Download - Crawleando sites com NodeJS

1
CRAWLEANDO SITES COMNODEJS
JSDAY CAMPINA GRANDE 2016Allisson Azevedo

2
ALLISSON AZEVEDOallissonazevedo.com
youtube.com/user/allissonazevedo
github.com/allisson
twitter.com/allisson
allisson.github.io/slides/

3
OBJETIVOCrawlear o Obter as receitas com imagemIndexar no ElasticsearchExibir os resultados com o ExpressJS
http://www.tudogostoso.com.br

4
WEB CRAWLER / ROBOT / SPIDERUm programa que navega por toda a rede de maneiraautomáticaGooglebot, BingBot, Yahoo! Slurp, BaiduspiderOpção quando não houver acesso aos dados via Web API

5
FUNCIONAMENTO1. Carrega url2. Parser do conteúdo3. Carrega novas urls a partir dos links da atual

6
FERRAMENTASnpm install requestnpm install cheerionpm install simplecrawler

7
SPEAKERS DO JSDAY'use strict'; const request = require('request'); const cheerio = require('cheerio');
request('http://jsday.com.br/speakers/', (error, response, body) => { let $ = cheerio.load(body); let speakers = []; $('.people-modal').each((i, element) => { let speaker = {}; speaker.title = $(element).find('h4').text(); speaker.description = $(element).find('.theme-description').text(); speaker.name = $(element).find('.name').contents()[0].data.trim(); speaker.about = $(element).find('.about').text(); speaker.image = $(element).find('.people-img').css('background-image').replace( speakers.push(speaker); }); console.log(JSON.stringify(speakers, null, 2)); });

