dwh ws0809 kapitel3 - universität ulm · auch mehr als einen artikel umfassen ©stefanie...
TRANSCRIPT

1
1©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Vorlesungs-Übersicht
1) Einführung und Definitionen2) Architektur eines Data-Warehouse-Systems
3) Das multidimensionale Datenmodell
4) ETL: Extraktion, Transformation, Laden
5) Anfrageverarbeitung und -optimierung
6) Indexstrukturen für das multidimensionale Datenmodell7) Materialisierte Views
8) Metadaten
9) OLAP, Data Mining, Process Mining
10) Zusammenfassung und Ausblick
Kapitel 3
- Das multidimensionale Datenmodell -
Vorlesung Data-Warehouse-Systeme im Sommersemester 2006

2
3©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Kapitel 3: Überblick
3.1 Data-Warehouse-Designprozess3.2 Konzeptuelle Datenmodellierung
3.3 Formalisierung und Analyseoperationen
3.4 Umsetzung des multidimensionalen Datenmodells
3.5 Zusammenfassung
4©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.1 Motivation
Zentrale Frage: Wie modellieren wir die Daten in geeigneter Weise, d.h. für die Anwendung im Data-Warehouse-System?Im Fokus: Modellierung sollte Analysen ermöglichen / unterstützen!
Anfragen beziehen sich meist auf mehrere Aspekte (z.B. Zeit, Ort, Produkt)
Forderung nach mehrdimensionaler Darstellung der Daten (z.B. als Würfel) 1. ASPEKT
Analog zu klassischen Datenbank-Systemen:Nicht sofort Relationen / Tabellen anlegen (also z.B. in SQL), sondernErst semantischer / konzeptueller Entwurf (z.B. Entity-Relationship)
Siehe auch Datenbank- bzw. Data-Warehouse-Designprozess2. ASPEKT

3
5©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.1 Motivation (1. ASPEKT)
Datenmodell sollte Analyse unterstützenWas soll analysiert werden? Kennzahlen (Erlöse, Gewinne, Verluste, etc.) meist aus betriebswirtschaftlicher SichtWie soll analysiert werden? Kennzahlen sollen aus unterschiedlichen Perspektiven (zeitlich, regional, produktbezogen) betrachtet werden können DimensionenDimensionen sollen in verschiedener Granularität betrachtet werden können (z.B. Zeit als Jahr, Quartal, Monat) Hierarchien oder Konsolidierungsebenen
Verfügbare InformationenQualifizierend Repräsentiert durch „Kategorienattribute“
Daten zur Nutzung als Navigationsraster („Drill-Pfade“)Modelliert als Begriffshierarchien im Rahmen von Dimensionen
QuantifizierendBilden Gegenstand der Auswertung („Summenattribute“)Zellen eines Würfels, mit Dimensionen als Kanten
3.1 Motivation (2. ASPEKT)
Sammeln von Information
Semantische Datenmodelleriung
Logische Datenmodelleriung
Datenbank-Installation
Konzeptuelles Schema
Analyse der Bedeutung
Rohmodellierung Präzise Modellierung
Zeit
• Interviews
• Analyse der Substantive
• Brainstorming
• Analyse von Dokumenten
• …
• Entity-Relationship-Modellierung (ERM)
• UML
• …
• hierarchisch
• Netzwerk
• relational
• objekt-orientiert
•…
•XML
• DB2
• ORACLE
• …
DBMS unabhängig DBMS abhängig
Konzeptuelles Schemadesign
Logisches Schemadesign
Physisches Schemadesign
Prozessmodell:
vgl. [HLV00]

4
7©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.1 Data-Warehouse-Designprozess (2. ASPEKT)
Analyse und Spezifikation der Anforderungen
Konzeptuelles Design
Logisches Design
Physisches Design
Operationales Datenbank-
schema
Zeit
• Interviews
• Analyse der Substantive
• Brainstorming
• Analyse von Dokumenten
• …
• ME/R
• mUML
• graphbasiert
• …
• multidimensional
• relational
• objekt-relational
•…
• DB2
• ORACLE
• MS Server
• Essbase
• MS Analysis Services
• …
Semiformales Geschäfts-
konzept
Formales konzeptuelles
Schema
Operationales Datenbank-
schema
Physisches Datenbank-
schema
vgl. [HLV00]
8©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.1 relationale vs. multidimensionale Schemaarchitektur (2. ASPEKT)
Konzeptuelles Schema
Entity-Relationship
Logisches Schema
Relationen
Physisches Schema
Speicherstrukturen
Konzeptuelles Schema
ME/R, mUML
Logisches Schema
Dimensionen, Würfel
Physisches Schema
Relationen (Faktentabelle, …),
MD-Strukturen
relational multidimensional

5
9©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Kapitel 3: Überblick
3.1 Data-Warehouse-Designprozess3.2 Konzeptuelle Datenmodellierung
3.3 Formalisierung und Analyseoperationen
3.4 Umsetzung des multidimensionalen Datenmodells
3.5 Zusammenfassung
10©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 … was wir kennen ….
Unterscheidung Klassifikationsstufen – (beschreibende) Attribute –Kenngrößen nicht direkt ersichtlich
z.B. Klassifikationsstufe Tag als Attribut modelliert, Klassifikationsstufe Artikel als Entität
Welche Beziehungen sind Klassifikationsbeziehungen nicht direkt ersichtlich
z.B. als 1:n Beziehung, aber auch als Attribut (z.B. Bezirk bei Stadt)
Packungstyp
Produktgruppe
Artikel Filiale
Stadtist verpackt
von
gehört zu
wurde verkauft
liegt in
Artikel-Nr.
Datum.
Bezirk
Name
Auszug eines E/R-Modells für das Kaufhausbeispiel
1
n
1
n
n m

6
11©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 … was wir brauchen: Dimensionen und Hierarchien
Dimension:Mögliche Perspektive, aus der Kennzahlen betrachtet werden könnenendliche Menge von n (n ≥ 2) Dimensionselementen (Hierarchieobjekten)Dimensionselemente stehen in Beziehung zueinander (z.B. Quartal ist „Unterteilung“ von Jahr)dienen der orthogonalen Strukturierung des DatenraumsBeispiele: Produkt, Geographie, Zeit
Dimensionselemente:Knoten einer KlassifikationshierarchieKlassifikationsstufe beschreibt VerdichtungsgradDarstellung von Dimensionen über Klassifikationsschema (Schema von Klassifikationshierarchien)
Formen:einfache Hierarchienparallele Hierarchien
12©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 einfache Hierarchien
Oberster Knoten: Top beschreibt die stärkste Verdichtung (also auf einen einzelnen Wert der Dimension)Jede höhere Hierarchieebene enthält jeweils die aggregierten Werte der niedrigeren Hierarchiestufe
Top
Produktkategorie
Produktfamilie
Produktgruppe
Artikel
Top
Land
Stadt
Filiale

7
13©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 parallele Hierarchien
Gruppierung innerhalb einer Dimension muss nicht immer eindeutigsein mehrere Gruppierungen können parallel existierenKeine hierarchische Beziehung in den parallelen Zweigen
Typisches Beispiel ist die Zeit-Dimension:
Top
Jahr
Quartal
Monat
Tag
Woche
14©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 Konzeptuelle Datenmodellierung
Transformation of the semi-formal business requirements specification into a conceptual multidimensional schema.
konzeptuelle DatenmodellierungModellierung relevanter Zusammenhänge des AnwendungsgebietesER oder UML Diagrammen fehlt durch ihren universellen Modellierungsanspruch eine DW-spezifische Semantik.
daher erfolgt die Modellierung durch ein MD-Designnotation. z.B. mE/R, mUMLevolutionär: Erweiterung, Spezialisierung bestehender Formalismen vs.
revolutionär: neue, maßgeschneiderte MethodikDiese unterstützen die Modellierung von Datenstrukturen wie Dimensionen, Kenngrößen, HierarchienEntwurf einer für den Anwender bedarfsgerechten Auswertungsstruktur

