dynamic procurement of new products with covariate...
TRANSCRIPT

Dynamic Procurement of New Products with CovariateInformation: The Residual Tree Method
Gah-Yi BanLondon Business School, Regent’s Park, London, NW1 4SA, United Kingdom.
Jérémie GallienLondon Business School, Regent’s Park, London, NW1 4SA, United Kingdom.
Adam MersereauKenan-Flagler Business School, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599 USA.
Problem definition: We study a challenging, practice-motivated problem of dynamically procuring a new,
short life-cycle product under demand uncertainty. The firm does not know the demand for the new product
but has data on similar products sold in the past, including demand histories and covariate information such
as product characteristics.
Academic/practical relevance: The dynamic procurement problem has long attracted academic and
practitioner interest, and we solve it in an innovative data-driven way with proven theoretical guarantees.
This work is the first to incorporate covariate information in solving a multi-stage stochastic program.
Methodology: We propose a new, combined forecasting and optimization algorithm called the residual
tree method, and analyze its performance via epi-convergence theory and computations.
Results: We prove, under fairly mild conditions, that the residual tree method is asymptotically optimal
as the size of the data set grows. We also numerically validate the method for problem instances derived using
data from the global fashion retailer Zara. We find that ignoring covariate information leads to systematic
bias in the optimal solution, translating to a 6–15% increase in the total cost for the problem instances under
study. We also find that solutions based on trees using just 2–3 branches per node, which is common in the
existing literature, are inadequate, resulting in 30–66% higher total costs compared with our best solution.
Managerial implications: The residual tree is a flexible approach to this problem, and effectively uses
past data on similar products to manage new product inventories. We also show the value of covariate
information and of granular demand modeling.
Key words : new product, inventory management, data-driven operations, scenario tree method, residual
tree method, demand uncertainty
History : February 24, 2017
1

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
2 Article submitted to Manufacturing & Service Operations Management; manuscript no.
1. Introduction
Matching supply with demand is a critical challenge for retailers selling short life cycle products
in markets with fast-changing demand trends, such as fashion apparel and consumer electronics.
In response, retailers and academics have considered specific operational strategies, such as quick
response and fast fashion, for facilitating this matching. Such strategies make use of many levers at
the firm’s disposal, including product design (e.g., component commonality), forecasting and mar-
ket tests (e.g., early order incentives), manufacturing locations (e.g., on-shoring and near-shoring),
manufacturing sequencing (e.g., delayed differentiation), pricing (e.g., clearance or in-season mark-
downs), and logistics (Fisher et al. 2001).
Another recognized strategy involves the dynamic allocation of demand with different levels of
uncertainty to manufacturing facilities characterized by different lead times and costs. The key idea
is to selectively use fast and expensive supply sources in order to either acquire as much information
as possible before procuring products with high demand uncertainty (risk-based supply portfolio
strategy; see Fisher and Raman 1996) or to supply the portion of demand that is associated with
more uncertainty (base/surge demand strategy; Allon and Van Mieghem 2010).
This paper is motivated by our interaction with Spain-based retailer Zara, which had implemented
such a procurement segmentation approach in its supply chain. Specifically, Zara would typically
purchase some initial quantity of a new product from China several months before the season, but
depending on sales during the season it could subsequently place one of several in-season replenish-
ment orders for the same product from more expensive vendors located in Turkey or Portugal (Patel
2012). However, this conceptually straightforward strategy is difficult to operationalize in practice
due to both forecasting and decision challenges which Zara managers made clear to us and which are
well-documented in other contexts (e.g., Agrawal et al. 2002). This is consistent with a recent survey
of 126 North American and Northern European retailers with sales in excess of $110m per annum
(Martec 2016), where 58% reported forecasting for new products as a key challenge. Furthermore,
many other sources also suggest that the decision problem of leveraging these forecasts to maximize
expected profits when determining order quantities from multiple vendors over time (the dynamic
procurement problem) is a complicated one, typically modeled as a dynamic program and solved
through specialized heuristics (see Section 2).
Fortunately, the recent and growing availability of large datasets relevant to product forecasting as
well as computational power and high-performance software for solving optimization models present
new opportunities for the dynamic procurement problem. In this paper we present, analyze and test
a practice-oriented, flexible, and tractable data-driven computational method for optimizing the

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 3
procurement of a short life cycle product from multiple sources over time. Specifically, this method
leverages generic and virtually unlimited covariate information to capture new product character-
istics and historical demand data for similar products sold in the past, without relying on specific
distributional assumptions. Relevant product covariates may, for example, include procurement cost,
retail price, colour, item type (e.g. sweater, t-shirt, etc.), fabric, design style (e.g. sporty, classic),
expert predictions of the product’s popularity, etc. The set of similar products would typically be
defined by leveraging existing product families (e.g. ‘outerwear’ or ‘women’s shirts’). Our framework
also captures demand correlation across time periods, by considering lagged demand observations as
covariates. Critically, it also captures the dynamics of demand learning over time, which is relevant
to determine the initial quantity that should be procured from cheap and slow sources before the
season (e.g., sea shipments from China to Spain), given the lead-times associated with faster but
more expensive sources that may later be used as recourse before the season finishes (e.g., ground
shipments from Turkey or Portugal). Our work is motivated by the opportunity to leverage such
data in order to improve the system currently used by Zara, which solves the dynamic procurement
problem using heuristics based on standard stochastic programming principles.
Our method relies on an approach we call the residual tree, which can be used to solve general
multi-stage stochastic programs when the problem uncertainty is not specified analytically but rather
through historical data trajectories related through covariate information. The residual tree method
is an extension of the classical scenario tree method of stochastic programming (see Dupačová et al.
2000), the difference being that scenario paths in a scenario tree are replaced by “residual paths,”
composed of residuals from a regression model relating the uncertainty in question and the available
information.
We show that a challenging multi-stage stochastic program capturing a generic version of the
dynamic procurement problem can be solved in a tractable manner to an arbitrary accuracy via
the residual tree method, following three steps: (i) a least-squares or lasso regression providing
demand forecasts capturing the covariate information; (ii) binning of output residuals for improved
computational efficiency; and (iii) solving a large linear program in which the demand is modeled
using regression-based point forecasts expanded using the binned residual paths. Drawing upon
recent epi-convergence results from stochastic programming, we specifically prove that under natural
assumptions the sequential method just described is asymptotically optimal as the number of similar
products increases.
Finally, we numerically validate the residual tree method on a stylized two-period problem and on
a four-period problem based on data provided by Zara. On the two-period problem, which is similar

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
4 Article submitted to Manufacturing & Service Operations Management; manuscript no.
to other procurement models in the literature, our solutions exhibit sensitivities to the problem
parameters that are intuitive and consistent with existing works. For both instances, our numerical
results are promising in that the residual tree method finds solutions quickly that have near-optimal
finite-sample performance. Our numerical results further show the importance of covariate infor-
mation. For example in the four-period problem, ignoring static covariates results in out-of-sample
cost increases on the order of 6-15%, with statistical significance at the 1% level. Finally, we also
find that considering just 2–3 scenarios for the dynamic procurement problem, as is the case in
the literature to date, is too simplistic and may result in solutions that underperform substantially,
with additional costs of 30%− 66% of the optimal total cost compared with our solution with 10
scenarios, also with statistical significance at the 1% level.
In the remainder of this paper, we discuss the related literature and our contributions in Section 2,
the model considered in Section 3, our proposed solution approach in Section 4, related asymptotic
optimality results in Section 5, and numerical experiments in Section 6. We conclude in Section 7.
The proofs of all mathematical results are relegated to the Appendix. Some of the data presented
in this paper have been disguised to protect its confidentiality, and we emphasize that the views
presented in this paper do not necessarily represent those of the Inditex Group.
2. Literature Review
This paper relates to the literature on production/inventory systems investigating how one or multi-
ple supply sources should be used when demand forecast updates become available over a finite time
horizon. These studies feature a variety of modeling approaches, including multi-period extensions
of the newsvendor model (Lau and Lau 1996), Bayesian updating (Eppen and Iyer 1997, Burnetas
and Gilbert 2001), the martingale model of forecast evolution (Iida and Zipkin 2006, Lu et al. 2006,
Wang et al. 2012) and the forecast band refinement model (Kaminsky and Swaminathan 2001,
2004). Within this body of work, our paper is closest to the practice-oriented studies motivated by
a collaboration with industry, such as Fisher and Raman (1996), Fisher et al. (2001), Jones et al.
(2001) and Peng et al. (2012). We also highlight Escudero et al. (1993) and Higle and Kempf (2011),
which also propose computational approaches based on stochastic programming to address produc-
tion/inventory problems with demand uncertainty. In this vein, the paper most related to ours is
Agrawal et al. (2002), which is a practice-based study that also develops a stochastic programming
model to address the dynamic procurement problem faced by a collaborating retailer, and reports
an industrial implementation. In contrast with all the papers just cited however, the approach we

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 5
present is data-driven, captures a potentially large amount of covariate information, and is justified
by an asymptotic optimality result.
This paper also contributes to the growing literature on data-driven approaches to operations
management challenges, which seeks to inform operational decisions using only available historical
data without a priori distributional assumptions. Studies of data-driven inventory management
problems include Burnetas and Smith (2000), Huh and Rusmevichientong (2009) and Kunnumkal
and Topaloglu (2008), which consider stochastic gradient algorithms; Godfrey and Powell (2001) and
Powell et al. (2004), which rely on adaptive value estimation; Levi et al. (2007), which introduces
a shadow dynamic program; and Ban (2016), which derives a procedure for the optimal estimation
of the (s, S) policy. A number of additional data-driven operations management studies are further
motivated by the increasing availability of large datasets featuring many variables describing each
historical observations (also referred to as covariates, features, or attributes). These include Ban
and Rudin (2014), Ferreira et al. (2015), Bertsimas and Kallus (2014), Bastani and Bayati (2015),
Cohen et al. (2016), Qiang and Bayati (2016) and Ban and Keskin (2016). Within the data-driven
operations management literature just discussed, our work is characterized by its focus on the
dynamic procurement problem, its consideration of covariate information, and the generalizability
to other multi-stage stochastic programs of our data-driven approach for capturing such covariate
information.
From a methodological standpoint our residual tree method is closely related to the generic sce-
nario tree method for solving multi-stage stochastic programs, for which we refer the reader to
Dupačová et al. (2000) for a review up to 2001, and Pennanen and Koivu (2002), Dupačová et al.
(2003), Heitsch and Römisch (2003), Casey and Sen (2005) or Pflug and Hochreiter (2003) for more
recent developments. Specifically, the residual tree method is inspired by Pennanen (2005, 2009),
which provide sufficient conditions for constructing scenario trees that yield consistent solutions. In
the scenario tree method however, the knowledge of the distribution of the underlying stochastic
process is assumed, enabling the decision-maker to simulate arbitrary amounts of data. In contrast,
the residual tree method is intended to be used when the decision-maker does not know the distri-
bution of the underlying stochastic process of interest, but instead has finite observations of other
stochastic processes that are related to the one in question through covariate information.
3. ModelWe formulate our dynamic procurement problem in two steps. We first formulate the stochastic
optimization problem based on a generic description of the demand process. We then describe our
assumed demand process and connect it to data that a fashion retailer is likely to have available.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
6 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Figure 1: Timeline of events.
3.1. Optimization Problem Formulation
We model the management of a single new product over a finite, T -period time horizon indexed
in the forward direction by t = 1, . . . , T . In each period t, the firm may order some quantity of
the product from a vendor chosen from a set S of potential suppliers, letting S = |S|. Orders from
supplier j placed in period t then arrive after a deterministic lead time `j at a cost of ctj.
Stochastic demand arrives in every period, described by a random vector D0tTt=1 defined on the
probability space (Ξ0,F0,P0), where each D0t : Ξ0t→ R+, 1≤ t≤ T is a random variable on P0t,
and P0 = P01× . . .×P0T is the product measure. (We use the index 0 to refer to the new product;
in Section 3.2 we introduce data from other products, indexed differently.) Note the demands up
to time t induce a natural filtration F0t = σ(D−10s (A) : 1≤ s≤ t,A ∈ Ω) on F0. We assume that
the demand D0t may be dependent on a set of (possibly random) covariate features X0t, but defer
a more detailed discussion of the demand process and its dependence on X0t until Section 3.2.
The firm has initial inventory I0. Any unmet demand is assumed lost, incurring opportunity costs
of bt per unit. The firm also incurs a holding cost of ht per unit for inventory held at the end of
periods t= 1, . . . , T − 1. At the end of the horizon, any remaining units of inventory are salvaged,
generating revenue v per unit.
Figure 1 illustrates the sequence of events within a period. Orders are chosen and placed after the
relevant features X0t = x0t have been observed, but before past orders arrive and the new demand
D0t is observed; note this timeline allows for orders from suppliers with zero lead time to arrive in
the same period the order is placed. Let qtj denote the quantity ordered in period t from supplier

