
“Artificial Intelligence” in my research
Seung-won HwangDepartment of CSE
POSTECH

2
Recap
Bridging the gap between under-/over-specified user queries
We went through various techniques to support intelligent querying, implicitly/automatically from data, prior users, specific user, and domain knowledge
My research shares the same goal, with some AI techniques applied (e.g., search, machine learning)

3
The Context:
Rank Formulation
Rank Processing
select * from housesorder by [ranking function F]limit 3
ranked results
querytop-3 houses
e.g., realtor.com

4
Overview
Rank Formulation
Rank Processing
select * from housesorder by [ranking function F]limit 3
ranked results
querytop-3 houses
e.g., realtor.com
Usability:Rank Formulation
Efficiency:Processing Algorithms

5
Part I: Rank Processing
Essentially a search problem (you studied in AI)
6
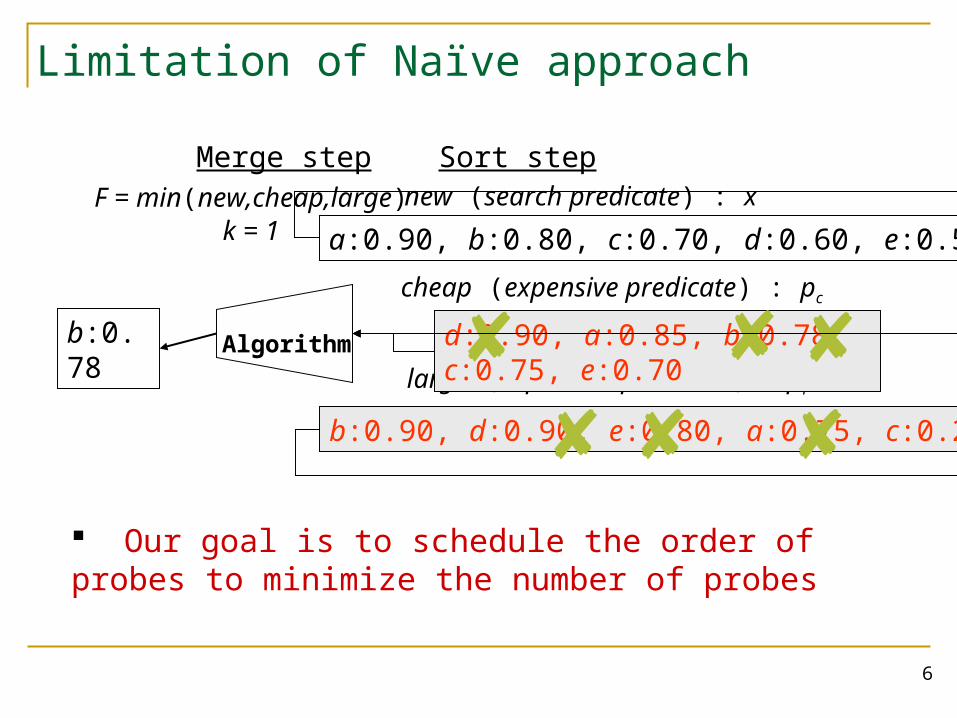
Limitation of Naïve approach
a:0.90, b:0.80, c:0.70, d:0.60, e:0.50
b:0.78 Algorithm
F = min(new,cheap,large)k = 1
Sort stepMerge stepnew (search predicate) : x
cheap (expensive predicate) : pc
large (expensive predicate) : pl
d:0.90, a:0.85, b:0.78, c:0.75, e:0.70
b:0.90, d:0.90, e:0.80, a:0.75, c:0.20
Our goal is to schedule the order of probes to minimize the number of probes
7
a:0.9
b:0.8
c:0.7
d:0.6
e:0.5
a:0.85
b:0.8
c:0.7
d:0.6
e:0.5
pr(a,pc) =0.85
pr(a,pl) =0.75
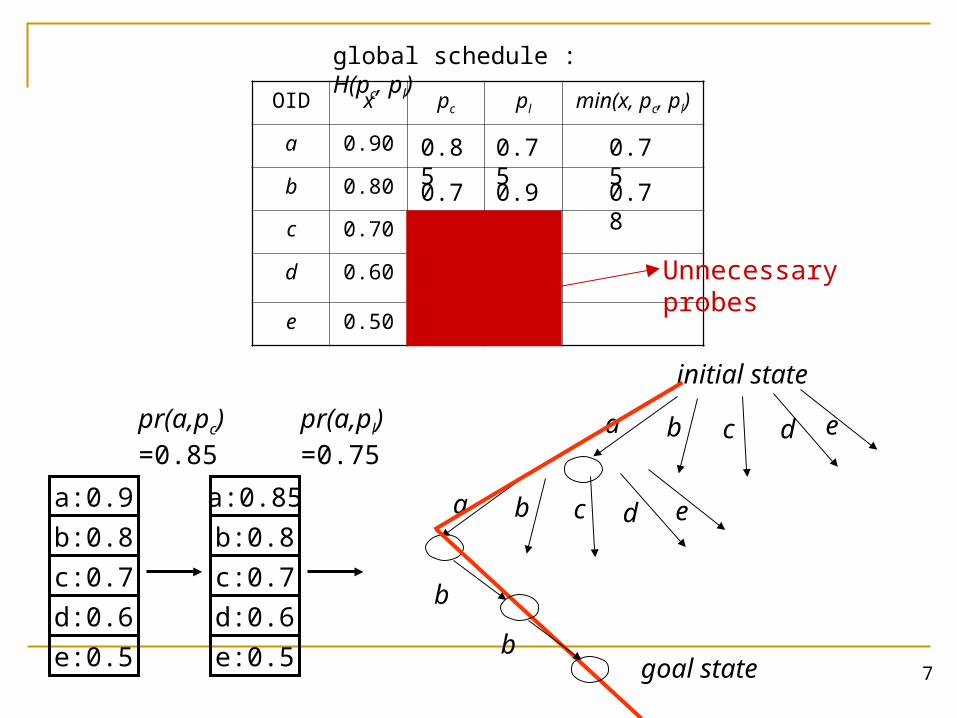
OID x pc pl min(x, pc, pl)
a 0.90
b 0.80
c 0.70
d 0.60
e 0.50
0.85
0.78
0.75
0.90
0.75
0.78
global schedule : H(pc, pl)
Unnecessary probes
initial state
a b c d
ea b c d
e
b
bgoal state