8
15©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 mE/R-Modell
multidimensional Entity/RelationshipErweiterung des klassischen ER-Modells (evolutionär)
Entity-Menge „Dimension Level“ (Klassifikationsstufe)keine explizite Modellierung von Dimensionen
n-äre Beziehungsmenge „Fact“Kennzahlen als Attribute der Beziehung
Binäre Beziehungsmenge „Classification“ bzw. „Roll-Up“ (Verbindung von Klassifikationsstufen)
definiert gerichteten, nicht-zyklischen Graphen
mE/R-Modell: Notation
FAKT
Kenngröße
Klassifikationsstufe Klassifkationsbeziehung
16©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 mE/R-Modell: Beispiel
Faktbeziehung: Verkaufsanalyse
Kenngrößen: Verkaufszahlen und Umsatz
Dimensionen: Produkt, Geographie, Zeit
Dimensionen ergeben sich aus den Basisklassifikationsstufen (z.B. Tag)
Alternativpfad in der Zeitdimension
Verkauf
Anzahl
Umsatz
Artikel
Filiale
Tag
Gruppe
Stadt
Monat
Woche
Familie
Bezirk
Quartal
Branche
Region
Jahr
9
17©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
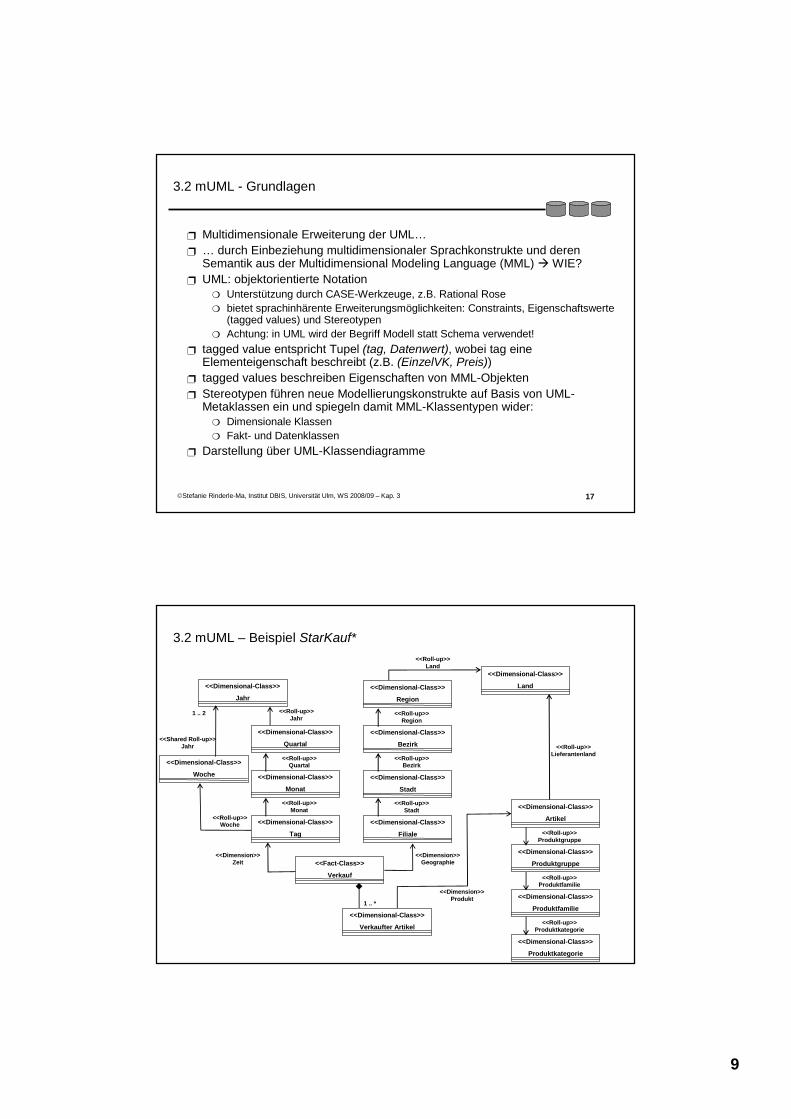
3.2 mUML - Grundlagen
Multidimensionale Erweiterung der UML…… durch Einbeziehung multidimensionaler Sprachkonstrukte und deren Semantik aus der Multidimensional Modeling Language (MML) WIE?UML: objektorientierte Notation
Unterstützung durch CASE-Werkzeuge, z.B. Rational Rosebietet sprachinhärente Erweiterungsmöglichkeiten: Constraints, Eigenschaftswerte (tagged values) und StereotypenAchtung: in UML wird der Begriff Modell statt Schema verwendet!
tagged value entspricht Tupel (tag, Datenwert), wobei tag eine Elementeigenschaft beschreibt (z.B. (EinzelVK, Preis))tagged values beschreiben Eigenschaften von MML-Objekten Stereotypen führen neue Modellierungskonstrukte auf Basis von UML-Metaklassen ein und spiegeln damit MML-Klassentypen wider:
Dimensionale KlassenFakt- und Datenklassen
Darstellung über UML-Klassendiagramme
3.2 mUML – Beispiel StarKauf*
<<Dimensional-Class>>
Produktgruppe
<<Dimensional-Class>>
Produktfamilie
<<Dimensional-Class>>
Produktkategorie
<<Dimensional-Class>>
Artikel
<<Roll-up>> Produktgruppe
<<Roll-up>> Produktfamilie
<<Roll-up>> Produktkategorie
<<Dimensional-Class>>
Bezirk
<<Dimensional-Class>>
Stadt
<<Dimensional-Class>>
Filiale
<<Dimensional-Class>>
Region
<<Roll-up>> Region
<<Roll-up>> Bezirk
<<Roll-up>> Stadt
<<Dimensional-Class>>
Land
<<Fact-Class>>
Verkauf
<<Dimensional-Class>>
Verkaufter Artikel
<<Dimensional-Class>>
Monat
<<Dimensional-Class>>
Tag
<<Dimensional-Class>>
Quartal
<<Roll-up>> Quartal
<<Roll-up>> Monat
<<Dimensional-Class>>
Jahr
<<Dimensional-Class>>
Woche
<<Roll-up>> Lieferantenland
<<Roll-up>> Land
<<Dimension>> Produkt
<<Dimension>> Geographie
1 .. *
<<Dimension>> Zeit
<<Roll-up>> Woche
<<Shared Roll-up>> Jahr
<<Roll-up>> Jahr
1 .. 2