8
PROGRAMAÇÃO DO JSDAY'use strict'; const request = require('request'); const cheerio = require('cheerio');
request('http://jsday.com.br/schedule/', (error, response, body) => { let $ = cheerio.load(body); let subEvents = []; $('.timeslot[itemtype="http://schema.org/subEvent"]').each((i, element) => { let event = {}; event.title = $(element).find('.slot-title').text(); event.time = $(element).find('.start-time').attr('datetime'); subEvents.push(event); }); console.log(JSON.stringify(subEvents, null, 2)); });
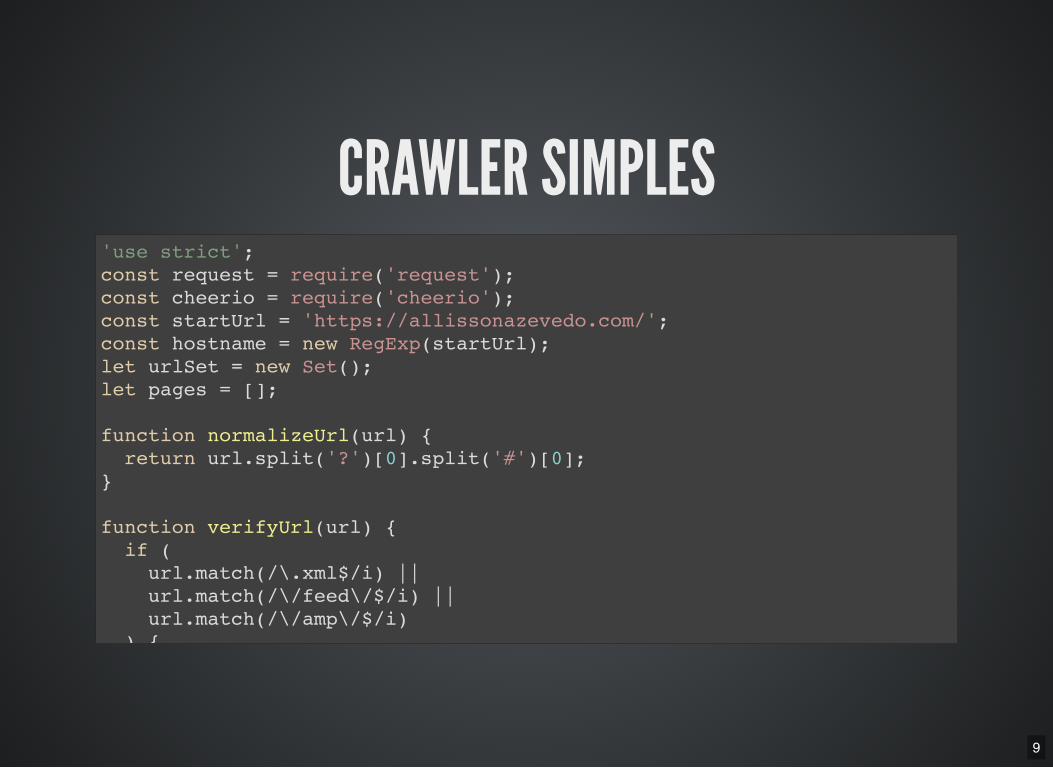
9
CRAWLER SIMPLES'use strict'; const request = require('request'); const cheerio = require('cheerio'); const startUrl = 'https://allissonazevedo.com/'; const hostname = new RegExp(startUrl); let urlSet = new Set(); let pages = [];
function normalizeUrl(url) { return url.split('?')[0].split('#')[0]; }
function verifyUrl(url) { if ( url.match(/\.xml$/i) || url.match(/\/feed\/$/i) || url.match(/\/amp\/$/i) ) {
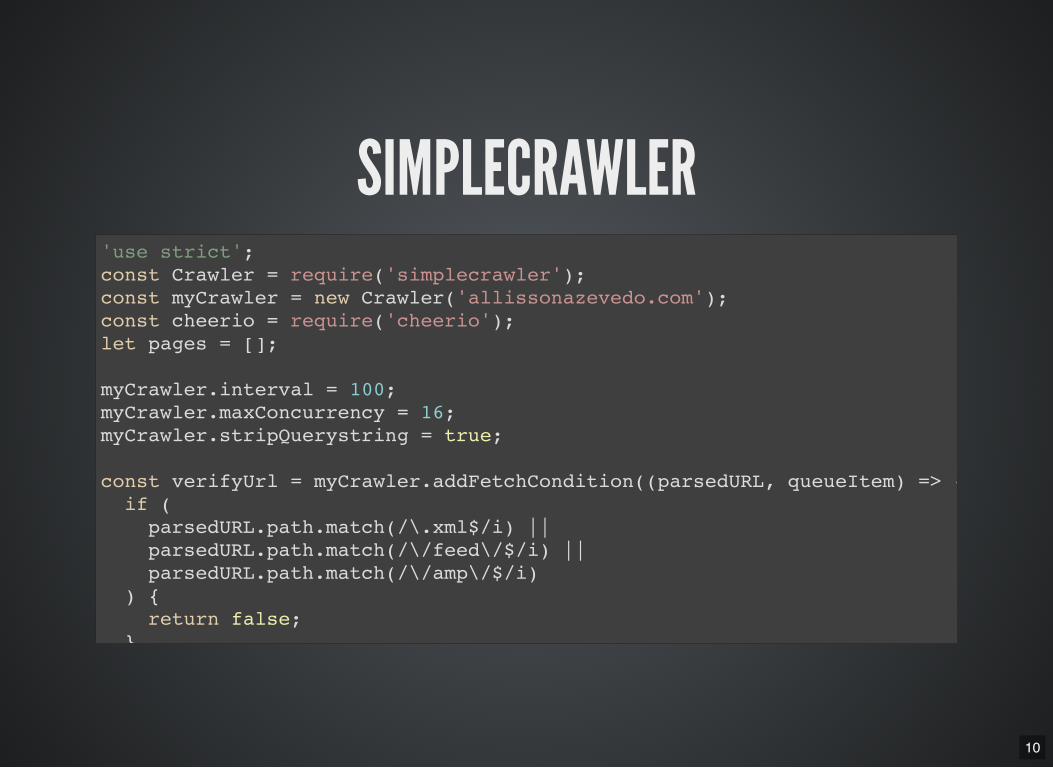
10
SIMPLECRAWLER'use strict'; const Crawler = require('simplecrawler'); const myCrawler = new Crawler('allissonazevedo.com'); const cheerio = require('cheerio'); let pages = [];
myCrawler.interval = 100; myCrawler.maxConcurrency = 16; myCrawler.stripQuerystring = true;
const verifyUrl = myCrawler.addFetchCondition((parsedURL, queueItem) => { if ( parsedURL.path.match(/\.xml$/i) || parsedURL.path.match(/\/feed\/$/i) || parsedURL.path.match(/\/amp\/$/i) ) { return false; }

