
Fabien BADEIG
Le 5 novembre 2004,
Projet Data Mining : Etude et analyse de données sur
le cinéma.
DEA127
Université Paris IX Dauphine
Professeur : E. DIDAY.

Projet Data Mining
Fabien BADEIG 2\24
Table des matières
Introduction ----------------------------------------------------------------------------------------------------- 3
1 Etat de l’art du Data Mining --------------------------------------------------------------------------- 4
2 Description de la base de données de choisie ------------------------------------------------------ 8
3 Définition des individus et des concepts ---------------------------------------------------------- 10
4 Définitions des requêtes ------------------------------------------------------------------------------ 12
5 SOE avec interprétations ---------------------------------------------------------------------------- 13
6 ACP (i.e. PCM) avec interprétations --------------------------------------------------------------- 17
7 STAT ----------------------------------------------------------------------------------------------------- 18
8 PYR ------------------------------------------------------------------------------------------------------ 20
9 DIV ------------------------------------------------------------------------------------------------------- 22
10 TREE-------------------------------------------------------------------------------------------------- 23
Conclusion----------------------------------------------------------------------------------------------------- 24

Projet Data Mining
Fabien BADEIG 3\24
Introduction
Les progrès de la technologie informatique dans le recueil et le transport
de données, font que dans tous les grands domaines de l'activité humaine,
on recueille maintenant des données en quantité souvent gigantesque et
de toutes sortes (numériques, textuelles, graphiques...).
L’exploitation de ces nouvelles informations peut présenter un intérêt pour
analyser et interpréter les comportements d’individus par exemple. Les
résultats obtenus s’insérant dans un dispositif d’analyse globale
permettent alors de dresser dans des plans stratégiques ou politiques les
axes d’effort à respecter.
Résumer ces données, à l'aide de concepts sous-jacents (une ville, un
produit...), afin de mieux les appréhender et d'en extraire de nouvelles connaissances constitue une question cruciale.
Le logiciel libre SODAS a pour objectif de répondre à cette question. C’est
ce logiciel qui va être utilisé dans le cadre de ce projet afin d’extraire les
données concentrées dans une base de donnée relationnelle de type
ACCESS et d’y appliquer les méthodes d’analyse contenues dans SODAS.
On présentera d'abord le cadre théorique de l'Analyse des données
symboliques basé sur la notion « d'objets symboliques ». On présentera
ensuite l'architecture et les outils de l'Analyse des données symboliques
développés dans SODAS. Ces outils généralisent les méthodes de
l'Analyse des données classiques et ceux de la statistique usuelle, aussi
bien en entrée, en autorisant des données plus complexes car plus proches de la réalité, qu'en sortie, en fournissant des objets symboliques
plus aptes à exprimer des connaissances que les résultats numériques
habituels.
La base d’étude du projet concerne le cinéma. Cette base de données
regroupe 100 films qui ont tous été nominés pour les oscars.

Projet Data Mining
Fabien BADEIG 4\24
1 Etat de l’art du Data Mining
A/ Définition du Data Mining :
Par définition, le Datamining est la technique d’analyse permettant, à
l’aide d’un logiciel, d’explorer des données pour mettre en évidence des comportements, des informations stratégiques.
Ce type d'application appartient à la famille des logiciels d'aide à la
décision des années 80. La base sur laquelle ils travaillent, sont les
énormes entrepôts de données d'aujourd'hui, qui peuvent contenir des
dizaines de gigaoctets.
Le terme anglais datamining exprime bien le travail de " mineur de fond "
qu'il est nécessaire d'effectuer sur d'énormes " gisements " de données
commerciales pour en extraire le " minerai " d'enseignements utiles à une
entreprise ou une administration.
Le Datamining (littéralement "fouille de données"), contrairement à
l'analyse multidimensionnelle, a pour but de mettre en évidence des
corrélations éventuelles dans un volume important de données afin de
dégager des tendances.
Le Datamining s'appuie sur des techniques d'intelligence artificielle
(réseaux de neurones) afin de mettre en évidence des liens cachés entre
les données.
B/ Les principaux logiciels avec positionnement de SODAS :
Data Mining
Editeur & Solution Positionnement Connexions natives
Business Objects
Application Foundation
Dans sa version 3.0, Application
Foundation intègre le moteur
d'analyse prédictive de l'éditeur
KXEN. Son objectif: modéliser des
données existantes en vue de faire
des projections.
CRM: Siebel, Prime Response
(Chordiant), Nortel (Clarify),
Peoplesoft/Vantive, Peregrine
(Remedy). ETL: intégration étroite
avec Informatica, et ensuite Acta et
Ascential Software. Entrepôts &
bases de données: Hyperion,
Oracle, IBM/Informix, Sybase.
Data mining: intègre KXen en
OEM.
Data Distilleries
DD Series
L'offre intègre DD/Marketer pour
générer les modèles prédictifs
(segmentation), DD/Sire pour
déployer les recommandations, et
DD/Expert pour construire les
scenarii
.
CRM Front-office: Siebel, AIMS,
Broadvision (eCRM). L'intégration
est déjà programmée avec Siebel
7.0.

