efficient hardware support for the partitioned global
TRANSCRIPT

Holger Fröning
Efficient Hardware Support for the Efficient Hardware Support for the Partitioned Global Address SpacePartitioned Global Address Space
Holger Fröning and Heiner LitzComputer Architecture Group
University of Heidelberg

Efficient Hardware Support for the Partitioned Global Address Space2 Holger Fröning
OutlineOutline
Motivation & GoalArchitecturePerformance EvaluationConclusion

Efficient Hardware Support for the Partitioned Global Address Space3 Holger Fröning
MotivationMotivationPGASPGAS
Cache coherent shared memory does not scaleNeither Broadcast- nor Directory-based cache protocolsSee also AMD’s Probe Filter
Partitioned Global Address Space (PGAS)Locally coherent, globally non-coherentYelick 2006: “Partitioned Global Address Space (PGAS) languages combine the programming convenience of shared memory with the locality and performance control of message passing.”
Leverage local coherency advantages,avoid global coherency disadvantages

Efficient Hardware Support for the Partitioned Global Address Space4 Holger Fröning
MotivationMotivationGoalGoal
PGAS relies onHigh bandwidth bulk transfersFine grain accesses for both communication and synchronization purposes
GoalProvide best support for fine grain accesses with minimal software overhead
Ban
dwid
th

Efficient Hardware Support for the Partitioned Global Address Space5 Holger Fröning
ArchitectureArchitectureOverviewOverview
1. Lean Shared Memory EngineAddress TranslationSrcTag Management Stateless on Origin sideVirtualized
2. Reliable network with in-order delivery
HT requests supposed to be answered
3. Leverage HyperTransport’s latency advantage and direct CPU connectivity
4. Minimal protocol conversionCPU HT On-chip network Network
Mem
ory
Mem
ory
Efficient Hardware Support for the Partitioned Global Address Space6 Holger Fröning
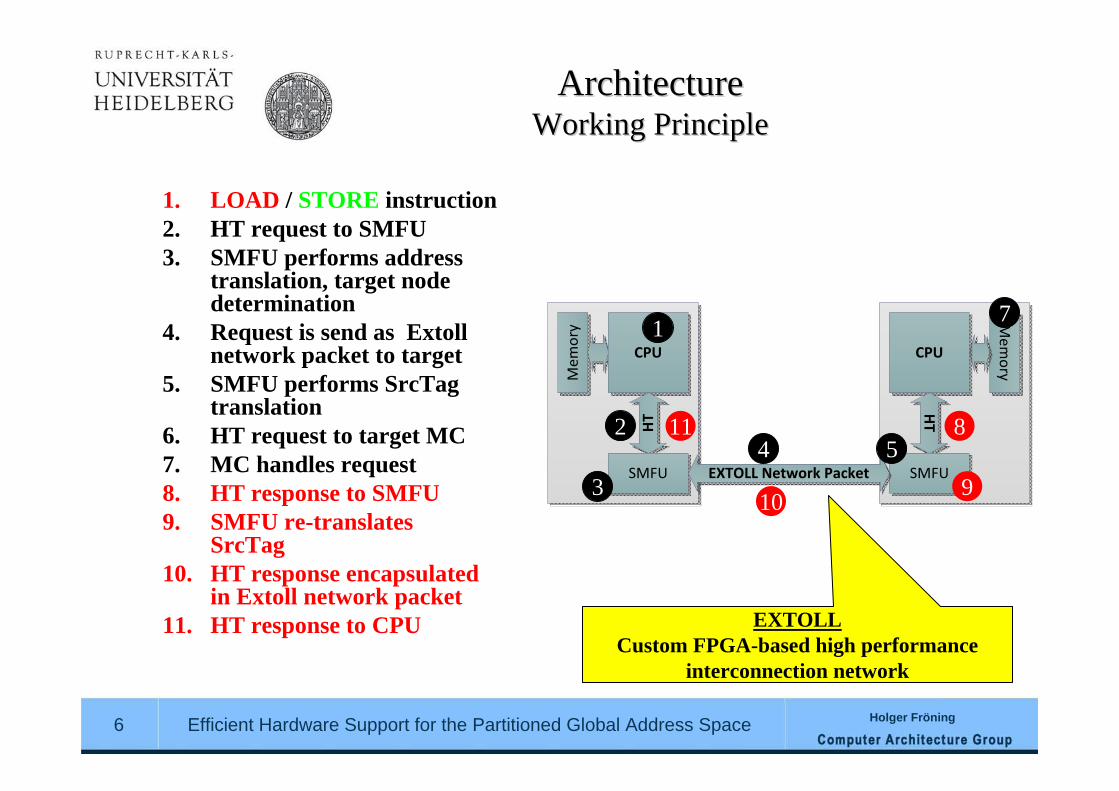
ArchitectureArchitectureWorking PrincipleWorking Principle
1. LOAD / STORE instruction2. HT request to SMFU3. SMFU performs address
translation, target nodedetermination
4. Request is send as Extollnetwork packet to target
5. SMFU performs SrcTagtranslation
6. HT request to target MC7. MC handles request8. HT response to SMFU9. SMFU re-translates
SrcTag10. HT response encapsulated
in Extoll network packet11. HT response to CPU
Mem
ory
CPU
HT
SMFU
Mem
ory
CPU
HT
SMFU EXTOLL Network Packet
1
2
34
95
7
8
10
11
EXTOLLCustom FPGA-based high performance
interconnection network

