
Generation of Synthetic Datasets for Performance Evaluation of Text/Graphics Document OCR
Mathieu DelalandreCVC, Barcelona, Spain
DAG MeetingCVC, Barcelona, Spain
Wednesday 19th of November 2008

Introduction
Huge amount of data exist, two main sources
• Text/graphics documentsText/graphics documents are used in a variety of fields like geography, engineering, social sciences …Some examples are
architectural drawing utility map geographic map
digitized documents (modern and old) web images
Introduction
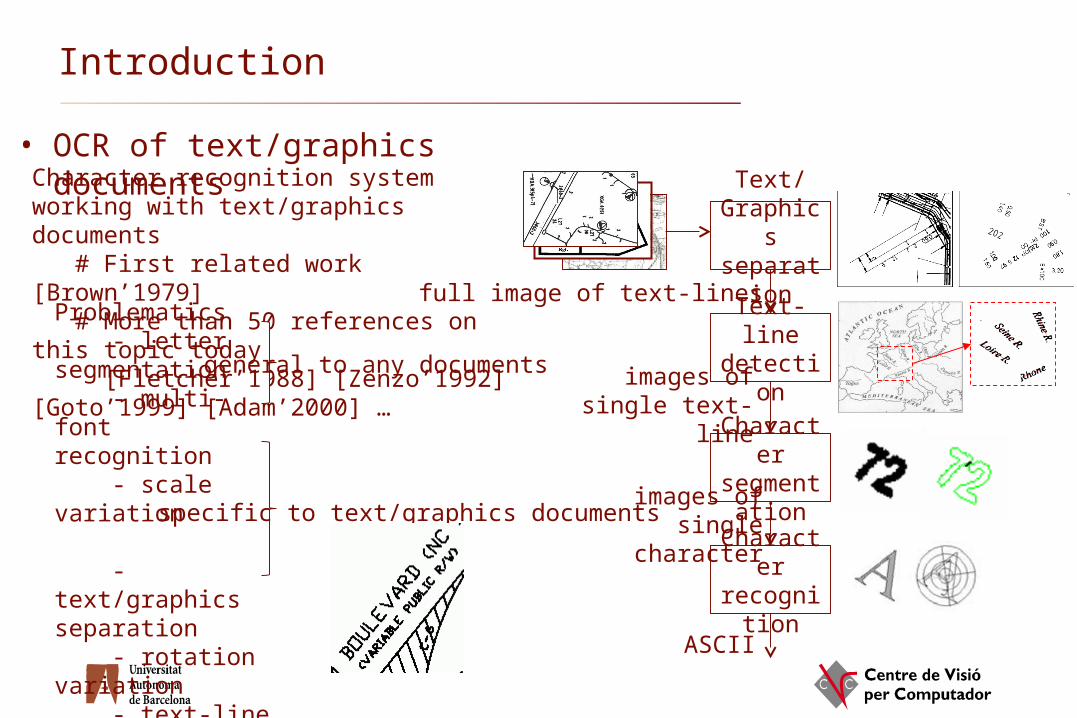
Character recognition system working with text/graphics documents # First related work [Brown’1979] # More than 50 references on this topic today [Fletcher’1988] [Zenzo’1992] [Goto’1999] [Adam’2000] …
• OCR of text/graphics documents
Problematics - letter segmentation - multi-font recognition - scale variation
- text/graphics separation - rotation variation - text-line detection - no reading order - no dictionary
general to any documents
specific to text/graphics documents
Text/Graphic
s separati
onText-line
detection
Character
segmentation
Character
recognition
full image of text-lines
images of single text-line
images of single character
ASCII

Introduction
The case of general OCR [Kanungo’1999]More than 40 references on the topic [Kanungo’1999]Several standard databases exist (NIST, MARS, CD-ROM English, …)Annual evaluation reports [Rice’1992] [Rice’1993]
Black-box evaluation: The evaluation considers the OCR system as an indivisible unit and evaluates it from its final results (i.e. OCR output vs. ASCII transcription of the text using string edit distances). White-box evaluation: The evaluation aims to characterize the performance of individual sub-modules of the OCR system (skewing, letter segmentation, block identification, character recognition, etc.).
Characterisation
GroundtruthGroundtruthGroundtruth
Groundtruthing
ResultsResultsResults
Performance evaluation
SystemResultsDocumentsDocuments
• About performance evaluation
The case of text/graphic document OCR [Wenyin’1997]Only 1 reference on the topicNo standard databasesNone complete evaluation done through 20 years of research

