
1© Cloudera, Inc. All rights reserved.
Why Apache Spark is the Heir to MapReduce in the Apache Hadoop Ecosystem
2© Cloudera, Inc. All rights reserved.
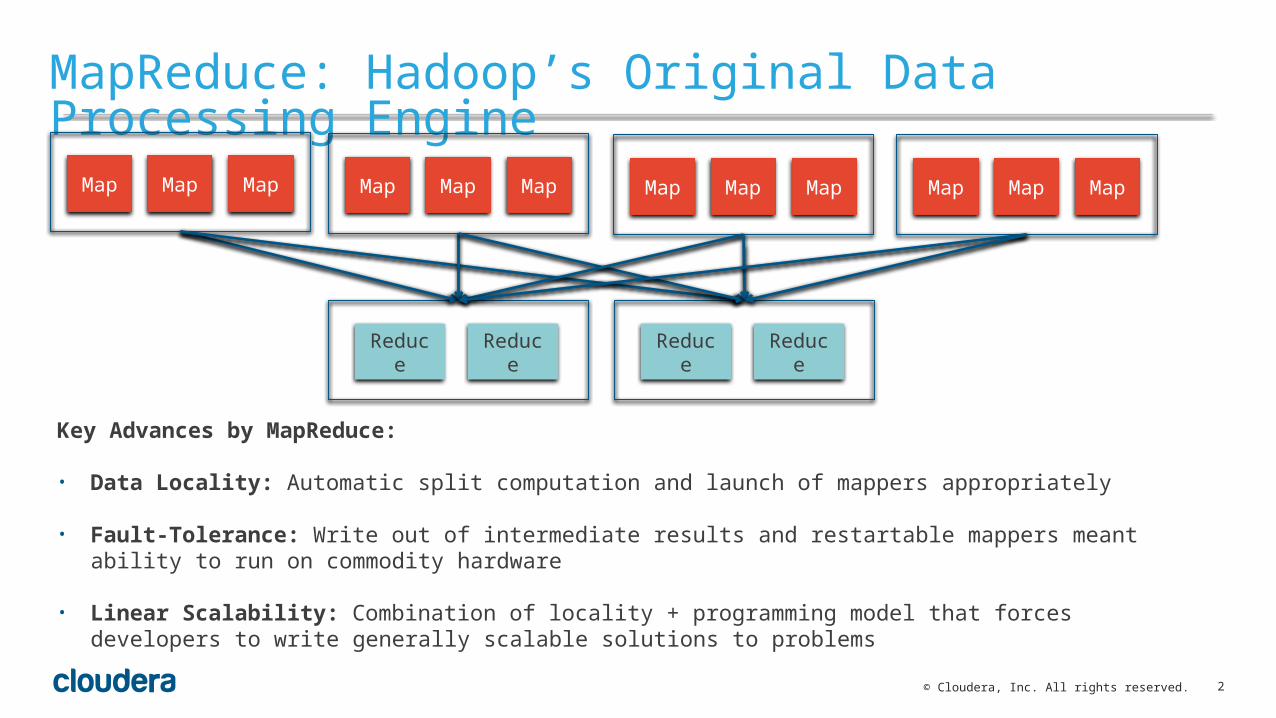
Key Advances by MapReduce:
• Data Locality: Automatic split computation and launch of mappers appropriately
• Fault-Tolerance: Write out of intermediate results and restartable mappers meant ability to run on commodity hardware
• Linear Scalability: Combination of locality + programming model that forces developers to write generally scalable solutions to problems
MapReduce: Hadoop’s Original Data Processing Engine
Map Map Map Map Map Map Map Map Map Map Map Map
Reduce Reduce Reduce Reduce

3© Cloudera, Inc. All rights reserved.
MR was sufficient for many use cases, but a bit like Haiku in its expressiveness:
A very rigid framework;Diverse, powerful.