Projet Data Mining
Fabien BADEIG 5\24
IBM
DB2 Intelligent Miner
DB2 Intelligent Miner est l'outil de
datamining utilisé dans
DecisionEdge for Relationship
Marketing (voir tableau 1), mais
IBM en propose de plus ciblés. Un
cas intéressant est celui de Internet
Sales Predictor, une applet Java
téléchargeable gratuitement sur le
site IBM consacré aux
développeurs.
Comme son nom l'indique, ne
fonctionne que sur une base de
données IBM DB2, mais dans de
nombreux environnements (AIX,
OS/390-400, Solaris, Windows
2000 et NT...). Cet outil et ses
déclinaisons sont en fait des
extensions à la base de données qui
en est le point central.
KXen
Composants KXEN intégrables
La position de KXen est
particulière. Son objectif est de
fournir des algorithmes avancés qui
se basent sur les théories récentes
du chercheur russe Vapnik, par
opposition à la méthode Fischer du
début du siècle, répandue dans la
plupart des autres solutions.
Bénéfice: résultat rapide et
pertinent.
Intégration de composants en OEM
dans Business Objects,
Profile4You (eCRM), Norkom et
Coheris/ISO (CRM). Travaux avec
Kana/Broadbase. Selon KXen, une
intégration totale des composants
dans un environnement donné
prend 2 ou 3 semaines maximum.
Composants programmés en C++,
DCom, Corba, Java. Echanges:
ODBC ou texte pur.
Oracle
9i Data Mining
Pour les commentaires, se reporter
à IBM deux cases au dessus.
Oracle 9i Data Mining est intégré à
Oracle Customer Intelligence.
Tout comme IBM, il s'agit d'une
extension à la base de données
Oracle 9i, et non d'un produit
surajouté réclamant une intégration
à travers une API Java ou C++.
SAS
e-Discovery
SAS est l'éditeur de référence dans
le domaine du data mining. e-
Discovery est la solution de
modélisation prédictive phare de
SAS dans le domaine du CRM
multi-canaux. Utilisateurs avertis
pour besoins pointus en règle
générale.
SAS livre sa propre plate-forme
Integration Technology pour
l'interconnexion au back-office et
aux solutions tierces. Comme
toujours, il faut être capable de
programmer en SAS. La dernière
version fournit un pont vers les
serveurs WebDAV et le
middleware Tibco/RendezVous.
SPSS
Clementine
SPSS est considéré comme le
leader sur le segment des outils
statistiques (pour des experts).
Clementine est sa plate-forme de
data mining. 14 méthodes
différentes de modélisation
prédictive sont compilées (d'autres
éditeurs fournissent aussi plusieurs
algorithmes). Rachat récent de
NetGenesis (eCRM/Web mining)
et de Lexiquest (analyse de
données non-structurées).
Principal partenaire: Siebel, qui
dispose d'une participation dans le
capital de SPSS.
Autre CRM: Chordiant à travers
Prime Response. Entrepôts de
données: Oracle, Hyperion,
Informix Red Brick Warehouse
(datamart).
ETL: Ascential.
SODAS Prototype gratuit

Projet Data Mining
Fabien BADEIG 6\24
C/ Domaines d’utilisation et intérêts pratiques :
Le Datamining peut s'appliquer à de nombreux domaines de l'entreprise.
L'objet du datamining n'est d'ailleurs plus seulement d'aider à la prise de
décision de haut niveau, mais de permettre un pilotage fin de la fonction
de gestion de la relation client (GRC ou CRM), par une connaissance
beaucoup plus étoffée des comportements et des préférences de la
clientèle.
Utilité pour l'entreprise : Augmenter la rentabilité de l'entreprise
Fidéliser ses clients Gérer la relation client
Gestion de la force de vente
Trouver les générateurs de coûts (contrôle de gestion...)

