques. Quels points sont ceux produits par lamethode du gradient si celui d’indice zero est le point de depart.
i) P0,P1,P2,P3 ii) Q0,Q1,Q2,Q3 iii) R0,R1,R2,R3.
Figure 4: Methode du gradient.
Exercice 2.5
Repondez par VRAI ou FAUX.
a) (x,y,z) = (0,0,0) est un point de selle de la fonction f (x,y,z) = x4− y4 + z4.
b) Soit x ∈ R3 un point critique d’une fonction differentiable tel que ∇2 f (x) =
1 0 00 2 30 3 0
.
Alors x est necessairement un point de selle.

11
3 Optimisation sous contraintesDans la plupart des problemes d’optimisation, les variables ne sont pas libres de prendre n’importe quelle valeur.Elles sont habituellement restreintes a un domaine. Dans cette section, nous nous penchons sur les problemessous la forme generale (1). Le resultat suivant, cite sans preuve, sera frequemment utilise.
Theoreme 3.1 Si l’ensemble S est ferme et borne, et si la fonction f est continue sur S, alors il existe unminimum global atteint en un point de S et un maximum global atteint en un point de S.
3.1 Multiplicateur de Lagrange pour une seule contrainte d’egaliteDans cette section nous considerons le cas particulier du probleme d’optimisation (1)
minx
f (x)
s.c. x ∈ S
S = {x ∈ Rn : h(x) = k}ou f : Rn→ R et h : Rn→ R sont differentiables, et ou k est une constante donnee.
Lagrange a montre qu’a l’optimalite, le vecteur gradient de la fonction objectif f doit etre perpendiculaire ala surface de niveau de la contrainte.
Condition necessaire de premier ordre de Lagrange.Si x∗ est un minimum local de la fonction f dans S, et si ∇h(x∗) 6= 0, alors h(x∗) = k, et de plus il existe unscalaire λ ∈ R pour lequel
∇ f (x∗) = λ∇h(x∗).
Un point x∗ satisfaisant cette condition est appele un point critique.
Exemple 3.2 Soit le probleme d’optimisation suivant :
minx
3x1−2x2
s.c. x21 +2x2
2 = 44.
La condition necessaire d’optimalite fait en sorte que l’on doive resoudre le systeme:
h(x∗) = k : (x∗1)2 +2(x∗2)
2 = 44
∂ f (x∗)∂x1
= λ∂h(x∗)
∂x1: 3 = λ(2x∗1)
∂ f (x∗)∂x2
= λ∂h(x∗)
∂x2: −2 = λ(4x∗2)
Les solutions de ce systeme sont
(x1,x2,λ) = (6,−2,14) avec f (6,−2,
14) = 22;
(x1,x2,λ) = (−6,2,−14) avec f (−6,2,
−14) =−22.

12
Il n’y a pas d’autres points critiques et donc le theoreme 3.1 nous assure que (6,−2, 14) est le maximum global et
que (−6,2, −14 ) est le minimum global.
Lorsque nous resolvons un probleme d’optimisation on obtient une valeur de λ en plus de la solution optimale.Cette valeur peut etre interpretee de la facon suivante. Considerons la fonction d’une variable v(k) qui, pour un kdonne retourne la valeur optimale du probleme
minx
f (x)
s.c. h(x) = k.
Comment est-ce que la fonction v varie lorsque la valeur k varie ? Pour un k donne, definissons x(k) ∈Rn commeetant la solution optimale du probleme ci-dessus, c’est-a-dire,
v(k) = f (x(k)) et h(x(k)) = k.
Observons aussi que ∂ f∂xi
= λ∂h∂xi
pour i = 1,2, . . . ,n. Pour mesurer la variation de v(k), on cherche alors a calculer
v′(k) =dvdk
=∂ f∂x1
dx1
dk+
∂ f∂x2
dx2
dk+ . . .+
∂ f∂xn
dxn
dk
= λ∂h∂x1
dx1
dk+ λ
∂h∂x2
dx2
dk+ . . .+ λ
∂h∂xn
dxn
dk
= λ
(∂h∂x1
dx1
dk+
∂h∂x2
dx2
dk+ . . .+
∂h∂xn
dxn
dk
)= λ
dhdk
= λ.
Et donc le multiplicateur de Lagrange λ represente le taux de variation de la valeur optimale v lorsque k augmente.On peut alors approcher la fonction v par son polynome de Taylor de degre un P1(k) autour de k0:
v(k) ≈ P1(k) = v(k0)+ v′(k0)(k− k0) = v(k0)+λ(k− k0).
Exemple 3.3 (suite de l’exemple 3.2...) Reprenons le dernier exemple. Estimez la valeur optimale du problemed’optimisation ou la contrainte x2 +2y2 = 44 est remplacee par x2 +2y2 = 45.
Ici, k0 = 44 et k = 45. Au minimum on avait λ = v′(44) = −14 et f = v(44) =−22. Donc la valeur optimale
serait approximativement
v(45) =
(minx,y
3x−2y
s.c. x2 +2y2 = 45
)≈ P1(45) = v(44)+ v′(44)(45−44) =−22.25.
3.2 Optimisation sous une contrainte d’inegaliteDans cette section nous considerons le cas particulier du probleme d’optimisation (1)
minx
f (x)
s.c. x ∈ S
S = {x ∈ Rn : h(x)≤ k}
avec f : Rn→ R et h : Rn→ R sont differentiables, et ou k est une constante donnee.Encore une fois, le theoreme 3.1 nous assure que si S est ferme et borne alors il contiendra a la fois le minimum
et le maximum global (remarquez il est possible qu’il y ait plus d’un minimum ou maximum global). Il y a deux