MapReduce Did Its Original Job Well, But…
MapReduce
Hive Pig Mahout Crunch Solr

4© Cloudera, Inc. All rights reserved.
Better Developer Productivity
Rich APIs for Scala, Java, and Python
Interactive shell
We Can Do Better with Apache Spark
Better Performance
General execution graphs
In-memory storage

5© Cloudera, Inc. All rights reserved.
• Native support for multiple languages with identical APIs
• Use of closures, iterations, and other common language constructs to minimize code
• Unified API for batch and streaming
High-Productivity Language Support
Pythonlines = sc.textFile(...)lines.filter(lambda s: “ERROR” in s).count()
Scalaval lines = sc.textFile(...)lines.filter(s => s.contains(“ERROR”)).count()
JavaJavaRDD<String> lines = sc.textFile(...);lines.filter(new Function<String, Boolean>() { Boolean call(String s) { return s.contains(“error”); }}).count();
6© Cloudera, Inc. All rights reserved.
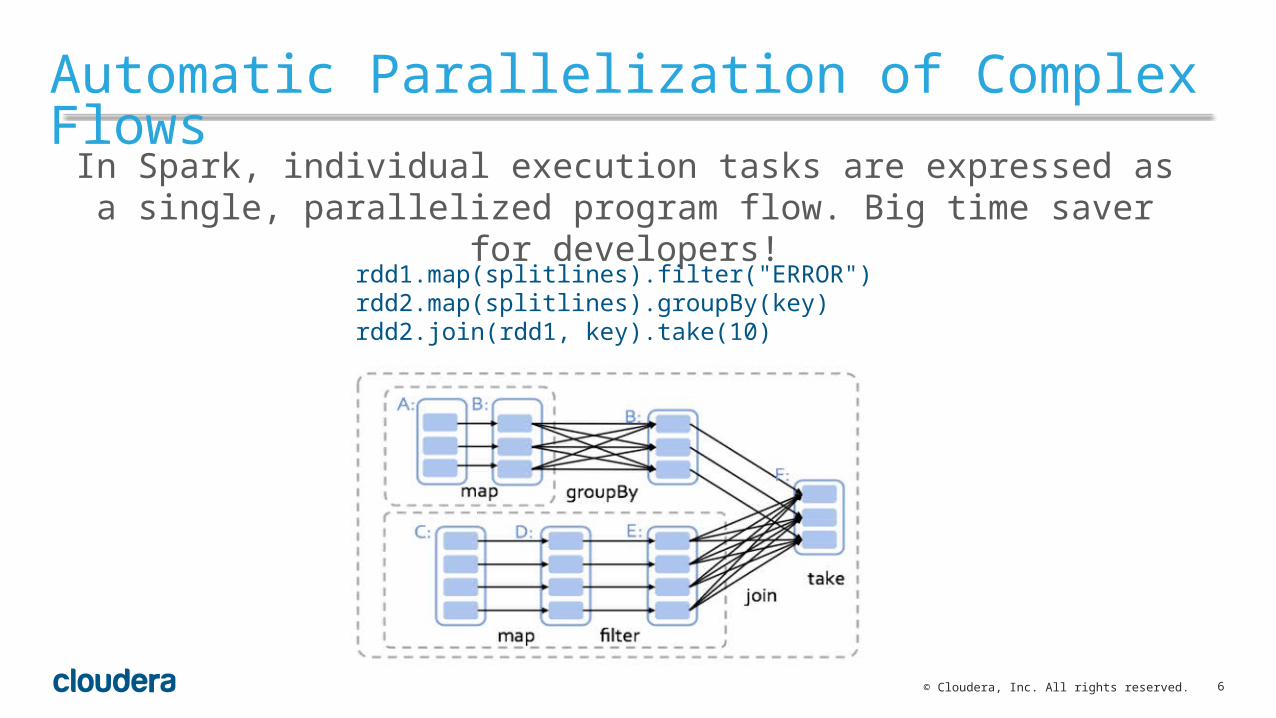
In Spark, individual execution tasks are expressed as a single, parallelized program flow. Big time saver for developers!
