Download - IBM Software Group Presentation Template

®
Information Management
© 2005 IBM Corporation
IBM Software Group
Data Warehousing with DB2 for z/OS
Paul [email protected]

Information Management
Agenda
Refocus on Business Intelligence and Data Warehousing
When DB2 for z/OS?
Reference Architecture and Components
Best Practices / Benchmarking
2

Information Management
The terminology as used in this presentation Business Intelligence (BI) and Data Warehousing (DWH) are sometimes
used interchangeablyBI includes end user tools for query, reporting, analysis, dashboarding etc.Both concepts depend on each other BI almost always assumes a Data Warehouse (DWH), Operational Data
Store (ODS) or Data Mart (DM) exists with timely, trusted information– An ODS is a subject oriented database organized by business area.
– up to date (vs. historical)– detailed (vs. summarized).
– A DM is a database designed to support the analysis of a particular business subject area.– data has usually been transformed and aggregated from the source DWH or
operational system– could be relational, multidimensional (OLAP) or statistical in nature.
A DWH depends on end user tools that turn data into information.
Both terms (DWH and BI) address desire for timely, accurate, available data delivered when, where and how the end users want it.
3

Information Management
Traditional TopologyOperational systems
Extract, transform, load
Line of Business Data Marts
Enterprise Data Warehouse
Operational data store
Dependent Data Marts
Independent Data Mart
metadata
ETLmetadata
4

Information Management
DB2 for z/OS: “Back into the ring” July 2006 Announcement
www.ibm.com/common/ssi/rep_ca/1/897/ENUS206-181/ENUS206-181.PDF
Announces availability of products to support the mission
Time is right, shift in customer requirements “Real-Time” data access Service Level Agreements to match Operational Operational BI and Embedded Analytics
Deliver BI to customer facing humans and applications (broad audience)
Integrate BI Components with Operational Systems & Information Portals
Massive number of queries Queries semi-aggregated data, i.e. data
aggregated at a low level
Analyst
Manager
Executive
Customer Service
Customers
1985
2007
< 50
> 10,000
5

Information Management
Operational Business Intelligence and Embedded Content – Customer Service View Operational Content
(red)
6

Information Management
Operational Business Intelligence and Embedded Content –a Customer Service View
Embedded BI Object (blue)
7

Information Management
Operational Business Intelligence and Embedded Content –a Customer Self Service View
Operational Content (red)
Operational Content alone delivers just data to information consumers.
8

Information Management
Operational Business Intelligence and Embedded Content –a Customer Self Service View
Embedded BI Object (blue)
Business Intelligence content puts the data into perspective.
9

Information Management
Dynamic WarehousingA New Approach to Leveraging Information
Dynamic Warehousing
Traditional Data Warehousing
OLAP & Data Mining to Understand Why and
Recommend Future Action
Query & Reporting to Understand
What Happened
Information On Demand to Optimize Real-Time Processes
10

Information Management
DB2 for z/OS features that support DWHing 64-Bit Addressability
2000 byte index keys
MQT’s
Multi-Row Operations
225 way table joins
In-Memory Workfiles
Automatic Space Allocation
Non-Uniform Distribution Statistics on Non-Indexed Columns
Parallel Sorting
Data Partitioned Secondary Indexes
2MB SQL Statements
Etc.
Partition by growth
Index Compression
Dynamic index ANDing
New row internal structure for faster VARCHAR processing
Fast delete of all the rows in a partition
Deleting first n rows
Skipping uncommitted inserted/updated qualifying rows
Etc.
A whitepaper can be downloaded from: http://www.ibm.com/software/sw-library/en_US/detail/A016040Z53841K98.html
11

Information Management
When should I consider… …a Data Warehouse on DB2 for z/OS (zDWH)?
Data requires highest levels of availability, resiliency, security, and recovery
Need true real-time Operational Data Store (ODS) Operational data is on System z ODS must virtually be in sync with the operational data
Embedded Analytics and Operational Business Intelligence OLTP data on System z
Keep existing data marts/warehouses on System z Consolidate data marts/warehouse on System z Implement an enterprise data warehouse (EDW)
SAP Business Warehouse when SAP R/3 is on System z Want to leverage & optimize existing System z skills and investment
to service the mixed workload environment
12

Information Management
DWH Solution Architecture using DB2 for z/OS
Member A
OLTP
CEC One
Member B
OLTP
CEC Two
DB2 DataSharingGroup
CF
CEC One CEC TwoCF
DB2 DataSharingGroupMember C
DWHMember D
DWH
Within a data sharing environment, the data warehouse can reside in the same group as the transactional data.
13

Information Management
DWH Solution Architecture using DB2 for z/OS
OLT
P Lo
catio
nAl
ias
Resources
Transactional Applications
Analy tical Applications
OLTP Subsy stemMEMBER A
OLTP Subsy stemMEMBER B
OLTP Subsy stemMEMBER C
OLAP Subsy stemMEMBER D
OLAP Subsy stemMEMBER E
WLM /I R D
OLA
P Lo
catio
nAl
ias
Centralized and Consolidated
Transactional and Warehouse data in one system
All members see all data, but each member is optimized for a particular workload
Location aliases for transaction routing
Shared Resources managed by Workload Manager (WLM) and the Intelligent Resource Director (IRD)
Single subsystem option for non-data sharing environments
14

