
STLab Università di Bologna
!
Knowledge Patterns for the Web: extraction, transformation, and reuse !
! Ph.D. candidate
Andrea Giovanni Nuzzolese [email protected]
!!!!
19 May 2014 - Bologna
Supervisor
Paolo Ciancarini !Tutors
Aldo Gangemi Valentina Presutti

STLab Università di Bologna
• Problem statement
• Knowledge Patterns (KPs)
• Methods and case studies of KP extraction from the Web
• K~ore: a software architecture for experimenting with KPs
• Aemoo: a KP-aware application for entity summarization and exploratory search on the Web
• Conclusion
Outline
2

STLab Università di Bologna3
Problem statement

STLab Università di Bologna4
The Linked Data cloud• The Web is evolving from a global information space of linked
documents to one where both documents and data are linked, known as Linked Data

STLab Università di Bologna5
The knowledge soup and the boundary problem
• What is the information in the Web that provides the relevant knowledge about Barack Obama as a Nobel Prize laureate?
• Interoperability problem: the Web is a knowledge soup because of the heterogeneity of formats, representation schemata and languages
• Relevance problem: It is hard to draw meaningful boundaries around data in order to extract relevant contextual knowledge

STLab Università di Bologna6
What do we need?
• We need structures that organize entities (e.g., Barack Obama) and concepts (e.g., Nobel Prize laureate) according to a unifying view
!
• We need methods for extracting these structures from the Web

STLab Università di Bologna7
Knowledge Patterns

STLab Università di Bologna
• Frames
“…any system of concepts related in such a way that to understand any one of them you have to understand the whole structure in which it fits; when one of the things in such a structure is introduced into a text, or into a conversation, all of the others are automatically made available…” [Fillmore 1968]
“…a remembered framework to be adapted to the reality by changing details as necessary. A frame is a data-structure for representing a stereotyped situation, like being in a certain kind of living room, or going to a child’s birthday party…” [Minsky 1975]
!
• Semantic Web
“…a KP is a formal schema for organizing concepts and relations that are relevant in a specific context…” [Gangemi and Presutti 2010]
8
KPs across disciplines
STLab Università di Bologna9
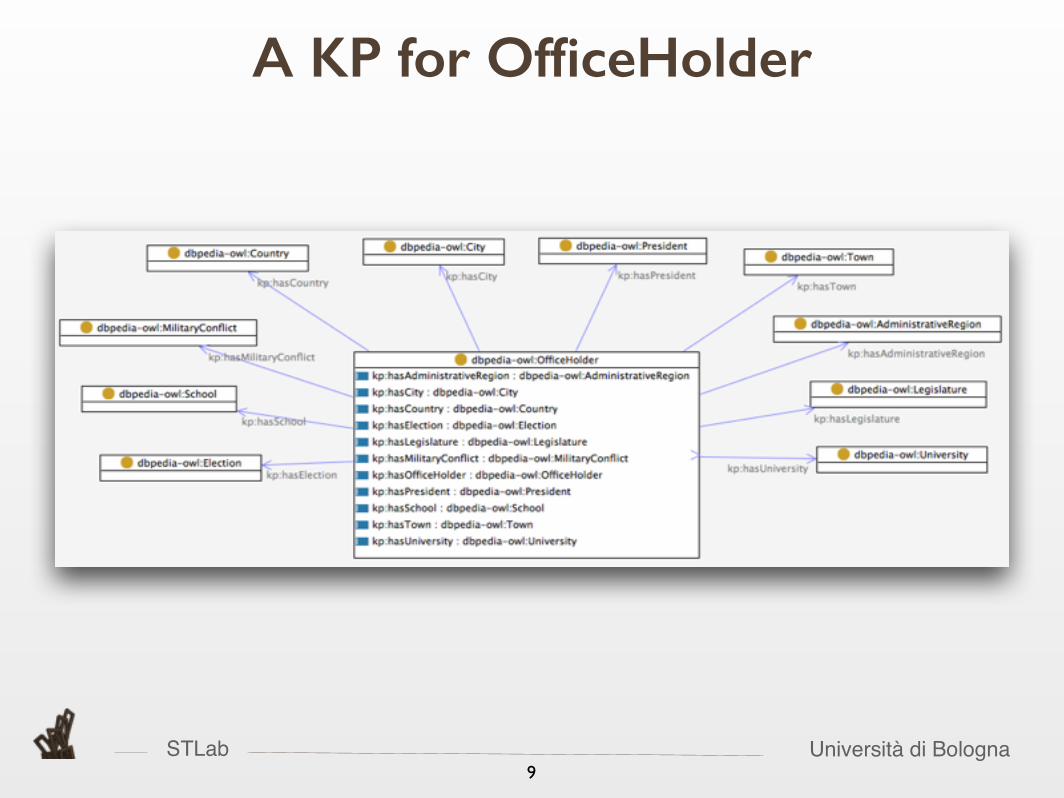
A KP for OfficeHolder

STLab Università di Bologna9
A KP for OfficeHolder
Formal represenation
STLab Università di Bologna9
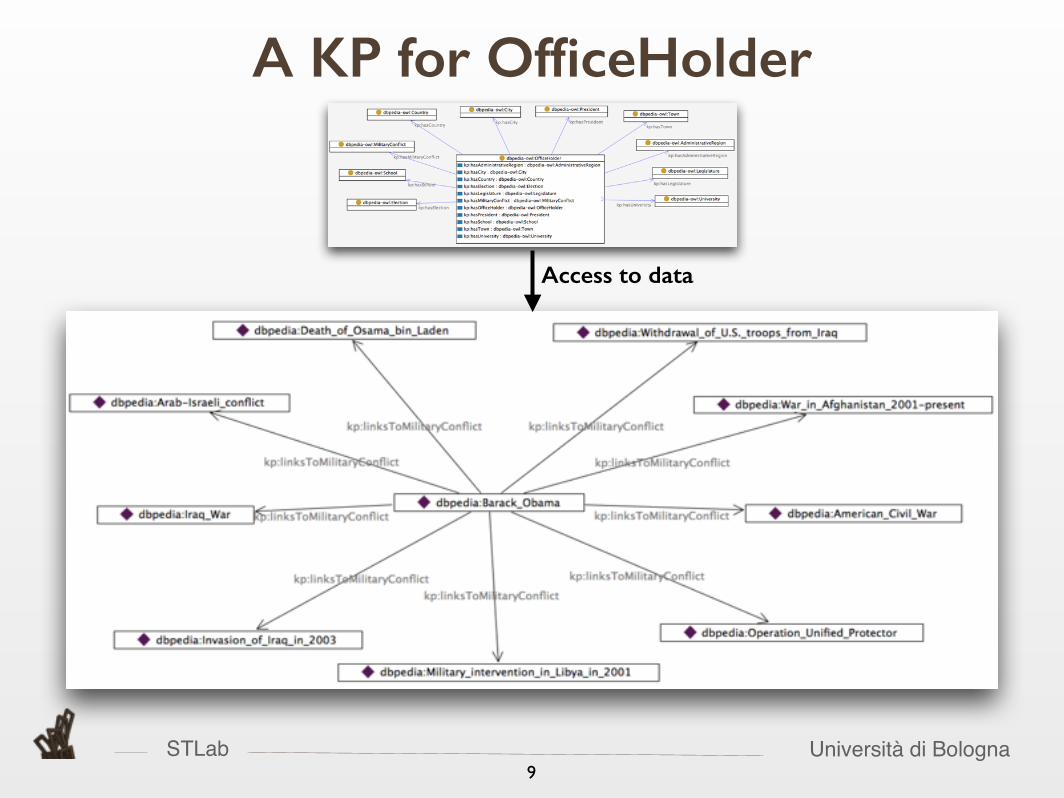
A KP for OfficeHolder
Access to data

