
1
Software Testing

2
Motivation
• People are not perfect– We make errors in design and code
• Goal of testing: given some code, uncover as many errors as possible
• Important and expensive activity:– May spend 30-40% of total project effort on testing– For safety critical system cost of testing is several
times higher than all other activities combined

3
A Way of Thinking
• Design and coding are creative activities• Testing is destructive
– The primary goal is to “break” the code
• Often same person does both coding and testing– Need “split personality”: when you start testing,
become paranoid and malicious– This is surprisingly difficult: people don’t like
to find out that they made mistakes.

4
Testing Objective
• Testing: a process of executing software with the intent of finding errors
• Good testing: a high probability of finding as-yet-undiscovered errors
• Successful testing: discovers unknown errors

5
Basic Definitions
• Test case: specifies – Inputs + pre-test state of the software– Expected results (outputs an state)
• Black-box testing: ignores the internal logic of the software, and looks at what happens at the interface (e.g., given this inputs, was the produced output correct?)
• White-box testing: uses knowledge of the internal structure of the software– E.g., write tests to “cover” internal paths

6
Testing Approaches
• We will look at a small sample of approaches for testing
• White-box testing– Control-flow-based testing– Loop testing– Data-flow-based testing
• Black-box testing– Equivalence partitioning

7
Control-flow-based Testing
• A traditional form of white-box testing• Step 1: From the source, create a graph describing
the flow of control– Called the control flow graph
– The graph is created (extracted from the source code) manually or automatically
• Step 2: Design test cases to cover certain elements of this graph– Nodes, edges, paths

8
Example of a Control Flow Graph (CFG)
if (x+y < 100) s:=s+x+y; else d:=d+x-y;}
1
2
3
4
5 67
8
s:=0;d:=0;while (x<y) {
x:=x+3;y:=y+2;

9
Elements of a CFG
• Three kinds of nodes:– Statement nodes: represent single-entry-single-exit
sequences of statements– Predicate nodes: represent conditions for branching– Auxiliary nodes: (optional) for easier understanding
(e.g., “join points” for IF, etc.)
• Edges: represents possible flow of control
• It is relatively easy to map standard constructs from programming languages to elements of CFGs
10
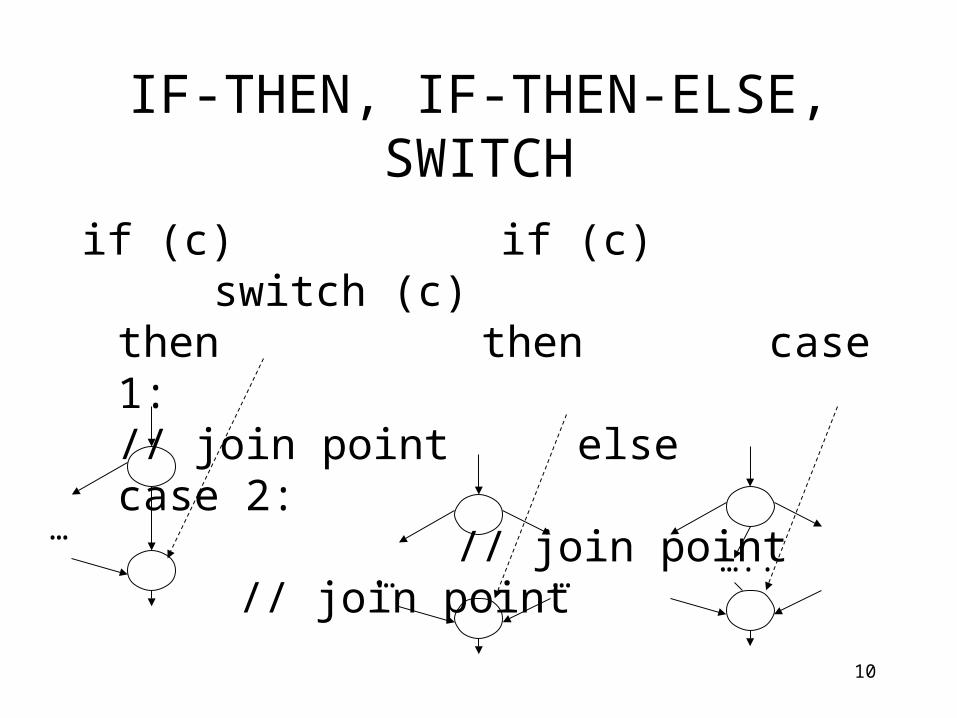
IF-THEN, IF-THEN-ELSE, SWITCH
if (c) if (c) switch (c)then then case 1:// join point else case 2:
// join point // join point
…
… … …..

11
Example
switch (position) case CASHIER if (empl_yrs > 5) bonus := 1; else bonus := 0.7; case MANAGER bonus := 1.5; if (retiring_soon) bonus := 1.2 * bonus case …endswitch
.
.
.
.