Information Management
Initial load of the Data Warehouse
Member A
OLTP
Member B
OLTP
CEC One CEC TwoCF
Member C
DWH
Member D
DWHETL Accelerator
pSeriesxSerieszLinux
ETL is done, by using an ETL Accelerator which in it’s current implementation is represented by DataStage (IBM Information Server) on a secondary system. Until end of 2007, pSeries and xSeries are the only supported systems. Later on the ETL Accelerator will move to zLinux as soon as the Information Server is available there.
Extract
Load
ExtractJDBC/ODBC
Software AGAdabas
VSAM,IAM &
sequential
CA IDMS
CA Datacom
IMS
Classic Federation Server
z/OS
DB2 UDBfor LUW
Oracle SQL Server
Distributed Data Sources- Integration -
ExtractJDBC/ODBC
The data is extracted from the OLTP information of the data sharing group, transformed by DataStage and then loaded into the data warehouse tables again.
Legacy data sources are integrated through the Classic Federation Server. This way data is extracted from DataStage directly out of the data sources like IMS, VSAM…
Distributed data sources are directly integrated through the IBM Information server.
Dat
aSta
ge P
aral
lel E
ngin
e
15

Information Management
Access to Data Outside of DB2 for z/OS
DataServer MetaData
IMS VSAM AD ABAS IDMS
ConnectorConnectorConnectorConnector
Relational Query Processor
WebSphere Classic Federation
Classic DataArchitect
DataStageETL Server
DB2 DataWarehouse
SQL via JDBC / ODBC
Mapping information from legacydata source to relational model,updated through DataServer byClassic Data Architect.
The ETL server does a read accesson the legacy data sources via SQLjust as to any other relationaldatabase through the ODBC driver.The data is then stored in stagingtables or already aggregated in theDB2 warehouse database.
Integrate data into the DWH
All data access appears relational
Mapping with Classic Data Architect
ETL Server access the data via ODBC / JDBC
16

Information Management
Incremental Updates at Runtime
LegacyData
Source
LoggerExit
ChangeCaptureAgent
Correlation Service
DataServer MetaData
Relational Query Processor
WebSphere Classic Data Event Publisher
Distribution Service
Publisher
UpdatingApplication
Classic DataArchitect
DataStageETL Server
DB2 DataWarehouse
WebSphereMQ
SQL via JDBC
There is more than one queue set upfor the distribution of the event. TheEvent Publisher also makes use of anadministrative queue used forsynchronization and a recovery queueused of the logger exit failed.
DataStage is able to readthe change events directlyfrom WebSphere MQ andstores the changes withinthe DB2 data warehouse.
This is any application which is updatingthe legacy (IMS, VSAM, IDMS, ADABAS...)data source.
Change Capture Agent detects changes in data sources
Correlation Service maps the data
Distribution Service and Publisher send the data to the ETL Server via MQ
DataStage reads from MQ and stores the changes in the warehouse with low latency
Optionally stack up in staging tables for batch window
17

Information Management
In Database ETL is triggered by DataStage
Member A
OLTP
Member B
OLTP
CEC One CEC TwoCF
Member C
DWH
Member D
DWHETL Accelerator
pSeriesxSerieszLinux
Simple example:
-- Aggregate by salary by department into AGGRSALARY
INSERT INTO AGGRSALARY ( DEPTCODE, AVGBAND, AVGSALARY ) SELECT DEPTCODE, AVG( BAND ) AS AVGBAND, AVG( SALARY ) AS AVGSALARY FROM STAFF GROUP BY DEPTCODE
Wherever possible, “In Database” transformations (ELT) are used to spare the transport of the data to the accelerator. But the used SQL is still sent from the ETL Accelerator to the database to have one place of documentation for all ETL steps. This can also be used to shift the data up the hierarchy within the Layered Data Architecutre.
SQLETL
18

Information Management
Information Server
Data Transformation and Cleansing
All data can be deployed as a SOA Services and fed to the Information Server
Cleanse Extract / Transform
DataStage®QualityStage™
19

Information Management
Enterprise Data Warehouse using DB2 for z/OSThe Complete Solution Architecture
DB2 DataSharingGroup
WebSphere Classic Federation
LegacyDataSource
LegacyDataSource
WebSphere Classic Data EventPublisher
DataStage
QualityStage
MetaData
Inf ormationServ er
Insert/UpdateExtract /Query
SOA Server
WebSphere MQ
z/OS zLinux/xLinux/AIX.. .
ODBC
Analy t ics andReport ingBI Query Workload
Data warehouse, Transf ormationand Deployment
Fede
ratio
n and
Cha
nge C
aptu
re
20

