efficient xml storage based on dtm for read-oriented workloads · efficient xml storage based on...
TRANSCRIPT

Efficient XML Storage based on DTMEfficient XML Storage based on DTM
for Readfor Read--oriented Workloadsoriented Workloads
Graduate School of Information Science,
Nara Institute of Science and Technology
Makoto Yui
Jun Miyazaki, Shunsuke Uemura, Hirokazu Kato
International Workshop on Advanced Storage Systems 2007 (ADSS 2007)

2
Outline
� Motivation� Related work� Document Table Model (DTM)� XML storage based on DTM
– System Overview– Physical Layout– Buffer Management
� Experimental Evaluation� Conclusions

3
Motivation - Backgrounds
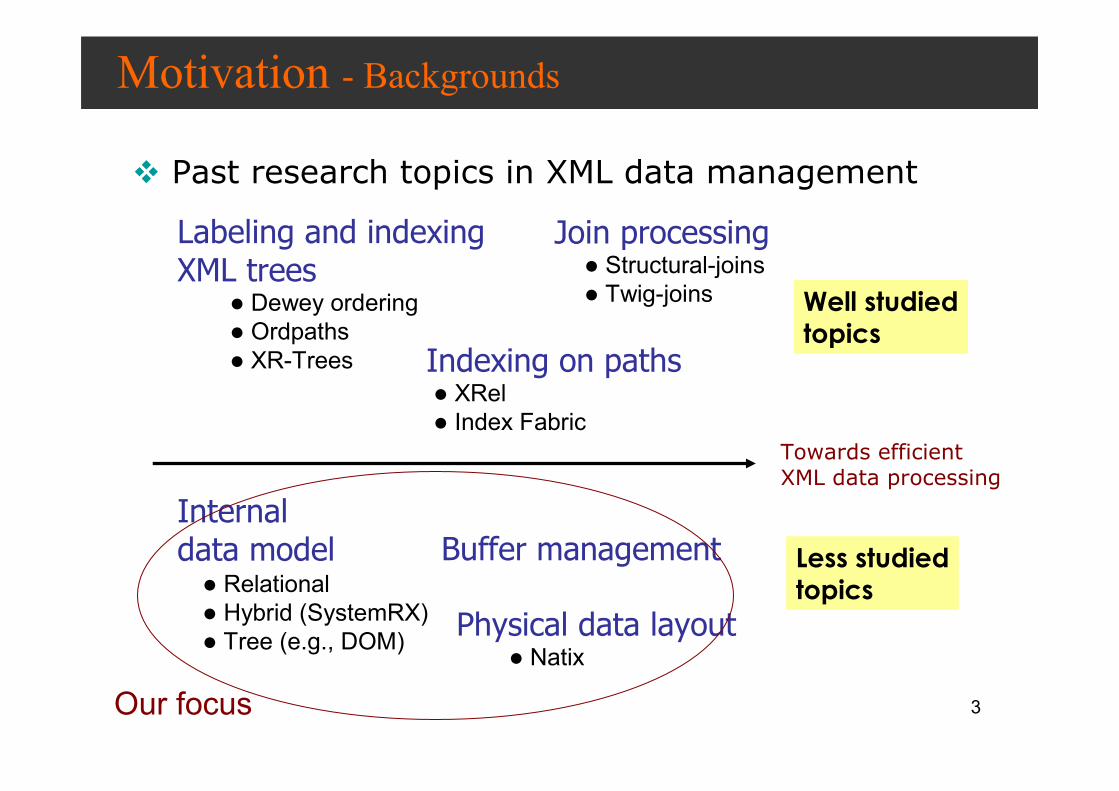
� Past research topics in XML data management
Towards efficient XML data processing
Labeling and indexing XML trees
Join processing
Indexing on paths
� Dewey ordering
� Ordpaths
� XR-Trees
� XRel
� Index Fabric
� Structural-joins
� Twig-joins
Internaldata model Buffer management
Physical data layout� Natix
� Relational
� Hybrid (SystemRX)
� Tree (e.g., DOM)
Well studied
topics
Less studied
topics
Our focus

