efficientsuperresolutionbyrecursive aggregation
TRANSCRIPT

Efficient Super Resolution by RecursiveAggregation
Zhengxiong Luo1,2,3 , Yan Huang1,2 , Shang Li2,3 , Liang Wang1,4,5 , and Tieniu Tan1,4
1Center for Research on Intelligent Perception and Computing (CRIPAC) National Laboratory of Pattern Recognition (NLPR)
2Institute of Automation, Chinese Academy of Sciences (CASIA)3School of Artificial Intelligence, University of Chinese Academy of Sciences (UCAS)
4Center for Excellence in Brain Science and Intelligence Technology (CEBSIT)5Chinese Academy of Sciences, Artificial Intelligence Research (CAS-AIR)
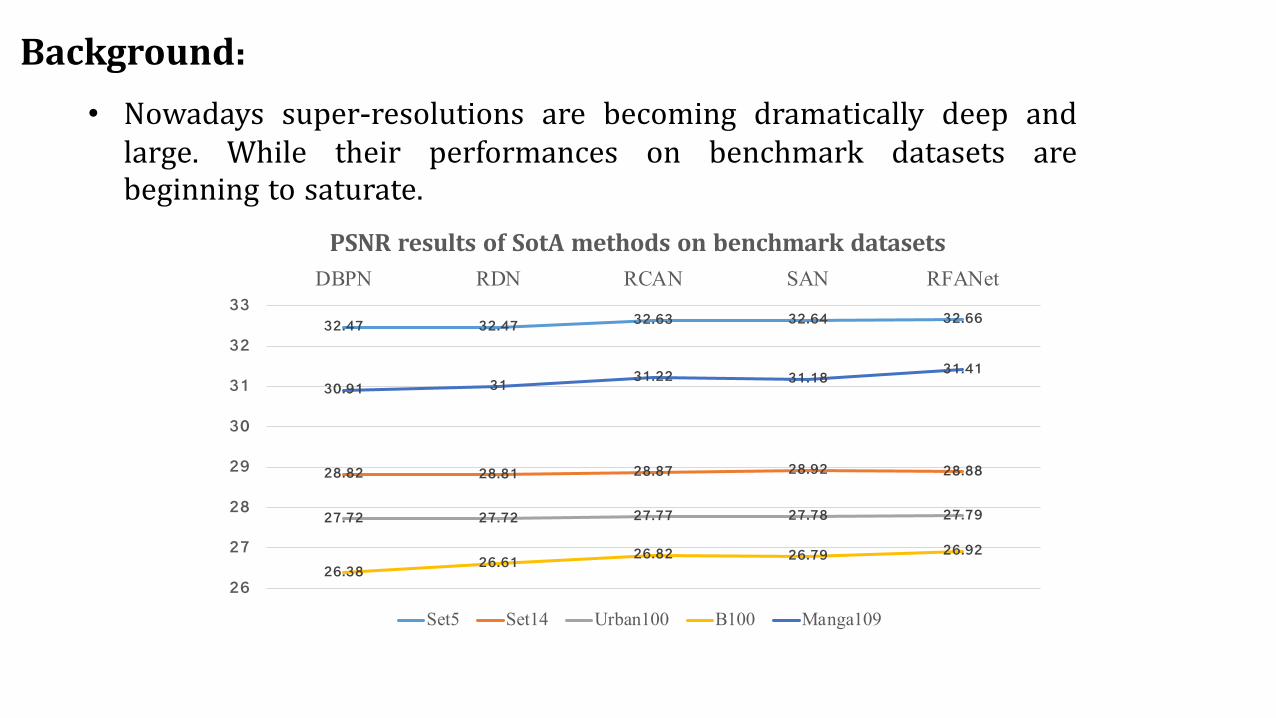
Background:• Nowadays super-resolutions are becoming dramatically deep andlarge. While their performances on benchmark datasets arebeginning to saturate.