Information Management
Enterprise Data Warehouse using DB2 for z/OSThe Complete Solution Architecture – Zoom Out
OLT
P Lo
catio
nAl
ias
Resources
Transactional Applications
Analy tical Applications
OLTP Subsy stemMEMBER A
OLTP Subsy stemMEMBER B
OLTP Subsy stemMEMBER C
OLAP Subsy stemMEMBER D
OLAP Subsy stemMEMBER E
WLM /I R D
OLA
P Lo
catio
nAl
ias
DataServer MetaData
IMS VS AM AD AB AS IDMS
ConnectorConnectorConnectorConnector
Relational Query Processor
WebSphere Classic Federation
Class ic DataArchitect
DataStageETL Server
DB2 DataWarehouse
SQL via JDBC / ODBC
Mapping information from legacydata source to relational model,updated through DataServer byClass ic Data Architect.
The ETL server does a read accesson the legacy data s ources via SQLjust as to any other relationaldatabas e through the ODBC driver.The data is then s tored in s tagingtables or already aggregated in theDB2 warehouse database.
LegacyData
Source
LoggerExit
ChangeCaptureAgent
Correlation Service
DataServer MetaData
Relational Query Processor
WebSphere Classic Data Event Publisher
Distribution Service
Publisher
UpdatingApplication
Classic DataArchitect
DataStageETL Server
DB2 DataWarehouse
WebSphereMQ
SQL via JDBC
There is more than one queue set upfor the dis tribution of the event. TheEvent Publisher also makes use of anadministrative queue used forsynchronization and a recovery queueused of the logger exit failed.
DataStage is able to readthe change events directlyfrom WebSphere MQ andstores the changes withinthe DB2 data warehouse.
This is any application which is updatingthe legacy (IMS, VSAM, IDMS, ADABAS...)data source.
DB2 DataSharingGroup
WebSphere Classic Federat ion
LegacyDataSource
LegacyDataSource
WebSphere Classic Data Ev entPublisher
DataStage
Quality Stage
MetaData
Inf ormationServer
Insert/UpdateExtract/Query
SOA Server
WebSphere MQ
z/OS zLinux/xLinux/AIX.. .
ODBC
Analy t ics andReport ingBI Query Workload
Data warehouse, Transf ormationand Deployment
Fede
ratio
n and
Cha
nge C
aptu
re
Cleanse Transform
DataStage®QualityStage™
AlphaBlox
DataQuant
QMF
21

Information Management
Alternative Architectures (Reporting & Analytics)
“Pure” System z BI Solution from a Data Perspective ODS, DWH, DMs in DB2 z/OS End User Tools (e.g. QMF, DataQuant, Business Objects,
Cognos) access DB2 z/OS directly (fat client implementation) or via browser (web server implementation)
Reporting solution may run on distributed WAS, e.g. Alphablox, QMF, DataQuant, Cognos ReportNet, Business Objects Server
“Hybrid” BI Solution from a Data Perspective ODS & Data Warehouse in DB2 z/OS Relational, Multidimensional (OLAP) and Statistical Datamarts
on System p and/or System x supporting End User Tools, e.g. DB2 DWE, Hyperion Essbase, Cognos PowerPlay
22

Information Management
Best Practices
Accurate requirements for solution right-fit
Demonstration and POC systems
Boblingen Lab
BI CoC / Teraplex Center Equivalent
Papers in progress
Work with IBM
23

Information Management
Capacity PlanningCritical Elements
Number of Users
Amount of Data
Size and Complexity of Query Workload
Growth in Maintenance Workload
Critical System Resources for a Balanced System
CPU
Central Storage
I/O Channels
Controllers (storage directors, cache, non-volatile storage) and disk
Parallel Sysplex / Coupling Facility Resources (links, CPU, storage).
24

Information Management
DB2 Sizing Tool Model based on workloads that
were run in IBM Lab environments Continually refined Classify queries into 5
categories Provide query category
definitions Specify % of data “touched” in
each query category Request size of data
warehouse Compute Large Systems
Perfromance Reference (LSPR) ratios for data warehouse workload
Compute required capacity including zIIP offload percentage
Alternate method - build a prototype and profile your own workload
Consider starting small and growing incrementally (benefit of System z DWH environment)
Query Profiles
Average # of Queries
Type of QueriesTrivial Online
Complex Online
Complex AdHoc
……
Output
CPU%
zIIP Offload%
Processor
25

Information Management
1. Business Intelligence applications via DRDA® over a TCP/IP connection
2. Complex Parallel Queries Star schema parallel queries (available June 30, 2006) All other parallel queries (available July 31, 2006)
3. DB2 Utilities for Index Maintenance
zIIP Specialty Engine
IBM zIIP leveraged by DWH workloads
http://www.ibm.com/systems/z/ziip
26