STLab Università di Bologna9
A KP for OfficeHolder
Textual grounding
From wikipedia.org

STLab Università di Bologna
• To identify methods for the extraction of KPs from the Web
!
!
!
!
!
• To design a software architecture for KP extraction
• To evaluate the effectiveness of KPs in a knowledge interaction task, e.g., entity summarization and exploratory search
10
My thesis objectives

STLab Università di Bologna11
Knowledge Pattern transformation

STLab Università di Bologna
• To increase syntactic and semantic interoperability, hence to decrease the soup problem
• By homogenizing existing KP-like artefacts expressed in heterogeneous formats, representing them as OWL 2 KPs
12
Motivations

STLab Università di Bologna
• To increase syntactic and semantic interoperability, hence to decrease the soup problem
• By homogenizing existing KP-like artefacts expressed in heterogeneous formats, representing them as OWL 2 KPs
12
Motivations
FrameNet• Examples are

STLab Università di Bologna
ontologydesignpatterns.org
• To increase syntactic and semantic interoperability, hence to decrease the soup problem
• By homogenizing existing KP-like artefacts expressed in heterogeneous formats, representing them as OWL 2 KPs
12
Motivations
• Examples are

STLab Università di Bologna
The Component Library
• To increase syntactic and semantic interoperability, hence to decrease the soup problem
• By homogenizing existing KP-like artefacts expressed in heterogeneous formats, representing them as OWL 2 KPs
12
Motivations
• Examples are

STLab Università di Bologna13
The KP transformation method: Semion

STLab Università di Bologna14
KPs from FrameNet
Syntactic reengineering

STLab Università di Bologna14
KPs from FrameNet
ABox refactoring
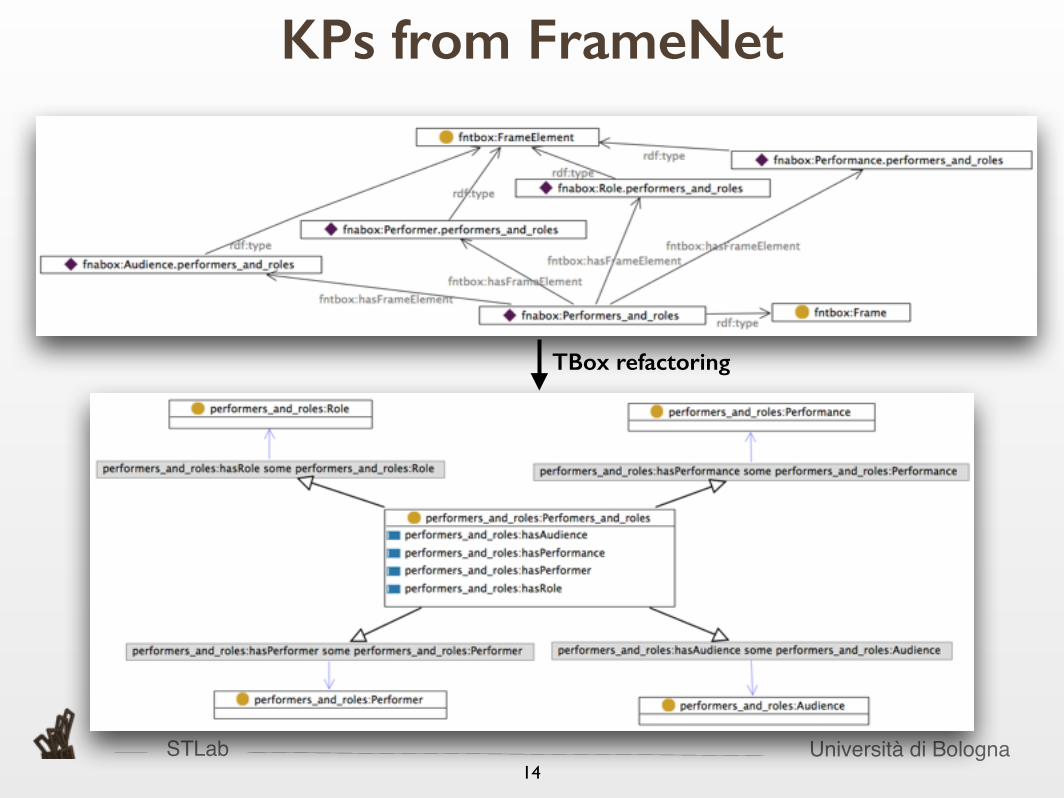
STLab Università di Bologna14
KPs from FrameNet
TBox refactoring

STLab Università di Bologna
• A lexical dataset in Linked Data
• Provides frames as RDF
• Accessible via SPARQL endpoint
• A set of 1024 KPs
• Conceptually equivalent to FrameNet frames, but with explicit formal semantics
• Published on ontologydesignpatterns.org
• Evaluation
• Based on the demonstration of the isomorphism of each transformation step
15
Results

STLab Università di Bologna16
Knowledge Pattern extraction from data

STLab Università di Bologna17
KP extraction: intuition

STLab Università di Bologna17
KP extraction: intuition

STLab Università di Bologna
!
• Motivation
• To address the knowledge boundary problem
!
• Hypothesis
• The linking structure of Linked Data resources conveys a rich knowledge that can be used for KP extraction
• Patterns observed over Linked Data links can be used for drawing meaningful boundaries around data
18
Motivation and hypothesis

STLab Università di Bologna19
Method: key concepts
1. Collect RDF links
2. Index links
3. Collect statistics on indexed links
4. Induce boundaries around data
5. Formalize the KP