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 7
j. We have qtj ∈Qtj, where Qtj is a bounded subset of R+. We require qtj ∈F0t, i.e. adapted to the
natural filtration of the demand process up to time t.
The multi-stage stochastic procurement problem we wish to solve is thus (denoted PP, for “pro-
curement problem”):
minqtj ,It,lt
1≤t≤T,1≤j≤S
E
[T−1∑t=1
htIt +T∑t=1
btlt +T∑t=1
S∑j=1
ctjqtj − vIT
](PP)
s.t.
qtj ∈F0t, ∀ 1≤ t≤ T, ∀ 1≤ j ≤ S, (PPa)
It =
It−1 +∑j∈S
∑1≤τ≤t−1:τ=t−`j
qτj −D0t
+
, ∀ 1≤ t≤ T (PPb)
lt =
D0,t− It−1−∑j∈S
∑1≤τ≤t:τ=t−`j
qτj
+
, ∀ 1≤ t≤ T (PPc)
qtj ∈Qtj, ∀ 1≤ t≤ T, ∀1 ≤ j ≤ S (PPd)
It ≥ 0, lt ≥ 0, ∀ 1≤ t≤ T, (PPe)
where the expectation is taken over the measure induced by D01, . . . ,D0T. Note∑
1≤τ≤t:τ=t−`j
qτj de-
notes the total order quantity arriving from supplier j during period t, lt the lost sales incurred
during period t and It the inventory on-hand at the end of time t. The constraint (PPa) is a re-
quirement that decisions are adapted to the history, (PPb) captures the inventory dynamics, (PPc)
captures the lost sales dynamics and (PPd)–(PPe) define the domains of the decision variables. Note
that constraints (PPb) and (PPc) apply almost surely. We assume the parameters of problem (PP)
are such that it is feasible and thus at least one optimal solution exists.
Denote the solution to (PP) by (q∗, I∗, l∗) ∈ RTS × RT × RT = RT (S+2), where q∗ =
[q∗1j, . . . , q∗Tj]
Sj=1 ∈ RTS, I∗ = [I∗1 , . . . , I
∗T ] ∈ RT and l∗ = [l∗1, . . . , l
∗T ] ∈ RT . (I0, the initial inventory
on-hand, is a constant assumed given as problem data.)
Some features of optimization formulation (PP) are motivated by considerations in Zara’s environ-
ment. The assumed unlimited number of supply sources with different delivery lead-times matches
the high number and diversity of Zara’s vendors, along with the various ground, air and sea trans-
portation options typically available for each one (in this model different transportation modes used
with the same vendor may be captured as different supply sources). While lead-times are assumed

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
8 Article submitted to Manufacturing & Service Operations Management; manuscript no.
to be deterministic for tractability reasons, we understand the typical variability of vendor delivery
times to be lower than, or at worst comparable to, our intended planning period of one week. We
also emphasize that the relatively mild assumption of boundedness imposed on sets Qtj allows to
capture realistic supply constraints and cost structures such as limited vendor capacity, minimum
order quantities, and all-units discount schemes. Finally, the assumed lost sales dynamics align
with Zara’s observations of typical customer behaviors when confronted with stock-outs of fashion
products. While these lost sales dynamics present specific tractability challenges (Zipkin 2008), the
following proposition establishes that the inventory and lost sales constraints (PPb)-(PPc) in (PP)
have equivalent linear expressions in this case.
Proposition 1. The multi-stage stochastic program (PP) is equivalent to the following problem,
in that the optimal solution(s) and the optimal objective values coincide:
minqtj ,It,lt
1≤t≤T,1≤j≤S
E
[T−1∑t=1
htIt +T∑t=1
btlt +T∑t=1
S∑j=1
ctjqtj − vIT
](PP2)
s.t.
qtj ∈F0t, ∀ 1≤ t≤ T, ∀ 1≤ j ≤ S, (PP2a)
It = It−1 + lt +∑j∈S
∑1≤τ≤t−1:τ=t−`j
qτj −D0t, ∀ 1≤ t≤ T. (PP2b)
qtj ∈Qtj, ∀ 1≤ t≤ T, ∀1 ≤ j ≤ S (PP2c)
It ≥ 0, lt ≥ 0, ∀ 1≤ t≤ T. (PP2d)
3.2. Demand Model
In this section we elaborate on the assumed demand process and its connection to data available
to the retailer. Specifically, we assume that random demand D0t for our focal product in period t is
given by the following linear demand model:
D0t|(X0t = x0t) = αt +β>t x0t + εt, (1)
where αt ∈R is a scalar intercept coefficient, βt ∈Rmt is the vector of model coefficients, x0t ∈Rmt
is a vector of mt observable product features as of time t, and εt is an error random variable to be
described shortly.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 9
While the feature vector x0t is known by the firm at the outset of period t, we assume that the
coefficients αt and βt are unknown and estimated from data. For this purpose, the firm has access
to a database of past demand trajectories D= (xk1, dk1)nk=1, . . . , (xkT , dkT )nk=1, which are assumed
sampled from the same population. That is, the data in D are sampled from
Dkt|(Xkt = xkt) = αt +β>t xkt + εt, 1≤ k≤ n. (2)
The database D may be simulated based on a known analytical demand model, but we envision
D more typically representing past demand for n similar products introduced previously (e.g., in
a past selling season). Our model explicitly allows for differences in the characteristics of products
through the feature vectors xkt, which may include static product characteristics (e.g., capturing
a product’s price, color, fabric, or design style, or expert predictions of the product’s popularity)
and known time-dependent factors (e.g., holiday indicators or seasonality indices). We note that the
coefficients αt and βt apply both to the new product 0 and all the products k= 1, . . . , n represented
in D, with βt capturing the impact of the features on expected demand in period t. A key aspect of
this model is that we explicitly allow for the feature dimension mt to change over time to allow for a
growing information set. This allows xkt also to include dynamic features such as realized demands
from past periods, so that our model subsumes martingale and auto-regressive demand processes.
More broadly, the inclusion of an arbitrary selection of variables only realized over time, including
past demand observations, enables the learning component of our model. This learning would typi-
cally be reflected by an estimated positive correlation structure between the initial observations of
weekly sales and sales subsequently predicted, and/or by an estimated decreasing variance pattern
for the random error term εt over time. While a variety of alternative demand learning models have
been used in past studies of related dynamic production/inventory problems (e.g., the Bayesian
model in Burnetas and Gilbert 2001, the MMFE in Wang et al. 2012, the band refinement model
in Kaminsky and Swaminathan 2001, 2004), we emphasize that our approach is data-driven. That
is, the main input assumed for the demand model (2), the combined estimation and optimization
method to be presented in Section 4 and the related asymptotic optimality theory to be developed
in Section 5 is a dataset of historical observations, as opposed to exogenously given parameters.
Indeed, an important motivation for the specific demand model considered here is the existence of
the ubiquitous associated estimation methods of linear and Lasso regressions, which is appealing
from both practical and theoretical standpoints.
As an example, if the new product 0 were a particular t-shirt design, we might let the database
D include the demand histories for other t-shirt products offered last season. For any product