32.47 32.47 32.63 32.64 32.66
28.82 28.81 28.87 28.92 28.88
27.72 27.72 27.77 27.78 27.79
26.38 26.61 26.82 26.79 26.92
30.91 31 31.22 31.18 31.41
26
27
28
29
30
31
32
33DBPN RDN RCAN SAN RFANetPSNR results of SotA methods on benchmark datasets
Set5 Set14 Urban100 B100 Manga109
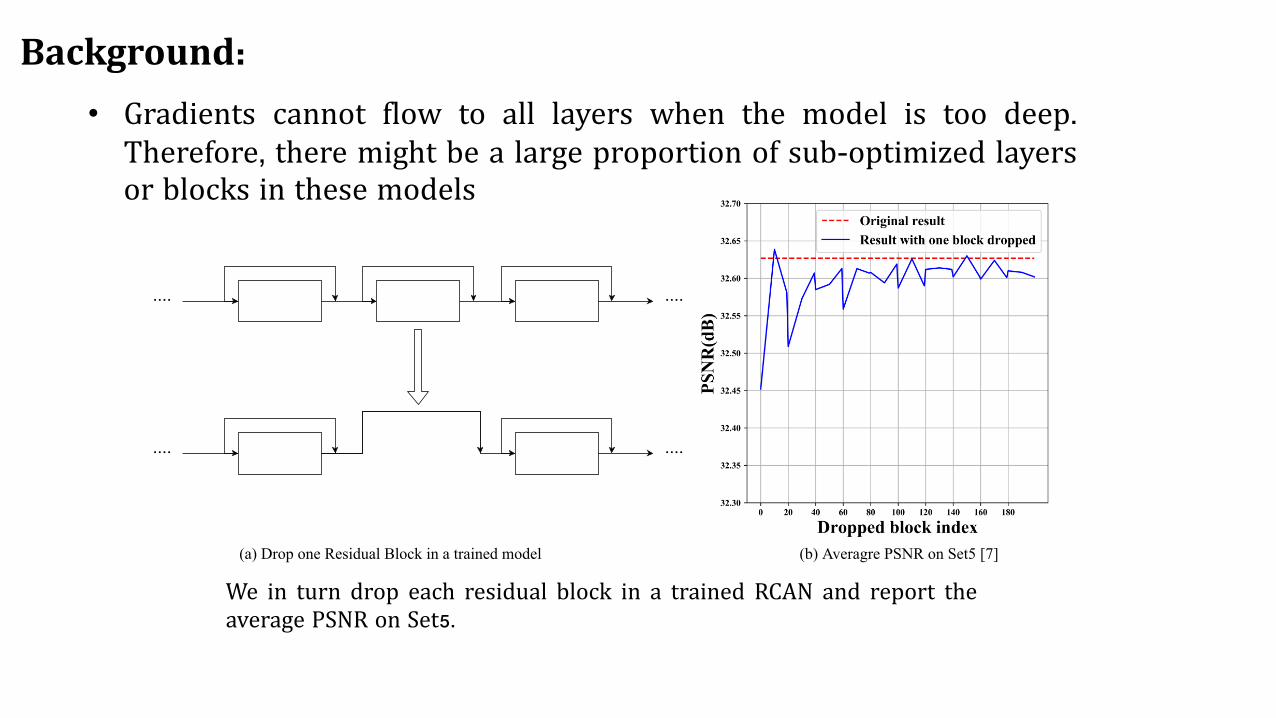
Background:
........
........
(a) Drop one Residual Block in a trained model (b) Averagre PSNR on Set5 [7]
We in turn drop each residual block in a trained RCAN and report theaverage PSNR on Set5.
