Download - MLaPP輪講 Chapter 1

MLaPP 輪講 第一回Ch1. Indroduction

名言
We are drowning in information and starving for knowledge.
- John Naisbitt, in Megatrends (1982)
2

ビッグデータ 1 兆のウェブページ Youtube にアップされる動画は 10 年分 / 日 38 億の塩基対 ×1000 人分 ウォルマートのデータベース 2.5 ペタバイト ドライバ 3200 人,走行距離 8000 万 km の
運転データ
人手では解析が追いつかない!
3
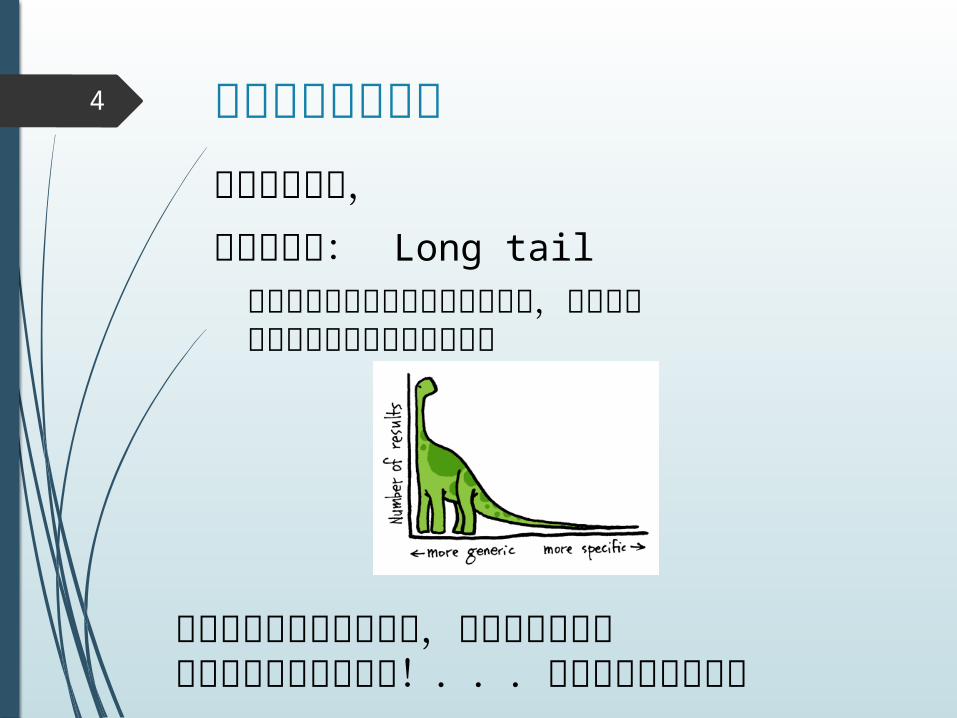
意外と小さいのね
重要な性質: Long tail重要なものはたくさん出てくるが,その他は比較的にほとんど出現しない
ビッグデータであっても,実質的に重要なデータサイズは小さい!...けどやっぱりデカイ
留意点として,
4
機械学習
データ中のパターンを自動的に発見し, それを用いて未来のデータを予測する 不確実性のもとで意思決定を行う
ような手法の集まりを,機械学習と定義
5

確率論
過去のデータが与えられたとき,最適な予測とは?
データを説明する最適なモデルは? 次にどのような観測を行えばよいか?
etc.など,機械学習では様々な形で不確実性が現れる.
不確実性を扱うツールとして,確率・統計を採用する.
6

MLaPP はクックブックではない!
確率的モデリング・推定の観点から,
機械学習における統一的な視点を与え
る
ことを目的とする.
7

機械学習の世界へ入りますが...
用語が多いので注意!専門用語を作りたがるのは人の性ですね。。ジャーゴン,ギャル語,猛虎弁...慣れるしかない(半年 ROM れ)
8

機械学習の分類
1. 教師あり学習
2. 教師なし学習
3. 強化学習
9

機械学習の分類
1. 教師あり学習
2. 教師なし学習
3. 強化学習Sutton & Barto 1998 を読みましょう.
10
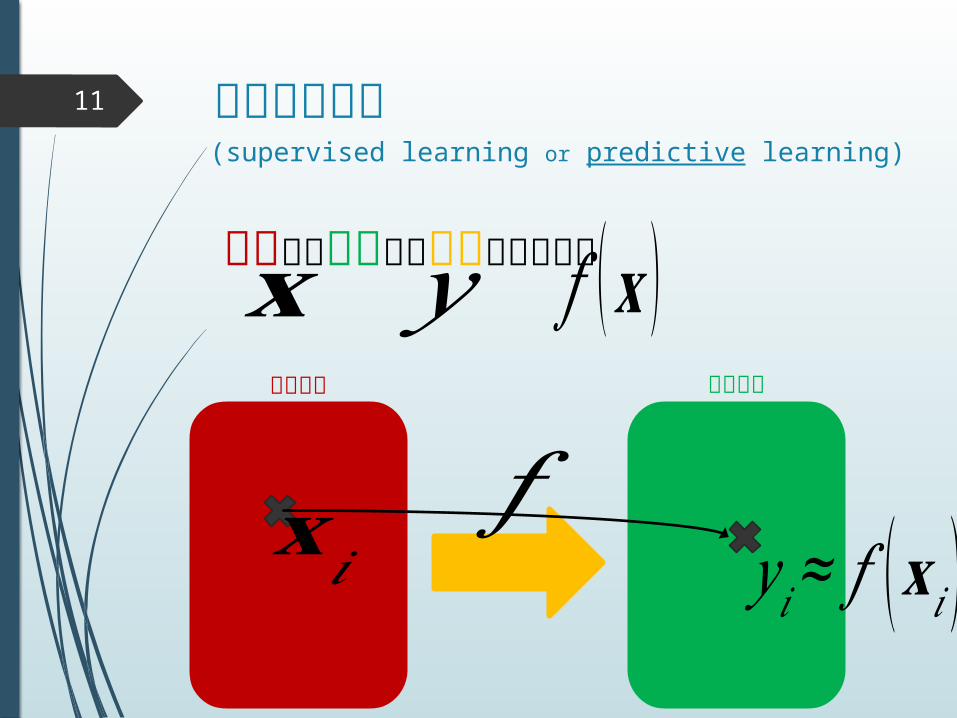
教師あり学習
入力から出力への写像を学習する𝐱 𝑦 𝑓 (𝐱 )(supervised learning or predictive learning)
入力空間 出力空間
𝐱𝑖 𝑦 𝑖≈ 𝑓 (𝐱 𝑖 )𝑓
11
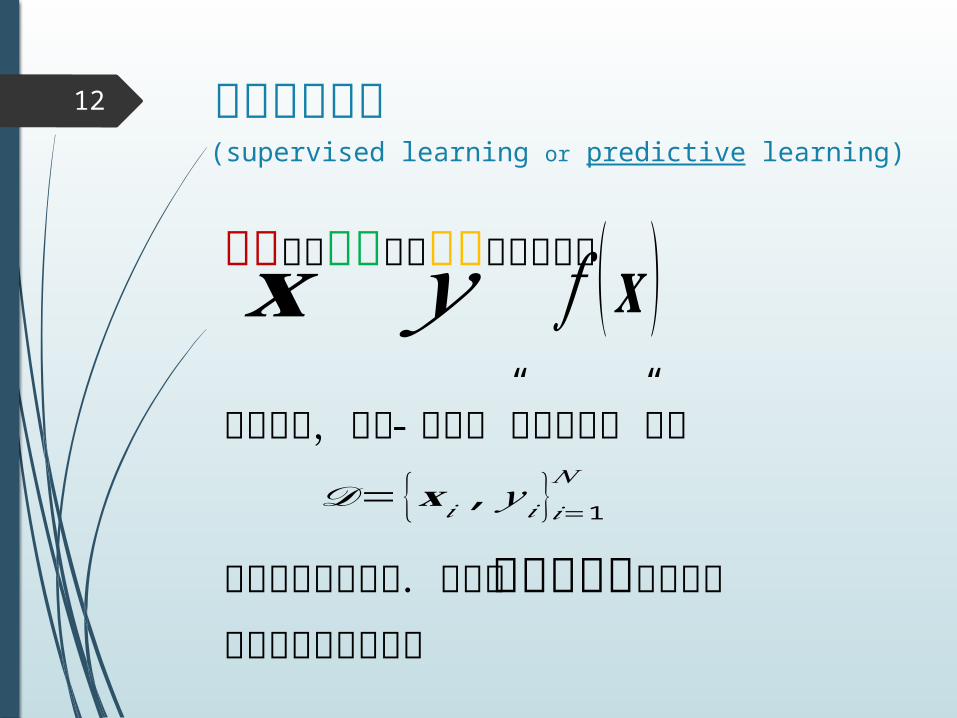
教師あり学習
入力から出力への写像を学習する𝐱 𝑦 𝑓 (𝐱 )このとき,入力 - 出力の”ラベル付き”集合 𝒟= {𝐱 𝑖 , 𝑦 𝑖 }𝑖=1
𝑁
を用いて学習する.これを訓練データという.(は訓練例の個数)
(supervised learning or predictive learning)
12