13
possibilite pour chacun de ceux-ci. Ou bien ils appartiendront a l’interieur strict de S ou bien ils se trouveront surla frontiere de S (l’interieur strict de S est {x ∈ Rn : h(x)< k}, et la frontiere de S est {x ∈ Rn : h(x) = k}).
L’analyse de ce probleme se fait en trois etapes. Premierement nous allons identifier tous les points ou legradient de f s’annule, et allons retenir seulement ceux appartenant a S. Deuxiemement nous allons appliquer lamethode du multiplicateur de Lagrange ou nous remplacerons l’inegalite par une egalite. Enfin, le minimum et lemaximum global sera alors l’un des points enumeres. Il suffira donc d’evaluer f en tous ces points.
Exemple 3.4 Resolvons (max
x,y(x−1)2 +(y−2)2
s.c. x2 + y2 ≤ 45.
)• Etape 1: Points critiques a l’interieur strict de S.
Trouvons les points ou ∇ f (x,y) = (0,0):∂ f (x,y)
∂x = 2(x−1) = 0 ⇒ x = 1; ∂ f (x,y)∂y = 2(y−2) = 0 ⇒ y = 2.
En ce point h(1,2) = 12 + 22 = 5 < 45, et donc le point critique (1,2) se trouve a l’interieur strict dudomaine S.
• Etape 2: Points critiques sur la frontiere de S.Multiplicateur de Lagrange :
h(x,y) = k : x2 + y2 = 45
∂ f (x,y)∂x = λ
∂h(x,y)∂x : 2(x−1) = 2λx
∂ f (x∗)∂y = λ
∂h(x,y)∂y : 2(y−2) = 2λy
Les solutions sont (x,y) = (3,6) et (x,y) = (−3,−6), qui sont alors deux points critiques.
• Etape 3: Evaluation de f aux points critiques.f (1,2) = 0, f (3,6) = 20, f (−3,−6) = 80.Ainsi la valeur minimale de f est 0 et la valeur maximale est de 80.
3.3 Multiplicateurs de Lagrange pour plusieurs contraintes d’egaliteConsiderons maintenant la formulation generale du probleme d’optimisation (1)
minx
f (x)
s.c. x ∈ S
S = {x ∈ Rn : h j(x) = k j, j = 1,2, . . . ,m}avec f : Rn→ R et h j : Rn→ R sont differentiables, et ou les k j sont des constantes donnees.
Condition necessaire de premier ordre de Lagrange.Si x∗ est un minimum local de la fonction f dans S ou {∇h j(x∗) : j = 1,2, . . . ,m} est un ensemble lineairementindependant, alors h j(x∗) = k j pour j = 1,2, . . . ,m, et de plus il existe un vecteur λ ∈ Rm pour lequel
∇ f (x∗) =m
∑j=1
λ j∇h j(x∗).

