Download - Stats 330: Lecture 19

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 1
Stats 330: Lecture 19

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 2
Plan of the day
In today’s lecture , we look at some general strategies for choosing models having lots of continuous and categorical explanatory variables, and discuss an example.

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 3
General Principle
• For a problem with both continuous and categorical explanatory variables, the most general model is to fit separate regressions for each possible combination of the factor levels.
• That is, we allow the categorical variables to interact with each other and the continuous variables.

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 4
Illustration• Two factors A and B, two continuous
explanatory variables X and Z• General model is y ~ A*B*X + A*B*Z• Suppose A has a levels and B has b levels, so
there are a b factor level combinations• Each combination has a separate regression
with 3 parameters– Constant term– Coefficient of X– Coefficient of Z

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 5
Illustration (Cont)
• There are a b constant terms, we can arrange them in a table
• Can split the table up into main effects and interactions as in 2 way anova
• Listed in output as Intercept, A, B and A:B

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 6
Illustration (Cont)• There are a b X-coefficients, we can
also arrange them in a table
• Again, we can split the table up into main effects and interactions as in 2 way anova
• Listed in output as X, A:X, B:X and A:B:X
• Ditto for Z
• If all the A:X, B:X, A:B:X interactions are zero, coefficient of X is the same for all the a b regressions

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 7
Model selection
• In these situations, the number of possible models is large
• Need variable selection techniques– Anova– stepwise
• Don’t include high order interactions unless you include lower order interactions

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 8
Caution
• Sometimes we don’t have enough data to fit a separate regression to each factor level combination (need at least one more data point than number of continuous variables per combination)
• In this case we drop out the higher level interactions, forcing coefficients to have common values.

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 9
Example: Risk factors for low birthweight
These data were collected at Baystate Medical Center, Springfield, Mass. during 1986, as part of a study to identify risk factors for low-birthweight babies.
The response variable was birthweight, and data was collected on a variety of continuous and categorical explanatory variables

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 10
Variables age : mother's age in years, continuous
lwt: mother's weight in pounds, continuous
race: mother's race (`1' = white, `2' = black, `3' = other), factor
smoke: smoking during pregnancy ( 1 =smoked, 0=didn’t smoke), factor
ht: history of hypertension (0=No, 1=Yes), factor
ui: presence of uterine irritability (0=No, 1=Yes), factor
bwt: birth weight in grams, continuous, response
Must be a
factor!!

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 11
Preliminary plots
100 150 200 250
10
00
20
00
30
00
40
00
50
00
Mothers weight (lbs)
Ba
by'
s w
eig
ht (
gm
)
0 1
1000
2000
3000
4000
5000
UI
Bab
y's
wei
ght
(gm
)
0 1
1000
2000
3000
4000
5000
Smoking
Bab
y's
wei
ght
(gm
)
0 1
1000
2000
3000
4000
5000
Hypertension
Bab
y's
wei
ght
(gm
)
1 2 3
1000
2000
3000
4000
5000
Race
Bab
y's
wei
ght
(gm
)

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 12
Plotting conclusions
some relationships between bwt and the covariates
–Slight relationship with lwt–Small effects due to the categorical
variables
On to fitting models……

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 13
Factor level combinations
• There are 2 continuous explanatory variables, and 4 categorical explanatory variables, race (3 levels), smoke (2 levels) ht (2 levels) and ui (2 levels). There are 3x2x2x2=24 factor level combinations.
• 24 regressions in all !!

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 14
Models• The most general model would fit separate
regression surfaces to each of the 24 combinations
• Assuming planes are appropriate, this means 24 x 3 = 72 parameters. There are 189 observations, so this is rather a lot of parameters. (usually we want at least 5 observations per parameter). In fact not all factor level combinations have enough data to fit a plane (need at least 3 points)
• The model fitting separate planes to each combination isbwt ~ age*race*smoke*ht*ui + lwt*race*smoke*ht*ui

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 15
Fitting• Can fit the model and use the anova
function to reduce number of variables> births.lm<-lm(bwt~age*race*smoke*ui*ht
+lwt*race*smoke*ui*ht, data=births.df)
> anova(births.lm)
• Also use the stepwise function with the forward option> null.lm<-lm(bwt~1,data=births.df) > step(null.lm, formula(births.lm), direction="forward")

