Download - DeNAオリジナル ゲーム専用プラットフォーム Sakashoについて

オリジナル
ゲーム専用プラットフォーム
について

少し自己紹介
● 2008年 DeNA入社(みんなのウェディング)
● 2010年 エンジニアになる
● 2011年 DeNA退社 -> 福岡へ
● 2013年 DeNAに出戻り
● 2016年 ゲーム事業本部
●
●
春山 誠

DeNAのゲーム開発について
DeNA for GAME CREATORS
参照元 : http://recruit-games.dena.jp/technology/

DeNA for GAME CREATORS
参照元 : http://recruit-games.dena.jp/technology/
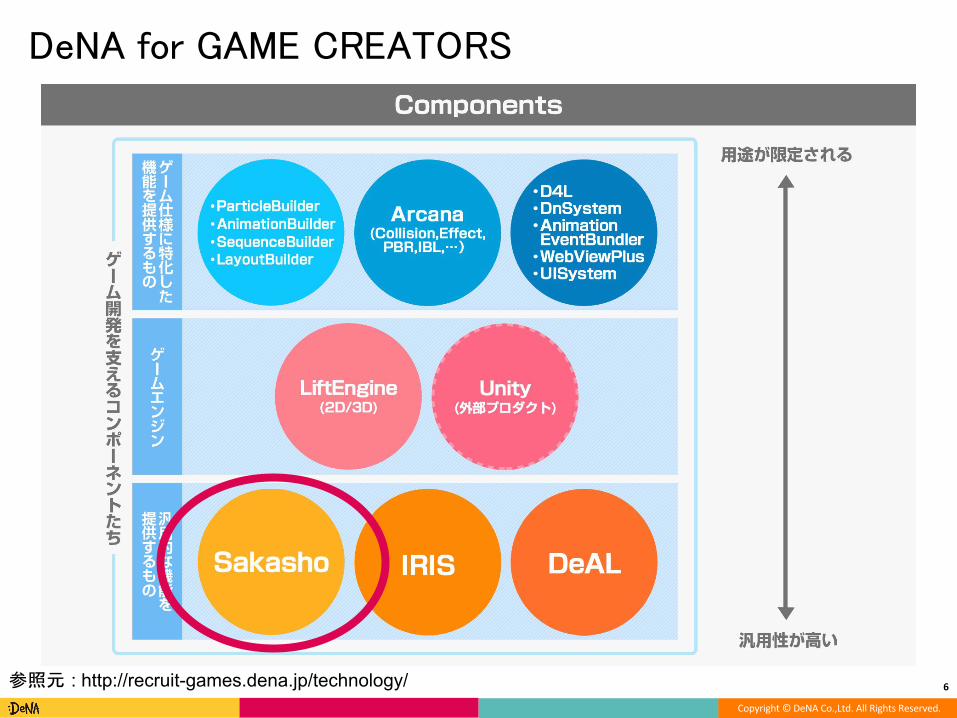
DeNA for GAME CREATORS
参照元 : http://recruit-games.dena.jp/technology/