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
10 Article submitted to Manufacturing & Service Operations Management; manuscript no.
k= 0,1, . . . , n and any time period t, the feature vector xkt could include numerical representations
of t-shirt k’s color, fabric, and design; the historical demand strength of t-shirts during the time
of year represented by period t; and the observed demand for t-shirt k in period t− 1. We remark
that in describing the database D we are not distinguishing between observed sales and demand.
In reality, sales may be a censored representation of demand. We discuss this complication and
remedies in Section 4.3.
The random errors εt are assumed to be independent across time and of the feature vectors Xkt,
k= 1, . . . , n, and common over all products k= 1, . . . , n. We assume that the errors corresponding to
period t are drawn from a continuous distribution with strictly increasing cumulative distribution
function Fεt (i.e., an inverse cdf exists), with mean zero and variance σ2t . As the error random
variable is not product-dependent, the underlying assumption is that the demands within the same
product family have the same distribution once adjusted for the mean. For example, the demands
for two different t-shirt designs both being normally distributed with the same variance but different
means would satisfy the assumptions of our model. This assumption facilitates cross-learning of
product demands. We believe this is a reasonable assumption, since all major effects due to other
factors are supposed to be captured by the linear demand model, leaving behind a noise term with
a common distribution across products.
The linear demand model (2) is a widely-used and useful model that can arbitrarily approximate
nonlinear models and is general enough to subsume many time-series models and martingale models
such as the Martingale Model of Forecast Evolution (MMFE) of Heath and Jackson (1994) and
Graves et al. (1986). We refer the readers to Ban and Rudin (2014) for details on how smooth
nonlinear models can be approximated by linear ones, and on how time-series models and MMFE
models can be captured by the linear demand model.
4. Solution Approach: the Residual Tree Method
The traditional approach to solving multi-stage stochastic programs is to model the uncertainty
using scenario trees that directly represent the evolution of the key uncertainty drivers such as
demand or price. This is feasible when the decision-maker has the knowledge of the data-generating
mechanism. Such a mechanism, however, is not available for our problem of procuring stocks of a
never-before sold product. As such, we develop a new method which builds trees based on residuals
arising from linear regressions run on historical data on similar items sold in the past.
As summarized in Section 1, our approach first fits linear or lasso regression models to the his-
torical demand database D, estimating the parameters αt and βt for all t and calculating residuals,
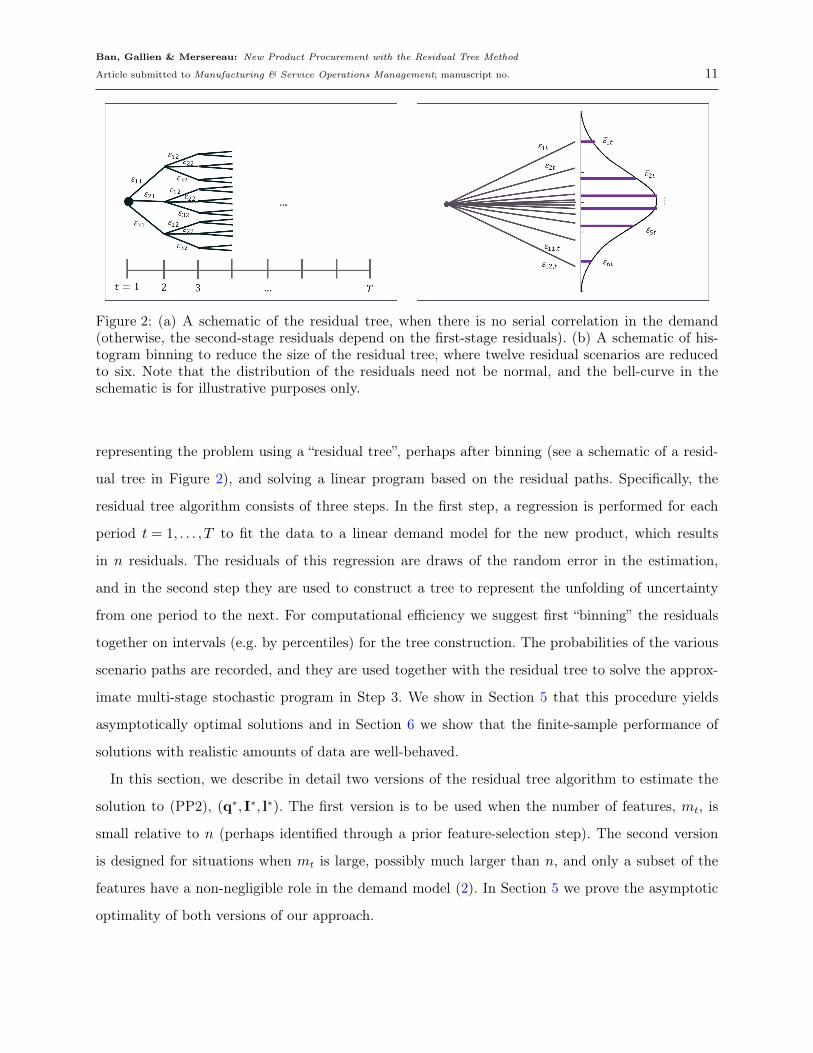
Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 11
Figure 2: (a) A schematic of the residual tree, when there is no serial correlation in the demand(otherwise, the second-stage residuals depend on the first-stage residuals). (b) A schematic of his-togram binning to reduce the size of the residual tree, where twelve residual scenarios are reducedto six. Note that the distribution of the residuals need not be normal, and the bell-curve in theschematic is for illustrative purposes only.
representing the problem using a “residual tree”, perhaps after binning (see a schematic of a resid-
ual tree in Figure 2), and solving a linear program based on the residual paths. Specifically, the
residual tree algorithm consists of three steps. In the first step, a regression is performed for each
period t = 1, . . . , T to fit the data to a linear demand model for the new product, which results
in n residuals. The residuals of this regression are draws of the random error in the estimation,
and in the second step they are used to construct a tree to represent the unfolding of uncertainty
from one period to the next. For computational efficiency we suggest first “binning” the residuals
together on intervals (e.g. by percentiles) for the tree construction. The probabilities of the various
scenario paths are recorded, and they are used together with the residual tree to solve the approx-
imate multi-stage stochastic program in Step 3. We show in Section 5 that this procedure yields
asymptotically optimal solutions and in Section 6 we show that the finite-sample performance of
solutions with realistic amounts of data are well-behaved.
In this section, we describe in detail two versions of the residual tree algorithm to estimate the
solution to (PP2), (q∗, I∗, l∗). The first version is to be used when the number of features, mt, is
small relative to n (perhaps identified through a prior feature-selection step). The second version
is designed for situations when mt is large, possibly much larger than n, and only a subset of the
features have a non-negligible role in the demand model (2). In Section 5 we prove the asymptotic
optimality of both versions of our approach.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
12 Article submitted to Manufacturing & Service Operations Management; manuscript no.
4.1. Residual Tree Algorithm 1
Step 1. OLS Regression. For each t ∈ [1, . . . , T ], perform least-squares regression on available data
on the n historical demand paths:
minαt∈R, βt∈Rmt
n∑k=1
(dkt−αt−β>t xkt)2. (3)
Let (αt, βt) denote the optimal solution, and εktnk=1 the residuals. Then the estimated
demand model for the new product (labelled 0) is
D0t = αt + β>t x0t, (4)
and we have n “sample” estimates for the new product: dk0t = αt + β>t x0t + εktnk=1, where
εkt are the residuals from the least-squares regression (3).
Step 2. Residual tree construction. For product 0, we now have n predicted samples at every point
in time. Thus there are nT scenario paths in total. We could use them directly, with each
scenario path occurring with probability 1/nT , or, if n is large, reduce the computation time
by smoothing out the residual distribution via a histogram (see Fig. 2 (b)). Let Bt(n) denote
the number of bins at time t, εbt, b= 1, . . . ,Bt(n) the center of the b-th bin at time t, and
pbt(n) the probability of being in bin b at time t. Bt(n) is necessarily at most of size n; the
smaller the value, the more coarse the histogram, but the more computationally efficient the
estimated stochastic optimization problem. After histogram binning, we have Bt(n) sample
predictions for the demand at time t conditional on x0t: d0t(b) := αt+ β>t x0t+ εbt1≤b≤Bt(n),
each occurring with probability pbt(n). The total number of scenarios is thus reduced to
Bn = B1(n)× . . .×BT (n). Let Bn = b1, . . . , bT1≤bt≤Bt(n),1≤t≤T
denote the set of labels for all
possible scenario paths, and denote a particular scenario path by b = [b1, . . . , bT ], which
occurs with probability pb(n) = pb1(n)× . . .× pbT (n). Denote the discretized state space
by Ξn = Ξ1(n) × . . . × ΞT (n) and the corresponding discretized probability measure by
Pn = P1(n)× . . .× PT (n).
There are a myriad of ways to construct the histogram, with the total number of bins,
Bt(n), and the ranges for each bin interval being free parameters. However, for asymptotic

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 13
optimality, we do require the histogram measure to be asymptotically equivalent to the
sample-average measure, that is, for all y ∈R and 1≤ t≤ T ,
∣∣∣∣ ∑1≤b≤Bt(n)
pbt(n)I(d0t(b)≤ y)− 1
n
n∑k=1
I(dk0t ≤ y)
∣∣∣∣= oP (1), (5)
where oP (1) denotes convergence in probability to zero as n tends to infinity. In other words,
the binned histograms need to converge to the true density just as the sample-average
distribution.
One simple and intuitive way to bin the residuals so that the above is satisfied is to bin
them into finer and finer intervals as n grows larger and larger (e.g. by binning into quartiles
at first, then by deciles, then in ever smaller percentiles as n grows).
Step 3. Solve the estimated problem using the residual tree from Step 2. Compute replenishment
decisions by solving the following optimization problem (denoted EPP, for “estimated pro-
curement problem”):
minqtj ,It,lt
1≤t≤T,1≤j≤S
∑b∈Bn
p(b;n)
[T−1∑t=1
htIt(b;n) +T∑t=1
btlt(b;n) +T∑t=1
S∑j=1
ctjqtj(b;n)− vIT (b;n)
]
(EPP)s.t.
qtj(b;n) = qtj(b′;n), ∀ b,b′ ∈Bn, s.t. d0τ (b;n) = d0τ (b
′;n),
∀ 1≤ τ ≤ t− 1, ∀ 1≤ t≤ T, ∀ 1≤ j ≤ S,
It(b;n) = It−1(b;n) +∑j∈S
+lt(b;n) +∑
1≤τ≤t−1:τ=t−`j
qτj(b;n)− d0,t(b;n),
∀ b∈Bn, ∀ 1≤ t≤ T,
qtj ∈Qtj, ∀ 1≤ t≤ T, ∀ 1≤ j ≤ S,
It(b;n)≥ 0, ∀ b∈Bn, ∀ 1≤ t≤ T,
lt(b;n)≥ 0, ∀ b∈Bn, ∀ 1≤ t≤ T,
where we indicate the dependence of the demand data and decisions on the particular
scenario path b explicitly. Denote the solution to (EPP) by (q(n), I(n), l(n))∈ (RTS×RT ×
RT )Bn , where q(n) = [q1j, . . . , qTj]Sj=1 ∈RTS, I(n) = [I1, . . . , IT ]∈RT and l(n) = [l1, . . . , lT ]∈
RT .

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
14 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Note that, for the sake of exposition simplicity, we continue to leave the sets Qtj unspec-
ified in (EPP), reminding the reader that the theory to be developed in Section 5 is only
proven here to hold when they are all bounded. Various possible choices of set types with
that property lead to different further specifications of (EPP) for computational purposes.
For example, closed intervals [0,Kj] where Kj is a capacity limit for supply source j would
be implemented as a linear program, sets of the type 0 ∪ [Oj,Kj] would also capture a
minimum order quantity Oj and lead to a mixed integer programming formulation. We refer
the reader to Subsection 4.3 for a more general discussion of implementation issues.
4.2. Residual Tree Algorithm 2: High Dimensional (“Big”) Data
When the number of features available at time t, mt is large, possibly much larger than n, then not
all play a role in the demand model (2). If only stmt of the features play a significant role (i.e. the
coefficients for all other features are zero in the demand model (2)), then we propose modifying Step
1 of the Residual Tree Algorithm by replacing the least squares regression with Lasso regression as
follows (see Belloni and Chernozhukov 2009 for a review and extension of recent results on Lasso
regression):
Step 1′. Lasso Regression. For each t∈ [1, . . . , T ], perform Lasso regularized regression on available
data on the n existing products:
minβt∈Rmt
n∑k=1
(dkt−αt−β>t xkt) +λn||βt||1,
where λn ≥ 0 is the regularization parameter, to be chosen via cross-validation (we refer to
Friedman et al. 2009 for readers unfamiliar with this technique), and || · ||1 denotes the L1
norm. Denote the solution vector by βLassot . By the properties of Lasso regression, many
elements of βLassot are zero, that is, βLassot is a sparse vector (with high probability; see
Belloni and Chernozhukov 2009 for details on the theoretical properties of βLassot ). The
estimated demand model for the new product is thus
DLasso0t = αLasso>t + βLasso>t xLasso0t + εt, (6)
and we have n “sample” estimates for the new product: dLasso0t = αLasso>t + βLasso>t xLasso0t +
εLassokt nk=1.
Note that (6) is a consistent estimate of the true sparse model as n→∞, mt =mt(n)→∞ and
st = st(n)→∞ under some mild technical conditions (Belloni and Chernozhukov 2009).

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 15
4.3. Implementation Issues
The models and algorithms described above in Section 3 and Sections 4.1-4.2 have been designed to
form the core of a practical solution to the dynamic procurement problem. Using these models to
develop an actual decision support system may require a number of company-specific adaptations
and extensions, however. We mention here a few of them, based on our experience working with the
Spanish firm Zara to develop and implement a procurement support system based on a stochastic
programming formulation derived from (PP2). This discussion is limited because the main focus in
this paper is to present, analyze and evaluate the core generic solution to the dynamic procurement
problem involving the residual tree method for capturing covariate information described earlier,
most of these extensions have been discussed elsewhere (e.g., Smith et al. 2002, Patel 2012, Serel
2016), and we are not at liberty to disclose all of Zara’s specific implementation details.
A first challenge is demand censoring. Specifically, while most firms have reliable records of their
historical sales information, many currently do not systematically estimate the demand information
which the model described in Section 4 assumes to be available. A number of methods for estimating
sales lost from stockouts may be possible depending on context, but we highlight two different
ones implemented by Zara. A first method, known as store clusters, is described in more detail in
Gallien et al. (2015). It involves the inference of what sales would have been in a particular store
on a day when it is out of stock from sales observations in one or several other stores and the
statistical characterization of the historical relationships among sales across stores. Another method
for estimating the weekly demand, described in Caro and Gallien (2012), involves the estimation
of demand during days of the week when a store is out of stock based on sales observations during
days with stock, correcting for appropriate intra- and inter-week seasonality factors.
Another challenge is to capture any additional cost or constraints that may be specific to particular
vendors, such as fixed order costs, quantity discounts and/or minimum order quantities. As discussed
for example in Bertsimas and Weismantel (2005), it is conceptually straightforward to capture these
features as part of the decision support system by expanding optimization problem (PP2) using
integer variables. This may induce an increase in computational time or solution sub-optimality
however.
Finally, we highlight the substantial challenges associated with the development and deployment
of any software-based decision support system adapted to the dynamic procurement problem in an
industrial setting. We refer the reader to Smith et al. (2002) for a more detailed discussion of these
software implementation challenges, and to Figure 3 for an illustration of the graphical interface
recently developed by Zara for such a system. The interface is designed to be used by a fashion buyer

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
16 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Figure 3: Screen copy of a component of the graphical user interface developed by the Spanishfirm Zara to deploy a decision support system adapted to the dynamic procurement problem in itsenvironment.
charged with making procurement decisions for a new product, and it includes tools for the buyer
to visualize and edit the demand forecasts (see the line chart in the graph) and to see, edit, and
optimize the procurement plan (see the bar chart in the graph and the table on the right-hand-side).
5. Theory: Asymptotic Optimality of the Residual Tree MethodThe main result of this section is that if nature generates product family demand data from the
random models (1)–(2), then both the optimal value and the optimal solution of (EPP ) converge to
the optimal objective value and the optimal solution of (PP ) as the number of products n tends to
infinity, which is known as epi-convergence in the stochastic programming literature. (Note that we
use the terms ‘epi-convergence’ and the more self-evident ‘asymptotic optimality’ interchangeably.)
We state this formally below; first for Residual Tree Algorithm 1 then for Residual Tree Algorithm
2. The proofs of the results are deferred to Appendix B, and below we provide some qualitative
explanations of the key ingredients.
Theorem 1. The optimal values of (EPP ) using Residual Tree Algorithm 1 converge to that of
(PP ) as n→∞ and all cluster points of q11(n), . . . , q1S(n), I1(n), l1(n)n∈N are optimal first-stage
solutions of (PP ).