Automatic Parallelization of Complex Flows
rdd1.map(splitlines).filter("ERROR")rdd2.map(splitlines).groupBy(key)rdd2.join(rdd1, key).take(10)

7© Cloudera, Inc. All rights reserved.
Run continuous processing of data using Spark’s core API.
Example use cases:• “On-the-fly” ETL as data is ingested into Hadoop/HDFS• Detecting anomalous behavior and triggering alerts• Continuous reporting of summary metrics for incoming data
Integrated Streaming
8© Cloudera, Inc. All rights reserved.
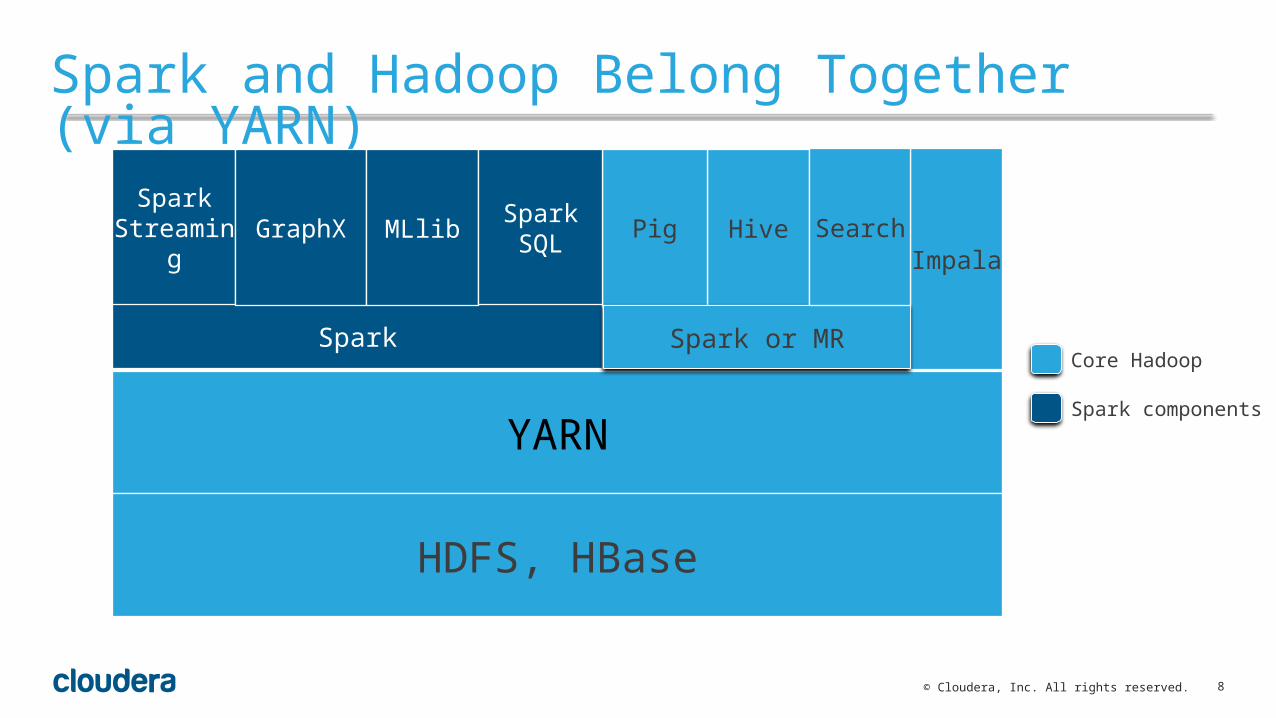
Spark and Hadoop Belong Together (via YARN)
YARN
Spark
SparkStreaming GraphX MLlib
HDFS, HBase
HivePigImpala
Spark or MR
Spark SQL Search
Core Hadoop
Spark components
9© Cloudera, Inc. All rights reserved.