Introduction
• Scope of the proposed work
Performance evaluation of text/graphics document OCR # white-box evaluation # groundtruthing step # datasets for text/line detection and character recognition # generation algorithms are “simple”, the main purpose of the talk will concern the setting contributions

Plan
1. Groundtruth definition2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets

Groundtruth definition
– Character level• ASCII code• font (name, size, style)• location point• orientated bounding box• orientation (ϴ)• scale ()
– Text level• first location point• groundtruth of
characters• characters/word
positionscha
rH e l l o W o r l d
p-wor
d0 0 0 0 0 1 1 1 1 1
p-cha
r0 1 2 3 4 0 1 2 3 4
1. Groundtruth definition2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets

Datasets for character recognition (1/2)
image
size
class
size learning
font(s)
rotation
scaling
Brown’1981
682 ??/10
20 000
× × yes yes
Zenzo’92
?? ??/62
72 000
× × yes yes
Takahashi’1992
242 ??/10
6 400
50% × yes yes
Adam’2000
282 51/62
15 000
33% × yes yes
Chen’2003
162-5122
26/26
1 000
14% 1 no yes
Choisy’2004
282 51/62
15 000
80% × yes yes
Hase’2004
322 ??/26
3 000
33% 3 yes no
Pal’2006
132-342
40/62
18 000
80% 2 yes yes
Roy’2008
132-742
40/62
8 000
80% many
yes yes
(1) (2) (3) (4) (5)
1. Groundtruth definition2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets
• Problematics
How to generate single character images ? Which number of class ? Which image resolution ? Which size for the datasets ? Which fonts ? Etc ….
• Published experiments
• Main conclusions
(1)The real sizes of characters can be only estimated.
(2)The confusion problem (e.g. 6 vs 9) is not still well defined, the 62 class problem (a-z A-Z 0-9) is the main goal.
(3)It is not possible to fix a standard size for the training/test sets, this information is still well defined, several thousands of images are mandatory for the training.
(4)The impact of fonts is few studied and should be take into account in the evaluation
(5)The invariance to rotation and scaling is the final goal, they are few studied independently.

Datasets for character recognition (2/2)
• Datasets
tests scaling
rotation
font(s)/
test
fonts images
3 no no 1 3 15 000
3 yes no 1 3 15 000
3 no yes 1 3 15 000
3 yes yes 1 3 15 000
• Generation setting
Geometry invariance
Font adequacy
Font scalability
1. Groundtruth definition2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets
15 000 +30 000 + 45 000 + 60 000
letter class
62 a-z; A-Z; 0-9
font class 30 fonts
http://www.codestyle.org/ with lower and upper case, no cursivebasic
fonts3 times, courier, arial
character size
322
pixelsmax dxdy of font symbols
dataset size
5 000 / font
62 classes; 40 samples/class; 50%/50%
training free ranked files allow a training specification 20% training on [file-4001 – file-5000]
character scaling
1.0 to 2.0
with a gap of 1/1000
character rotation
0 to 2×π
with a gap of π/500
• Generation algorithm font manager, centering, scale
and rotation processes
tests scaling
rotation
font(s)/
test
fonts images
4 yes yes 3; 6; 9; 12
12 150 000
tests scaling
rotation
font(s)/
test
fonts images
30 yes yes 1 30 150 000

