
Pa#ern Recogni-on and Applica-ons Lab
University
of Cagliari, Italy
Department of Electrical and Electronic
Engineering
Sparse Support Faces
Ba#sta Biggio, Marco Melis, Giorgio Fumera, Fabio Roli
Dept. Of Electrical and Electronic Engineering University of Cagliari, Italy
Phuket, Thailand, May 19-‐22, 2015 ICB 2015
http://pralab.diee.unica.it
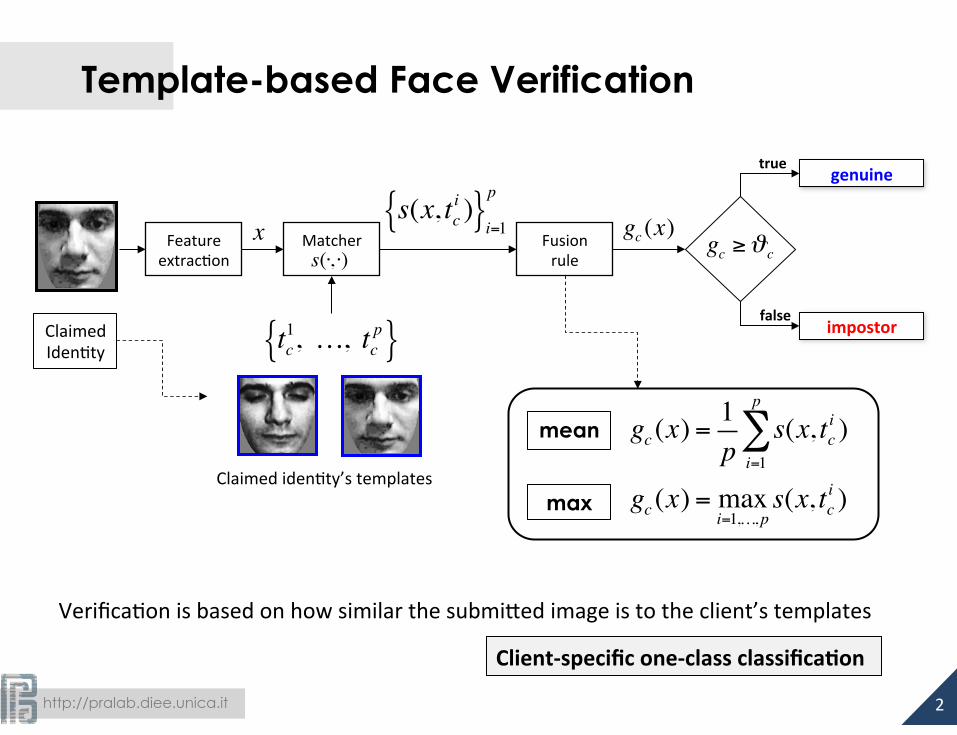
Template-based Face Verification
2
gc ≥ϑ c
genuine
impostor
true
false
s(x, tci ){ }i=1
p
Matcher s(⋅, ⋅)
Fusion rule
gc (x)xFeature extrac-on
Verifica-on is based on how similar the submi#ed image is to the client’s templates
Client-‐specific one-‐class classifica:on
mean gc (x) =1p
s(x, tci )
i=1
p
∑
gc (x) = maxi=1,…,ps(x, tc
i )max
Claimed Iden-ty tc
1, …, tcp{ }
Claimed iden-ty’s templates
http://pralab.diee.unica.it
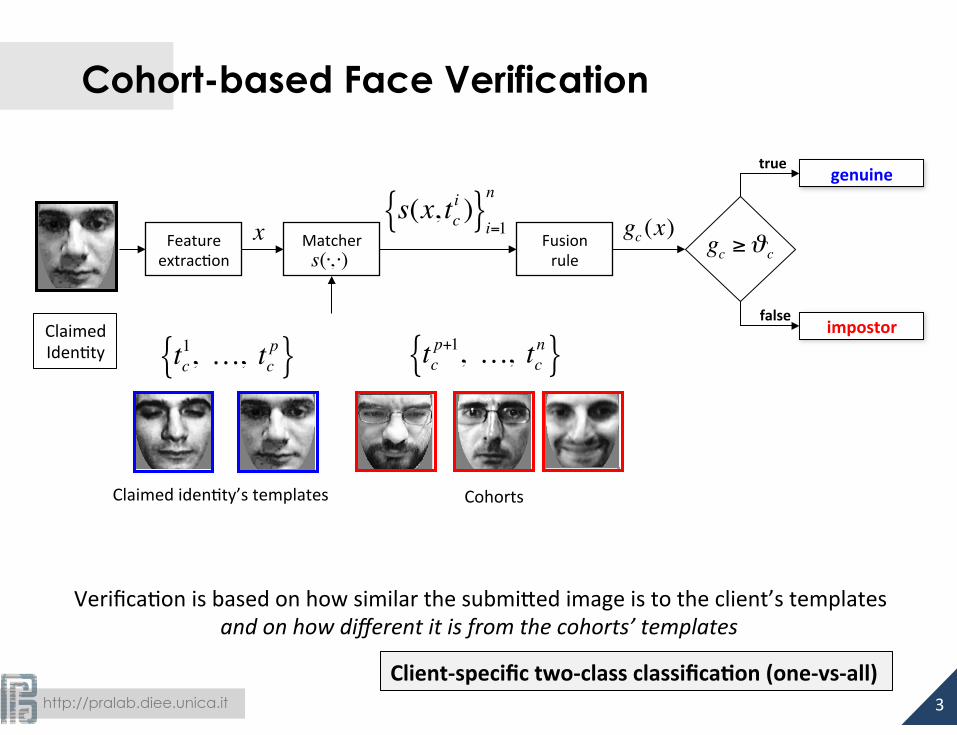
Cohort-based Face Verification
3
Verifica-on is based on how similar the submi#ed image is to the client’s templates and on how different it is from the cohorts’ templates
Client-‐specific two-‐class classifica:on (one-‐vs-‐all)
gc ≥ϑ c
genuine
impostor
true
false
s(x, tci ){ }i=1
n
Matcher s(⋅, ⋅)
Fusion rule
gc (x)xFeature extrac-on
tc1, …, tc
p{ }
Claimed iden-ty’s templates Cohorts
tcp+1, …, tc
n{ }Claimed Iden-ty