10
3.2 mUML – Modellierung (1)
<<Dimensional-Class>>
Produktgruppe
<<Dimensional-Class>>
Produktfamilie
<<Dimensional-Class>>
Produktkategorie
<<Dimensional-Class>>
Artikel
<<Roll-up>> Produktgruppe
<<Roll-up>> Produktfamilie
<<Roll-up>> Produktkategorie
<<Dimensional-Class>>
Bezirk
<<Dimensional-Class>>
Stadt
<<Dimensional-Class>>
Filiale
<<Dimensional-Class>>
Region
<<Roll-up>> Region
<<Roll-up>> Bezirk
<<Roll-up>> Stadt
<<Dimensional-Class>>
Land
<<Fact-Class>>
Verkauf
<<Dimensional-Class>>
Verkaufter Artikel
<<Dimensional-Class>>
Monat
<<Dimensional-Class>>
Tag
<<Dimensional-Class>>
Quartal
<<Roll-up>> Quartal
<<Roll-up>> Monat
<<Dimensional-Class>>
Jahr
<<Dimensional-Class>>
Woche
<<Roll-up>> Lieferantenland
<<Roll-up>> Land
<<Dimension>> Produkt
<<Dimension>> Geographie
1 .. *
<<Dimension>> Zeit
<<Roll-up>> Woche
<<Shared Roll-up>> Jahr
<<Roll-up>> Jahr
1 .. 2
<<Fact-Class>>
Verkauf
Anzahl:Verkäufe
EinzelVK:Preis
/Umsatz:Preis{formula=„Anzahl*EinzelVK“, parameter=„Anzahl, EinzelVK“}
Tagged value
3.2 mUML – Modellierung (2)
<<Dimensional-Class>>
Produktgruppe
<<Dimensional-Class>>
Produktfamilie
<<Dimensional-Class>>
Produktkategorie
<<Dimensional-Class>>
Artikel
<<Roll-up>> Produktgruppe
<<Roll-up>> Produktfamilie
<<Roll-up>> Produktkategorie
<<Dimensional-Class>>
Bezirk
<<Dimensional-Class>>
Stadt
<<Dimensional-Class>>
Filiale
<<Dimensional-Class>>
Region
<<Roll-up>> Region
<<Roll-up>> Bezirk
<<Roll-up>> Stadt
<<Dimensional-Class>>
Land
<<Fact-Class>>
Verkauf
<<Dimensional-Class>>
Verkaufter Artikel
<<Dimensional-Class>>
Monat
<<Dimensional-Class>>
Tag
<<Dimensional-Class>>
Quartal
<<Roll-up>> Quartal
<<Roll-up>> Monat
<<Dimensional-Class>>
Jahr
<<Dimensional-Class>>
Woche
<<Roll-up>> Lieferantenland
<<Roll-up>> Land
<<Dimension>> Produkt
<<Dimension>> Geographie
1 .. *
<<Dimension>> Zeit
<<Roll-up>> Woche
<<Shared Roll-up>> Jahr
<<Roll-up>> Jahr
1 .. 2
Modellierung der Dimensionen
Roll-up Pfade
11
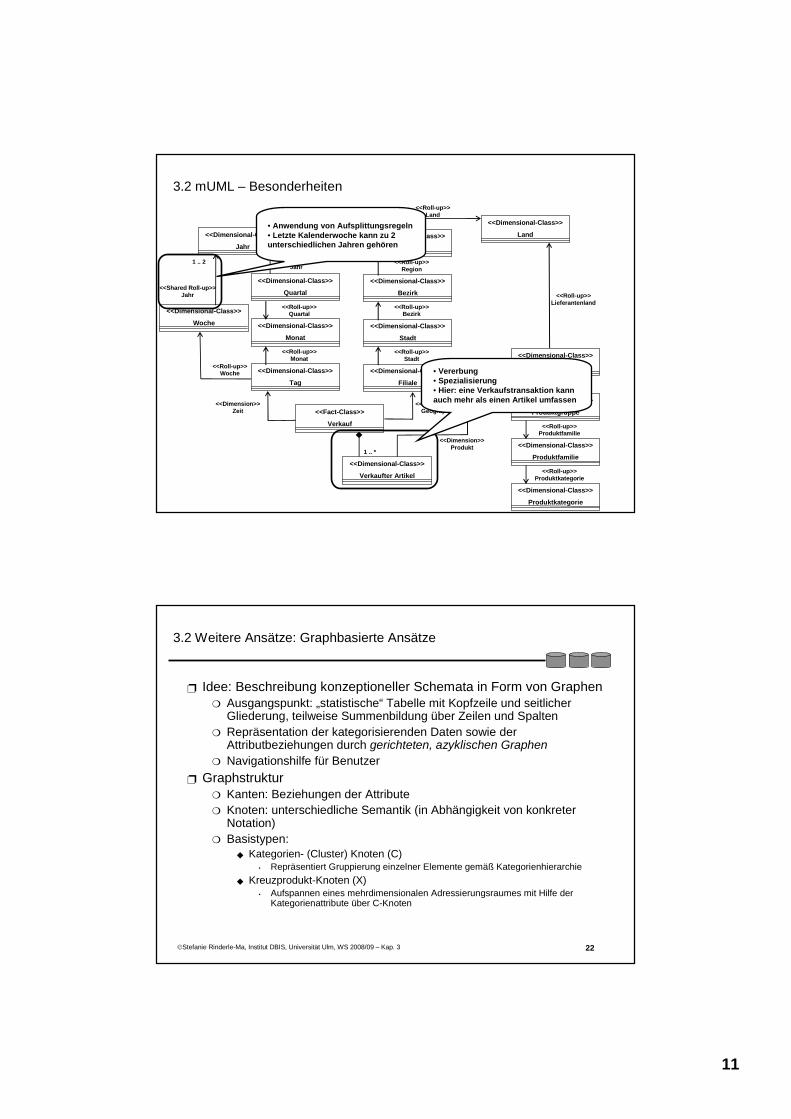
3.2 mUML – Besonderheiten
<<Dimensional-Class>>
Produktgruppe
<<Dimensional-Class>>
Produktfamilie
<<Dimensional-Class>>
Produktkategorie
<<Dimensional-Class>>
Artikel
<<Roll-up>> Produktgruppe
<<Roll-up>> Produktfamilie
<<Roll-up>> Produktkategorie
<<Dimensional-Class>>
Bezirk
<<Dimensional-Class>>
Stadt
<<Dimensional-Class>>
Filiale
<<Dimensional-Class>>
Region
<<Roll-up>> Region
<<Roll-up>> Bezirk
<<Roll-up>> Stadt
<<Dimensional-Class>>
Land
<<Fact-Class>>
Verkauf
<<Dimensional-Class>>
Verkaufter Artikel
<<Dimensional-Class>>
Monat
<<Dimensional-Class>>
Tag
<<Dimensional-Class>>
Quartal
<<Roll-up>> Quartal
<<Roll-up>> Monat
<<Dimensional-Class>>
Jahr
<<Dimensional-Class>>
Woche
<<Roll-up>> Lieferantenland
<<Roll-up>> Land
<<Dimension>> Produkt
<<Dimension>> Geographie
1 .. *
<<Dimension>> Zeit
<<Roll-up>> Woche
<<Shared Roll-up>> Jahr
<<Roll-up>> Jahr
1 .. 2
• Anwendung von Aufsplittungsregeln• Letzte Kalenderwoche kann zu 2 unterschiedlichen Jahren gehören
• Vererbung• Spezialisierung• Hier: eine Verkaufstransaktion kann auch mehr als einen Artikel umfassen
22©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 Weitere Ansätze: Graphbasierte Ansätze
Idee: Beschreibung konzeptioneller Schemata in Form von GraphenAusgangspunkt: „statistische“ Tabelle mit Kopfzeile und seitlicher Gliederung, teilweise Summenbildung über Zeilen und SpaltenRepräsentation der kategorisierenden Daten sowie der Attributbeziehungen durch gerichteten, azyklischen GraphenNavigationshilfe für Benutzer
GraphstrukturKanten: Beziehungen der AttributeKnoten: unterschiedliche Semantik (in Abhängigkeit von konkreter Notation)Basistypen:
Kategorien- (Cluster) Knoten (C)• Repräsentiert Gruppierung einzelner Elemente gemäß Kategorienhierarchie
Kreuzprodukt-Knoten (X)• Aufspannen eines mehrdimensionalen Adressierungsraumes mit Hilfe der
Kategorienattribute über C-Knoten
12
23©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
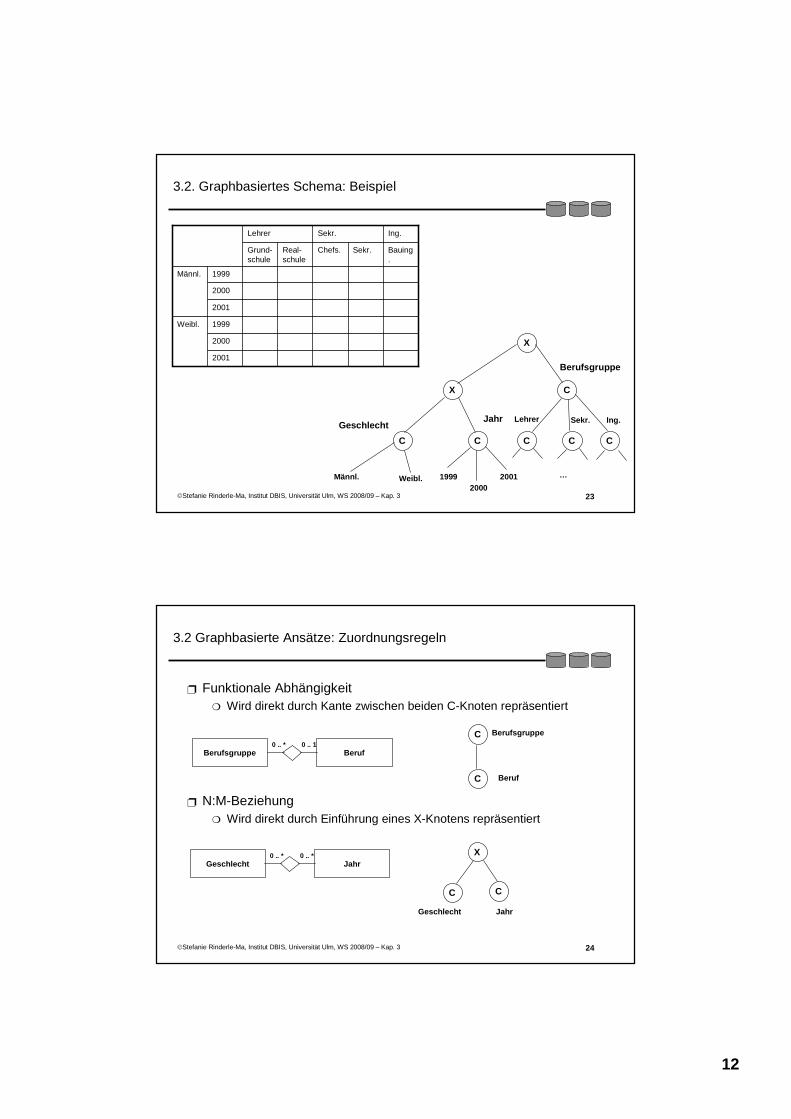
3.2. Graphbasiertes Schema: Beispiel
2001
2000
1999Weibl.
2001
2000
1999Männl.
Bauing.
Sekr.Chefs.Real-schule
Grund-schule
Ing.Sekr.Lehrer
X
X C
C C C C C
Männl. Weibl. 19992000
2001
GeschlechtJahr Lehrer Sekr. Ing.
Berufsgruppe
…
24©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 Graphbasierte Ansätze: Zuordnungsregeln
Funktionale AbhängigkeitWird direkt durch Kante zwischen beiden C-Knoten repräsentiert
N:M-BeziehungWird direkt durch Einführung eines X-Knotens repräsentiert
Berufsgruppe Beruf0 .. * 0 .. 1
C
C
Berufsgruppe
Beruf
Geschlecht Jahr0 .. * 0 .. *
C C
Geschlecht Jahr
X

13
25©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 Graphbasierte Ansätze: weitere Knotentypen
Terminale Knoten (tn-Knoten)Repräsentation eines der möglichen Werte aus dem Wertebereich des übergeordneten KategorieattributesBeispiel: „männlich“, „weiblich“ für „Geschlecht“
Summenknoten (S-Knoten)Explizite Spezifikation des quantitativen Teils eines Objektgraphen (Mehrfachverwendung von Graphen)Beispiel: „mittleres Einkommen“, „Anteil am Gesamteinkommen“ zu X-Knoten
Topic-Knoten (T-Knoten)Repräsentation einer Menge statistischer ObjekteDekomposition statistischer Sachverhalte
Logische Verbindung von S-Knoten
26©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 Graphbasierte Ansätze: Modellierung der Abstraktion
Aggregation (A-Knoten)Zusammenfassung logisch zusammengehöriger EinzelfaktenBeispiel: (Straße, Stadt, Land) zu Wohnort, (PersNr, Name, Wohnort, Beruf) zu Erwerbstätige
Generalisierung (G-Knoten)Definition einer übergeordneten Klasse abstrakter Objekte
Beispiel: Erwerbstätige, Erwerbslose zu Erwerbsperson