入力
特徴,素性,共変量,説明変数,独立変数,予測変数,…
Input, feature がよく使うかな 今のところ で良い 画像,文,時系列,分子形状,グラフな
ど,ベクトルとみなすには厳しい場合も多い
確率変数なので,本当は とか書かなきゃいけないが,大体無視される
13
出力
応答変数,従属変数など (input より少ない! )
Output, response variable 出力の種類により,問題の名前が違う
1. カテゴリ変数 識別,パターン認識 として知られる
2. 実数値 (多次元の場合もある)回帰 regression
classification, pattern recognition
カテゴリに順序がある場合も (amazon の★ )
14

出力
応答変数,従属変数など (input より少ない! )
Output, response variable 出力の種類により,問題の名前が違う
1. カテゴリ変数 識別,パターン認識 として知られる
2. 実数値 (多次元の場合もある)回帰 regression
classification, pattern recognition
カテゴリに順序がある場合も (amazon の★ )
ここらへんはノリで.
15

まず例より始めよ
例示は理解の試金石 ...って数学ガールで言ってた
大体の人は理論より実践を求めてますよね 理論のほうが好きな変態さんもいることを忘れないで
16
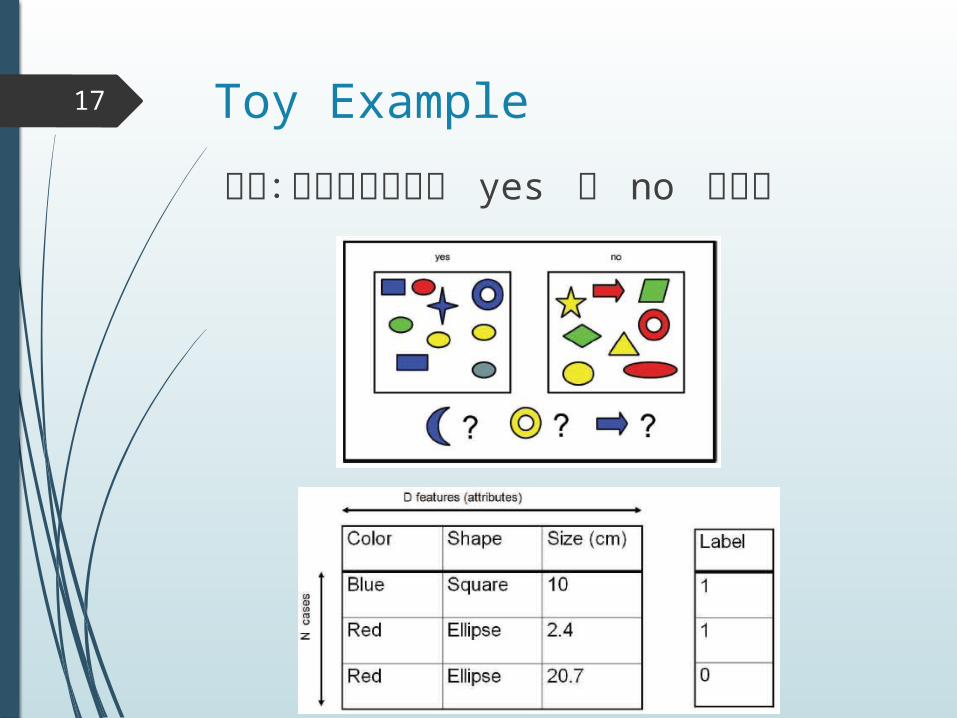
Toy Example17
問題:オブジェクトが yes か no を識別
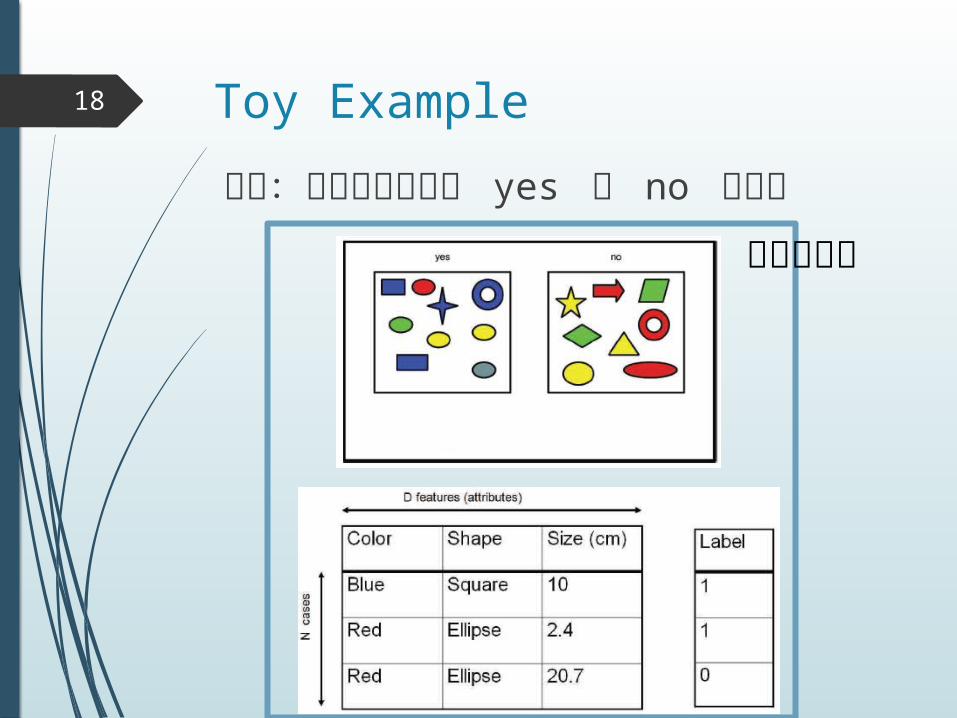
Toy Example18
問題:オブジェクトが yes か no を識別
訓練データ
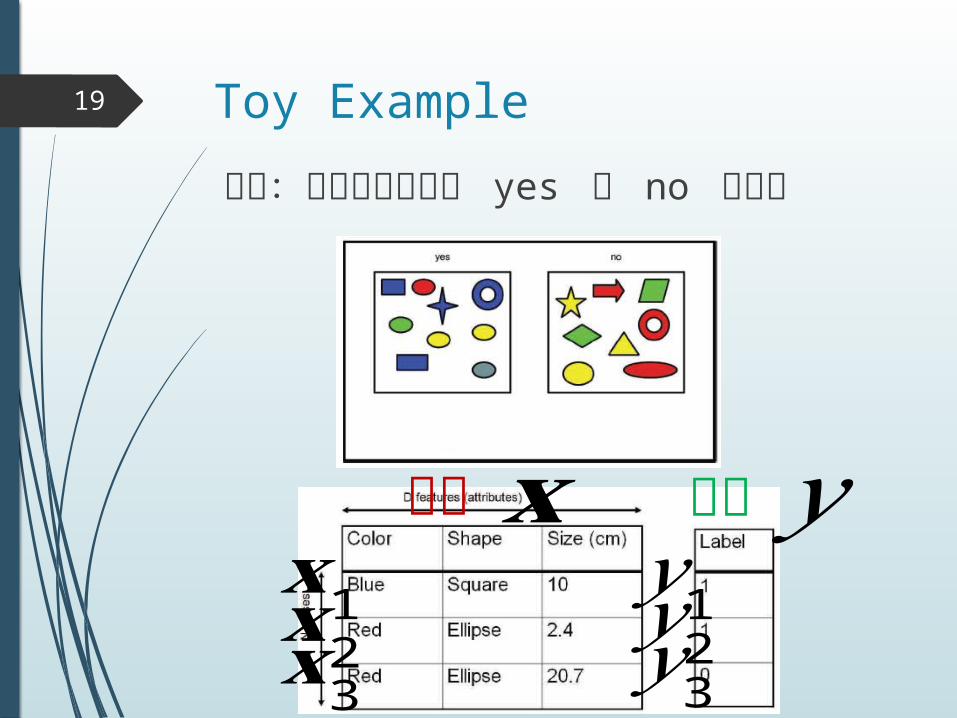
Toy Example19
問題:オブジェクトが yes か no を識別
𝐱入力 出力𝑦𝐱1𝐱 2𝐱 3
𝑦 1𝑦 2𝑦 3

Toy Example20
問題:オブジェクトが yes か no を識別
テストデータ
これら未知のオブジェクトは yes か no か?
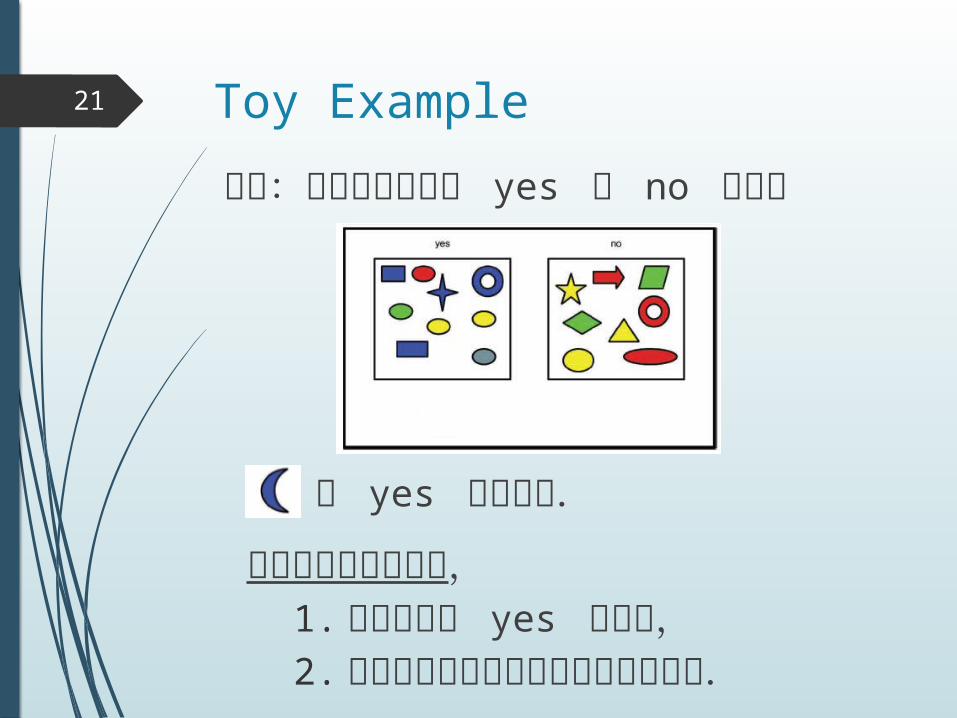
Toy Example21
問題:オブジェクトが yes か no を識別
は yes であろう.
訓練データにおいて,1. 青はすべて yes であり,2. 月はいずれにも含まれていないから.