11
CRAWLEANDO O TUDOGOSTOSO1. Veri�car as urls que são carregadas2. Identi�car as urls que são receitas3. Parser e indexação no Elasticsearch
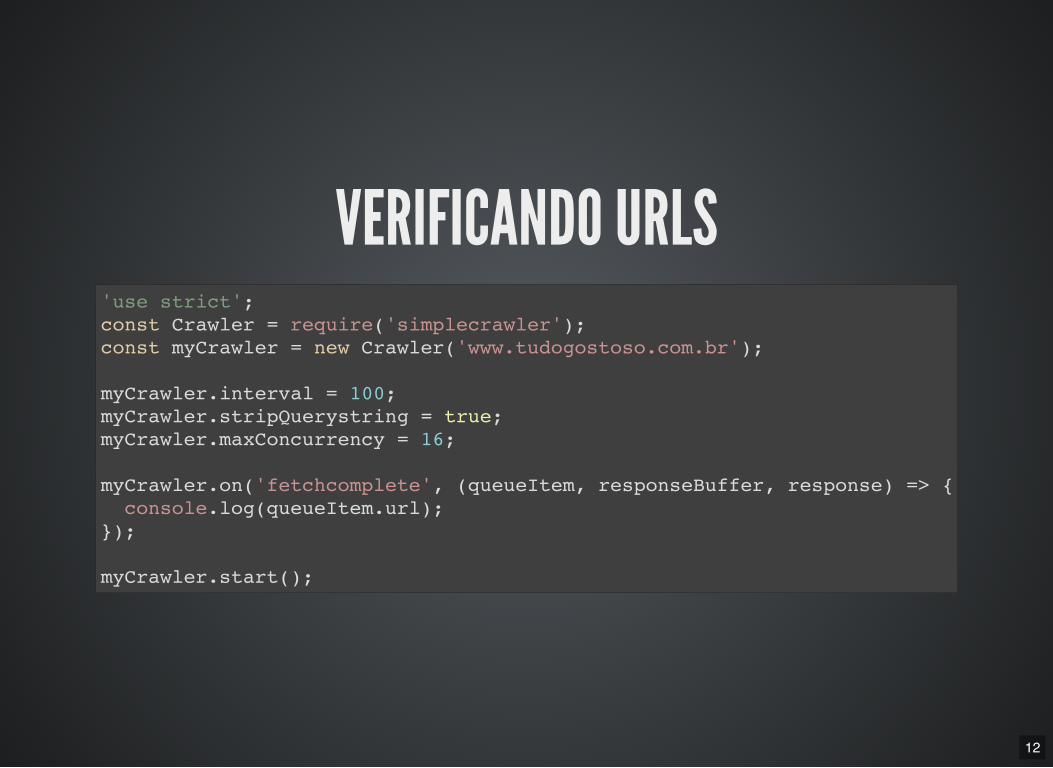
12
VERIFICANDO URLS'use strict'; const Crawler = require('simplecrawler'); const myCrawler = new Crawler('www.tudogostoso.com.br');
myCrawler.interval = 100; myCrawler.stripQuerystring = true; myCrawler.maxConcurrency = 16;
myCrawler.on('fetchcomplete', (queueItem, responseBuffer, response) => { console.log(queueItem.url); });
myCrawler.start();