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 17
To prove Theorem 1, we make use of recent results of Pennanen (2005) and Pennanen (2009),
who establish sufficient conditions for discretized multi-stage stochastic programs to epi-converge
(i.e. both the objective and the first-stage solutions converge). The results in Pennanen (2005)
and Pennanen (2009) are significant because epi-convergent solution algorithms have to date been
established on a case-by-case basis, if discussed at all. Our main contributions are in recognizing
the applicability of these results to the residual tree method and in establishing that the residual
tree algorithm satisfies the required conditions. Intuitively, the residual tree translates to a dis-
cretized approximation of a multi-stage stochastic program, which is why we can adopt the results
of Pennanen (2005) and Pennanen (2009).
Nevertheless, the full proof is quite intricate, and we simplify the presentation by first establishing
three separate lemmas on the nature of the true problem (PP), one on the continuity property of
the random objective function, one on the expectation of the objective function, and one on the
property of the demand model. Apart from the well-behaved nature of (PP), asymptotic optimality
requires the consistency of the estimated demand process (with or without the residual binning),
and convergence of the probabilities of the scenario paths as the number of similar products grows.
We show that our residual trees (with and without binning) satisfy both requirements, which is
intuitive because they are constructed on the basis of consistent approximations of the true demand
process. The same requirements apply to Residual Tree Algorithm 2, whose convergence we formally
state below.
Corollary 1. The optimal values of (EPP ) using Residual Tree Algorithm 2 converge to that of
(PP ) as n→∞ and all cluster points of q11(n), . . . , q1S(n), I1(n), l1(n)n∈N are optimal first-stage
solutions of (PP ).
6. Numerical StudyIn this section we present results of a numerical study designed to understand the properties and
behavior of the residual tree algorithm. Our primary goals in this section are to understand the finite-
sample performance of the algorithm— namely, the dependence of the performance on the amount
of available data (both covariate information and the number of observations), the resolution of the
residual tree, and the running time of the algorithm— thereby providing insight into its potential for
wide-spread applicability in practice. All results we report on were calculated using MATLAB 8.6,
calling Gurobi 6.00 to solve linear programs, running on a single Macintosh desktop computer with
a 3.2 GHz Intel i5 processor. We view this as a conservative choice relative to industrial computing
clusters available at many firms.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
18 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Our tests focus on two sets of procurement problem instances differing primarily in how we
simulate the demand data inputs. The first set of problem instances are two-period problems in
which the demand does not depend on static covariates but is serially correlated across periods. The
second includes four-period problems in which the generative model is based on both static and time-
series covariates. In both cases, we first specify the true demand model (either by construction or
from raw Zara data), then simulate data sets of various sizes from them to evaluate the convergence
behavior of the residual tree algorithm.
For both sets of examples we use the “Residual Tree Algorithm 1” as described in Section 4, and we
reduce the size of our residual trees using the binning technique described in Step 2, which controls
the number of branches Bt(n) at each node in period t of the residual tree. The bin breakpoints are
set at equal percentiles of the residual data used to fit the tree, and we represent each bin in the
tree by its median residual value. It follows that all the branches b= 1, . . . ,Bt(n) emanating from a
node are assigned equal probabilities pbt(n) = 1/Bt(n). Note that this binning method satisfies the
required condition specified in (5) if Bt(n) is made to grow to infinity with n.
6.1. Two-Period Instances without Static Covariates
For the instances considered in this subsection, there are two periods with ordering opportunities
and demand realizations in each period. There are three supply options: the firm can place an order
to be delivered prior to period 1 at cost 0.5 (“pre-season” supplier), the firm can place an order prior
to period 1 to be delivered between the two periods at cost 0.5 (“slow” supplier), and the firm can
deliver after period 1 for delivery prior to period 2 at cost 1 (“fast” supplier). We assume a penalty
cost of b= b1 = b2 = 11 per unit of unmet demand, a holding cost of h1 = 0.25 per unit carried over
between the two periods, and no salvage value for units left over at the end of the problem horizon.
We simulate demand trajectories such that demand realizations do not depend on any static
covariates but are linearly dependent across periods. For each path, demand in period 1 is sampled
from a normal distribution with mean 1000 and standard deviation 100, and demand in period 2 is
sampled from a normal distribution with standard deviation σ2 = 100 and mean equal to the period
1 demand realization. That is, we sample based on the following population demand models:
Dk1 = 1000 + ε1, ε1 ∼N(0,1002), (7)
Dk2 = 0 + 1D1 + ε2, ε2 ∼N(0, σ22),
for k= 1, . . . , n, where n is the number of similar products in the product family for which the firm
has demand data. In what follows, we set σ2 = 100 unless otherwise indicated.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 19
Note that in demand model (7) the standard deviation σ2 of the second error term ε2 is a
parameter capturing the amount of learning occurring between the first and the second period. This
is because smaller values of σ2 induce larger correlations between Dk1 and Dk2 in our problem, so
that observations of the first-period demand are more predictive of the second-period demand when
σ2 is small. As a result, the problem instance defined in this subsection is qualitatively similar to the
two period models with learning considered for example in Fisher et al. (2001), Milner and Kouvelis
(2002, 2005) and Li et al. (2009).
For each of the results reported here, we run the algorithm on n= 200 independently generated
training sets, then we evaluate the resulting policies on a single, common, and independently gen-
erated “test set.” We vary the number n of demand trajectories in the training sets, but we use
a common test set of size 100,000. (Since the instances we consider here do not depend on static
covariates, the same policy applies to all paths in the test set. We take a different approach in the
next subsection, where demand depends on static covariates that differ across test set paths.) Times,
costs, and orders reported in this subsection are averaged across the 200 runs. Unless indicated
otherwise, we keep the number of bins per node constant (i.e., B = Bt = Bt(n) for all t) for each
instance. We examine the performance of our approach as a function of the training set size n and
of the tree size, measured by the binning parameter B.
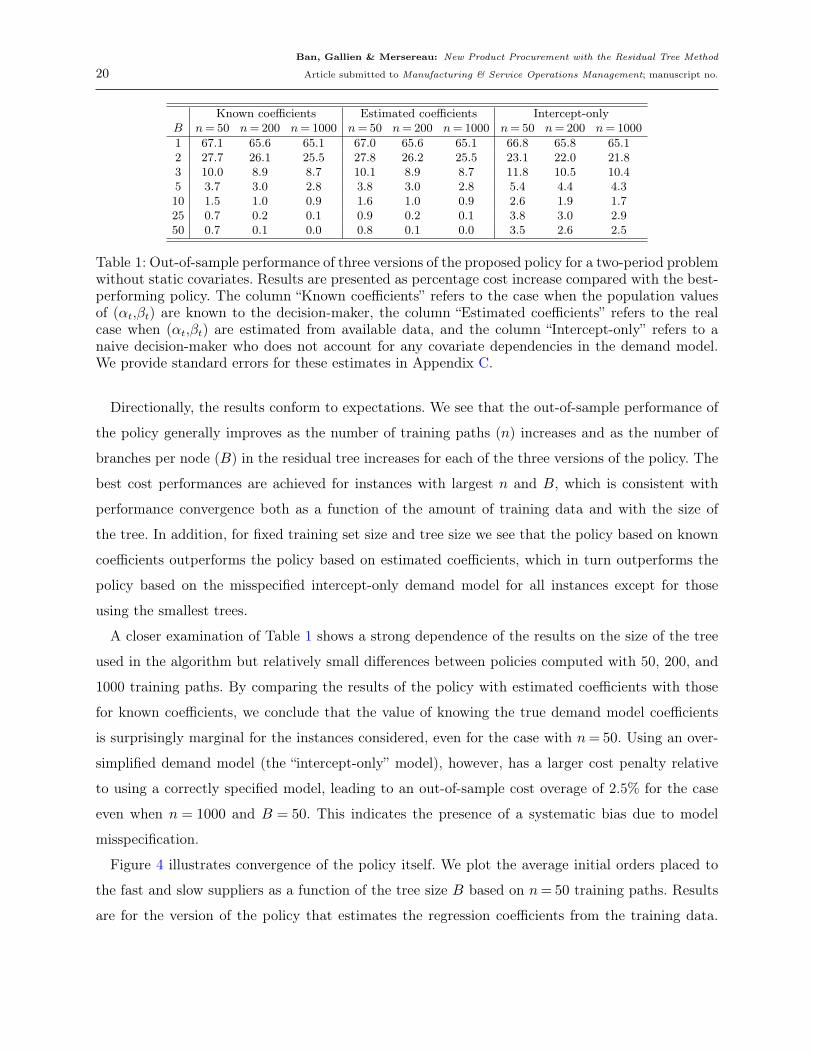
Table 1 reports the performances of policies generated using training sets (n= 50,200,1000) and
trees of different sizes (B =B1 =B2 = 1,2,3,5,10,25,50). Among the policies considered, the one
calculated using n= 1000 and B = 50 achieves the best average out-of-sample cost of 1813.46 mea-
sured on the test set, achieving numerical convergence within 1%. We therefore express the average
percentage costs in Table 1 as percentages relative to the cost of this best-performing policy. We
give results for versions of the model in which the coefficients in the generative demand model
(7) are known, unknown and estimated from the training data, and estimated using a misspeci-
fied intercept-only set of models that ignore the dependence between the first and second period
demands.
Remarkably, the “estimated coefficients” policy based on a relatively small dataset of n = 50
training paths and a relatively small residual tree with B = 10 branches per node achieves an out-
of-sample cost performance just 1.6% larger than our best policy. This is a promising result from an
implementation standpoint, as n= 50 is a realistically small number of similar items in a product
family. B = 10 branches per node achieves an attractive balance in this case between oversimplifying
the stochasticity in the problem and computational efficiency.
Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
20 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Known coefficients Estimated coefficients Intercept-onlyB n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000
1 67.1 65.6 65.1 67.0 65.6 65.1 66.8 65.8 65.12 27.7 26.1 25.5 27.8 26.2 25.5 23.1 22.0 21.83 10.0 8.9 8.7 10.1 8.9 8.7 11.8 10.5 10.45 3.7 3.0 2.8 3.8 3.0 2.8 5.4 4.4 4.310 1.5 1.0 0.9 1.6 1.0 0.9 2.6 1.9 1.725 0.7 0.2 0.1 0.9 0.2 0.1 3.8 3.0 2.950 0.7 0.1 0.0 0.8 0.1 0.0 3.5 2.6 2.5
Table 1: Out-of-sample performance of three versions of the proposed policy for a two-period problemwithout static covariates. Results are presented as percentage cost increase compared with the best-performing policy. The column “Known coefficients” refers to the case when the population valuesof (αt,βt) are known to the decision-maker, the column “Estimated coefficients” refers to the realcase when (αt,βt) are estimated from available data, and the column “Intercept-only” refers to anaive decision-maker who does not account for any covariate dependencies in the demand model.We provide standard errors for these estimates in Appendix C.
Directionally, the results conform to expectations. We see that the out-of-sample performance of
the policy generally improves as the number of training paths (n) increases and as the number of
branches per node (B) in the residual tree increases for each of the three versions of the policy. The
best cost performances are achieved for instances with largest n and B, which is consistent with
performance convergence both as a function of the amount of training data and with the size of
the tree. In addition, for fixed training set size and tree size we see that the policy based on known
coefficients outperforms the policy based on estimated coefficients, which in turn outperforms the
policy based on the misspecified intercept-only demand model for all instances except for those
using the smallest trees.
A closer examination of Table 1 shows a strong dependence of the results on the size of the tree
used in the algorithm but relatively small differences between policies computed with 50, 200, and
1000 training paths. By comparing the results of the policy with estimated coefficients with those
for known coefficients, we conclude that the value of knowing the true demand model coefficients
is surprisingly marginal for the instances considered, even for the case with n= 50. Using an over-
simplified demand model (the “intercept-only” model), however, has a larger cost penalty relative
to using a correctly specified model, leading to an out-of-sample cost overage of 2.5% for the case
even when n = 1000 and B = 50. This indicates the presence of a systematic bias due to model
misspecification.
Figure 4 illustrates convergence of the policy itself. We plot the average initial orders placed to
the fast and slow suppliers as a function of the tree size B based on n= 50 training paths. Results
are for the version of the policy that estimates the regression coefficients from the training data.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 21
600
700
800
900
1000
1100
1200
1300
1400
0 10 20 30 40 50
Initialorder
Branchespernode(B)
Pre-season supplier Slowsupplier
Figure 4: Initial orders under the policy as a function of the number of branches per node (B) inthe residual tree.
We omit the cases with more training paths (n = 200,1000) from the plot, but we note that the
average initial orders implied by those policies are nearly identical to the results plotted in Figure
4. Overall, we conclude that the numerical results are consistent with asymptotic optimality as a
function of both n and B.
We have observed that the computation time required to compute the policy depends primarily on
the size of the residual tree. The largest tree we considered (B = 50) required an average computation
time of approximately 24 seconds to compute a policy based on a single training set of 1000 demand
paths.
In all the computations discussed above, we have built residual trees with the same number of
bins Bt(n) for each node. However, the architecture of the residual tree can be optimized for a
particular instance. Figure 5 shows the out-of-sample performance of the policies generated from
residual trees with more or fewer bins in the first period relative to the second period. Letting
B1 and B2 indicate the number of bins per node in the first and second periods, respectively, we
consider 9 policies with B1 = 1,2,3,4,6,9,12,18,36 and B2 = 36/B1. We see that for the particular
problem considered, the best policies result from slightly more branching in the first period relative
to the second (B1 = 9,B2 = 4). In practice, the best tree architecture to use for a given problem
depends on the underlying uncertainty and how it evolves over time.
We have also investigated the sensitivity of the policies generated by our approach to various
problem parameters. We have found the sensitivities to the problem cost parameters to be quite
intuitive, and we omit the details in the interest of brevity. For example, we have seen that the
average total order quantity increases with the shortage penalty cost b and decreases with the
supply costs. We have also found that as we increase the costs of the pre-season and slow suppliers