http://pralab.diee.unica.it
Cohort-based Fusion Rules
• Cohort selection is heuristically driven – e.g., selection of the closest cohorts to the client’s templates
• Cohort-based fusion rules are also based on heuristics
– Test-normalization [Auckenthaler et al., DSP 2000]
– Aggarwal’s max rule [Aggarwal et al., CVPR-W 2006]
4
gc (x) =1
σ c (x)1p
s(x, tci )
i=1
p
∑ −µc (x)#
$%
&
'(
gc (x) =maxi=1,…,p
s(x, tci )
maxj=p+1,…,n
s(x, tcj )

http://pralab.diee.unica.it
Open Issues
• Fusion rules and cohort selection are based on heuristics – No guarantees of optimality in terms of verification error
• Our goal: to design a procedure to optimally select the reference templates and the fusion rule – Optimal in the sense that it minimizes verification error (FRR and FAR)
• Underlying idea: to consider face verification as a two-class classification problem in similarity space
5

http://pralab.diee.unica.it
s(x, )
s(x, )
Face Verification in Similarity Space
• The matching function maps faces onto a similarity space – How to design an optimal decision function in this space?
6
?

http://pralab.diee.unica.it
Support Face Machines (SFMs)
• We learn a two-class SVM for each client – using the matching score as the kernel function – genuine client y=+1, impostors y=-1
• SVM minimizes the classification error (optimal in that sense) – FRR and FAR in our case
• The fusion rule is a linear combination of matching scores • The templates are automatically selected for each client
– support vectors à support faces
7
gc (x) = αis(x, tci )
i∑ − α js(x, tcj )
j∑ + b

http://pralab.diee.unica.it
Support Face Machines (SFMs)
8
s(x, )
s(x, )
• Maximum-margin classifiers
gc (x) = αis(x, tci )
i∑ − α js(x, tcj )
j∑ + b

http://pralab.diee.unica.it
Sparse Support Faces
• Open issue: SFMs require too many support faces – Number of support faces scales linearly with training set size
• Our goal: to learn a much sparser combination of match scores
• by jointly optimizing the weighting coefficients and support faces:
9
hc (x) = βis(x, zck )+ b
k=1
m
∑ , m << n
minβ ,z
Ω β, z( ) = 1n
uk gc (xk )− hc (xk )( )2+λβTβ
i=1
n
∑

