
SeerSuite For Distributed Indexing, Federated Search and Meta Search
Pradeep Teregowda (Technical Director – CiteSeerx)
C. Lee Giles, Prasenjit Mitra, Karl Mueller
Pennsylvania State University, University Park, PA, USA

Federated Search - Motivation Variety in available information – Individual sources
incomplete:
– Example: One engine may identify the location, while another might identify its type (convention center).
Access Restrictions: Some information proprietary, some restricted due to disputes
and other issues.
Fusion of available information is necessary.
Many problems: Entity resolution and matching Disambiguation Multiple languages Ranking

Federated Search - Introduction Federated Search:
Federated Search.
Metasearch.
Challenges.
SeerSuite
Enabling Federated Search
Discussion
Summary

Federated Search
Federated Search:
Query and assemble results from multiple sources. Sources include Search Engines, Databases and
Indices. These sources can cover different areas. - Computer Science, Chemistry, Biology.
Preferred solution where multiple disciplines share sources and resources. - Libraries, cross disciplinary research. - Scitopia (Deep Web Search), SeSat, Vivisimo, etc.

Federated Search

Metasearch Metasearch
Query and assemble results from multiple sources: - Differentiation from Federated Search:
Sources are generally Search Engines. Data Source is common to all the Engines: - Example: Web.
At one time, very popular for web search.
Examples:
Dogpile. Metacrawler. Inquirus, Inquirus2.

Challenges Ranking:
How do you compare and merge results from different indices ?. - Is this comparing apples and oranges ?.
- Are the results complete ?.
Handling results: Real Time processing of Queries and Results: - Delay.
Different schema notations, map without distortion: Requires understanding of the schema, relevance to query.
Handling Queries: - Translate user queries to native formats:
Requires understanding of various special features and quirks.

SeerSuite Federated Search.
SeerSuite Features and Components.
Outline – Ingestion and Query Process.
CiteSeerx and TableSeer.
Enabling Federated Search.
Discussion.
Summary.

SeerSuite -Features and Components Open source search engine and digital library tool kit being built on search
engines and digital libraries such as CiteSeerx, ChemXSeer, ArchSeer,etc. Modular, scalable, extensible, robust design:
Extensible to other disciplines Some Integrated features:
Focused crawler - heritrix Indexer - lucene Metadata extraction Ranked results
Builds on experience with other domain engines and OS tools: The MySQL Database and InnoDB Storage Engine Lucene and Solr Apache Tomcat The Spring Framework Acegi Security ActiveMQ ActiveBPEL Open Source Engine The Apache Commons Libraries SVMlight support vector machine package CRF++ conditional random field package
Reasonable hardware requirements.

SeerSuite – Ingestion Process
Header Parser Citation Parser
XML Merge
Crawler 1 Extraction Crawl – Java/Heretrix Converter – Convert PDF to TEXT
pdfbox Header Parser – Perl/C++
SVM Citation Parser – C++
CRF XML Merge
Java
Converter