DeNA for GAME CREATORS
参照元 : http://recruit-games.dena.jp/technology/

今日お話すること
1. Sakashoとは
2. Sakashoの構成について
3. Rubyを使った開発について
4. 最近の取り組み
5. まとめ

Sakashoとは

DeNA for GAME CREATORS
ネイティブゲーム用プラットフォーム
Sakasho
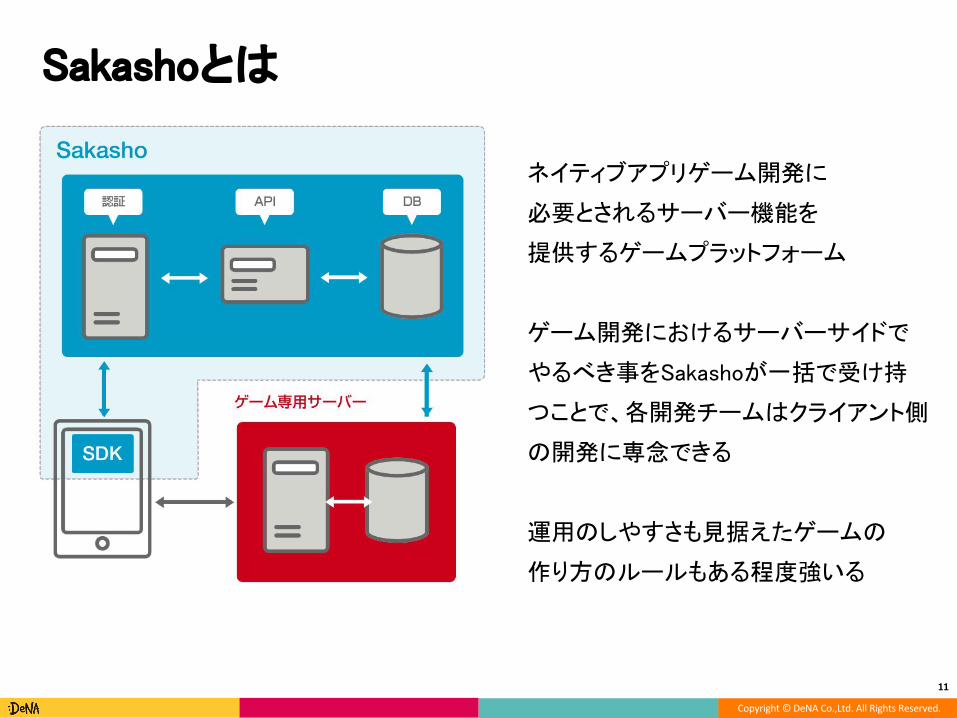
Sakashoとは
ネイティブアプリゲーム開発に
必要とされるサーバー機能を
提供するゲームプラットフォーム
ゲーム開発におけるサーバーサイドで
やるべき事をSakashoが一括で受け持
つことで、各開発チームはクライアント側
の開発に専念できる
運用のしやすさも見据えたゲームの
作り方のルールもある程度強いる

ゲーム開発・運用に必要なAPIの提供
● ユーザー情報API
● マスターデータ配信API
● ログインボーナスAPI など
Sakashoが提供している機能
● 課金API
● アセット配信API
● CS対応のための機能
SDK
● 課金やPush通知など、OSに依存している機能について
簡単に使えるインターフェースの提供
● Unity、C++のゲームエンジンに対応
Sakashoが提供している機能

WebView用インターフェースの提供
● お知らせの配信
● 掲示板
● 利用規約など
Sakashoが提供している機能
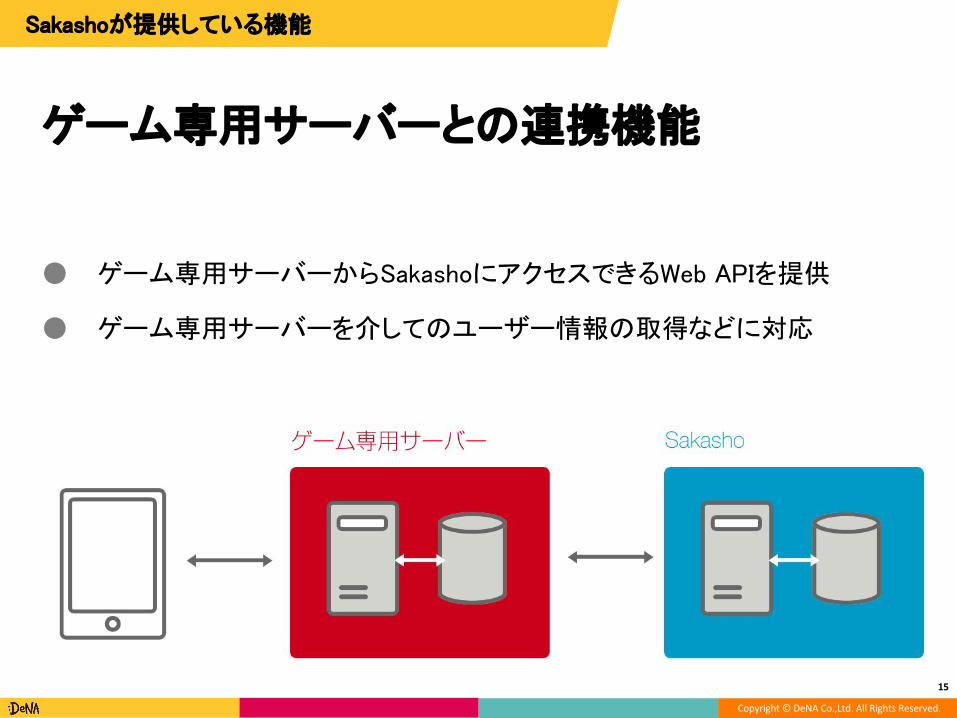
ゲーム専用サーバーとの連携機能
● ゲーム専用サーバーからSakashoにアクセスできるWeb APIを提供
● ゲーム専用サーバーを介してのユーザー情報の取得などに対応
Sakashoが提供している機能