Information Management
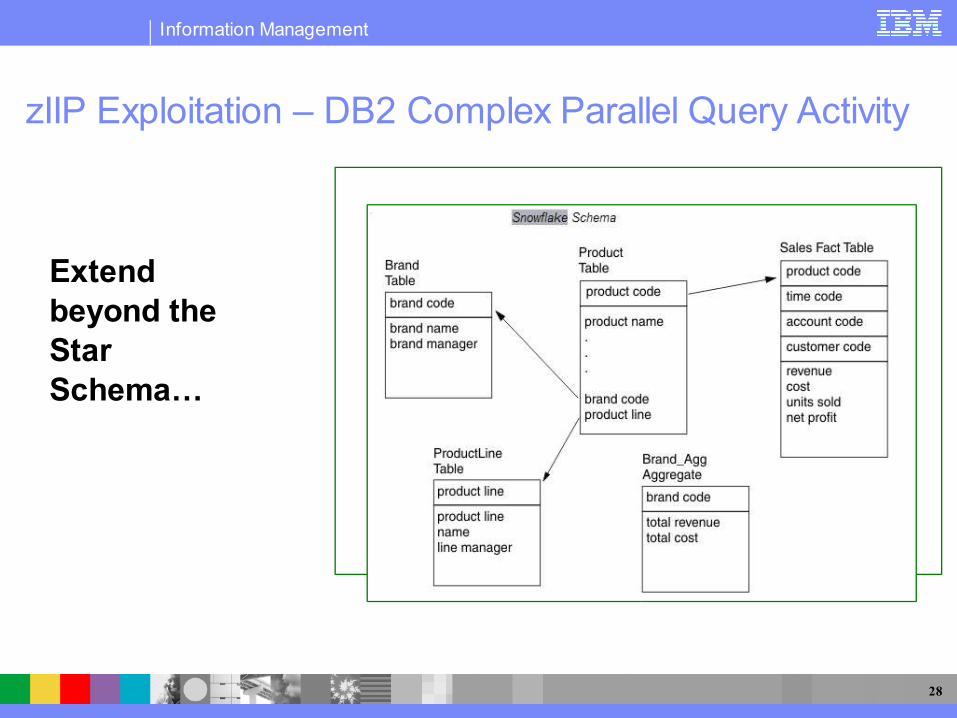
Star schema = a relational database schema for representing multidimensional data
Sometimes graphically represented as a ‘star’Data stored in a central fact table Surrounded by additional dimension tables holding information
on each perspective of the dataExample: store "facts" of the sale (units sold, price, ..) with
product, time, customer, and store keys in a central fact table. Store full descriptive detail for each keys in surrounding dimension tables. This allows you to avoid redundantly storing this information (such as product description) for each individual transaction
Complex star schema parallel queries include the acts of joining several dimensions of a star schema data set (like promotion vs. product).
If the workload uses DB2 for z/OS V8+ to join star schemas, then portions of that DB2 workload will be eligible to be redirected to the zIIP.
What is Star Schema?
27
Information Management
zIIP Exploitation – DB2 Complex Parallel Query Activity
Extend beyond the Star Schema…
28

Information Management
Star schema workloads may benefit from two redirected tasks1. ‘Main’ task = the DRDA request
If the request is coming in via DRDA via TCP/IP it can take advantage of the DRDA use of zIIP, just like any other network attached Enterprise Application.
2. ‘Child’ task = the star schema parallel queries
If the business intelligence and data warehousing application uses star schemas, then a significant amount of this task (star schema) processing is eligible to be redirected to the ziip.
The child (star schema) & main tasks (coming in through DRDA via TCP/IP) are additive. Combining the child and the main tasks is expected to yield a larger amount of redirect than
that of just DRDA via TCP/IP alone.
Longer running queries see higher benefit.
Benefits to a data warehousing application may vary significantly depending on the details of that application.
Focus on Star Schema
29

Information Management
For illustrative purposes only. Single application only.
Actual workload redirects may vary depending on how long the queries run, how much parallelism is used, and the number of zIIPs and CPs employed
Complex star schema parallel queries via DRDA over a TCP/IP connection will have portions of this work directed to the zIIP
BI Distributed with parallel complex query
High utilization
Reduced utilization
DB2/DRDA/StSch
DB2/Batch
BI
Application DB2/DRDA/StSch
DB2/DRDA
DB2/DRDA
DB2/DRDA
DB2/DRDA
DB2/DRDA/StSch
DB2/DRDA/StSch
TCP/IP(via Network or HiperSockets™)
CP
Portions of eligible DB2 enclave SRB workload executed on zIIP
DB2/DRDA
DB2/DRDA/StSch
DB2/DRDA/StSch
DB2/DRDA
DB2/DRDA/StSch
DB2/DRDA
DB2/DRDA/StSch
DB2/DRDA/StSch
zIIP
DB2/DRDA/StSch
DB2/Batch
DB2/DRDA
DB2/DRDA
DB2/DRDA
CP
30

Information Management
1. Query enters system
2. Sliced into Parallel tasks, classified via WLM
3. Each parallel task of the query accumulates Service Units, with the total aggregated across all tasks to determine when to invoke period switch.
WLM definition:Period 1 - Importance 2, 1000 SUs
Period 2 - Importance 4, 4000 SUs
Period 3 - Importance 5, “the rest”
Query requires 50,000 SUs to complete
Before zIIP PTFs
WLM/DB2
GCP GCP GCP GCP GCP Assuming even distribution/usage across all 5 CPs:
•After 200 SUs on each CP (total 1000 for query), move tasks to Period 2
•After 800 more SUs on each CP (overall total of 5000 for query), move tasks to Period 3
31