• Gradients cannot flow to all layers when the model is too deep.Therefore, there might be a large proportion of sub-optimized layersor blocks in these models
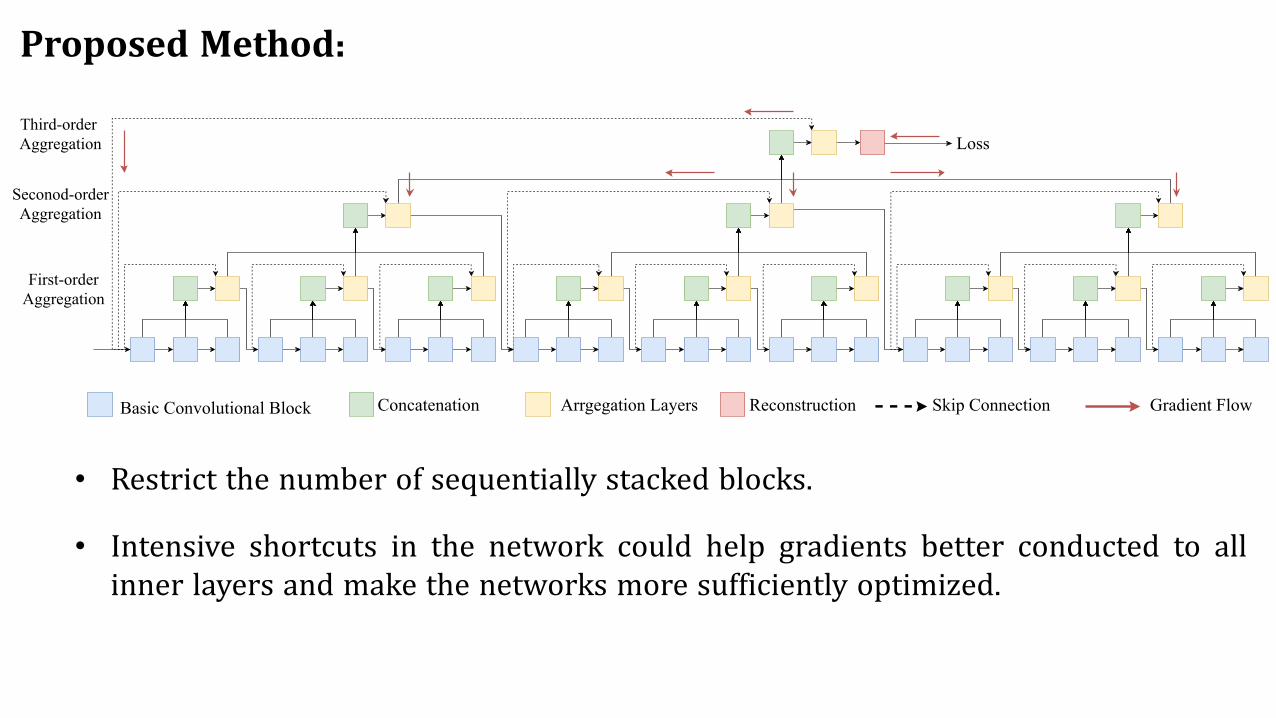
Proposed Method:
Basic Convolutional Block Concatenation Arrgegation Layers Reconstruction
First-orderAggregation
Seconod-orderAggregation
Third-order Aggregation Loss
Skip Connection Gradient Flow
• Restrict the number of sequentially stacked blocks.
• Intensive shortcuts in the network could help gradients better conducted to allinner layers and make the networks more sufficiently optimized.
