
Русскоязычное сообщество пользователей PostgreSQL #RuPostgres http://RuPostgres.org
Вступительное слово. Что же нового в PostgreSQL 9.6?
Николай Самохваловemail: [email protected], twitter: @postgresmen
04.10.2016, Москва, офис компании «Яндекс»

Русскоязычное сообщество PostgreSQL
● Митап-группа RuPostgres.org
○ митапы в Москве и СПб
○ онлайн-митапы
○ много видео: http://bit.do/rupostgres-video
● Конференции:
○ Highload.ru (с секцией PostgreSQL!) — 7-8 ноября 2016, Москва
○ PgConf.ru — 15-17 марта 2017, Москва
○ PgDay.ru — лето 2017, Санкт-Петербург
● Общение (telegram, slack, gitter): Postgres.chat

PostgreSQL 9.6
★ Вышел 29.09.2016
★ 220 изменений в Changeloghttps://www.postgresql.org/docs/9.6/static/release-9-6.html
★ Рассказать обо всём в одном выступлении невозможно.
Нет «идеального» обзора новинок.
★ Ещё больше настроек и инструментов. Ещё сложнее стать гуру.

Источники информации
★ “Waiting for 9.6” by Hubert "depesz" Lubaczewski: http://bit.do/9-6-depesz (серия заметок, разбор pgsql-patches@ с примерами)
★ Bruce Momjian: http://bit.do/9-6-momjian-pdf (pdf, 14 стр.)http://bit.do/9-6-momjian (видео, 50 мин)
★ PostgresPro:http://bit.do/9-6-pgpro видео, 126 мин
★ Magnus Hagander:http://bit.do/9-6-hagander-pdf (pdf, 48 стр.)http://bit.do/9-6-hagander (видео, 51 мин)

Чем хорош и зачем обновляться?
1. Производительность:
- много полезных «доводок» (часть — не требуют усилий!)
- highload-улучшения (для крупных проектов)
2. Много новинок для DBA. Больше прозрачности и контроля
3. Много всего для DBD (особенно от PostgresPro)

Часть 1Производительность

Параллельные запросы
● Все обзоры начинаются с этого. Новинка-флагман!
● А по умолчанию-то не работает. И ускоряет не всегда (но часто!)
● А иногда — и замедляет (SELECT * FROM table;)
● Подходящий случай: SSD, мало клиентов, ускоряем
агрегирование
● Нужно внимательно анализировать свою ситуацию
● Есть ряд настроек:test=# select array(select name from pg_settings where name ~ 'parallel');{force_parallel_mode, max_parallel_workers_per_gather,min_parallel_relation_size,parallel_setup_cost,parallel_tuple_cost}
● При анализе удобно использовать EXPLAIN ANALYZE VERBOSE
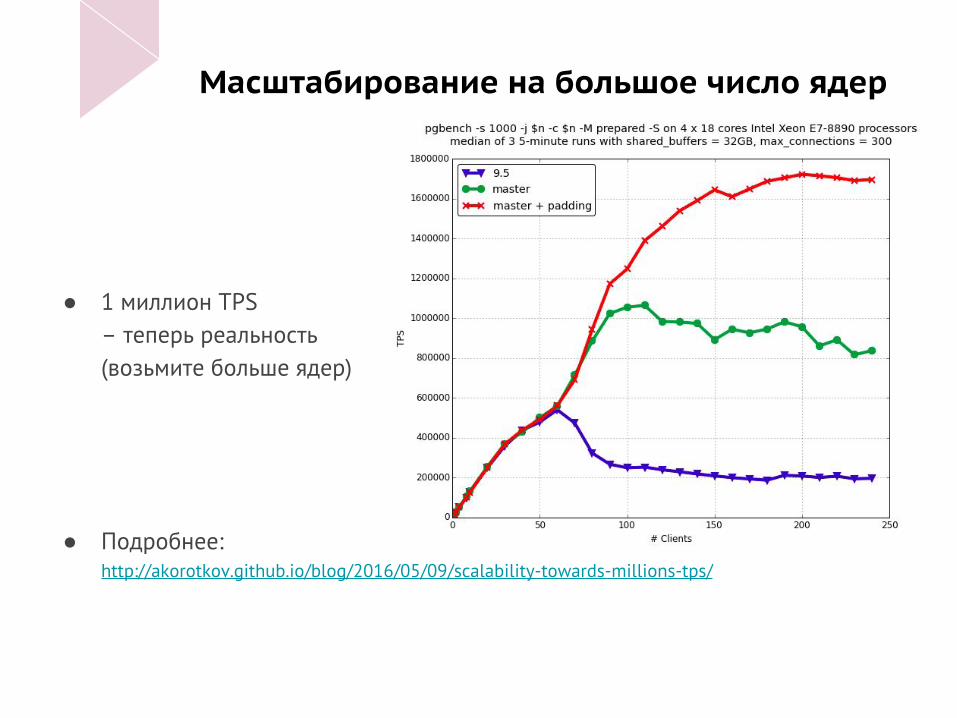
Масштабирование на большое число ядер
● 1 миллион TPS – теперь реальность(возьмите больше ядер)
● Подробнее:http://akorotkov.github.io/blog/2016/05/09/scalability-towards-millions-tps/