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
22 Article submitted to Manufacturing & Service Operations Management; manuscript no.
1200
1250
1300
1350
1400
1450
1500
1550
1600
1650
0 10 20 30 40AverageO
ut-of-Sam
plePerfo
rmance
B1=36/B2
Figure 5: Out-of-sample performance of policies based on residual trees with more or fewer bins inthe first period relative to the second period.
relative to the fast supplier, the retailer (intuitively) tends to substitute the fast supplier for the
less responsive suppliers.
Figure 6 shows how the average orders placed with the various supply options depend on the
learning parameter σ2 defined earlier. We observe that total orders tend to increase with σ2, which
can be understood from basic newsvendor arguments; that is, the retailer stocks more stock to buffer
added demand uncertainty. This increase comes from larger orders placed with the slow supplier.
We observe that orders with the pre-season supplier are unaffected by σ2 in these instances. (The
demand uncertainty in period 1 of our problem is relatively small compared with the expected
demand in period 2, implying that the problem effectively decomposes across periods.) The average
orders placed with the fast supplier actually decrease with σ2, which is more clearly evident in
the right-hand plot of Figure 6. Because smaller values of σ2 reflect a greater amount of learning
occurring between the first and second periods, our results suggest that the attractiveness of the fast
supplier increases with the ability to better predict second period demand based on the observation
of demand in the first period. We have confirmed this insight by measuring the increase in cost
when we make the fast supplier unavailable. Indeed, this cost increase exceeds 7% for σ2 = 25 but
is only 2% for σ2 = 200. We note that these results are qualitatively consistent with the numerical
findings for the value of flexibility reported in analytical studies of two period ordering problems
with learning, such as Milner and Kouvelis (2002, 2005).
Figure 7 illustrates the policy we compute for ordering from the fast supply option as a function
of realized first-period demand. We see that fast supplier orders given σ2 = 200 are no larger than
orders given σ2 = 25, in keeping with Figure 6. Both computed policies therefore involve a minimum
threshold for the second period order based on first period demand realization, and a linear increase

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 23
0
500
1000
1500
2000
2500
0 50 100 150 200
Averageo
rderquantity
s2
Pre-season supplier Slowsupplier Fastsupplier Totalorder
0
10
20
30
40
50
60
70
80
90
100
0 50 100 150 200
Averageo
rderquantity
s2
Fastsupplier
Figure 6: Sensitivity of policy to standard deviation σ2 of ε2. (left plot) Average fast supplier ordersshown with smaller graph scaling. (right plot). (Policies are averaged over all runs and all test setdemand paths for training sets of size n= 200 and residual trees with B1 =B1 = 25 branches pernode.)
for the second period order beyond that threshold. This exactly matches the (s,S) policy structure
that is proven to be optimal or near-optimal in analytical studies of two period ordering problems
with specific distributional assumptions, such as Milner and Kouvelis (2005) and Li et al. (2009).
Furthermore, we note that the ordering threshold for the second order decreases with the amount
of learning, and that the slope of the increasing portion of both plots is approximately two. This
comes from two sources: (1) each additional unit of first-period sales depletes stock by one unit
that must be replenished, and (2) each additional unit of first-period demand raises the expectation
for second-period demand by one unit, arising from the slope of “1” in the equation for D2 in (7).
Overall, we conclude that the solutions produced by our computational approach exhibit the same
key qualitative properties that were previously established by available analytical and parametric
studies of similar two period problem instances.
6.2. Instances with Static Covariates
As discussed in Section 3.2, a key innovation of our approach is its accounting for covariates in its
assumed demand process. While the demand model considered in the previous subsection includes
lagged demand as a “dynamic” covariate in the second period, we would also like to consider demand
models that include “static” covariates that reflect information known about the product prior to
the selling season. As mentioned earlier, in practice these static covariates may capture features
such as price, design, or expected popularity.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
24 Article submitted to Manufacturing & Service Operations Management; manuscript no.
0
50
100
150
200
250
300
350
400
450
500
750 850 950 1050 1150 1250
Fastsu
pplierorder
Realizeddemandinfirstperiod
s2 = 200 s2 = 25
Figure 7: Policy for ordering from fast supplier as a function of the first-period demand realization.(Each policy is computed based on a single training set path.)
In this section we consider four-period problems the population demand model includes both static
and dynamic covariates. Specifically, the population demand models for the k = 1, . . . , n products
are:
Dk1 = 738 + 1072Xk1− 403Xk2 + 2.8x3− 55Xk4 + ε1+ , ε1 ∼N(0,10442),
Dk2 = −399− 638Xk1 + 53Xk4 + 0.854Dk1 + ε2+ , ε2 ∼N(0,7812),
Dk3 = −5 + 0.955Dk2 + ε3+ , ε3 ∼N(0,6012),
Dk4 = 874− 46Xk4 + 0.516Dk2 + 0.318Dk3 + ε4+ , ε4 ∼N(0,8202),
where the static covariates are distributed as follows:
Xk1iid∼ Bernoulli(0.25),
Xk2iid∼ Bernoulli(0.5),
Xk3iid∼ Normal(900,2002),
Xk4iid∼ Discrete Uniform on 7.95,8.95, . . . ,22.95.
This demand model is based on regression models fit using stepwise forward variable selection
method to real sales data for a single category of 70 garments introduced by Zara during a single
season. Here, the covariates Xk1 and Xk2 correspond to binary features present (or absent) in each
garment, Xk3 to the number of stores in which the garment was initially introduced, and Xk4 to
the retail price of the garment. The distributions of these covariates are loosely based on observed
data for the category.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 25
We assume two supply options available each period: a fast supplier able to supply with zero lead
time `1 = 0 at cost c1 = c11 = c21 = c31 = c41 = 1, a slow supplier able to supply with lead time `2 = 1
and cost c2 = c21 = c22 = c32 = c42 = 0.5, a holding cost of h = h1 = h2 = h3 = h4 = 0.25 per unit
per period, and a penalty cost of b= b1 = b2 = b3 = b4 = 11 per unit of unmet demand. We assume
salvage value of zero for inventory left over at the end of the horizon.
As previously, we simulate datasets to serve as training and test data for fitting and evaluating the
policies, respectively. Here, for each demand path we also generate a set of static covariates, randomly
and independently drawn according to the distributions specified above. Solving the optimization
problem (EPP) yields an ordering policy conditional on a single set of static covariates. Therefore,
to generate the results in this section we must re-solve the policy for each test demand path. For
this reason, we make use of a smaller test set than in Section 6.1. Specifically, the test set comprises
200 independently generated combinations of covariates and demand paths. As before, we vary the
size of the training sets and the size of the residual trees.
In Table 2, we present the out-of-sample performance of policies generated using training
sets of sizes n = 50,200,1000 and residual trees of increasing sizes (B = B1 = B2 = B3 = B4 =
1,2,3,5,7,10). We compute four versions of the policy in order to better understand the value of
covariate information in our instances: one in which we assume that the true regression coefficients
used to generate the data are known, one in which the form of the true regression model is known
but the coefficients must be estimated from the training data, one in which the static covariates
are unavailable, and one that ignores both static and dynamic (i.e., lagged demand) covariates. As
previously, we present the results as percentages relative to the best-performing policy, which was
computed based on 1000 training paths and a residual tree with 10 branches per node.
As we saw in the previous 2-period example, in Table 2 we see that the policy performances
improve with the amount of training data, with the size of the residual tree, and with better-specified
regression models. We observe that strong performance can be achieved even with a relatively limited
amount of training data; for example, for trees with 10 branches per node, the performance difference
between the n = 50 and n = 1000 policies is just 2.0% for the policy based on known coefficients
and 4.0% for the policy based on estimated coefficients. Convergence of the policy performances is
evident as the underlying residual trees increase in size.
We see that the performance of our approach to be quite good for a realistically small training
set of n=50 products, even for small B. For n= 50 and B = 10, the performance of the estimated
problem is within 4.9% of the best-performance; again supporting the practical validity of the
algorithm. The value of the covariate information is evident; for the same data set size n= 50 and