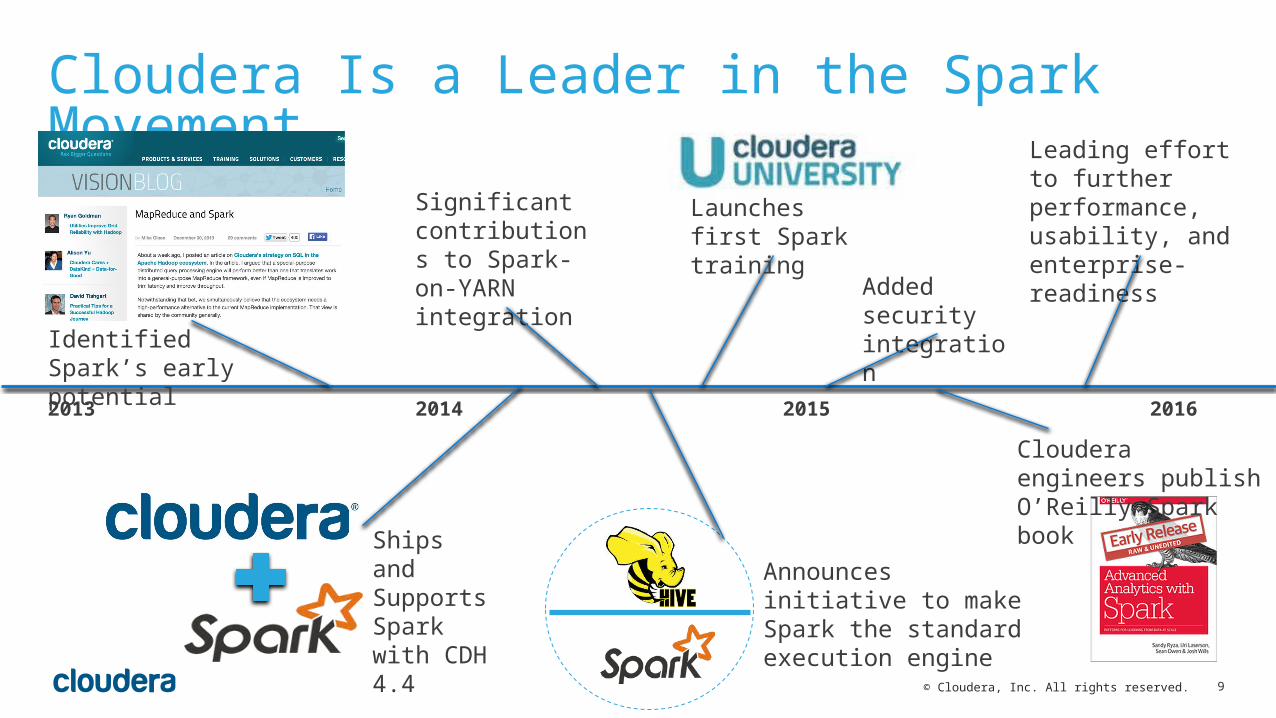
Cloudera Is a Leader in the Spark Movement
2013 2014 2015 2016
Identified Spark’s early potential
Ships and Supports Spark with CDH 4.4
Significant contributions to Spark-on-YARN integration
Announces initiative to make Spark the standard execution engine
Launches first Spark training
Added security integration
Cloudera engineers publish O’Reilly Spark book
Leading effort to further performance, usability, and enterprise-readiness

10© Cloudera, Inc. All rights reserved.
Spark is Replacing MapReduce as the Open Standard
With help from Cloudera’s Apache committers, ecosystem communities are complementing MapReduce with Spark as their execution engine/making Spark
the default:
Hive Pig Mahout Crunch Solr

11© Cloudera, Inc. All rights reserved.