Toy Example22
問題:オブジェクトが yes か no を識別
は yes か no か?
訓練データにおいて,1. 黄色はいずれにも含まれており,2. ドーナツもいずれにも含まれている.
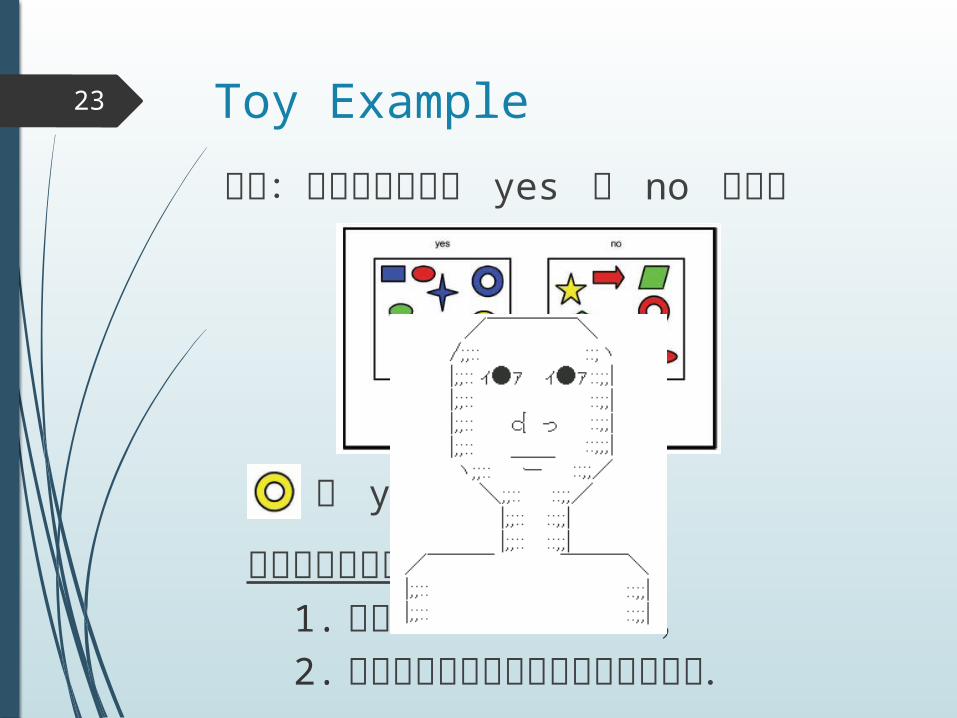
Toy Example23
問題:オブジェクトが yes か no を識別
は yes か no か?
訓練データにおいて,1. 黄色はいずれにも含まれており,2. ドーナツもいずれにも含まれている.
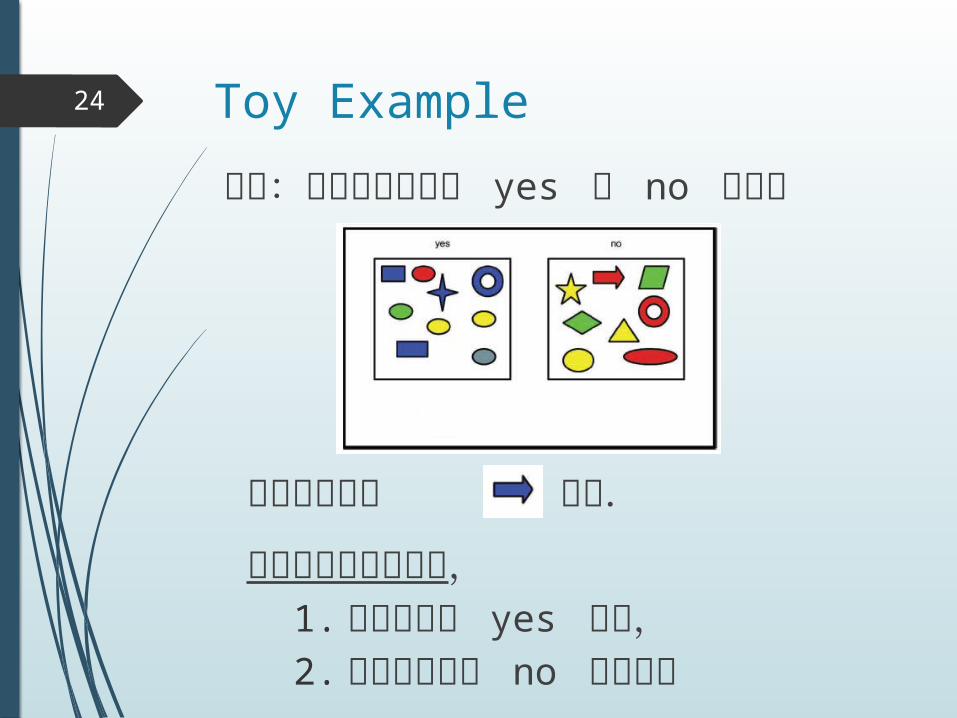
Toy Example24
問題:オブジェクトが yes か no を識別
同様の困難が にも.
訓練データにおいて,1. 青はすべて yes だが,2. 矢印はすべて no である.

確率的な表現が必要25
この問題では,決定論的な識別が困難
日常シーンでも,決定論的なことは,実はあまりない 空気が湿ってるから雨振りそう(はずれ
ることもある)
やつは 3ポイントをうってくるはずだ 識別の基準として,確率を基礎におく
(不確実性を扱うため!)
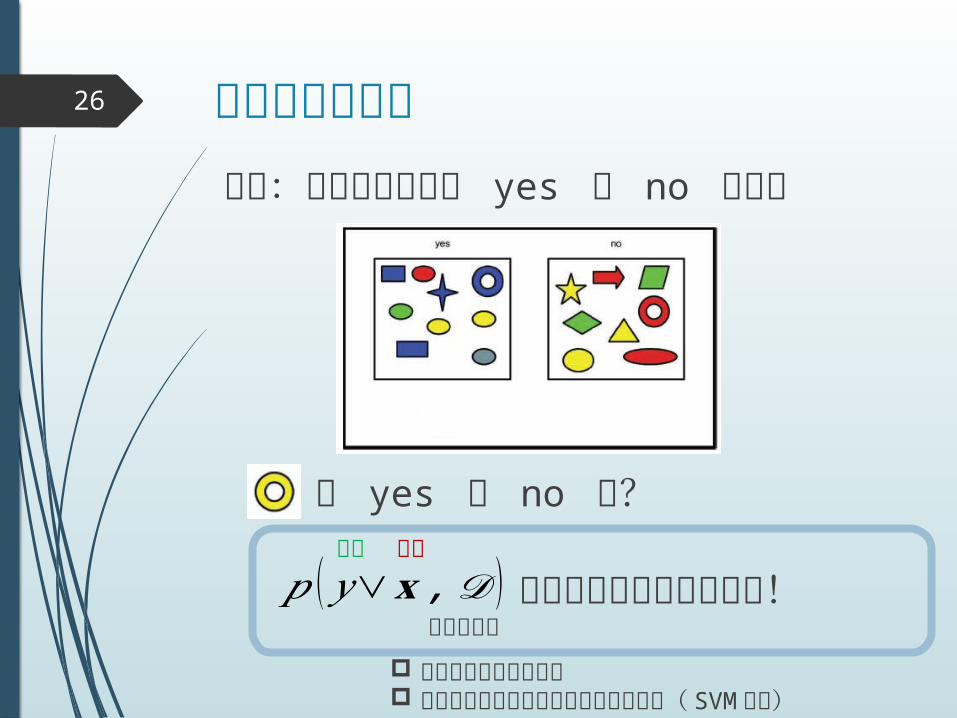
確率分布で表現26
問題:オブジェクトが yes か no を識別
は yes か no か?
𝑝 (𝑦∨𝐱 ,𝒟 ) にもとづいて識別しよう!出力 入力
訓練データ
我々のひとまずの立場 確率モデルにもとづかない手法もある( SVM と
か)

確率分布で表現27
問題:オブジェクトが yes か no を識別
は yes か no か?𝑝 (𝑦=1∨𝐱 ,𝒟 ) なら yes𝑝 (𝑦=0∨𝐱 ,𝒟) なら no