Information Management
1. Query enters system
2. Sliced into Parallel tasks, classified via WLM
3. Each parallel task of the query accumulates Service Units, with period switch determined for each task, not the overall query.
Same WLM definition Period 1 - Importance 2, 1000 SUs
Period 2 - Importance 4, 4000 SUs
Period 3 - Importance 5, “the rest”
Query requires 50,000 SUs to complete
After PTFs – zIIP redirect execution
WLM/DB2
GCP GCP GCP zIIP zIIP
• After a task gets 1000 SUs on CP/zIIP, move it to Period 2 (total of 5000 SUs for overall query)
•After 4000 more SUs on CP/zIIP, move the task to Period 3 (accumulated total of 25,000 SUs for overall query)
If query uses 5 parallel tasks and assume no zIIPonCP time:
• 2680 SUs run on CP in Period 1
• 2320 SUs run on zIIP in Period 1
• 4000 SUs run on CP in Period 2
• 16000 SUs run on zIIP in Period 2
• 5000 SUs run on CP in “the rest”
• 20000 SUs run on zIIP in “the rest”
32

Information Management
zIIP redirect
zIIP processors offer significant hardware and software savings.
Number of zIIP processors can not be more than the number of general processors in a physical server. However, an LPAR can be configured to contain more zIIPs than general processors.
A percentage of parallel task activities are eligible to run on zIIP. Actual offload percentage depends on: Ratio of parallel to non-parallel work
Thresholds
Available zIIP capacity
RMF and OMEGAMON reports provide projection of offload percentage prior to installation of zIIP processors, but actual offload will probably be slightly lower. z/OS dispatcher algorithm
Benchmark and internal workloads indicates offload between 50% and 80% with a typical mix of queries
33

Information Management
zIIP Experiences
0
2
4
6
8
10
2 CPs 1CP/1 zIIP 2 CPs/1 zIIP
zIIPGen Proc
The dark bars represent the processing cycles consumed by the query workload on the general processing engine, and the blue colored bars reflect the processing that was redirected to the available zIIP engine.
0
2
4
6
8
10
12
2 Gen CPs 2 GenCPs/w/Parallel
2 CPs/1 zIIP
The first bar represents the query processing execution time, without using parallel processing. The second bar represents the same query workload when using parallelism on general processors. The last bar represents the query execution time when leveraging a zIIP engine to complete the processing.
34

Information Management
Speaking of parallelism…… is DB2 for z/OS a “Parallel Database”?
Query I/O parallelism Manages concurrent I/O requests for a
single query, fetching pages into the buffer pool in parallel. This processing can significantly improve the performance of I/O-bound queries.
Query CP parallelism Enables true multitasking within a query.
A large query can be broken into multiple smaller queries. These smaller queries run simultaneously on multiple processors accessing data in parallel reducing the elapsed time for each query. Starting with DB2 V8, the parallel queries exploit zIIPs when they are available on the system thus reducing the costs.
Sysplex query parallelism To further expand the processing capacity
available for processor-intensive queries, DB2 can split a large query across different DB2 members in a data sharing group, known as Sysplex query parallelism.
35

Information Management
DB2 for z/OS Parallelism – Another Graphic
I/O ParallelismSingle Execution UnitMultiple I/O streams
CP ParallelismMultiple Execution UnitsEach has a single I/O stream
SRBs(paralleltasks)
TCB(originating
task)
V3 V4
V5 Sysplex Query ParallelismSysplex Query ParallelismParallel tasks spread across Parallel Sysplex
I/O Channel
Mem ory
Processor
I/O Channel Mem ory
Processor
I/O Channel
Memory
Processor
36

Information Management
Parallel Degree Determination Engine
Number of
I/O
CPU
OptimalDegree
Data skew
CP CP CP CP CP CPNumber of
Processor speed
DB2 for z/OS has the flexibility to choose the degree of parallelism
Degree determination is done by the DBMS -- not the DBAUsing statistics and costs of the query to provide the optimal access path with low overhead taking data skew into consideration
Parallel Task #1Parallel Task #2Parallel Task #3
Parallel Degree Determination
that qualify
37

Information Management
Trust with Limits – Set the Max. Degree of Parallelism
...
CP 0 CP 1 CP 2
Set the maximum degree between the # of CPs and the # of partitions
CPU intensive queries - closer to the # of CPs
I/O intensive queries - closer to the # of partitions
Data skew can reduce # of degrees
38

Information Management
DB2 for z/OS Partitioning (Range) Partitioning in DB2 for z/OS V8 and beyond is defined at the table level
Maximum of 4096 partitions
DB2 can generate a maximum of 254 parallel operations
Effectively cluster by two dimensions
Partition by Growth – DB2 9 feature that relates (in a way) to hash
Secondary Index -- partition eded like the underlying data (DPSI)
Secondary Index -- non-partitioneded (NPSI)
102,
MAR
,MO
103,
DEC
, MI
104,
NO
V, IL
105,
APR
, CT
106,
JAN
, KY
101,
FEB
, DE
203,
OC
T, IA
204,
DEC
, MD
205,
JAN
, AL
206,
FEB
, NC
201,
JU
L, N
J
302,
JU
L, M
D
303,
MAY
,MN
304,
APR
, MS
305,
SEP
, CT
306,
JU
N, N
H
301,
NO
V, L
A
402,
NO
V, IA
403,
MA
R, F
L40
4, F
EB, I
N
405,
JU
N, M
A
406,
OC
T, N
H40
1, S
EP, N
Y
MA
R
DE
C N
OV
AP
R
JAN
FE
B
AU
G O
CT
DE
C
JA
N F
EB
JU
L
JU
L
MA
Y A
PR
SEP
JU
N
NO
V
NO
V
MA
R F
EB
JU
N
OC
T S
EP
Partitioned table
202,
AU
G, F
L
MO
MI
IL KY
DE
FL IA MD
AL NC
NJ
MN
MS
NH
LAIN MA
NY
CT
39