Projet Data Mining
Fabien BADEIG 7\24
C/ Description du logiciel SODAS :
Il s’agit d’un logiciel prototype public destiné à l’analyse de données
symbolique.
Le logiciel SODAS est issu d’un projet de EUROSTAT portant le même
nom. Ce logiciel a pour vocation de fournir un cadre aux différentes
avancées récentes et futures dans le domaine de l’analyse des données
symboliques.
L’idée générale de ce projet est de construire, à partir d’une base de
données relationnelle, un tableau de données symboliques muni
éventuellement de règles de taxonomies. Le but étant de décrire des concepts résumant un vaste ensemble de données et d’analyser ensuite
ce tableau pour en extraire des connaissances par des méthodes d’analyse
de données symboliques. Dans ce pré rapport, nous utiliserons les deux
méthodes SOA et ACP.
Une analyse des données dans SODAS suit les étapes suivantes :
Partir d’une base de données relationnelle (ORACLE, ACCESS…)
Définir ensuite un contexte par :
Des unités statistiques de premier niveau (habitants,
familles, entreprises, accidents...)
Les variables qui les décrivent
Des concepts (villes, groupes socio-économiques, scénario d’accident…).
Chaque unité statistique de premier niveau est associée à un concept (par
exemple, chaque région est associé à son pays). Ce contexte est défini
par une requête sur la base de données relationnelle.
Le tableau de données symboliques peut être construit, les nouvelles
unités statistiques sont les concepts décrits par généralisation des
propriétés des unités statistiques de premier niveau qui leur sont
associées.
Ainsi, chaque concept est décrit par des variables dont les valeurs peuvent
être des histogrammes, des intervalles, des valeurs uniques
(éventuellement munies de règles et de taxonomies) selon le type de variables et le choix de l’utilisateur.
Il est alors possible de créer un fichier d’objets symboliques sur lequel une
douzaine de méthodes d’analyse de données symboliques peut déjà
s’appliquer (histogrammes des variables symboliques, classification
automatique, analyse factorielle, analyse discriminante, visualisations
graphiques…).
Le logiciel SODAS est téléchargeable à l’adresse suivante : http:/www.ceremade.dauphine.fr/~touati/sodas-pagegarde.htm

Projet Data Mining
Fabien BADEIG 8\24
2 Description de la base de données de choisie
Pour notre étude, nous nous servirons d’une base de données sur le
cinéma BDCinéma.mdb. Cette base de données provient du site LISE de Monsieur Diday. Elle fut tirée du projet de Vanessa Le Marrec. Il s’agit
d’une base de données relationnelles formatée sous ACCESS. Elle fut
créée à partir de données récupérées sur deux sites Internet :
www.monsieurcinéma.fr.
www.amazon.com.
Cette base de données regroupe 100 films qui ont tous été nominés pour
les oscars. Les informations concernant les films sont notamment le
réalisateur, l’acteur principal, le budget consacré ainsi que le revenu
retiré…
Description des tables : Nous allons présenter en détail chacune des tables composant la base de données :
- La table FILM contient les informations décrivant les 100 films de notre base. - La table RÉALISATEUR reprend les réalisateurs des différents films. - La table CONTINENT_TOURNAGE stocke les noms des continents où ont été tournés les films. - La table LIEU_TOURNAGE stocke les noms des lieux de tournage des films : chaque lieu de tournage se trouve dans l’un des continents présents dans la table CONTINENT_TOURNAGE. - La table PAYS_RÉALISATEUR stocke les noms des pays d’origine des réalisateurs. - La table RÉGION_RÉALISATEUR stocke les noms des régions d’origine des réalisateurs : chaque région se trouve dans l’un des pays qui sont dans la table PAYS_RÉALISATEUR. - Six autres tables ont été créées pour permettre l’exploitation d’écarts : OSCARS, AGE_RÉALISATEUR, BUDGET_ÉCART, REVENU_ÉCART, REVENU_ÉCART2 et BENEFECART.
Les tables écart ont été implémentées pour permettre de transformer les variables quantitatives en variables qualitatives. Dans notre cas, on a préféré mettre des intervalles comme description car ils sont plus explicites que des mots mais on aurait pu mettre par exemple pour revenu écart : faible revenu, revenu moyen, revenu fort, …
Je vais exposer une vue globale de la base de données dans le schéma
relationnel suivant :