𝑝 (𝑦=1∨𝐱 ,𝒟 )+𝑝 ( 𝑦=0∨𝐱 ,𝒟)=1
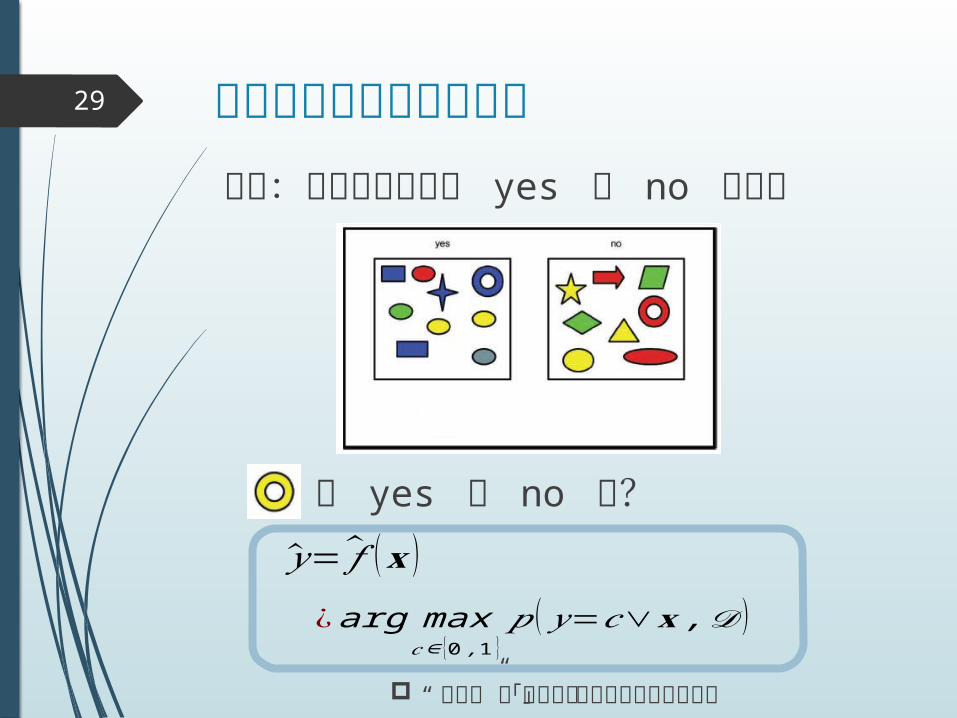
確率分布で表現28
問題:オブジェクトが yes か no を識別
は yes か no か?
が成り立つので,𝑝 (𝑦=1∨𝐱 ,𝒟 ) のみわかれば良い.
識別ルールはこう決める29
問題:オブジェクトが yes か no を識別
は yes か no か?�̂�= 𝑓 (𝐱 )
¿ arg max𝑐∈ {0 ,1 }
𝑝 (𝑦=𝑐∨𝐱 ,𝒟 )
“ ハット”は「推定値」という意味でよく使う
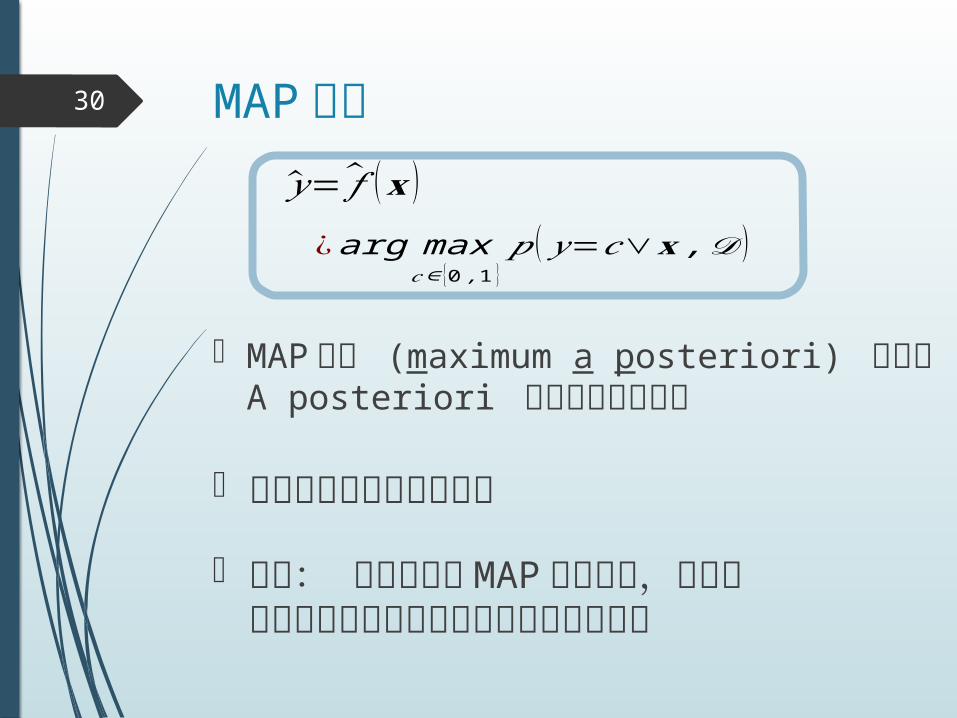
MAP 推定30
�̂�= 𝑓 (𝐱 )
¿ arg max𝑐∈ {0 ,1 }
𝑝 (𝑦=𝑐∨𝐱 ,𝒟 )
MAP 推定 (maximum a posteriori) というA posteriori は事後分布のこと
確率分布の最頻値を選択
補足: 機械学習で MAP 推定とは,普通はパラメータ推定の意味において使う言葉

「わからない」という勇気31
�̂�= 𝑓 (𝐱 )
¿ arg max𝑐∈ {0 ,1 }
𝑝 (𝑦=𝑐∨𝐱 ,𝒟 )
一番大きい事後確率 がある値よりも小さいとき,「わかりません」という識別結果を返すときもある
医薬・金融など間違いが許されない分野
クイズ・ミ■オネアとかね

オモチャで遊ぶのは終わり
実問題を紹介 まずは識別から 回帰は例の紹介のみ
32

文書識別 or スパムフィルタリング 文書識別
文書・ウェブページなどの , トピックなどを識別
33
スパムフィルタリング メールが , スパムかハムかを識別

Bag-of-words34
文書 について,ある単語 が出現する場合は そうでなければ
クラスによって単語の出現パターンに差 文脈は無視
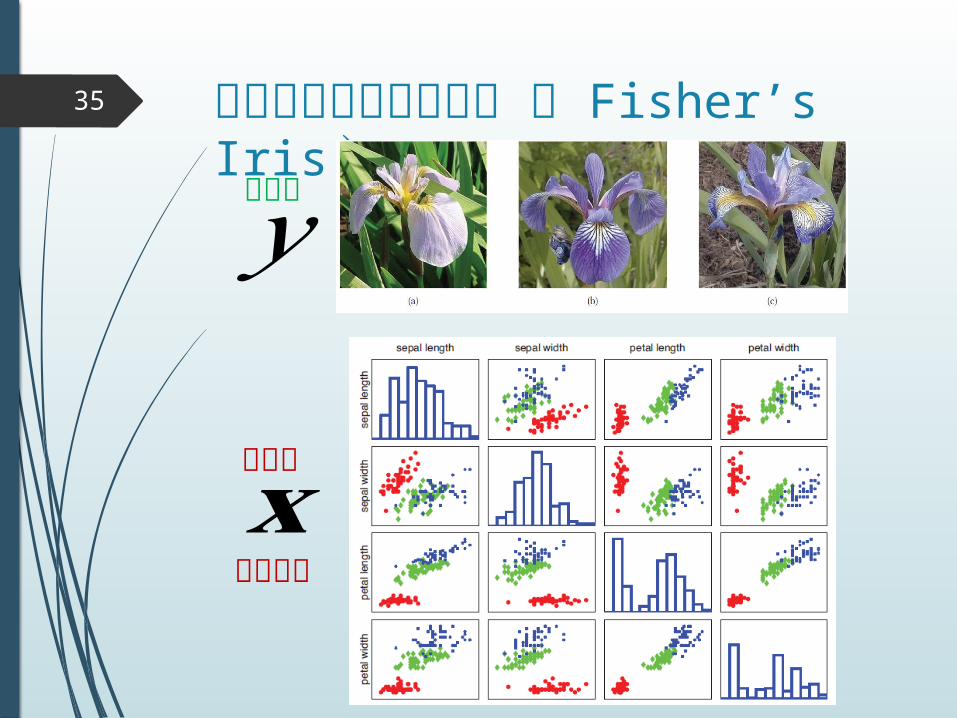
フィッシャーのアヤメ ( Fisher’s Iris )
35
𝐱
𝑦クラス
特徴量
の散布図
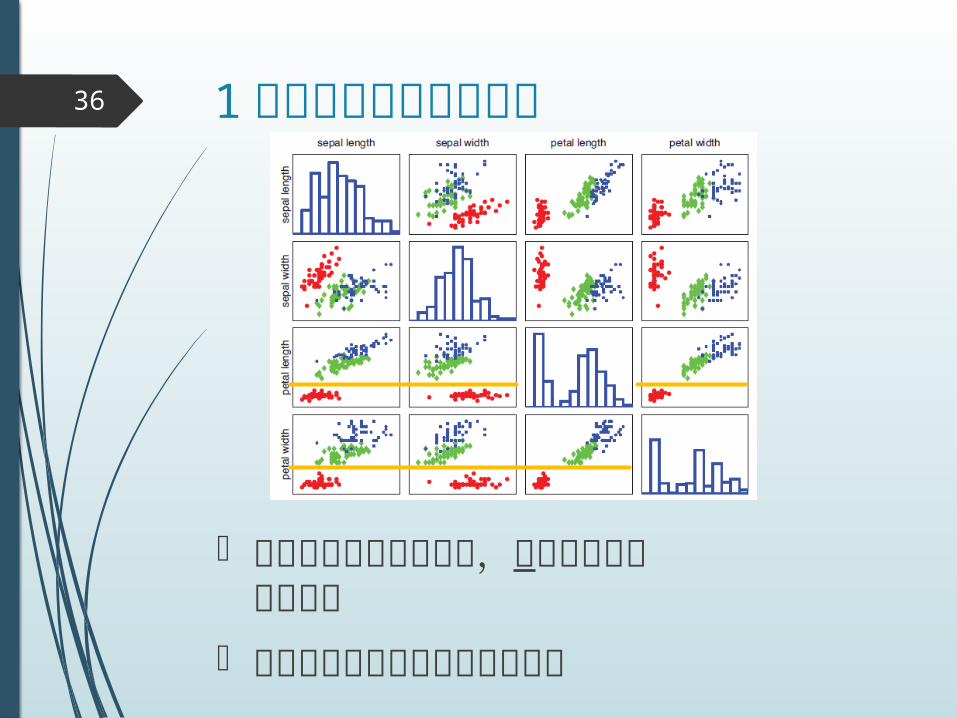
1 つの特徴量で分離可能
適切な特徴量を選べば,赤のクラスを分離可能
水平線で分離できるということ
36