Information Management
Partition by Time Each partition holds data for a certain period
days, weeks, months, years etc.
Possible data skew due to seasonal factors
Ease of operations Enable rolling off old data at regular intervals Back up latest data only Coexistence of data refresh and queries
. . .. . .
Jan 2007
Feb 2007
March 2007
load into current period
empty
Oct2007
Nov2007
Dec2007
. . .
40

Information Management
Partition by Time - Advantages
Queries consume less resources DB2 uses partition scanning vs scanning entire table
Consistent query response times over time Adding history to database does not affect query ET
Potentially smaller degrees of parallelism
Data Rolling – Alter Table Rotate Partition First to Last
2003 2004 2005 2006 2007
archive
data
empty
2005 2006 2007 20082004
After Data Rolling
41

Information Management
Data Compression DB2 compression should be strongly considered in a data warehousing
environment.
Savings is generally 50% or more.
Data warehousing queries are dominated by sequential prefetch accesses, which benefit from DB2 compression.
Newer generation of z processors implement instructions directly in circuits, yielding low single digits of overhead. Index access only - no overhead.
More tables can be pinned in buffer pools.
Index compression supported in V9
42

Information Management
Hardware-assisted data compression
0
20
40
60
80
100
Com
pressed Ratio
Compressed Non-compressed
53%46%
61%
I/O Intensive
CPU Intensive
281
157
283
200
354
412
Elapsed tim
e (sec)
Non-Compressed Compressed 60%I/O Wait I/O WaitCPU
CPU
Compress CPUOverhead
Effects of Compression on Elapsed Time
Compression Ratios
Achieved
43

Information Management
DB2 Compression Study
((
DB2 hardware compression (75+% data space savings)
uncompressed raw data5.3 TB
1.3 TB
indexes, system,work, etc.
1.3 TB
1.6 TB
2.9 TB1.6 TB
6.9 TB
(58% disk savings)
44

Information Management
Workload Management
Traditional workload management approach:
Screen queries before they start execution
Time consuming for DBAs.
Not always possible.
Some large queries slip through the crack.
Running these queries degrades system performance.
Cancellation of the queries wastes CPU cycles.45

Information Management
Workload Management
The ideal workload manager policy for data warehousing:
Consistent favoring ofshorter running work........
with select favoring of criticalbusiness users
keep em shortthrough WLM period aging
through WLM explicit prioritization of criticalusers
** no need to pre-identify shorts either
Think about this:
Large query submitter behavior:
Short query submitter behavior:
Who's impacted more real time ??
expect answer now
expect answer later
Priority
Query
Type
High Medium Low
Long
Medium
Short
Business Importance
Period Ageing
Business Importance
46

Information Management
Query Monopolization
End Users
Processors
Work queue
47

Information Management
Inconsistent Response Times for Short Running Queries
Mon
day
Tues
day
5 secs.
5 mins!
Response Time Workload Activity
48

Information Management
Workload Management
IWEB
DB2
DDF
JES2
OMVS
STC
WLMRules
Service Class
Crit ical
Ad hoc
WarehouseRefresh
Intelligent Miner
Report Class
Market ing
S ales
Test
Head-quarters
Workload Manager Overview
business objectives
monitoring
49

Information Management
Service Classification
CPU Usage
Type textPeriod Duration Performance Goal Importance
1 5,000 Velocity = 80 2
2 50,000 Velocity = 60 2
3 1,000,000 Velocity = 40 3
4 30,000,000 Velocity = 30 45 Discretionary
50

Information Management
Query Monopolization Solution
0
100
200
300
400
500
192 195
48 46
101 95
162 155
base small medium large
Avg responsetime in seconds
12trivial
+4 k
iller
que
ries
10 456174 461181
Killer
50 Concurrent Users Queries
+4 k
iller
que
ries
1468 1726
Runaway queries cannotmonopolize system resources
aged to low priority class
period duration velocity importance 1 5000 80 2 2 50000 60 2 3 1000000 40 3 4 10000000 30 4 5 discretionary
51

Information Management
Consistent Response Time
Avg q
uery
ET
in se
cond
s
Consistent Response Time Consistent Response Time for Short-running work for Short-running work
20 u sers 50 u sers 100 u sers 200 u sers0
20
40
60
80
100
120
000000000000000000
T ri vialS mal lM ed iu mL arg e
52