4
Motivation – Design goals
� Design an XML storage scheme optimizedfor read-oriented workload
– Node-level update is not always required
– Updating capabilities have more or less drawbacks
� Focus on iterative XQuery processingin which an operator tree consists of iterators
The design of read-oriented database has been suggested for relational databases but not studied for XML databases yet
– Ideal XML storage scheme depends on the processing model
(e.g., tuple-at-a-time or set-at-a-time)
How the data access is achieved for each of the two processing model ?
Norman May, et al., Index vs. Navigation in XPath Evaluation. XSym 2006
The reason we selected this model is
set-at-a-time processing of XQuery
involves lots of joins, and it causes performance deteriation.
5
site
regions regions
site
auction
regions
site/regions
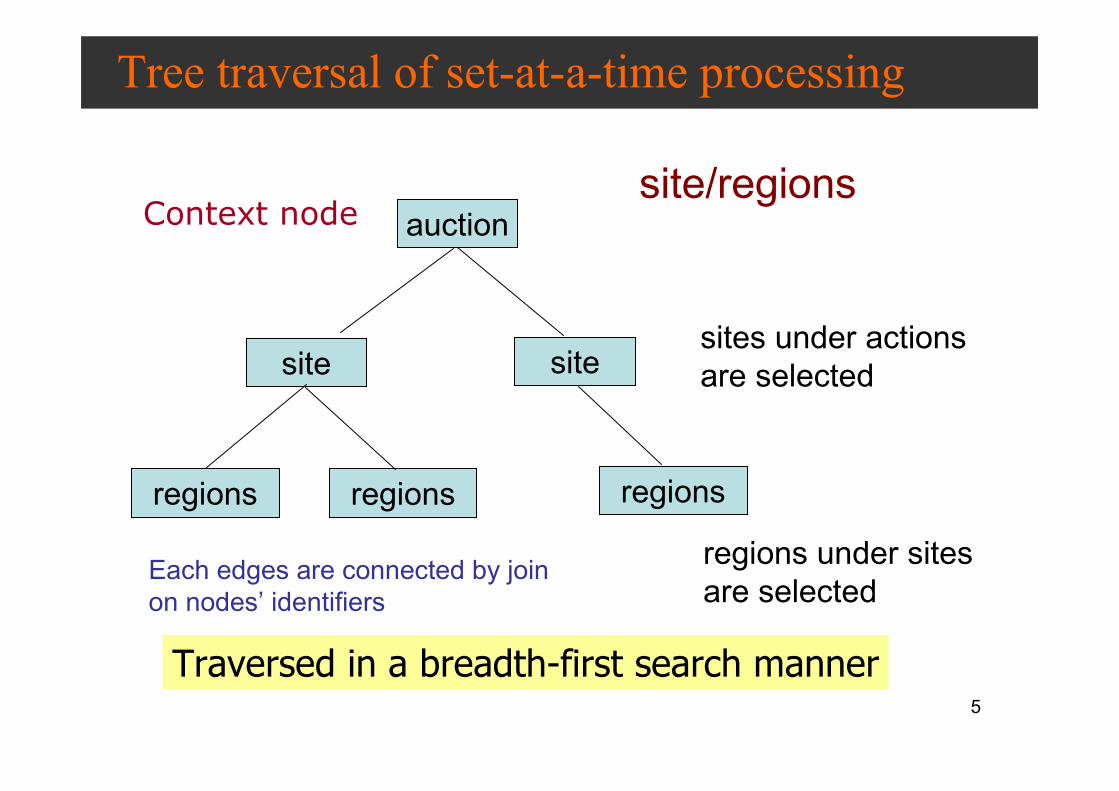
Tree traversal of set-at-a-time processing
Context node
Traversed in a breadth-first search manner
sites under actions
are selected
regions under sites
are selectedEach edges are connected by join
on nodes’ identifiers