12
Mapping for Loops
Note: other loops (e.g., FOR, DO-WHILE,…) are mapped similarly. Figure out how this is done.
while (c) {
} …

13
Statement Coverage
• Basic idea: given the control flow graph define a “coverage target” and write test cases to achieve it
• Traditional target: statement coverage– Need to write test cases that cover all nodes in the
control flow graph
• Intuition: code that has never been executed during testing may contain errors– Often this is the “low-probability” code

14
Example• Suppose that we write and
execute two test cases• Test case #1: follows path 1-
2-exit (e.g., we never take the loop)
• Test case #2: 1-2-3-4-5-7-8-2-3-4-5-7-8-2-exit (loop twice, and both times take the true branch)
• Do we have 100% statement coverage?
1
2
3
4
5 67
8
T F

15
Branch Coverage
• Target: write test cases that cover all branches of predicate nodes– True and false branches of each IF– The two branches corresponding to the
condition of a loop– All alternatives in a SWITCH statement
• In modern languages, branch coverage implies statement coverage

16
Branch Coverage• Statement coverage does not imply branch
coverage– Can you think of an example?
• Motivation for branch coverage: experience shows that many errors occur in “decision making” (i.e., branching)– Plus, it subsumes statement coverage.

17
Example
• Same example as before
• Test case #1: follows path 1-2-exit
• Test case #2: 1-2-3-4-5-7-8-2-3-4-5-7-8-2-exit
• What is the branch coverage?
1
2
3
4
5 67
8
T F

18
Achieving Branch Coverage
• For decades, branch coverage has been considered a necessary testing minimum
• To achieve it: pick a set of start-to-end paths (in the CFG) that cover all branches, and then write test cases to execute these paths
• It can be proven that branch coverage can be achieved with at most E-N+2 paths

19
Example
• First path: 1-2-exit (no execution of the loop)
• Second path: we want to include edge 2-3, so we can pick 1-2-3-4-5-7-8-2-exit
• What would we pick for the third path?
1
2
3
4
5 67
8
T F

20
Determining a Set of Paths
• How do we pick a set of paths that achieves 100% branch coverage?
• Basic strategy:– Consider the current set of chosen paths– Try to add a new path that covers at least one
edge that is not covered by the current paths
• Sometimes, the set of paths chosen with this strategy is called the “basic set”

21
Some Observations
• It may be impossible to execute some of the chosen paths from start-to-end.– Why?– Thus, branches should be executed as part of
other chosen paths
• There are many possible sets of paths that achieve branch coverage

22
Loop Testing
• Branch coverage is not sufficient to test the execution of loops– It means two scenarios will be tested: the loop is
executed zero times, and the loop is executed at least once
• Motivation for more testing of loops: very often there are errors in the boundary conditions
• Loop testing is a white-box technique that focuses on the validity of loops

23
Testing of Individual Loops
• Suppose that m is the min possible number of iterations, and n is the max possible number of iterations
• Write a test case that executes the loop m times and another one that executes it m+1 times
• Write a test case that executes the loop for a “typical number” of iterations
• Write a test case that executes the loop n-1 times and another one for n times

24
Testing of Individual Loops (cont.)
• If it is possible to have variable values that imply less than m iterations or more than n iterations, write test cases using those
• E.g., if we have a loop that is only supposed to process at most the 10 initial bytes from an array, run a test case in which the array has 11 bytes

25
Nested Loops
• Example: with 3 levels of nesting and 5 test cases for each level, total of 125 possible combinations: too much
• Start with the innermost loop do the tests (m,m+1, typical, ), keep the other loops at their min number of iterations
• Continue toward the outside: at each level, do tests (m,m+1, typical, )– The inner loops are at typical values– The outer loops are at min values

26
Data-flow-based Testing
• Basic idea: test the connections between variable definitions (“write”) and variable uses (“read”)
• Starting point: variation of the control flow graph– Each node represents a single statement, not a chain of
statements
• Set DEF(n) contains variables that are defined at node n (i.e., they are written)
• Set USE(n): variables that are read

27
ExampleAssume y is already initialized
1 s:= 0;2 x:= 0;3 while (x<y) {4 x:=x+3;5 y:=y+2;6 if (x+y<10)7 s:=s+x+y; else8 s:=s+x-y;
DEF(1) := {s}, USE(1) := DEF(2) := {x}, USE(2) :=DEF(3) := , USE(3) := {x,y}DEF(4) := {x}, USE(4) := {x}DEF(5) := {y}, USE(5) := {y}DEF(6) := , USE(6) := {x,y}DEF(7) := {s}, USE(7) := {s,x,y}
DEF(8) := {s}, USE(8) := {s,x,y}DEF(9) := , USE(9) := DEF(10) := , USE(10) :=
1 2 3
4
5
6
7 8
9
10