14
27©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 weitere Notationen
Erweiterungen von ER:Dimensional Fact Modeling
ADAPTApplication Design for Analytical Processing Technologies Beschreibung sämtlicher Metadaten-Objekte
Aber: keine formale Grundlage
Graphbasiert:SUBJECT, GRASS, STORM, ADaS, …
Zur Zeit kein Standard verfügbarGraphbasierte Ansätze zwar mächtig + flexibel, aber kaum verbreitet
28©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.2 TAFELÜBUNG: Konzeptuelle Modellierung
Gegeben: meteorologische Daten In der meteorologischen Station MetWatch wird die Entwicklung von Temperatur und Luftfeuchtigkeit innerhalb Deutschlands über die letzten Jahre gemessen und ausgewertet. Dazu interessieren die einzelnen Tageswerte, aber auch die wöchentliche, monatliche und jährliche Entwicklung soll auswertbar sein.Außerdem sollen die Werte einzelner Bundesländer, Regionen und Städte analysiert werden.Schließlich soll auch der Faktor „Großwetterlage“ mit den Kategorien „Hoch“ und „Tief“ einbezogen werden.
Stellen Sie den obigen Sachverhalt in als mE/R-Modell dar.

15
29©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Dimensionen: Großwetterlage, Geographie, Zeit
3.2 TAFELÜBUNG: Ergebnis
Wetter
Temperatur
Luftfeuchtigkeit
HochTief
Stadt
Tag
Region
Monat
Woche
Jahr
Bundesland
30©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Kapitel 3: Überblick
3.1 Data-Warehouse-Designprozess3.2 Konzeptuelle Datenmodellierung
3.3 Formalisierung und AnalyseoperationenMotivationDefinitionenOperationen
3.4 Umsetzung des multidimensionalen Datenmodells
3.5 Zusammenfassung

16
31©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Motivation: Beispiel multidimensionales Schema
Verkauf
Anzahl
Umsatz
Artikel
Filiale
Tag
Gruppe
Stadt
Monat
Woche
Familie
Bezirk
Quartal
Kategorie
Region
Jahr
Einkauf
Menge
Preis
VK-Preis
Lager
Lagerbestand
Es befinden sich 4 Würfel in der Datenbank
Nämlich: Verkauf, Einkauf, Preis, Lager
Mit den Dimensionen: Produkt, Zeit, Geographie, Kunde
Kunde Alter
32©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Schema einer Dimension
Schema einer Dimension DSPartiell geordnete Menge von Kategorienattributen ({K1, …, Kn, TopD}; →)
Generisches maximales Element TopD
Funktionale Abhängigkeit →TopD wird von allen Attributen funktional bestimmt:
∀i, 1 ≤ i ≤ n: Ki → TopD
Genau ein Ki, das alle anderen Kategorieattribute bestimmtGibt feinste Granularität einer Dimension vor:
∃i, 1 ≤ i ≤ n, ∀ j, 1 ≤ j ≤ n, i ≠ j, Ki → Kj
Beispiel für die Zeitdimension DSZeit = ({Tag, Woche, Monat, Quartal, Jahr, TopZeit) mit den funktionalen Abhängigkeiten
Tag → WocheTag → Monat → Quartal → JahrTag → TopZeit, Woche → TopZeit, Quartal → TopZeit, Jahr → TopZeit

17
33©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Kategorienattribute
Inhaltliche Verfeinerung durch unterschiedliche RollenPrimärattribut
Kategorienattribut, das alle anderen Attribute einer Dimension bestimmt
Definiert maximale FeinheitBeispiel: „Tag“
KlassifikationsattributElement der Menge, die mehrstufige Kategorisierung (Klassifikationshierarchie) bildenBeispiel: „Monat“, „Quartal“
Dimensionales AttributElement der Menge der Attribute, die vom Primärattribut oder einem Klassifikationsattribut bestimmt werden und nur TopD bestimmenBeispiel: „Artikelnummer“ zu Artikel
34©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Kategorienattribute : Beispiel
Verkauf
Anzahl
Umsatz
Artikel
Filiale
Tag
Gruppe
Stadt
Monat
Woche
Familie
Bezirk
Quartal
Branche
Region
Jahr
KlassifkationsattributePrimärattribut
Kunde Alter
Dimensionales Attribut

18
35©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Kennzahlen / Fakten
Kennzahlen/Fakten (engl. facts):(verdichtete) numerische MessgrößenBeschreiben betriebswirtschaftliche Sachverhalte
Fakt: BasiskennzahlKennzahl:
aus Fakten konstruiert (abgeleitete Kennzahl)Durch Anwendung arithmetischer Operationen
Beispiele: Umsatz, Gewinn, Verlust, DeckungsbeitragEin Fakt F eines multidimensionalen Schemas ist definiert als Tupel
F:= (G, SumTyp) mit G := {DS1.K1, …, DSn.Kn} bezeichnet die Granularität des betrachteten Schemas mit
DS1, …, DSn im Schema existierende Dimensionsschemata mit DSi = ({Ki1, …, Ki
m}, )∀ i, p mit 1 ≤ i, p ≤ n, i ≠ p: ¬ (DSi.Ki → DSp.Kp), d.h. keine funktionale Abhängigkeit zwischen Kategorienattributen einer GranularitätBeispiel: GVerkauf1 = (Produkt.Gruppe, Zeit.Monat, Geographie.Stadt)
Summationstyp SumTyp (bestimmt, welche Aggregrationsfunktion auf Fakt / Kenngröße angewendet werden darf)
36©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Kennzahl
Kennzahl M ist definiert als Tripel M = (G, f(F1, …, Fk), SumTyp) mitGranularität GBerechnungsvorschrift f()
Summationstyp SumTypBerechnung über nichtleerer Teilmenge der im Schema existierenden Fakten
Berechnungsvorschrift Bildung von f()
Skalarfunktionen• +, -, *, /, mod• Beispiel: Umsatzsteueranteil = Menge * Preis * Steuersatz
Aggregatfunktionen• Funktion H() zur Verdichtung eines Datenbestandes, indem aus n Einzelwerten ein Aggregatwert
ermittelt wird
• H: 2 dom(X1) ×… × dom(Xn) dom(Y)• SUM(), AVG(), MIN(), MAX(), COUNT()
Ordnungsbasierte Funktionen• Definition von Kennzahlen auf Basis zuvor definierter Ordnungen• Bsp.: Kumulation, TOP(n)

19
37©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Summationstyp
erlaubte AggregationsoperationenFLOW
Beliebig aggregierbarBeispiel: Bestellmenge eines Artikels pro Tag
STOCKBeliebig aggregierbar mit Ausnahme temporaler Dimension
Beispiele: Lagerbestand, Einwohnerzahl pro Stadt
VALUE-PER-UNIT (VPU)Aktuelle Zustände, die nicht summierbar sindZulässig nur: MIN(), MAX, AVG()Beispiele: Wechselkurs, Steuersatz
38©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Summierbarkeit
+++COUNT
+++AVG
-+-+SUM
+++MIN/MAX
JaNein
VPUSTOCK: Aggregration über temporale Dimension?
FLOW

20
3.3 Weitere Eigenschaften
DisjunktheitEin konkreter Wert einer Kennzahl geht exakt einmal in Ergebnis einBsp.: Studierende im Grundstudium
VollständigkeitKennzahlen auf höherer Aggregationsebene lassen sich komplett aus Werten tieferer Stufen berechnen
49243225Gesamt
21111510BWL
28131715Informatik
Gesamt 200120001999Studierende
118117Gesamt
2220Augsburg
5052Stuttgart
4645Ulm
20022001Restaurants
40©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Multidimensionaler Datenwürfel für Verkauf
Produkt
Artikel
Zeit
Filiale
Stadt
Bundesland
Kategorie
Quartal
Halbjahr
Jahr
Geographie
KennzahlUmsatz
Dimension
Kategorienattribut
Aus Darstellungsgründen im Folgenden Abstraktion von
Dimension Kunde