Projet Data Mining
Fabien BADEIG 9\24

Projet Data Mining
Fabien BADEIG 10\24
3 Définition des individus et des concepts
Dans nos deux requêtes, les individus sont les mêmes. Ce sont les films
qui ont été présentés pour les oscars.
Quant à nos variables de description pour la requête sur l’intervalle des
revenus, nous avons :
X variables qualitatives : Genre, nom réalisateur, acteur principal,
lieu de tournage et pays d’origine du film (sa nationalité).
Y variables quantitatives : Budget du film, le nombre d’oscar obtenu,
la durée du film et son année.
Nous avons choisi comme concept les intervalles de revient d’un film.
Soit :
revenuEcart2
Revenu_Ecart(K)
0-15000
15001-50000
50001-100000
100001-150000
150001-200000
200001-250000
250001-300000
300001-400000
400001-500000
+ de 500001
Donc nous avons dû transformer une variable quantitative en variable
qualitative à l’aide de la table revenuEcart2. Nous avons modifié la table
Revenu_Ecart car cette dernière ne disposait pas d’assez de concepts et
surtout disposait de deux intervalles avec un nombre d’individus
importants donc j’ai éclaté ces deux intervalles afin d’avoir une meilleure
répartition des individus. Divers problèmes se sont posés lors de la
sélection des concepts car le fait de transformer une variable quantitative
en qualitatif nous a fait perdre une variable quantitative alors que la base n’en disposait au départ de beaucoup. Et d’essayer de choisir les concepts
parmi les variables qualitatives me paraissait difficile du fait de ce qui
avait déjà été réalisé.
J’ai essayé de trouver d’autres concepts et je me suis orienté vers les
intervalles de bénéfices d’un film. Qui sont obtenus à partir de la
soustraction entre le coût de revient et le budget d’un film. Cependant je
ne suis pas sûr qu’il soit judicieux par la suite de mettre en variables
quantitatives le revenu du film et son budget. Je vous mets quand même
les concepts. Pour si le temps le permet tenter de faire une analyse
factorielle de ces derniers.

Projet Data Mining
Fabien BADEIG 11\24
Les concepts sont les suivants :
Benef_Ecart
Benef_Ecart(K)
benef negatif
1-100000
100001-200000
200001-300000
+600000
50001-100000
100001-150000
150001-200000
300001-600000
Pour les concepts j’ai également pensé à la concaténation de deux
variables qualitatives. Par exemple le réalisateur d’un film concaténé avec
l’acteur principal. Mais après concaténation des deux il n’y avait
pratiquement aucun regroupement.

