
Presto As A Service トレジャーデータでの運用事例
Taro L. Saito, Treasure Data [email protected] April 24th, 2015 Presto 勉強会 @ IPROS

自己紹介 Taro L. Saito @taroleo
• 2002 東京大学 理学部 情報科学科卒 • 2007 Ph.D.
– XMLデータベース、トランザクション処理の研究
• ~ 2014 東京大学 情報生命科学専攻 助教 – ゲノムサイエンス研究
• 大規模データ処理、並列・分散コンピューティング
• 2014.3月~ Treasure Data – ソフトウェアエンジニア
MPP Team Leader (Presto)
2

Prestoとは?
• Facebook社が開発している分散SQLエンジン – ペタスケールのデータに対しインタラクティブ(対話的)な検索が必要に
• それまではHive中心 – 2013年11月にオープンソース化
• Prestoの特徴 – CPU使用効率・スピード重視(アドホック検索) – インメモリ処理 – 教科書的なRDBMSの実装
– ANSI SQLベース
3

バッチクエリ(Hive) とアドホッククエリ (Presto)
4
TDでは独自にリトライ機構を導入
スループット重視 CPU使用効率、レスポンスタイム重視
耐障害性

エラーからの回復
• Prestoそのものには障害耐性はない
• エラーの種類 – 文法、関数名などの誤り – 存在しないテーブル、カラム名の利用 – Insufficient resource
• タスク辺りの上限メモリ量を超える – Internal failure (内部エラー)
• I/O error – S3の遅延
• ノードの障害 • など
5
Treasure DataのPrestoではクエリの再実行により耐障害性を持つ

クエリ再実行の頻度 (log scale)
• 99.8%のクエリが1回目で成功。再実行は稀
6

Treasure Dataとは?
• 米シリコンバレー発日本人創業のビッグデータ関連企業 – 2011年12月、米Mountain Viewにて創業 – 2012年11月、東京丸の内に日本支社設立
• クラウド型データマネージメントサービス「Treasure Data Service」を提供
7
芳川裕誠 – CEO Open source business veteran
太田一樹 – CTO Founder of world’s largest Hadoop Group
主要投資家
Bill Tai Charles River Ventures, Twitterなどに投資
まつもとゆきひろ Ruby言語開発者
Sierra Ventures – (Tim Guleri) 企業向けソフト・データベース領域での有力VC
創業者
Jerry Yang Yahoo! Inc. 創業者
古橋貞之 – Software Engineer MessagePack, Fluentd開発者

Treasure Data Service ビッグデータのための「クラウド + マネジメント」一体型サービス
データ収集~保存~分析までワンストップでサポート
8
• 毎日数百億規模のレコードが取り込まれている – 2014年5月に5兆(trillion)レコードに到達
• SQLベース(Hive, Presto, Pigなど)による検索サービスを提供

Importing more than 500,000 records / sec.
0
1000
2000
3000
4000
5000
6000
7000
Da
ta G
row
th in
Bill
ions
Data (records) Imported
Service Launched
3 Trillion
4 Trillion
1 Trillion
5 Trillion
2 Trillion
Series A Funding
100 Customers
Gartner Cool Vendor Report
9

Treasure Data: Presto Queries
10
• More than 10k queries / day

TD Presto
• Presto 0.100
• AWS・IDCF クラウドで運用
• td-presto connector – PlazmaDB にアクセスするコネクター – S3 (AWS) / RiakCS (IDCF) からデータを取得
– 列志向ストレージ • MessagePack フォーマット + 圧縮 (MPC file)
11

Hive
TD API / Web Console Interactive query
batch query
Presto
Treasure Data
PlazmaDB
td-presto connector

Web Console
13

14

buffer
Optimizing Scan Performance
• Fully utilize the network bandwidth from S3 • TD Presto becomes CPU bottleneck
15
TableScanOperator
• s3 file list • table schema header
request
S3 / RiakCS
• release(Buffer) Buffer size limit Reuse allocated buffers
Request Queue
Header Column Block 0 (column names)
Column Block 1
Column Block i
Column Block m
MPC1 file
HeaderReader
• callback to HeaderParser
ColumnBlockReader
header HeaderParser
• parse MPC file header • column block offsets • column names
column block request Column block requests
column block
prepare
MessageUnpacker
buffer
MessageUnpacker MessageUnpacker
S3 read
S3 read
pull records
Retry GET request on - 500 (internal error) - 503 (slow down) - 404 (not found) - eventual consistency
S3 read • decompression • msgpack-java v07
S3 read
S3 read
S3 read