21
41©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Würfel
Würfel (engl. cube, eigentlich Quader):Grundlage der multidimensionalen AnalyseKanten DimensionenZellen ein oder mehrere Kennzahlen (als Funktion der Dimensionen)Anzahl der Dimensionen DimensionalitätVisualisierung
2 Dimensionen: Tabelle3 Dimensionen: Würfel>3 Dimensionen: Multidimensionale Domänenstruktur
Schema W eines Würfels ist definiert als Tupel W(G, M) mitGranularität GMenge der Kennzahlen M = (M1, …, Mm)
Beispiel: Verkauf((Produkt.Artikel, Zeit.Tag, Geographie.Filiale), (Verkauf, Umsatz))
Instanz eines Würfels wird durch das Kreuzprodukt der Wertebereiche aller am Würfelschema beteiligten Attribute definiert (formal: WI ⊆ dom(G) × dom(M))
Beispiel für eine Würfelzelle des Verkaufswürfels: ((„Milch“, „22.02.05“, „Filiale Ulm“),(5, 4.95))
In multidimensionalen Schemata gilt Orthogonalität, d.h.Keine funktionalen Abhängigkeiten zwischen Attributen unterschiedlicher Dimensionen∀ i, 1 ≤ i ≤ n, ∀ j, 1 ≤ j ≤ n, i ≠ j, ¬ ∃ k, l : DSi.Kk DSj.Kl
Aus Darstellungsgründen im Folgenden Abstraktion von
Dimension Kunde
42©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 TAFELÜBUNG: Formalisierung konzeptuelles Modell
Gegeben: unsere Wetterstation MetWatchWie sieht die formale Definition des Würfels aus, der die Kenngrößen Temperatur und Luftfeuchtigkeit auf den Klassifikationsstufen Monat und Bundesland beschreibt?Welche Berechnungsvorschrift bietet sich für die Kenngröße Temperatur an?Geben Sie eine beliebige Würfelzelle dieses Würfels an.
Wetter1((Zeit.Monat, Geographie.Bundesland, Großwetterlage.HochTief), (Temperatur, Luftfeuchtigkeit))Bspw. Durchschnittsbildung AVG() oder Maximum / Minimum (Temperatur vom Typ VALUE-PER-UNIT)
Z.B. ((„April_2004“, „Hessen“, „Hoch“), (14, 20))

22
43©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Grundoperatoren
Restriktion: Gegeben W((D1.K1, …, Dn.Kn), (M1, …, Mk)), Prädikat PRestriktion ist definiert als σP(W) = {z ∈ W | P(z)}, falls alle Variablen in P
Entweder Klassifikationsstufen K sind, die funktional von einer Klassifikationsstufe der Granularität von W abhängen
(formal: ∃Di.Ki mit Ki → K)Oder Kenngrößen aus (M1, …, Mk) sind
Beispiel: Wselect = σP.Produktgruppe=„Video“(Verkauf)
Die Projektion einer Funktion der Kenngrößen F(K) eines Würfels W ist definiert als πF(K)(W) = {(g, F(m)) ∈ dom(G) × dom(F(K)) | (g, m) ∈ W}Verbundoperationen
Verbinden Kennziffern aus verschiedenen Würfeln zu einer neuen Kennzahl
Gegeben: W1(G1, M1), W2(G2, M2) lassen sich verbinden ⇔ G1 = G2 :=GVerbund der Zellen wird über ihre Kennzahlen durchgeführt
Ergebnis W:= W1 W2 mit W(G, M1 ∪ M2)
3.3 Pivotierung / Rotation
Drehen des Würfels durch Vertauschen der Dimensionen Analyse der Daten aus verschiedenen Perspektiven
Produkt
Zei
tGeo
graphi
e
Zeit
Geo
gra
ph
iePro
dukt
Geographie
Pro
du
ktZei
t
Zeit
Pro
du
ktGeo
graphi
e
Produkt
Geo
gra
ph
ieZei
t
Geographie
Zei
tPro
dukt

23
45©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Roll-Up / Drill-Down / Drill-Across
Roll-Up:Erzeugen neuer Informationen durch Aggregierung der Daten entlang des KonsolidierungspfadesDimensionalität bleibt erhalten
Beispiel: Tag → Monat → Quartal → Jahr
Drill-Down:komplementär zu Roll-UpNavigation von aggregierten Daten zu Detail-Daten entlang der Klassifikationshierarchie
Drill-Across:Ausweisen von Kennzahlen bzgl. einer anderen Klassifikationshierarchie bzw. Dimension
Also: „Wechsel von einem Würfel zu einem anderen“
46©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Drill Down / Roll-up (2)
Pro
du
ktGeo
graphi
e
1. Q
uarta
l2.
Qua
rtal
3. Q
uarta
l4.
Qua
rtal
Zeit
Drill-Down
Pro
du
ktGeo
graphi
e
Zeit
Jan.
Feb.
Mär
zApr
ilM
aiJu
ni Juli
Aug.
Sept.
Okt
.Nov
.Dez
.
Roll-up

24
47©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Slice and Dice (1)
Erzeugen individueller SichtenSlice:
Herausschneiden von „Scheiben“ aus dem Würfel durch Punkt- oder Listeneinschränkungen auf KlassifikationsattributenVerringerung der DimensionalitätBeispiel: alle Werte des aktuellen Jahres in den Filialen Ulm und Bonn (Jahr = „2006“, Filiale IN („Ulm“, „Bonn“))
Dice:Herausschneiden einen „Teilwürfels“Erhaltung der Dimensionalität, Veränderung der Hierarchieobjekte
Beispiel: die Werte bestimmter Produkte oder Regionen
48©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.3 Slice and Dice
Zeit
Geo
gra
ph
iePro
dukt
Slicing:
Zeit
Geo
gra
ph
iePro
dukt
Zeit
Geo
gra
ph
iePro
dukt
Dicing:

25
49©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Kapitel 3: Überblick
3.1 Data-Warehouse-Designprozess3.2 Konzeptuelle Datenmodellierung
3.3 Formalisierung und Analyseoperationen
3.4 Umsetzung des multidimensionalen DatenmodellsRelationale Speicherung
Multidimensionale Speicherung
3.5 Zusammenfassung
50©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Allgemeine Anmerkungen
Multidimensionale SichtModellierung der DatenAnfrageformulierung
Interne Verwaltung der Daten erfordert Umsetzung aufROLAP (relationales OLAP), Umsetzung der multidimensionalen Struktur in Relationen
Vorteile: • relationale DBMS weit verbreitet
• Ausgereifte Technologie
Nachteile:• Umsetzung der multidimensionalen Strukturen als Relationen:
• Welche Nachteile ergeben sich hieraus?

26
51©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Allgemeine Anmerkungen
MOLAP (multidimensionales OLAP), direkte Speicherung in multidimensionalen Strukturen
Vorteile:• Keine Transformationen notwendig
Nachteile:• Zellen können unter Umständen nur dünn besetzt sein (sparsity)
• Skalierbarkeit
Hybrid, also Kombination von ROLAP und MOLAPVorteile beider VariantenNachteil: Komplexität
Wesentliche Aspekte bei der Umsetzung multidimensionaler Strukturen:
Speicherung
Anfrageformulierung bzw. -ausführung
52©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Relationale Speicherung: Anforderungen
Informationen aus dem multidimensionalen Modell (z.B. Klassifikationshierarchien) sollen nicht verloren geheneffiziente Übersetzung und Verarbeitung multidimensionaler Anfragen
Update der gespeicherten Daten soll einfach sein
Analysen sollen adäquat unterstützt werden (z.B. Beachtung der Anfragecharakteristik und des Datenvolumens)