STLab Università di Bologna
dbpedia:War_in_Afghanistan
20
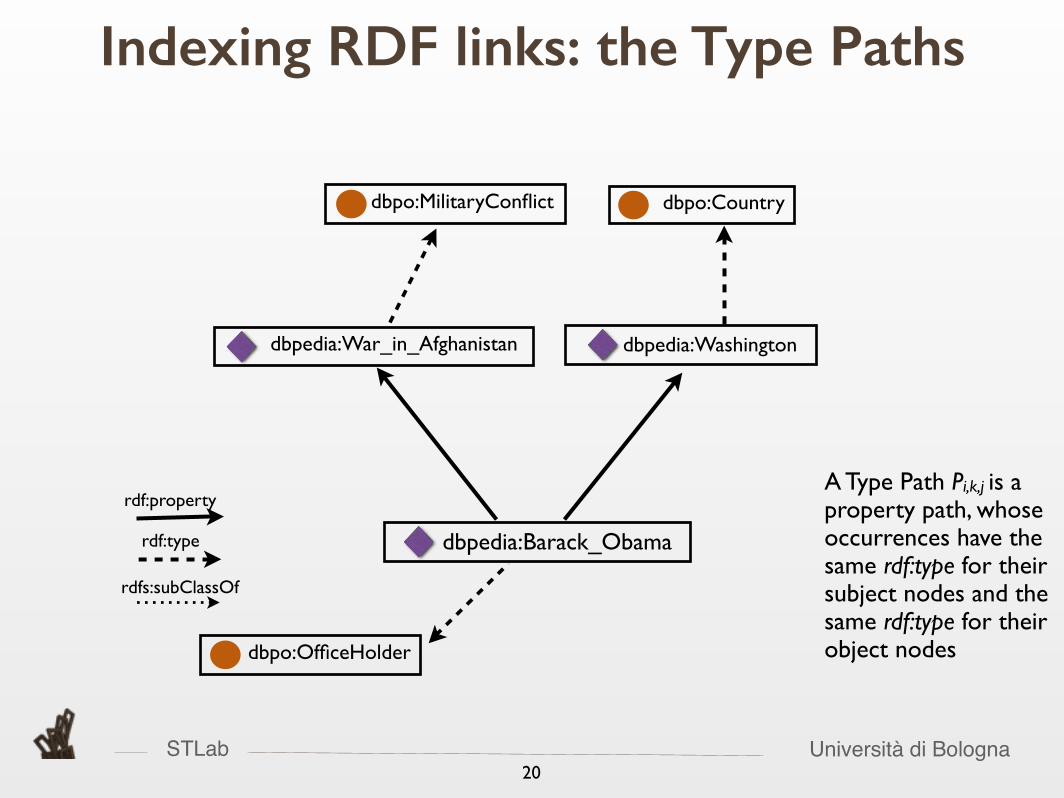
Indexing RDF links: the Type Paths
rdf:propertyA Type Path Pi,k,j is a property path, whose occurrences have the same rdf:type for their subject nodes and the same rdf:type for their object nodes
dbpedia:Washington
dbpedia:Barack_Obama
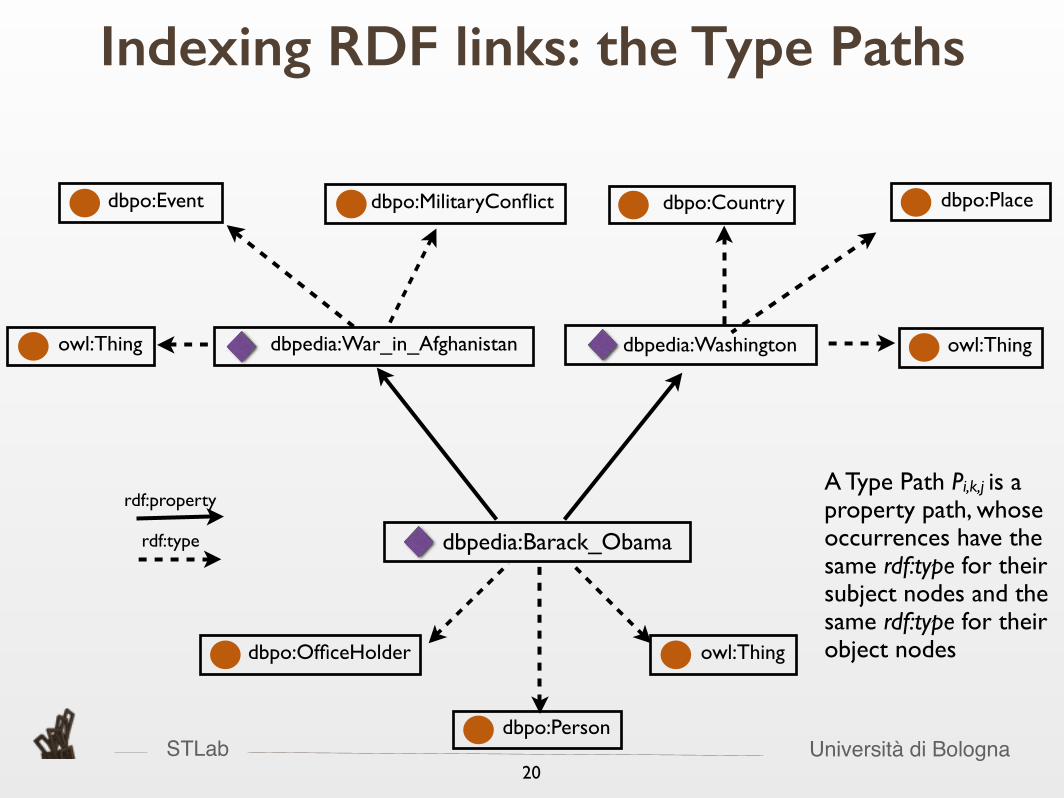
STLab Università di Bologna
dbpedia:War_in_Afghanistan
20
Indexing RDF links: the Type Paths
rdf:type
rdf:propertyA Type Path Pi,k,j is a property path, whose occurrences have the same rdf:type for their subject nodes and the same rdf:type for their object nodes
dbpedia:Washington
dbpedia:Barack_Obama
owl:Thing
dbpo:Event dbpo:MilitaryConflict
owl:Thing
dbpo:Person
dbpo:OfficeHolder
dbpo:Country dbpo:Place
owl:Thing

STLab Università di Bologna
dbpedia:War_in_Afghanistan
20
Indexing RDF links: the Type Paths
rdf:type
rdf:property
rdfs:subClassOf
A Type Path Pi,k,j is a property path, whose occurrences have the same rdf:type for their subject nodes and the same rdf:type for their object nodes
dbpedia:Washington
dbpedia:Barack_Obama
owl:Thing
dbpo:Event dbpo:MilitaryConflict
owl:Thing
dbpo:Person
dbpo:OfficeHolder
dbpo:Country dbpo:Place
owl:Thing
STLab Università di Bologna
dbpedia:War_in_Afghanistan
20
Indexing RDF links: the Type Paths
rdf:type
rdf:property
rdfs:subClassOf
A Type Path Pi,k,j is a property path, whose occurrences have the same rdf:type for their subject nodes and the same rdf:type for their object nodes
dbpedia:Washington
dbpedia:Barack_Obama
dbpo:MilitaryConflict
dbpo:OfficeHolder
dbpo:Country
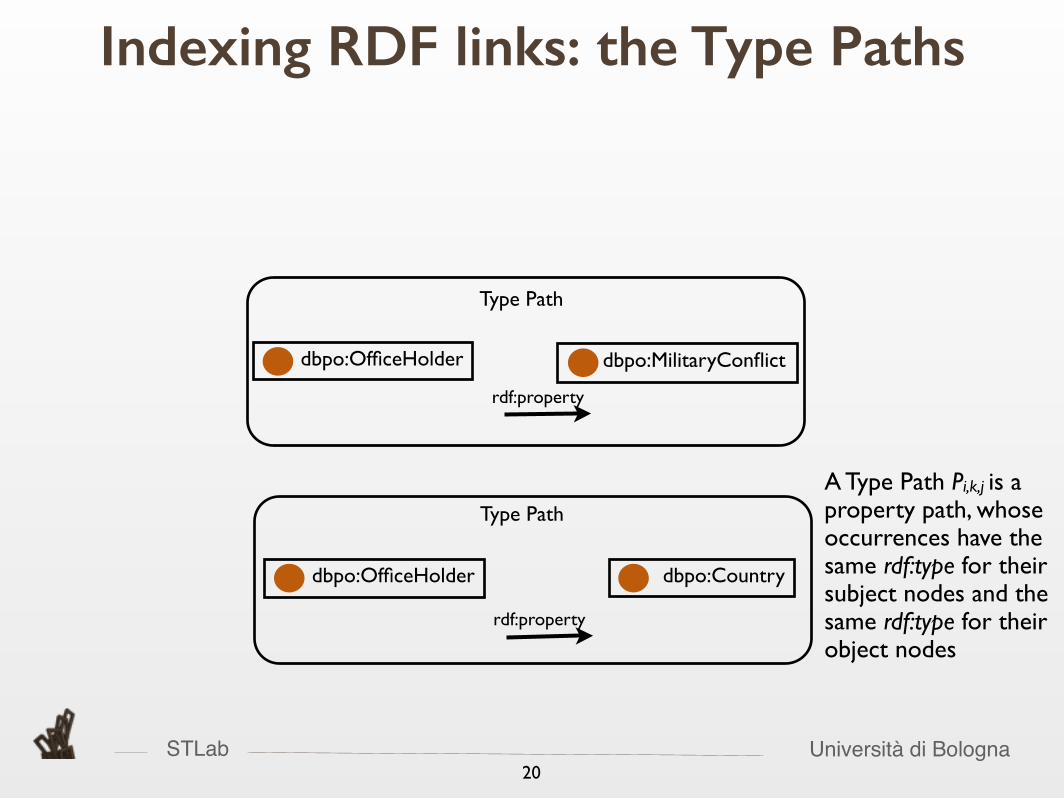
STLab Università di Bologna20
Indexing RDF links: the Type Paths
rdf:property
Type Path
Type Path
A Type Path Pi,k,j is a property path, whose occurrences have the same rdf:type for their subject nodes and the same rdf:type for their object nodes
dbpo:MilitaryConflict
dbpo:OfficeHolder dbpo:Country
dbpo:OfficeHolder
rdf:property