28
Reaching DefinitionsA definition of variable x at node n1
reaches node n2 if and only if there is a path between n1 and n2 that does not contain a definition of x
DEF(1) := {s}, USE(1) := DEF(2) := {x}, USE(2) :=DEF(3) := , USE(3) := {x,y}DEF(4) := {x}, USE(4) := {x}DEF(5) := {y}, USE(5) := {y}DEF(6) := , USE(6) := {x,y}DEF(7) := {s}, USE(7) := {s,x,y}DEF(8) := {s}, USE(8) := {s,x,y}
1 2 3
4
5
6
7 8
9
10
Reaches nodes 2,3,4,5,6,7,8, but not 9 and 10.

29
Def-use Pairs
• A def-use pair (DU) for variable x is a pair of nodes (n1,n2) such that – x is in DEF(n1)
– The definition of x at n1 reaches n2
– x is in USE(n2)
• In other words, the value that is assigned to x at n1 is used at n2– Since the definition reaches n2, the value is not killed
along some path n1...n2.

30
Examples of Def-Use Pairs
DEF(1) := {s}, USE(1) := DEF(2) := {x}, USE(2) :=DEF(3) := , USE(3) := {x,y}DEF(4) := {x}, USE(4) := {x}DEF(5) := {y}, USE(5) := {y}DEF(6) := , USE(6) := {x,y}DEF(7) := {s}, USE(7) := {s,x,y}DEF(8) := {s}, USE(8) := {s,x,y}
1 2 3
4
5
6
7 8
9
10
Reaches nodes 2, 3, 4, 5, 6, 7, 8, but not 9,10
For this definition, two DU pairs:1-7, 1-8

31
Data-flow-based Testing
• Identify all DU pairs and construct test cases that cover these pairs– Several variations with different “relative strength”
• All-DU-paths: For each DU pair (n1,n2) for x, exercise all possible paths n1, n2 that are clear of a definition of x
• All-uses: for each DU pair (n1,n2) for x, exercise at least one path n1 n2 that is clear of definitions of x

32
Data-flow-based Testing
• All-definitions: for each definition, cover at least one DU pair for that definition– i.e., if x is defined at n1, execute at least one path n1..n2
such that x is in USE(n2) and the path is clear of definitions of x
• Clearly, all-definitions is subsumed by all-uses which is subsumed by all-DU-paths
• Motivation: see the effects of using the values produced by computations – Focuses on the data, while control-flow-based testing
focuses on the control

33
Black-box Testing
• Unlike white-box testing, here we don’t use any knowledge about the internals of the code
• Test cases are designed based on specifications– Example: search for a value in an array
• Postcondition: return value is the index of some occurrence of the value, or -1 if the value does not occur in the array
• We design test cases based on this spec

34
Equivalence Partitioning
• Basic idea: consider input/output domains and partition them into equiv. classes– For different values from the same class, the
software should behave equivalently
• Use test values from each class– Example: if the range for input x is 2..5, there
are three classes: “<2”, “between 2..5”, “5<”– Testing with values from different classes is
more likely to uncover errors than testing with values from the same class

35
Equivalence Classes
• Examples of equivalence classes– Input x in a certain range [a..b]: this defines three
classes “x<a”, “a<=x<=b”, “b<x”– Input x is boolean: classes “true” and “false”– Some classes may represent invalid input
• Choosing test values– Choose a typical value in the middle of the class(es)
that represent valid input– Also choose values at the boundaries of all classes:
e.g., if the range is [a..b], use a-1,a, a+1, b-1,b,b+1

36
Example
• Suppose our spec says that the code accepts between 4 and 24 inputs, and each one is a 3-digit integer
• One partition: number of inputs– Classes are “x<4”, “4<=x<=24”, “24<x”– Chosen values: 3,4,5, 14, 23,24,25
• Another partition: integer values– Classes are “x<100”, “100<=x<=999”, “999<x”– Chosen values: 99,100,101, 500, 998,999,1000

37
Another Example
• Similar approach can be used for the output: exercise boundary values
• Suppose that the spec says “the output is between 3 and 6 integers, each one in the range 1000-2500
• Try to design input that produces– 3 outputs with value 1000– 3 outputs with value 2500– 6 outputs with value 1000– 6 outputs with value 2500

38
Example: Searching
• Search for a value in an array– Return value is the index of some occurrence of
the value, or -1 if the value does not occur in the array
• One partition: size of the array– Since people often make errors for arrays of
size 1, we decide to create a separate equivalence class
– Classes are “empty arrays”, array with one element”, “array with many elements”