Projet Data Mining
Fabien BADEIG 12\24
4 Définitions des requêtes
Je dispose de deux requêtes, une requête pour les concepts des
intervalles de revenus et un concept pour les intervalles de bénéfice. J’ai exécuté les deux méthodes SOE et PCM sur le dernier concept mais je n’ai
pas effectué d’interprétation ni fourni de résultats.
A/ RevenuEcartReq2 :
SELECT Film.Titre, revenuEcart2.[Revenu_Ecart(K)], Film.Genre, Réalisateur.Nom,
Film.Acteur_Principal, Lieu_Tournage.Lieu_Tournage, Film.Pays, Film.Durée,
Film.[Budget(K)], Film.Nombre_Oscars, Film.Année
FROM revenuEcart2, Lieu_Tournage INNER JOIN (Réalisateur INNER JOIN Film ON
Réalisateur.N°_Réalisateur = Film.N°_Réalisateur) ON Lieu_Tournage.Lieu_Tournage_id =
Film.Lieu_Tournage_id
WHERE (([Film]![N°_Réalisateur]=[Réalisateur]![N°_Réalisateur]) AND
([Film]![Lieu_Tournage_id]=[Lieu_Tournage]![Lieu_Tournage_id]) AND
(([Film]![Revenu(K)])>[revenuEcart2]![Revenu_Min(K)] And
([Film]![Revenu(K)])<[revenuEcart2]![Revenu_Max(K)]));
B/ etudBenefEcart :
SELECT DISTINCT Film.Titre, Benef_Ecart.[Benef_Ecart(K)], Film.Genre, Film.Pays,
Film.[Budget(K)], Film.[Revenu(K)], Film.Nombre_Oscars, Film.Durée,
Lieu_Tournage.Lieu_Tournage, Réalisateur.Nom
FROM Revenu_Ecart, Benef_Ecart, Lieu_Tournage INNER JOIN (Réalisateur INNER JOIN
Film ON Réalisateur.N°_Réalisateur = Film.N°_Réalisateur) ON
Lieu_Tournage.Lieu_Tournage_id = Film.Lieu_Tournage_id
WHERE (([Film]![Lieu_Tournage_id]=[Lieu_Tournage]![Lieu_Tournage_id]) AND
(([Film]![Bénéfice(K)])>[Benef_Ecart]![Benef_Min(K)] And
([Film]![Bénéfice(K)])<[Benef_Ecart]![Benef_Max(K)]) AND
(([Film]![N°_Réalisateur])=[Réalisateur]![N°_Réalisateur]));

Projet Data Mining
Fabien BADEIG 13\24
5 SOE avec interprétations
La méthode SOE permet d’obtenir un tableau qui pour chaque concept fournit les valeurs
prises par les variables descriptives de ce concept. Les variables qualitatives seront
représentées par l’ensemble des valeurs de la variable associées à son pourcentage. Par
exemple, pour la variable qualitative genre du film nous obtenons pour chaque concept le
descriptif ci-dessus
L’interprétation de la première ligne est que pour le concept [150001-200000], 22% des
individus de ce concept (i.e., des films dont le revenu est compris entre [150001-200000])
sont des films de sciences fiction, …
Par contre, les variables quantitatives sont exprimées sous forme d’intervalle. Par exemple, la
durée des films du concept [0-15000] est comprise entre 96 et 146.
On a ainsi une vue d’ensemble des concepts.
De plus, l’éditeur permet de visionner un objet symbolique sous une représentation
graphique : l’étoile zoom. Cette représentation est basée sur des axes radiaux. Chaque
représente une variable. On peut choisir dans l’étoile zoom les axes radiaux.
Le but de cette représentation est de fournir une image synthétique de l’objet, un profil et de
comparer les profils.
Nous allons étudier les objets symboliques suivants (car ces derniers émergent de l’analyse
PCM qui est faite dans la partie suivante et sont bien représentés) :
[0-15000]
[100001-150000]
[300001-400000]
+ de 500001
Pour connaître la répartition des individus en fonction des concepts j’ai créé la requête
rapportNbFilmIntervalleRevenu.

Projet Data Mining
Fabien BADEIG 14\24
Les images sont fournies juste à titre indicatif, car pour visualiser les variables qualitatives
relatives au nom des réalisateurs et des acteurs, il faut observer l’histogramme associé à l’axe
radial.
Les deux interprétations majeures flagrantes sur cette représentation sont la concentration des
films dont le revenu est supérieur à 500001 sur la valeur USA de l’axe Pays d’origine des
films et sur la valeur sciences fiction de l’axe genre du film. Il faut remarquer que malgré
l’importance du genre science fiction représentée à 43%, le genre fantastique est également
représenté à 29%.
Par ailleurs, on constate que les films dont les revenus ont « explosé » sont apparus à partir de
1977 indiqué par l’intervalle [1977,1999] de l’axe radial Année. Les axes budget,
nombre_Oscars et durée ne sont pas très représentatifs du fait de leur intervalle trop important
pour affiner l’analyse il faudrait travailler sur les intervalles et donc transformer cette variable
quantitative en variable qualitative.
Les lieux de tournage ont également une représentation significative car Londres et les USA
sont représentés à 29% chacun. On ne peut ignorer la Californie, Hawaï et la Tunisie
représentés à 14% chacun.
L’interprétation générale est que les films dont le revenu est important (supérieur à 500001),
proviennent tous des USA, et ont été réalisés à partir de 1977. De plus, ces films sont
essentiellement des films de science fiction, des films fantastiques. De même, les réalisateurs
fars de ces films sont Lucas ou Spiel. En effet, à eux deux il regroupe 58% des films de
revenu supérieur à 500000.
Pour les concepts suivants, je vais moins détailler l’interprétation.