SeerSuite – Ingestion Process
Header Parser Citation Parser
XML Merge
Crawler
Database Ingestion
Index Updates
1
2 Ingestion Database Ingestion
Java - MySQL Index Updates
Java - Solr
Extraction Converter
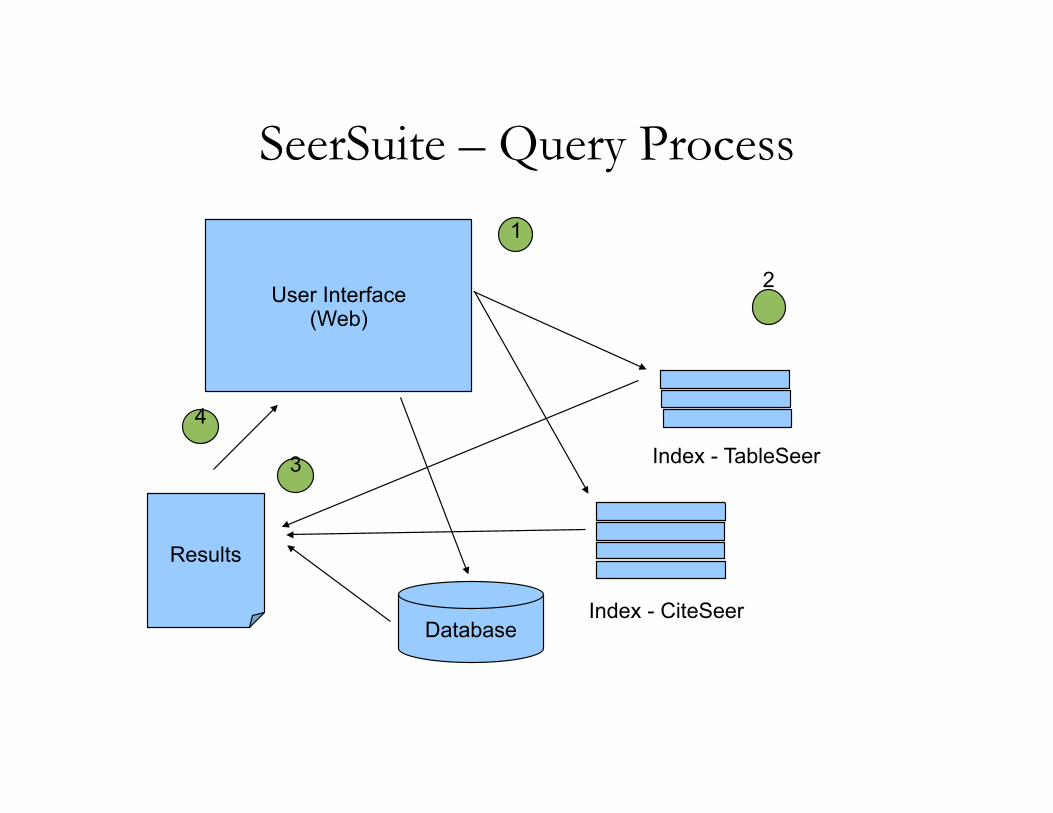
SeerSuite – Query Process
Database
Results
Index - CiteSeer
Index - TableSeer
User Interface (Web)
1
2
3
4

The Seers In various stages of the system lifecycle
Being proposed, but do not exist - CensorSeer - PhDSeer - IntelSeer
Mature and developing - CiteSeer, now CiteSeerx
Not standalone - TableSeer
Very new, future TBD - ChemXSeer - ArchSeer - PubMedSeer
Dead (could be revived) - BizSeer
Static, limping by - BotSeer

CiteSeerx
Focus on Computer Science and Information Science – related documents.
Indexes over 1.4 million documents More added every week.
27 million citations.
700 thousand tables.
3 Million hits per day, open access, global usage, open source.
Other Services: myCiteSeerX, Disambiguation, Statistics

http://citeseerx.ist.psu.edu

CiteSeerx Search
Search Entities: - Authors, Documents, Citations.
Across fields: - Most document entities like: Title, Abstract, References,
Publication Venues etc.
Ranking based on: - Relevance, Citations, Recency.
Scoring Similarity based scoring.

TableSeer

Ranking
CiteSeerx
Uses tf, idf based scoring system for queries (Solr/Lucene default query system).
Table Search
Rank tables by rating the <query, table> pairs - Avoids False Positives.
The similarity between a <table, query> pair: the cosine of the angle between vectors

Discussion Federated Search
SeerSuite
Enabling Federated Search
Discussion Ranking Discussion
Challenges - Opportunities
Search Federation.
Summary

Challenges - Opportunities
The documents in the CiteSeer repository Are indexed by both CiteSeer and TableSeer separately –
ease of management, extraction.
Same collection – TableSeer indexes sub sections of the document indexed by CiteSeer. - Matching schema's is easier.
Existing interface allows search of individual indices. Example: Search for documents in CiteSeer and Tables in
TableSeer.
Users would like to see results from both table search and document search through the same interface.

Ranking - Discussion
Federation – Ranking Challenge. Document 1 has 10 citations, 2 incoming cites
Document 2 has 3 citations, no incoming cites.

Ranking Discussion – Merging Results Ranking by the number of incoming cites
Inherit properties. - A table could inherit the ranking of the document it is embedded
in.
- Challenge: The TableSeer Index may not be aware of the citations.
Walk-through – Inheriting properties - Inherit the properties of the document – Citations, References of
the document in which the table is embedded. Affected by the Ingestion Process and updates.
- Document 1 would be ranked higher for both citation count and cited count based results.