Sakashoの機能一覧(一部抜粋)
● マスターデータ配信
● アセット配信
● プレイヤー管理
● お知らせ管理
● アイテム管理
● ログインボーナス
● お問合せ機能
● 課金
● ログ管理
● ランキング
● 掲示板
● 補填機能
● メンテナンス
● Push通知
● プレイヤー検索機能
● ギルド
● アプリのバージョン管理
● CS運用ツール
Sakashoが提供している機能
主なリリースタイトル

Sakashoの構成について

Sakashoの構成について

Sakashoの構成について(Web View)

マイクロサービス?
役割毎に10の独立したAPIコード群がある
○ メリット
■ 他のAPIへの影響を考えずにデプロイできる
■ リソースを細かく調整できる
○ デメリット
■ 運用工数がかかる(gemの更新とか)
■ 結局サービス毎に人を専用にアサインとかしなかったので、全員
全部見る状態
コード量も少ない(API全部ファイル数が700程度、行数3万行)のでこの規模
だと管理工数のほうが大きい
Sakashoの構成について

Sakashoの構成について

○ MySQLのMaster/Slave構成 + sharding
○ MHAでMasterの高可用性
○ MySQLへの接続は都度接続
○ DNSサーバーはMyDNSを使って、DeNA独自の拡張も入っている
DB周りは、基本インフラチームの指針にそっており、DeNAのオーソドックス
な構成になっています
Sakashoの構成について
DBに関して

Rubyを使った開発

Rubyを書ける人が多いチーム
○ Rubyで開発、運用 > Perlでの開発・運用
○ 何かあってもフォローできる人材がいる
採用面
○ Rubyでサービス開発を経験している人材の増加
Rubyの選択
Rubyを使った開発
PerlからRubyへの移行対応も責任をもって進めた

1. API サーバー : Sinatra + Sequel + Jbuilder
a. アクセス数が多いので、省メモリ・ハイパフォーマンス
b. JSONしか返さない
2. Web View向けWeb サーバ : Ruby on Rails
a. アクセス数は少ない
b. DBに直接アクセスせずに、1のAPIを経由してデータを取得する(API
の仕様そのまま)
c. Web UIを簡単に作れる
フレームワーク選定
Rubyを使った開発

1. 管理 ツール : Ruby on Rails
a. アクセス数は限られている
b. Web UIを簡単に作れる
c. 多少パフォーマンスが犠牲にしても、開発スピードを上げる
フレームワーク選定
Rubyを使った開発

詳細は下記資料をご参照頂ければ
Rubyを使った開発期
http://www.slideshare.net/blueskyblue/de-na-game-backend-as-a-service-20150129

最近の取り組み

パフォーマンス向上

キャッシュ戦略

最近の取り組み
● 基本的にSakashoのキャッシュ戦略はオンメモリキャッシュ
● 幸か不幸かマイクロサービスっぽい作りで、役割分担がされている
○ SakahsoはのAPIサーバーはprefork型(rubyのUnicorn)
○ wokerの数はAPI単位だと少ない(10位)
○ メモリの消費は激しくないため、念のため定期的に再起動はしてい
るが、それにも1h一回程度
■ 1サーバ 125プロセス(60MB 〜 100MB/process)
○ 主にゲームの設定値をキャッシュするので、そこまでメモリを消費す
ることもない
メモリキャッシュ

最近の取り組み
DBのクエリ改善

最近の取り組み
● KVS使う?
○ 一旦冷静に考えて
○ request headerに詰めて渡しているのもある
■ プレイヤーのID
■ shardのID
Proxy -> API間でどうやって共有?