6
site
regions regions
site
auction
regions
site/regions
Tree traversal of tuple-at-a-time processing
Context node
Traversed in a depth-first search manner
It is as same manner as a document ordering
• Each two nodes are connected by links
• Path processing is achieved by
navigating link edges

7
Motivation
� Design an XML storage scheme optimizedfor read-oriented workload
� Focus on iterative XQuery processingin which an operator tree consists of iterators
We examined actual data access patternswhen evaluating XQuery queries in order to design the suitable data layout

8
Outline
� Motivation� Related Work� Document Table Model (DTM)� XML Storage based on DTM (pDTM)
– System Overview– Pyshical Layout– Buffer Management
� Experimental Evaluation� Conclusions

9
Natix (University of Mannheim, Germany)T. Fiebig, et.al. Anatomy of a Native XML Base Management System.
VLDB Journal, 2002.
f1
f4
f8f7f3f2 f5 f6
h1 h2
p3p2p1
r1
r2 r3 r4
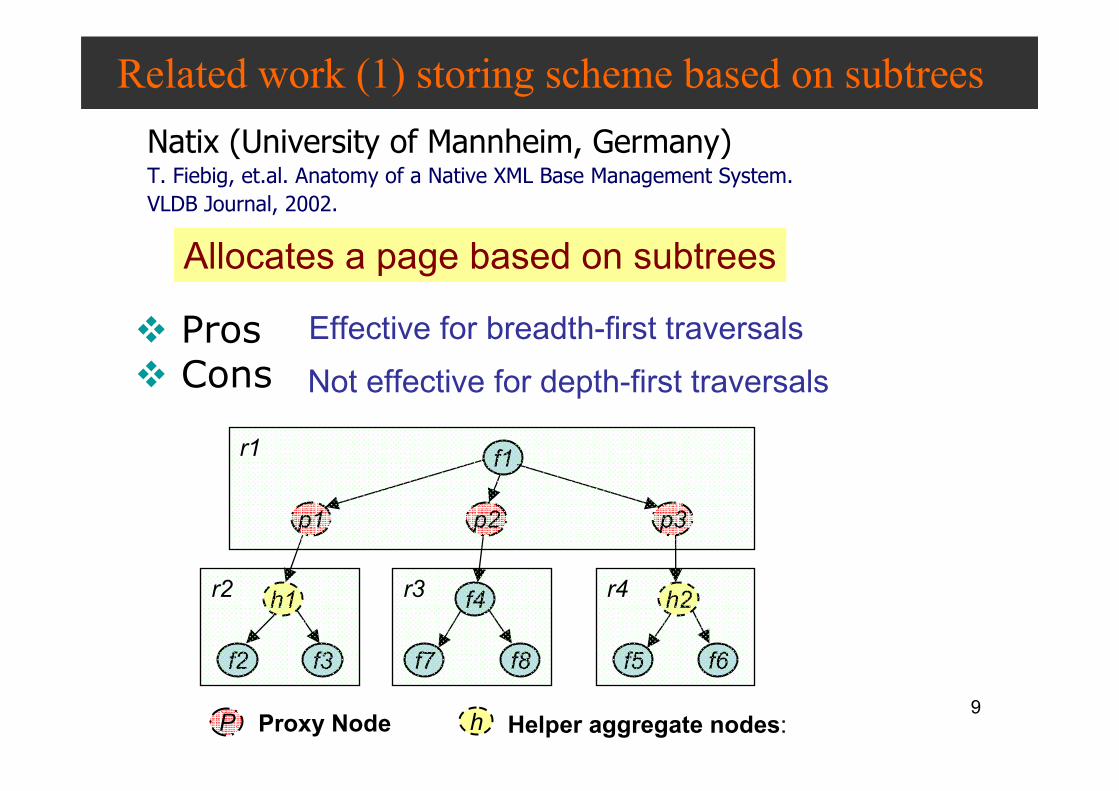
P Proxy Node h Helper aggregate nodes:
Related work (1) storing scheme based on subtrees
� Pros� Cons
Effective for breadth-first traversals
Not effective for depth-first traversals
Allocates a page based on subtrees