Information Management
High Priority Queries
CPU Usage
Type textService Class = QUERY
Period Duration Performance Goal Importance
1 5,000 Velocity = 80 1
2 20,000 Velocity = 70 2
3 1,000,000 Velocity = 50 34 Velocity = 30
Service ClassificationService Classification
Service Class = CRITICAL Period Duration Performance
Goal Importance
1 Velocity = 90% 1
53
Information Management
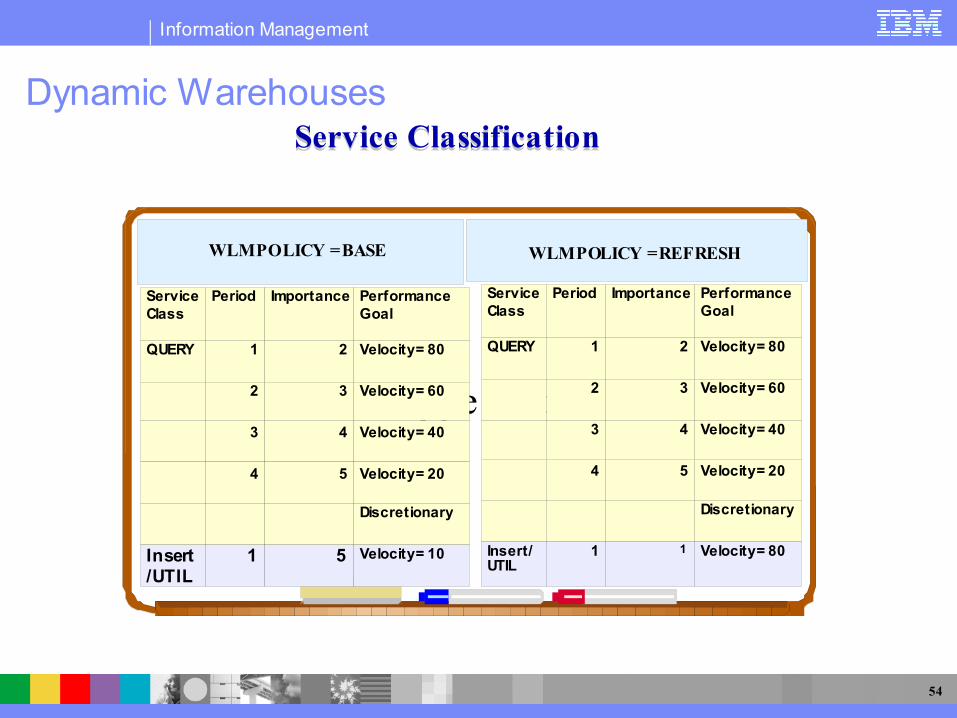
Dynamic Warehouses
Type text
WLM POLICY = BASE WLM POLICY = REFRESH
Service Class
Period Importance Performance Goal
QUERY 1 2 Velocity = 80
2 3 Velocity = 60
3 4 Velocity = 40
4 5 Velocity = 20
Discretionary
Insert/UTIL
1 5 Velocity = 10
Service ClassificationService Classification
Service Class
Period Importance Performance Goal
QUERY 1 2 Velocity = 80
2 3 Velocity = 60
3 4 Velocity = 40
4 5 Velocity = 20
Discretionary
Insert/ UTIL
1 1 Velocity = 80
54

Information Management
Planning for DASD Storage and I/O Bandwidth
Rules of Thumb offered by IBM include allowances for:
Indexes
Tables
Free space
Work files
Active and archive logs
DB2 directory and catalog
Temporary tables
MQTs
Balance bandwidth with available processing power
ROTs available based on current processor ratings
55

Information Management
Implementation
Carefully plan DB2 data set placementBalance I/O activity among different volumes, control units, and channels to minimize I/O elapsed time and I/O queuing
Use DFSMS
Sort Work Files – Large, Many, Spread
Dynamic Parallel Access Volumes (PAV)Multiple Addresses / Unit Control Blocks versus just multiple paths / channels
Modified Indirect Access Word (MIDAW)Increased channel throughput
VSAM Data Striping
Partition
33
Example of Sort WorkfileDistribution with 4 DSG Members
Member ALPAR1.1
Member BLPAR1.2
CEC One
Member CLPAR2.1
Member DLPAR2.2
CEC Two
CF
Vol5
Vol4
Vol3
Vol2
Vol1
SWF A.1SWF B.1SWF C.1SWF D.1SWF A.2SWF B.2SWF C.2SWF D.2SWF A.3SWF B.3SWF C.3SWF D.3SWF A.4SWF B.4SWF C.4SWF D.4SWF A.5SWF B.5SWF C.5SWF D.5
Storage
56

Information Management
Balanced I/O Configuration
Ran tests to show how fast a zSeries processor can scan data with different degrees of SQL complexity.Last tests were based on z900 processorsProjected System z9 scan rates based on LSPR ratio
Will determine System z9 scan rates based on benchmark results (analysis not done yet)
IBM Storage provides tools to your IBM team to project bandwidth of DS8000 subsystems.
Balance CPU and I/O configurations by matching up scan rates.
57