DBのindex

最近の取り組み
● まあ、あるあるで昔作ったコードでPKがない、indexが足りてないとかとか
がたくさんある。。。。
● どうやって修正していくか?
○ 目をつむって ALTER(まあ、40万rowsくらい目安) + Online DDL
○ 徐々に移行(別テーブルに移す)
○ ALTER打ってMHA(最終手段)
○ 仕様変える
まあ、当たり前にみんなやるよね。。

最近の取り組み
● まあ、あるあるで昔作ったコードでPKがない、indexが足りてないとかとか
がたくさんある。。。。
● どうやって修正していくか?
○ 目をつむって ALTER(まあ、40万rowsくらい目安) + Online DDL
○ 徐々に移行(別テーブルに移す)
○ ALTER打ってMHA(最終手段)
○ 仕様変える
まあ、当たり前にみんなやるよね。。

最近の取り組み
● テーブル定義、indexが正しいテーブルを用意
● 古いテーブルと新しいテーブルへ二重に書き込み
○ 整合性チェックスクリプトは用意しておく
● (有効期限あるデータなのであれば)古いテーブルにデータがなければ、
新しいテーブルをみるようなフォールバックコードをいれる
● 移行完了かどうか判定するスクリプトは用意しておき、確認
● 確認完了したら、古いテーブルへの書き込みは停止
● 新しいテーブルのみの参照に切り替え
徐々に移行

Disk Full

最近の取り組み
Diskがあふれる
● プレイヤーの保存履歴を持っている
○ 保存するたびにjsonを保存している
○ DBに保存するには大きすぎるが、ログとして残しておく必要がある
○ DBの増設やshardで対応は現実的でない

最近の取り組み
S3へ逃がす
● jsonをS3へ逃がす
○ dailyでプレイヤー毎に履歴をjsonファイルにして、S3へアップロード
する
○ 今は毎日バッチで対応
● 管理ツールからの検索
○ 日付とプレイヤーのIDで履歴を閲覧可能に
○ そこまでの検索頻度はないので転送量はそこまでかかっていない

メモリ効率化

最近の取り組み
● SakahsoはのAPIサーバーはprefork型(rubyのUnicorn)
● 今までは、Unicornの新しいプロセス(master + worker)が全て新規に立ち
上がるのを見届けてから古いプロセスを停止させていた
○ 一時的にプロセス数が全体の2倍になり、最悪の場合メモリ使用量
が平常時の2倍になりえる (CoWが効いているのでので実際には2
倍にはならないが。。。)
● これを防ぐために、新しいworkerプロセスを1つ起動できたタイミングで古
いworkerプロセスを停止するように修正
APIサーバーのslow restart

最近の取り組み
DeNAのオーソドックスなプロセス管理
● daemontools
○ プロセスの監視
■ プロセスが死んだ場合の自動再起動
○ ログの収集

最近の取り組み
DeNAのオーソドックスなプロセス管理
● daemontools + unicorn
○ unicornをdaemontoolsの配下で動かそうと思ったとき、masterを
graceful restartしようとSIGUSR2を送信すると、親プロセス(旧
worker)が終了した時点で子プロセス(新worker)がinitプロセスの養
子に入ってしまう
○ そうするとdaemontoolsの管理から外れてしまう
○ そこでgraceful restartをServer::Starterに任せる構成にしている
参照元 : http://d.hatena.ne.jp/limitusus/20131225/1387993119

最近の取り組み
DeNAのオーソドックスなプロセス管理
/bin/sh /command/svscanboot\_ svscan /service| \_ supervise log| | \_ multilog t s999999 n10 ./main| \_ supervise sake| | \_ perl start_server --path=/sake/current/tmp/sockets/unicorn.sock --signal-on-term=QUIT --signal-on-hup=QUIT --status-file=/sake.status --pid-file=/sake.pid --dir=/sake/current --envdir=/sake/env -- /sake/current/bin/unicorn -c config/unicorn.rb| | \_ unicorn master #sake -c config/unicorn.rb| | \_ unicorn worker[0] #sake -c config/unicorn.rb