STLab Università di Bologna
• A KP is a set of type paths, such that
Pi,k,j ∈ KP ⟺ pathPopularity(Pi,k,j) ≥ t
• t is a threshold, under which a type path is not included in an KP
!
• The pathPopularity is the ratio of how many distinct resources of a certain type participate as subject in a path to the total number of resources of that type. E.g.:
• POfficeHolder,wikiPageWikiLink,MilitaryConflict counts of 2500 occurrences in DBpedia
• 20555 individuals belongs to OfficeHolder in DBpedia
• pathPopularity(POfficeHolder,wikiPageWikiLink,MilitaryConflict) = 0.12
!21
Boundaries of KPs

STLab Università di Bologna
• Wikipedia contains a lot of knowledge
• It is a collaboratively edited, multilingual, free Internet encyclopaedia
• It is a peculiar source for KP extraction
• It has an RDF dump in Linked Data, i.e., DBpedia, grounded in a large corpus
• The following design constraints that make KP investigation easier
• Each wiki page describes a single topic, which corresponds to a single resource in DBpedia;
• Wikilinks relate wiki pages. Hence each wikilink links two DBpedia resources, which are typed with DBPO classes
22
Case study: extracting KPs from Wikipedia links
STLab Università di Bologna23
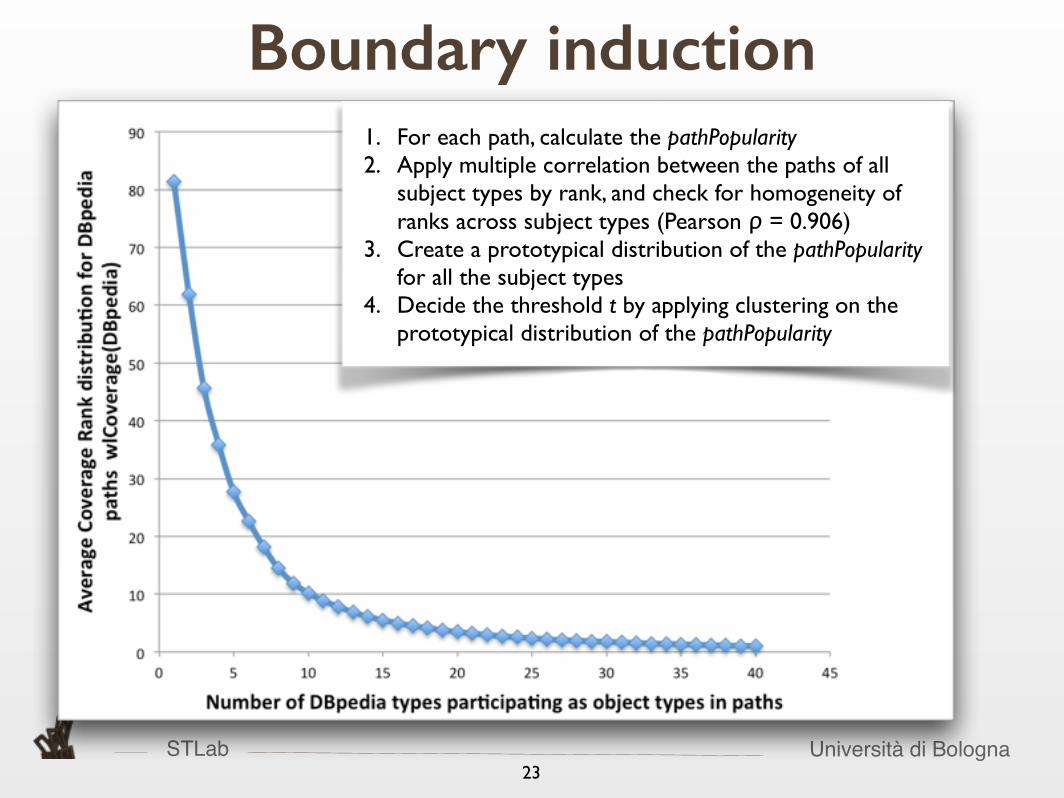
Boundary induction1. For each path, calculate the pathPopularity 2. Apply multiple correlation between the paths of all
subject types by rank, and check for homogeneity of ranks across subject types (Pearson ρ = 0.906)
3. Create a prototypical distribution of the pathPopularity for all the subject types
4. Decide the threshold t by applying clustering on the prototypical distribution of the pathPopularity

STLab Università di Bologna23
Boundary induction1. For each path, calculate the pathPopularity 2. Apply multiple correlation between the paths of all
subject types by rank, and check for homogeneity of ranks across subject types (Pearson ρ = 0.906)
3. Create a prototypical distribution of the pathPopularity for all the subject types
4. Decide the threshold t by applying clustering on the prototypical distribution of the pathPopularity
k-means (4 clusters): • 3 small clusters with ranks above 27,67% • 1 big cluster with ranks below 18,18%