Projet Data Mining
Fabien BADEIG 15\24
Cette représentation correspond aux films dont le revenu est faible (i.e., compris entre 0 et
15000). Les informations clés qui ressortent sont encore une fois l’importance du pays
d’origine car les USA dominent avec 93% de la représentation sur l’axe radial Pays.
Cependant, la France fait une apparition timide qui n’est pas significative (0,08%) pour ne pas
dire inexistante face à la représentation américaine. Donc on peut dire que la majorité des
films à faible revenu provienne des Etats-Unis.
Il est intéressant de s’attarder sur l’axe radial correspondant au budget des films et au nombre
d’oscars reçus. En effet, les films à faible revenu sont des films dont le budget n’est pas très
élevé. Le budget est compris entre 400 et 18000. Quant au nombre d’oscars, il est également
peu élevé, il est compris entre 0 et 2. Après on ne connaît pas la répartition des oscars donc
pour affiner l’analyse il faudrait calculer cette répartition, mais cette représentation est
suffisante pour en déduire que les films à faible revenu ne sont pas des films fortement
nominés. Par ailleurs, l’axe de la durée du film est indicatif car la durée moyenne des films à
faible revenu (on prend le milieu de l’intervalle [96,146]) est de 111 minutes et en
comparaison à la moyenne des autres intervalles durée des autres objets symboliques, cette
durée est la plus faible, ce qui semble cohérent étant donnée que ces films à faible revenu sont
des films à faible budget.
Les autres axes connaissent une répartition relativement équilibrée. Par exemple, si on étudie
le genre des films à faible revenu, on trouve des films de différents genres même si le genre
dramatique est légèrement plus représenté. On peut s’intéresser aussi au lieu de tournage car
deux points émergent la Californie et les USA. Comme la remarque précédente, étant donné
que la majorité des films à faible revenu sont des films américains et à faible budget, il paraît
évident que les moyens pour ces films sont faibles et ils n’ont pas la possibilité d’aller tourner
à l’étranger.
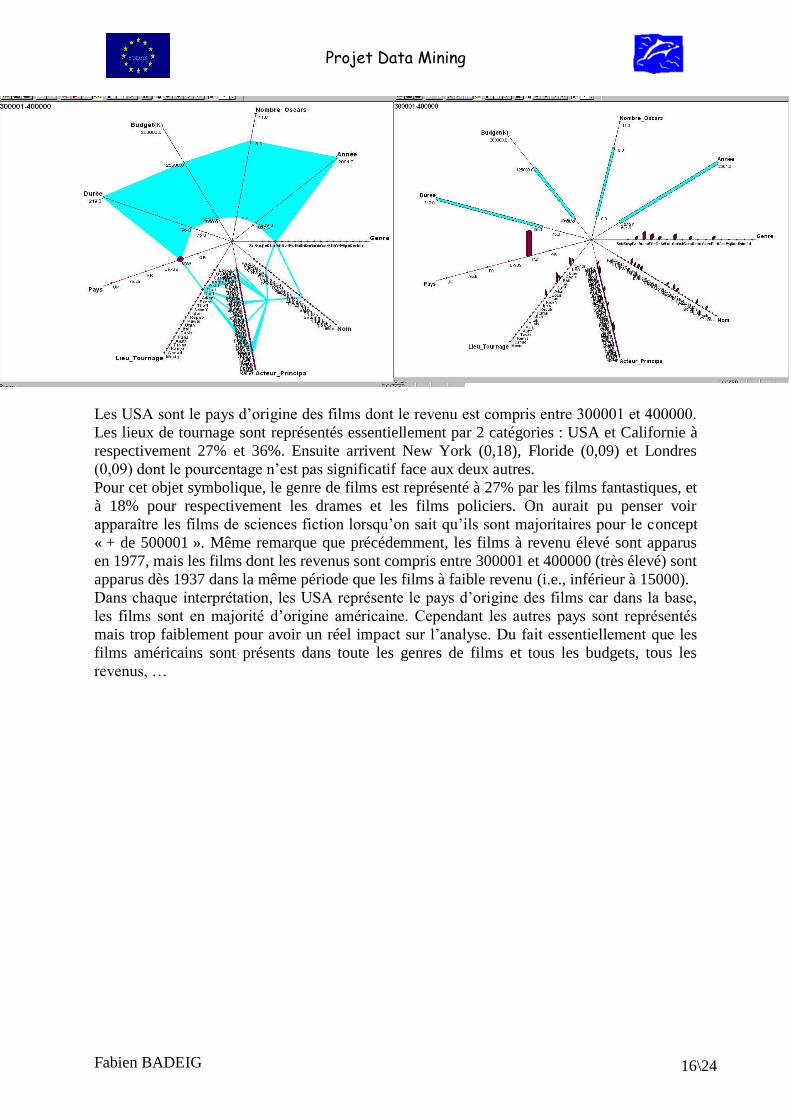
Projet Data Mining
Fabien BADEIG 16\24
Les USA sont le pays d’origine des films dont le revenu est compris entre 300001 et 400000.
Les lieux de tournage sont représentés essentiellement par 2 catégories : USA et Californie à
respectivement 27% et 36%. Ensuite arrivent New York (0,18), Floride (0,09) et Londres
(0,09) dont le pourcentage n’est pas significatif face aux deux autres.
Pour cet objet symbolique, le genre de films est représenté à 27% par les films fantastiques, et
à 18% pour respectivement les drames et les films policiers. On aurait pu penser voir
apparaître les films de sciences fiction lorsqu’on sait qu’ils sont majoritaires pour le concept
« + de 500001 ». Même remarque que précédemment, les films à revenu élevé sont apparus
en 1977, mais les films dont les revenus sont compris entre 300001 et 400000 (très élevé) sont
apparus dès 1937 dans la même période que les films à faible revenu (i.e., inférieur à 15000).
Dans chaque interprétation, les USA représente le pays d’origine des films car dans la base,
les films sont en majorité d’origine américaine. Cependant les autres pays sont représentés
mais trop faiblement pour avoir un réel impact sur l’analyse. Du fait essentiellement que les
films américains sont présents dans toute les genres de films et tous les budgets, tous les
revenus, …