http://pralab.diee.unica.it
z-‐step
Sparse Support Faces
10
SFM with 12 support faces
−5 0 5−5
0
5
−5
0
5SSFM with 4 virtual faces
−5 0 5−5
0
5
−5
0
5
β-‐step
Solu:on algorithm is an itera-ve two-‐step procedure:
If s(x,z) is not differentiable or analytically given, gradient can be approximated
http://pralab.diee.unica.it
0.5 1 2 5 100
5
10
15
20 AT&T − RBF Kernel
FAR (%)
FR
R (
%)
mean (5)max (5)t−norm (10)aggarwal−max (10)SFM (37.5 ± 3.8)SFM−sel (10)SFM−red (2)SSFM (2)
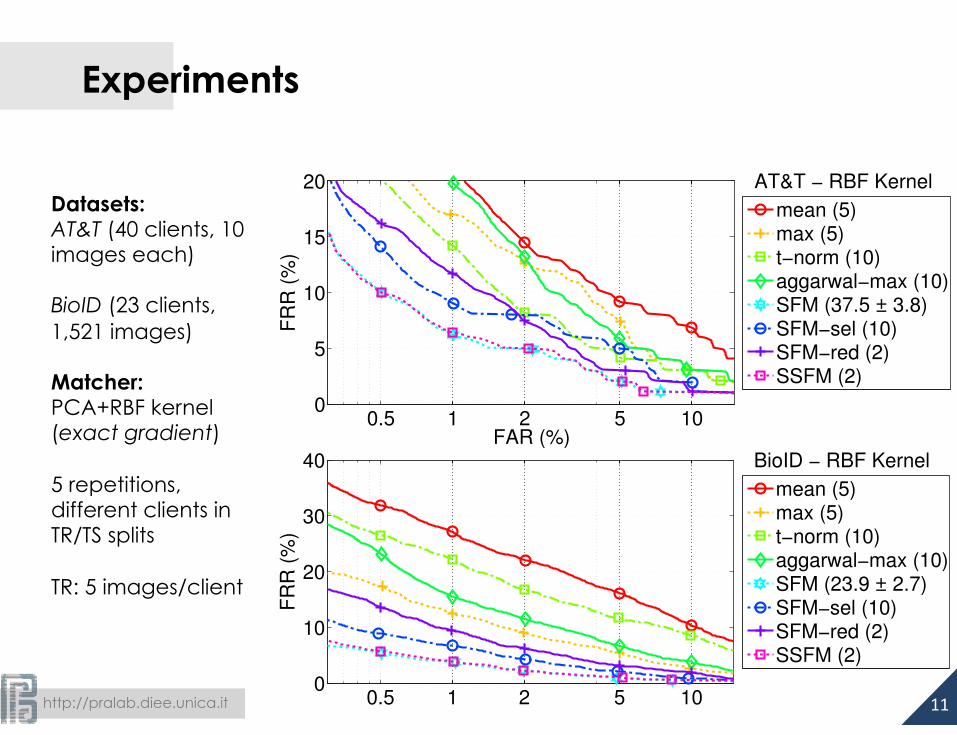
Experiments
11
Datasets: AT&T (40 clients, 10 images each) BioID (23 clients, 1,521 images) Matcher: PCA+RBF kernel (exact gradient) 5 repetitions, different clients in TR/TS splits TR: 5 images/client
0.5 1 2 5 100
10
20
30
40 BioID − RBF Kernel
FAR (%)
FR
R (
%)
mean (5)max (5)t−norm (10)aggarwal−max (10)SFM (23.9 ± 2.7)SFM−sel (10)SFM−red (2)SSFM (2)

http://pralab.diee.unica.it
Experiments
12 0.5 1 2 5 100
10
20
30
40 BioID − EBGM
FAR (%)
FR
R (
%)
mean (5)max (5)t−norm (10)aggarwal−max (10)SFM (15.0 ± 2.6)SFM−sel (5)SFM−red (5)SSFM (5)
0.5 1 2 5 100
5
10
15
20 AT&T − EBGM
FAR (%)
FR
R (
%)
mean (5)max (5)t−norm (10)aggarwal−max (10)SFM (19.5 ± 3.0)SFM−sel (5)SFM−red (5)SSFM (5)
Datasets: AT&T (40 clients, 10 images each) BioID (23 clients, 1,521 images) Matcher: EBGM (approx. gradient) 5 repetitions, different clients in TR/TS splits TR: 5 images/client

http://pralab.diee.unica.it
From Support Faces to Sparse Support Faces
• A client’s gallery of 17 support faces (and weights) reduced to 5 virtual templates by our sparse support face machine – Dataset: BioID – Matching algorithm: EBGM
13
4.040 2.854 −0.997 −3.525 −2.208

http://pralab.diee.unica.it
Conclusions and Future Research Directions
• Sparse support face machines: – reduce computational time and storing requirements during
verification without affecting verification accuracy – by jointly learning an optimal combination of matching scores, and a
corresponding sparse set of virtual support faces
• No explicit feature representation is required – Matching algorithm exploited as kernel function – Virtual templates created exploiting approximations of its gradient
• Future work – Fingerprint verification
– Identification setting • Joint reduction of virtual templates for each client-specific classifier
14
http://pralab.diee.unica.it
? Any questions Thanks for your a#en-on!
15
Code available at: http://pralab.diee.unica.it/en/SSFCodeProject