STLab Università di Bologna23
Boundary induction1. For each path, calculate the pathPopularity 2. Apply multiple correlation between the paths of all
subject types by rank, and check for homogeneity of ranks across subject types (Pearson ρ = 0.906)
3. Create a prototypical distribution of the pathPopularity for all the subject types
4. Decide the threshold t by applying clustering on the prototypical distribution of the pathPopularity
k-means (6 clusters): • 1 big cluster with ranks below 11,89% • the 9th rank of pathPopularity is at 11,89% and 9 is
the average number of frame elements in FrameNet
STLab Università di Bologna
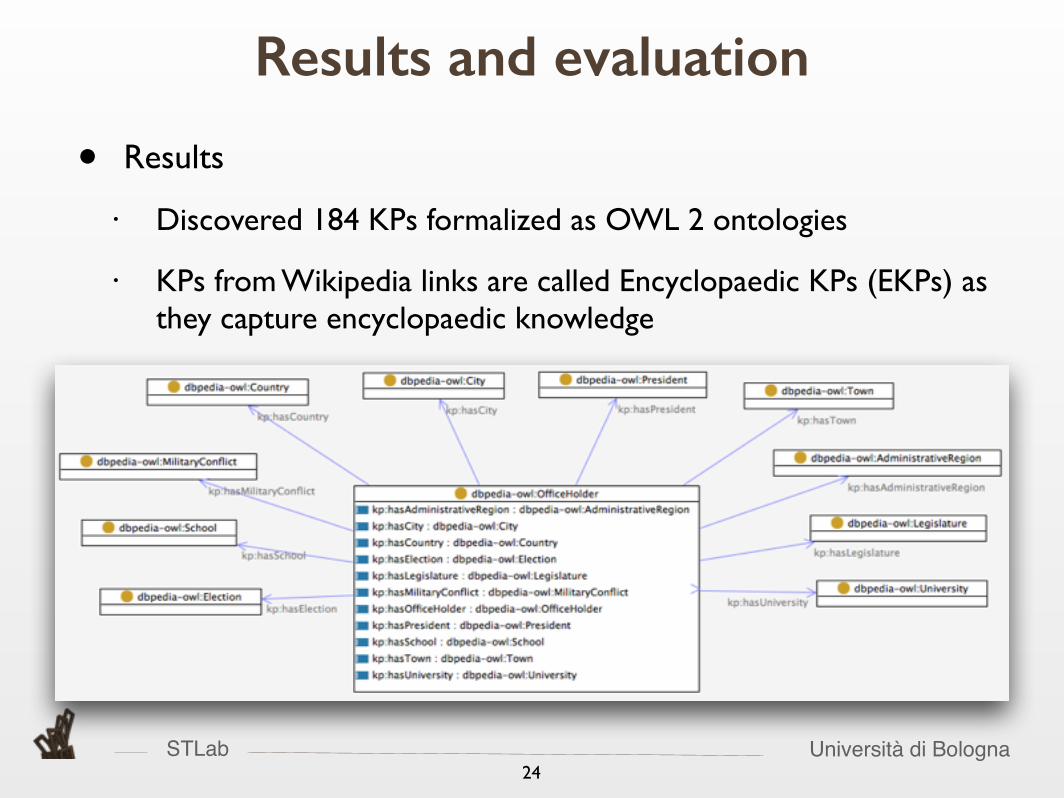
• Results
• Discovered 184 KPs formalized as OWL 2 ontologies
• KPs from Wikipedia links are called Encyclopaedic KPs (EKPs) as they capture encyclopaedic knowledge
24
Results and evaluation

STLab Università di Bologna
• Results
• Discovered 184 KPs formalized as OWL 2 ontologies
• KPs from Wikipedia links are called Encyclopaedic KPs (EKPs) as they capture encyclopaedic knowledge
24
Results and evaluation
• Evaluation
• We conducted a user study asking 17 users to judge how relevant were a number of (object) types (i.e., paths) for describing things of a certain (subject) type, for a sample of 12 DBPO classes
• We compared average multiple correlation (Spearman’s ⍴ ~0.75 on a range [-1, 1]) between users' assigned scores (Kendall’s W among users ~0.68 on a range [0, 1]), and pathPopularity based scores.

STLab Università di Bologna25
Source enrichment

STLab Università di Bologna
• Motivations
• Most of the Web links are untyped and unlabelled hyperlinks
• In many cases RDF statements do not provide typed entities (e.g., 33% of DBpedia entities are untyped)
• The Web knowledge is mainly expressed by means of natural language
• Hypothesis
• Natural language text can be used for generating RDF data suitable for KP extraction
• E.g., a text surrounding anchors in Web pages or annotations in RDF graphs
26
Motivations and hypothesis

STLab Università di Bologna
• Using natural language definitions available in DBpedia abstracts in order to type DBpedia entities
27
Automatic typing of DBpedia entities
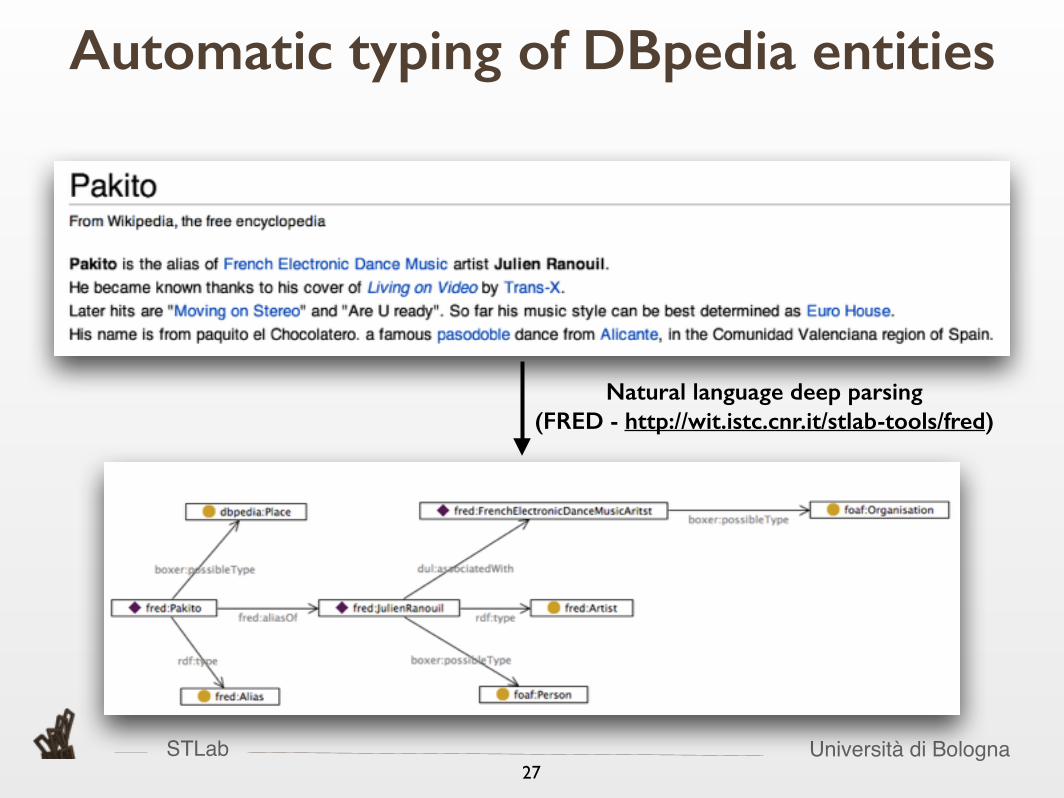
STLab Università di Bologna27
Automatic typing of DBpedia entities
Natural language deep parsing (FRED - http://wit.istc.cnr.it/stlab-tools/fred)

STLab Università di Bologna27
Automatic typing of DBpedia entities
Graph-based pattern matching

STLab Università di Bologna27
Automatic typing of DBpedia entities
Word-sense disambiguation

STLab Università di Bologna27
Automatic typing of DBpedia entities
Ontology Alignment

STLab Università di Bologna28
Results
• ORA: the Natural Ontology of Wikipedia
• Typed 3,023,890 entities with associated taxonomies of types
• Evaluation against a golden standard of the accuracy of types assigned to a sample set of 318 Wikipedia entities
• User study for evaluating the soundness of the induced taxonomy of types for each DBpedia entity
• Kendall’s W: 0.79

STLab Università di Bologna29
Source enrichment: general approach

STLab Università di Bologna29
Source enrichment: general approach
• Based on this approach other applications have been developed so far
• CiTalO: automatic identification of the nature of citations with respect to the CiTO ontology [Di Iorio et al.]
• Sentilo: a semantic sentiment analysis tool [Reforgiato et al.]
• Legalo: automatic uncovering of the semantics of hyperlinks
STLab Università di Bologna30
K~ore

