
Accelerating Proton Computed Tomography with GPUs
Thomas'D.'Uram,'Argonne'Leadership'Compu2ng'Facility'Michael'E.'Papka,'Argonne'Leadership'Compu2ng'Facility,'Northern'Illinois'University'Nicholas'T.'Karonis,'Northern'Illinois'University,'Argonne'Na2onal'Laboratory

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Overview‣ Proton'computed'tomography'(pCT)'is'an'alterna2ve'to'xEray'based'CAT'scans,'which'
promises'several'medical'benefits'at'the'cost'of'being'significantly'more'computa2onally'expensive'
‣ We'designed'a'60Enode'GPU'cluster'to'meet'the'computa2onal'challenge'!
!
‣ Computed'tomography'‣ Benefits'of'proton'computed'tomography'‣ Computa2onal'problem'descrip2on'‣ CPU/GPU'performance'comparison
2

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
What is Computed Tomography?‣ CAT'(or'CT)'scans'are'wellEknown'‣ CAT'=='“computerized'axial'tomography”'‣ CAT'scans'are'used'to'reconstruct'the'density'distribu2on'within'a'volume,'typically'used'
in'medical'imaging'‣ CAT'scans'are'conducted'with'photons'(XErays)'
!
‣ What'is'Proton'Computed'Tomography?'• A'reconstruc2on'technique'similar'to'XEray'computed'tomography,'conducted'with'
protons'instead'of'photons
3

‣ 13'million'people'are'diagnosed'with'cancer'each'year'worldwide'‣ 2.6'million'of'them'are'candidates'for'proton'therapy'treatment'‣ Proton'therapy'involves'deposi2ng'protons'at'precise'loca2ons'within'a'tumor'
site'where'they'irradiate'the'target'2ssue'‣ The'protons'emit'lower'radia2on'as'they'travel'through'the'body'un2l'they'
reach'the'target,'where'they'emit'a'burst'of'radia2on'(the'Bragg'peak)'• Healthy'2ssue'beyond'the'tumor'site'receives'nominally'no'radia2on'
‣ It'is'crucially'important'to'precisely'iden2fy'the'tumor'site'• To'ensure'that'cancerous'2ssue'is'destroyed'• To'avoid'damaging'healthy'2ssue'surrounding'the'tumor,'especially'in'
sensi2ve'areas'‣ Proton'therapy'treatment'planning'is'currently'performed'using'XEray'imaging'
• Photons'and'protons'interact'with'intermediate'material'differently'• Conversion'between'photon/proton'modali2es'involves'a'systema0c'range'
error'of'365%
Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Why Proton Computed Tomography?
4
Image source: Wikipedia

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
‣ Our'goal'is'to'reconstruct'volume'of'adult'human'head'in'under'10'minutes''
‣ Protons'directed'through'two'frontal'planes,'the'target'volume,'two'backing'planes,'and'finally'a'calorimeter'
‣ Measures'posi2on'and'angle'of'incidence'of'protons'at'entry'and'exit,'and'the'energy'loss
5
Final System (in black): 4 tracking planes with XY Si detectors: calorimeter with 64 end=on CsI Crystals
Planned Scaled Prototype (in red): 4 planes of XY Si detectors (2 X-SSDs and 2 Y-SSDs per plane): 8 CsI Crystal bars
Calorimeter: Each bar corresponds to a 5cm x 5cm CsI Crystal, read out by a photodiode
Tracking Plane: Each large square corresponds to one double-sided or two single-sided 9cm x 9cm SSDs
Proton computed tomography

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Problem Description‣ Proton'source,'detector'planes,'and'calorimeter'
mounted'on'rota2ng'gantry,'as'in'familiar'XEray'CT'configura2ons'
‣ Data'collected'over'a'full'rota2on'of'the'gantry,'180'samples'(every'2'degrees)'
‣ Ini2al'detector'designed'to'image'a'human'head'(nominally'25cm'cube)'
‣ From'physics'domain,'and'so'that'each'voxel'is'sufficiently'represented'in'the'resul2ng'system'matrix,'we'approximate'requiring'a'volume'consis2ng'of'256x256x36'(2,359,296=~'2.4M)'voxels'and'2'billion'protons'total'
‣ For'each'proton,'we'track'11'values:'‣ [x,y,z]'at'entry'‣ [x,y,z]'at'exit'‣ angle'at'entry'and'exit'‣ input'and'output'energy'‣ gantry'rota2on'angle
6
Final System (in black): 4 tracking planes with XY Si detectors: calorimeter with 64 end=on CsI Crystals
Planned Scaled Prototype (in red): 4 planes of XY Si detectors (2 X-SSDs and 2 Y-SSDs per plane): 8 CsI Crystal bars
Calorimeter: Each bar corresponds to a 5cm x 5cm CsI Crystal, read out by a photodiode
Tracking Plane: Each large square corresponds to one double-sided or two single-sided 9cm x 9cm SSDs