Efficient Hardware Support for the Partitioned Global Address Space7 Holger Fröning
ArchitectureArchitectureEgress & Ingress UnitEgress & Ingress Unit

Efficient Hardware Support for the Partitioned Global Address Space8 Holger Fröning
ArchitectureArchitectureAddress TranslationAddress Translation
oStartAddroAddrgAddr −=
( ) countshiftmaskgAddrtNodeID _& >>=
( ) tStartAddrmaskgAddrtAddr += ~&
oStartAddr
tStartAddr
oAddr
tAddr
Efficient Hardware Support for the Partitioned Global Address Space9 Holger Fröning
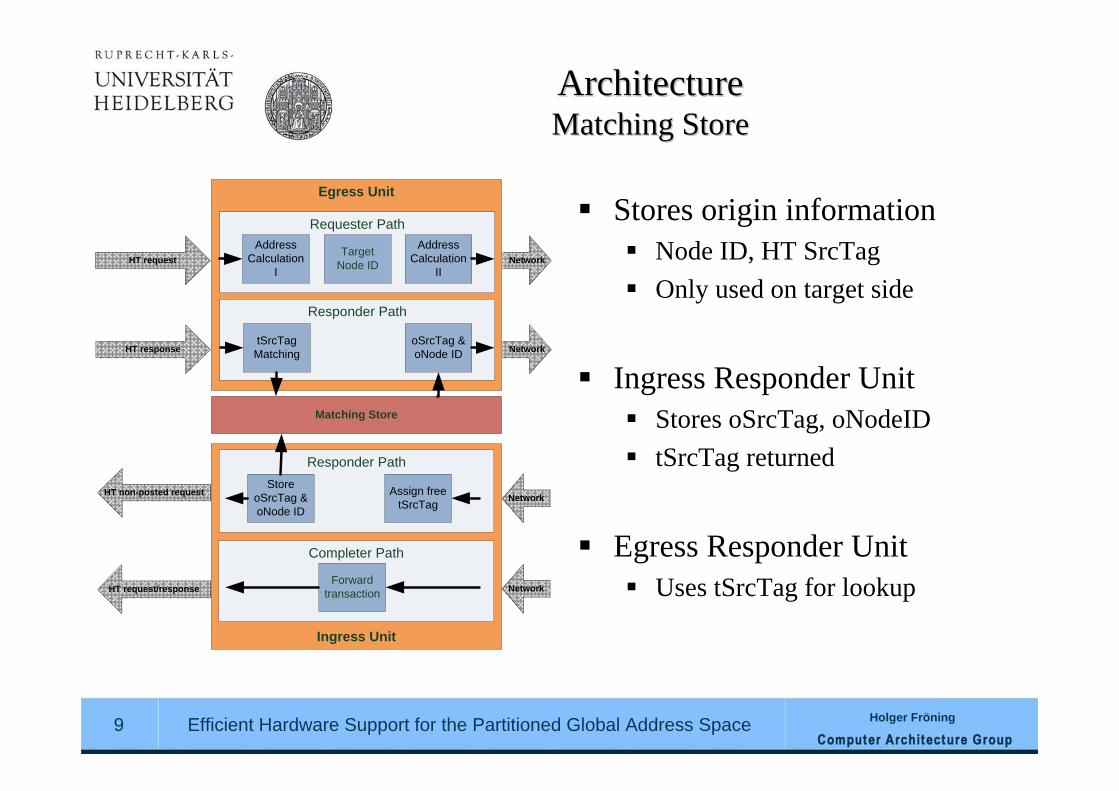
ArchitectureArchitectureMatching StoreMatching Store
Ingress Unit
Egress Unit
Requester PathAddress
Calculation I
Target Node ID
Address Calculation
IINetwork
Responder Path
HT response Network
Matching Store
tSrcTag Matching
oSrcTag & oNode ID
Completer Path
Forward transaction NetworkHT request/response
Responder Path
NetworkAssign free tSrcTag
Store oSrcTag & oNode ID
HT non-posted request
HT request
Stores origin informationNode ID, HT SrcTagOnly used on target side
Ingress Responder UnitStores oSrcTag, oNodeIDtSrcTag returned
Egress Responder UnitUses tSrcTag for lookup
Efficient Hardware Support for the Partitioned Global Address Space10 Holger Fröning
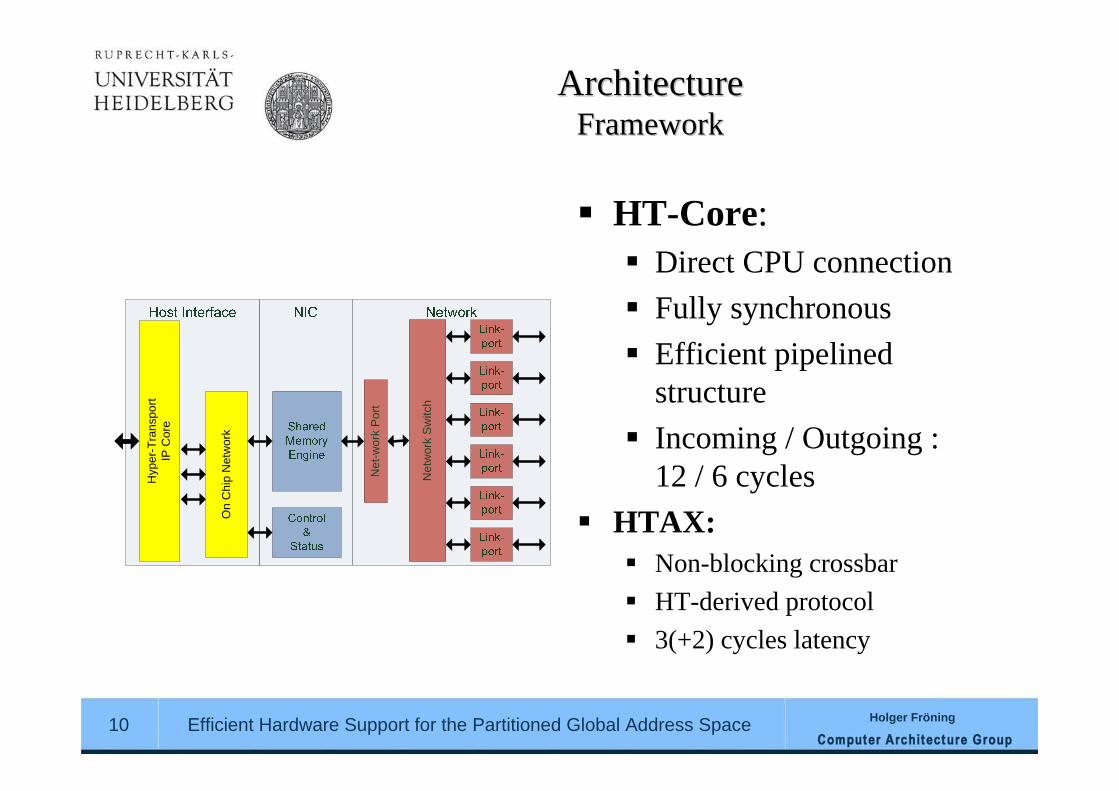
ArchitectureArchitectureFrameworkFramework
HT-Core:Direct CPU connectionFully synchronousEfficient pipelined structureIncoming / Outgoing : 12 / 6 cycles
HTAX:Non-blocking crossbarHT-derived protocol3(+2) cycles latency
Hyp
er-T
rans
port
IP C
ore
On
Chi
p N
etw
ork
Net
wor
k S
witc
h
Net
-wor
k P
ort