STLab Università di Bologna31
Architecture
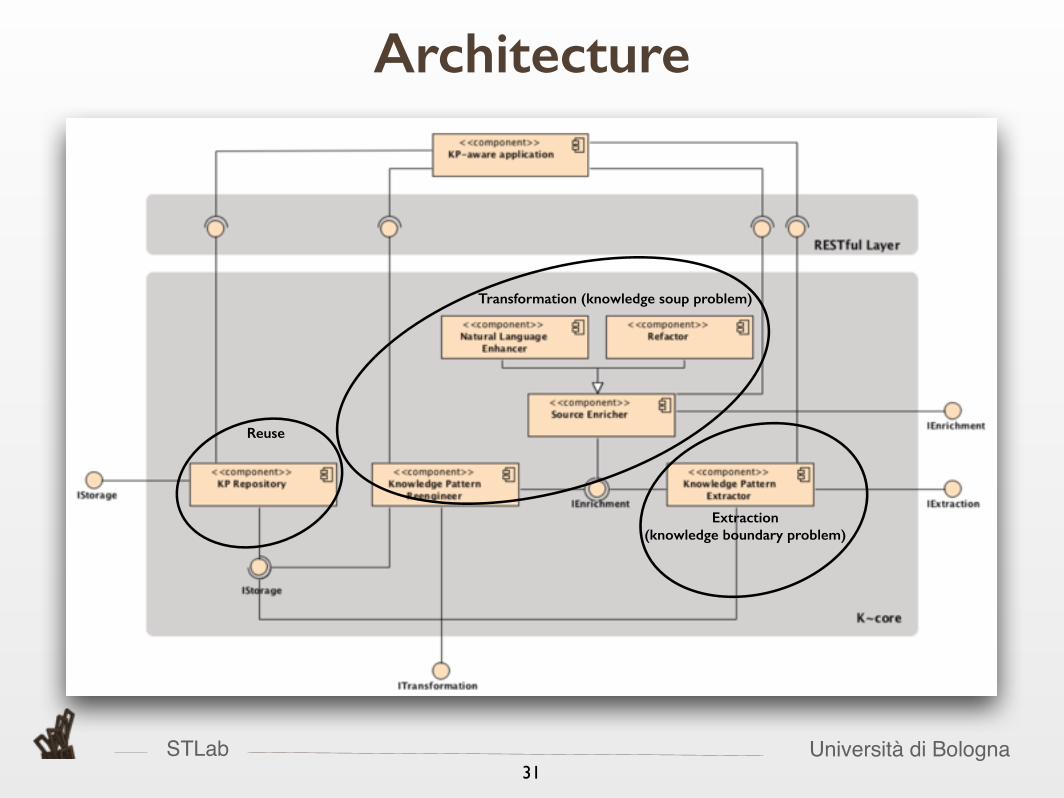
STLab Università di Bologna31
Architecture
Transformation (knowledge soup problem)
Extraction (knowledge boundary problem)
Reuse
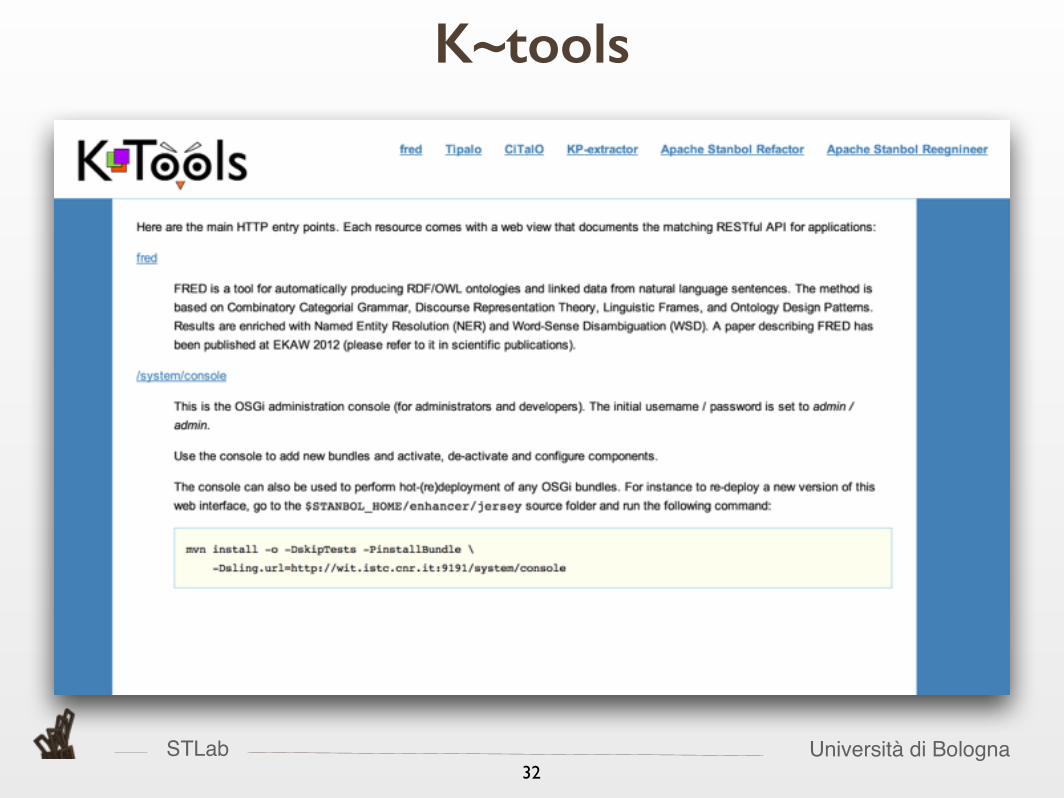
STLab Università di Bologna32
K~tools

STLab Università di Bologna32
K~tools

STLab Università di Bologna32
K~tools

STLab Università di Bologna32
K~tools

STLab Università di Bologna32
K~tools

STLab Università di Bologna33
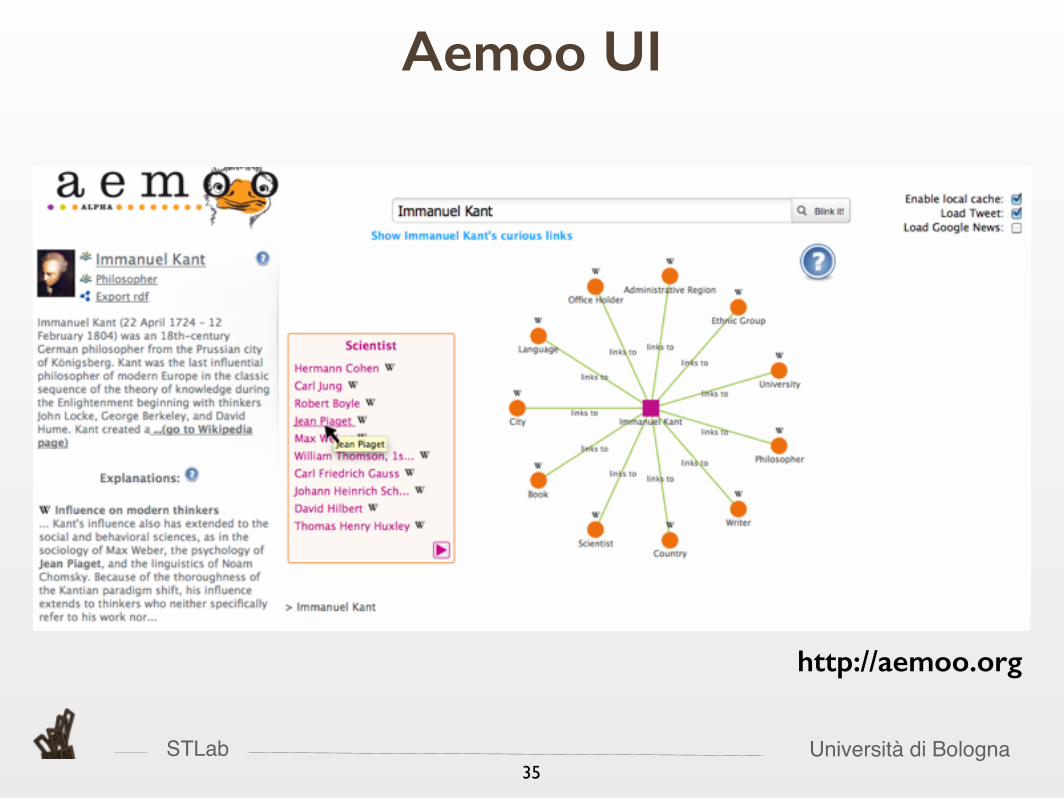
Aemoo

STLab Università di Bologna
• Aemoo is a KP-aware application
• A KP-aware application is a system which
• Benefits from KPs for addressing knowledge interaction tasks
• Uses KPs as the basic unit of mean for representing, exchanging, as well as reasoning with knolwedge
• Aemoo exploits EKPs for
• Entity summarisation and Exploratory search
• Distinguishing between core and peculiar knowledge
• The data sources are Wikipedia, DBpedia, Twitter, and GoogleNews
34
Aemoo in a nutshell
STLab Università di Bologna35
Aemoo UI
http://aemoo.org