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 16
Results: anovaAnalysis of Variance Table Df Sum Sq Mean Sq F value Pr(>F) age 1 806927 806927 2.0610 0.153251 race 2 4456772 2228386 5.6916 0.004167 ** smoke 1 7098861 7098861 18.1314 3.674e-05 ***ui 1 6513795 6513795 16.6370 7.414e-05 ***ht 1 2458238 2458238 6.2786 0.013317 * lwt 1 2779537 2779537 7.0993 0.008579 ** age:race 2 368694 184347 0.4708 0.625420 age:smoke 1 2220991 2220991 5.6727 0.018520 * race:smoke 2 1085210 542605 1.3859 0.253374 age:ui 1 187617 187617 0.4792 0.489886 race:ui 2 774013 387006 0.9885 0.374625 smoke:ui 1 43060 43060 0.1100 0.740641 age:ht 1 1573461 1573461 4.0188 0.046844 * race:ht 2 318415 159207 0.4066 0.666639 smoke:ht 1 115215 115215 0.2943 0.588322 race:lwt 2 1008962 504481 1.2885 0.278798 smoke:lwt 1 86923 86923 0.2220 0.638215

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 17
Results: anova (cont)Analysis of Variance Table Df Sum Sq Mean Sq F value Pr(>F)
ui:lwt 1 196810 196810 0.5027 0.479457 ht:lwt 1 1145508 1145508 2.9258 0.089300 . age:race:smoke 2 1063946 531973 1.3587 0.260218 age:race:ui 2 108742 54371 0.1389 0.870455 age:smoke:ui 1 533 533 0.0014 0.970632 race:smoke:ui 1 617235 617235 1.5765 0.211272 age:race:ht 2 1220320 610160 1.5584 0.213948 age:smoke:ht 1 406773 406773 1.0389 0.309752 race:smoke:lwt 2 1052747 526373 1.3444 0.263898 race:ui:lwt 2 786735 393367 1.0047 0.368668 smoke:ui:lwt 1 1128102 1128102 2.8813 0.091744 . race:ht:lwt 1 435519 435519 1.1124 0.293310 age:race:smoke:ui 1 2544108 2544108 6.4980 0.011832 * race:smoke:ui:lwt 1 150811 150811 0.3852 0.535806 Residuals 146 57162471 391524

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 18
Results: stepwise (forward/both)
Step: AIC= 2451.34 bwt ~ ui + race + smoke + ht + lwt + ht:lwt + race:smoke
Df Sum of Sq RSS AIC<none> 73000256 2451- race:smoke 2 1657370 74657625 2452+ ui:lwt 1 304152 72696104 2453+ smoke:ht 1 168685 72831571 2453- ht:lwt 1 1397486 74397742 2453+ age 1 149901 72850355 2453+ smoke:lwt 1 11843 72988412 2453+ race:ht 2 497275 72502981 2454+ race:lwt 2 441336 72558920 2454- ui 1 6968046 79968302 2467