2 つの特徴量である程度分離
2 次元の特徴量を用いれば,青と緑のクラスを割りと分離できる
特徴量で,原理的に分離可能かが決まる
37
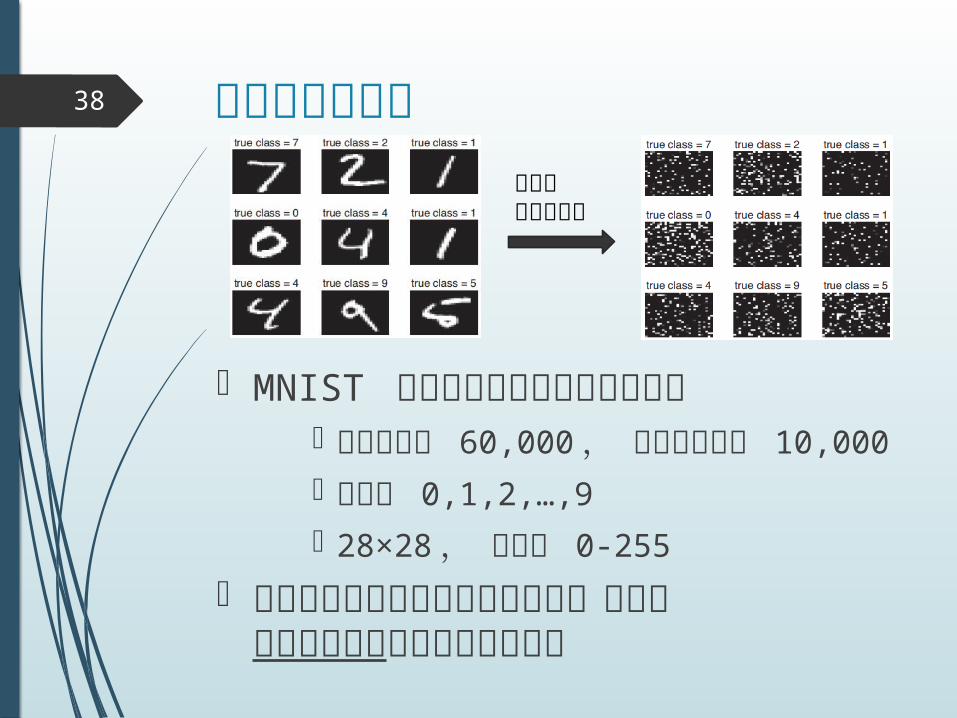
手書き文字認識
MNIST 郵便番号の手書き文字データ 訓練データ 60,000 , テストデータ
10,000
クラス 0,1,2,…,9
28×28 , 画素値 0-255 単純にベクトル化するだけでは,画像の構造的な情報を無視しかねない
38
次元をシャッフル

顔検出39
窓をスライドさせていく スケール変化・回転を許容 テンプレートとのマッチ
ング例えばこんなんグンマー部族の仮面かな?
デジカメに標準搭載 Google ストリートビューで,歩行者の顔に自動モザイク
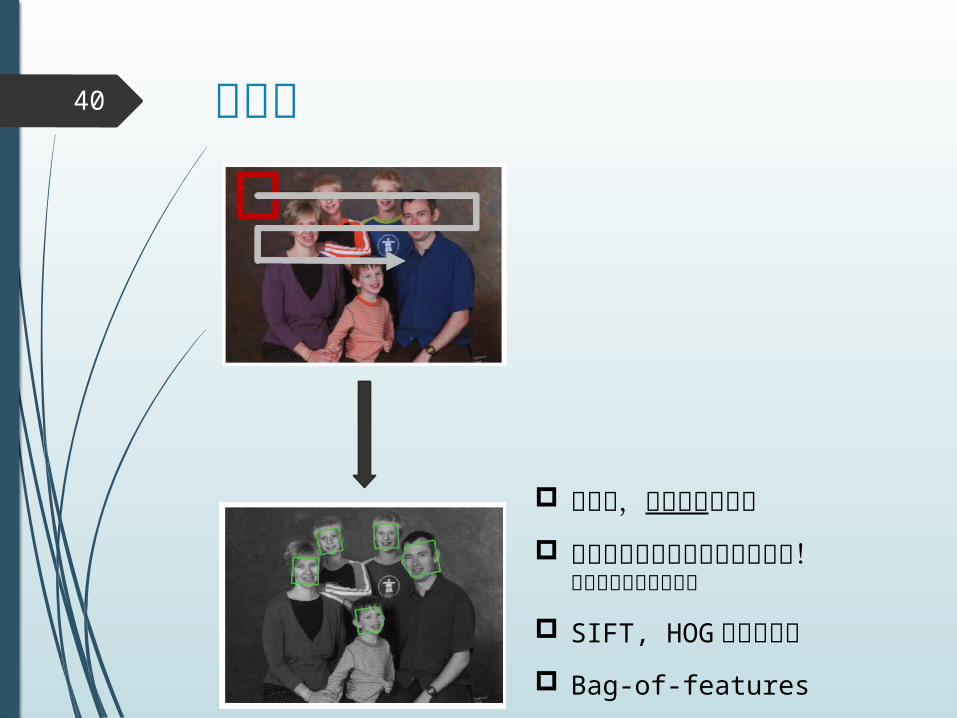
顔認識40
検出後,誰なのかを認識
特徴量は検出とは大きく異なる!グンマー仮面では無理
SIFT, HOG などが有名 Bag-of-features

回帰41
回帰では出力が実数に
例だけ紹介 市場の状態から明日の株価を予測 YouTube閲覧履歴から年齢を推定 制御信号からロボットアームの手先位置推定

ここまでは教師ありの話
次は教師なし学習
42
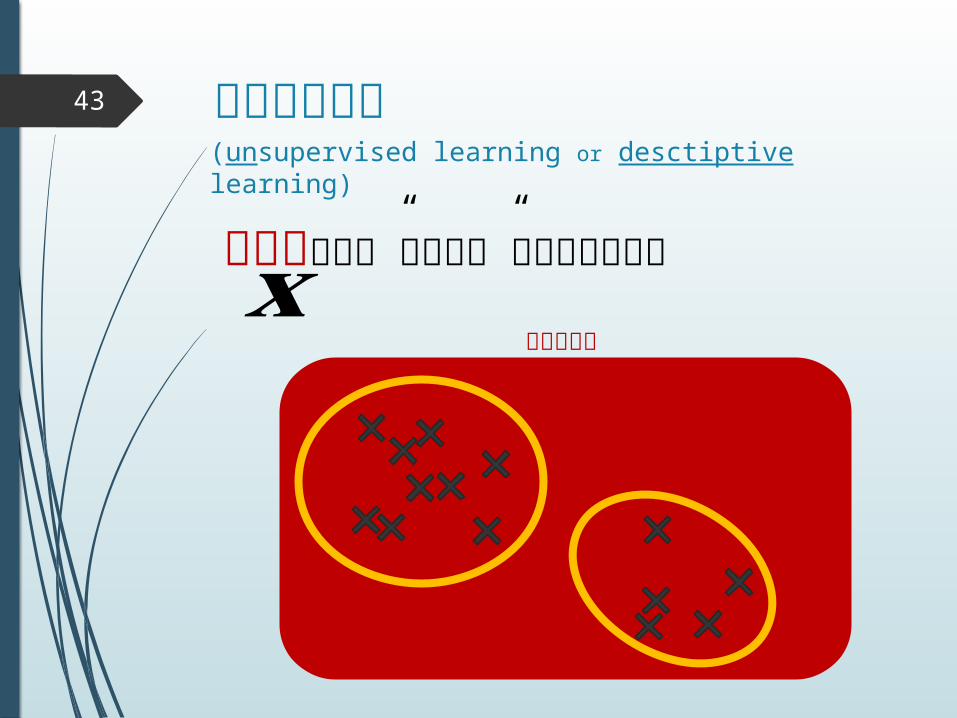
教師なし学習43
データの中の”興味深い”構造を見つける𝐱(unsupervised learning or desctiptive learning)
データ空間

