effective string processing and matching for author entity
TRANSCRIPT

Effective String Processing and Matching for Author
Disambiguation
Source:Journal of Machine Learning Research’14Speaker:LIN,CI-JIE

Outline
IntroductionMethodExperimentConclusion

Outline
IntroductionMethodExperimentConclusion

Introduction
Track 2 of KDD Cup 2013 aims at determining duplicated authors in a data set from Microsoft Academic Search
Track 2 in KDD Cup 2013 is a task of name disambiguation

Introduction
1. Author.csv2. Paper.csv3. PaperAuthor.csv4. Conference.csv 5. Journal.csv

Outline
IntroductionMethodExperimentConclusion

Overview of Data sets
1. Alleviation2. Unusual Name3. Inconsistent Information4. Typo5. Incomplete Name6. Empty Entry7. Missing Value8. Nickname9. Wrong matching between authors and papers10.Non-English characters

Main Strategies
The first strategy is that we identify duplicates mainly based on string matching
The second strategy is that if an author in Author.csv has no publication records in PaperAuthor.csv, then we assume that this author has no duplicates
The third strategy is to classify an author as Chinese or non-Chinese before any string matching

Implementation
Two implementations of the framework were finished by two groups within the team

The Framework
1. Chinese-or-not2. Cleaning3. Selection4. Identification5. Splitting6. Linking
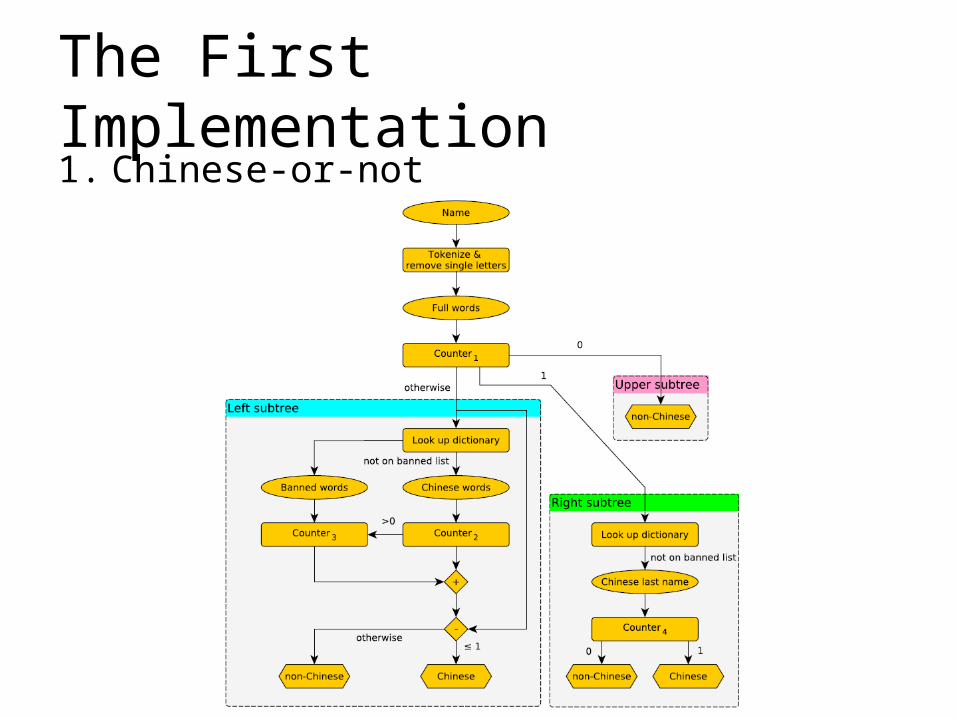
The First Implementation1. Chinese-or-not

The First Implementation
2. Cleaning Split two consecutive uppercase characters
replace “CJ" with “C J.” Remove English honorics (e.g., “Mr." and “Dr.") Transform uppercase to lowercase Remove apostrophes and replace punctuation. For
example, “o'relly" becomes “orelly.“

The First Implementation
2. Cleaning Replace European alphabets with similar English
alphabets Replace common English nicknames
replace “bill” with “william."