Prestoのアーキテクチャ
16

Query Planner
SELECT name, count(*) AS c FROM impressions GROUP BY name
SQL
impressions ( name varchar time bigint)
Table schema
Table scan (name:varchar)
GROUP BY (name, count(*))
Output (name, c)
+
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Logical query plan
Distributed query plan

Sink
Partial aggregation
Table scan
Sink
Partial aggregation
Table scan
Execution Planner
• StageをTaskに分割して並列度を上げる
+ Node list
✓ 2 workers
Sink
Final aggregation
Exchange
Output
Exchange
Sink
Final aggregation
Exchange
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Worker 1 Worker 2

Execution Planner - Split
• 各TaskにはSplitが割り当てられ、並列に実行される
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Split
many splits / task = many threads / worker (table scan)
1 split / task = 1 thread / worker
Worker 1 Worker 2
1 split / worker = 1 thread / worker

クエリの実行時間
• 90%以上のPrestoクエリが2分以内に処理されている
20

Prestoで処理されるレコード数
• 1億レコード以上を処理するクエリも珍しくない
21

Prestoの性能
• クエリ中で一秒間に処理されるレコード数の分布
22

Challenges in Database as a Service
• トレードオフ
• Reference – Workload Management for Big Data Analytics. A. Aboulnaga
[SIGMOD2013 Tutorial]
23
個々のクエリを 単一クラスタで実行
全てのクエリを 必要最小限の クラスタで実行
速いが非常に高価 $$$ 性能は制限されるが、
手頃な価格で利用できる

Prestoクエリを快適に使うコツ
24

COUNT(DISTINCT x)
• 何種類の値があるかをチェック
• 種類が多い時(数百万種類~)にメモリを多く消費 – Task exceeded max memory ? GB エラーが生じやすい
• count(distinct x) を approx_distinct(x) に置き換える – 省メモリで近似的に値の種類をカウント
• 標準誤差2.3%
– Probabilistic counting (Hyper-LogLog counting)という技術
• その他: – approx_percentile(column, percentage) – 例:approx_percentile(v, 0.5) = ほぼmedian
25

WINDOW関数
• https://prestodb.io/docs/current/functions/window.html
• 利用例:累積和を計算したい場合
• SELECT month, cnt, sum(cnt) over(order by month) from data;
26
month cnt total 2015-01 14 14 2015-02 20 34 2015-03 5 39

WINDOW関数: PARTITION
• https://prestodb.io/docs/current/functions/window.html
• グループごとに累積和を計算したい場合
• SELECT month, item, cnt, sum(cnt) over(partition by item order by month) from data
27
month item cnt total 2015-01 A 14 14 2015-02 A 20 34 2015-01 B 5 5 2015-02 B 18 23

カラーチャート (bar, rgb 関数)
28

Presto + BIツール:Prestogres
• PostgreSQLを経由してPrestoにクエリを送信 – ODBCドライバ経由でBIツールに接続
• Tableau, Excel (Windows), ChartIOなど
pgpool-II + patch
Presto Coordinator
client
1. SELECT COUNT(1) FROM tbl1;
4. rewrite query to: SELECT * FROM presto_result;
PostgreSQL
3. FROM_PRESTO_AS_TEMP_TABLE() function runs the query on Presto and writes result into a new temporary table
2. select run_presto_as_temp_table( ‘presto_result’, ‘SELECT COUNT(1) FROM tbl1’ );
pgpool-II + patch client
1. SELECT COUNT(1) FROM tbl1
4. SELECT * FROM presto_result;
PostgreSQL
3. “run_persto_as_temp_table” function Prestoでクエリを実行
Presto Coordinator

Monitoring Presto with ChartIO + Prestogres
30
TD + chartio.com

Database As A Service
31

Claremont Report on Database Research
• データベースの研究者、ユーザー、識者が今後のDBMSについて議論 – CACM, Vol. 52 No. 6, 2009
• Cloud Data Serviceの発展を予測 – SQLの重要な役割
• 機能を制限できる • サービスとして提供するには好都合
– 難しい例:Spark • 任意のコードを実行させるためのセキュアなコンテナ開発が別途必要
32

Beckman Report on Database Research
• 2013年版 – http://beckman.cs.wisc.edu/beckman-report2013.pdf
– ほぼ全面Big Dataについての話題
• End-to-end – データの収集から、knowledgeまで生み出す
• Cloud Serviceの普及 – IaaS, PaaS, SaaS – DBMSの全てをクラウドで、という理想にはまだ到達していない
33