Projet Data Mining
Fabien BADEIG 17\24
6 ACP (i.e. PCM) avec interprétations
Les concepts qui sont les intervalles des revenus des films se distinguent par leurs variables
descriptives quantitatives relatives au budget du film, à son année de parution, à sa durée et à
son nombre d’oscars. Le principe de la création des rectangles dans la méthode PCM est de
trouver le plus petit rectangle qui contiendra le nuage d’individus du concept C1 et à ce
rectangle est alors associé le concept C1.
La matrice de corrélation permet d’interpréter l’évolution des variables entre elles. Dans la
matrice on constate qu’aucun terme n’est négatif donc on peut en conclure que toutes les
variables vont évoluer dans le même sens.
Corrélations Matrice :
Durée 1.0000 0.1097 0.0921 0.0443
Budget(K) 0.1097 1.0000 0.1551 0.1356
Nombre_Oscars 0.0921 0.1551 1.0000 0.0465
Année 0.0443 0.1356 0.0465 1.0000
PC1 = budget(32,55) et PC3 = durée(22,82)
Les concepts {0-15000} et {400001-500000} sont différenciés par l’axe PC1 qui représente
les budgets nécessaires pour réaliser ces derniers. Par contre leur projection sur l’axe PC2 qui
représente la durée d’un film ne permet de les différencier car ils sont regroupés dans le même
intervalle. Cette interprétation est logique car en général les films qui ont ramené peu d’argent
sont les films à petit revenu alors que les films à gros budget sont des films dont le revenu est
élevé donc la différenciation sur l’axe 1. Par contre, lorsqu’on regarde les interprétations SOE
on constate qu’en règle générale la durée des films est équivalente quelque soit le concept
étudié et ce résultat est corroboré par STAT qui montre que la majorité des films ont une
durée entre 100 minutes et 160 minutes.