Datasets for text-line detection (1/2)
• Problematicsuse-case ima
gestext-lines
curved
font/img
scaling
Roy’2008
geographic map
?? 5 000
yes many
yes
Pal’2004
artistic document
?? 1 521
yes many
yes
Loo’2002
poster, newspape
r
2 118 yes many
yes
Park’2001
poster, publicity
30 1265 yes many
yes
Goto’1999
Japanese form
170 9 831
yes many
yes
Tan’1998
map 8 96 no many
yes
He’1996 drawing 1 16 no many
yes
Burgue’1995
cadastral map
4 150 no many
yes
Deseilligny’1995
cadastral map
3 1 250
no many
yes
(1) (2) (3)
1. Groundtruth definition2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets
How to generate single character images ? Which number of word per image ? Which image size ? Which size for the datasets ? Which number of font ? Etc ….
• Main conclusions
(1)The use-cases are heterogeneous, the sizes and resolutions of images are few provided, the text density is then difficult to estimate, images with significant text content are preferred.
(2)Depending the use-cases, not all the methods work on curved text, a combination of curved and straight text is necessary.
(3)All the methods use context to extract the text-line (i.e. font type, character size, line model). The size of characters could change a lot, the number of font is generally small (less to ten).

Datasets for text-line detection (2/2)
test text-line/img
scaling
curved
font(s)/test
words
1 low yes no 3 in progress
1 medium yes no 3 in progress
1 high yes no 3 in progress
The insert algorithm step 1 step 2
132 llld dd y sin dd x cos
B1 ejects B2 of dx,dyl2
l1
l3
dydx
d
θ
B1
B2
22yx ddd
• Setting
1. Groundtruth definition2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets
• DatasetsText-line density
• Generation algorithm
test text-line/img
scaling
curved
font(s)/test
words
1 medium no no 9 in progress
1 medium no no 6 in progress
1 medium no no 3 in progress
1 medium no no 1 in progress
Font context
test text-line/img
scaling
curved
font(s)/test
words
1 medium no no 1 in progress
1 medium yes no 1 in progress
Size context
dictionary
422 text-lines
countries and capitals
font class
30 fonts http://www.codestyle.org/ with lower and upper case, no cursivecharacte
r size322
pixelsmax dxdy of font symbols
image size
6402 10-50 text-lines per image
dataset size
100 images
text scaling
1.0 to 1.5
with a gap of 1/1000
text rotation
-π/2 to +π/2
with a gap of π/500

In progress datasets 1. Groundtruth definition and
setting2. Datasets for character
recognition3. Datasets for text-line detection4. In progress datasets

Conclusions
Conclusions # in progress work … # character recognition datasets are ready # bags of words still under packaging, but will be ready soon.
Perspectives # middle term, experimentations with standard feature extraction
methods [Roy’2008] [Valveny’2007] # long term, experimentations with bags of word and text/graphics
documents [Delalandre’2007] [Wenyin’1997]

References (1/2)1. R. Brown and M. Lybanon and L. K. Gronmeyer. Recognition of Handprinted Characters for Automated Cartography: A
Progress Report. Proceedings of the SPIE, Vol. 205, 1979.2. L.A. Fletcher & R. Kasturi. A Robust Algorithm for Text String Separation from Mixed Text/Graphics Images. Transactions on
Pattern Analysis and Machine Intelligence (PAMI), vol (10), pp. 910-918 , 1988. 3. S.D. Zenzo; M.D. Buno; M. Meucci & A. Spirito. Optical recognition of hand-printed characters of any size, position, and
orientation. IBM Journal of Research and Development, vol (36), pp. 487-501 , 1992. 4. H. Goto & H. Aso. Extracting curved text lines using local linearity of the text line. International Journal on Document
Analysis and Recognition (IJDAR), vol (2), pp. 111-119 , 1999. 5. S. Adam; J.M. Ogier; C. Cariou; R. Mullot; J. Labiche & J. Gardes. Symbol and Character Recognition : Application to
Engineering Drawings. International Journal on Document Analysis and Recognition (IJDAR), vol (3), pp. 89-101 , 2000. 6. T. Kanungo; G.A. Marton & O. Bulbu. Performance evaluation of two Arabic OCR products. Workshop on Advances in
Computer-Assisted Recognition (AIPR) , SPIE Proceedings, vol (3584), pp. 76-83 , 1999. 7. S.V. Rice J. Kanai & T.A. Nartker. A Report on the Accuracy of OCR Devices. Information Science Research Institute,
University of Nevada, USA, 1992.8. S.V. Rice; J. Kanai & T.A. Nartker. An Evaluation of OCR Accuracy. Information Science Research Institute, University of
Nevada, USA, 1993. 9. L. Wenyin & D. Dori. A Protocol for Performance Evaluation of Line Detection Algorithms. Machine Vision and Applications,
vol (9), pp. 240-250 , 1997.10. R.M. Brown. Handprinted Symbol Recognition System: A Very High Performance Approach To Pattern Analysis Of Free-form
Symbols. Conference Southeastcon , pp. 5-8 , 1981.11. H. Takahashi. Neural network architectures for rotated character recognition. International Conference on Pattern
Recognition (ICPR) , pp. 623-626 , 1992.12. Q. Chen. Evaluation of OCR algorithms for images with different spatial resolutions and noises. School of Information
Technology and Engineering, University of Ottawa, Canada, 2003.13. C. Choisy; H. Cecotti & A. Belaid. Character Rotation Absorption Using a Dynamic Neural Network Topology: Comparison
With Invariant Features. International Conference on Enterprise Information Systems (ICEIS) , pp. 90-97 , 2004.