最近の取り組み
● すでにServer::Starter + kill-old-delay で運用されている
● 稼働サーバー台数も増えている
○ --signal-on-hupの変更(QUITからCONTへ)を行うことは、作業量が
多すぎるため避ける
○ ワーカー数の多いAPIについてはkill-old-delayを伸ばした上で、
slow restartを導入する
Sakashoの場合の運用事情

最近の取り組み
● check-rack-server-status での監視が unicorn の masterプロセスに対
して、空いているワーカー数を数えている
○ 再起動直後はワーカー数が足りない状態が検出されてしまうという
問題
○ 回避するためcheck-rack-server-statusは複数リクエストの結果で
判断してもらうように監視を修正
Sakashoの場合の運用事情

APIサーバーのslow restart
最近の取り組み
● 実際どうなったの?

キャパシティ管理

最近の取り組み
● リソースの取得方法
○ 自前 daemon
○ fluentd
● リソースの可視化
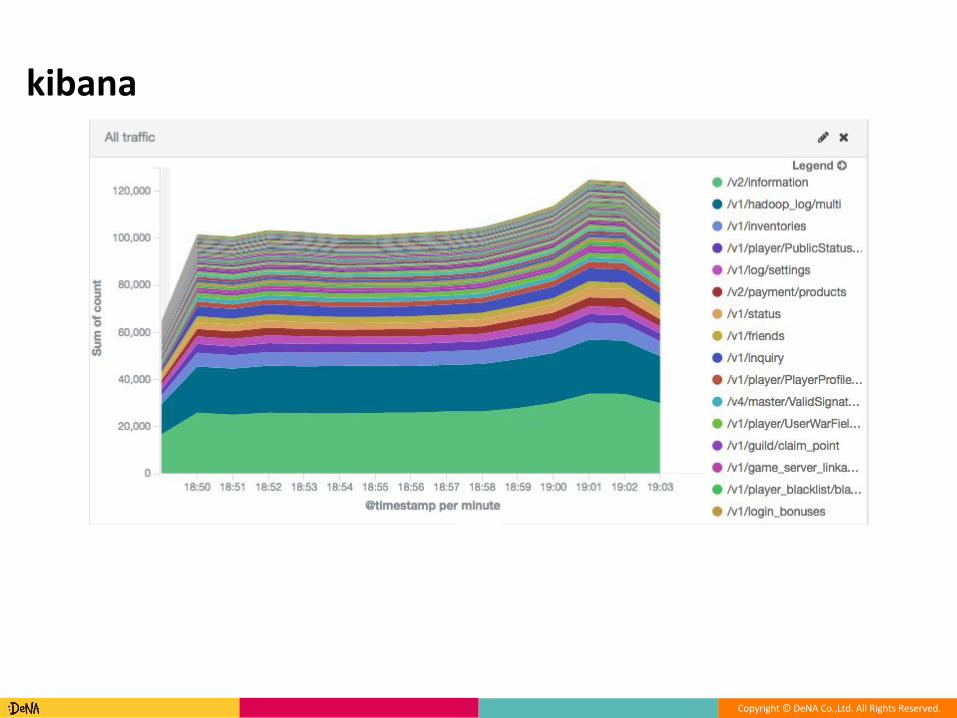
○ kpi-viewer
○ kibana
● 必要リソースの見積もり + リソースレポート作成
○ report-sakasho-web-kpi
キャパシティ管理