13
URLS QUE DEVEMOS EVITARhttp://www.tudogostoso.com.br/favicon-v2.1.ico
http://www.tudogostoso.com.br/app/assets/stylesheets/ie.css
http://www.tudogostoso.com.br/images/layout/logo-v4.png
http://www.tudogostoso.com.br/assets/layout/blank.gif
http://www.tudogostoso.com.br/imagens/renew/footer-bg.jpg
http://www.tudogostoso.com.br/dicas/10-pontos-do-brigadeiro/print
http://www.tudogostoso.com.br/receita/print_recipe.php?recipe_id=2721
http://www.tudogostoso.com.br/receita/4683/comentarios.js
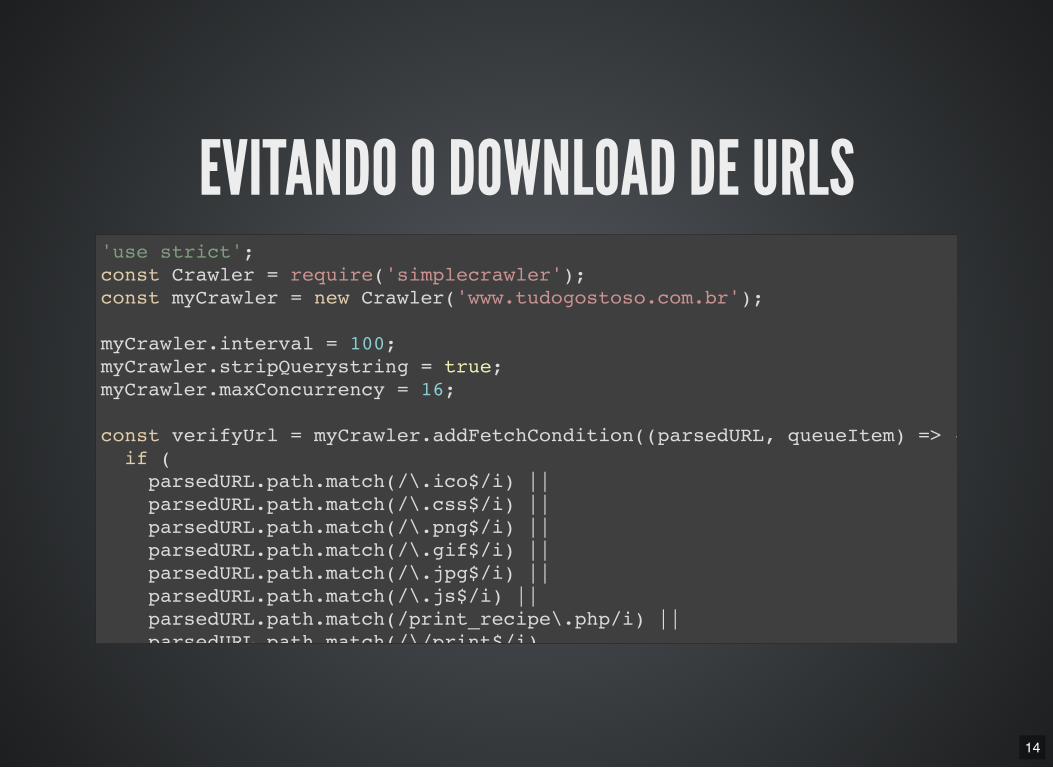
14
EVITANDO O DOWNLOAD DE URLS'use strict'; const Crawler = require('simplecrawler'); const myCrawler = new Crawler('www.tudogostoso.com.br');
myCrawler.interval = 100; myCrawler.stripQuerystring = true; myCrawler.maxConcurrency = 16;