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Baseline execution times
7
‣ Began'with'serial'code'that'took'more'than'7'hours'to'process'131M'protons'
‣ Parallelized'with'MPI'to'use'mul2ple'CPUs'
‣ Established'baseline'execu2on'2mes
{Phase Execution time (seconds)
Setup 128.2
Most Likely Path (MLP) 1278.5
Linear solver (CARP) 664.9
Overall execution time 2072.0
1 billion protons, 60 nodes, CPU only

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
MLP (Most Likely Path)
8
‣ In'contrast'with'XEray'computed'tomography'in'which'the'par2cles'traverse'the'volume'in'straight'lines,'in'pCT'the'protons'are'scakered'by'the'material'as'they'travel'through'the'volume'
‣ MLP'computes'the'path'integral'of'the'protons'through'the'material'based'on'their'known'entry'and'exit'loca2ons'and'angles'and'the'energy'loss'
‣ The'proton'paths'are'discre2zed'as'the'voxels'touched'while'traversing'the'volume'
‣ Path'integral'calcula2ons'are'independent'and'parallelize'at'the'level'of'protons'(but'inherently'sequen2al'within'each'path)

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Linear solver (CARP)‣ The'result'of'MLP'is'a'system'of'equa2ons'rela2ng'each'proton’s'touched'
voxels'to'the'rela2ve'stopping'power'(roughly,'the'energy'loss)'‣ We'began'the'project'with'a'CPU'implementa2on'of'the'rowEac2on'based'
sparse'itera2ve'solver'CARP'(component'averaged'row'projec2ons)'‣ CARP'decomposes'the'matrix'into'row'blocks,'one'block'per'processor,'and'
iterates'to'sa2sfactory'convergence:'• Performs'a'JacobiElike'itera2on'sequen2ally'through'the'rows'to'produce'a'perE
block'solu2on'vector'• Averages'the'perEblock'solu2on'vectors'(in'componentEwise'fashion)'• Redistributes'the'solu2on'vector'x'to'all'processors
9

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Hardware: Gaea GPU cluster at Northern Illinois University‣ 60'compute'nodes'‣ Node'configura2on'
• 2x'Intel'X5650'12Ecore'CPUs'• 2x'NVIDIA'M2070'GPUs'• 72GB'RAM'• QDR'Infiniband
10

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Data decomposition‣ 2.1B'protons'/'60'nodes'=~'35M'protons'per'node'‣ 2'GPUs'E>'17M'protons'per'GPU'‣ The'maximum'voxels'per'proton'is'~364'‣ 17M'protons'x'364'voxels'x'4'bytes/voxel'='25GB'data'per'GPU'
• Larger'than'available'M2070'GPU'memory'of'6GB'‣ High'watermark'memory'requirement'on'cluster'is'3TB'(aggregate)
11

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
MLP (Most Likely Path) CUDA implementation‣ MLP'involves'calcula2ng'path'integral'of'the'protons'‣ Ini2al'implementa2on'assigns'a'thread'per'proton'‣ PerEGPU'proton'data'is'larger'than'GPU'memory'on'M2070'‣ Stage'batches'of'protons'to'GPU'‣ MLP'was'ported'to'the'GPU,'with'mul2ple'variants'
• gpu'struct:'Direct'port'of'CPUEbased'code'using'structured'proton/voxel'data'• gpu'flat'memory:'Flat'memory'space'with'perEproton'padded'voxel'arrays'• gpu'flat'memory'+'overlap:'Streaming'computa2on'to'overlap'compute'and'
hostEdevice'transfers'
12

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
MLP (Most Likely Path) CUDA implementation (26M protons, 2 GPUs)
13
Implementation Execution time (seconds) Speedup
cpu 598.7 -
gpu_struct 77.6 7.7x
gpu_flat_memory 55.5 10.8x
gpu_flat_memory + overlap 53.0 11.3x

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Linear solver (CARP) CUDA implementation (26M protons, 2 GPUs)‣ CARP'ported'directly'from'CPU'code'‣ PerEnode'rowEblock'data'larger'than'GPU'memory;'batch'process'‣ Further'subdivide'perEnode'rowEblock'into'rowEblocks'per'streaming'mul2processor'
!
!
!
!
!
!
!
‣ Limited'speedup'in'GPU'implementa2on,'because:'• rowEac2on'based'solver'constrains'parallel'granularity'• scakered'memory'accesses'constrain'performance,'as'is'typical'of'sparse'matrix'opera2ons
14
Implementation Execution time (seconds) Speedup
cpu 161.0 -
gpu 139.3 1.16x