Information Management
SMS Implementation Use DB2 Storage groups (to define and manage data sets) in conjunction with
SMS Storage Classes / Groups (for data set allocation)
Spread tables, indexes and work files
Simple ACS Routines using HLQs to direct datasets to appropriate Storage Class / Storage Group
Storage Groups requiring maximum concurrent bandwidth should consist of addresses spread across the I/O configuration
For Storage Classes, set Initial Access Response Time (IART) parameter to non-zero so SMS will use internal randomization algorithm for final volume selection
TablesIndexes
Work files.. .
58

Information Management
Planning for Central Storage
1.0Working storage size
0.5Code storage size
0.6Data set control block storage size
0.5RID pool size
0.5Sort pool size
1.0Buffer pool size
1.0EDM pool storage size
FactorCategory
Virtual (see also Installation Guide) Real
1 160Region size (below 16-MB line) (assume SWA above the line)
=252 328?Total main storage size (above 16-MB line)
55 800?Working storage size
30 00030 000Code storage size
17 928?Data set control block storage size
8 000?RID pool size
2 000?Sort pool size
104 000?Buffer pool size
33 600?EDM pool storage size
Default [KB]
Your sizeCategory
59

Information Management
Large Memory Configurations
Up to 512 GB of central memory for a single z9 server.
Benchmark workload testing shows improved performance for certain queriesHigher buffer pool hit ratiosReduced number of I/OReduced CPU consumption
Optimal performance requires a good understanding of the query workload and database design
60

Information Management
Noteworthy zPARMs in a Data Warehouse Environment
Default is 15. If changed, setMXQDC=TABLES_JOINED_THRESHOLD*(2**N)-1
MXQDC=15
DISABLE, unless SAP BW on z/OS usedSTARJOIN=DISABLE,
8000(means 8 MB Sort Pool)
SRTPOOL=8000,
#Processors <= X <= 2*#ProcessorsIf concurrency level is low , the ratio can be higher.
PARAMDEG=X,
OPTIORC=ON – explanation???OPTIORC=ON
OPTIXIO=ON: Provides stable I/O costing w ith signif icantly less sensitivity to buffer pool sizes. (This is the new default and recommended setting).
OPTIXIO=ON
enables f ix PK26760 (ineff icient access plan)OPTCCOS4=ON,
NORecommendation: For best performance, specify NO for this parameter. To resolve storage constraints in DBM1 address space, specify YES. See also: CONTSTOR
MINSTOR=NO,
YESSecondary extent allocations for DB2-managed data sets are to be sized according to a sliding scale
MGEXTSZ=YES,
YESThe DB2-managed data set has a VSAM control interval that corresponds to the buffer pool that is used for the table space.
DSVCI=YES,
NOFor best performance, specify NO for this parameter. To resolve storage constraints in DBM1 address space, specify YES. See also: MINSTOR
CONTSTOR=NO,
ANYAllow parallelism for DW.any: parallelism, 1: no parallelism
CDSSRDEF=ANY,
CommentsRecommendation for DWH
61

Information Management
Why DWH on System z?
Qualities of ServiceSuperior QualitySuper AvailabilitySecurity and Regulatory
ComplianceScalabilityBackup and recovery
Positioned for the futureWeb-based applicationsXML supportService Oriented Architecture
(SOA)
Operational data and the ODS together meansReduced complexityReduced costShared processes, tools,
proceduresStreamlined compliance and
security
zIIP specialty engine improves TCO
Better leverage System z skills and investment
62

Information Management
Suggested reading list (The Classics)
DB2 for OS/390 Capacity Planning, SG24-2244
Capacity Planning for Business Intelligence Applications: Approaches and Methodologies, SG24-5689
Building VLDB for BI Applications on OS/390: Case Study Experiences, SG24-5609
Business Intelligence Architecture on S/390 Presentation Guide, SG24-5641
e-Business Intelligence: Data Mart Solutions with DB2 for Linux on zSeries, SG24-6294
www.redbooks.ibm.com
63

Information Management
New (sort of in some cases) Releases
Best Practices for SAP Business Information Warehouse on DB2 for z/OS V8, SG24-6489
DB2 UDB for z/OS: Design Guidelines for High Performance and Availability, SG24-7134
Business Performance Management . . . Meets Business Intelligence, SG24-6340
Preparing for DB2 Near-Realtime Business Intelligence, SG24-6071
Disk storage access with DB2 for z/OS, REDP-4187
How does the MIDAW facility improve the performance of FICON channels using DB2 and other workloads?, REDP-4201
Index Compression with DB2 9 for z/OS, REDP-4345
System Programmer’s Guide To: Workload Manager, SG24-6472
www.redbooks.ibm.com
64

Information Management
What is DataQuant?
DataQuant provides a comprehensive query, reporting and data visualization platform for both web and workstation-based environments.
DataQuant introduces a wide variety of powerful business intelligence capabilities, from executive dashboards and interactive visual applications to information-rich graphical reports and ad-hoc querying and data analysis.
DataQuant provides 2 components DataQuant for Workstation – An Elipse based environment for the
development of query, report and dashboard solutions DataQuant for WebSphere – A runtime environment capable of displaying
DataQuant content using a “thin client” model
65

Information Management
Platform for Customized Analytic Applications and Inline Analytics
Pre-built components (Blox) for analytic functionality
Allows you to create customized analytic components that are embedded into existing business processes and web applications
What is Alphablox?
66