教師あり
教師なし学習44
データの中の”興味深い”構造を見つける𝐱(unsupervised learning or desctiptive learning)
𝑝 (𝑦∨𝐱 ,𝜽 ) 教師なし 𝑝 (𝐱∨𝜽 )
推定するもの:
はパラメータ.今のところは ( ゚ ε ゚ ) キニシナイ !!
教師なしでは,多次元変数の分布を推定する,というのが大きな違い

ヒントン大先生いわく45
When we’re learning to see, nobody’s telling us what the right answers are — we just look. Every so often, your mother says “that’s a dog”, but that’s very little information.
You’d be lucky if you got a few bits of information — even one bit per second — that way. The brain’s visual system has 1014 neural connections. And you only live for 109 seconds. So it’s no use learning one bit per second. You need more like 105 bits per second. And there’s only one place you can get that much information: from the input itself.
Geoffrey Hinton, 1996
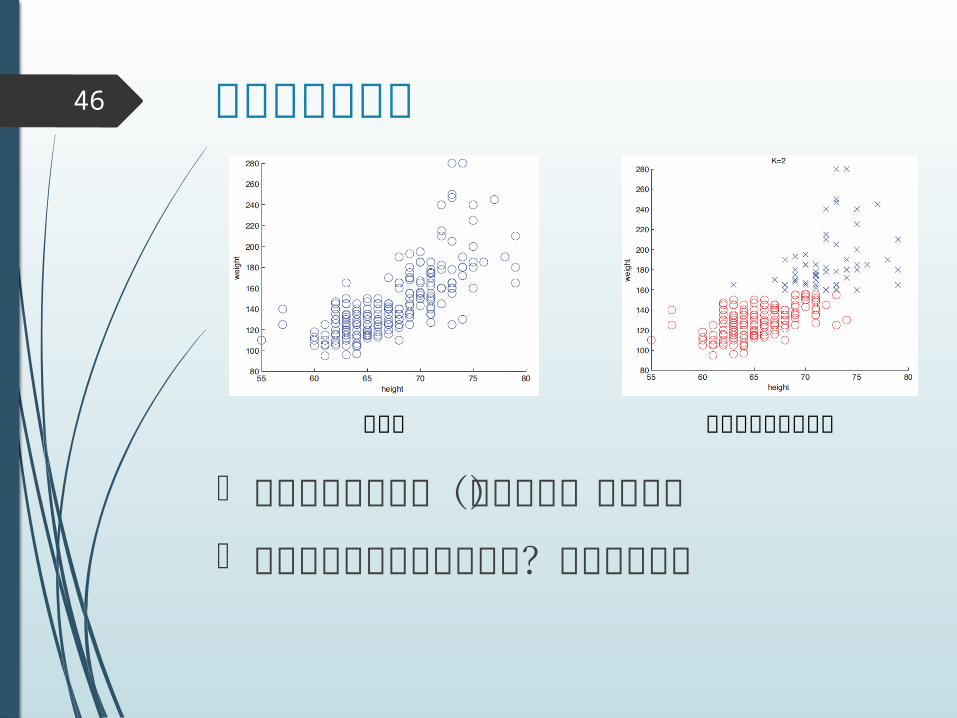
クラスタリング46
データ クラスタリング結果
クラスタ数をどう決めるか?が大きな問題
データをグループ(クラスタ)に分ける
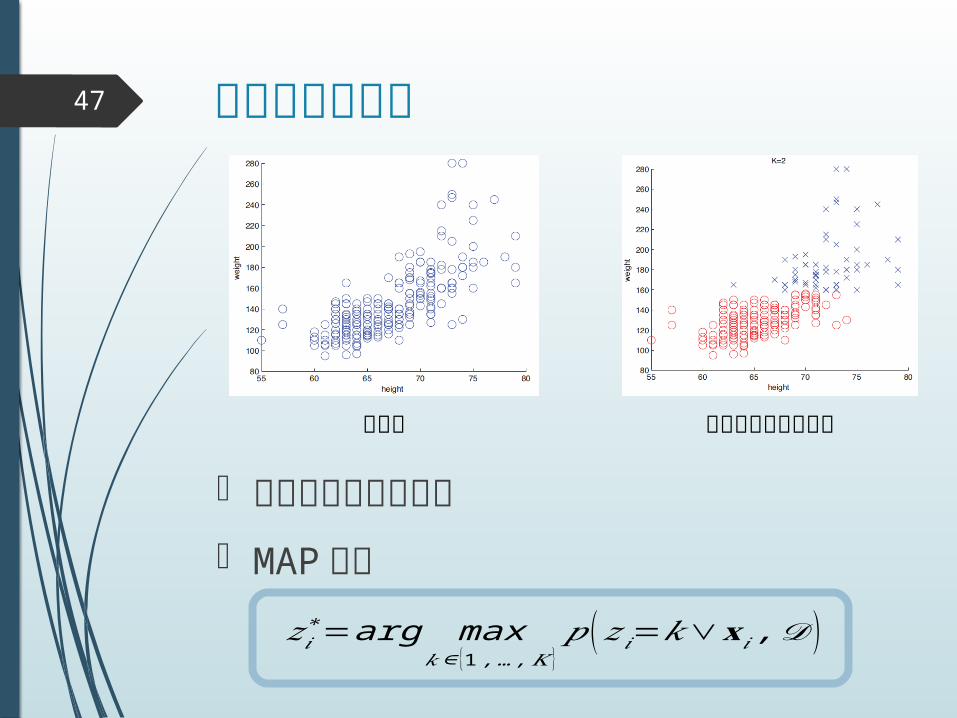
クラスタリング47
データ クラスタリング結果
MAP 推定
クラスタへの割振り
𝑧𝑖∗=arg max
𝑘∈ {1 ,…,𝐾 }𝑝 (𝑧 𝑖=𝑘∨𝐱𝑖 ,𝒟 )

クラスタリングの応用例48
フローサイトメトリーのデータをクラスタリングして細胞亜集団を発見
天体のクラスタリングで新種の星を発見 超オシャンティー
ユーザの購買傾向のクラスタリング レコメンドシステムなど

次元削減49
高次元データは,実質的により低次元の部分空間に分布することがある
平面に射影( PCA)
少数の潜在因子によりデータを説明可能

主成分分析( PCA)50
データのばらつきを表す行列の固有値に対応する”固有顔”
固有顔は”平均顔”からのズレを説明
PCA により潜在因子を抽出

グラフ構造の発見51
グラフはまたちょっと特殊なので省略 教師あり学習の問題を解く前に,
変数同士の相関構造を調べることがある

行列の補間52
主に,欠損値の予測
観測なし
例. 画像修復
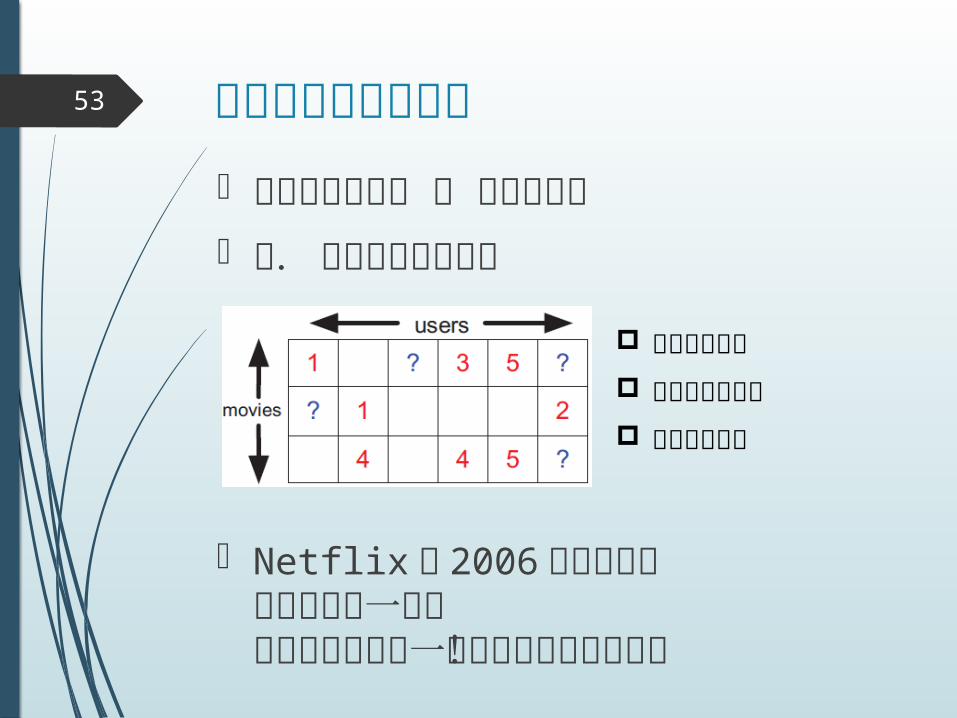
協調フィルタリング53
クラスタリング + 欠損値予測 例. 映画レーティング
Netflix が 2006 年にコンペなんと賞金一億円機械学習で人生一発逆転も夢じゃない!
超絶スパース 観測はごく少数 クラスに順序