STLab Università di Bologna
• We asked to 83 users to use Aemoo, RelFinder and Google for tasks of
• Summarization
• Lookup
• Exploratory search
36
Evaluation

STLab Università di Bologna37
Conclusion• We have provided methodologies for
• KP transformation
• KP extraction
• Source enrichment
• We have designed a software architecture which implements such methodologies
• We have developed a KP-aware application: Aemoo
• We are contributing to the realization of the Semantic Web as an empirical science
• We have generated KPs and published them into a repository for reuse

STLab Università di Bologna
• 16 peer reviewed articles in international conferences and workshops
• V. Presutti, D. Reforgiato A. Gangemi, A. Nuzzolese, S. Consoli. Sentilo: Frame-based Sentiment Analysis. Cognitive Computation, to appear.
• Paolo Ciancarini, Angelo Di Iorio, Andrea Giovanni Nuzzolese, Silvio Peroni, Fabio Vitali: Evaluating Citation Functions in CiTO: Cognitive Issues. In Proceedings of the 11th Extended Semantic Web conference (ESWC 2014). Springer, pp 580-594, Heraklion, Greece, 2014
• A. G. Nuzzolese, V. Presutti, A. Gangemi, A. Musetti, P. Ciancarini. Aemoo: exploring knowledge on the web , In: Proceedings of the 5th Annual ACM Web Science Conference . ACM, pp. 272-275, Paris, France, 2013.
• A. Gangemi, A. G. Nuzzolese, V. Presutti, F. Draicchio, A. Musetti, P. Ciancarini. Automatic typing of DBpedia entities . In: J. Hein, A. Bernstein, P. Cudre-Mauroux, editors, Proceedings of the 11th International Semantic Web Conference (ISWC2012). Springer, pp. 65-91, Boston, Massachusetts, US, 2012.
• A. G. Nuzzolese. Knowledge Pattern Extraction and their usage in Exploratory Search. In: J. Hein, A. Bernstein, P. Cudre-Mauroux, editors, Proceedings of the 11th International Semantic Web Conference (ISWC2012) . Springer, pp. 449-452, Boston, Massachusetts, US, 2012.
• A. G. Nuzzolese, A. Gangemi, V. Presutti, P. Ciancarini. Encyclopedic Knowledge Patterns from Wikipedia Links . In: L. Aroyo, N. Noy, C. Welty, editors, Proceedings of the 10th International Semantic Web Conference (ISWC2011) . Springer, pp. 520-536, Bonn, Germany, 2011.
• A. G. Nuzzolese, A. Gangemi, and V. Presutti. Gathering Lexical Linked Data and Knowledge Patterns from FrameNet . In M. Musen, O. Corcho, editors, Proceedings of the 6th International Conference on Knowledge Capture (K-CAP) , pp. 41-48. ACM, Alberta, Canada, 2011.
38
Publications

STLab Università di Bologna39
Thank you

STLab Università di Bologna40

STLab Università di Bologna
• FrameNet is an XML lexical knowledge base
• Cognitive soundness
• Grounded in a large corpus
• It consists of a set of frames, which have
• Frame elements
• Lexical units, which pair words (lexemes) to frames
• Relations to corpus elements
• Each frame can be interpreted as a class of situations
41
FrameNet

STLab Università di Bologna42
Natural Language Enhancer
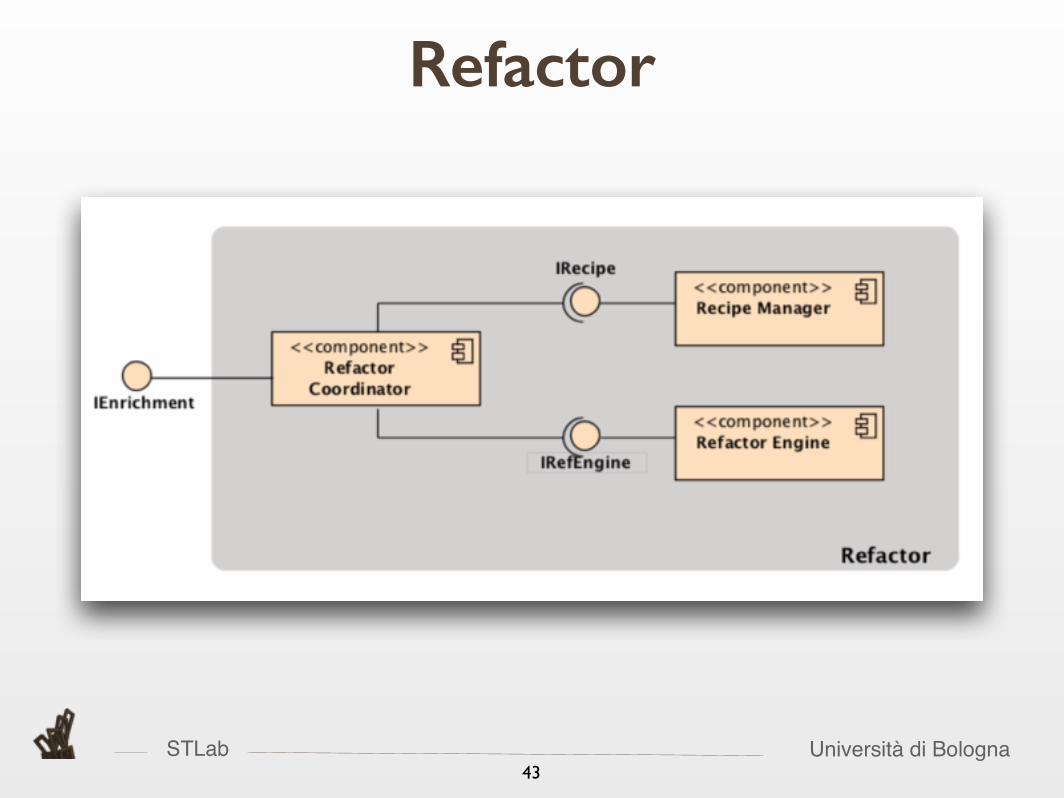
STLab Università di Bologna43
Refactor
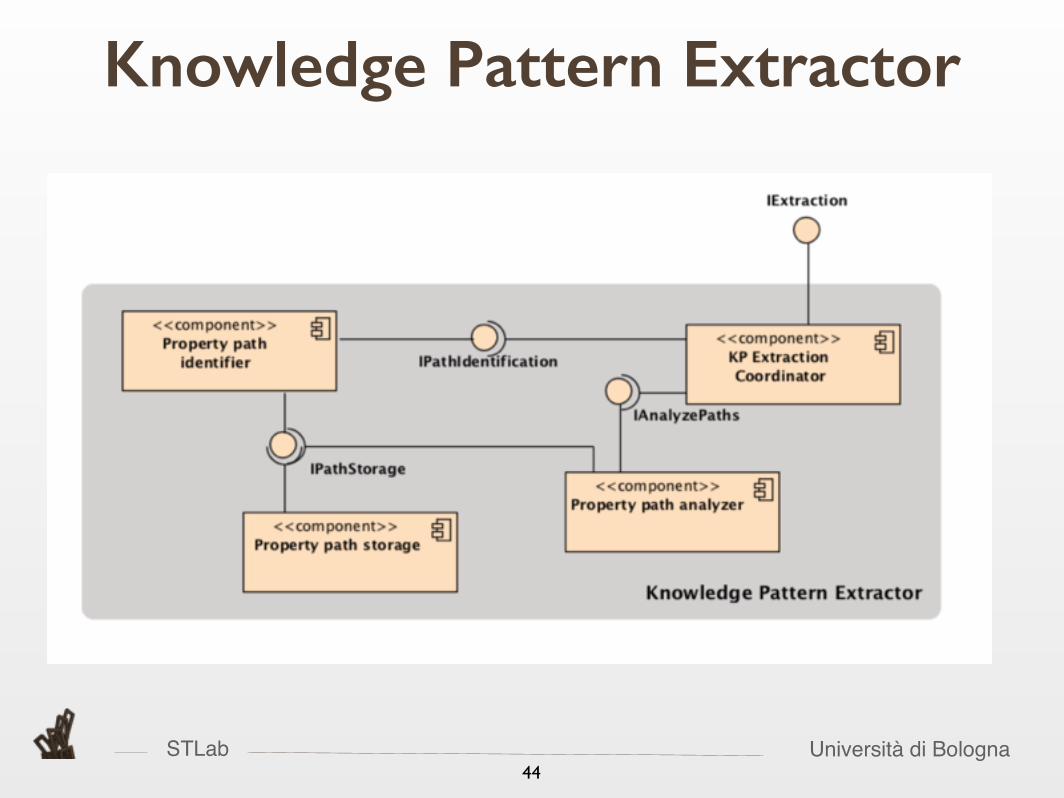
STLab Università di Bologna44
Knowledge Pattern Extractor