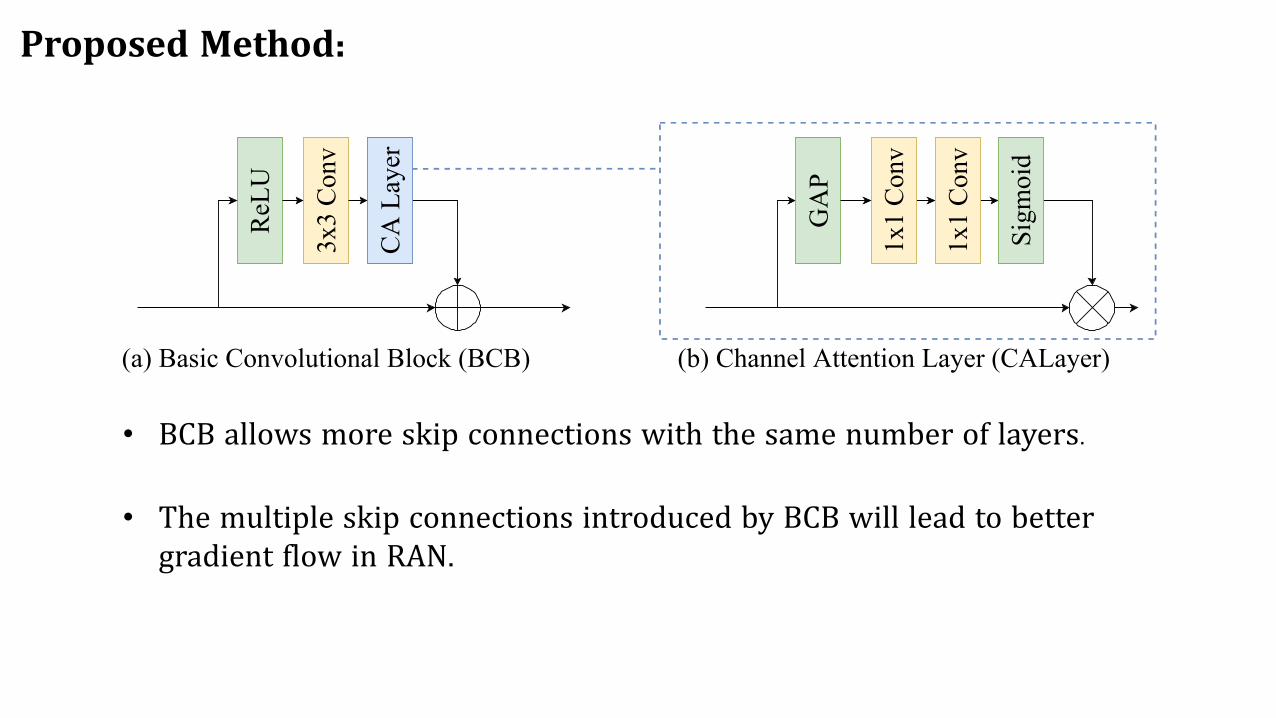
Proposed Method:
ReL
U
3x3
Con
v
CA
Lay
er(a) Basic Convolutional Block (BCB) (b) Channel Attention Layer (CALayer)
GA
P
1x1
Con
v
1x1
Con
v
Sigm
oid
• BCB allows more skip connections with the same number of layers.
• The multiple skip connections introduced by BCB will lead to bettergradient flow in RAN.

Proposed Method:
Con
cat
1x1
Con
v
3x3
Con
v
FAB
Conv Block
Feature Map
Upscale
Tensor Operation
Mapping Stage
FAB FAB
Extract Shallow Features
ReconstructHR images
(a) Overall structure of second order RAN
(b) Structure of First-order Aggreagtion Block (FAB)
(c) Structure of Reconstruction Block
Pixe
lSh
uffle
3x3
Con
v
3x3
Con
v
x4
3x3
Con
v
x2 x3
Pixe
lSh
uffle
Pixe
lSh
uffle
Reconstruction
BCB BCB BCB
Con
cat
1x1
Con
v
First-order Aggreagtion Block (FAB)
3x3
Con
v
Aggregation Layers
3x3
Con
v
Details about a second-order RAN. (a) shows the overall structure of our second order RAN. (b) shows thestructure of first-order aggregation block, which is constructed by basic convolutional blocks (BCBs). (c) showsthe structure of our reconstruction module. Two PixelShuffle layers are used for ×4 and one is used for ×2 and×3.

Experiments:Benchmark results for relative small models. average PSNR/SSIM for ×2, ×3, ×4 models.
Benchmark results for relative large models. average PSNR/SSIM for ×2, ×3, ×4 models.