10
Related work (2) storing scheme based on a schema
OrientStore (Renmin University, China)X. Meng et.al. OrientStore: A Schema Based Native XML Storage System.VLDB 2003.
� Pros� Cons
• Effective for path processing
• Schema information is required
• Not effective for serialization and
string-value calculationClusters records according to
a semantic segmentation

11
Outline
� Motivation� Related work� Document Table Model (DTM)� XML Storage based on DTM (pDTM)
– System Overview– Pyshical Layout– Buffer Management
� Experimental Evaluation� Conclusions

12
Document Table Model (DTM)
� Originally used by Apache Xalan XSLT processor
� Expresses an XML document as a table form
DTM table consists of primitive data types
CID
--9107--56-NEXTSIB
1771123210PARENT
ETEETETEEEEvent
10987654321
CID
--9107--56-NEXTSIB
1771123210PARENT
ETEETETEEEEvent
10987654321E
E T E
E E
T
E T
E
1
2
3
4
5
6 7
8 9
10
0
DOM has object footprints(e.g., object instantiation and memory consumptions)
DTM can avoid such object footprints
An XML tree structure can be represented as a table
by using link values

13
AsiaNorthAmerica
Africa…
縈緹緱CID
綋綋繮緱緫繇綋綋縕縠綋NEXTSIB
緱繇繇緱緱緹縈緹緱緫PARENT
翎聱翎翎聱翎聱翎翎翎TYPE
Pyshical
Model
Abstract
Model
Page in
record page
#1 site
#2 region
#3 ..
DTMs
StringChunk
PageBuffer QNameTable
Cache miss
System Overview

14
Pyshical layout
� Before designing physical layout of XML documents, we analyzed actual data access patterns of XQuery queries.
Analyzing data access patterns
In general,
Pages are required in the document-orderSequential accesses are frequently appeared

15
Access pattern analysis of XMark queries (1)
Required Page
Access count
This plot explains that
28,000th data access
requires a page #22,000.
page #0 is assigned to
nodes nearby the root
page #40,000 is assigned to
nodes nearby end of the document
Document order is reflected
to the Y-axis
pages are required in a document order
from the lower left to the upper right.

16
Access pattern analysis of XMark queries (2)
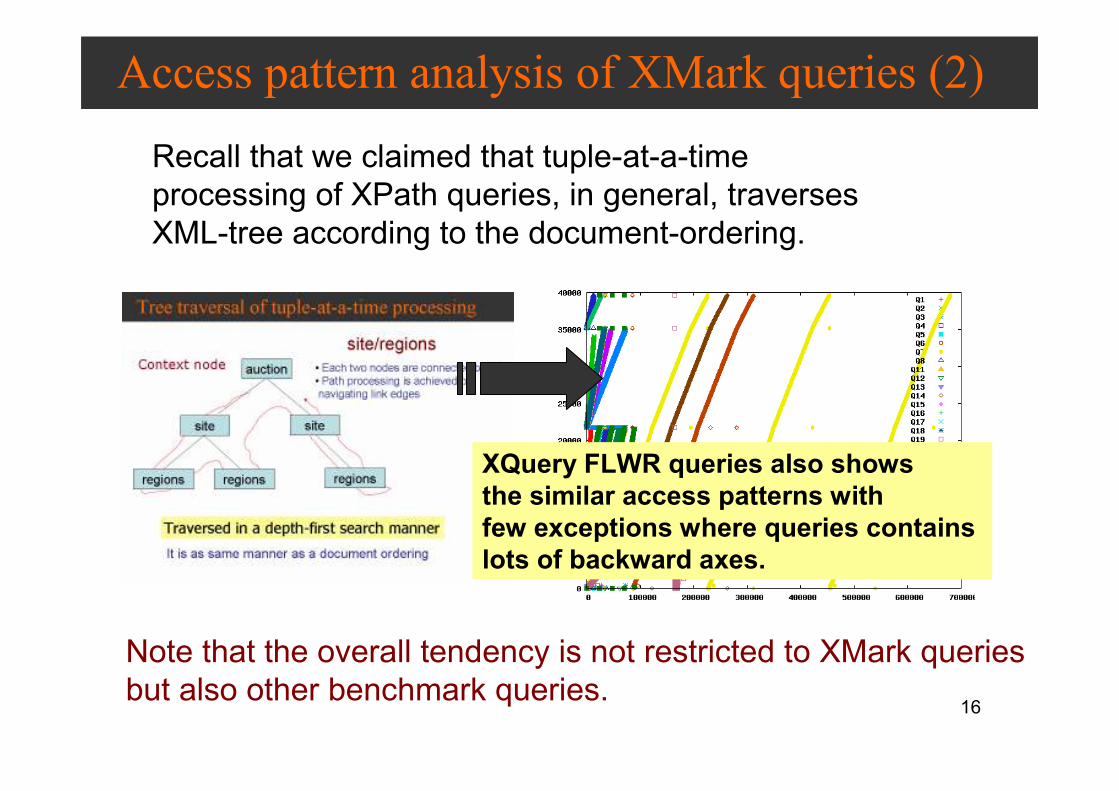
Recall that we claimed that tuple-at-a-time
processing of XPath queries, in general, traverses
XML-tree according to the document-ordering.
Note that the overall tendency is not restricted to XMark queries
but also other benchmark queries.
XQuery FLWR queries also shows
the similar access patterns with
few exceptions where queries contains
lots of backward axes.