const verifyUrl = myCrawler.addFetchCondition((parsedURL, queueItem) => { if ( parsedURL.path.match(/\.ico$/i) || parsedURL.path.match(/\.css$/i) || parsedURL.path.match(/\.png$/i) || parsedURL.path.match(/\.gif$/i) || parsedURL.path.match(/\.jpg$/i) || parsedURL.path.match(/\.js$/i) || parsedURL.path.match(/print_recipe\.php/i) || parsedURL.path.match(/\/print$/i)
15
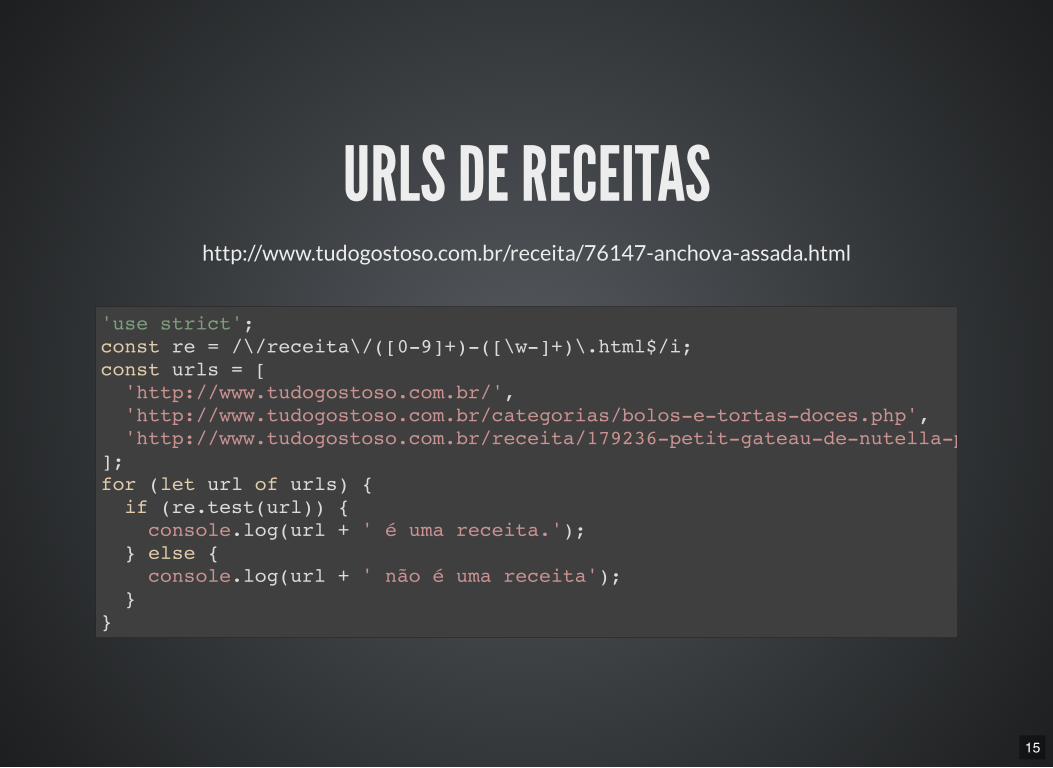
URLS DE RECEITAShttp://www.tudogostoso.com.br/receita/76147-anchova-assada.html
'use strict'; const re = /\/receita\/([0-9]+)-([\w-]+)\.html$/i; const urls = [ 'http://www.tudogostoso.com.br/', 'http://www.tudogostoso.com.br/categorias/bolos-e-tortas-doces.php', 'http://www.tudogostoso.com.br/receita/179236-petit-gateau-de-nutella-perfeito.html']; for (let url of urls) { if (re.test(url)) { console.log(url + ' é uma receita.'); } else { console.log(url + ' não é uma receita'); } }