● リソースログの取得○ 共通
■■■
○■
○■
●●● など
○ 内製 を各サーバに設置し収集したリソースログを に保存
リソースの取得方法1

● アクセスログの収集○
■ 各 サーバ上で実行● を収集
○○○○
■●
○ 物理実機● で可視化
リソースの取得方法2
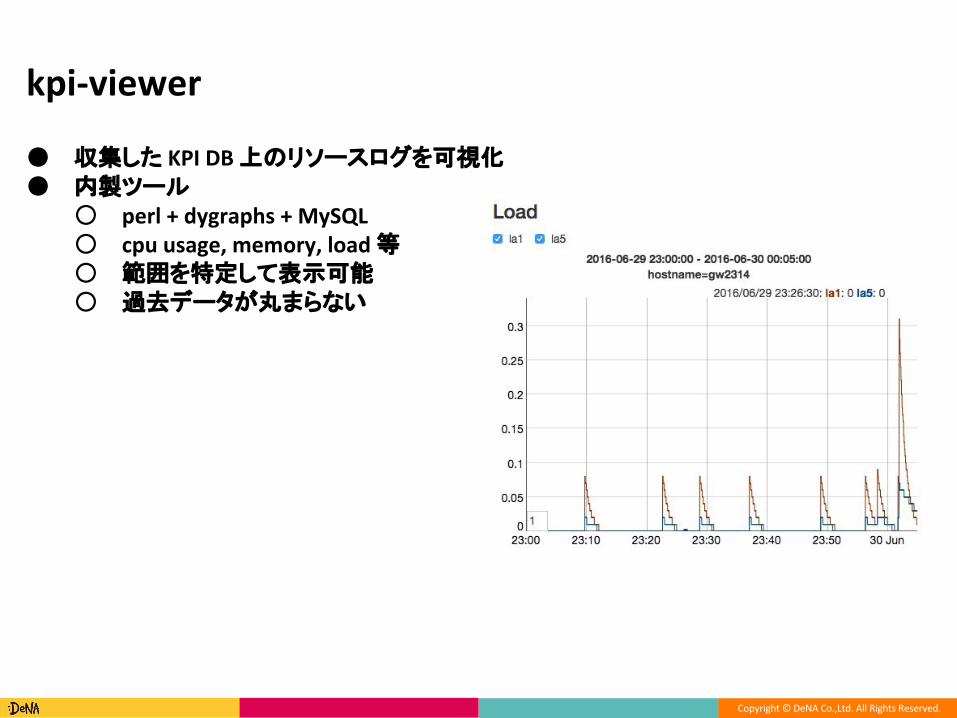
● 収集した 上のリソースログを可視化● 内製ツール
○○ 等○ 範囲を特定して表示可能○ 過去データが丸まらない
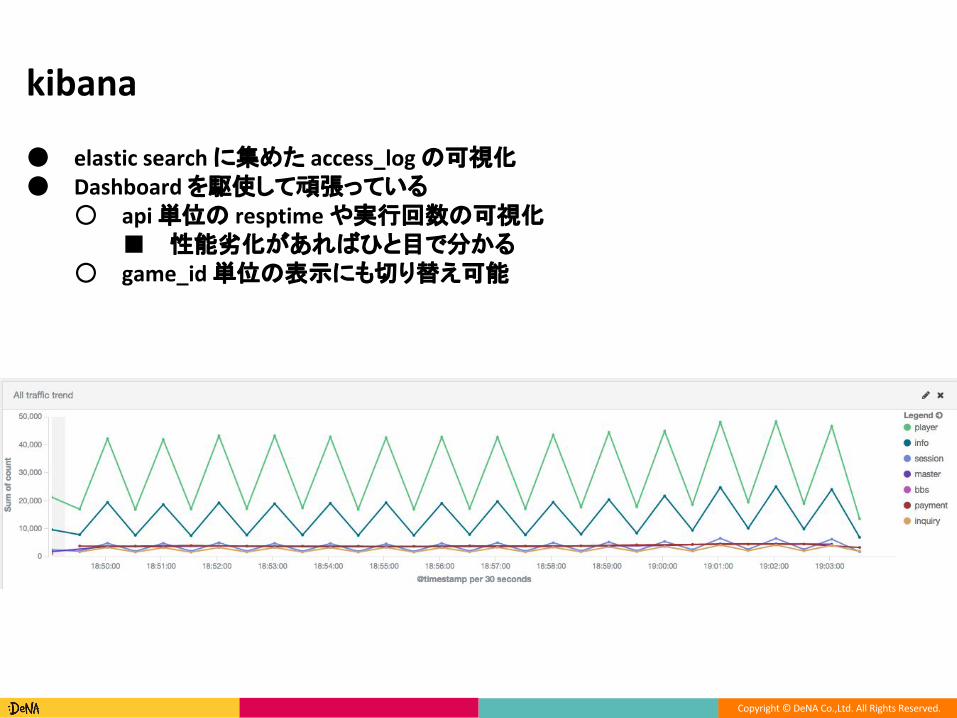
● に集めた の可視化● を駆使して頑張っている
○ 単位の や実行回数の可視化■ 性能劣化があればひと目で分かる
○ 単位の表示にも切り替え可能