27
53©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Relationale Speicherung: Faktentabelle
Ausgangspunkt: Umsetzung des Datenwürfels ohne Klassifikationshierarchien
Dimensionen, Kennzahlen Spalten der RelationZelle Tupel
Primärschlüssel: Artikel, Filiale, TagKenngrößen (measure, häufig numerisch): VerkaufResultierende Tabelle heißt Faktentabelle (fact table)
Produkt
Zeit
Geographie 21420.04.06StuttgartMelitta
50021.04.06UlmJacobs
20020.04.06UlmMelitta
VerkaufTagFilialeArtikel
Melitta
Jacobs
Ulm Stuttgart
20.04.0621.04.06
Aus Darstellungsgründen im Folgenden Abstraktion von
Dimension Kunde
54©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
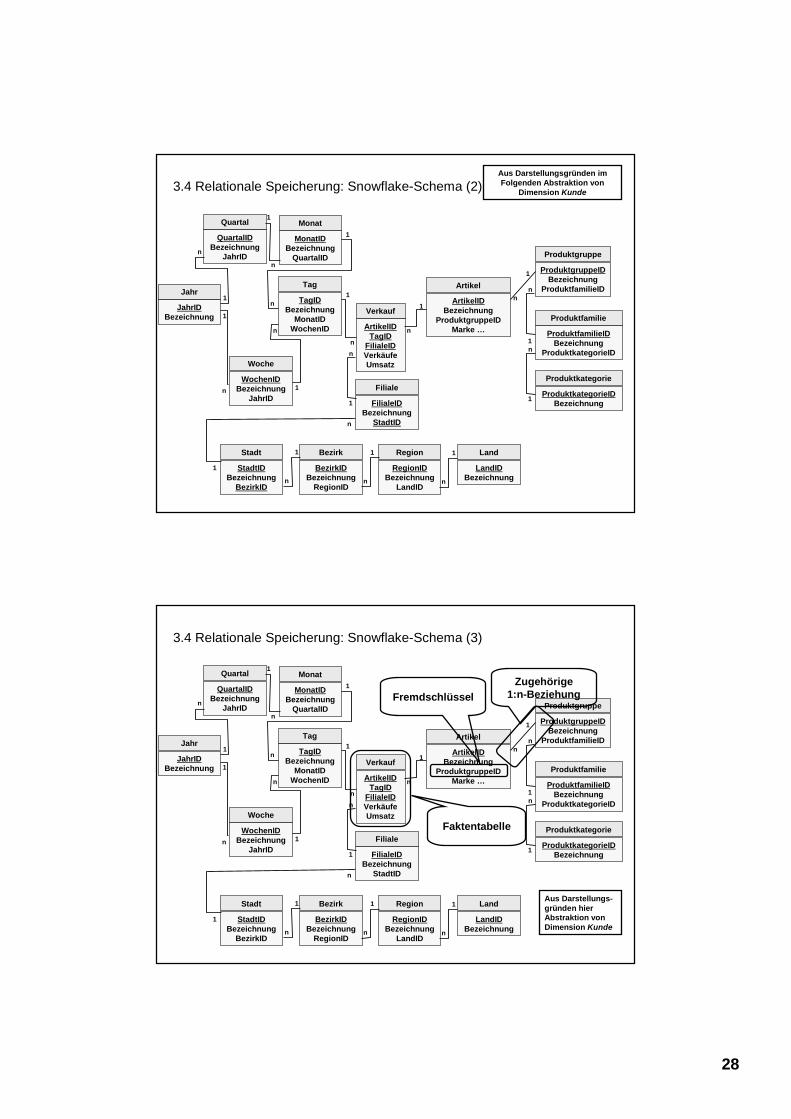
3.4 Relationale Speicherung: Snowflake-Schema (1)
Klassifikationsstufen werden jeweils als eine Tabelle abgebildet (z.B. Artikel, Produktgruppe, etc.)Tabelle enthält
ID für Klassifikationsknotenbeschreibendes Attribut (z.B. Marke, Hersteller, Bezeichnung)Fremdschlüssel der direkt übergeordneten Klassifikationsstufe
Faktentabelle enthält (neben Kenngrößen):Fremdschlüssel der jeweils niedrigsten KlassifikationsstufeFremdschlüssel bilden zusammengesetzte Primärschlüssel für Faktentabelle
Vorteile:
Nachteile:
28
3.4 Relationale Speicherung: Snowflake-Schema (2)
ArtikelIDTagID
FilialeIDVerkäufe Umsatz
Verkauf ArtikelID
Bezeichnung ProduktgruppeID
Marke …
Artikel
ProduktgruppeIDBezeichnung
ProduktfamilieID
Produktgruppe
ProduktfamilieIDBezeichnung
ProduktkategorieID
Produktfamilie
ProduktkategorieIDBezeichnung
Produktkategorie
FilialeIDBezeichnung
StadtID
Filiale
StadtIDBezeichnung
BezirkID
Stadt
BezirkIDBezeichnung
RegionID
Bezirk
RegionIDBezeichnung
LandID
Region
LandIDBezeichnung
Land
TagIDBezeichnung
MonatIDWochenID
Tag
WochenIDBezeichnung
JahrID
Woche
MonatIDBezeichnung
QuartalID
Monat
QuartalIDBezeichnung
JahrID
Quartal
JahrIDBezeichnung
Jahr
1
n
1
n
1
n
1
n
1
n
1
n
1
n
1
n
1
n
n
1
1
n
n
1
n
1
n
1
1
n
Aus Darstellungsgründen im Folgenden Abstraktion von
Dimension Kunde
3.4 Relationale Speicherung: Snowflake-Schema (3)
ArtikelIDTagID
FilialeIDVerkäufe Umsatz
Verkauf ArtikelID
Bezeichnung ProduktgruppeID
Marke …
Artikel
ProduktgruppeIDBezeichnung
ProduktfamilieID
Produktgruppe
ProduktfamilieIDBezeichnung
ProduktkategorieID
Produktfamilie
ProduktkategorieIDBezeichnung
Produktkategorie
FilialeIDBezeichnung
StadtID
Filiale
StadtIDBezeichnung
BezirkID
Stadt
BezirkIDBezeichnung
RegionID
Bezirk
RegionIDBezeichnung
LandID
Region
LandIDBezeichnung
Land
TagIDBezeichnung
MonatIDWochenID
Tag
WochenIDBezeichnung
JahrID
Woche
MonatIDBezeichnung
QuartalID
Monat
QuartalIDBezeichnung
JahrID
Quartal
JahrIDBezeichnung
Jahr
1
n
1
n
1
n
1
n
1
n
1
n
1
n
1
n
1
n
n
1
1
n
n
1
n
1
n
1
1
n
Faktentabelle
FremdschlüsselZugehörige
1:n-Beziehung
Aus Darstellungs-gründen hier Abstraktion von Dimension Kunde

29
57©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 TAFELÜBUNG: Snowflake-Schema
Gegeben: unsere Wetterstation MetWatchGeben Sie die relationale Speicherung des Wetter-Würfels als Snowflake-Schema an.
StadtIDTagIDHTID
Temp. Luftf.
Wetter StadtID
Bezeichnung RegionID
Stadt
RegionIDBezeichnung BundeslandID
Region
BundeslandIDBezeichnung
Bundesland
HTIDBezeichnung
HochTief
TagIDBezeichnung
MonatIDWochenID
Tag
WochenIDBezeichnung
JahrID
Woche
MonatIDBezeichnung
QuartalID
Monat
JahrIDBezeichnung
Jahr
1
n
1
n
1
n
1
n
n
1
1
n
n
1
n
1
1
n
58©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Relationale Speicherung: Star-Schema (1)
Snowflake-Schema ist normalisiert:Vermeidung von Update-Anomalien Anfragen verursachen jedoch häufig „Monsterjoins“ (Joins über mehrere Tabellen)
deshalb Übergang zum so genannten Star-Schema:Die zu einer Dimension gehörenden Tabellen werden denormalisiert, also zu einer Dimensionstabelle (pro Dimension) „zusammengefasst“
Eine Konsequenz hieraus sind Redundanzen in der DimensionstabelleDiese Redundanzen erlauben jedoch eine schnellere AnfragebearbeitungBeispiel: Artikel, Produkt, Produktgruppe etc. als Spalten in einer Tabelle Produkt
Vorteile des Star-Schemas:Intuitive Umsetzung der multidimensionalen StrukturSchnellere Anfrageauswertung, keine „Monsterjoins“
Nachteile:Redundanzen aufgrund der DenormalisierungMehrfache Hierarchien können nicht direkt modelliert werden

30
59©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Relationale Speicherung: Star-Schema (2)
Dim1_Schlüssel
Dim2_Schlüssel
Dim3_Schlüssel
…
Measure1
Measure2
Measure3
…
Faktentabelle
Allgemeines Star-Schema
Dim1_Schlüssel
Dim1_Attribute
1. Dimensionstabelle
Dim2_Schlüssel
Dim2_Attribute
2. Dimensionstabelle
Dim3_Schlüssel
Dim3_Attribute
3. Dimensionstabelle
Dim4_Schlüssel
Dim4_Attribute
4. Dimensionstabelle
60©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Relationale Speicherung: Star-Schema (3)
ProduktID
ZeitID
GeographieID
Verkäufe
Umsatz
Verkauf
ProduktID
Artikel
Produktgruppe
Produktfamilie
Produktkategorie
Bezeichnung
Marke
Packungstyp
…
Produkt
ZeitID
Tag
Woche
Monat
Quartal
Jahr
Zeit
GeographieID
Filiale
Stadt
Bezirk
Region
Land
…
Geographie
n
1
n
n
1
1
StarKauf*-Szenario als Star-Schema modelliert
Aus Darstellungsgründen im Folgenden Abstraktion von
Dimension Kunde

31
3.4 Relationale Speicherung: Star-Schema (4)
Muster eines Star-Schemas: Multidimensionales Schema mit n DimensionenDimensionstabellen D1, ..., Dn der Form Di(PAi, Ai1, ..., Aik)
Faktentabelle F(PA1, ..., PAn, f1, ..., fk)Jeder Teil des kompositen Primärschlüssels der Faktentabelle ist Fremdschlüssel zum Primärschlüsselattribut der korrespondierenden Dimension
Redundanzen in Dimensionstabelle durch DenormalisierungBeispiel: Zugehörigkeit eines Artikels zu Produktgruppe führt zu Zugehörigkeit zu Produktfamilie
…
…
…
…
Heißgetränke
Heißgetränke
Heißgetränke
Heißgetränke
Kaffee
Kaffee
Kaffee
Kakao
Filterkaffee
Filterkaffee
Espresso
Instant-Kakao
…
…
…
…
Melitta
Jacobs
Lavazza
Nesquik
123
124
125
126
…KategorieProduktfamilieProduktgruppe…ArtikelProduktID
62©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Vergleich von Star- und Snowflake-Schema (1)
Vorüberlegung: Wie sehen DWH-Anwendungen typischerweise aus?Häufig werden Anfragen auf höhere Klassifikationsstufen gestellt Dimensionstabellen weisen im Vergleich zu Faktentabellen ein geringes Datenvolumen auf
Klassifikationen werden sehr selten geändert
Vorteile des Star-Schemasleicht verständliche Struktur Benutzer kann Anfragen intuitiver formuliereneffiziente Anfrageverarbeitung innerhalb einer Dimension (keine Join-Operation notwendig)Redundanzen aufgrund Denormalisierung und damit verbunden das Datenvolumen halten sich meistens in GrenzenGefahr von Update-Anomalien gering