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
26 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Known coefficients Estimated coefficients Ignoring static covariates Ignoring all covariatesB n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000
1 181.2 178.4 178.9 184.3 183.0 179.8 199.8 190.7 192.8 195.2 189.7 191.42 55.3 52.1 53.0 71.2 58.9 53.8 69.1 66.5 69.8 75.6 75.1 74.33 26.3 21.3 22.6 34.6 25.3 26.7 34.6 34.2 34.0 46.2 46.2 45.35 6.3 6.2 4.9 15.7 8.0 6.2 19.6 17.5 15.6 27.6 26.5 24.57 2.8 3.0 2.6 7.6 5.4 2.1 14.3 14.2 11.6 22.0 22.4 21.510 2.0 0.4 0.0 4.9 1.5 0.9 10.8 9.1 9.0 20.3 18.8 19.0
Table 2: Out-of-sample performance of four versions of the proposed policy for a four-period prob-lem with static covariates. Results are presented as percentage cost increase compared with best-performing policy. The column “Known coefficients” refers to the case when the population valuesof (αt,βt) are known to the decision-maker, the column “Estimated coefficients” refers to the realcase when (αt,βt) are estimated from available data, the column “Ignoring static covariates” refersresults with only static covariates and the column “Ignoring all covariates” refers results that ignoreall covariates. We provide standard errors for these estimates in Appendix C.
coarseness B = 10, the loss in the total cost by ignoring static covariates only and by ignoring
all covariates are 10.8%− 4.9% = 5.9% and 20.3%− 4.9% = 15.4% of the total cost of the best-
performing policy, respectively. Note a two-sample t-test revealed that this difference is statistically
significant at the 1% level
Interestingly, we also observe that the performance of the algorithm heavily depends on the
number of bins used. For instance, for n= 50 with all covariates, using B = 2 yields solutions that
are worse than then B = 10 by 71.2%−4.9% = 66.3% of the total cost of the best-performing policy.
For B = 3, the difference is 34.6%− 4.9% = 29.7% of the total cost of the best-performing policy.
Both differences are statistically significant at the 1% level. This is an important observation for
practice, as the literature on the dynamic procurement problem to date typically consider only 2–3
demand branches per node. Our results indicate that such simplified models may not yield good
solutions in practice.
We also examine the convergence of the policy decisions in Figure 8, which plots average initial
orders to the fast and slow suppliers as a function of the size of the underlying residual tree. Results
reflect the policy based on the correctly specified regression model with estimated coefficients and
training sets of n = 50 demand paths, although we note that using larger training sets makes no
discernible difference in the appearance of this plot. As predicted by our theory, we see the policy
decisions converging as the tree increases in size and granularity.
Finally, Figure 9 shows the average computation time required to compute the policy for a sin-
gle run for the four-period problems considered here. This figure reflects runs of the policy with
estimated coefficients run on a training set of 1000 demand paths. The computation time appears

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 27
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 2 4 6 8 10 12
Initialorder
Branchespernode(B)
Fastsupplierorder Slowsupplierorder
Figure 8: Initial orders under the policy as a function of the number of branches per node (B) inthe residual tree.
0.1
1
10
100
1000
0 2 4 6 8 10 12
Computatio
ntim
e(se
conds)
Branchespernode(B)
Figure 9: Average computation time required to compute the “estimated coefficients” policy basedon a single set of 1000 training paths. Computation time is represented on a logarithmic scale.
to grow approximately exponentially with the number of branches per node, as expected. How-
ever, even the largest trees we’ve considered, which have 10 branches per node for a total tree size
of 11,111 nodes (B4 +B3 +B2 +B1 + 1) permit an average computation time of approximately
200 seconds. As mentioned earlier, we expect this time to be considerably smaller on an industrial
computing platform with optimized code.
7. Conclusion
We have proposed, analyzed, and tested a new method for solving a fairly general dynamic pro-
curement problem using historical data a retailer is likely to have. Our method relies on a demand
model that uses historical demand paths directly without specific distributional assumptions, using
covariate information to account for differences across historical products. We are not aware of the

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
28 Article submitted to Manufacturing & Service Operations Management; manuscript no.
use of covariate information in past literature on the dynamic procurement problem. We believe
the residual tree method is a flexible and practical approach to solving this challenging problem.
The method is both theoretically grounded and also capable of solving problems of meaningful size,
allowing us to generate insights on the value of covariate information and the behavior of good
policies.
One limitation of the residual tree method is, as with the scenario tree method, in the computa-
tional limits when the planning horizon, T , becomes too large. We have demonstrated solutions for
problems with T = 4. While it is natural to make each time period equal to a week in our motivating
context, we believe that a very reasonable approximation approach for longer selling seasons would
be to use a coarser time granularity, as there may be limited incremental benefit to modeling more
ordering opportunities within the selling season. We leave for future work the solving of longer hori-
zon problems, noting that promising ideas beyond coarser time granularity include smart scenario
reduction methods, parallelization, limited lookahead heuristics, resolving on rolling horizons, and
hybrid approaches that combine some of these ideas.
The residual tree method is a general data-driven method for solving multi-stage stochastic pro-
grams, and as such may be valuable for other applications classically approached using stochastic
programming. Examples include financial options pricing, where historical data abounds on instru-
ment prices and there are many available features including economic indicators and market and
industry factors; and energy utility management, where a utility is likely to have a long history of
demand that can be related to the present through demographic, climate, and weather features. As
the typical approach to multi-stage stochastic programming assumes decision-makers have knowl-
edge of the stochastic primitive (e.g., the stochastic models for instrument prices in the case of
options pricing and for electricity demand in the case of energy planning) from which unlimited
data can be generated, the residual tree method closes the gap between the typical model-driven
approach to these multi-stage problems and the data-driven reality.
AcknowledgmentsThe authors thank Yiangos Papanastasiou for input in early stages of this project and Miguel Díaz, Francisco
Babio Fernandez, Juan José Lema, Julio López and Olaia Vázquez from Zara/Inditex for sharing real-world
context and data and for many helpful discussions. The third author thanks the Sarah Graham Kenan
Foundation for support.
ReferencesAgrawal, Narendra, Stephen A Smith, Andy A Tsay. 2002. Multi-vendor sourcing in a retail supply chain.
Production and Operations Management 11(2) 157–182.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 29
Allon, Gad, Jan A Van Mieghem. 2010. Global dual sourcing: Tailored base-surge allocation to near-and
offshore production. Management Science 56(1) 110–124.
Ban, Gah-Yi. 2016. The data-driven (s,S) policy: Why you can have confidence in censored demand data.
Available at SSRN 2654014 URL https://ssrn.com/abstract=2654014.
Ban, Gah-Yi, N. Bora Keskin. 2016. Personalized dynamic pricing. Working Paper .
Ban, Gah-Yi, Cynthia Rudin. 2014. The big data newsvendor: Practical insights from machine learning.
Available at SSRN 2559116 .
Bastani, Hamsa, Mohsen Bayati. 2015. Online decision-making with high-dimensional covariates. Available
at SSRN 2661896 .
Belloni, Alexandre, Victor Chernozhukov. 2009. Least squares after model selection in high-dimensional
sparse models .
Bertsimas, Dimitris, Nathan Kallus. 2014. From predictive to prescriptive analytics. arXiv preprint
arXiv:1402.5481 .
Bertsimas, Dimitris, Robert Weismantel. 2005. Optimization Over Integers. Dynamic Ideas, Belmont,
Massachusetts.
Burnetas, Apostolos, Stephen Gilbert. 2001. Future capacity procurements under unknown demand and
increasing costs. Management Science 47(7) 979–992.
Burnetas, Apostolos N, Craig E Smith. 2000. Adaptive ordering and pricing for perishable products. Oper-
ations Research 48(3) 436–443.
Caro, Felipe, Jérémie Gallien. 2012. Clearance pricing optimization for a fast-fashion retailer. Operations
Research 60(6) 1404–1422.
Casey, Michael S, Suvrajeet Sen. 2005. The scenario generation algorithm for multistage stochastic linear
programming. Mathematics of Operations Research 30(3) 615–631.
Cohen, Maxime C, Ilan Lobel, Renato Paes Leme. 2016. Feature-based dynamic pricing. Available at SSRN
.
Dupačová, Jitka, Giorgio Consigli, Stein W Wallace. 2000. Scenarios for multistage stochastic programs.
Annals of operations research 100(1-4) 25–53.
Dupačová, Jitka, Nicole Gröwe-Kuska, Werner Römisch. 2003. Scenario reduction in stochastic programming.
Mathematical programming 95(3, Ser. A) 493–511.
Eppen, Gary D, Ananth V Iyer. 1997. Improved fashion buying with Bayesian updates. Operations research
45(6) 805–819.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
30 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Escudero, Laureano F., Pasumarti V. Kamesam, Alan J. King, Roger J-B. Wets. 1993. Production planning
via scenario modelling. Annals of Operations Research 43 311–335.
Ferreira, Kris Johnson, Bin Hong Alex Lee, David Simchi-Levi. 2015. Analytics for an online retailer: Demand
forecasting and price optimization. Manufacturing & Service Operations Management 18(1) 69–88.
Fisher, Marshall, Kumar Rajaram, Ananth Raman. 2001. Optimizing inventory replenishment of retail
fashion products. Manufacturing & Service Operations Management 3(3) 230–241.
Fisher, Marshall, Ananth Raman. 1996. Reducing the cost of demand uncertainty through accurate response
to early sales. Operations research 44(1) 87–99.
Friedman, Jerome, Trevor Hastie, Robert Tibshirani. 2009. The elements of statistical learning, 2nd ed..
Springer series in statistics Springer, Berlin.
Gallien, Jérémie, Adam J Mersereau, Andres Garro, Alberte Dapena Mora, Martin Novoa Vidal. 2015. Initial
shipment decisions for new products at Zara. Operations Research 63(2) 269–286.
Godfrey, Gregory A, Warren B Powell. 2001. An adaptive, distribution-free algorithm for the newsvendor
problem with censored demands, with applications to inventory and distribution. Management Science
47(8) 1101–1112.
Graves, Stephen C, Harlan C Meal, Sriram Dasu, Yuping Qui. 1986. Two-stage production planning in a
dynamic environment. Multi-stage production planning and inventory control . Springer, 9–43.
Heath, David C, Peter L Jackson. 1994. Modeling the evolution of demand forecasts ith application to safety
stock analysis in production/distribution systems. IIE transactions 26(3) 17–30.
Heitsch, Holger, Werner Römisch. 2003. Scenario reduction algorithms in stochastic programming. Compu-
tational optimization and applications 24(2-3) 187–206.
Higle, Julia H., Karl G. Kempf. 2011. Production planning under supply and demand uncertainty: A stochas-
tic programming approach. G. Infanger, ed., Stochastic Programming , chap. 14. International Series in
Operations Research and Management Science, Springer Science+Business Media, 297–315.
Huh, Woonghee Tim, Paat Rusmevichientong. 2009. A nonparametric asymptotic analysis of inventory
planning with censored demand. Mathematics of Operations Research 34(1) 103–123.
Iida, Tetsuo, Paul H Zipkin. 2006. Approximate solutions of a dynamic forecast-inventory model. Manufac-
turing & Service Operations Management 8(4) 407–425.
Ioffe, Alexander D. 1977. On lower semicontinuity of integral functionals. i. SIAM Journal on Control and
Optimization 15(4) 521–538.
Jones, Philip C., Timothy J. Lowe, Rodney D. Traub, Greg Kegler. 2001. Matching supply and demand:
The value of a second chance in producing hybrid seed corn. Manufacturing & Service Operations
Management 3(2) 122–137.