● の 回数はゲームによって異なる○ なら 万 捌けても、 は一極集中型のため、 万が限界○ ということもあり、リソース見積もりが難しい○ 分間 万回のコールならば捌けるという視点で考える
● 単位の収容限界値は、ここまでで取得したデータから見積もり可能○ ならば、 万 処理可能
● つまり、テストプレイで得られたデータ 目標 の負荷が乗った場合、耐えられるか計算すればよい

● キャパシティの過不足判断を出来るコマンドを開発
基準日目標
● 基準日に新規タイトルの負荷が上乗せされた場合のリソースをシミュレーション● 経験上、 は の を超えることは非常に考えにくい● すべてのユーザがテストプレイ通りにアクティブにプレイすることはあり得ない
○ 上限値と見做して問題なし

● 本スクリプトを に仕込み、日次で実行○ を飛ばし、日々振り返り実施○ 台数調整の指標

最近の課題

Sakashoチーム

チーム
○ だいたい8人くらい
■ ブラウザタイトル担当からアプリタイトル担当へ移行する際に
Sakashoの運用を経験することが多い
リリースサイクル
○ 2週間に一度のペースでリリース
○ 2週間でできることやる
Sakasho専任チーム
Sakashoチーム
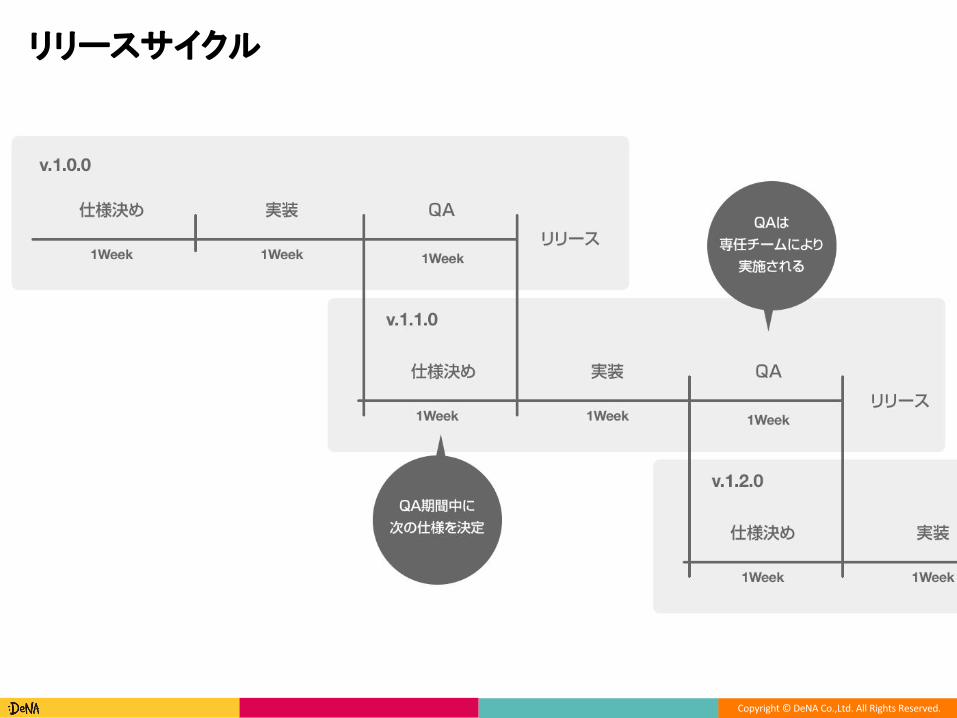
リリースサイクル

● 要望確確認会: リリースに含める
フィーチャーを検討
● Sakasho定例: リリースに含める予
定のフィーチャーをチームにシェア
● QA Kickoff: リリースに予定の
フィーチャーをQAに伝え、リリース
するフィーチャーとリリース日を決
める
● リリース告知: ゲームデベロッパに
アナウンスする。
リリースサイクルを細かく
● 仕様書コンプリート
● 開発開始
● SDKのスケルトン提出
● フィーチャーコンプリート
● QA開始
● サインオフ(QA完了)
● リリース
● QA確認
● ゲームデベロッパにリリースした旨をア
ナウンス
● Sakasho定例: フェーズの振り返り
Sakashoチーム