17
Pyshical layout
� Pages are required in a document-order� Sequential accesses are frequently appeared
Prefetching is effective
The prefetching entries can compete
for hot cache entries
We conducted informed prefetching with
scan-resistant buffer management
Scan-resistant buffer management
Is also effective to sequential scans in XML query processing
Document-ordered block allocation is suitable

18
Outline
� Motivation� Related work� Document Table Model (DTM)� XML Storage based on DTM (pDTM)
– System Overview– Pyshical Layout– Buffer Management
� Experimental Evaluation� Conclusions

19
Experimental evaluation
� Compared to Natix version 2.1.1 where XMark SF = 5 and SF = 10
� Experimental settings
SF = 5 SF = 10
Elapsed time
in a log scale
Query number
Today’s normal PC setting

20
XMark SF=10
Queries whose outputs are large
Has following-sibling Contains “//”
Our method is effective for
IO-intensive workloads
Natix showed better performance
for breadth-first traversals
(e.g., following-sibling)

21
Conclusions
� Proposed an efficient XML storage schemebase on DTM for iterative XQuery processing
� Our approach is effective for IO-intensive workloadssuch as queries including ‘//’.
� Document-ordered block allocation� Informed prefetching and scan-resistant caching
Summary
Future work� Automatic database tuning based on online analysis of data access patterns (e.g., buffer replacement policy and prefetching)

22
Thank you for your attention!
Questions?

23
Problem in XML-Relational mapping
<student><id>0551133</id><name>ichiro</name>
</student>
XML
Student
id name
XML Tree
A
B C
Hard disk
Relational Table
contentparentid
--A
0551133AB
ichiroA郅
Mapping

24
綋
綋
綋
R
緫縈緹緱羑翮羿
綋綋繮綋繇綋綋縑縠綋耔翎肫聱聠翮罡
緱繇繇緱緱緹縈緹緱緫耦罓耼翎耔聱
翎聱翎翎聱翎聱翎翎翎聱胗耦翎
縈
縑
緹
翎
Updating facilities and versioning
When accessing to a record,
Logical address Physical address
For updating facilities, we change this method as follows:
Logical address Physical address
Address conversion table