Ranking Example Ranking independently – Merging results.
- Example: Searching for Citations in CiteSeerx. - Combine both the results in a single results page.
Avoid Duplication.
- Citations can be visualized as documents. Have authors, title, publication information. Missing abstract, text.
- Challenges: Can confuse the user. Number of Citations and Tables will be greater than the number of
documents – distortions in the results.

Federated Search an Introduction Federated Search
SeerSuite
Enabling Federated Search
Discussion
Summary Summary
Download
Q & A

Summary
Federated Search: Federated search presents an unique set of challenges - Query and Results processing from index and databases.
- Ranking: Relevance, Other Systems.
SeerSuite: – Provides a robust open source framework and structure for
building Search Engines/Digital Libraries.
An example of Federated Search in SeerSuite - CiteSeerx.

Download
SeerSuite @
http://sourceforge.net/projects/citeseerx
Free and provided under the Apache Software License v2.

Q & A

Appendix

Schema
Due to the fact that the tables are subsets of the document. Easy to map the schema's.
Merge Documents.
Example: Tables can comparatively ranked, have different. - Dimensions, headings
- Inheritance helps link the results.

Advantages of Federated Search Federated Search
Deep Web accessibility – Exploit Databases and dynamic Pages - Compared to superficial skimming (Google).
Single interface - Improve efficiency of Search
Discovery - Find new sources of information.
Access Control - Granularity of access – Control access at document/engine level.
Need not host the sources of information - Utilize multiple sources offered free (web) to provide required
access.

Distributed Indexing Why ?
Single index is too large to be effective
Reliability
How ? Split the postings: - Across keywords
- Across data sources.
Split according to functionality - Area coverage
Challenge (assuming common schema): Speed of search, ranking.

SeerSuite – Ingestion Process
Header Parser Citation Parser
XML Merge
Crawler 1
Extraction Crawl – Java/Heretrix Converter – Convert PDF to TEXT
pdfbox Header Parser – Perl/C++
SVM Citation Parser – C++
CRF XML Merge
Java
Converter
Table Extractor
Table Extraction happens independently of Citation

Sample Table Metadata Extracted File
• <Table> • <DocumentOrigin>Analyst</DocumentOrigin> • <DocumentName>b006011i.pdf</DocumentName> • <Year>2001</Year> • <DocumentTitle>Detection of chlorinated methanes by tin oxide gas sensors </DocumentTitle> • <Author>Sang Hyun Park, a ? Young-Chan Son, a Brenda R . Shaw, a Kenneth E. Creasy,* b and Steven L. Suib* acd a Department of
Chemistry, U-60, University of Connecticut, Storrs, C T 06269-3060</Author> • <TheNumOfCiters></TheNumOfCiters> • <Citers></Citers> • <TableCaption>Table 1 Temperature effect o n r esistance change ( D R ) and response timeof tin oxide thin film with 1 % C Cl 4</
TableCaption> • <TableColumnHeading>D R Temperature/ ¡ã C D R a / W ( R ,O 2 ) (%) R esponse time Reproducibiliy </TableColumnHeading> • <TableContent>100 223 5 ~ 22 min Yes 200 270 9 ~ 7-8 min Yes 300 1027 21 < 2 0 s Yes 400 993 31 ~ 1 0 s No </TableContent> • <TableFootnote> a D R =( R , CCl 4 ) - ( R ,O 2 ). </TableFootnote> • <ColumnNum>5</ColumnNum> • <TableReferenceText>In page 3, line 11, … Film responses to 1% CCl4 at different temperatures are summarized in Table 1……</
TableReferenceText> • <PageNumOfTable>3</PageNumOfTable> • <Snapshot>b006011i/b006011i_t1.jpg</Snapshot> • </Table>

SeerSuite Software Overview • Ingestion Process: Responsible for obtaining and preparing a document and the related metadata.
– Process the document • Submitted by the user or Crawler
– Extract Metadata • Header • Citations • Acknowledgements
– Store the metadata and documents. • Citation Matching
» Identifying the underlying graph structure – documents citing this document and the relationship between documents and citations
– Inference matching and graph generation – User Corrections (Version Maintenance)
» Determine and accept valid user corrections – Regular Notification Mechanisms
» Ensure that the user is notified when new documents are added to the collection • Linked to MyCiteSeer.
• Update and Maintenance – Update and make valid the full text index and various statistics. – Statistics
– Index updates