16
PARSER DA RECEITA'use strict'; const cheerio = require('cheerio'); const Crawler = require('simplecrawler'); const myCrawler = new Crawler('www.tudogostoso.com.br'); const re = /\/receita\/([0-9]+)-([\w-]+)\.html$/i;
myCrawler.interval = 100; myCrawler.stripQuerystring = true; myCrawler.maxConcurrency = 16;
const verifyUrl = myCrawler.addFetchCondition((parsedURL, queueItem) => { if ( parsedURL.path.match(/\.ico$/i) || parsedURL.path.match(/\.css$/i) || parsedURL.path.match(/\.png$/i) || parsedURL.path.match(/\.gif$/i) || parsedURL.path.match(/\.jpg$/i) || parsedURL.path.match(/\.js$/i) ||
17
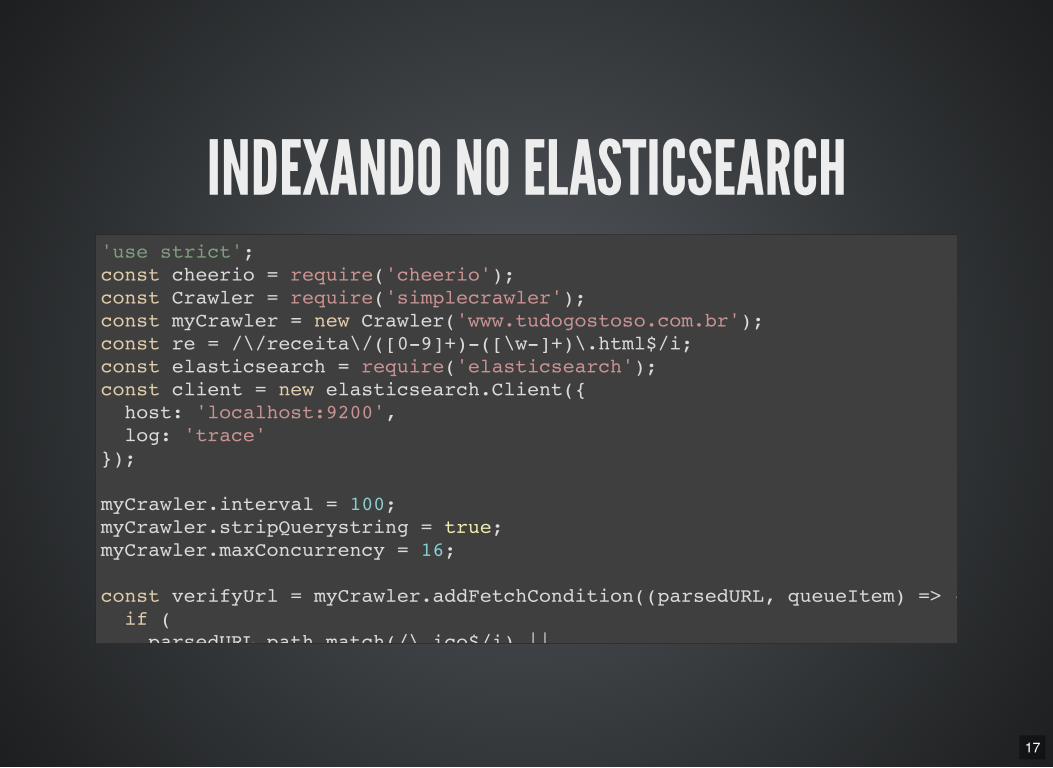
INDEXANDO NO ELASTICSEARCH'use strict'; const cheerio = require('cheerio'); const Crawler = require('simplecrawler'); const myCrawler = new Crawler('www.tudogostoso.com.br'); const re = /\/receita\/([0-9]+)-([\w-]+)\.html$/i; const elasticsearch = require('elasticsearch'); const client = new elasticsearch.Client({ host: 'localhost:9200', log: 'trace' });
myCrawler.interval = 100; myCrawler.stripQuerystring = true; myCrawler.maxConcurrency = 16;
const verifyUrl = myCrawler.addFetchCondition((parsedURL, queueItem) => { if ( parsedURL.path.match(/\.ico$/i) ||

18
DEMO DO WEBAPP

19
OBRIGADO!