39
Example: Searching
• Another partition: location of the value– Four classes: “first element”, “last element”, “middle element”,
“not found”
Array Value OutputEmpty 5 -1[7] 7 0[7] 2 -1[1,6,4,7,2] 1 0[1,6,4,7,2] 4 2[1,6,4,7,2] 2 4[1,6,4,7,2] 3 -1

40
Testing Strategies
• We talked about testing techniques (white-box, black-box)
• Many unanswered questions– E.g., who does the testing? – Which techniques should we use ?– And when? – And more…?
• There are no universal strategies, just principles that have been useful in practice– E.g., the notions of unit testing and integration testing

41
Some Basic Principles
• Testing starts at the component level and works “outwards”– Unit testing integration testing system testing
• Different testing techniques are appropriate at different scopes
• Testing is conducted by developers and/or by a specialized group of testers
• Testing is different from debugging– Debugging follows successful testing

42
Scope and Focus
• Unit testing: scope = individual component– Focus: component correctness– White-box and black-box techniques
• Integration testing: scope = set of interacting components– Focus: correctness of component interactions– Mostly black-box, some white-box techniques
• System testing: scope = entire system– Focus: overall system correctness– Only black-box techniques

43
Test-First Principle
• Modern practices emphasize the importance of testing during development
• Example: test-first programming– Basic idea: before you start writing any code, first write
the tests for this code
– Write a little test code, write the corresponding unit code, make sure it passes the tests, and then repeat
– What programming methodology uses this approach?
– What are the advantages of test-first programming?

44
Advantages of Test-First Programming
• Developers do not “skip” unit testing• Satisfying for the programmer: feeling of
accomplishment when the tests pass• Helps clarify interface and behavior before
programming– To write tests for something, first you need to
understand it well!
• Software evolution– After changing existing code, rerun the tests to gain
confidence (regression testing)

45
Traditional Testing Strategies

46
Context for Traditional Testing• Waterfall model: starts with requirements
analysis then design– The design often has a hierarchical module
structure
Direction of increasing decision making
Typical decision making module
Typical worker modules

47
Context for Traditional Testing
• Modules are tested and integrated in some order based on the module hierarchy– Two common cases: top-down order and bottom-up
order
– Unit testing: focus on an individual module
– Integration testing focus on module interactions, after integration
• System testing: the entire system is tested w.r.t. customer requirements, as described in the spec

48
Unit Testing
• Scope: one component from the design– Often corresponds to the notion of “compilation unit”
from the programming language
• Responsibility of the developer– Not the job of an independent testing group
• Both white-box and black-box techniques are used for unit testing
• Maybe necessary to create stubs: – If modules not yet implemented or not yet tested

49
Basic Strategy for Unit Testing
• Create black-box tests– Based on the specification of the unit (as determined
during design)• Evaluate the tests using white-box techniques (test
adequacy criteria)– How well did the tests cover statements, branches,
paths, DU-pairs, etc.?– Many possible criteria; at the very least need 100%
branch coverage• Create more tests for the inadequacies: e.g., to
increase coverage of DU-pairs

50
System Testing
• Goal: find whether the program does what the customer expects to see– Black-box techniques
• In the spec created during requirements analysis, there should be validation criteria– How are the developers and the customers going to
agree that the software is OK?
• Many issues: functionality, performance, documentation, usability, portability, etc.

51
System Testing (cont)
• Initial part of system testing is done by the software producer
• Eventually, we need testing done by the customers– Every time a customer runs the software he/she is
testing it– Customers are good at doing unexpected things, which
is great for testing• If the software is build for a single customer:
series of acceptance tests– Deploy the software in the customer environment and
have end-users run it

52
System Testing (cont)
• If the software is produced for multiple customers: two phases
• Alpha testing: conducted at the vendor’s site by a few customers– The vendor records any errors and usage problems
• Beta testing: the software is distributed to many end-users; they run it in their own environment and report problems– Often done by thousands of users

53
Stress Testing
• Form of system testing: the behavior of the system under very heavy load– E.g., what if we have data sets that are an order
of magnitude larger than normal? Will we run out of memory? Will the OS start writing memory pages to disk (thrashing)?
– E.g., what if our server gets 10 times more client requests than usual?

54
Stress Testing (cont)
• Goal: find how well the system can cope with overload
• Reason 1: determine failure behavior – If load goes above the intended (which often is a
possibility) how gracefully does the system fail?
• Reason 2: expose bugs that only occur under heavy loads– Especially for OS, middleware, servers, etc.– E.g., memory leaks, incorrect resource allocation and
scheduling, race conditions

55
Regression Testing
• Basic idea: rerun old tests to make sure that nothing was “broken” by a change– Changes: bug fixes, module integration, maintenance
enhancements, etc.
• To be able to do this regularly, need test automation tools– Load tests, execute them, check correctness – Everything has to be completely automatic
• Could happen at any time: during initial development or after deployment

56
• Questions on the exam?