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
Article submitted to Manufacturing & Service Operations Management; manuscript no. 31
Kaminsky, Philip, Jayashankar M Swaminathan. 2001. Utilizing forecast band refinement for capacitated
production planning. Manufacturing & Service Operations Management 3(1) 68–81.
Kaminsky, Philip, Jayashankar M Swaminathan. 2004. Effective heuristics for capacitated production plan-
ning with multiperiod production and demand with forecast band refinement. Manufacturing & Service
Operations Management 6(2) 184–194.
Kunnumkal, Sumit, Huseyin Topaloglu. 2008. Using stochastic approximation methods to compute optimal
base-stock levels in inventory control problems. Operations Research 56(3) 646–664.
Lau, Hon-Shiang, Amy Hing-Ling Lau. 1996. The newsstand problem: A capacitated multiple-product
single-period inventory problem. European Journal of Operational Research 94(1) 29–42.
Levi, Retsef, Robin O Roundy, David B Shmoys. 2007. Provably near-optimal sampling-based policies for
stochastic inventory control models. Mathematics of Operations Research 32(4) 821–839.
Li, Jian, Suresh Chand, Maqbool Dada, Shailendra Mehta. 2009. Managing inventory over a short season:
models with two procurement opportunities. Manufacturing & Service Operations Management 11(1)
174–184.
Lu, Xiangwen, Jing-Sheng Song, Amelia Regan. 2006. Inventory planning with forecast updates: Approximate
solutions and cost error bounds. Operations research 54(6) 1079–1097.
Martec, International. 2016. State of the retail supply chain 2016: Europe and north america. Available
Online. http: // hub. relexsolutions. com/ state-of-retail-supply-chain-2016 .
Milner, Joseph M, Panos Kouvelis. 2002. On the complementary value of accurate demand information and
production and supplier flexibility. Manufacturing & Service Operations Management 4(2) 99–113.
Milner, Joseph M, Panos Kouvelis. 2005. Order quantity and timing flexibility in supply chains: The role of
demand characteristics. Management Science 51(6) 970–985.
Patel, Jalpa. 2012. Optimization-based decision support system for retail sourcing. Master’s thesis, Mas-
sachusetts Institute of Technology.
Peng, Chen, Feryal Erhun, Erik F. Hertzler, Karl G. Kempf. 2012. Capacity planning in the semiconductor
industry: Dual-mode procurement with options. Manufacturing & Service Operations Management
14(2) 170–185.
Pennanen, Teemu. 2005. Epi-convergent discretizations of multistage stochastic programs. Mathematics of
Operations Research 30(1) 245–256.
Pennanen, Teemu. 2009. Epi-convergent discretizations of multistage stochastic programs via integration
quadratures. Mathematical Programming 116(1-2) 461–479.
Pennanen, Teemu, Matti Koivu. 2002. Integration quadratures in discretization of stochastic programs.
Stochastic Programming E-Print Series .

Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
32 Article submitted to Manufacturing & Service Operations Management; manuscript no.
Pflug, Georg, Ronald Hochreiter. 2003. Scenario generation for stochastic multi-stage decision processes as
facility location problems. Tech. rep., Technical report, Department of Statistics and Decision Support
Systems, University of Vienna.
Powell, Warren, Andrzej Ruszczyński, Huseyin Topaloglu. 2004. Learning algorithms for separable approx-
imations of discrete stochastic optimization problems. Mathematics of Operations Research 29(4)
814–836.
Qiang, Sheng, Mohsen Bayati. 2016. Dynamic pricing with demand covariates. Available at SSRN 2765257
.
Serel, D. A. 2016. Intelligent procurement systems to support fast fashion supply chains in the apparel
industry. Tsan-Ming Choi, ed., Information Systems for the Fashion and Apparel Industry , Wood-
head Publishing Series in Textiles, vol. 179, chap. 7. Elsevier, Amsterdam, The Netherlands, 121–144.
Http://dx.doi.org/10.1016/B978-0-08-100571-2.00007-5.
Smith, A., N. Agrawal, A. Tsay. 2002. Sam: A decision support system for retail supply-chain planning
for private-label merchandise with multiple vendors. Joseph Geunes, Panos M. Pardalos, Edwin H.
Romeijn, eds., Supply Chain Management: Models, Applications, and Research Directions. Kluwer Aca-
demic Publishers, Dordrecht, The Netherlands.
Wang, Tong, Atalay Atasu, Mümin Kurtuluş. 2012. A multiordering newsvendor model with dynamic forecast
evolution. Manufacturing & Service Operations Management 14(3) 472–484.
Zipkin, Paul. 2008. On the structure of lost-sales inventory models. Operations research 56(4) 937–944.

e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method ec1
Electronic Companion to “Dynamic Procurement of New Products
with Covariate Information: the Residual Tree Method"
Appendix A: Proof of Proposition 1
We proceed by first proving (A) that a feasible solution to problem (PP) is feasible in problem (PP2). Then
we prove (B) that an optimal solution to problem (PP2) is feasible in (PP). Because the objective functions
of the two problems are identical, it follows that the optimal solutions to the two problems and their objective
values must coincide. We show both reductions pathwise, for a fixed demand path d0 = d01, . . . , d0T andfixed order decisions q = q1j , . . . , qTj. As a shorthand, we let Qt =
∑j∈S
∑1≤τ≤t−1:τ=t−`j
qτj indicate the total
shipment received in period t given the demand path.
To prove claim (A), let the pair (I∗, l∗), where I∗ = I∗1 , . . . , I∗T and l∗ = l∗1, . . . , l∗T, denote a feasible
solution to (PP). Fix t and consider the sign of I∗t−1 +Qt−d0t. If I∗t−1 +Qt−d0t ≥ 0 then I∗t = I∗t−1 +Qt−d0tby constraint (PPb) (which holds almost surely) and l∗t = 0 by constraint (PPc). Therefore constraint (PP2b)
holds on the given demand path for t. Furthermore, I∗t ≥ 0 so I∗t ∈ R+ and l∗t ≥ 0 so l∗t ∈ R+. Similarly, if
I∗t−1 +Qt−d0t < 0 then I∗t = 0 by constraint (PPb) and l∗t = d0t−I∗t−1−Qt by constraint (PPc) so constraint
(PP2b) holds and we have I∗t ≥ 0 and l∗t ≥ 0. Since this holds for all d0 and q, we have (A).
To prove claim (B), now let the pair (I∗, l∗), where I∗ = I∗1 , . . . , I∗T and l∗ = l∗1, . . . , l∗T, denote an optimal
solution to (PP2). We prove (B) via the following lemma.
Lemma EC.1. Let (I∗, l∗) be an optimal solution to problem (PP2) given the assumed demand path. Then
l∗t > 0 implies I∗t = 0 for all t∈ 1, . . . , T.
(Proof of Lemma EC.1.) Suppose l∗τ ≥ ε and I∗τ ≥ ε for some τ ∈ 1, . . . , T and some ε > 0. We contradict
the optimality of this solution by constructing an alternative solution (I, l) with strictly lower cost. Our
construction of this alternative solution depends on τ .
If τ = T , then let
lt = l∗t , ∀t∈ 1, . . . , T − 1
lT = l∗T − ε
It = I∗t , ∀t∈ 1, . . . , T − 1
IT = I∗T − ε.
It is straightforward to show that (I, l) is feasible in (PP2). Furthermore, the cost of solution (I∗, l∗) less
the cost of (I, l) is strictly positive:
p(l∗T − lT
)− pm
(I∗T − IT
)= (p− pm)ε > 0.

ec2 e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
If τ < T , then let
lt = l∗t , ∀t∈ 1, . . . , T\τ, τ + 1
lτ = l∗τ − ε
lτ+1 = l∗τ+1 + ε
It = I∗t , ∀t∈ 1, . . . , T\τ
Iτ = I∗τ − ε.
Again, (I, l) is feasible in (PP2). The cost of solution (I∗, l∗) less the cost of (I, l) is strictly positive:
p(l∗τ − lτ
)+ p
(l∗τ+1− lτ+1
)+h
(I∗τ − Iτ
)= pε− pε+hε= hε > 0.
Since this holds for all d0 and q, we have (B).
Returning to claim (B), we fix t and consider two cases. First, suppose l∗t = 0. Then constraint (PP2b)
implies I∗t = I∗t−1 − d0t +Qt and the non-negativity of I∗t implies that I∗t = I∗t−1 − d0t +Qt ≥ 0. Therefore
(PPb) holds. Furthermore, I∗t−1− d0t +Qt ≥ 0 implies that(d0t− I∗t−1−Qt
)+= 0 so (PPc) holds.
Second, suppose l∗t > 0. Lemma EC.1 then implies I∗t = 0, and constraint (PP2b) implies l∗t = d0t− I∗t−1−
Qt > 0 so (PPb) holds. Furthermore, d0t− I∗t−1−Qt > 0 implies that(I∗t−1 +Qt− d0t
)+= 0 so (PPc) holds.

e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method ec3
Appendix B: Proofs of results in Section 5.
The proofs of Theorem 1 and Corollary 1 rely on the following three lemmas.
Lemma EC.2. The function f : RT (S+2)×Ξ0→ (−∞,∞] given by
f(q, I, l;D0,[1,T ]) =
T−1∑t=1
htIt +
T∑t=1
btlt +
T∑t=1
S∑j=1
ctjqtj − vIT , (EC.1)
where q = [q1j , . . . , qTj ]1≤j≤S, I = [I1, . . . , IT ], and l = [l1, . . . , lT ] may depend on the random vector D0,[1,T ] =
[D01, . . . ,D0T ], is lower semi-continuous in the first argument and has the lower compactness property of
Ioffe (1977).
Lemma EC.3. The following conditions hold for the stochastic optimization problem (PP): for every fea-
sible z ∈ RT (S+2), there is a uniformly bounded sequence yµ → z of non-anticipative, P0-a.s. continuous
functions yµ : Ξ0→RT (S+2) such that
lim supn→∞
EPnf(yµ(D0,[1,T ]);D0,[1,T ])≤EP0
f(yµ(D0,[1,T ]);D0,[1,T ]), ∀ µ∈Z+ and (a)
lim supµ→∞
EP0f(yµ(D0,[1,T ]);D0,[1,T ])≤EP0
f(z(D0,[1,T ]);D0,[1,T ]). (b)
Lemma EC.4. The stochastic demand model (1) is a time series model with uniform innovations, i.e. for
each t= 1, . . . , T , the demand is of the form
D0t|X0t = gt(D00,D01, . . . ,D0,t−1, ωt), (EC.2)
where D00 is a (non-random) constant, ω1, . . . , ωT are mutually independent random variables, with ωt uni-
formly distributed in the unit interval [0,1], and gt : Ξ01× . . .×Ξ0,t−1× [0,1]→Ξ0t.
(Proof of Lemma EC.2.) Firstly, f(· ;D0,[1,T ]) is continuous for every D0,[1,T ] ∈ Ξ0 so it is lower semi-
continuous. Secondly, the function f : RT (S+2) ×Ξ0→ (−∞,∞] satisfies the lower compactness property of
Ioffe (1977) if there exists a non-decreasing real-valued function g on [0,+∞) and a real number b such that
f(z;D0,[1,T ])≥−g(||z||∞)− b, ∀ z∈RT (S+2), ∀ D0,[1,T ] ∈Ξ0.
Now
f(q, I, l;D0,[1,T ])≥−T (c∞S||q||∞+ (h∞ ∨ v)||I||∞+ b∞||l||∞), ∀ (q, I, l)∈RT (S+2), ∀ D0,[1,T ] ∈Ξ0,
where c∞ = maxc1j , . . . , cTj1≤j≤S, h∞ = maxh1, . . . , hT−1 and b∞ = maxb1, . . . , bT, thus f(· ; ·) satisfies
the lower compactness property of Ioffe (1977).