Cloudera & Intel: Joint Roadmap for Spark Cloudera and Intel engineers are major contributors to Spark, working alongside those of DataBricks and the rest of the global Apache community to help build the platform.
• 23 total engineers working on Spark (including 5 committers)• Cloudera: 8 (4 committers)
• Intel: 15 (1 committer)
• 900+ patches contributed to date
12© Cloudera, Inc. All rights reserved.
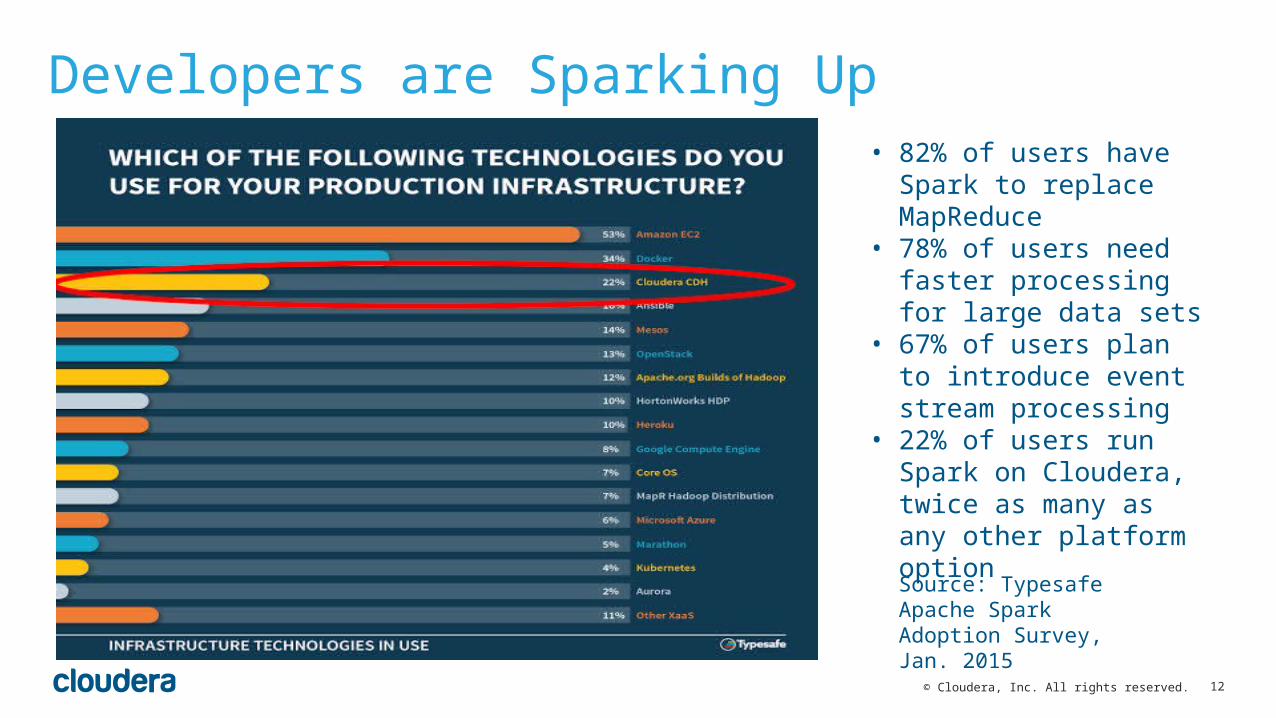
Developers are Sparking Up
Source: Typesafe Apache Spark Adoption Survey, Jan. 2015
• 82% of users have Spark to replace MapReduce
• 78% of users need faster processing for large data sets
• 67% of users plan to introduce event stream processing
• 22% of users run Spark on Cloudera, twice as many as any other platform option
13© Cloudera, Inc. All rights reserved.