Results Push
Results Push
SQL
Big Data Simplified: The Treasure Data Approach A
pp S
erve
rs
Multi-structured Events!• register!• login!• start_event!• purchase!• etc!
SQL-based Ad-hoc Queries
SQL-based Dashboards
DBs & Data Marts
Other Apps
Familiar & Table-oriented
Infinite & Economical Cloud Data Store
ü App log data!ü Mobile event data!ü Sensor data!ü Telemetry!
Mobile SDKs
Web SDK
Multi-structured Events
Multi-structured Events
Treasure Agent
Treasure Agent
Treasure Agent
Treasure Agent Treasure Agent
Treasure Agent
Treasure Agent
Treasure Agent
Embedded SDKs
Server-side Agents
34
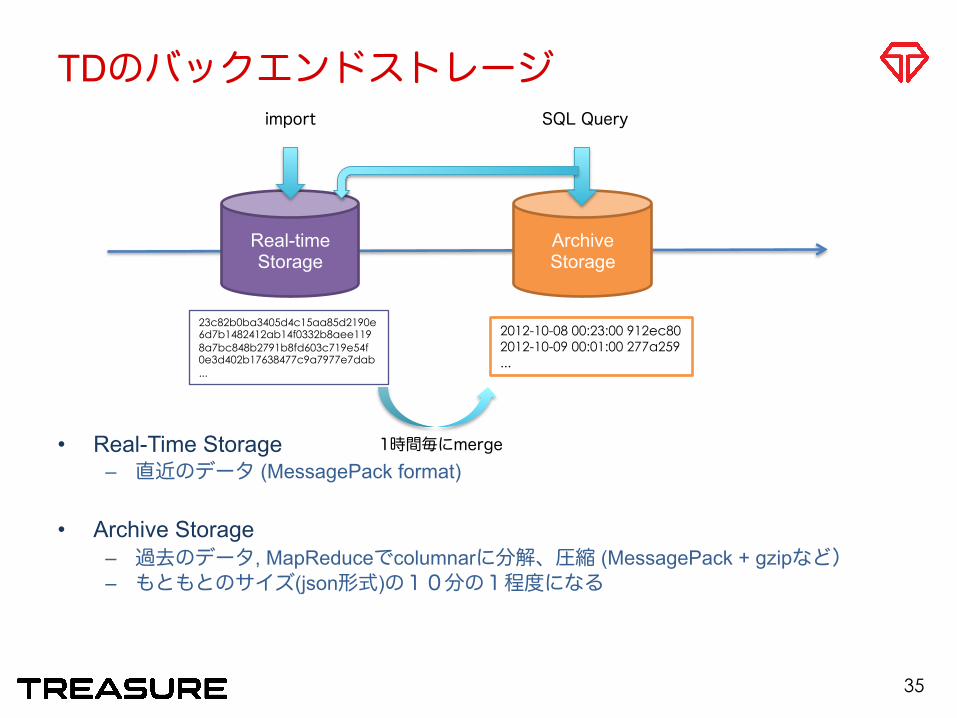
TDのバックエンドストレージ
• Real-Time Storage – 直近のデータ (MessagePack format)
• Archive Storage – 過去のデータ, MapReduceでcolumnarに分解、圧縮 (MessagePack + gzipなど) – もともとのサイズ(json形式)の10分の1程度になる
35
Real-time Storage
Archive Storage
23c82b0ba3405d4c15aa85d2190e 6d7b1482412ab14f0332b8aee119 8a7bc848b2791b8fd603c719e54f 0e3d402b17638477c9a7977e7dab ...
2012-10-08 00:23:00 912ec80 2012-10-09 00:01:00 277a259 ...
1時間毎にmerge
import SQL Query

Object Storage + Index
• Storage – Amazon S3を利用。S3互換のRiak CS (Basho)も利用できる – HTTP経由のデータ通信
• Object Index: PostgreSQLを使用 – S3ファイルのリスト列挙操作は遅いため – ユーザー毎、時系列毎の範囲で検索するためにGiST indexを利用
36
Real-time Storage
Archive Storage
23c82b0ba3405d4c15aa85d2190e 6d7b1482412ab14f0332b8aee119 8a7bc848b2791b8fd603c719e54f 0e3d402b17638477c9a7977e7dab ...
2012-10-08 00:23:00 912ec80 2012-10-09 00:01:00 277a259 ...
1時間毎にmerge
import SQL Query