14
Exemple 3.5 Soit les trois problemes d’optimisation suivants :
minx
x1− x2 + x3
s.c. x21 + x2
2 + x23 = 1
x21 +(x2−1)2 +(x3−2)2 = 4,
minx
x1− x2 + x3
s.c. x21 + x2
2 + x23 = 1.01
x21 +(x2−1)2 +(x3−2)2 = 4
etmin
xx1− x2 + x3
s.c. x21 + x2
2 + x23 = 1
x21 +(x2−1)2 +(x3−2)2 = 3.9.
Resoudre le premier, et donnez un estime de la valeur optimale des deux autres. La condition necessaired’optimalite fait en sorte que l’on doive resoudre le systeme:
h1(x∗) = k1 : (x∗1)2 +(x∗2)
2 +(x∗3)2 = 1
h2(x∗) = k2 : (x∗1)2 +(x∗2−1)2 +(x∗3−2)2 = 4
∂ f (x∗)∂x1
= λ1∂h1(x∗)
∂x1+λ2
∂h2(x∗)∂x1
: 1 = 2λ1x∗1 +2λ2x∗1
∂ f (x∗)∂x2
= λ1∂h1(x∗)
∂x2+λ2
∂h2(x∗)∂x2
: −1 = 2λ1x∗2 +2λ2(x∗2−1)
∂ f (x∗)∂x3
= λ1∂h1(x∗)
∂x3+λ2
∂h2(x∗)∂x3
: 1 = 2λ1x∗3 +2λ2(x∗3−2).
La troisieme equation assure que x∗1 6= 0, et donc on peut diviser par cette variable pour obtenir 2λ1 +2λ2 =1x∗1
.En substituant dans les quatrieme et cinquieme equations, on obtient
−1 =x∗2x∗1−2λ2 et 1 =
x∗3x∗1−4λ2 et donc 4λ2 =
2x∗2x∗1
+2 =x∗3x∗1−1.
Prenons maintenant la difference entre les deux premieres equations, et simplifions les termes quadratiques. Onobtient alors que les solutions doivent satisfaire l’egalite lineaire x∗2 +2x∗3 = 1. et donc on peut fixer x∗3 =
12 −
x∗22 .
En substituant cette valeur dans 2x∗2x∗1
+ 2 =x∗3x∗1− 1 on trouve x∗2 = 1
5 −6x∗15 . Les troisieme et quatrieme equations
donnent les multiplicateurs
λ1 =1
10− 2
5x∗1et λ2 =−
110
+1
10x∗1.
La premiere equation se simplifie en 14(x∗1)2
5 + 15 = 1 et admet les deux solutions −
√27 et
√27 . Le tableau 1 donne
les valeurs des autres variables. Il n’y a pas d’autres points critiques et donc le theoreme 3.1 assure que lapremiere solution est le maximum global et la deuxieme le minimum global.
x∗1 x∗2 x∗3 λ1 λ2 f (x∗)
−√
27
635
√14+ 1
5 − 335
√14+ 2
5 −15
√14+ 1
10 − 120
√14− 1
10 −25
√14+ 1
5 ≈−1.2967√27 − 6
35
√14+ 1
5335
√14+ 2
515
√14+ 1
101
20
√14− 1
1025
√14+ 1
5 ≈ 1.6967
Tableau 1: Solutions

15
Le deuxieme probleme d’optimisation est identique au premier, sauf que le terme k1 passe de 1 a 1.1. On peutalors estimer que la valeur optimale du second probleme est
v1(1.1) ≈ v1(1)+ v′1(1)(1.1−1) = v1(1)+λ1(1.1−1)
= −25
√14+
15+
(−1
5
√14+
110
)1
10≈ −1.3615.
Le calcul exact de la valeur optimale pour k1 = 1.1 donne −1.3593.Le troisieme probleme d’optimisation est identique au premier, sauf que le terme k2 passe de 4 a 3.9. On peut
alors estimer que la valeur optimale du troisieme probleme est
v2(3.9) ≈ v2(4)+ v′2(4)(3.9−4) = v2(4)+λ2(3.9−4)
= −25
√14+
15+
(− 1
20
√14− 1
10
)−110
≈ −1.2680.
Le calcul exact de la valeur optimale pour k2 = 3.9 donne −1.2674.
3.4 ExercicesExercice 3.1
Le diagramme de courbes de niveau ci-dessous illustre au point P, le minimum qu’atteint f (x,y) sous la contrainteg(x,y) = 1. La courbe en trait plein represente la courbe de niveau f (x,y) = 10 et la courbe en pointille la courbede niveau g(x,y) = 1. Les gradients sont egalement representes.
Figure 5: Courbes de niveau.
a) En observant le graphique, determinez la valeur du multiplicateur de Lagrange λ associe au point P.
b) Donnez une approximation de la valeur minimale qu’atteint la fonction f (x,y) sous la contrainte g(x,y) =0.9.