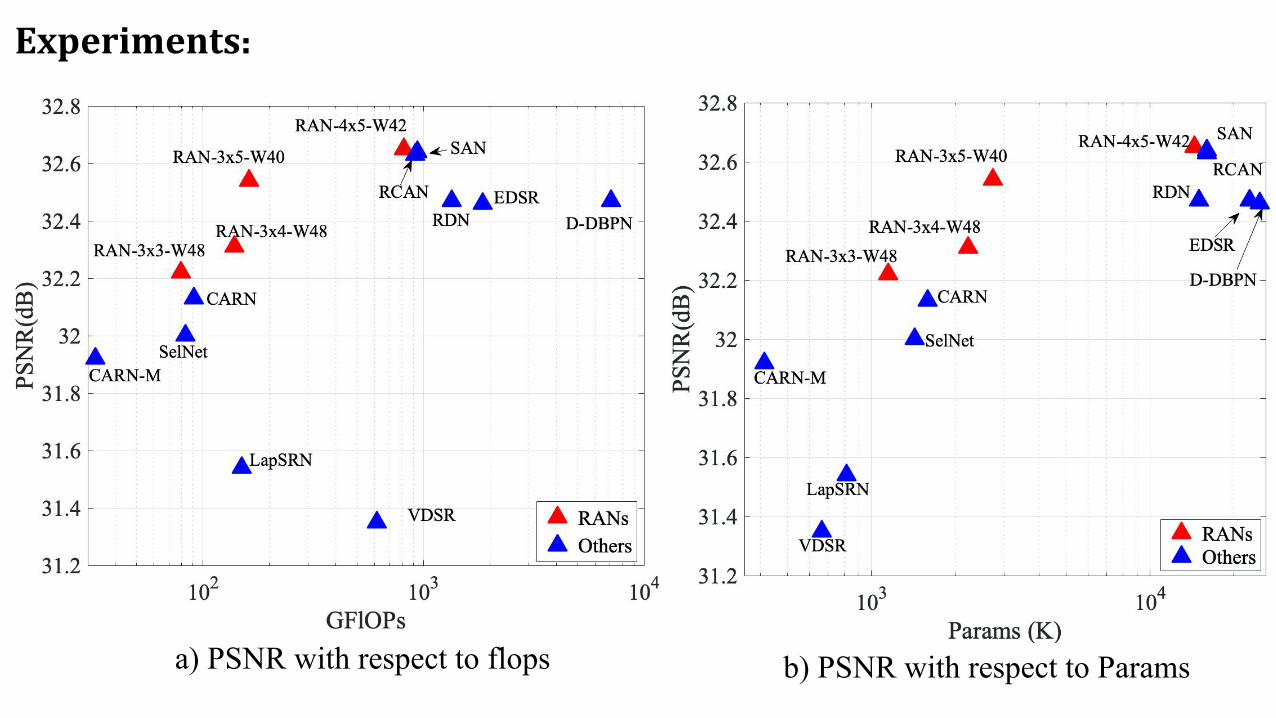
Experiments:
a) PSNR with respect to flops b) PSNR with respect to Params

Experiments:• Study of Basic Convolutional Block (BCB).
• Study of Aggregation Period.

(c) Results on B100
(a) Results on Set5 (b) Results on Set14
(d) Results on Urban100
Experiments:• Better Results with Less Layers

PSNR / SSIM 19.52 / 0.7490 20.60 / 0.7984 18.98 / 0.6457
20.26 / 0.7649 20.62 / 0.789619.83 / 0.7659 20.79 / 0.8119Urban100 Image-005
HR EDSR D-DBPN VDSR
RDN RCAN SAN RRN-4x5-W42
PSNR / SSIM 20.09 / 0.5813 18.32 / 0.4561 20.65 / 0.6064
18.97 / 0.4111 23.12 / 0.8311 24.35 / 0.8979Set14 Zebra
HR FSRCNN LapSRN CARN-M
CARN RRN-3x3-W48 RRN-3x4-W48 RRN-3x5-W48
23.87 / 0.8550
Experiments:• Visual results

Thanks !Zhengxiong Luo Ph.D.
Center for Research on IntelligentPerception and Computing
E-mail: [email protected]