PlazmaDB
37
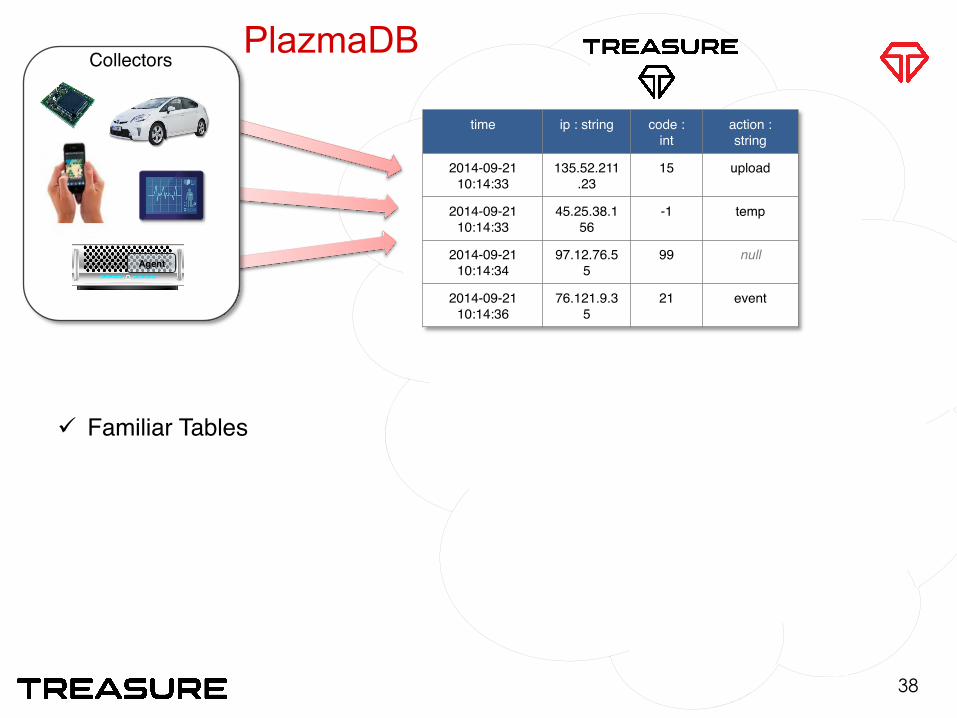
time ip : string code : int
action : string
2014-09-21 10:14:33
135.52.211.23
15 upload
2014-09-21 10:14:33
45.25.38.156
-1 temp
2014-09-21 10:14:34
97.12.76.55
99 null
2014-09-21 10:14:36
76.121.9.35
21 event
ü Familiar Tables
Agent
CollectorsPlazmaDB
38

time ip : string code : int
action : string
2014-09-21 10:14:33
135.52.211.23
15 upload
2014-09-21 10:14:33
45.25.38.156
-1 temp
2014-09-21 10:14:34
97.12.76.55
99 null
2014-09-21 10:14:36
76.121.9.35
21 event2014-09-21 11:27:41
97.12.76.55
99 null
2014-09-21 11:27:42
45.25.38.156
-1 temp
2014-09-21 11:27:42
135.52.211.23
15 upload
2014-09-21 12:02:18
97.12.76.55
99 null
2014-09-21 12:02:18
45.25.38.156
-1 temp
2014-09-21 12:02:19
135.52.211.23
15 upload
ü Familiar Tablesü Time-based Partitioning
Agent
Collectors
QueryPartitionPruning
PlazmaDB
39

time ip : string code : int
action : string
status : string
2014-09-21 10:14:33
135.52.211.23
15 upload null
2014-09-21 10:14:33
45.25.38.156
-1 temp null
2014-09-21 10:14:34
97.12.76.55
99 null null
2014-09-21 10:14:36
76.121.9.35
21 event null2014-09-21 11:27:41
97.12.76.55
99 null null
2014-09-21 11:27:42
45.25.38.156
-1 temp null
2014-09-21 11:27:42
135.52.211.23
15 upload null
2014-09-21 12:02:18
97.12.76.55
99 null null
2014-09-21 12:02:18
45.25.38.156
-1 temp null
2014-09-21 12:02:19
135.52.211.23
15 upload null
2014-09-21 12:03:24
76.34.123.54
13 status ok
2014-09-21 12:03:25
92.67.7.113
13 status error
2014-09-21 12:04:51
135.52.211.23
15 upload null
ü Familiar Tablesü Time-based Partitioningü Schema-Flexible
Agent
CollectorsPlazmaDB
40