32
63©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Vergleich von Star- und Snowflake-Schema (2)
Vergleiche basieren häufig auf für KostenbetrachtungenWir werden im Folgenden Kostenabschätzungen für Speicherbedarf und Anfragekomplexität für Snowflake- und Starschema erarbeiten
Annahmen hierzu: D Dimensionen, je K Klassifikationsstufen plus Top
Jeder Klassifikationsknoten hat 3 Kinder ⇒
M Fakten, gleich verteilt in DimensionenAttribut: b Bytes; Knoten haben nur ID;
f Faktattribute
64©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Vergleich von Star- und Snowflake-Schema (3)

33
65©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Vergleich von Star- und Snowflake-Schema (4)
66©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Vergleich von Star- und Snowflake-Schema (5)
Anfrage: Verkäufe der Produktgruppe „Soft-Drink“ pro Filiale und JahrSnowflake-Schema:
Anzahl der Joins: 6 (steigt linear mit Anzahl der Aggregationspfade)

34
67©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Vergleich von Star- und Snowflake-Schema (6)
Anfrage für Star-Schema:
Anzahl der Joins: 3 (unabhängig von der Länge der Aggregationspfade)
68©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Weitere Möglichkeiten
„Mix“ aus Snowflake-Schema oder Star-SchemaEntscheidung für jeweilige Dimension anhand der folgenden Fragen:
Wie häufig ändert sich die jeweilige Dimensionen?
Wie viele Klassifikationsstufen besitzt die Dimension? Wie viele Dimensionselemente besitzt die Dimension? Sollen bestimmte Aggregate materialisiert gehalten werden?
Zusammenfassungen innerhalb des Star-Schemaseine Faktentabelle
mehrere Kennzahlen nur möglich bei gleichen DimensionenIm Beispiel (Folie 31) haben nur die Kennzahlen Verkauf und Umsatz die gleichen Dimensionen und können deshalb durch eine gemeinsame Faktentabelle repräsentiert werden
Galaxie (Multi-Faktentabellen-Schema, Multi-Cube, Hyper-Cube)mehrere Faktentabellen
teilweise mit gleichen Dimensionstabellen verknüpft

35
69©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Fact Constellation
Aus Optimierungsgründen kann es sinnvoll sein, bestimmte Aggregate (die z.B. häufig angefragt werden) vorzuhalten (z.B. Umsatz pro Monat).Erste Möglichkeit: Speicherung der Aggregate in der Faktentabelle
Hierzu nötig: Unterscheidung in Dimensionstabelle über spezielle Attribute (z.B. „Stufe“, siehe Abbildung auf Folie 72)
Alternative: die Aggregrate werden in eigenen Faktentabellen gehaltenDiese Art von Schema wird Fact-Constellation-Schema genannt (da mehrere Faktentabellen) und ist ein Spezialfall des Galaxie-Schemas.
Einführung des zusätzlichen Attributes „Stufe“ ist nicht nötigWürfel, die durch Aggregation auseinander hervorgehen, teilen sich entsprechende Dimensionen
3.4 Klassifikationshierarchien (1)
Horizontal: Modellierung der Stufen der Klassifikationshierarchie als Spalten der denormalisierten DimensionstabelleVorteil:
Nachteile:
SELECT DISTINCT Produktgruppe
FROM Produkt
WHERE Produktkategorie = „Heissgetraenk“
Heissgetraenk
Heissgetraenk
HeissgetraenkHeissgetraenk
Filterkaffee
Filterkaffee
EspressoInstant-Kakao
Melitta
Jacobs
LavazzaNesquik
123
124
125126
ProduktkategorieProduktgruppeArtikelProduktID

36
71©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Klassifikationshierarchien (2)
Vertikal (rekursiv): normalisierte Dimensionstabelle mit AttributenDimensions_ID: Schlüssel, der Beziehung zu Faktentabelle herstelltEltern_ID: Attributwert der Dimensions-ID der nächsthöheren Stufe
Vorteile:Einfache Änderung am Klassifikationsschema
Einfache Behandlung vorberechneter Aggregate
Nachteil:Self-Join für Anfragen einzelner Stufen (Bsp.: Produktgruppe innerhalb einer Kategorie)
RekursionSELECT L3.ElternID
FROM Produkt AS L1, Produkt AS L2, Produkt AS L3
WHERE L1.DimensionID = „Heissgetraenk“ AND
L2.ElternID = L1.DimensionID AND
L3.ElternID = L2.DimensionID
FilterkaffeeFilterkaffee
…
Heissgetraenk…Lebensmittel…
MelittaJacobs
…Filterkaffee…
Heissgetraenk…
ElternIDDimensionsID
72©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Klassifikationshierarchien (3)
Kombination von horizontaler und vertikaler DarstellungRepräsentation der Klassifikationsstufen als Spalten Spaltenbezeichner werden generisch gehaltenSpeicherung der Knoten aller höheren Stufen als TupelZusätzliches Attribut „Stufe“ Angabe der bezeichneten Klassifikationsstufe
Wie können bei der relationalen Abbildung Semantikverluste verhindert werden?
0
0
1
2
Heißgetränke
Heissgetraenk
NULL
NULL
Filterkaffee
Filterkaffee
Heissgetraenk
NULL
Melitta
Jacobs
Filterkaffee
Heissgetraenk
StufeStufe2_IDStufe1_IDDimesionsID

37
73©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Relationale Umsetzung multidimensionaler Anfragen
Hängt von der Abbildungsvariante für das Schema abMeistens Aggregatanfragen bestehend aus (n+1)-Wege-Verbund zwischen n Dimensionstabellen und der Faktentabelle Star-Join-AnfragemusterBeispiel: „Wie viele Artikel der Produktkategorie Heißgetränke wurden 2004 pro Monat in den unterschiedlichen Regionen verkauft?“
SELECT G.Region, Z.Monat, SUM (Verkäufe)FROM Verkauf V, Zeit Z, Produkt P, Geographie G
WHERE V.Produkt_ID = P.Produkt_ID AND
V.ZEIT_ID = Z.ZEIT_ID AND
V.Geo_ID = G.Geo_ID AND
P.Produktfamilie = „Heissgetraenk“ AND
Z.Jahr = 2004 AND
G.Land = „Deutschland“
GROUP BY G.Region, Z.Monat
3.4 CUBE-Operator (1)
Erweiterung in SQL: Gruppierung einer Eingaberelation nach mehreren Gruppierungskombinationen CUBE-Operator
SELECT Region, Prodfamilie, Jahr, SUM(Verkäufe) AS Verkäufe FROM …GROUP BY Region, Prodfamilie, Jahr;
12485831676615
555122506751…
1998199920001996199920001996
199920001998199920001996…
VideoVideoVideoAudioAudioAudioTV
TVTVVideoVideoVideoAudio
…
BayernBayernBayernBayernBayernBayernBayern
BayernBayernHessen HessenHessenHessen…
VerkäufeJahrProdfamilieRegionVerkauf
Einfache Gruppierungsbedingung

38
3.4 CUBE-Operator (2)
12485811831676616415555112140322…501349615625782…172382350806
199819992000NULL199819992000NULL199619992000NULLNULL1998…NULL199819992000NULL1996…199819992000NULL
VideoVideoVideoVideoAudioAudioAudioAudioTVTVTVTVNULLVideo…NULLVideoVideoVideoVideoAudio…NULLNULLNULLNULL
BayernBayernBayernBayernBayernBayernBayernBayernBayernBayernBayernBayernBayernHessen…HessenNULLNULLNULLNULLNULL…NULLNULLNULLNULL
VerkäufeJahrProdfamilieRegionVerkauf
(SELECT Region, Prodfamilie, Jahr, SUM(Verkäufe) AS Verkäufe
FROM…
GROUP BY Region, Prodfamilie, Jahr)
UNION
(SELECT Null AS Prodfamilie, Region, Jahr, SUM(Verkäufe) AS Verkäufe
FROM
GROUP BY Region, Jahr)
UNION
… // (Prodfamilie,Region), (Prodfamilie,Jahr)
// (Region), (Jahr)
UNION
(SELECT Prodfamilie, NULL AS Region, NULL AS Jahr, SUM(Verkäufe) AS Verkäufe
FROM…
GROUP BY Prodfamilie)
UNION
(SELECT NULL AS Prodfamilie, NULL AS Region, NULL AS Jahr, SUM(Verkäufe) AS Verkäufe
FROM…)
Komplexe Gruppierungsbedingung
76©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 CUBE-Operator (3)
Nachteile dieser Lösung:Aufwendige Formulierung (aber automatische Generierung durch OLAP-Tools)Potenziell teure Verbundoperationen müssen für jede Teilanfrage neu ausgewertet werdenCUBE-Operator erzeugt alle möglichen Gruppierungskombinationen; andernfalls nur über lange UNION-Listen möglich
SELECT
Region, Prodfamilie, Jahr,
GROUPING(Region), GROUPING(Prodfamilie), GROUPING(Jahr),
SUM(Verkäufe) AS Verkäufe
FROM…
GROUP BY
CUBE(Region, Prodfamilie, Jahr)