ec4 e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
(Proof of Lemma EC.3.) The condition (a) holds because by (5), Pn converges to the sample average
measure as n goes to infinity, then by the Weak Law of Large Numbers (WLLN) on the sample average
measure.
For condition (b), let z = (q, I, l)∈RT (S+2) be a feasible solution to (PP). Consider, for µ∈Z+,
yµ = z− 10
µ,
where 10 is a vector with T (S+ 2) ones and a zero at the end (corresponding to the location of IT in the z
vector). Then
||yµ||∞ ≤ ||z||∞+ 1,
hence yµ is uniformly bounded for every z.
We also have, by elementary algebra,
f(yµ(D0,[1,T ]);D0,[1,T ]) = f(z(D0,[1,T ]);D0,[1,T ])−C
µ,
where C is the positive constant
C =
T−1∑t=1
ht +
T∑t=1
bt +
T∑t=1
S∑j=1
ctj ,
which is clearly dominated by f(z;D0,[1,T ]) for all µ∈Z+. Thus we have
EP f(yµ(D0,[1,T ]);D0,[1,T ])≤EP f(z(D0,[1,T ]);D0,[1,T ])
for all µ∈Z+, and (b) follows.
(Proof of Lemma EC.4.) Define the function
gt(D00, . . . ,D0,t−1, ωt) := αt +β>t x0t +F−1εt(ωt), (EC.3)
where some elements of x0t may depend on past demands [D00, . . . ,D0,t−1], and F−1εtis the inverse cdf of the
random error term εt in the demand model (2). We immediately have
D0t|(X0t = x0t) = gt(D00, . . . ,D0T , ωt), (EC.4)
which satisfies the definition of a time series model with uniform innovations.
Remark. Note D0,[1,T ] is uniquely determined by ωT = (ω1, . . . , ωT ) according to (EC.4).
We are now ready to prove the main results.
(Proof of Theorem 1). The proof of Theorem 1 relies on the following two conditions:

e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method ec5
• Condition 1 : First, some definitions. Define the Lebesgue space Z(P0) :=L∞(Ξ0,F0,P0;RT (S+2)), and
the set of (F0t)Tt=1-adapted elements of Z(P0)
N (P0) := z∈Z(P0) | z contains an (F0t)Tt=1 -adapted function.
In other words, N (P0) is the set of feasible solutions (each of which are, technically speaking, equivalence
classes, as solutions that differ on sets of measure zero have equivalent objective values) of (PP).
Now consider the discretized demand space Ξn. Let Ξbt(n) denote the b-th bin out of Bt(n) bins at time t.
Define, for each n∈Z+ and t= 1, . . . , T , the functions sn : Ξ0→Ξ0 and ψt,n : Ξt→R given by
sn(d0,[1,T ]) := d0,[1,T ], and
ψt,n(d0,t) :=pbt(n)
P(Ξbt(n))if d0t ∈ Ξbt(n).
Let Nn(P) be the set of (sn)−1(F0t)-adapted elements of X(P0). Then Condition 1 is that the sequence
Pn∞n=1 of discretized measures is such that Nn(P)⊂N (P0) for all n∈Z+ and
sn(D0,[1,T ])P→ D0,[1,T ], and (EC.5)
maxb∈Bt(n)
∣∣∣∣ pbt(n)
P (Ξbt(n))− 1
∣∣∣∣→ 0, ∀ 1≤ t≤ T, (EC.6)
as n tends to infinity.
• Condition 2 :
(a) The function f : RT (S+2)×Ξ0→ (−∞,∞] given by (EC.1) is lower semi-continuous in the first argument
and has the lower compactness property of Ioffe (1977).
(b) For every feasible z∈RT (S+2), there is a uniformly bounded sequence yµ→ z of non-anticipative, P -a.s.
continuous functions yµ : Ξ0→RT (S+2) such that
lim supn→∞
EPnf(yµ(D0,[1,T ]);D0,[1,T ])≤EP f(yµ(D0,[1,T ]);D0,[1,T ]) ∀ µ∈Z+
lim supµ→∞
EP f(yµ(D0,[1,T ]);D0,[1,T ])≤EP f(z(D0,[1,T ]);D0,[1,T ]),
where f(·, ·) is the function defined in (EC.1).
By Corollary 3.1. of Pennanen (2005), epi-convergence follows if our problem satisfies Conditions 1 and 2.
In words, Condition 1 states necessary conditions on the data-driven estimate of the stochastic program
(PP). Specifically, (EC.5) is a statement regarding the asymptotic consistency of the data-driven estimate of
the demand process and (EC.6) is a statement regarding the consistency of the residual histogram tree. In
a separate paper, Pennanen (2009) (Theorem 2) shows that if the underlying stochasticity of a multi-stage
stochastic program is a time series model with uniform innovations as is the case with our problem by Lemma
EC.4, then the sequence (Pn)∞n=1 satisfies Condition 1 if the following conditions hold for all t= 1, . . . , T :

ec6 e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method
C1. gt(D00, . . . ,D0,t−1, ·) is a bijection for every D0,[1,T ] ∈Ξ0, where gt(·) is the function defined in (EC.2)
of Lemma EC.4,
C2. gt(·) and the function (D01, . . . ,D0t) 7→ gt(D00, . . . ,D0,t−1, ·)−1(D0t) are Borel-measurable,
C3. gt(·) is P01× . . .×P0,t−1×Ut-almost-surely continuous, and
C4. Ut(n)→Ut weakly, as n→∞,
Below we show the conditions C1–C4 are satisfied by our problem.
PC1. By the model assumption, εt has an inverse cdf, so gt(D00, . . . ,D0T , ·) is a bijection for every D0,[1,T ] ∈
Ξ0.
PC2. The Borel-measurability of gt(·) and of the function (D00, . . . ,D0,t−1) 7→ gt(D00, . . . ,D0,t−1, ·)−1(D0t)
follows from the measurability of ωt and εt.
PC3. It is clear that the function gt(·) is continuous in all its arguments.
PC4. By Lemma 2 of Pennanen (2009), this is equivalent to (EC.5) and (EC.6) being satisfied. (EC.5) is
satisfied by the classical result on the consistency of the least-squares regression model, and (EC.6)
is satisfied by the asymptotic equivalence of the histogram distribution to the empirical distribution
(spelled out in (5) of Step 2. of Residual Tree Algorithm 1), the latter of which is uniformly consistent
via the Glivenko-Cantelli Theorem.
Condition 2 concerns the structure of the original problem itself, and we have shown that our problem
satisfies these conditions by Lemmas EC.2 and EC.3. Thus our problem satisfies the assumptions of Corollary
3.1. of Pennanen (2005) and the conclusions follow.
Proof of Corollary 1. All we need to check is that the map sLasson : Ξ0 7→Ξ0 defined by
sLasson (d0,[1,T ]) := dLasso0,[1,T ]
converges to the identity map as n→∞, mt = mt(n)→∞ and st = st(n)→∞. This is achieved by con-
struction since (6) is a consistent estimate of the true sparse demand model.
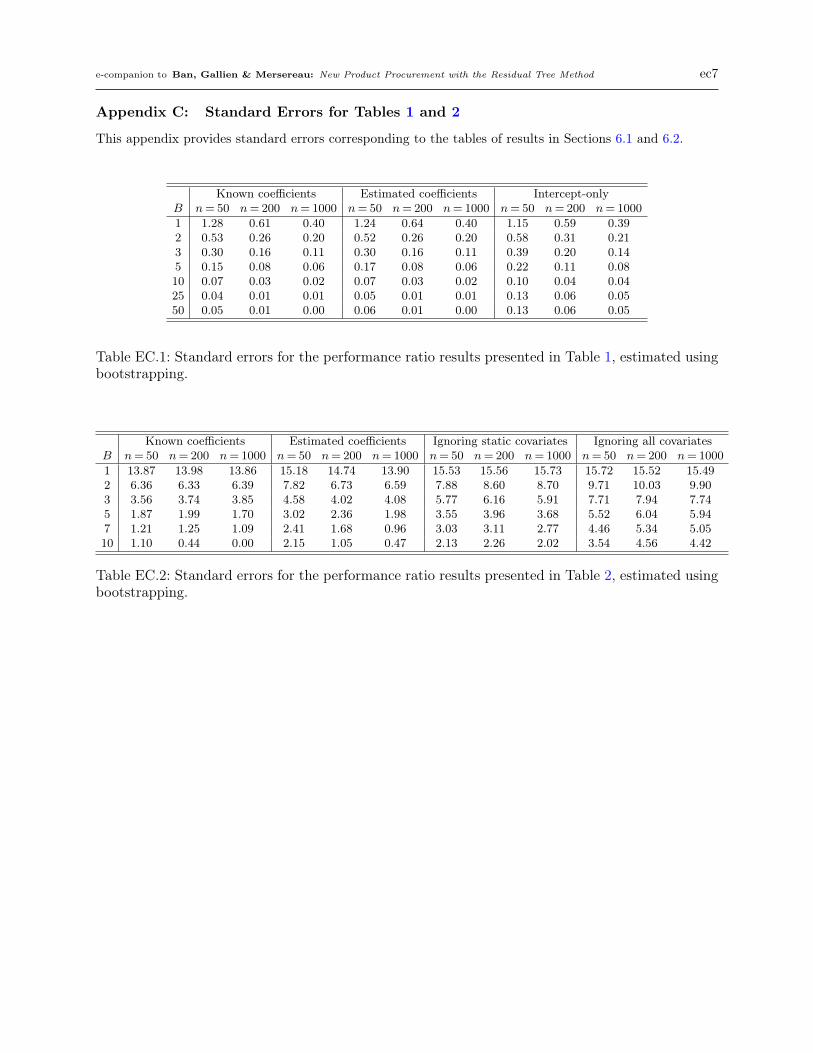
e-companion to Ban, Gallien & Mersereau: New Product Procurement with the Residual Tree Method ec7
Appendix C: Standard Errors for Tables 1 and 2
This appendix provides standard errors corresponding to the tables of results in Sections 6.1 and 6.2.
Known coefficients Estimated coefficients Intercept-onlyB n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000
1 1.28 0.61 0.40 1.24 0.64 0.40 1.15 0.59 0.392 0.53 0.26 0.20 0.52 0.26 0.20 0.58 0.31 0.213 0.30 0.16 0.11 0.30 0.16 0.11 0.39 0.20 0.145 0.15 0.08 0.06 0.17 0.08 0.06 0.22 0.11 0.0810 0.07 0.03 0.02 0.07 0.03 0.02 0.10 0.04 0.0425 0.04 0.01 0.01 0.05 0.01 0.01 0.13 0.06 0.0550 0.05 0.01 0.00 0.06 0.01 0.00 0.13 0.06 0.05
Table EC.1: Standard errors for the performance ratio results presented in Table 1, estimated usingbootstrapping.
Known coefficients Estimated coefficients Ignoring static covariates Ignoring all covariatesB n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000 n= 50 n= 200 n= 1000
1 13.87 13.98 13.86 15.18 14.74 13.90 15.53 15.56 15.73 15.72 15.52 15.492 6.36 6.33 6.39 7.82 6.73 6.59 7.88 8.60 8.70 9.71 10.03 9.903 3.56 3.74 3.85 4.58 4.02 4.08 5.77 6.16 5.91 7.71 7.94 7.745 1.87 1.99 1.70 3.02 2.36 1.98 3.55 3.96 3.68 5.52 6.04 5.947 1.21 1.25 1.09 2.41 1.68 0.96 3.03 3.11 2.77 4.46 5.34 5.0510 1.10 0.44 0.00 2.15 1.05 0.47 2.13 2.26 2.02 3.54 4.56 4.42
Table EC.2: Standard errors for the performance ratio results presented in Table 2, estimated usingbootstrapping.