1.4 は機械学習の基礎概念の紹介 まずはパラメトリックモデルとノンパラメトリックモデルの対比から
54
パラかノンパラか それが問題だ パラメトリックモデル固定された数の有限個のパラメータを持つ
55
ノンパラメトリックモデルパラメータの個数が訓練データ量に従い増える
教師あり 教師なし
パラメトリック
ノンパラメトリック
イメージということで。。

状況によって使いわけよう パラメトリックモデル
ノンパラに比べ,計算が軽い データの分布に強い仮定を置く 高次元のデータを扱える
56
ノンパラメトリックモデル パラに比べ,計算量が多い データの分布に関する仮定が弱いため,柔軟 高次元のとき,次元の呪いにかかる

K近傍法: ノンパラ識別器の例 未知のデータが入ってきた際,
1. 訓練データすべての点との距離を計算2. K 個の最近傍点を選び,対応する出力を K 個得る3. K 個の出力で,一番多いラベルを未知のデータの
出力とする
57
近傍の数 は固定 予め決めなければならない 平滑化パラメータという
(により決定境界の滑らかさが決まるから)

K近傍法: ノンパラ識別器の例58
確率モデルで表すと
𝑝 (𝑦=𝑐∨𝐱 ,𝒟,𝐾 )= 1𝐾 ∑
𝑖∈
𝕀 (𝑦 𝑖=𝑐 )最近傍点の集合 ( は指示関数)
やはり MAP 推定�̂� (𝐱 )=argmin
𝑐𝑝 (𝑦=𝑐∨𝐱 ,𝒟 ,𝐾 )
のとき,決定境界はボロノイ分割となる

K近傍法の例59
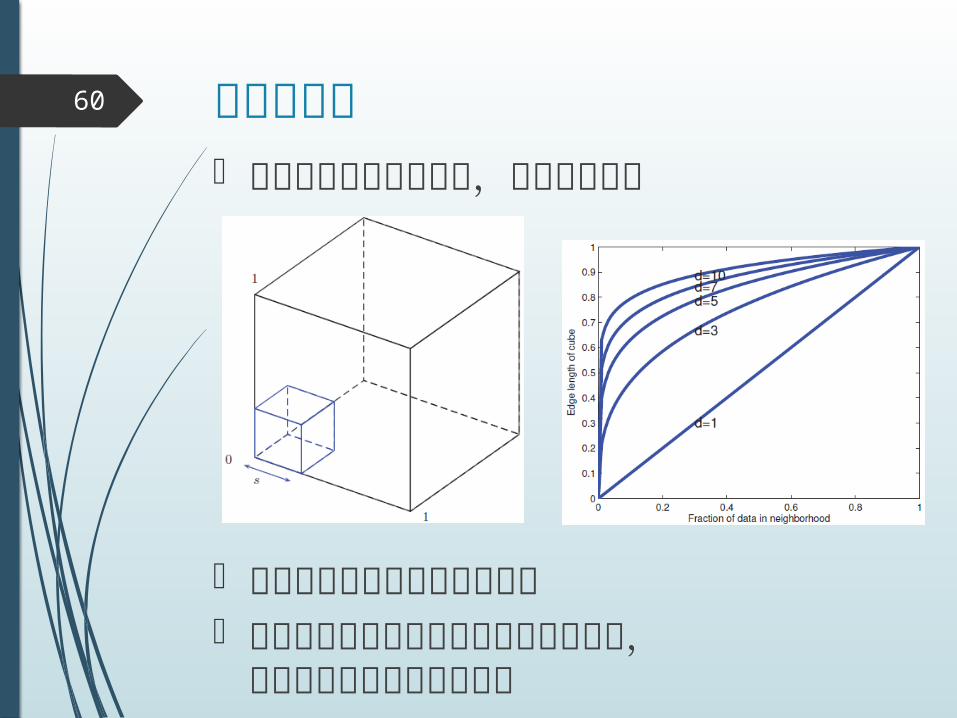
次元の呪い60
データが高次元のとき,闇に呑まれる
訓練データがスカスカになる あるデータ点から他のデータを見ると,超球面上に集まって見える

闇に呑まれないためには?61
データの分布に仮定を置きましょう 教師あり or
教師なし
帰納バイアスという
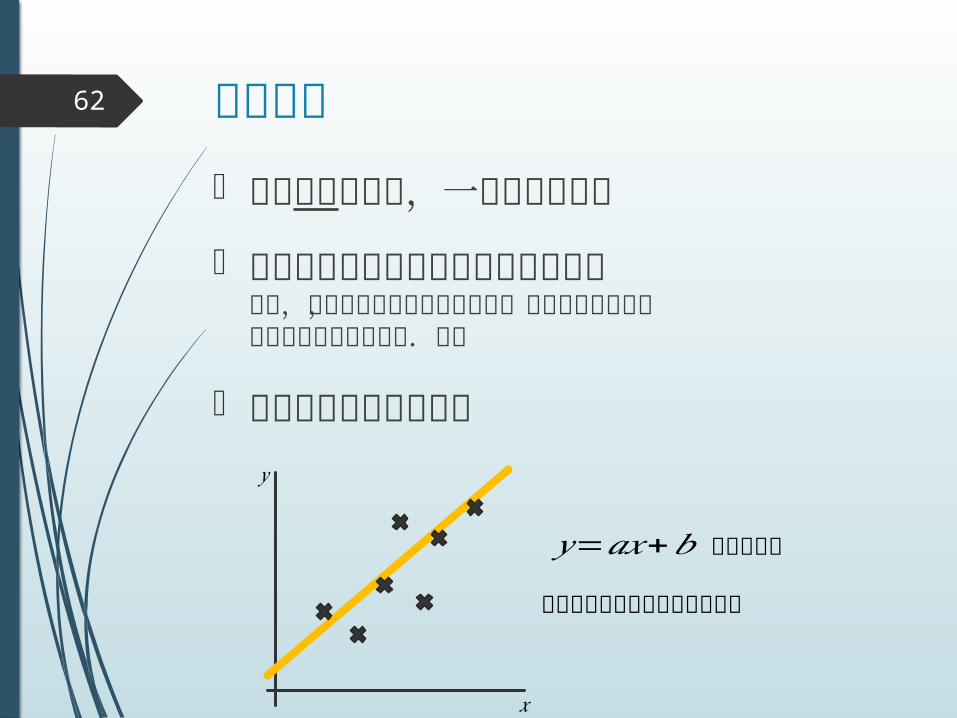
線形回帰62
教師あり回帰で,一番単純なもの
入出力関係が線形だという強い仮定まぁ,実問題ではほとんどの場合,成り立たないよねでも割りとうまくいく.偉い
統計の授業で必ず習う
𝑥
𝑦
𝑦=𝑎𝑥+𝑏 で当てはめ
パラメータは最小二乗法で推定

線形回帰を確率モデルで63
𝑦 (𝐱 )=𝑤0+∑𝑗=1
𝐷
𝑤 𝑗 𝑥 𝑗+𝜖 ,
データがこのように生成されると仮定:
.
標準正規分布 入力が 1 次元の場合のデータの分布

線形回帰を確率モデルで64
入力の 1 次元目に 含めると:𝑦 (𝐱 )=𝐰𝑇 𝐱+𝜖 , .
ただし .
このとき,𝑝 (𝑦∨𝐱 ,𝜽 ) 𝒩 (𝑦∨𝐰𝑇 𝐱 ,𝜎2 )
ただし .
パラメータ推定は,のちの章で(多分)
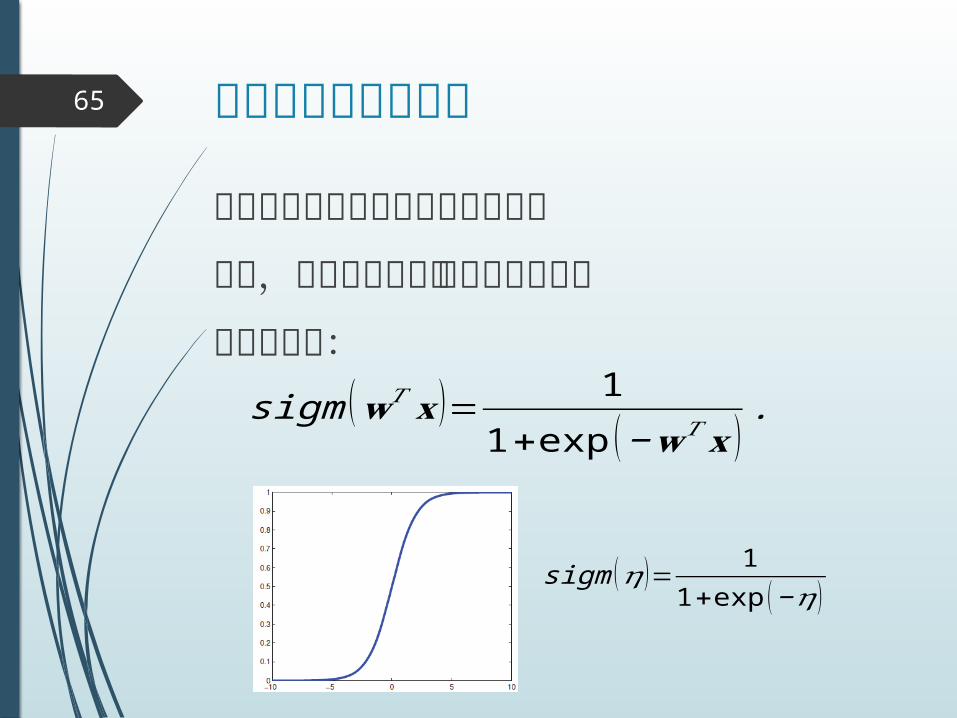
ロジスティック回帰65
今度は,線形モデルを使った識別
sigm (𝜂 )= 11+exp (−𝜂 )
まず,線形回帰の式にシグモイド関数
をかませる:sigm (𝐰𝑇 𝐱 )= 1
1+exp (−𝐰 𝑇𝐱 ).