25
Buffer management (XMark Q10 as an example)
緫繢緫綆縠繇縈緱繢縕綌縕縠緹耺
縕縠繇綆繇緫緹緱綆繮緱繮綆縕繢縠緹緱緱綌繢縈耎耼聵
膴莆舡舡舃荃糫荃舃苆芎膄臏舃芮舃芷荕
荕芾荕膄芎糫荃舃膄臹糫膴芎芾臏艏荑
翎芎膄苆荑舃臹糫荕艆芮舃糫絓芮荑舃臏絙
14.2% speedups
20% of original document is returned
as the result

26

27
Rows
Blocks
Read in Pages
accessed row
Pages
dynamically
configured
nullRow Skeleton
Pyshical layout

28
DC/SD Normal TC/SD Normal
Access pattern analysis of XBench queries

29
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags,int fd, off_t offset);
int munmap(void *start, sizt_t length);
Memory Mapped DTM
We present a memory mapped scheme
extending the DTM model, it has boost
the performance significantly.

Efficient XML Storage based on DTMEfficient XML Storage based on DTM
for Readfor Read--oriented Workloadsoriented Workloads
Graduate School of Information Science,
Nara Institute of Science and Technology
Makoto Yui
Jun Miyazaki, Shunsuke Uemura, Hirokazu Kato
International Workshop on Advanced Storage Systems 2007 (ADSS 2007)

2
Outline
� Motivation� Related work� Document Table Model (DTM)� XML storage based on DTM
– System Overview– Physical Layout– Buffer Management
� Experimental Evaluation� Conclusions
3
Motivation - Backgrounds
� Past research topics in XML data management
Towards efficient XML data processing
Labeling and indexing XML trees
Join processing
Indexing on paths
� Dewey ordering
� Ordpaths
� XR-Trees
� XRel
� Index Fabric
� Structural-joins
� Twig-joins
Internaldata model Buffer management
Physical data layout� Natix
� Relational
� Hybrid (SystemRX)
� Tree (e.g., DOM)
Well studied
topics
Less studied
topics
Our focus

4
Motivation – Design goals
� Design an XML storage scheme optimizedfor read-oriented workload
– Node-level update is not always required
– Updating capabilities have more or less drawbacks
� Focus on iterative XQuery processingin which an operator tree consists of iterators
The design of read-oriented database has been suggested for relational databases but not studied for XML databases yet
– Ideal XML storage scheme depends on the processing model
(e.g., tuple-at-a-time or set-at-a-time)
How the data access is achieved for each of the two processing model ?
Norman May, et al., Index vs. Navigation in XPath Evaluation. XSym 2006
The reason we selected this model is
set-at-a-time processing of XQuery
involves lots of joins, and it causes performance deteriation.