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Performance at scale
15
Phase Execution time (seconds)
Setup 22.3
Most Likely Path (MLP) 151.0
Linear solver (CARP) 265.5
Overall execution time 438.8Initial goal was to complete in <600s (10mins)
2'billion'protons,'60'nodes,'12'CPU'cores/node,'2'GPUs/node
Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
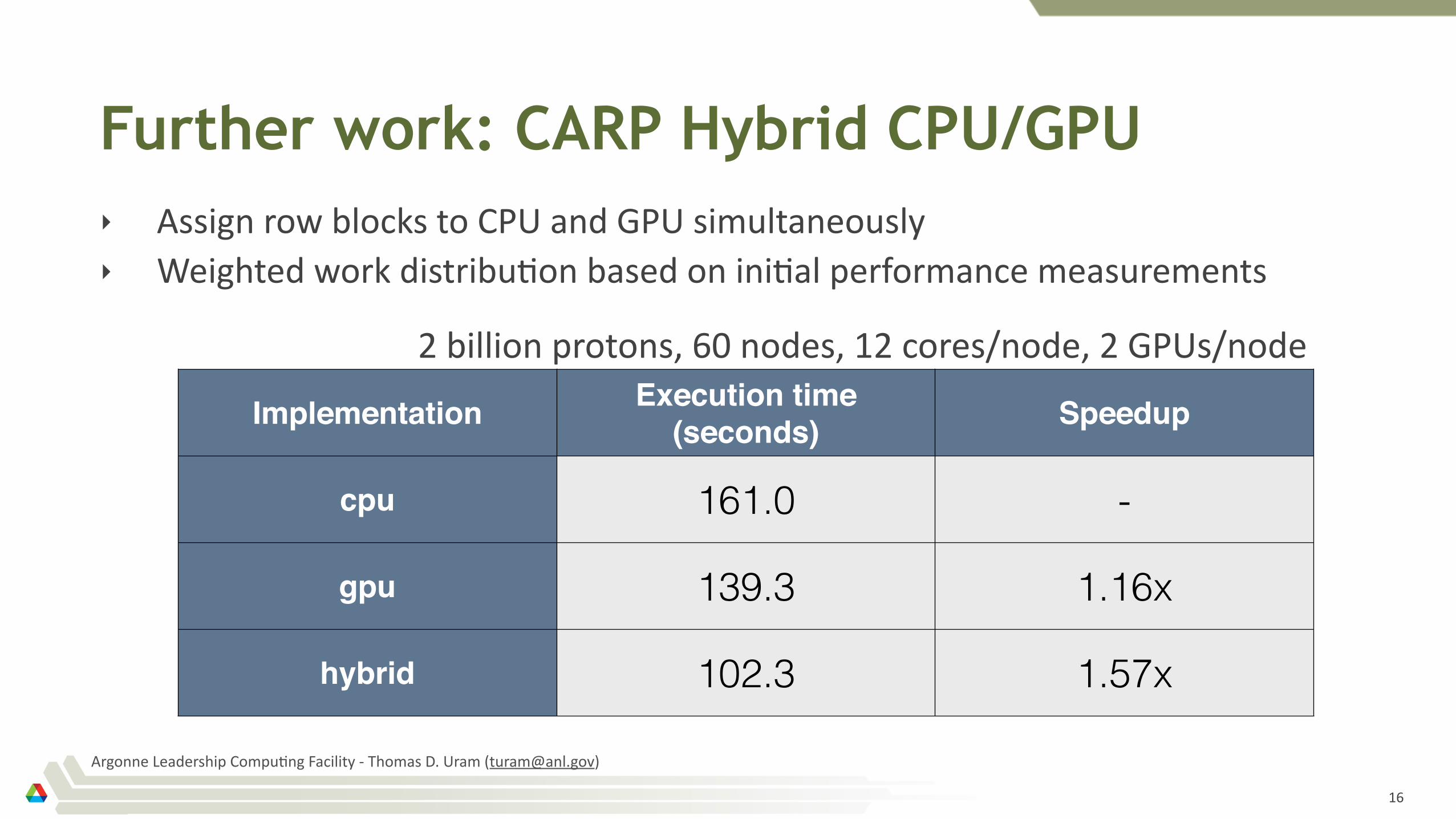
Further work: CARP Hybrid CPU/GPU‣ Assign'row'blocks'to'CPU'and'GPU'simultaneously'‣ Weighted'work'distribu2on'based'on'ini2al'performance'measurements
16
Implementation Execution time (seconds) Speedup
cpu 161.0 -
gpu 139.3 1.16x
hybrid 102.3 1.57x
2'billion'protons,'60'nodes,'12'cores/node,'2'GPUs/node

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
Future work‣ Integrate'alterna2ve'linear'solvers'to'improve'performance
(amgX,'cusparse,'PETSc)'‣ Consider'alternate'data'decomposi2ons'to'improve'cache'locality'
• volume'slab'per'streaming'mul2processor'• volume'wedge'per'streaming'mul2processor''
‣ Measure'performance'on'nextEgenera2on'GPUs'• K80'for'greater'performance'• Jetson/TK1'for'greater'performance/wak'
‣ Experiment'with'GPU'cloud'plauorms'(Amazon'cloud)
17

Argonne'Leadership'Compu2ng'Facility'E'Thomas'D.'Uram'([email protected])
AcknowledgementsNicholas'T.'Karonis,'Northern'Illinois'University'(NIU)'and'Argonne'Na2onal'Laboratory'(ANL)'Michael'E.'Papka,'NIU'and'ANL'Caesar'Ordoñez,'NIU'Eric'Olson,'ANL'Kirk'Duffin,'NIU'Venkat'Vishwanath,'ANL'!
US'Department'of'Defense'contract'number'W81XWHE10E1E0170'sponsored'this'work.'
18