8
Search Strategies?
Depth-first Breadth-first Depth-limited / iterative deepening (try every depth
limit) Bidirectional Iterative improvement (greedy/hill climbing)

9
Best First Search
Determining which node to explore next, using evaluation function
Evaluation function: exploring more on object with the highest “upper bound
score” We could show that this evaluation function minimizes the
number of evaluation, by evaluating only when “absolutely necessary”.

10
Necessary Probes?
Necessary probes probe pr(u,p) is necessary if we cannot determine top-k
answers until probing pr(u,p), where u: object, p: predicate
OID x pc pl min(x, pc, pl)
a 0.90
b 0.80
c 0.70
d 0.60
e 0.50
top-1: b(0.78)
Can we decide top-1 without probing pr(a,pc)?
0.85
0.78
0.75
0.75
0.90
0.20
0.75
0.78
0.20
≤0.90
Let global schedule be H(pc, pl)
No pr(a,pc) necessary!
0.90 0.90
0.70 0.80
0.60
0.50

11
a:0.9
b:0.8
c:0.7
d:0.6
e:0.5
a:0.85
b:0.8
c:0.7
d:0.6
e:0.5
b:0.8
a:0.75
c:0.7
d:0.6
e:0.5
a:0.75
c:0.7
d:0.6
e:0.5
b:0.78b:0.78
a:0.75
c:0.7
d:0.6
e:0.5
b:0.78
pr(a,pc) =0.85
pr(a,pl) =0.75
pr(b,pc) =0.78
pr(b,pl) =0.90
Top-1
OID x pc pl min(x, pc, pl)
a 0.90
b 0.80
c 0.70
d 0.60
e 0.50
0.85
0.78
0.75
0.90
0.75
0.78
global schedule : H(pc, pl)
Unnecessary probes

12
Generalization
FA, TA, QuickCombine
r =1 (cheap)
r = h (expensive)
r = (impossible)
CA, SR-Combine
NRA, StreamCombine
s =1 (cheap)
s = h (expensive)
s = (impossible)
Random AccessSorted Access
FA, TA, QuickCombine
NRA, StreamCombine
MPro[SIGMOD02/TODS]
Unified Top-k Optimization[ICDE05a/TKDE]

13
Strong nuclear force
Electromagnetic force
Weak nuclear force
Gravitational force
Unified field theory
Just for Laugh: Adapted from Hyountaek Yong’s presentation

14
FA
TA
NRA
CA
MPro
Unified Cost-based Approach

15
Generality
Across a wide range of scenarios One algorithm for all

16
Adaptivity
Optimal at specific runtime scenario

17
Cost based Approach
Cost-based optimization Finding optimal algorithm for the given scenario, with
minimum cost,
from a space
)(argmin Ω MCostM Mopt
Mopt

18
Evaluation: Unification and Contrast (v. TA)
T
NN
T
N
Unification: For symmetric function, e.g., avg(p1, p2), framework NC behaves similarly to TA
Contrast: For asymmetric function, e.g., min(p1, p2), NC adapts with different behaviors and outperforms TA
depth into p1
dept
h in
to p
2
depth into p1
dept
h in
to p
2
costcost

19
Part II: Rank Formulation
Rank Formulation
Rank Processing
select * from housesorder by [ranking function F]limit 3
ranked results
querytop-3 houses
e.g., realtor.com
Usability:Rank Formulation
Efficiency:Processing Algorithms