References (2/2)14. H. Hase; T. Shinokawa; S. Tokai & C.Y. Suen. A robust method of recognizing multi-font rotated characters.
International Conference on Pattern Recognition (ICPR) , vol (2), pp. 363- 366 , 2004. 15. U. Pal; F. Kimura; K. Roy & T. Pal. Recognition of English Multi-oriented Characters. International Conference on
Pattern Recognition (ICPR) , vol (2), pp. 873-876 , 2006.16. P.P. Roy; U. Pal & J. Llados. Multi-oriented character recognition from graphical documents. International Conference
on Cognition and Recognition (ICCR) , pp. 30-35 , 2008.17. U. Pal & P. P. Roy. Multi-oriented and curved text lines extraction from Indian documents. IEEE Transactions on
Systems, Man and Cybernetics- Part B, vol (34), pp. 1676-1684 , 2004. 18. P.K. Loo & and C.L. Tan. Word and Sentence Extraction Using Irregular Pyramid. Workshop on Document Analysis
System (DAS) , Lecture Notes in Computer Science (LNCS), vol (2423), pp. 307-318 , 2002. 19. H.C. Park; S.Y. Ok; Y.J. Yu & H.G. Cho. Word Extraction in Text/Graphic Mixed Image Using 3-Dimensional Graph
Model. International Journal on Document Analysis and Recognition (IJDAR) , vol (4), pp. 115 130 , 2001. 20. H. Goto & H. Aso. Extracting curved text lines using local linearity of the text line. International Journal on Document
Analysis and Recognition (IJDAR), vol (2), pp. 111-119 , 1999. 21. C.L. Tan & P.O. Ng. Text extraction using pyramid. Pattern Recognition (PR), vol (31), pp. 63-72 , 1998. 22. S. He, N. Abe & C. L. Tan. A clustering-based approach to the separation of text strings from mixed text/graphics
documents. International Conference on Pattern Recognition (ICPR) , pp. 706-710 , 1996. 23. M. Burge & G. Monagan. Extracting Words and Multi Part Symbols in Graphics Rich Documents. International
Conference on Image Analysis and Processing (ICIAP) , 1995. 24. M. Deseilligny; H. Le Men & G. Stamon. Characters string recognition on maps, a method for high level
reconstruction. International Conference on Document Analysis and Recognition (ICDAR) , pp. 249 252 , 1995. 25. E. Valveny; S. Tabbone; O. Ramos & E. Philippot. Performance Characterization of Shape Descriptors for Symbol
Representation. Workshop on Graphics Recognition (GREC) , 2007. 26. M. Delalandre; T. Pridmore; E. Valveny; E. Trupin & H. Locteau. Building Synthetic Graphical Documents for
Performance Evaluation. Workshop on Graphics Recognition (GREC) , Lecture Note in Computer Science (LNCS), vol (5046), pp. 288-298 , 2008.