5
site
regions regions
site
auction
regions
site/regions
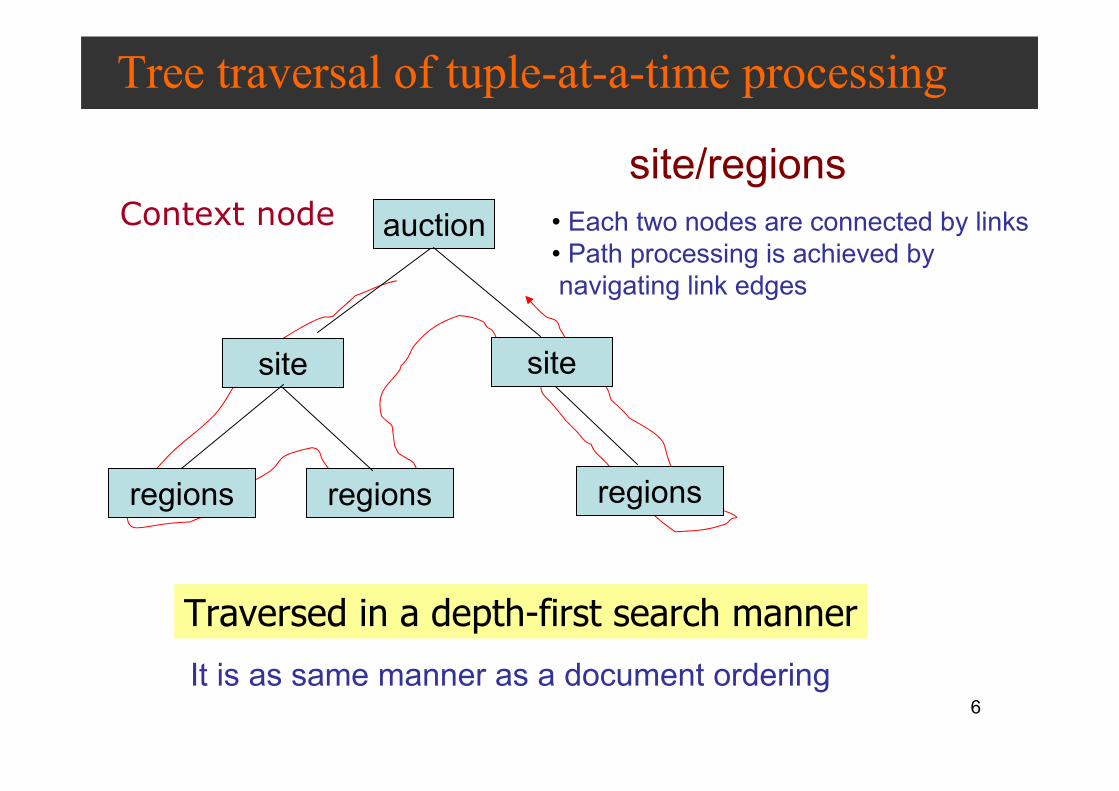
Tree traversal of set-at-a-time processing
Context node
Traversed in a breadth-first search manner
sites under actions
are selected
regions under sites
are selectedEach edges are connected by join
on nodes’ identifiers
6
site
regions regions
site
auction
regions
site/regions
Tree traversal of tuple-at-a-time processing
Context node
Traversed in a depth-first search manner
It is as same manner as a document ordering
• Each two nodes are connected by links
• Path processing is achieved by
navigating link edges

7
Motivation
� Design an XML storage scheme optimizedfor read-oriented workload
� Focus on iterative XQuery processingin which an operator tree consists of iterators
We examined actual data access patternswhen evaluating XQuery queries in order to design the suitable data layout

8
Outline
� Motivation� Related Work� Document Table Model (DTM)� XML Storage based on DTM (pDTM)
– System Overview– Pyshical Layout– Buffer Management
� Experimental Evaluation� Conclusions
9
Natix (University of Mannheim, Germany)T. Fiebig, et.al. Anatomy of a Native XML Base Management System.
VLDB Journal, 2002.
f1
f4
f8f7f3f2 f5 f6
h1 h2
p3p2p1
r1
r2 r3 r4
P Proxy Node h Helper aggregate nodes:
Related work (1) storing scheme based on subtrees
� Pros� Cons
Effective for breadth-first traversals
Not effective for depth-first traversals
Allocates a page based on subtrees

10
Related work (2) storing scheme based on a schema
OrientStore (Renmin University, China)X. Meng et.al. OrientStore: A Schema Based Native XML Storage System.VLDB 2003.
� Pros� Cons
• Effective for path processing
• Schema information is required
• Not effective for serialization and
string-value calculationClusters records according to
a semantic segmentation

11
Outline
� Motivation� Related work� Document Table Model (DTM)� XML Storage based on DTM (pDTM)
– System Overview– Pyshical Layout– Buffer Management
� Experimental Evaluation� Conclusions

12
Document Table Model (DTM)
� Originally used by Apache Xalan XSLT processor
� Expresses an XML document as a table form
DTM table consists of primitive data types
CID
--9107--56-NEXTSIB
1771123210PARENT
ETEETETEEEEvent
10987654321
CID
--9107--56-NEXTSIB
1771123210PARENT
ETEETETEEEEvent
10987654321E
E T E
E E
T
E T
E
1
2
3
4
5
6 7
8 9
10
0
DOM has object footprints(e.g., object instantiation and memory consumptions)
DTM can avoid such object footprints
An XML tree structure can be represented as a table
by using link values