The First Implementation
3. Selection build a dictionary of (key, value) pairs. Each key is a set
of words, while each value is a set of authors containing the key

The First Implementation
4. Identification Matching Functions
1. Two names share the same set of words “ Chih Jen Lin“ and “ Lin Chih Jen.„
2. A shortened name " Ch. J. Lin" and " Chih Jen Lin.“
3. A partially shortened name "C. J. Lin" and "C. J. Lint.“
4. Alias dry-run procedure
“ C J Lin “ and “ Chih Jen Lion “ are loosely identical, while “ Chih Jen Lin“ and “ Chen Ju Lin “ are not.

The First Implementation
5. Splitting Each author name is a full name with two words. Neither author name is a partially shortened
name of the other. " kazuo kobayashi" and "kunikazu kobayashi"

The Second Implementation
1. Chinese-or-not2. Cleaning3. Selection4. Identification

The Second Implementation
5. Splitting Common extended names(CEN) Longest common extended name(LCEN)

The Second Implementation
6. Linking previous stages group duplicated names rather
than identifiers. However, the competition task is to group
duplicated identifiers

Ensemble
the two implementations detect different sets of duplicates,an ensemble of their results may improve the performance
The filter considers that two authors have a similar background Affiliation、 field of study

Typo Correction
handle typos in author names of Author.csvTwo author names are considered as
duplicates iftheir word sets are the same after treating each
typo the same as after its correction,andtheir affiliations share at least one common word

Outline
IntroductionMethodExperimentConclusion

Experiment
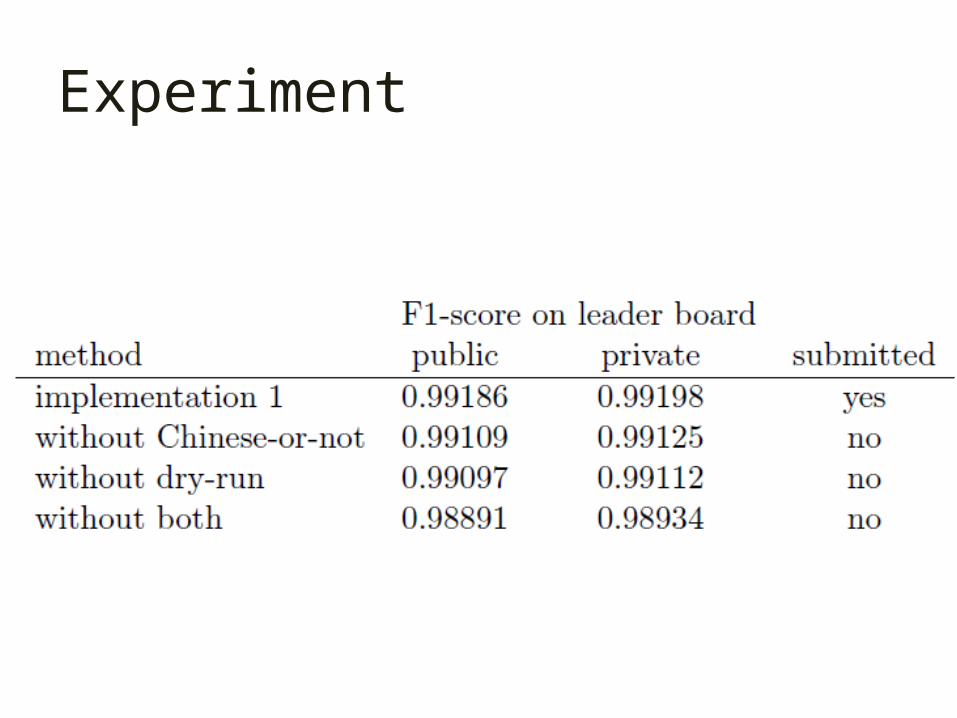
Experiment

Outline
IntroductionMethodExperimentConclusion

Conclusion
try best to keep all information and delay the modification on the data set because the provided data set is noisy and incomplete
an important advantage of using rule-based approaches is that we can easily trace the change of results after a rule is added