ロジスティック回帰66
次に,出力にのるノイズがベルヌーイ分布
Ber (𝑦∨𝑝 )=𝑝 𝑦 (1−𝑝)1−𝑦
に従うとする( 0-1 変数だから):
𝑝 (𝑦∨𝐱 ,𝐰 )=Ber (𝑦∨sigm (𝐰𝑇 𝐱 )) .
SAT スコアを入力として,授業に合格したか (1) ,落第したか (0) をフィッティングした図(嫌な図だ)
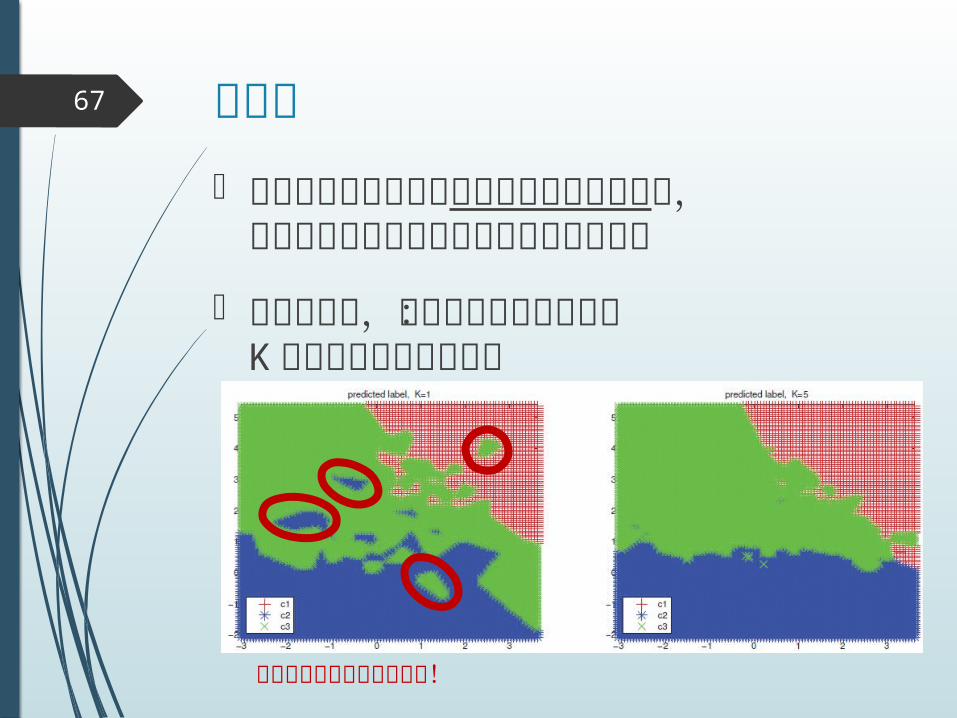
過学習67
データの量に対してモデルが複雑すぎると,未知のデータに対する予測能力が落ちる
典型的には,ノンパラで陥りがち:K近傍法でが小さいとき
訓練データに適合しすぎィ!
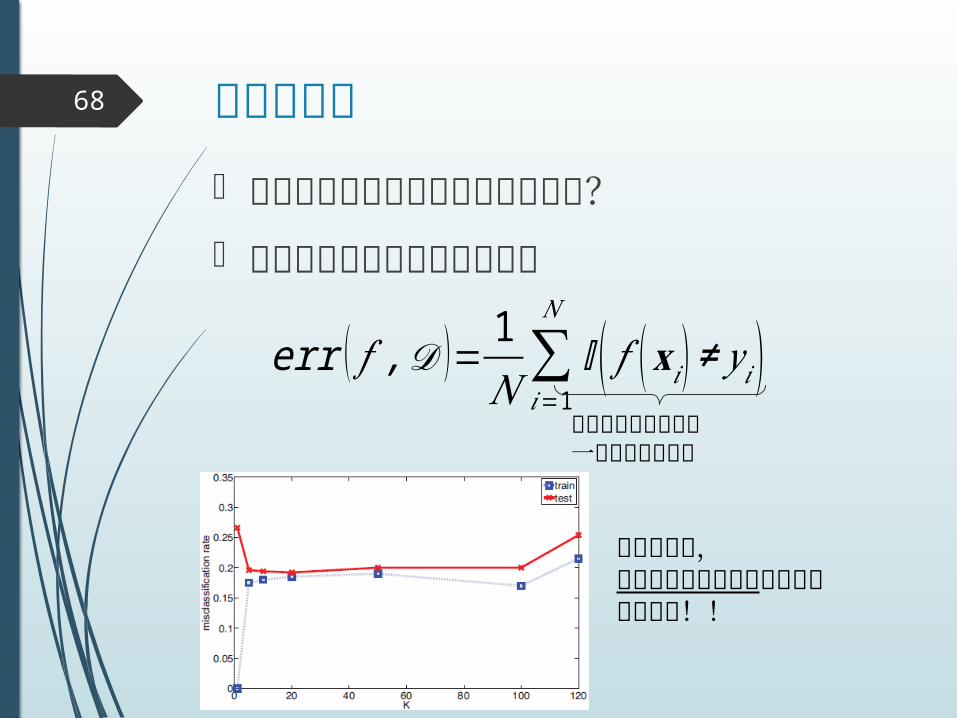
モデル選択68
どの程度複雑なモデルが良いのか? 訓練データに対する誤識別率
err ( 𝑓 ,𝒟 )= 1𝑁∑
𝑖=1
𝑁
𝕀 ( 𝑓 (𝐱𝑖 )≠ 𝑦 𝑖)予測と真のラベルが一致するかどうか
訓練誤差は,テスト誤差の推定値としてはよくない!!
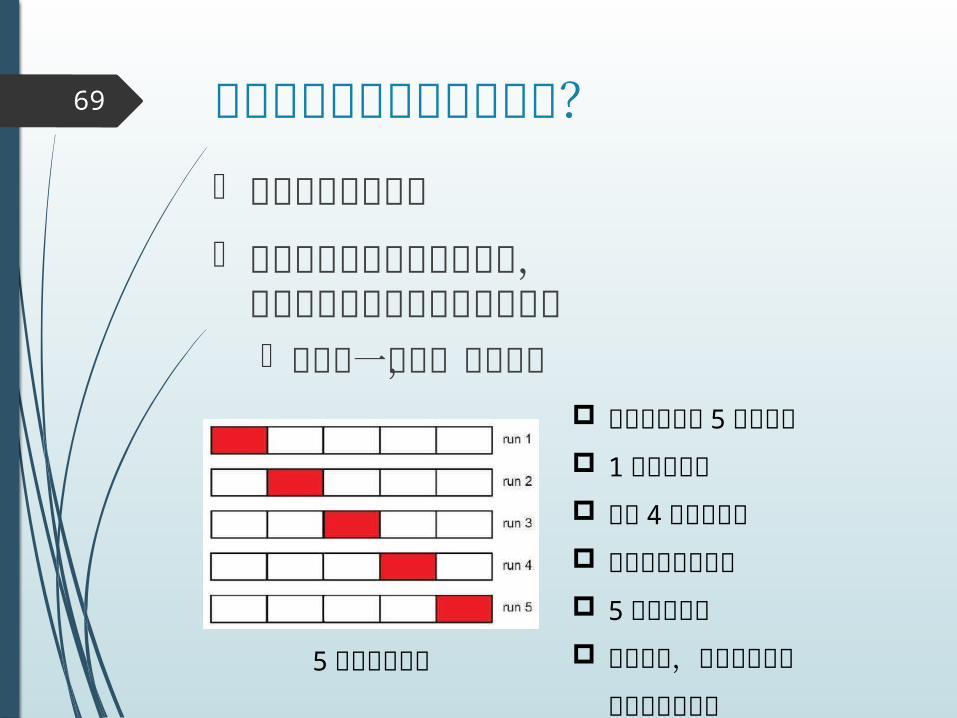
どのようにして選択するか?69
とても難しい問題 テスト誤差が推定できれば,
それに従って選ぶのが良かろう 答えの一つに,交差確認
5 分割交差確認
訓練データを 5 つに分割 1 つは確認用 残り 4 つは訓練用 訓練誤差を求める 5 回繰り返し 平均して,テスト誤差の
推定値とみなす

ノーフリーランチ定理70
あらゆる問題で性能の良い最強の汎用アルゴリズムは存在しないので,その問題に関する知識を持っているならば,その知識を使うべきである
C.f. 醜いアヒルの子定理 (特徴量)

ここまで 1章 長い戦いだった71
ところどころ大事な概念が散らばってる
だが基本的には後の章に書いてある(はず)
72