STLab Università di Bologna45
Boundary induction
Step Description
1 For each path, calculate the path popularity
2 For each subject type, get the N top-ranked path popularity values
3Apply multiple correlation (Pearson ρ) between the paths of all subject types by rank, and check for homogeneity of ranks across subject types
4 For each of the N path popularity ranks, calculate its mean across all subject types
5 Apply clustering (e.g., k-means) on the N ranks
6 Decide threshold(s) based on the clustering as well as other indicators (e.g., FrameNet roles distribution)
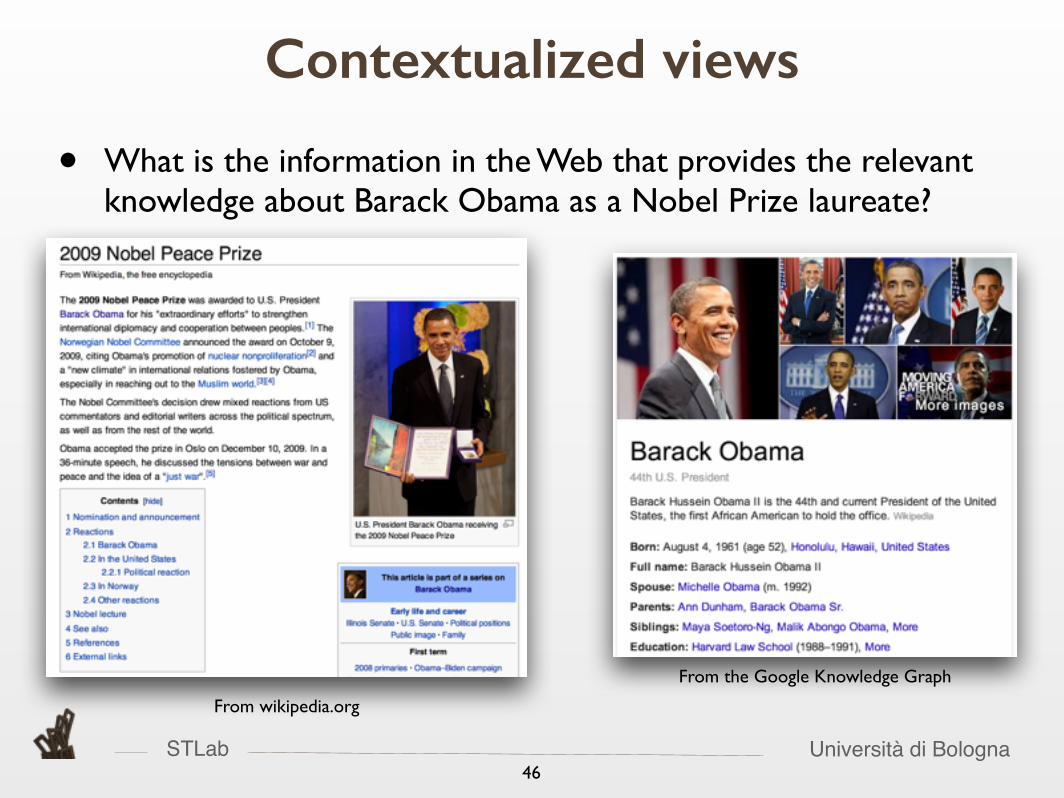
STLab Università di Bologna46
Contextualized views
• What is the information in the Web that provides the relevant knowledge about Barack Obama as a Nobel Prize laureate?
From the Google Knowledge Graph
From wikipedia.org

STLab Università di Bologna
• Linked Data is a breakthrough in Semantic Web for the creation of the Web of Data
• The Web of Data offers large datasets for empirical research
• For the first time in the history of knowledge engineering we have datasets
• Created by large communities of practice
• With a lot of realistic data
• On which experiments can be performed
• The Semantic Web can be founded as an empirical science
• In our vision KPs are the research objects of the Web as an empirical science
47
The Web of Data

STLab Università di Bologna
• They are archetypal solutions to common and frequently occurring design problems
• They were introduced in the seventies by the architect and mathematician Christopher Alexander.
“a good architectural design can be achieved by means of a set of rules that are packaged in the form of patterns, such as “courtyards which live”, “windows place”, or “entrance room” [Alexander 1979]
• They enable design based on reuse
• Software Engineering has eagerly borrowed design patterns
“. . . designers […] look for patterns to match against plans, algorithms, data structures, and idioms they have learned in the past. . .” [Gamma et al. 1993]
48
Design Patterns

STLab Università di Bologna
• Ontologies are artefacts that encode a description of some world
• Like any artefact, they have a lifecycle: they are designed, implemented, evaluated, fixed, exploited, reused, etc.
• An Ontology Design Pattern (ODP) [Gangemi and Presutti 2009] is a modeling solution to solve a recurrent ontology design problem
• Reusability in Ontology Engineering
49
Ontology Design Patterns

STLab Università di Bologna
• A Knowledge Pattern is a small, well connected and recurrent unit of meaning, which provides a semantic interpretation for a symbolic schema. It is
• task based: a KP is associated to an explicit task typically expressed by means of competency questions
• well-grounded: a KP enables access to big data
• cognitively sound: a KP closely mirrors the human ways of organizing knowledge
50
A definition for KP