16
Exercice 3.2
Trouvez les valeurs minimale et maximale de
a) f (x,y) = xy sous la contrainte x2 +2y2 ≤ 1;
b) f (x,y,z) = x+ y+ z sous les contraintes x2 + y2 + z2 = 1 et x− y = 1.
Exercice 3.3
Une ville B est a 10 km a l’est d’une ville A et une ville C est a 3 km au nord de la ville B. Voir la figure.
Figure 6: Villes A,B et C.
On veut realiser un projet d’autoroute entre les villes A et C. Le cout de 1 km d’autoroute le long de la routeexistante entre A et B est de 400 000 $, alors que le cout de 1 km d’autoroute ailleurs est de 500 000 $. On desiredeterminer ou doit se situer le point pivot P (c’est-a-dire, a quelle distance de A, l’autoroute doit bifurquer pouretre construite en plein champ) pour minimiser le cout de realisation de l’autoroute.
a) Formulez cette question en un probleme de minimisation d’une fonction de deux variables f (x,y) soumisea une contrainte non lineaire h(x,y) = 9. (Ne pas resoudre)
b) Resolvez le probleme obtenu en a) par la methode des multiplicateurs de Lagrange.
c) On mesure a nouveau, et on realise que la distance entre B et C est de 2.9 km et non 3 km. Estimez le coutoptimal en vous servant du resultat en b).
Exercice 3.4
Deux generateurs utilisent du gaz naturel pour produire de l’electricite. L’energie produite est de 2 ln(1+ x)pour le generateur 1 et de 4ln(1+ y) pour le generateur 2, ou x et y sont les quantitees de gaz brulees dans lesgenerateurs 1 et 2. Le volume total de gaz disponible est de 19.
a) Modelisez la question d’identifier les quantitees x et y maximisant l’energie totale comme un problemed’optimisation soumise a une contrainte d’egalite. (Ne pas resoudre)
b) Resolvez le probleme obtenu en a) par la methode des multiplicateurs de Lagrange.
c) Suite a une modification de l’offre, on se rend compte que le volume total de combustible est de 19.5 au lieude 19. Sans resoudre le nouveau probleme d’optimisation, estimez l’augmentation de la quantite d’energieproduite.

17
Solutions
Section 2 : Optimisation sans contraintes2. 1 Soit (a,b) un point critique. Alors ∇ f (a,b) = (0,0). Posons d1 = f
′′xx(a,b) le determinant de la premiere
matrice principale du hessien, et d2 = f′′xx(a,b) f
′′yy(a,b)− ( f
′′xy(a,b))
2 le determinant de la deuxieme matriceprincipale.
Si d1 > 0 et d2 > 0, alors (a,b) est un minimum local de f ;si d1 < 0 et d2 > 0, alors (a,b) est un maximum local de f ;
si d2 < 0, alors (a,b) est un point de selle de f ;si d2 = 0, alors le test n’est pas concluant pour classer (a,b).
Remarquez que l’encadre est equivalent a celui de la page 812 du livre. Le livre utilise cependant uneterminologie differente, en affirmant que f (a,b) est un minimum ou un maximum ou un point de selle, Nousadoptons la terminologie plus courante affirmant que c’est plutot (a,b) qui est le minimum ou un maximum ouun point de selle.
2. 2 a) Nonb) (1,0) max local; (−1,0) point selle; (1,1) point selle;(1,−1) point selle; (−1,1) min local; (−1,−1) min local.c) (1, 0).
2. 3 a) 22.3; b) −√
19; c) (45 ,
45 ,
75)
T ; d) 20; e) 0.
2. 4 i).
2. 5 a) VRAI b) VRAI.
Section 3 : Optimisation sous contraintes3. 1 a) −1
2 ; b) 10.05.
3. 2 a) (min,max) = (−√
24 ,√
24 ); b) (min,max) = (− 3√
6, 3√
6).
3. 3 a)
(minx,y
4×105(10− y)+5×105x
s.c. x2− y2 = 9
); b) y = 4; c) f ≈ 4 870 500$.
3. 4 a)
(max
x,y2ln(1+ x)+4ln(1+ y)
s.c. x+ y = 19.
); b) (x,y) = (6,13); c) 1
7 .