FDW pushdown
● Foreign Data Wrappers (FDW) – очень мощный функционал. Они пришли, чтобы остаться
● Всё новое обычно сначала появляется в postgres_fdw
● UPDATE, DELETE, JOIN, ORDER BY, как правило, теперь удалённо(приходит результат, а не сырые данные)
● Будут ещё улучшения. В других FDW тоже

Есть ещё много улучшений
● Например: VACUUM для больших таблиц работает оптимальнее
● Например: index-only scans для частичных индексов
● Например: избыточные шаги в GROUP BY игнорируются
● Например: копирование в файл таблицы из одного поля timestamp теперь в 2 раза быстрее (хех)
● Например: когда несколько агрегатных функций в одном запросе, иногда время выполнения ~ одной агрегатной функции
…и так далее. Как правило, ничего делать не надо, применится само

Часть 2Новое для DBA

idle in transation
idle_in_transaction_session_timeout = '1 min'
● Прибивается сессия (disconnect).

«Честные» синхронные реплики
synchronous_commit = 'remote_apply'
● Теперь точно на слейве не будет задержки в данных.(НО: мастер теперь должен ждать чуть дольше — на только WAL, но и его «накатывание»!)
● Полезно, если нужны кристально честные чтения на реплике

Несколько синхронных реплик● С помощью synchronous_standby_names можно гибко
управлять количеством и составом синхро-реплик
● До 9.6 можно было иметь только 1 синхро-реплику
● Может замедлить мастер
● Может совсем «остановить» мастер (при проблемах с репликами)

Много нового для мониторинга*● Мониторинг ожиданий в pg_stat_activity
● Ход работы VACUUM (pg_stat_progress_vacuum)
● Представление pg_config
… и ряд других возможностей
____________________* OKmeter, не отставай!
Новое в psql
● \ev для редактирования представлений, \sv — для вывода определения
● \crosstabview
● \gexec
● Множественные -c и -f
… но как много людей это будут использовать?(на самом деле много, #nogui)

Часть 3Новинки для DBD

Улучшения полнотекстового поиска● Поиск по фразам
$ select phraseto_tsquery('ru', 'привет, как дела?'); phraseto_tsquery ------------------------------------------- 'привет <2> 'дело' | 'привет' <2> 'деть' (1 row)
(есть некоторые накладные расходы)
● Функции для манипуляций с tsvector
● Лучше всего послушать выступления Ф. Сигаева

Это только верхушка айсбергаМного интересного у PostgresPro:
○ CREATE ACCESS METHOD○ bloom index (есть в contrib)○ RUM index (можно скачать)○ Новое в SP-GiST○ Поиск ближайших соседей для модуля cube

Следующая версия — 10.0
● Версии теперь будут ХХ.ХХ вместо Х.ХХ.ХХ (semver.org — в прошлом)
● 2ndQuadrant уже подготовили ответ на случай с Uber● Ещё больше параллелизма● Ещё больше pushdown для FDW● Партиционирование должно, наконец, улучшиться● BDR● pglogical