13
AsiaNorthAmerica
Africa…
321CID
--9107--56-NEXTSIB
1771123210PARENT
ETEETETEEETYPE
Pyshical
Model
Abstract
Model
Page in
record page
#1 site
#2 region
#3 ..
DTMs
StringChunk
PageBuffer QNameTable
Cache miss
System Overview

14
Pyshical layout
� Before designing physical layout of XML documents, we analyzed actual data access patterns of XQuery queries.
Analyzing data access patterns
In general,
Pages are required in the document-orderSequential accesses are frequently appeared

15
Access pattern analysis of XMark queries (1)
Required Page
Access count
This plot explains that
28,000th data access
requires a page #22,000.
page #0 is assigned to
nodes nearby the root
page #40,000 is assigned to
nodes nearby end of the document
Document order is reflected
to the Y-axis
pages are required in a document order
from the lower left to the upper right.
16
Access pattern analysis of XMark queries (2)
Recall that we claimed that tuple-at-a-time
processing of XPath queries, in general, traverses
XML-tree according to the document-ordering.
Note that the overall tendency is not restricted to XMark queries
but also other benchmark queries.
XQuery FLWR queries also shows
the similar access patterns with
few exceptions where queries contains
lots of backward axes.

17
Pyshical layout
� Pages are required in a document-order� Sequential accesses are frequently appeared
Prefetching is effective
The prefetching entries can compete
for hot cache entries
We conducted informed prefetching with
scan-resistant buffer management
Scan-resistant buffer management
Is also effective to sequential scans in XML query processing
Document-ordered block allocation is suitable

18
Outline
� Motivation� Related work� Document Table Model (DTM)� XML Storage based on DTM (pDTM)
– System Overview– Pyshical Layout– Buffer Management
� Experimental Evaluation� Conclusions

19
Experimental evaluation
� Compared to Natix version 2.1.1 where XMark SF = 5 and SF = 10
� Experimental settings
SF = 5 SF = 10
Elapsed time
in a log scale
Query number
Today’s normal PC setting

20
XMark SF=10
Queries whose outputs are large
Has following-sibling Contains “//”
Our method is effective for
IO-intensive workloads
Natix showed better performance
for breadth-first traversals
(e.g., following-sibling)

21
Conclusions
� Proposed an efficient XML storage schemebase on DTM for iterative XQuery processing
� Our approach is effective for IO-intensive workloadssuch as queries including ‘//’.
� Document-ordered block allocation� Informed prefetching and scan-resistant caching
Summary
Future work� Automatic database tuning based on online analysis of data access patterns (e.g., buffer replacement policy and prefetching)

22
Thank you for your attention!
Questions?

23
Problem in XML-Relational mapping
<student><id>0551133</id><name>ichiro</name>
</student>
XML
Student
id name
XML Tree
A
B C
Hard disk
Relational Table
contentparentid
--A
0551133AB
ichiroAC
Mapping

24
-
-
-
R
0321CID
--9-7--46-NEXTSIB
1771123210PARENT
ETEETETEEETYPE
3
4
2
E
Updating facilities and versioning
When accessing to a record,
Logical address Physical address
For updating facilities, we change this method as follows:
Logical address Physical address
Address conversion table

25
Buffer management (XMark Q10 as an example)
080,673185.562Q
567,7021,919,586211.83LRU
buffer replacement
total read blocks
Elapsed time (msec)
14.2% speedups
20% of original document is returned
as the result

26

27
Rows
Blocks
Read in Pages
accessed row
Pages
dynamically
configured
nullRow Skeleton
Pyshical layout

28
DC/SD Normal TC/SD Normal
Access pattern analysis of XBench queries

29
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags,int fd, off_t offset);
int munmap(void *start, sizt_t length);
Memory Mapped DTM
We present a memory mapped scheme
extending the DTM model, it has boost
the performance significantly.