39
77©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 CUBE-Operator (3)
Nachteile dieser Lösung:Aufwendige Formulierung (aber automatische Generierung durch OLAP-Tools)Potenziell teure Verbundoperationen müssen für jede Teilanfrage neu ausgewertet werdenCUBE-Operator erzeugt alle möglichen Gruppierungskombinationen; andernfalls nur über lange UNION-Listen möglich
SELECT
Region, Prodfamilie, Jahr,
GROUPING(Region), GROUPING(Prodfamilie), GROUPING(Jahr),
SUM(Verkäufe) AS Verkäufe
FROM…
GROUP BY
CUBE(Region, Prodfamilie, Jahr)
GROUPING liefert 1, falls auf Gruppierungsattribut angewandt und über dieses Attribut hinweg aggregiert wirdAndernfalls liefert GROUPING 0
Falls Gesamtsumme nicht zurück geliefert werden soll:
HAVING NOT(GROUPING(Prodfamilie) = 1AND GROUPING(Region) = 1AND GROUPING(Jahr) = 1)
78©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 CUBE-Operator(4): Pivotierung / Rotation (zur Erinnerung)
Produkt
Zei
tGeo
graphi
e
Zeit
Geo
gra
ph
iePro
dukt
Geographie
Pro
du
ktZei
t
Zeit
Pro
du
ktGeo
graphi
e
Produkt
Geo
gra
ph
ieZei
t
Geographie
Zei
tPro
dukt

40
79©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 CUBE-Operator (5)
806258291257SUMME
403137127139SUMME
1605142672004
1213734502003
1224951222002Hessen
403121164118SUMME
1755166582004
1705567482003
581531122002Bayern
SUMMETVAudioVideoVerkäufe
335102108125SUMME
SUMME
2004
2003
2002
Verkäufe
Hessen
Bayern
SUMME
Hessen
Bayern
SUMME
Hessen
Bayern
806258291257
160514267
175516658
2919210198
121373450
170556748
180648234
122495122
58153112
SUMMETVAudioVideo
mit 2 unterschiedlichen Pivotierungen
80©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 CUBE-Operator(6): Roll-Up (SQL99)
SELECT
Prodkategorie, Prodfamilie, Region, Land,
SUM(Verkäufe) AS VerkäufeFROM…
WHERE…GROUP BY
ROLLUP(Produktkategorie, Prodfamilie), ROLLUP(Land, Region)
Erzeugt: (Prodkategorie, Prodfamilie) kreuz (Land, Region)(Prodkategorie) (Land)() ()
zuerst dann
Bei 4 Gruppierungsattribute– Cube-Operator: 24 = 16 unterschiedl. Gruppierungen– Rollup-Operator: 3*3 = 9 unterschiedl. Gruppierungen
Rollup in dieser Dimension in folgenden Schritten:
d.h. A1, …, An-1, An
A1, …, An-1
…
A1
()

41
81©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 GROUPING Sets
Komplexeste Art der Gruppierung (in SQL:99)Argumente können selbst wieder Gruppierungen sein, außer GroupingSets.Beispiel:SELECT ... SUM(Verkäufe) AS Verkäufe
FROM ...
GROUP BY
ROLLUP(Produktkategorie, Produktfamilie) (1)GROUPING SETS((STADT),(REGION)), (2)GROUPING SETS(ROLLUP(Jahr, Quartal, Monat),(Woche)) (3)
Bedeutung:(1) entlang der Klassifikationshierarchie(2) nur für Städte und Regionen(3) Nutzung der Parallelhierarchie (Jahr Quartal Monat) und Woche
82©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Probleme der relationalen Speicherung
Multidimensionale Struktur muss in eine oder mehrere „flache“relationale Tabellen gepresst werden.Transformation multidimensionaler Anfragen in relationale Repräsentation notwendig komplexe Anfragen
Einsatz komplexer Anfragewerkzeuge notwendig (OLAP-Werkzeuge)
Semantikverlust
daher: direkte multidimensionale Speicherung ?

42
83©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Multidimensionale Speicherung (1)
Verwendung unterschiedlicher Datenstrukturen für Datenwürfel und Dimensionen
Dimension:endliche, geordnete Liste von Dimensionswerten
Ordnung der Dimensionswerte
Würfel:Für n Dimensionen: n-dimensionaler Raum
m Dimensionswerte einer Dimension: Aufteilung des Würfels in m parallele EbenenZelle eines n-dimensionalen Würfels wird eindeutig über n-Tupel von Dimensionswerten identifiziert
Zelle kann ein oder mehrere Kennzahlen eines zuvor definierten Datentyps aufnehmenWir als Array gespeichert
häufig proprietäre Strukturen (und Systeme)
84©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Multidimensionale Speicherung (2)
Klassifikationsstufen:Wichtig: Knoten der höheren Stufen bilden weitere Ebenen
Ulm
Stuttgart
Baden-Württemberg
München
Bayern
Januar Februar
März 1. Quartal
Umsatz in Stuttgart im 1. Quartal
Umsatz in Baden-Württemberg im
Januar

43
85©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Multidimensionale Speicherung (3)
Vergleich Aggegration zur Laufzeit versus VorberechnungLaufzeit:
Berechnung aus Detaildatenhohe Aktualität, jedoch hoher Aufwandeventuell Caching
Vorberechnung:Berechnung und Eintragen der Aggregationswerte in entsprechende ZellenNeuberechnung nach jeder Datenübernahme notwendighohe Anfragegeschwindigkeit, jedoch Zunahme der Würfelgröße und Laufzeitaufwand
86©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Multidimensionale Speicherung (4)
Weitere DatenstrukturenVirtueller Würfel
Ergibt sich aus bestehenden Würfeln durch die Anwendung von Berechnungsfunktionen (z.B. Gewinn)
Teilwürfel (Kombination mehrerer Ebenen eines Würfels virtuell)Attribute
Merkmale einer Dimension Untermengen von Dimensionswerten können über Attribute identifiziert werden (z.B. „Produktfarbe“)

44
3.4 Multidimensionale Speicherung (5)
Speicherung des Würfels als n-dimensionales Array hierzu Linearisierung in eine eindimensionale Liste ( Kapitel 6, multidimensionale Indexstrukturen)
Indizes des Arrays ≡ Koordinaten der Würfelzellen (Dimensionen Di)Indexberechnung für Zelle mit Koordinaten x1, …, xn
Index(z) = x1 + (x2 – 1) * |D1|
+ (x2 – 1) * |D1| * |D2| + …+ (xn – 1 ) * |D1| * … * |Dn-1|
Linearisierungsreihenfolge:D3
D1
D2
2019181716
1514131211
109876
54321
Hos
en (1
)H
emde
n (2
)R
öcke
(3)
Kle
ider
(4)
Män
tel (
5)
Januar (1)
Februar (2)
März (3)
April (4)
88©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Multidimensionale Speicherung (6)
Probleme bei der multidimensionalen Speicherung:ungünstige Linearisierungsreihenfolgen können zu schlechtem Anfrageverhalten führen!
Eventuell Abhilfe durch Caching
Skalierbarkeitsprobleme aufgrund dünn besetzter Datenräumeteilweise einseitige Optimierung bezüglich LeseoperationenReorganisation nach Änderungen an den Dimensionen kann aufwendig werden (da Dimensionswerte geordnet)
keine Standard für multidimensionale DBMS ( Spezialwissen notwendig)

45
89©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.4 Multidimensionale Speicherung (7)
Vergleich von multidimensionaler und relationaler SpeicherungWelche Faktoren spielen eine Rolle?
Relational (Star-Schema)ArraySpeicherungFaktoren
90©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Kapitel 3: Überblick
3.1 Data-Warehouse-Designprozess3.2 Konzeptuelle Datenmodellierung
3.3 Formalisierung und Analyseoperationen
3.4 Umsetzung des multidimensionalen Datenmodells
3.5 Zusammenfassung

46
91©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
3.5 Zusammenfassung
Konzeptuelle Modellierung der Daten:Multidimensionale Erweiterungen vonEntity/Relationship-Modell (mE/R)
UML (mUML)Weitere Ansätze (z.B. graphbasiert)
Umsetzung der konzeptuellen Modellierung:Relational (ROLAP): Snowflake-Schema, Star-SchemaMultidimensional (MOLAP)
Hybrid (HOLAP): Kombination aus ROLAP und MOLAP
92©Stefanie Rinderle-Ma, Institut DBIS, Universität Ulm, WS 2008/09 – Kap. 3
Referenzen
[HLV00] Bodo Hüsemann, Jens Lechtenbörger, Gottfried Vossen: Conceptual Data Warehouse Design, In Proc. Int‘l Workshop on Design and Management of Data Warehouses, pp. 3–9 (2000)