Efficient Hardware Support for the Partitioned Global Address Space11 Holger Fröning
ArchitectureArchitectureFrameworkFramework
Network Switch:In-order delivery of packetsHardware retransmissionVirtual Output QueuingVirtual channelsCut-through switchingSource-Path routingCredit based flow-controlFault toleranceRemote management access
Hyp
er-T
rans
port
IP C
ore
On
Chi
p N
etw
ork
Net
wor
k S
witc
h
Net
-wor
k P
ort

Efficient Hardware Support for the Partitioned Global Address Space12 Holger Fröning
Performance EvaluationPerformance Evaluation
Two nodes, each:4x AMD Opteron 2.2GHz Quad Core16GB RAMStandard Linux
Virtex-4 FX100 Prototype156MHz core clockHT400 interface (1.6GB/s)6 links, each 6.24 GbpsFPGA: 75% utilization

Efficient Hardware Support for the Partitioned Global Address Space13 Holger Fröning
Performance EvaluationPerformance EvaluationLimitations & SolutionsLimitations & Solutions
CPU microarchitectureOnly one outstanding load transaction on MMIO spaceMax. size of load on uncacheable memory 64bit
BIOSMMIO space per PCI B:D:F number max. 256MB
Move to DRAM space
Cacheable memory
Extended MMIO (EMMIO)Move to DRAM space