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 19
Comparisons
• 3 models to compare– Full model– Model indicated by anova (model 2)
bwt ~ age +ui + race + smoke + ht + lwt + age:ht + age:smoke,
– Model chosen by stepwise (model 3) bwt ~ ui + race + smoke + ht + lwt + ht:lwt + race:smoke,
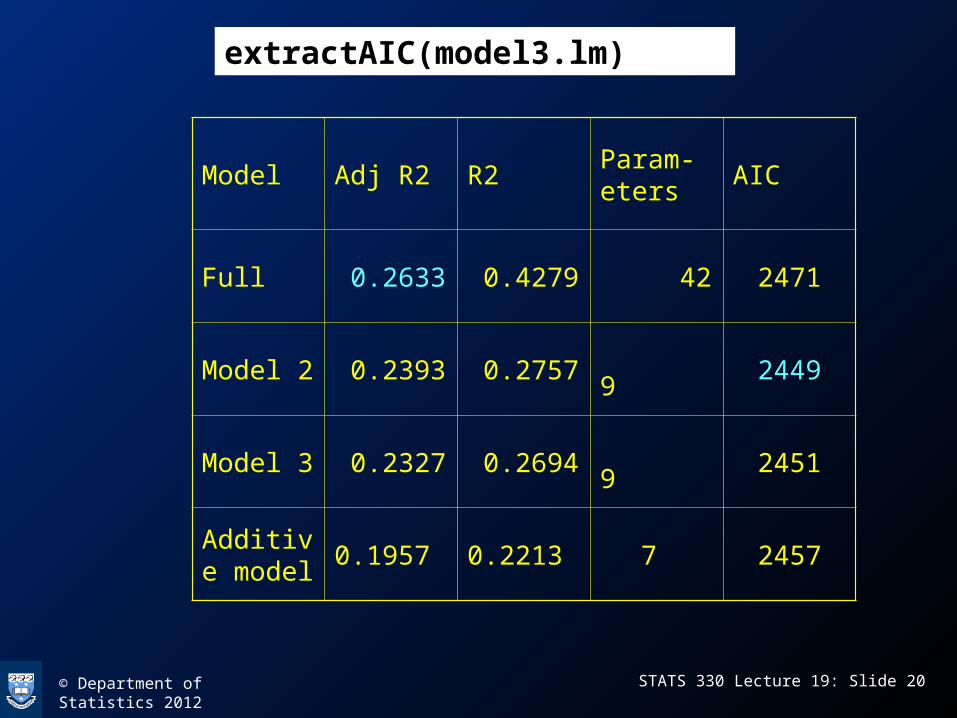
© Department of Statistics 2012 STATS 330 Lecture 19: Slide 20
Model Adj R2 R2Param-eters
AIC
Full 0.2633 0.4279 42 2471
Model 2 0.2393 0.2757 9 2449
Model 3 0.2327 0.2694 9 2451
Additive model
0.1957 0.2213 7 2457
extractAIC(model3.lm)

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 21
Deleting?
• Point 133 seems influential – big Cov ratio, HMD
• Refitting without 133 now makes model 3 the best – will go with model 3
• Could also just use a purely additive model (i.e parallel planes) - but adjusted R2 and AIC are slightly worse.

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 22
Summary Model 3
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3158.801 267.867 11.792 < 2e-16 ***ui1 -548.459 133.567 -4.106 6.12e-05 ***race2 -561.784 187.680 -2.993 0.003152 ** race3 -500.440 133.004 -3.763 0.000228 ***smoke1 -529.973 133.865 -3.959 0.000109 ***ht1 -1978.134 711.642 -2.780 0.006026 ** lwt 2.426 1.788 1.357 0.176520 ht1:lwt 10.236 4.535 2.257 0.025217 * race2:smoke1 255.066 300.258 0.849 0.396750 race3:smoke1 510.755 244.031 2.093 0.037768 *

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 23
Interpretation (cont)Other things being equal:• Uterine irritability associated with lower birthweight• Smoking associated with lower birthweight, but
differently for different races• Hypertension associated with lower birthweight• Race associated with lower birthweight
– Black lower than white– “Other” lower than white
• Higher mother’s weight associated with higher birthweight, for hypertension group
• Smoking lowers birthweight more for race 1 (white).• These effects significant but small compared to
variability.

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 24
Interpretation of interactions
White Black Other
Smoke No 0 -561 -500
Smoke Yes -530 -836 -580
-836 = -530 -561 + 255

© Department of Statistics 2012 STATS 330 Lecture 19: Slide 25
Diagnostics for model 2
Check for high-influence etc
1500 2000 2500 3000 3500
-200
0-1
000
010
00
Fitted values
Res
idua
ls
Residuals vs Fitted
132
136138
-3 -2 -1 0 1 2 3
-3-2
-10
12
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
Normal Q-Q plot
132
136138
1500 2000 2500 3000 3500
0.0
0.5
1.0
1.5
Fitted values
Sta
ndar
dize
d re
sidu
als
Scale-Location plot132
136138
0 50 100 150
0.00
0.02
0.04
0.06
0.08
0.10
Obs. number
Coo
k's
dist
ance
Cook's distance plot
130
132106
Point 133 !!