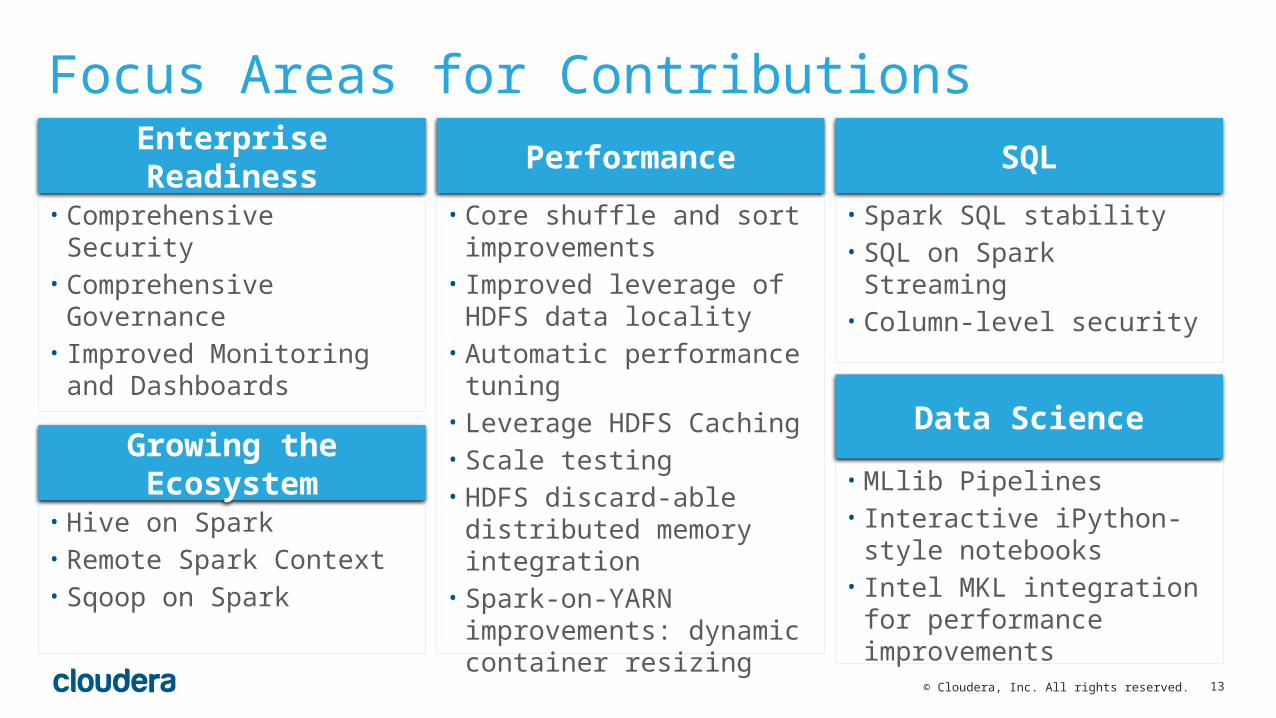
Focus Areas for ContributionsEnterprise Readiness Performance SQL
• Comprehensive Security• Comprehensive Governance• Improved Monitoring and
Dashboards
• Core shuffle and sort improvements
• Improved leverage of HDFS data locality
• Automatic performance tuning• Leverage HDFS Caching• Scale testing • HDFS discard-able distributed
memory integration• Spark-on-YARN improvements:
dynamic container resizing
• Spark SQL stability• SQL on Spark Streaming• Column-level security
Growing the Ecosystem
• Hive on Spark• Remote Spark Context• Sqoop on Spark
Data Science
• MLlib Pipelines• Interactive iPython-style
notebooks• Intel MKL integration for
performance improvements

14© Cloudera, Inc. All rights reserved.
Get Educated About Spark at cloudera.com/spark
Read the Spark book byCloudera’s committers
Get Spark trainingGet hands-on with Spark and Hadoop on AWS

15© Cloudera, Inc. All rights reserved.
Thank You
cloudera.com/spark