Efficient Hardware Support for the Partitioned Global Address Space14 Holger Fröning
Performance EvaluationPerformance EvaluationRemote LoadsRemote Loads
Read Latency
1.21 1.27
1.981.89
0.0
0.5
1.0
1.5
2.0
2.5
4 8Size[byte]
Late
ncy[μ
s]
Measurement HT400 / 156MHz core clock
Simulation HT1000 / 800MHz core clock
Read Latency
1.21 1.27
1.981.89
0.0
0.5
1.0
1.5
2.0
2.5
4 8Size[byte]
Late
ncy[μ
s]
Measurement HT400 / 156MHz core clock
Simulation HT1000 / 800MHz core clock
Read Throughput
0
20
40
60
80
100
120
140
160
180
200
4 8 16 32 64
Size[byte]
Thro
ghpu
t[M
B/s]
Nonposted Measurement, max. 1 outstanding
Nonposted Simulation, max. 1 outstanding
Nonposted Simulation, max. 32 outstanding
Read Throughput
0
20
40
60
80
100
120
140
160
180
200
4 8 16 32 64
Size[byte]
Thro
ghpu
t[M
B/s]
Nonposted Measurement, max. 1 outstanding
Nonposted Simulation, max. 1 outstanding
Nonposted Simulation, max. 32 outstanding
Little’s Law (1961, queuing theory)Number outstanding N = 1Response Time R = 2 usec (approx.)Throughput X
sMBus
BRNX /4281/ =⋅
==
Full round trip latency
including main memory access

Efficient Hardware Support for the Partitioned Global Address Space15 Holger Fröning
Performance EvaluationPerformance EvaluationRemote StoresRemote Stores
At network peak bandwidth for 64bytesOutstanding transaction rate
Write Throughput
0
200
400
600
800
1000
1200
1400
8 16 32 64 128
Size[byte]
Thro
ghpu
t[M
B/s]
Simulation HT1000 /800MHz core clock
Measurement HT400 /156MHz core clock
Write Throughput
0
200
400
600
800
1000
1200
1400
8 16 32 64 128
Size[byte]
Thro
ghpu
t[M
B/s]
Simulation HT1000 /800MHz core clock
Measurement HT400 /156MHz core clock
Posted Transaction Rate
0.0001,0
00,00
0.0002,0
00,00
0.0003,0
00,00
0.0004,0
00,00
0.0005,0
00,00
0.0006,0
00,00
0.0007,0
00,00
0.000
8 16 32 64 128 256 512 1024 2048 4096
Size [Byte]
Rate
[1/s
]
Posted Transaction Rate
0.0001,0
00,00
0.0002,0
00,00
0.0003,0
00,00
0.0004,0
00,00
0.0005,0
00,00
0.0006,0
00,00
0.0007,0
00,00
0.000
8 16 32 64 128 256 512 1024 2048 4096
Size [Byte]
Rate
[1/s
]

Efficient Hardware Support for the Partitioned Global Address Space16 Holger Fröning
Performance EvaluationPerformance EvaluationPut it into context!Put it into context!
Comparing SMFU vs. EXTOLL (API)(two nodes, 4x 2.2GHz K10 Opteron)
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
400.00
8 16 32 64 128 256 512 1,024 2,048 4,096 8,192
size [bytes]
MB
/s
0.00
2.50
5.00
7.50
10.00
12.50
15.00
17.50
20.00
SpeedupSMFU over EXTOLL
SpeedupSMFU over IB
Shared Memory(FPGA-based)Remote StoresAPI over EXTOLL(FPGA-based)NetPIPE StreamMPI over IB(ASIC-based)NetPIPE Stream
Comparing SMFU vs. EXTOLL (API)(two nodes, 4x 2.2GHz K10 Opteron)
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
400.00
8 16 32 64 128 256 512 1,024 2,048 4,096 8,192
size [bytes]
MB
/s
0.00
2.50
5.00
7.50
10.00
12.50
15.00
17.50
20.00
SpeedupSMFU over EXTOLL
SpeedupSMFU over IB
Shared Memory(FPGA-based)Remote StoresAPI over EXTOLL(FPGA-based)NetPIPE StreamMPI over IB(ASIC-based)NetPIPE Stream

Efficient Hardware Support for the Partitioned Global Address Space17 Holger Fröning
Conclusion & FutureConclusion & Future
ConclusionProve of concept of Distributed Shared MemoryFine grained remote stores & loadsEfficient and slim designFirst performance numbers outstanding and encouraging (taken into account the technology differences)
FutureAtomic operationsDRAM space (requires coherency)Consistency supporting strict and relaxed operationsApplication level evaluation
UPC/GASNetAggregating memory…