MessagePack
41
• レコードはMessagePack形式 • 入力時のデータ型はそのまま保存
– intやstring型のデータが列中に混在した状況でも使える
PlazmaDBがスキーマに合わせて自動型変換を行う

MessagePack Format Types
• 0x00 ~ 0x7f int – 1 byte
• 0xe0 ~ 0xff neg int – 1 byte
• Support fixed/variable length data
42

Dynamic Data Type Conversion
43
{“user”:54, “name”:”test”, “value”:”120”, “host”:”local”}
(Explicit) Schema user:int name:string value:int
SELECT 54 (int)
データ(JSON)
“test” (string) 120 (int)
host:int
NULL

Monitoring
44

Monitoring Presto Usage with Fluentd
45
Hive
Presto

DataDog
• Monitoring CPU, memory and network usage • Query stats
46

DataDog: Presto Stats
47

Memory Usage
• G1GC -XX:+UseG1GC 適宜プロセスメモリが解放される (Presto 0.99で改善された)
• -Xmx の値は低めに設定 – システムメモリの8割程度
• GCのタイミングでプロセスのメモリ使用量が跳ね上がることがある – OutOfMemory Error 対策
48

Query Collection in TD
• SQL query logs – query, detailed query plan, elapsed time, processed rows, etc.
• Presto is used for analyzing the query history
49

Clustering SQL
• Clustering some customer queries – 10000 queries, 2726 terms, 24 clusters.
50

Deployment
• Building Presto takes more than 20 minute
• Facebook frequently releases new versions
• Let CircleCI build Presto – Deploy jar files to private Maven repository – We sometime use non-release versions
• for fixing serious bugs • hot-fix patches
• Integration Test – td-presto connector
• PlazmaDB, Multi-tenant query scheduler • Query optimizer
– Run test queries on staging cluster
51

Production: Blue-Green Deployment
• http://martinfowler.com/bliki/BlueGreenDeployment.html
• 2 Presto Coordinators (Blue/Green)
– Route Presto queries to the active cluster – No down-time upon deployment
• Launch Presto worker instances with chef <- less than 5 min. in AWS • Inactive clusters is used for pre-production testing and customer
support – Investigation and tuning of customer query performance – Trouble shooting
52

Usage Shift: Simple to Complex queries
53

Admission control is necessary
• Adjust resource utilization – Running Drivers (Splits) – MPL (Multi-Programming Level)
54

Challenge: Auto Scaling
• Setting the cluster size based on the peak usage is expensive
• But predicting customer usage is difficult
55

Problematic Queries
• 90% of queries finishes within 2 min. – But remaining 10% is still large
• 10% of 10,000 queries is 1,000.
• Long-running queries • Hog queries
56

Long Running Queries
• Typical bottlenecks – Cross joins – IN (a, b, c, …)
• semi-join filtering process is slow – Complex scan condition
• pushing down selection • but delays column scan
– Tuple materialization • coordinator generates json data
– Many aggregation columns • group by 1, 2, 3, 4, 5, 6, …
– Full scan • Scanning 100 billion rows…
• Adding more resources does not always make query faster • Storing intermediate data to disks is necessary
57
Result are buffered
(waiting fetch)
slow process
fast
fast

Hog Query
• Queries consuming a lot of CPU/memory resources – Coined by S. Krompass et al. [EDBT2009]
• Example:
– select 1 as day, count(…) from … where time <= current_date - interval 1 day union all select 2 as day, count(…) from … where time <= current_date - interval 2 day union all
– … – (up to 190 days)
• More than 1000 query stages. • Presto tries to run all of the stages at once.
– High CPU usage at coordinator
58

Presto Team at Facebook
• Currently 12 members
• Talked with core developers of Presto
• 2015 Q2 Plan – Per-query memory resource management – Stage-wise resource allocation
– Raptor connector • native storage • + MySQL index • (internal-use only)
59

• Huge Query Processing
• Idea – Bushy plan -> Deep plan – Introduce stage-wise resource assignment
Huge Query Processing
60

Task-based memory limit -> Query Base Memory Limit
• Task毎のメモリ割当はわかりにくい -> クエリ毎のメモリ割当に
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Split
many splits / task = many threads / worker (table scan)
1 split / task = 1 thread / worker
Worker 1 Worker 2
1 split / worker = 1 thread / worker

Treasure Data: US Office
62

MessagePack Hackathon at Silicon Valley
• SV – @frsyuki – @oza_x86 – @hkmurakami – @taroleo
• JP – @komamitsu
63

64