20
Learning F from implicit user interactions
Using machine learning technique (that you will learn soon!) to combine quantitative model for efficiency and qualitative model for usability
Quantitative model Query condition is represented as a mapping F of objects into
absolute numerical scores DB-friendly, by attaining the absolute score on each object Example F( )=0.9 F( )=0.5
Qualitative model Query condition is represented as a relative ordering of
objects User-friendly by alleviating user from specifying the absolute
score on each object Example >
21
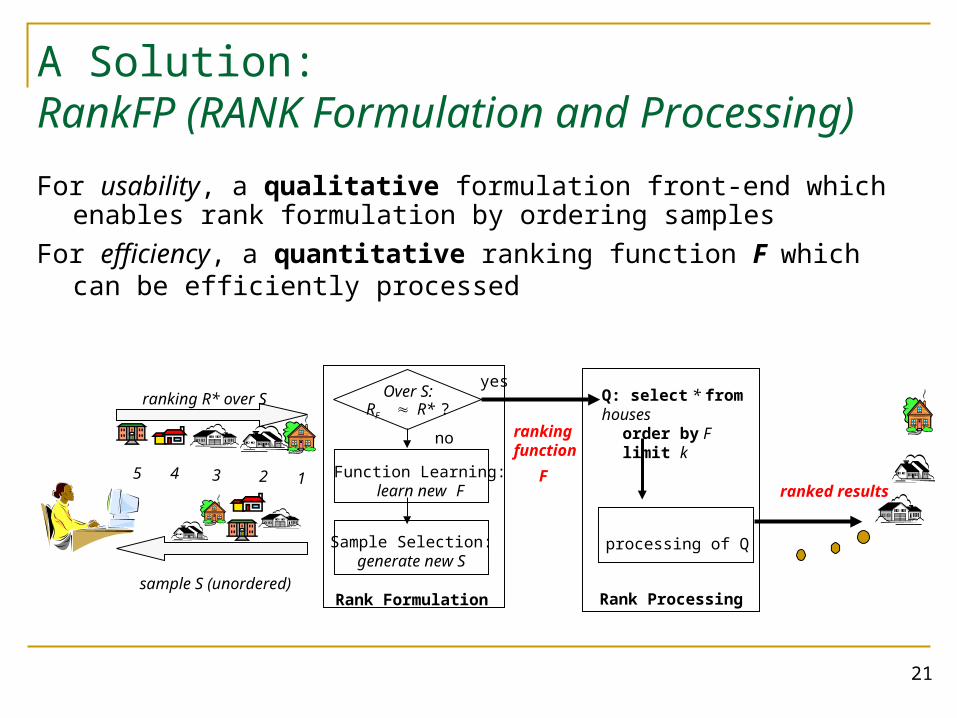
A Solution: RankFP (RANK Formulation and Processing)For usability, a qualitative formulation front-end which enables rank
formulation by ordering samples
For efficiency, a quantitative ranking function F which can be efficiently processed
sample S (unordered)
Sample Selection:generate new S
Function Learning:learn new F
ranking R* over S Over S:RF R* ?
12345
no
yes
F
ranking function
Rank Formulation Rank Processing
ranked results
processing of Q
Q: select * from houses order by F limit k

22
Task 1: RankingClassification
Challenge: Unlike a conventional learning problem of classifying objects into groups, we learn a desired ordering of all objects
Solution: We transform ranking into a classification on pairwise comparisons [Herbrich00]
learning algorithms: a binary classifier
+
-F
a-b
b-cc-dd-ea-c… …
ranking view: c > b > d > e > a
cb
de
a
classification view:
--++-
pairwise comparison classification
[Herbrich00] R. Herbrich, et. al. Large margin rank boundary for ordinal regression. MIT Press, 2000.

23
Task 2: ClassificationRanking
Challenge: With the pairwise classification function, we need to efficiently process ranking.
Solution: developing duality connecting F also as a global per-object ranking function.
Suppose function F is linearClassification View: Ranking View:F(ui-uj)>0 F(ui)- F(uj)>0 F(ui)> F(uj)
b
d e
ac
F(a-b)? F(a)=0.7
F(a-c)?
F(a-d)?….. Rank with F(.)
e.g., F(c)>F(b)>F(d)>…

24
Task 3: Active Learning
Finding samples maximizing learning effectiveness Selective sampling: resolving the ambiguity
Top sampling: focusing on top results
Achieving >90% accuracy in <=3 iterations (<=10 ms)
F
F

25
Using Categorization for Intelligent Retrieval
Category structure created a-priori (typically a manual process) At search time: each search result placed under pre-assigned category Susceptible to skew information overload

26
Categorization: Cost-based Optimization
Categorize results automatically/dynamically Generate labeled, hierarchical category structure dynamically
based on the contents of the tuples in the result set
Does not suffer from problems as in a-priori categorization
Contributions: Exploration/cost models to quantify information overload
faced by an user during an exploration
Cost-driven search to find low cost categorizations
Experiments to evaluate models/algorithms

27
Thank You!