その結果

Sakashoチーム
● 機能数の増大
○ 約50のAPI(メソッド単位だともっと、、)
● SDKのバージョンも増えている
○ 全部で45バージョンくらい
● 変にマイクロサービスぽくしていて開発効率が悪い
○ 共通化されているgemの管理
機能数の増大と複数バージョンのサポート

品質の担保
デグレチェック

人の手でやることじゃない

SDKのテストと自動化

最近の取り組み
● google製のC++テスティングFW
○ https://github.com/google/googletest
○ ライブラリのインストールはいらず、ccファイルをテストコードと一緒
にビルドすればテストの実行ファイルができる
● Xcode(XCTest)と一緒に動かせる
● テスト結果を出力しやすいこと(JUnit形式)
● Native Sakasho SDKが対象
googletestの採用
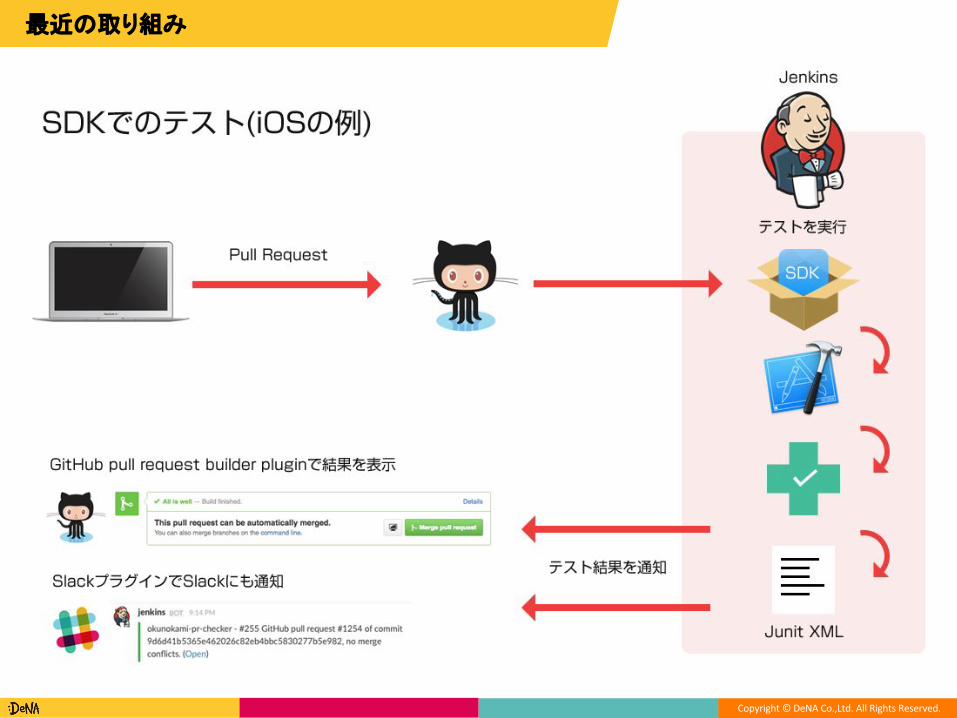
最近の取り組み
SDK
✔テスト結果を通知
テストを実行
Slackプラグインで通知も
GitHub pull request builder pluginで結果を表示
PP
Junit XML

最近の取り組み
SDKのテスト(iOS)

DEMO(時間があれば)
最近の取り組み
SDKのテスト
● SWETチームとの共同作業
参照元 : https://career.dena.jp/job.phtml?job_code=476

まとめ
ゲーム開発を支えるプラットフォームSakasho
○ Sakashoがサーバー側の運用を一括で受け持つことで
各ゲームタイトルはゲーム開発に集中できる
Sakashoのサーバーサイドの開発はRubyを使っている
○ 大規模なアプリケーションの開発・運用に
必要な仕組みを整備しました
開発・運用の効率化を行っています
○ API
■ メモリキャッシュの利用
■ slow restartの対応
○ SDK
■ googletestを利用した結合テストの整備