Projet Data Mining
Fabien BADEIG 18\24
7 STAT
De ce graphe, on peut en déduire qu’une majorité des films nominés aux oscars reçoivent
entre 0 et 2 oscars (de l’ordre de 21%). Par majorité, j’entends le fait que si on choisit un film
au hasard la probabilité qu’il est entre 0 et 2 oscars est plus importants que les autres. Par
contre, très peu de films obtiennent entre 8 et 10 oscars.
En terme de majorité au sens propre, la majorité des films reçoivent entre 0 et 4 oscars.

Projet Data Mining
Fabien BADEIG 19\24
La majorité des films nominés aux oscars dure entre 110 minutes et 170 minutes. On a
également 15% des films qui dure entre 100 et 110 minutes.

Projet Data Mining
Fabien BADEIG 20\24
8 PYR
Where_the_labels_are_of_the_variables_are:
y1.=Genre
y7.=Budget(K)
y8.=Nombre_Oscars
L’interprétation est la suivante lorsque j’ai deux concepts éloignés dans la hiérarchie je peux
en déduire qu’ils se différencient par rapport aux variables choisies (genre budget et nombre
d’oscars).

Projet Data Mining
Fabien BADEIG 21\24
Where_the_labels_are_of_the_variables_are:
y1.=Genre
y4.=Lieu_Tournage

Projet Data Mining
Fabien BADEIG 22\24
9 DIV PARTITION IN 4 CLUSTERS :
-------------------------:
Cluster 1 (n=2) :
"50001-100000" "0-15000"
Cluster 2 (n=3) :
"300001-400000" "400001-500000" "200001-250000"
Cluster 3 (n=1) :
"+ de 500001"
Cluster 4 (n=4) :
"150001-200000" "100001-150000" "15001-50000" "250001-300000"
Explicated inertia : 92.705477
N’importe quelle variable quantitative choisie j’obtiens toujours cette classification. Donc la
variable budget est la plus explicative de mes concepts.

Projet Data Mining
Fabien BADEIG 23\24
10 TREE
J’ai choisi comme variable de classe la moyenne des bénéfices des films triés en fonction de
leurs intervalles des revenus. Mais j’ai transformé cette variable quantitative en une variable
qualitative. Pour cela, j’ai dû créer une nouvelle table transfovarquantQual qui a chaque
moyenne aussi une évaluation de cette variable en fonction de l’intervalle à laquelle elle
appartient.
Les intervalles de revenus des films nominés aux oscars dont la moyenne des bénéfices est
très moyen, se différencient de ceux dont la moyenne des bénéfices est faible et très faible,
par la valeur de la variable nombre d’oscars supérieure ou égale à 4. La catégorie « tres
moyen » a davantage d’oscars que que la catégorie « faible » et « tres faible ». De même, les
intervalles de revenus des films nominés aux oscars dont la moyenne des bénéfices est faible,
se différencient de ceux dont la moyenne des bénéfices est très faible, par la valeur de la
variable nombre d’oscars supérieure ou égale à 2.
Je ne peux pas exécuter la méthode TREE sur mes variables qualitatives car leur modalité est
supérieure à 12 ce qui est trop important pour la méthode (dommage car cette classification
aurait été intéressante pour mon étude).

Projet Data Mining
Fabien BADEIG 24\24
Conclusion
J’ai rencontré divers bugs sur des machines différentes lors de l’utilisation de SOADAS, et
pour être plus précis lors de l’exécution de la méthode PCM. Je n’ai pas réussi à connaître la
provenance de ces bugs. En fait, j’exécutais la méthode et une boite de dialogue m’indiquant
le loading de la méthode s’affichait ; ensuite j’obtenais un message d’erreur alors qu’il n’y
avait eu au préalable aucun problème avec la méthode SOE. Dans le même style lorsque la
méthode PCM ne renvoyait pas de message erreur, je n’obtenais pas de graphe et le rapport
m’indiquait qu’il fallait mettre un fichier en entrée comme paramètre (seul petit problème est
que tout était bien rentrée selon moi). Et encore plus bizarre j’ai essayé de réaliser le même
chaining sur l’ordinateur d’un des étudiants du DEA et la méthode fonctionnait.
A part ces contre temps, ce projet m’a permis de mettre en pratique les différentes notions
vues en cours sur l’analyse factorielle et surtout de nous familiariser avec l’outil SODAS. On
a pu vraiment appliquer concrètement les notions abordées en cours et ainsi avoir une
visualisation







